2.3 匯編學習環境
我們通過上一章筆記,得知 計算機好像 只會通過位運算 進行 數字的加法。
而機器語言的魅力就是 位運算,解析規則。它們也都是通過 電路 來進行實現的。這就是 計算機最底層的本質了!!!
- 匯編語言
所謂的匯編語言,不就是 通過助記符,來替代我們的 二進制嘛。只是為了 簡化 我們的操作。而被發明出來的。
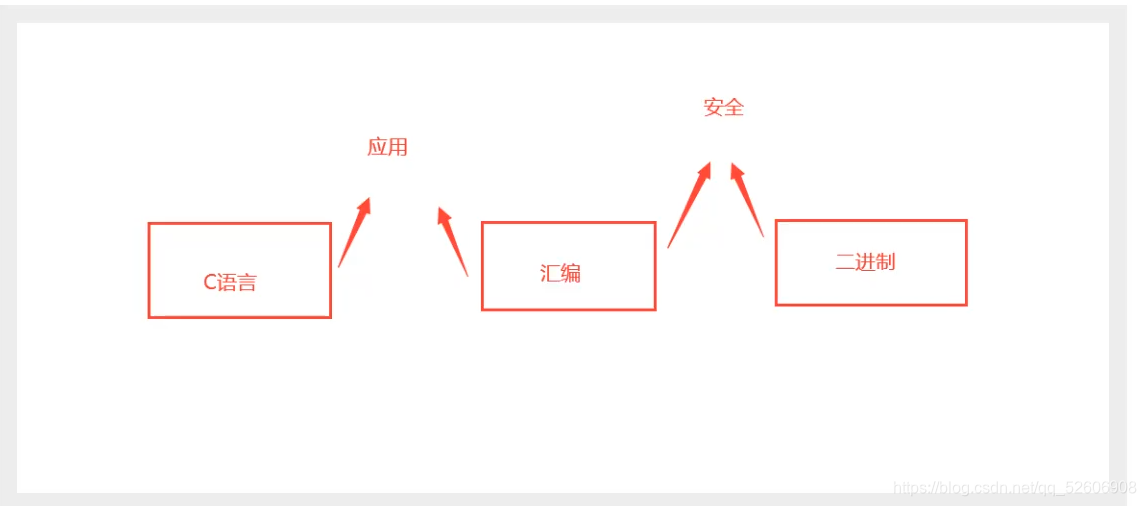
32 位 和 64位 的本質架構區別不大,只是尋址能力得到了增強。
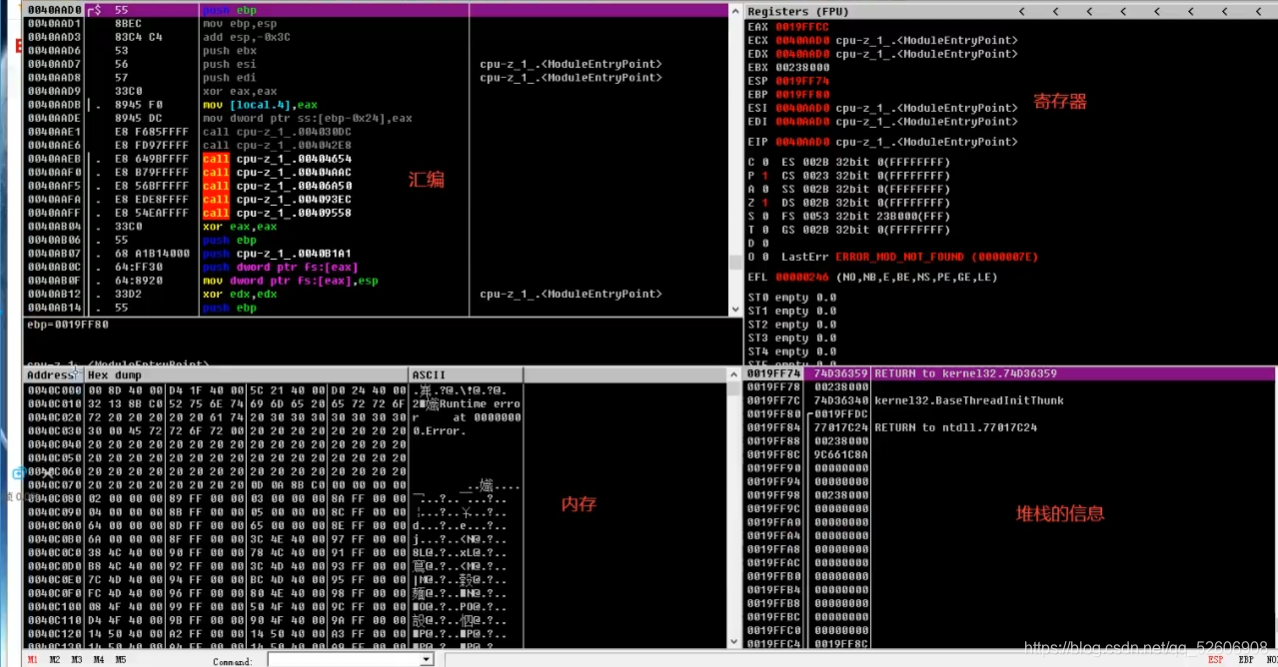
目前 學習匯編 其實不需要什么 IDE 去寫代碼寫程序了。而是 直接 下載 反匯編 工具 就可以。比如 OD、CE、x64dbg 這些。當然 搭配 VC++6.0 食用更佳。
2.4 通用寄存器(可以存儲任何的值)
存儲數據的過程:CPU --> 內存 --> 硬盤
32 位 CPU :8 16 32
64 位 CPU :8 16 32 64
現在的 操作系統其實都是向下兼容的!也就是說 32 位 的軟件有很多很多呀。但是 都可以 運行在 64 位的系統上。
- 32位的通用寄存器 只有 8個

存值的范圍只有:0 ~ FFFF FFFF
計算機如果向寄存器里存值,怎么存 ?
