Zipformer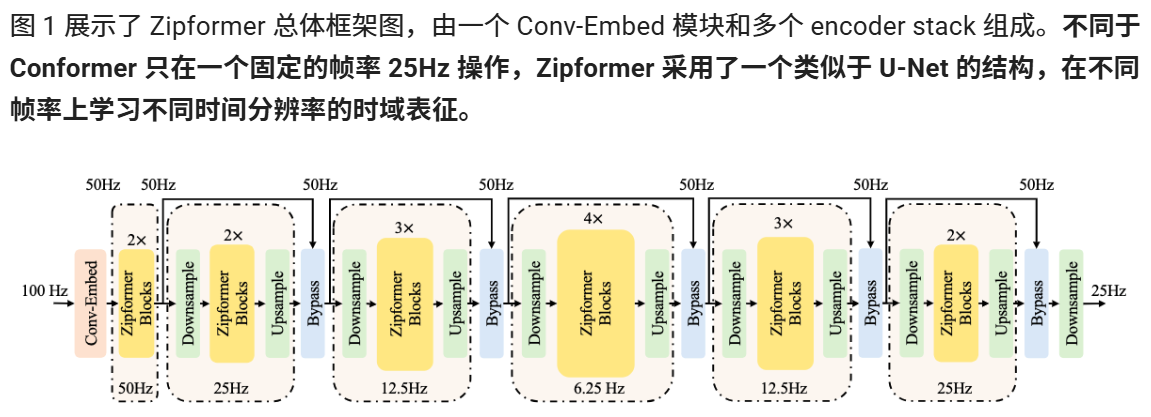
首先,Conv-Embed 將輸入的 100Hz 的聲學特征下采樣為 50 Hz 的特征序列;然后,由 6 個連續的 encoder stack 分別在 50Hz、25Hz、12.5Hz、6.25Hz、12.5Hz 和 25Hz 的采樣率下進行時域建模。除了第一個 stack 外,其他的 stack 都采用了降采樣的結構。在 stack 與 stack 之間,特征序列的采樣率保持在 50Hz。不同的 stack 的 embedding 維度不同,中間stack 的 embedding 維度更大。每個 stack 的輸出通過截斷或者補零的操作,來對齊下一個 stack 的維度。Zipformer 最終輸出的維度,取決于 embedding 維度最大的 stack。















)


)
)


