Deep reinforcement learning for drone navigation using sensor data 基于傳感器數據的無人機導航深度強化學習方法
評價:MDP無記憶性,使用LSTM補足缺點。PPO解決新舊策略差距大的問題。
對于環境中的障礙物,設置增量課程,障礙物由1—>32.使用了PPO8, PPO16, PPO,和啟發式算法(基準)作對比實驗。PPO8和PPO16在訓練初期學習速度較慢,但后期表現更穩定。隨著訓練進行,PPO8和PPO16的性能逐漸超越PPO,表明記憶機制的有效性。
LSTM的時間步數為4or8。輸入一個長度為n的狀態序列。每步的狀態為[時間,障礙物信息,距離dx, dy]。LSTM輸出的是策略(即 【動作,概率】),LSTM的優化不是通過標簽,而是通過策略梯度函數優化。LSTM是網絡結構,其算法結構是PPO. 其策略網絡和價值網絡共享LSTM參數,但其梯度不同,進行聯合優化。
文章目錄
- Deep reinforcement learning for drone navigation using sensor data 基于傳感器數據的無人機導航深度強化學習方法
- 摘要
- 二、RL
- 2.1 MDP
- 2.2 Partially observable MDPs (POMDPs)
- 2.3 Policy gradients learning
- 2.4 Proximal policy optimisation (PPO) algorithm
- 2.5 PPO 代碼
- 三、 Models and system architecture
- 3.1 Agents
- 3.2 Brains
- 3.3 Academy
- 3.4 Configuration
- 3.5 Curriculum learning
- 3.6 Memory
- 3.7 Training
- 四、實驗
- 4.1實驗評估: 對比算法
- 4.2 實驗結果:訓練過程分析
- 4.3 實驗結果:性能對比
- 五、安全保障
- 5.1 安全保障:功能失效分析
- 5.2 安全保障:訓練與模型驗證
- 六、總結與展望
- 七、模型的實踐
- 7.1 數據收集階段
- 7.2 訓練階段
- 7.3 數據流圖示
- 7.4 優化目標
- 7.6 PPO的約束機制'
- 7.7 LSTM的時序優化
- 7.8 LSTM+PPO的網絡結構
- 7.9 策略網絡與價值網絡的關系
摘要
移動機器人,如 無人機(drone),可用于建筑物、基礎設施和環境中的監視、監控和數據收集。準確且多方面的監測的重要性眾所周知,可以早期發現并防止問題升級。這推動了對靈活、自主和強大決策能力的移動機器人的需求。這些系統需要能夠通過融合來自多個來源的數據進行學習。直到最近,它們都是針對特定任務的。在本文中,我們描述了一種通用的導航算法,該算法使用無人機機載傳感器的數據來引導無人機到達問題地點。在危險和安全關鍵的情況下,準確且快速地定位問題是至關重要的。我們使用近端策略優化深度強化學習算法 結合 增量課程 學習和長短期記憶神經網絡來實現我們的通用且可適應的導航算法。我們通過啟發式技術評估不同的配置以展示其準確性和效率。最后,我們考慮如何通過評估無人機在真實世界場景中使用我們的導航算法的安全性來保證無人機的安全。


二、RL
如上所述,我們使用局部算法進行導航,因為無人機只能看到探索空間的局部(它們是部分可觀察的)。有許多局部導航方法。遺傳算法可以執行部分可觀測的導航[13]。它們生成一個隨機生成的解決方案群體,并使用自然選擇的原則來選擇有用的一組解決方案。然而,它們傾向于陷入局部最小值。模糊邏輯算法[55]已被用于學習導航,Aouf等人[4] 表明他們的模糊邏輯方法優于三種元啟發式(群體智能)算法:粒子群優化,人工蜂群和元啟發式算法螢火蟲算法,用于導航時間和路徑長度。然而,在動態環境中,模糊邏輯算法難以應對,因為它們在環境變化時太慢而無法實時重新計算路徑[46]。Patle等[38]綜述了包括這些元啟發式算法(如遺傳算法和群體智能(包括粒子群優化、人工蜂群、飛蛾算法和蟻群優化)在內的多種技術,用于機器人導航。元啟發式群體智能算法旨在通過智能方式探索模型空間來找到最佳模型。它們旨在找到一個好解決方案而不是最優解,并且可能陷入局部最小值。Patle等人[38]得出結論,遺傳算法和群體智能可以在不確定的環境中導航,但它們復雜且不適合低成本機器人。常規神經網絡如多層感知器可以用于訓練導航模型[38, 46],但它們沒有深度學習算法的計算能力,并且只能在更簡單的環境中使用。導航算法可以使用深度分類學習與深度神經網絡結合。深度神經網絡通過生成帶有標簽的訓練數據來學習導航,其中標簽評估所選路徑的質量[49]。然而,準確地標記足夠多的訓練樣本既費時又困難。
相比之下,深度強化學習(deep RL)使用試錯方法( error approac),在無人機導航時生成獎勵和懲罰。這種深度RL的一個關鍵目標是產生能夠在現實世界中進行經驗驅動學習的自適應系統。Matiisen等人。[34]觀察到深度RL已被用于解決電子游戲中的困難任務[35]、移動性[33, 44]以及機器人技術[31]。它還被用于機器人導航[56],作者們能夠以62%的成功率在20x20的網格中導航。強化學習(RL)本身是一個自主的數學框架,用于經驗驅動的學習[5]。正如Arulkumaran等人所指出的,[5],RL以前取得了一些成功,例如直升機導航[37],但這些方法不是通用的、可擴展的,并且僅限于相對簡單的挑戰。
2.1 MDP
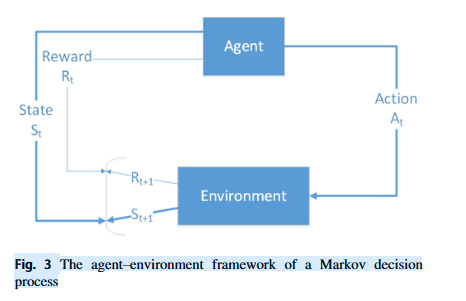
- 有限狀態集S,加上起始狀態分布p(s0)p(s_0)p(s0?)。可能存在一個終端狀態sT。學習任務的復雜度相對于定義狀態所用變量的數量呈指數增長。我們稍后描述如何最小化狀態表示
- 一組動作A,涵蓋每個狀態下可用的所有代理。我們只有一個代理可以向四個可能方向之一移動。
- 轉換動態(策略)πθ(st+1∣st,at)\pi_{\theta}(s_{t+1}|s_t,a_t)πθ?(st+1?∣st?,at?),它使用參數集θ\thetaθ將時間t時的狀態/動作對映射到時間t+1時的狀態分布。
轉換僅取決于當前狀態和動作(馬爾可夫假設) - 與每個轉換相關的瞬時獎勵函數R(st,at,st+1)R(s_t,a_t,s_{t+1})R(st?,at?,st+1?);用于評估最優轉換。
- 折現因子γ∈[0,1]\gamma \in [0,1]γ∈[0,1],這是未來獎勵的當前值。它量化了即時獎勵和未來獎勵之間的重要性差異(較低的值更強調即時獎勵)。
- 無記憶性。一旦當前狀態已知,歷史就被抹去,因為當前的馬爾可夫狀態包含了所有來自歷史的有用信息;“在給定現在的情況下,未來與過去無關”。
我們將無人機導航問題類比于網格世界導航問題[48]。在本文中,我們知道無人機的GPS位置、無人機正前方N、E、S、W方向以及傳感器讀數在笛卡爾坐標系中的方向(x距離,y距離)(其中N、E、S和W相對于地面在這個例子中)。在現實場景中,我們可以使用相對于地面或相對于無人機的方向來確定傳感器讀數在極坐標系中的方向和幅度,具體取決于情況。幅度和方向可以輕松地從極坐標轉換為笛卡爾坐標。如果有8個傳感器以圖4中所示的八角形排列,則最高傳感器讀數給出了相對于地面或無人機的方向,以及異常的幅度(強度)。這里無人機將朝東北方向飛行。

