DeepSeek使用與提示詞工程課程重點
Homework:ollama 安裝 用deepseek-r1:1.5b 分析PDF 內容
python 代碼建構:
1.小模型 1.5b 可以在 筆記本上快速執行
2.分析結果還不錯
3. 重點是提示詞 prompt 的寫法
一、DeepSeek模型創新與特點
1. DeepSeek-V3模型特點
- 采用MoE架構(61個專家模塊),總參數量671B但僅激活37B參數
- 引入MLA(Multi-Head Latent Attention)注意力機制,顯著減小KV緩存
- 使用混合精度框架(FP8)降低訓練計算量
- 在主流榜單中與頂級閉源模型性能相當
2. DeepSeek-R1模型突破
- 基于V3模型通過GRPO強化學習訓練
- 思維鏈長度可達數萬字,支持復雜推理
- 性能對標OpenAI o1模型
- 提供API調用(deepseek-reasoner)
二、模型部署與使用
1. 私有化部署選項
| 模型類型 | 參數量 | 顯存需求 | 適用場景 |
|---|---|---|---|
| 1.5B-14B | 小模型 | 1-12GB | 輕量級任務 |
| 32B | 中模型 | 24-48GB | 專業領域 |
| 70B | 大模型 | 96-128GB | 高精度任務 |
| 671B | 滿血版 | 496GB | AGI研究 |
2. 部署方式
?Ollama部署?:支持macOS/Linux/Windows
ollama pull deepseek-r1:1.5b ollama run deepseek-r1:1.5b?vLLM高速推理框架?: 公司使用
vllm serve deepseek-r1-distill-qwen-32b --tensor-parallel-size 2
三、提示詞工程核心原則
1. 提示詞組成要素(重要性排序)
- ?任務?:明確動詞開頭的目標
- ?上下文?:提供背景信息
- ?示例?:展示期望輸出格式
- ?角色?:指定AI扮演的身份
- ?格式?:定義輸出結構
- ?語氣?:設定回答風格
2. 通用模型vs推理模型提示策略
| 模型類型 | 提示特點 | 適用場景 |
|---|---|---|
| 通用模型 | 需要分步引導,依賴Few-shot示例 | 創意寫作、常規問答 |
| 推理模型 | 簡潔指令,信任內化能力 | 數學、編程等邏輯任務 |
四、Prompt實戰技巧
1. 核心技巧
?限制輸出格式?:如JSON結構化返回
"以JSON格式輸出包含名稱、價格、流量的套餐信息"?使用分隔符?:清晰區分輸入部分
'''請總結以下三個引號內的文本'''?CoT思維鏈?:分步解決復雜問題
"請按步驟計算:1.加1000 2.減500 3.乘1.2"
2. 優化方法
- ?迭代測試?:根據輸出持續調整Prompt