答:mov指令 直接 就能 存。
mov 目標地址,存儲的數值
mov 目標地址,被傳輸的地址
mov 目標寄存器,存儲的數值
mov 目標寄存器,被傳輸的寄存器
不同的寄存器(存儲的數據寬度也不同)
| 32位 | 16位 | 8位 |
|---|---|---|
| EAX | AX | AL(AX的低八位) |
| EBX | BX | BL (BX的低八位) |
| ECX | CX | CL (CX的低八位) |
| EDX | DX | DL (DX的低八位) |
| ESP | SP | AH(AX的高八位) |
| EBP | BP | BH (BX的高八位) |
| ESI | SI | CH(CX的高八位) |
| EDI | DI | DH (DX的高八位) |
ESP:通常存儲棧頂的地址
EBP:通常存儲棧底的地址
EIP:通常存儲的是 調用的 CALL 的地址。(跳轉地址)
2.4 內存
寄存器是很小的,不夠用。所以說,我們的數據怎么存儲呢?就誕生了一個東西,叫做 內存。
我們規定每個應用程序進程 其實 都可以 使用 4GB 的內存空間。(也被我們稱為 虛擬內存)但實際上我們并不能用那么多的內存空間。所以相當于 空頭支票。
內存地址:其實就是 為我們的每一塊內存 起的一個名字。方便我們找到它。
尋址能力:就是能夠 找到多大 范圍的 地址。x86(32位) 能夠找到 0x FFFF FFFF 的地址。 這其實 不算 龐大。
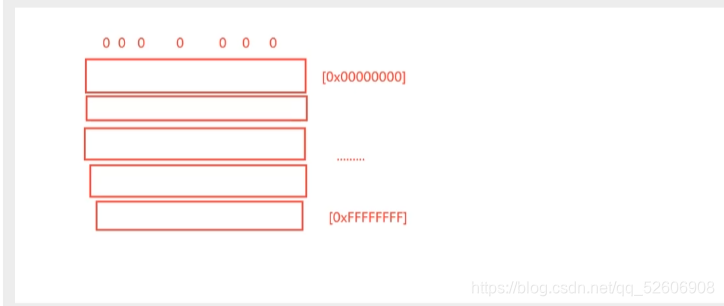
32 位 內存地址的數量是 FFFF FFFF + 1 = 4,294,967,297 個地址。
一個地址 對應著 一個 八位的 二進制串。也就是說 一個地址 相當于 一個字節。
所以理論上 能存 4,294,967,297 /1024 /1024 /1024 = 4GB
所以我們才說,32位 理論上 4GB 就是它的極限。
- x64 位尋址能力 和 極限
x64 位尋址能力:0 - 0xFFFF FFFF FFFF FFFF
1,152,921,504,606,846,976 * 16 個內存地址。
x64 的 極限:17,179,869,184 GB
其實指針是什么呢?就是用來存儲 內存地址的 類型變量。或指向內存地址的東西。是方便我們 操作 內存地址和其值的。
當你學會了 這個 底層,你會發現 指針 很容易!
比如說:我們存儲的數據一般情況下,沒有特別小的數據類型,可以小到 一個字節的。當然 JAVA有個 Byte 類型。如果 超過了 一個字節的類型,它在 內存中 怎么存儲呢?