在我們的無人機導航推薦系統中,只有部分環境在任何時間點可觀察。在現實世界中,我們只能通過無人機的避碰機制知道無人機的近似位置。我們不知道更遠前方(在現實世界中它們可能被更近的障礙物遮擋)或超出無人機視野范圍內的障礙物的位置。網格世界導航問題的替代公式將環境視為一幅圖片(觀察結果),其中網格中的每個單元映射到一個像素值,表示該單元的內容{空、障礙物、目標}[50]。這需要環境的完整信息,而無人機無法提供。此外,這種方法不能擴展到不同的網格大小,因為它使用N x N網格作為圖像來學習導航。在16 x 16觀察網格上訓練的深度學習器不能用這種觀察公式推廣到32 x 32網格,因為網絡輸入尺寸不同(16 x 16與32 x 32),并且會錯位。我們的公式是可擴展、適應和靈活的。
2.2 Partially observable MDPs (POMDPs)
無人機不可能看到全局地圖,它只能感知到自己周圍的局部信息,這就是所謂的部分可觀測(POMDP)。
為了使用這種部分(局部)信息訓練無人機,我們使用了一種稱為部分可觀測馬爾可夫決策過程(POMDPs)的MDPs的泛化。
在POMDP中,代理接收一個觀察值ot∈Ωo_t\in \Omegaot?∈Ω,其中觀察值的分布P(ot+1∣st+1,a)P(o_{t+1}|s_{t+1},a)P(ot+1?∣st+1?,a)取決于先前的動作a t和當前狀態st+1s_{t+1}st+1? 。這里,觀察值由一個依賴于當前狀態{傳感器方向,傳感器幅度,N,E,S,W空間}和之前應用的動作(無人機是否移動了N,E,S,W)的狀態空間模型中的映射來描述。
MDP表示從一個狀態到另一個狀態的轉移概率。策略π\piπ是在給定狀態下的行動分布πθ(at∣st)=P[At=at∣St=st]\pi_{\theta}(a_t|s_t)=P[A_t=a_t|S_t=s_t]πθ?(at?∣st?)=P[At?=at?∣St?=st?]?。
策略完全定義了在當前狀態下代理的行為;它根據當前狀態sts_tst?生成一個動作ata_tat?,并且該動作在執行時產生一個獎勵rtr_trt?。
RL的目標是識別最優策略π?\pi^*π?,該策略最大化所有狀態下的獎勵(即最大化期望獎勵值E):π?=arg?max?πE[Rt∣π]\pi^*=\argmax _{\pi}E[R_t|\pi]π?=argmaxπ?E[Rt?∣π]。確定最優策略有兩種常見的方法:價值學習,它維護一個價值函數模型;以及無模型的策略學習,直接搜索最優策略。
在本文中,我們使用策略學習。價值學習在每次迭代時考慮所有動作,并且很慢;它的執行時間是策略評估的 |A| 倍。此外,策略在每次迭代時不會改變,浪費了更多的時間。
2.3 Policy gradients learning

與許多其他AI算法一樣,RL的缺點是內存使用、計算復雜性和樣本復雜性。最近,人們開始用 深度神經網絡(DNN)來支持RL,這提供了強大的函數逼近和表示學習特性。深度RL算法的一個子集是策略梯度算法。它們通過沿著策略的梯度上升來尋找策略質量的局部最大值。策略梯度學習是穩健的,但梯度方差很高。為了降低這種方差,我們使用梯度的無偏估計,并減去幾個回合的平均回報作為基線。此外,策略梯度具有較大的參數集,這可能導致嚴重的局部最小值。為了最小化局部最小值的可能性,我們可以使用信任區域(rust regions.)。信任區域搜索通過約束優化步驟,使它們位于真實成本函數近似仍然有效的區域內。我們可以通過確保更新后的策略與先前的策略有低偏差來減少非常差的更新可能性,使用Kullback–Leibler (KL)散度[29]來衡量當前和提議策略之間的偏差。信任區域策略優化(Trust region policy optimisation)(TRPO)通過限制策略可以改變的幅度并保證其單調改進,證明了其魯棒性。然而,這種受限優化需要計算二階梯度,這限制了其適用范圍。為了克服這一點,Schulman等人[45]開發了近端策略優化(PPO)算法,該算法執行無約束優化,僅需要一階梯度信息。PPO執行多次隨機梯度下降以進行每次策略更新。因此,它以與隨機梯度下降兼容的方式進行信任區域更新,從而通過消除自適應更新的需要簡化了算法。在每個時間步t處計算更新,該更新最小化成本函數,同時確保與先前的策略的偏差相對較小。
2.4 Proximal policy optimisation (PPO) algorithm
PPO的核心思想是在更新策略時,限制新策略與舊策略之間的差異,確保每次更新都在一個相對安全的區域內進行,避免策略發生劇烈變化導致性能下降。這就像開車時平穩加速,而不是猛踩油門。PPO通過裁剪重要性比率來實現這一點,既保證了學習效率,又提高了訓練的穩定性。