- ?角色扮演?:明確AI身份(如"你是一名專業客服")
- ?示例引導?:提供輸入輸出對示范
五、典型應用案例
1. 小球碰撞模擬
- 使用DeepSeek-R1生成HTML/JavaScript代碼
- 通過多次交互優化物理效果
- 最終實現包含重力、彈力等參數的完整模擬
2. 客服場景Prompt優化
"""
你是一名電信客服"小瓜",需:
1. 保持禮貌官方口吻
2. 準確提及套餐名稱、價格、流量
3. 不可使用網絡用語
已知套餐:
- 經濟套餐:50元/10G
- 暢游套餐:180元/100G
"""Ollama 運用代碼
流程說明
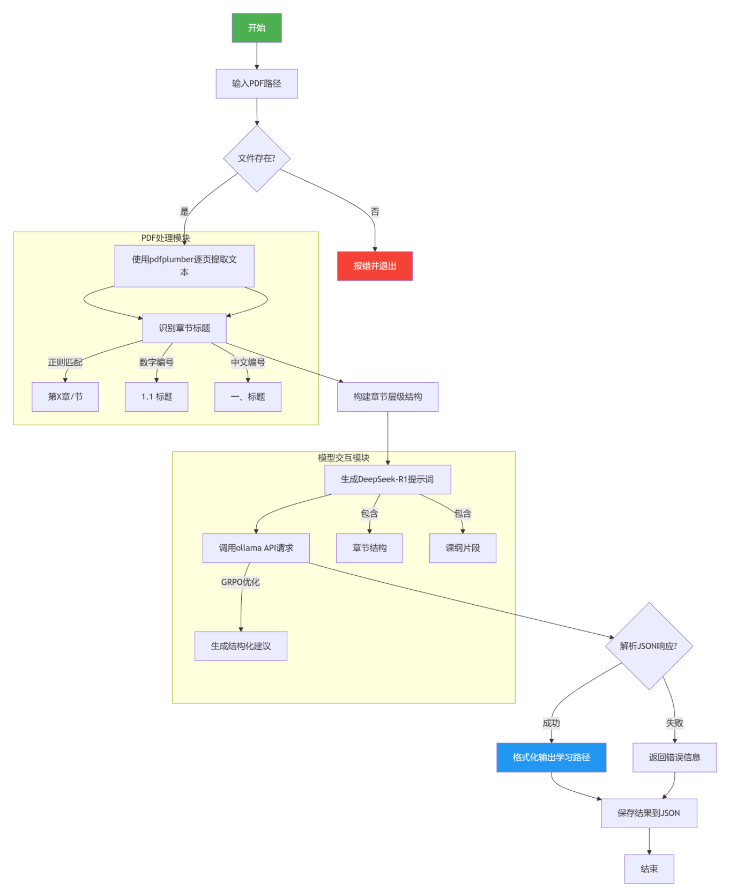
?PDF解析階段?
1. 代碼功能概述?
該代碼實現了一個課程大綱分析系統,主要功能包括:
?2.2 學習路徑生成?
?2.3 輸出處理?
?3. 關鍵技術點?
?4. 擴展應用場景?
?5. 改進建議?
- ?PDF文本提取?:使用
pdfplumber庫解析PDF文件,提取文本內容和章節結構 - ?章節識別?:通過正則表達式匹配多級標題(如"第X章"、"1.1"等格式)
- ?學習路徑生成?:調用DeepSeek-R1模型(通過Ollama API)生成結構化學習建議
- ?結果輸出?:
2. 核心模塊解析?
?2.1 PDF解析與章節識別?
- ?文本提取?:
使用pdfplumber.open()逐頁讀取PDF,通過extract_text()獲取文本內容,并標注頁碼信息。 - ?標題識別邏輯?:
- 正則匹配多級標題(如
r'^第[一二三四五六七八九十\d]+章'匹配中文章節) - 輔助規則:全大寫文本、含"學習"/"知識"等關鍵詞的短文本也被視為標題
- 層級判定:
- 一級標題:
第X章或1. 標題 - 二級標題:
1.1 標題或一、標題 - 三級標題:
1.1.1 標題
- 一級標題:
- 正則匹配多級標題(如
- ?模型交互?:
- 構建結構化提示詞,包含章節樹狀結構和課綱前8000字符
- 調用DeepSeek-R1時啟用
temperature=0.2和top_p=0.9,平衡創造性與穩定性 - 響應解析優先提取JSON塊(兼容模型可能附加的解釋文本)
- ?錯誤處理?:
- JSON解碼失敗時保留原始響應
- 捕獲API超時等異常
- ?控制臺展示?:
格式化輸出學習階段、核心概念、練習順序等,使用符號圖標(如📖、🎯)增強可讀性 - ?JSON持久化?:
按時間戳生成文件名,確保ASCII轉義關閉(ensure_ascii=False)以支持中文 ?PDF解析優化?
- 混合正則規則與啟發式判斷,提升標題識別準確率
- 記錄頁碼+行號,便于人工校驗
?大模型工程化應用?
- 兩階段生成:先提取章節結構,再填充細節(如學習目標、練習類型)
- 通過
num_predict=2000確保長文生成完整性
?結構化輸出設計?