根據連續的內存空間,進行存儲。因為 我們說 一個內存地址只對應一個 字節的 內存空間。那么4字節的 類型數據,我們就需要用到 4個 連續的內存空間 來進行 存儲。
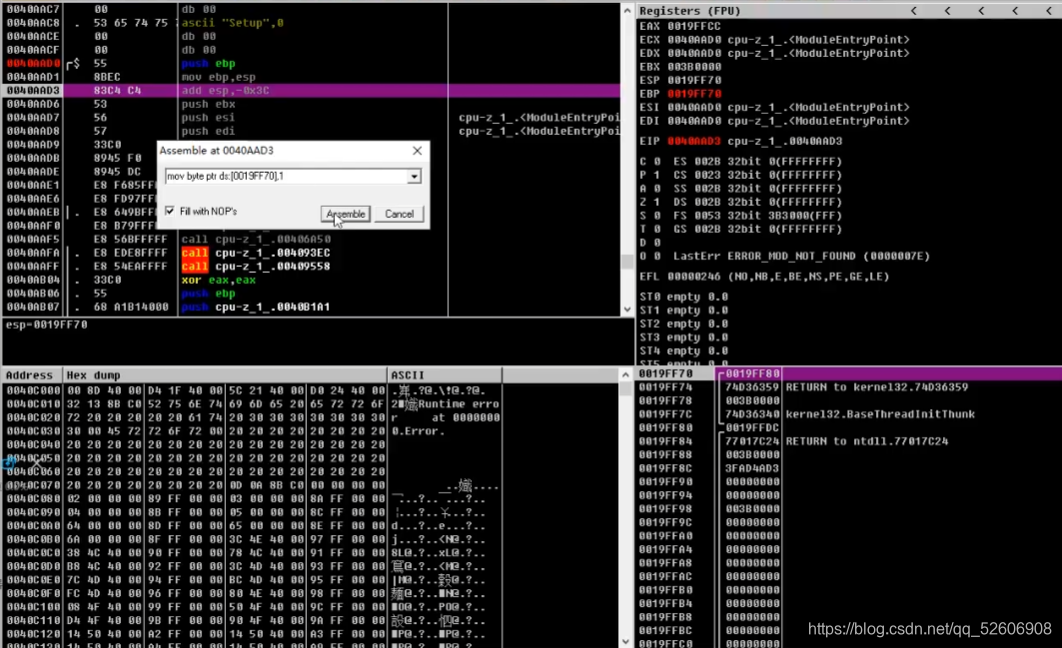
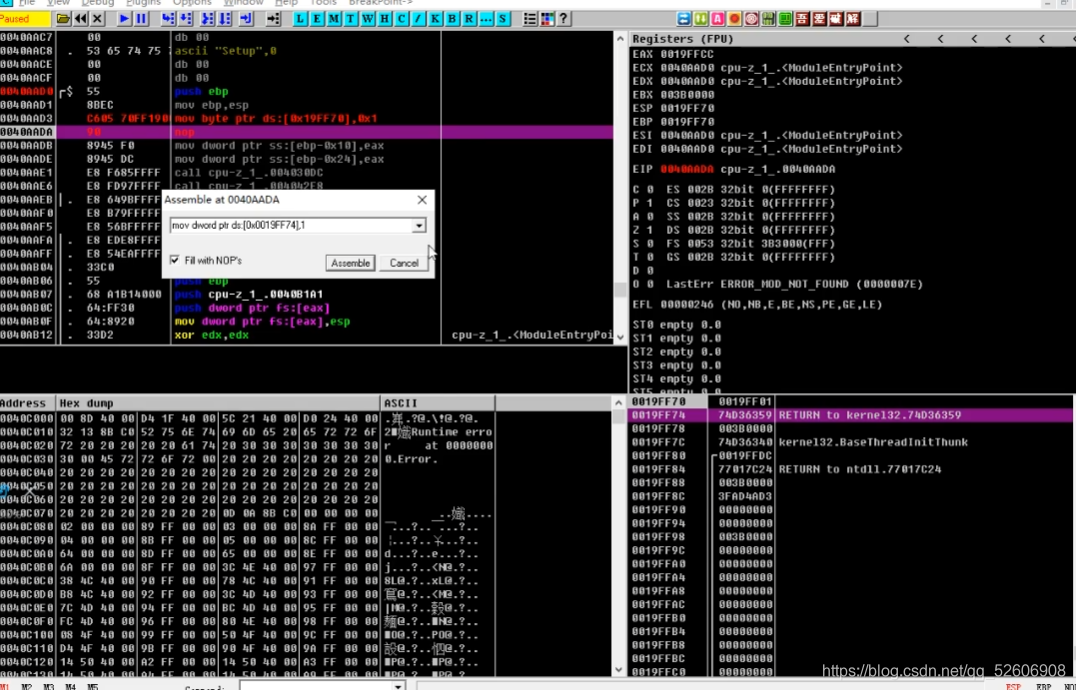
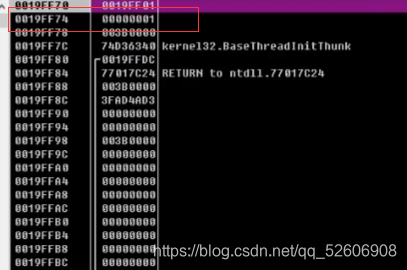
最標準mov代碼:mov dword ptr ds:[內存地址]
byte、word、dword:數據寬度
ptr:相當于 Type類型
CS (Code Segment) 代碼段
DS (Data Segment) 數據段
ES (Extra Segment) 附加段
SS (Stack Segment) 棧段
FS:(Flag segment) 標志段寄存器
GS:(Global segment) 全局段寄存器
)
)













:運行狀態鏈)


)