💡小分析
新策略是通過梯度下降法從舊策略產生的。PPO算法在每次迭代時計算策略梯度,然后使用梯度下降來更新策略參數θ,從而得到新策略πθπ^{θ}πθ
Why 新舊策略差異會很大?
在強化學習中,策略更新是通過梯度計算進行的,但梯度方向可能很"激進"(特別是當獎勵信號稀疏或噪聲較大時)。
如果直接按梯度方向大幅更新策略(比如用較大的學習率),新策略可能會與舊策略產生顯著差異,導致:
- 策略崩潰:新策略可能完全偏離之前學到的有效行為
- 訓練不穩定:過大的更新會導致策略性能劇烈波動
為什么需要信任區域(Trust Region)
信任區域的核心思想是:限制每次策略更新的幅度,確保新策略不會偏離舊策略太遠。PPO通過兩種機制實現:
- 重要性比率裁剪:強制比率rt(θ)保持在[1-ε,1+ε]范圍內,本質上限制了策略更新的最大步長
- KL散度約束(在TRPO中顯式使用):從數學上保證新舊策略的KL散度不超過閾值
裁剪重要性比率是PPO算法的核心操作,具體包括:
- 計算重要性比率:rt(θ)=πθ(at∣st)/πoldθ(at∣st)r_t(θ) = π^θ(a_t|s_t)/π^θ_{old}(a_t|s_t)rt?(θ)=πθ(at?∣st?)/πoldθ?(at?∣st?)
- 對重要性比率進行裁剪:clip(rt(θ),1?ε,1+ε)(r_t(θ), 1-ε, 1+ε)(rt?(θ),1?ε,1+ε)
- 取裁剪前后比率的最小值作為最終目標函數
其中ε是超參數(通常設為0.1或0.2),用于限制策略更新的幅度。假設舊策略以90%概率選擇動作A,10%選擇B。如果新策略突然變成10%A、90%B(由于一次激進的梯度更新),這樣的劇烈變化可能導致:
- 之前積累的經驗數據(基于舊策略)對新策略不再適用
- 策略需要重新探索,降低學習效率
PPO方法
PPO的目標是解決傳統策略梯度方法(如REINFORCE或TRPO)的兩大問題:
- 步長敏感:更新幅度過大可能導致策略崩潰(性能驟降)。
- 樣本效率低:需要大量交互數據。
PPO通過以下設計實現穩定更新:
- “信任區域”的近似:用**裁剪(Clipping)**機制代替TRPO的復雜二階優化約束。
* 重要性采樣:利用舊策略的數據高效計算新策略的梯度。
2.5 PPO 代碼
class PPOAgent:def __init__(self, policy_net, lr=3e-4, clip_eps=0.2):self.policy = policy_net # 1. 策略網絡 πθ(a|s)self.optimizer = torch.optim.Adam(self.policy.parameters(), lr=lr)self.clip_eps = clip_eps # 2. ε:PPO 的裁剪閾值def update(self, states, actions, old_log_probs, advantages):# 3. 對同一批數據做 K_EPOCHS 次小批量梯度上升for _ in range(K_EPOCHS): # K_EPOCHS 通常 10~30new_log_probs = self.policy(states).log_prob(actions) # 4. 前向:拿新的 log πθratio = (new_log_probs - old_log_probs).exp() # 5. 重要性采樣系數 r_t(θ)surr1 = ratio * advantages # 6. 未裁剪的目標surr2 = torch.clamp(ratio,1-self.clip_eps,1+self.clip_eps) * advantages # 7. 裁剪后的目標loss = -torch.min(surr1, surr2).mean() # 8. PPO-Clip 的目標函數取負號(因為 PyTorch 只能最小化)self.optimizer.zero_grad()loss.backward() # 9. 反向傳播self.optimizer.step()| 行號 | 代碼 | 含義 | ||
|---|---|---|---|---|
| 1 | policy_net | 一個 torch.nn.Module,輸入狀態 s,輸出動作分布。連續動作常用 Normal(mean, std);離散動作常用 Categorical(logits)。 | ||
| 2 | clip_eps=0.2 | PPO 論文默認 0.1~0.3。它決定了「策略一次不能更新太多」。 | ||
| 3 | for _ in range(K_EPOCHS) | 用同一批 rollout 數據反復訓練多次。提高樣本利用率,同時因為數據固定,梯度方差小。 | ||
| 4 | log_prob(actions) | 對新網絡 πθ 再跑一次前向,得到當前策略下這批動作的對數概率 logπθ(at∣st)log πθ(a?| s?)logπθ(at?∣st?)。注意 不重新采樣動作,而是用 rollout 里已經做過的動作。 | ||
| 5 | ratio = (new_log_probs - old_log_probs).exp() | 計算重要性采樣權重:r_t(θ)=π_θ(a_t∣s_t)π_θ_old(a_t∣s_t)r\_t(\theta)=\frac{\pi\_\theta(a\_t | s\_t)}{\pi\_{\theta\_{\text{old}}}(a\_t | s\_t)} r_t(θ)=π_θ_old(a_t∣s_t)π_θ(a_t∣s_t)?這里用對數相減再 exp,數值穩定。 | ||
| 6 | surr1 = ratio * advantages | 未裁剪的目標:鼓勵提高 advantage>0 的動作概率,降低 advantage<0 的動作概率。 | ||
| 7 | surr2 = torch.clamp(...) | 把 ratio 強行限制在 [1-ε, 1+ε] 區間內,防止策略一步邁太大。 | ||
| 8 | loss = -torch.min(...).mean() | 取 min(surr1, surr2) 再平均,最后加負號變成「損失」讓優化器去最小化。 | ||
| 9 | backward() & step() | 普通梯度下降。 |
三、 Models and system architecture
我們的無人機仿真使用Unity 3-D的ML-agents框架[26]來設計、開發和測試仿真,然后在實際部署之前進行測試。ML-agents使用Unity 3-D#開發框架作為前端和中間件接口,與Google TensorFlow[1]后端通過Python連接。MS Windows版本的ML-agents有一個DLL庫,用于C#和Python之間的接口。它允許用戶開發訓練智能代理的環境[26]。在本文中,我們專注于2-D導航,并且不考慮無人機的高度。因此,我們的異常檢測問題是使用Unity3-D ML-agents中的網格世界實現的確定性、單代理搜索、POMDP問題。我們指定網格大小和障礙物數量,并隨機生成網格(參見圖5以獲取示例網格)。Unity 3-D游戲環境運行模擬。我們的系統包括三個主要交互過程。


💡了解socket
在 Unity ML-Agents 框架中,Socket(套接字)通信 用于連接 Unity 環境(C#)和 Python 訓練后端(TensorFlow/PyTorch),使兩者能夠實時交換數據。以下是它的工作原理和關鍵點:
- Socket 通信的作用
- Unity(C# 端) :負責環境模擬(如無人機導航的網格世界)、狀態(State)采集、動作(Action)執行。
- Python(訓練端) :運行強化學習算法(如 PPO),接收狀態,計算動作,并返回給 Unity。
- 通信方式:通過 TCP/IP Socket 實現跨語言、跨進程的數據交換。
- 通信流程
- Unity 啟動 Socket 服務端
- Unity 在訓練模式下會啟動一個 Socket 服務端,監聽特定端口(默認 5005)。
服務端代碼在 Unity 的 Academy 類中實現(ML-Agents 的核心協調模塊)。- Python 客戶端連接
- Python 通過 mlagents.train 模塊啟動訓練時,會主動連接 Unity 的 Socket 服務端。
連接成功后,雙方通過約定的協議交換數據。
- 數據交換內容
- Unity → Python:
- 發送當前狀態(State):如無人機周圍的障礙物信息、目標距離等(N, E, S, W, x-dist, y-dist)。
- 發送獎勵(Reward):上一步動作的即時獎勵。
- Python → Unity:
- 返回動作(Action):如移動方向(N, E, S, W)。
- 其他控制指令(如重置環境)。