{"learning_stages": [{"stage_number": 1,"key_concepts": ["核心概念1", "核心概念2"],"practice_order": ["練習類型1", "練習類型2"]}] }字段覆蓋教學設計的核心要素(時間預估、預習要求等)
- ?教育自動化?:適配在線教育平臺的課程規劃自動化
- ?文檔分析?:擴展支持EPUB、Word等格式(需調整解析邏輯)
- ?多模型支持?:替換Ollama接口為其他LLM(如GPT-4)
- ?性能優化?
- 使用多線程處理PDF分頁解析(注意
pdfplumber的線程安全性) - 緩存模型響應,減少重復請求
- 使用多線程處理PDF分頁解析(注意
- ?錯誤恢復?
- 添加PDF解析失敗時的備用文本提取方案(如
PyMuPDF)
- 添加PDF解析失敗時的備用文本提取方案(如
- ?交互增強?
- 支持用戶手動修正誤識別的章節標題
- 支持控制臺格式化展示和JSON文件保存
6.完整代碼
try:import pdfplumber
except ImportError:print("? 請安裝pdfplumber: pip install pdfplumber")exit(1)import ollama
from typing import List, Dict, Tuple
import re
import json
import os
from datetime import datetimeclass SyllabusAnalyzer:def __init__(self, model_name="deepseek-r1:1.5b"):self.model_name = model_namedef extract_pdf_content(self, pdf_path: str) -> Tuple[str, List[Dict]]:"""提取PDF內容并識別章節結構"""if not os.path.exists(pdf_path):raise FileNotFoundError(f"PDF文件不存在: {pdf_path}")full_text = ""sections = []with pdfplumber.open(pdf_path) as pdf:for page_num, page in enumerate(pdf.pages):# 提取頁面文本text = page.extract_text()if text:full_text += f"\n=== 第{page_num+1}頁 ===\n{text}\n"# 按行分析文本,識別章節標題lines = text.split('\n')for line_num, line in enumerate(lines):clean_line = line.strip()if clean_line and self._is_section_title(clean_line):level = self._determine_section_level(clean_line)sections.append({"title": clean_line,"level": level,"page": page_num + 1,"line": line_num + 1})return full_text, sectionsdef _is_section_title(self, text: str) -> bool:"""判斷是否為章節標題"""# 匹配各種章節標題格式patterns = [r'^第[一二三四五六七八九十\d]+章', # 第X章r'^第[一二三四五六七八九十\d]+節', # 第X節r'^\d+\.\s+.+', # 1. 標題r'^\d+\.\d+\s+.+', # 1.1 標題r'^[一二三四五六七八九十]+、', # 一、標題r'^([一二三四五六七八九十\d]+)', # (一)標題]for pattern in patterns:if re.match(pattern, text):return True# 檢查是否為全大寫標題或特殊格式return len(text) < 50 and (text.isupper() or '學習' in text or '知識' in text)def _determine_section_level(self, text: str) -> int:"""確定章節層級"""if re.match(r'^第[一二三四五六七八九十\d]+章', text):return 1elif re.match(r'^\d+\.\s+', text):return 1elif re.match(r'^\d+\.\d+\s+', text):return 2elif re.match(r'^\d+\.\d+\.