3.1 Agents
在ML-agents框架中,代理Agents [智能體]是Unity 3-D游戲對象,如[10, 11, 32]和[54]中所示。在我們的模擬中,代理是一架無人機。在ML-agents中,代理生成狀態,執行指定的動作并分配累積獎勵。代理與一個大腦(第3.2節)鏈接。
代理(無人機)采取指定動作(向北、東、南或西移動一格),以導航網格,避開障礙物并找到目標。我們的狀態空間是一個長度為6的向量,包含相鄰網格單元的內容(N, E, S, W),以及到目標(異常)的x距離和y距離。這既緊湊,可擴展又現實。
(在真實世界中,無人機只能感知其局部環境;由于遮擋,它不能保證前方可見。)
在我們的RL中,代理每次移動都會收到一個小懲罰,到達目標時獲得正獎勵(+1),與障礙物碰撞時獲得負獎勵(-1)。
3.2 Brains
每個代理都有一個與之相連的腦,提供智能并決定行動。大腦為代理做出決策提供邏輯;它在每次情況下確定最佳行動。
我們的大腦使用由OpenAI開發的近端策略優化(PPO)RL算法[45],該算法針對實時環境進行了優化。
ML代理的PPO算法在TensorFlow中實現,并在一個單獨的Python進程中運行(通過套接字與正在運行的Unity應用程序通信)。PPO算法接收狀態空間表示(相鄰網格單元的內容(N、E、S、W),以及x距離和y距離)和可能的動作集(向N、E、S或W移動一個單元格)作為輸入,并選擇使用學習到的策略來最大化獎勵的動作。
3.3 Academy
環境中的這個元素協調決策過程。它在大腦(邏輯)和實際的Python TensorFlow實現之間形成了一條管道,后者將邏輯作為學習到的深度神經網絡模型以程序化方式包含其中。
3.4 Configuration
為了配置代理和大腦,我們花費了很長時間評估不同的代理、狀態、獎勵配置。這些設置是成功實現的關鍵,因此值得花時間評估不同的配置。我們分析了:
- 不同的狀態表示,特別是不同的距離表示,我們使用了與網格大小和剩余距離相關的不同縮放因子。我們發現最佳結果來自使用N、E、S、W、d(x),d(y)的狀態空間。
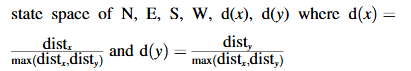
- 不同的步獎勵,我們使用了與網格大小相關的不同縮放因子發現一個步的懲罰

- 我們嘗試了多種PPO的超參數組合,發現最好的結果來自“附錄”中列出的設置。


如果我們使用訓練網格中的1個障礙物來訓練代理,那么代理將學會直接前往目標,這是理想的。然而,在訓練和評估期間,當遇到更復雜的障礙物(2或更多紅十字交叉)時,它會掙扎。如果我們在開始訓練時使用多個障礙物,例如32個障礙物(隨機放置的紅十字),則它會學會隨意行走。這使它能夠克服更復雜的障礙物,但在網格世界環境中障礙物很少時,它不會直接前往目標。
這存在一個問題,消除了我們希望代理是通用的并能夠應對各種環境的愿望。因此,我們觀察了接下來描述的逐步(課程)學習。
💡思考
這就涉及到一個問題,人工智能(如強化學習)訓練中,障礙物的數量或比例 會顯著影響訓練效果和最終策略的性能。以下是關鍵影響因素及其作用機制:
- 障礙物數量/比例的影響
(1) 訓練難度與泛化能力
- 低障礙物密度(簡單環境):
無人機容易找到直達目標的路徑,訓練速度快。但學到的策略可能過于簡單,無法應對復雜場景(如現實中的密集障礙)。
風險:策略過擬合到簡單環境,泛化能力差。- 高障礙物密度(復雜環境):
訓練初期難度大,無人機容易陷入局部最優(如繞圈或反復碰撞)。但最終學到的策略更魯棒,能適應動態或未知環境。
典型問題:稀疏獎勵問題(長時間無正向反饋)。探索效率低(需更多訓練步數)。
(2) 障礙物分布形態
規則障礙(如網格) :策略可能學會特定“套路”(如貼墻走)。
隨機障礙:迫使策略學會通用避障邏輯,但訓練更耗時。
動態障礙(如移動障礙物):需引入記憶(如LSTM)或在線適應機制。作者通過 漸進式課程學習(Incremental Curriculum Learning) 解決障礙物數量/比例的影響:
- 分階段訓練:
從簡單環境(如1個障礙)開始,逐步增加障礙物數量(1 → 4 → 8 → 16 → 32)。
每階段訓練到策略穩定后(通過平均獎勵判斷),再進入下一階段。- 平衡探索與利用:
早期階段快速學會基礎導航(如直線趨近目標)。
后期階段專注復雜避障(如繞行凹形障礙)。- 實驗數據支持:
直接訓練32障礙的環境時,策略收斂慢且易學“無意義隨機游走”。
課程學習后的策略在測試中表現更優(見表1/2,PPO?在32障礙環境成功率更高)。其他優化方法
(1) 獎勵函數設計
- 稀疏獎勵改進:
- 添加基于距離的中間獎勵(如每步靠近目標給予小獎勵)。
- 懲罰無效動作(如反復撞墻)。
- 課程學習 + 動態獎勵:
早期階段側重“到達目標”,后期階段增加“路徑效率”權重。(2) 記憶機制(LSTM)
- 應對復雜障礙:
- LSTM記憶過去幾步的狀態,避免重復探索無效路徑(如死胡同)。
- 論文中LSTM長度8比16更優(過長記憶反而干擾短期決策)。
(3) 障礙物比例建議
- 訓練初期:障礙物占比 ≤ 10%(如16×16網格中10~20個障礙)。
- 最終階段:可提升至30%~50%(模擬極端場景)。
- 動態調整:根據訓練指標(如碰撞率)自動調整障礙密度。
3.5 Curriculum learning

課程學習從一個簡單的任務開始,隨著學習的進行逐漸增加任務的復雜性,直到我們達到感興趣的訓練標準。它不會忘記之前學過的實例。每次課(訓練標準)在訓練期間生成一組不同的權重,基于先前的權重。我們從1個障礙物到4個然后是8個,接著是16個,最后是32個,都在一個16x16的網格中。在這個序列結束時,無人機仍然可以高效地導航16x16網格中的1個障礙物,因為網絡沒有忘記在第一節課中學到的知識。它現在能夠利用在最后的課程中學到的知識,高效地導航16×16格中的32個障礙物。
在本文中,我們使用一種自適應課程學習方法,稱為“增量式課程學習incremental curriculum learning’’”。課程學習需要預先指定每節課的迭代次數,例如訓練第一節課5百萬次。通常,這個數字無法提前準確確定。
增量式課程學習允許用戶根據優化訓練調整每節課的迭代次數。它在預指定的迭代次數內訓練網絡,除非用戶提前停止學習過程,如果模型已經充分訓練,則無需額外迭代;如果模型未在預指定的迭代次數后得到足夠訓練,則增加額外迭代。有許多指標可以用來確定每個課程需要訓練多少個epoch,例如損失、熵或最終平均獎勵。
我們分析了這些指標,并發現最終平均獎勵生成了最佳的導航模型,適用于我們的增量式課程學習。其他指標往往導致模型過度訓練或訓練不足,從而導致泛化能力差。因此,我們使用平均最終獎勵來確定每節課何時應結束。
例如,如果我們指定訓練課程一為5百萬次迭代,并檢查代理的平均最終獎勵(每隔10,000次訓練迭代進行平均),我們可以確定獎勵是否仍在增加還是已經穩定。如果它仍在增加,那么我們假設代理沒有足夠地學習這個課程步驟,并且可以在第一課中再添加0.5百萬次迭代,并在運行了5.5百萬次迭代后再次測試。因此,我們逐步學習每一課,直到我們確信PPO已經充分地學會了這節課,然后我們進入下一節課(課程中的更復雜任務)。我們在本節5的評估中進一步分析這種增量式課程學習。
訓練一個復雜的AI模型,不能一開始就扔給它最難的任務,否則它會圈。
3.6 Memory
在第2節中,我們正式定義了一個MDP。我們強調了MDPs是無記憶的。這成為我們的導航推薦系統的一個問題。
當代理遇到凹陷障礙物(死胡同)時,缺乏記憶是一個問題。PPO代理無法記住之前的移動而來回走或反復圈轉。為了克服這個問題,我們在PPO深度學習中添加了一個LSTM記憶層,如圖6所示。LSTM是一種特殊的遞歸神經網絡[20],能夠學習更長的依賴關系(序列),使其非常適合為代理提供一個記憶層。
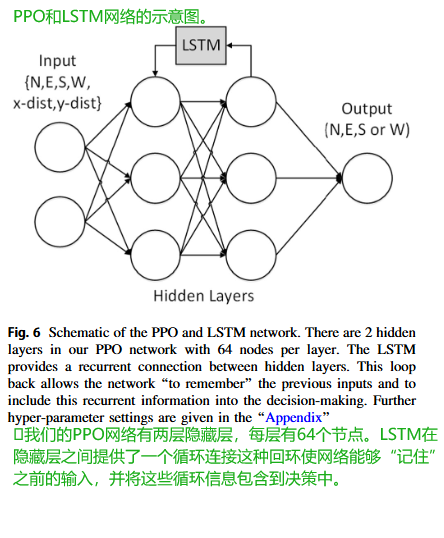
LSTM網絡由稱為單元cells的內存塊memory blocks組成。這些單元形成序列,并負責記憶和記憶操作,以更新隱藏狀態(記憶)。每個單元都有門控機制,因此可以存儲或刪除信息(通過打開和關閉門)。因此,LSTM可以從其記憶中讀取、寫入和刪除信息。序列長度是代理必須記住的步驟數。它也是輸入數據和在訓練期間通過LSTM傳遞的序列的長度。這個長度需要足夠長,以捕獲代理必須記住的信息。
然而,較長的序列會增加訓練時間,因為這增加了LSTM的復雜性。在這種情況下,我們需要記住足夠的步驟,使代理能夠導航死胡同和其他更復雜的障礙物。LSTMS是遞歸的,并且通過時間和層反向傳播輸出誤差。這種遞歸機制允許此類網絡在時間步長上學習。
💡如何使用LSTM呢?
在論文描述的PPO+LSTM框架中,每個時間步的輸入包含兩部分:
- 當前狀態觀測(State):[N, E, S, W障礙信息, x-distance, y-distance] (例如:[0, 1, 0, 0, 3.2, -1.5] 表示東側有障礙,目標在東北方向)
- 歷史狀態序列:
LSTM會接收過去 n 個時間步的狀態(如 n=8),形成時間維度。💫時間序列的生成方式
- 滑動窗口:
每次輸入是一個長度為 n 的狀態序列,例如:[[t-7: N, E, S, W, x, y], # 8步前的狀態[t-6: N, E, S, W, x, y], ..., [t: N, E, S, W, x, y] # 當前狀態 ]
- 實際實現:Unity ML-Agents 會自動緩存歷史狀態,按LSTM長度 (sequence_length) 打包成序列輸入。
💫為什么需要時間序列?
- 解決部分可觀測性(POMDP):單步觀測無法判斷凹形障礙(如U型墻),需記憶過去路徑。
- 避免循環行為:通過歷史狀態識別“繞圈”或“反復撞墻”等無效動作。
💡LSTM的輸出:動作決策
(1) 輸出內容
- 策略分布(Policy):LSTM輸出的是當前狀態下各動作的概率分布(如 [N:0.7, E:0.1, S:0.1, W:0.1])。通過Softmax層實現多分類。
- 狀態價值估計(Value):附加一個線性層輸出標量,表示當前狀態的長期回報預測(用于PPO的優勢函數計算)。
(2) 輸出與動作的關系 :PPO的決策流程:
- LSTM處理時間序列狀態 → 生成動作概率
- 按概率采樣動作(訓練時)或選最高概率動作(測試時)
- 執行動作后,新狀態加入序列,更新LSTM隱藏狀態
(3) 輸出示例
# 假設LSTM輸出層結構: output = {'action_probs': [0.7, 0.1, 0.1, 0.1], # 對應[N, E, S, W]'value': 0.85 # 當前狀態價值 }
3.7 Training
在訓練期間,帶有LSTM序列記憶的TensorFlow PPO模型執行決策。TensorFlow模型與Unity環境分離并通過套接字通信。我們使用增量課程學習訓練了大腦5000萬次訓練。每個場景由Unity3-D獨立生成,作為單獨的導航任務。對于每個網格(場景),導航器要么解決網格,要么失敗或超時。然后它繼續到下一個網格布局。使用Unity 3-D C#隨機數生成器在網格中放置障礙物以選擇位置。PPO網絡設置如圖6所示,Unity ML-Agents的參數集見“附錄”。網絡輸入為六維狀態向量(N, E, S, W, x-距離, y-距離),輸出為采取的動作:向N、E、S或W移動一步。
💡 與PPO的協同工作
(1) 訓練時的數據流
- 序列采樣:
- 從經驗回放緩存中抽取長度為 n 的連續狀態-動作-獎勵序列。
- 序列需對齊,避免時間錯位(ML-Agents 自動處理)。
- 梯度更新:
- LSTM的隱藏狀態在序列內傳遞,但不同序列間重置。
- PPO的損失函數(含策略裁剪)同時優化LSTM和全連接層。
(2) 超參數設置
關鍵參數(論文附錄):LSTM:sequence_length: 8 # 時間步數(記憶長度)hidden_units: 64 # LSTM隱藏層維度num_layers: 1 # 堆疊層數
- 長度選擇依據:
過短(如4):無法記住繞行路徑。
過長(如16):訓練慢且引入噪聲。
論文中 8 是平衡點(足以應對多數凹形障礙)。
💡 LSTM通常用于有監督學習,存在標簽。那么在強化學習中沒有標簽,如何優化呢???優化流程如下:
(1) 策略梯度(Policy Gradient)驅動
- LSTM的輸出是策略分布(動作概率),即 π(a∣s,h)π(a|s, h)π(a∣s,h),其中 h 是LSTM的隱藏狀態。
- 優化目標:通過策略梯度定理,直接調整LSTM的參數,使得高獎勵的動作概率增加,低獎勵的動作概率降低。
梯度公式(簡化版):(2) PPO的裁剪機制與LSTM
PPO通過重要性采樣比率裁剪限制策略更新幅度,避免LSTM的隱藏狀態劇烈變化:
LCLLP(θ)=E[min?(rt(θ)At,clip(rt(θ),1?ε,1+ε)At)]L^{CLLP}(\theta) =\mathbb{E}[\min(r_t(\theta)A_t,clip(r_t(\theta),1-\varepsilon,1+\varepsilon)A_t)]LCLLP(θ)=E[min(rt?(θ)At?,clip(rt?(θ),1?ε,1+ε)At?)]
rt(θ)r_t(θ)rt?(θ) 是LSTM新舊策略的概率比,裁剪后約束LSTM的參數更新步長。(3)時間序列的梯度傳播
LSTM的隱藏狀態 h_t 在時間步之間傳遞,梯度通過 時間反向傳播(BPTT) 更新:
- 每個時間步的梯度包含當前獎勵和未來獎勵的折現(通過γ調節)。
- 序列長度(如8步)影響梯度回溯的深度,需平衡長期記憶和訓練穩定性。