\d+\s+', text):return 3else:return 2def generate_learning_path(self, pdf_text: str, sections: List[Dict]) -> Dict:"""使用deepseek-r1模型生成學習路徑"""# 構建章節結構section_structure = self._build_section_structure(sections)# 構建詳細的提示詞prompt = self._build_analysis_prompt(section_structure, pdf_text)try:response = ollama.chat(model=self.model_name,messages=[{"role": "user", "content": prompt}],options={"temperature": 0.2,"top_p": 0.9,"num_predict": 2000})# 嘗試解析JSON響應content = response['message']['content']# 提取JSON部分(如果響應包含其他文本)json_match = re.search(r'\{.*\}', content, re.DOTALL)if json_match:json_str = json_match.group()return json.loads(json_str)else:# 如果沒有找到JSON,嘗試直接解析return json.loads(content)except json.JSONDecodeError as e:return {"error": f"JSON解析失敗: {str(e)}","raw_response": response['message']['content']}except Exception as e:return {"error": f"生成學習路徑時出錯: {str(e)}","raw_response": str(e)}def _build_section_structure(self, sections: List[Dict]) -> str:"""構建章節結構字符串"""structure_lines = []for i, section in enumerate(sections[:30]): # 限制章節數量indent = " " * (section['level'] - 1)structure_lines.append(f"{indent}{section['title']} (第{section['page']}頁)")return "\n".join(structure_lines)def _build_analysis_prompt(self, section_structure: str, pdf_text: str) -> str:"""構建分析提示詞"""return f"""你是一名專業的教學設計師和課程規劃專家。請根據以下課綱內容,設計一份詳細的學習路徑指南。## 課綱章節結構:
{section_structure}## 分析要求:
1. 將整個課程合理劃分為3-5個學習階段
2. 每個階段建議學習2-4個章節
3. 為每個階段標注建議學習時長(以小時為單位)
4. 明確指出每個階段需要預習的知識點
5. 推薦每個階段的練習順序和類型
6. 提取每個章節的核心知識點(3-5個)## 輸出格式(嚴格按照JSON格式):
{{"course_title": "課程名稱","total_estimated_hours": 總學習時長,"learning_stages": [{{"stage_number": 1,"stage_name": "階段名稱","chapters": ["章節1", "章節2", "章節3"],"suggested_hours": 學習時長數字,"prerequisites": ["預習知識點1", "預習知識點2"],"key_concepts": ["核心概念1", "核心概念2", "核心概念3"],"practice_order": ["練習類型1", "練習類型2", "練習類型3"],"learning_objectives": ["學習目標1", "學習目標2"]}}],"study_tips": ["學習建議1", "學習建議2", "學習建議3"]
}}## 課綱內容:
{pdf_text[:8000]}請嚴格按照上述JSON格式輸出,確保所有字段都包含有意義的內容。"""def save_results(self, learning_path: Dict, output_file: str = None):"""保存分析結果到文件"""if output_file is None:timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")output_file = f"learning_path_{timestamp}.json"with open(output_file, 'w', encoding='utf-8') as f:json.dump(learning_path, f, ensure_ascii=False, indent=2)print(f"學習路徑已保存到: {output_file}")def display_learning_path(self, learning_path: Dict):"""格式化顯示學習路徑"""if "error" in learning_path:print("? 生成學習路徑時出錯:")print(learning_path["error"])if "raw_response" in learning_path:print("\n原始響應:")print(learning_path["raw_response"])returnprint("📚 課程學習路徑分析")print("=" * 60)print(f"課程名稱: {learning_path.get('course_title', '未知課程')}")print(f"預計總時長: {learning_path.get('total_estimated_hours', '未知')} 小時")print()for stage in learning_path.get('learning_stages', []):print(f"🎯 階段 {stage.get('stage_number', '?')}: {stage.get('stage_name', '未知階段')}")print(f" ?? 建議時長: {stage.get('suggested_hours', '?')} 小時")print(f" 📖 包含章節: {', '.join(stage.get('chapters', []))}")print(" 🔍 核心知識點:")for concept in stage.get('key_concepts', []):print(f" ? {concept}")print(" 📋 預習要求:")for prereq in stage.get('prerequisites', []):print(f" ? {prereq}")print(" 🏃 練習順序:")for i, practice in enumerate(stage.get('practice_order', []), 1):print(f" {i}. {practice}")print(" 🎯 學習目標:")for objective in stage.get('learning_objectives', []):print(f" ? {objective}")print("-" * 60)if 'study_tips' in learning_path:print("💡 學習建議:")for tip in learning_path['study_tips']:print(f" ? {tip}")def main():"""主函數"""# 初始化分析器analyzer = SyllabusAnalyzer()# PDF文件路徑 - 請修改為你的實際路徑pdf_path = input("請輸入課綱PDF文件路徑: ").strip().strip('"')if not pdf_path:print("? 請提供有效的PDF文件路徑")returntry:print("📖 正在提取PDF內容...")pdf_text, sections = analyzer.extract_pdf_content(pdf_path)print(f"? 成功提取 {len(sections)} 個章節")print("🤖 正在使用 deepseek-r1:1.5b 分析課綱...")learning_path = analyzer.generate_learning_path(pdf_text, sections)print("📊 分析完成,正在顯示結果...")analyzer.display_learning_path(learning_path)# 保存結果save_option = input("\n是否保存結果到文件?(y/n): ").strip().lower()if save_option == 'y':analyzer.save_results(learning_path)except FileNotFoundError:print(f"? 找不到PDF文件: {pdf_path}")except Exception as e:print(f"? 處理過程中出錯: {str(e)}")if __name__ == "__main__":main()7. 輸出截屏
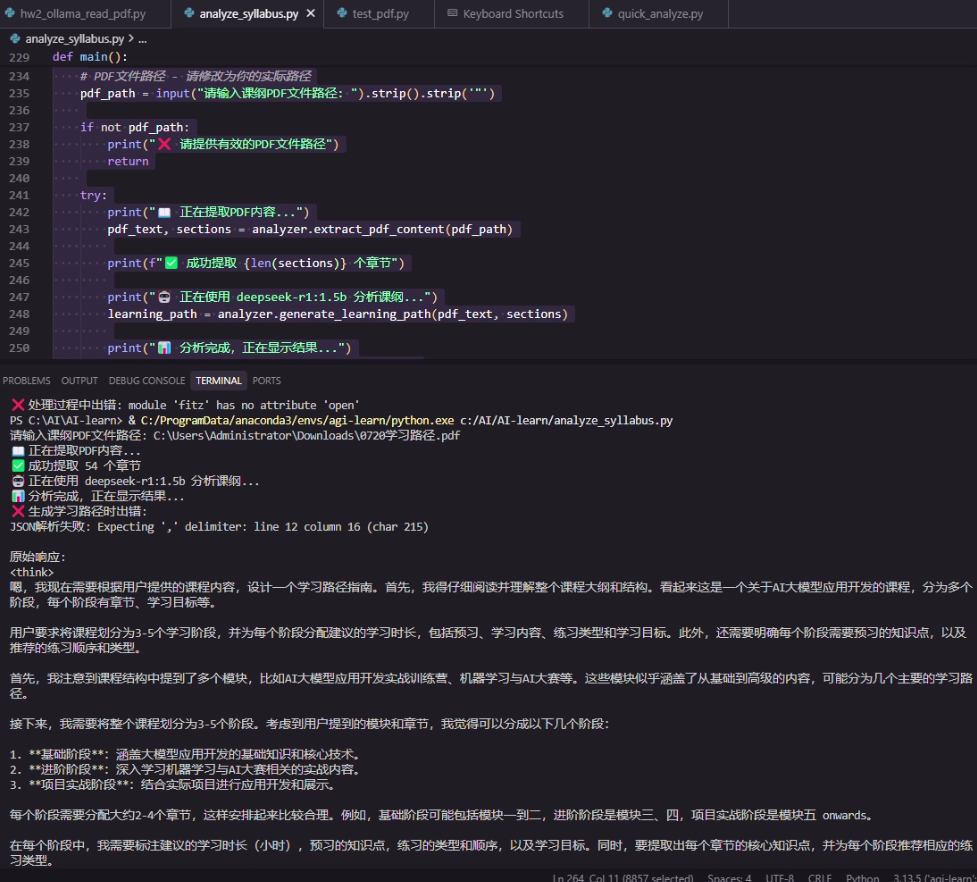
)

)
IO流:數據洪流中的航道設計)

)
)


)


順序表算法題)