四、實驗
一旦我們有了訓練好的模型,我們就切換到內部模式,在該模式下Unity 3-D環境使用它來導航。Unity將代理的當前狀態傳遞給存儲的TensorFlow圖,后者返回推薦的動作。這表示在系統當前狀態和可能動作集的情況下采取的最佳行動。在內部模式中,不再進行學習,并且模型圖被凍結。如果需要,可以通過切換回Unity 3-D設置中的訓練模式進一步訓練模型。
4.1實驗評估: 對比算法

我們比較了三種基于PPO的算法:PPO8和PPO16分別代表帶有不同長度8步和16步記憶的LSTM增強版PPO,以及基礎的PPO無
記憶。同時,我們還設置了一個啟發式算法作為基準對比。啟發式算法很簡單,就是看哪個方向離目標最近就往哪走,遇到障礙物就隨機選個沒被擋住的方向。
4.2 實驗結果:訓練過程分析
圖7顯示了在訓練課程第一課(16x16網格,1個障礙物)的前500萬次迭代中PPO、PPO 8和PPO 16的平均獎勵以及在訓練課程第二課(16x16網格,4個障礙物)期間PPO 8 L2的平均獎勵。PPO 8 L2在第一課已經在一個16x16網格上進行了500萬次訓練迭代,我們展示了這如何影響訓練。下圖是上圖的放大版本,更清楚地顯示了平均獎勵的波動。類似地,圖8示出了PPO、PPO 8和PPO 16的課程的第一課訓練期間獎勵的標準偏差以及PPO 8的課程的第二課訓練期間獎勵的標準偏差。
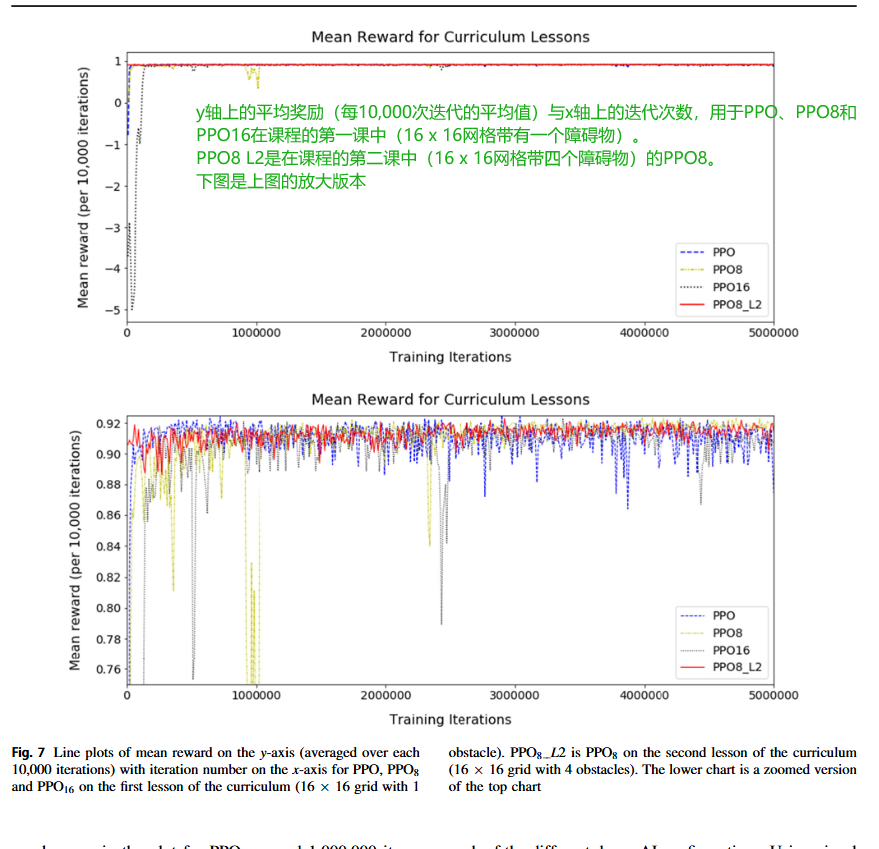
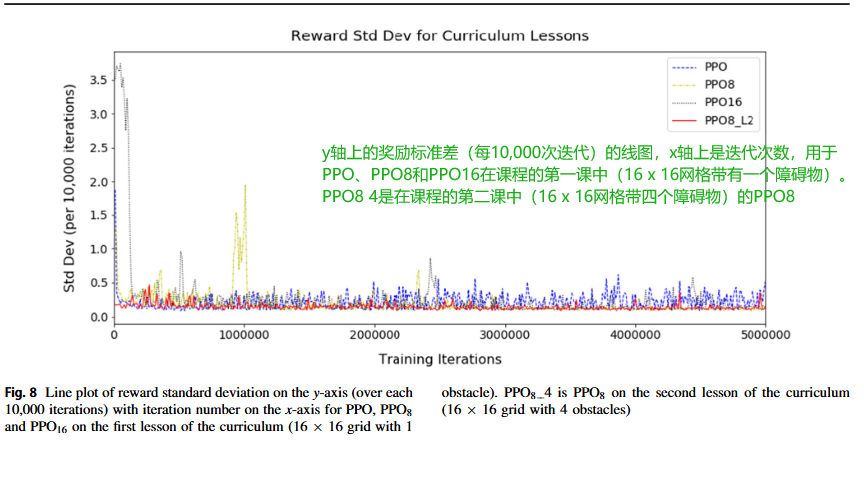
圖7和8顯示,對于第1課,沒有記憶的PPO最初學習最快,因為平均獎勵和獎勵標準差的曲線波動最小并迅速穩定,但在大約4百萬次訓練迭代時波動略有增加。圖表表明AI的記憶越大,則AI學習所需的時間越長。這通過初始時波動更大且最慢穩定的曲線線來說明。在訓練開始時,PPO 16需要240,000次迭代才能達到平均獎勵0.9,而PPO和PPO 8則需要50,000和150,000次。然而,在3百萬次訓練迭代后,由于記憶的幫助,PPO 8的波動最小,與沒有記憶的PPO相比。當PPO 8處于第二課時,PPO 8 L2的波動最小,并且迅速穩定下來,因為它已經學會了前一課,并將導航知識從一課傳遞到下一課。這種長度的可變性表明了為什么我們使用增量課程學習,因為可以根據AI的時間調整每節課的長度,并確保其經過充分訓練以學習。圖7和圖8顯示PPO 8和PPO 8 L2已準備好進入下一節,但PPO和PPO 16至少需要額外0.5百萬次迭代才能受益。
由于我們的隨機網格生成,本課程中標準差存在一些變化。我們計算每塊10,000次迭代的平均獎勵和獎勵標準差。某些區塊可能包含更多從起點到目標有長路徑的網格,而其他區塊可能包含更多有短路徑的網格,這是由于偶然性造成的。然而,標準差仍應在一個范圍內穩定。在學習過程中,AI有時可能會陷入停滯。這在PPO 8的圖表中可以看到,大約在1,000,000次迭代時,平均獎勵下降,標準差增加,因為AI需要重新學習。同樣,通過改變課程長度并使用度量,我們可以確保AI在進入下一課程之前已經充分學習。

從實驗結果來看,PPO8和PPO16在訓練初期,也就是剛開始學習的時候,速度確實比沒有記憶的PPO要慢一些,曲線波動也更大。這是因為引入LSTM增加了模型的復雜度,學習曲線自然會更陡峭一些。但是,隨著訓練的進行,特別是當它們積累了足夠的經驗后,PPO8和PPO16的表現反而更加穩定,而且在處理復雜環境時更有優勢。這也再次證明了我們增量課程學習策略的有效性,通過監控獎勵指標,我們可以精確控制每個階段的訓練時長,確保模型充分學習后再進入下一階段,而不是盲目地按預設時間訓練。
4.3 實驗結果:性能對比
我們分析了場景長度(無人機到達目標所需的步數)、場景結束時的獎勵(無論是無人機到達目標、撞到障礙物還是耗盡步數)以及準確度(在2000次運行中,代理成功找到目標的次數)。每個劇集可以持續長達1000步,直到它超時。
圖9和表1及2詳細說明了每種算法在8個不同網格大小和障礙物數量的網格世界場景中的分析。注意,僅在有32個障礙物的32x32網格上訓練了這些代理;所有其他網格世界設置都是新的。
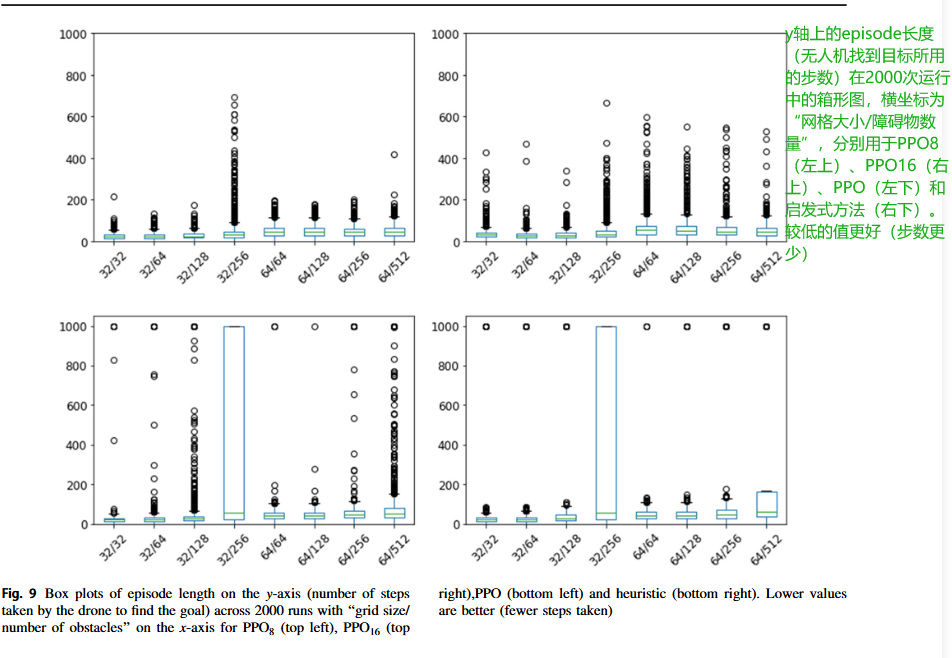
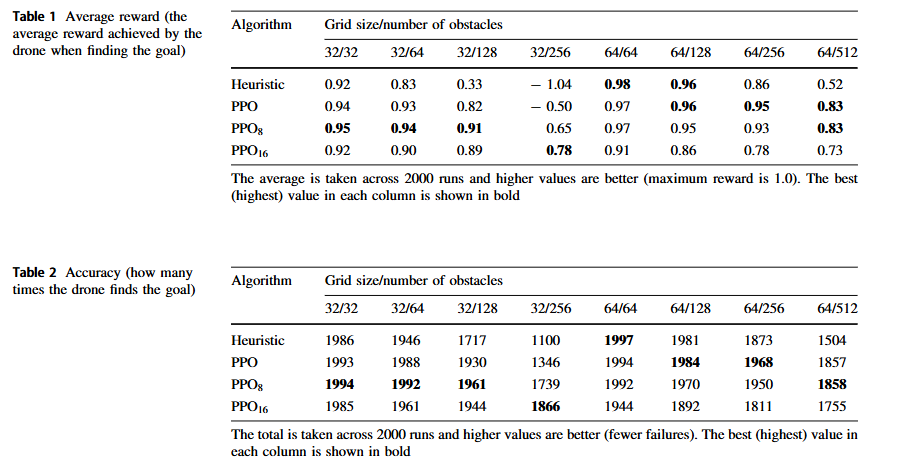

綜合來看,PPO8表現最為均衡,可以說是全能選手,在大多數測試場景下都取得了最好的成績,無論是平均獎勵、回合長度還是成功率,都相對較高。PPO16在障礙物非常多、環境極其擁擠的情況下,憑借更強的記憶力,能更好地回溯路徑,表現最佳,但代價是訓練和運行時間都更長。
五、安全保障
本文中描述的無人機導航推薦系統在現實世界環境中的使用有可能對人類造成傷害。這種傷害可能是由系統直接引起的(例如,系統故障導致無人機與環境中其他障礙物發生碰撞),也可能是由于系統導致無法成功完成任務而間接產生的(例如,延遲緊急救援響應)。如果在現實世界環境中使用無人機導航推薦系統,我們必須提供對系統使用不會導致此類傷害的信心。我們將這種行為安全的自信稱為“保證”。本節將重點討論直接造成的傷害,并簡要討論在系統中證明保證的策略以及部署前需要解決的挑戰。
5.1 安全保障:功能失效分析

FFA: 系統地檢查系統可能出錯的地方。
通過分析這些潛在的故障模式及其可能導致的后果,我們就能識別出哪些是真正需要重點關注的安全風險,并據此制定嚴格的安
全要求。
5.2 安全保障:訓練與模型驗證
有了安全要求,接下來就是如何保證滿足這些要求。這涉及到三個層面:訓練過程的保障、學習模型本身的保障,以及最終系統整體性能的保障。

六、總結與展望

七、模型的實踐
7.1 數據收集階段
- 運行環境:
LSTM基于當前策略控制無人機,生成狀態-動作-獎勵序列 (s1,a1,r1,...,sTs_1, a_1, r_1, ..., s_Ts1?,a1?,r1?,...,sT?)。
- Unity環境生成當前狀態 s_t(含障礙物信息、目標相對位置等)。
- LSTM接收 sts_tst? 和上一時刻的隱藏狀態 ht?1h_{t-1}ht?1?,輸出動作概率分布 π(at∣st,ht)π(a_t|s_t, h_t)π(at?∣st?,ht?)。
- 按概率采樣動作 a_t(如“向東移動”),執行后得到新狀態 s_{t+1} 和即時獎勵 r_t。
- 隱藏狀態 hth_tht? 在序列內持續傳遞,序列間重置。
- 存儲經驗:將 (st,at,rt,st+1)(s_t, a_t, r_t, s_{t+1})(st?,at?,rt?,st+1?)存入經驗回放緩沖區,保持時間連續性(LSTM依賴序列順序)。
7.2 訓練階段
-
采樣序列:
從緩沖區抽取多個連續序列(如長度=8 ,(si,ai,ri,si+1)(s_i, a_i, r_i, s_{i+1})(si?,ai?,ri?,si+1?) 片段))。
每個序列初始隱藏狀態 h_0 可重置為零或繼承上一序列末尾狀態(實驗設定)。 -
LSTM前向傳播:
輸入序列狀態 [s1,s2,...,s8][s_1, s_2, ..., s_8][s1?,s2?,...,s8?],輸出對應動作概率 [π1,π2,...,π8][π_1, π_2, ..., π_8][π1?,π2?,...,π8?] 和狀態價值 [V1,V2,...,V8][V_1, V_2, ..., V_8][V1?,V2?,...,V8?]。 -
計算優勢:
使用廣義優勢估計(GAE,Generalized Advantage Estimation)計算每個動作的優勢值 A_t。 -
損失計算:
聯合優化策略損失(含LSTM輸出)和值函數損失:
L=LCLIP?c1LVF+c2H(π)L=L^{CLIP} -c_1L^{VF}+c_2 H(\pi)L=LCLIP?c1?LVF+c2?H(π)
- LVFL^{VF}LVF 是值函數損失(均方誤差)。
H(π)是策略熵(鼓勵探索)。
- 梯度更新:通過Adam等優化器更新LSTM和全連接層參數
7.3 數據流圖示
# 簡化的數據流示例
for episode in episodes:h_t = LSTM.init_hidden() # 初始化隱藏狀態for t in timesteps:a_t, π_t, V_t = LSTM(s_t, h_t) # 動作采樣s_{t+1}, r_t = env.step(a_t) # 環境交互buffer.push(s_t, a_t, r_t, V_t, π_t) # 存儲序列h_t = LSTM.update_hidden() # 更新隱藏狀態# 訓練時
batch = buffer.sample_sequence(length=8)
A_t = GAE.calculate(batch) # 優勢估計
loss = PPO_loss(π_t, A_t, V_t) # 計算損失
optimizer.step(loss) # 更新LSTM和策略網絡
7.4 優化目標
PPO+LSTM的優化目標是最大化期望累積獎勵,通過以下兩個核心機制實現:
- 策略梯度(Policy Gradient):
- 直接優化策略分布 π(a∣s,h)π(a|s, h)π(a∣s,h),使得高優勢動作的概率增加。
- 梯度公式:
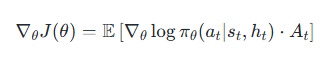
- 值函數優化(Value Function):
- 最小化值函數誤差(均方誤差),使 V(s_t) 更準確預測累積獎勵:
7.6 PPO的約束機制’
-
重要性采樣裁剪:限制新舊策略差異,避免LSTM因大幅更新而失效:
LCLIP=E[min?(πθ(at∣st,ht)πold(at∣st,ht))At,clip(πθπold,1?ε,1+ε)At]L^{CLIP}=\mathbb{E}[\min(\frac{\pi_{\theta}(a_t|s_t,h_t)}{\pi_{old}(a_t|s_t,h_t)})A_t,clip(\frac{\pi_{\theta}}{\pi_{old}},1-\varepsilon, 1+\varepsilon)A_t]LCLIP=E[min(πold?(at?∣st?,ht?)πθ?(at?∣st?,ht?)?)At?,clip(πold?πθ??,1?ε,1+ε)At?] -
熵正則化:鼓勵探索,防止策略過早收斂:
-
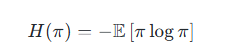
7.7 LSTM的時序優化
- 時間反向傳播(BPTT) :梯度沿時間步傳播,更新LSTM的權重和隱藏狀態。
- 序列長度權衡:
過短(如4步):無法學習長期依賴(如繞行U型障礙)。
過長(如16步):梯度消失/爆炸風險增加(論文中選擇8步)。
7.8 LSTM+PPO的網絡結構
(1) 共享的LSTM主干
輸入層:接收當前狀態 s_t 和上一時刻的隱藏狀態 h_{t-1}。
- 狀態 s_t 的維度:[N, E, S, W障礙信息, x-distance, y-distance](6維向量)。
- 示例:[0, 1, 0, 0, 3.2, -1.5] 表示東側有障礙,目標在東北方向。
- 訓練時輸入一個時間窗口的序列(如長度=8),形狀為 [batch_size, 8, 6]。
LSTM層:
- 隱藏單元數:64(論文附錄超參數)。
- 層數:1層(單層LSTM已足夠處理導航任務的時序依賴)。
- 輸出:時序特征 h_t(隱藏狀態)和 c_t(細胞狀態)。
(2) 分離的輸出頭
策略頭(Policy Head):
- 結構:全連接層(Linear + Softmax)。
- 輸入:LSTM輸出的 h_t。
- 輸出:動作概率分布 π(a|s_t)(4維,對應 N, E, S, W)。如 [N:0.7, E:0.1, S:0.1, W:0.1]。
價值頭(Value Head):
- 結構:全連接層(Linear)。
- 輸入:與策略頭共享 h_t。
- 輸出:標量狀態價值 V(s_t)(預測當前狀態的長期回報)。標量,如 0.85,表示當前狀態的預期累積獎勵。
(3)結構代碼示例
# 偽代碼描述網絡結構
class PPOLSTM(nn.Module):def __init__(self):self.lstm = nn.LSTM(input_size=6, hidden_size=64, num_layers=1)self.policy_head = nn.Sequential(nn.Linear(64, 4), # 4 actionsnn.Softmax(dim=-1))self.value_head = nn.Linear(64, 1) # 1 valuedef forward(self, s_t, h_t):# s_t: [batch_size, sequence_length, 6]# h_t: (h0, c0) 兩個張量形狀都是 [num_layers, batch_size, hidden_size]lstm_out, (h_next, c_next) = self.lstm(s_t, h_t)# lstm_out: [batch_size, seq_len, 64]policy = self.policy_head(lstm_out) # [batch, seq_len, 4]value = self.value_head(lstm_out) # [batch, seq_len, 1]return policy, value, (h_next, c_next)

| 變量 | 形狀 | 含義 |
|---|---|---|
s_t | [B, L, 6] | 一批長度為 L 的序列觀測(可一次送 L=1 做單步,也可 L=T 做整段 rollout)。 |
h_t | 元組 (h0, c0) | LSTM 的初始/當前隱狀態,形狀 [1, B, 64]。推理時要記得把上一時刻的 (h_next, c_next) 傳回來。 |
lstm_out | [B, L, 64] | 所有時間步的隱狀態序列。 |
policy | [B, L, 4] | 每一步每個動作的 softmax 概率。 |
value | [B, L, 1] | 每一步的狀態值 V(s)。 |
(h_next, c_next) | [1, B, 64] | 經過 L 步后的最終隱狀態,用于下一步繼續 rollout 或訓練。 |
(4)數據收集
h = (torch.zeros(1, B, 64), torch.zeros(1, B, 64)) # 初始化 LSTM 隱藏態
for t in range(T):obs = env.step(...) # [B, 6]logits, val, h = model(obs.unsqueeze(1), h) # unsqueeze 變成 [B,1,6]action = Categorical(logits.squeeze(1)).sample()buffer.store(obs, action, val.squeeze(), h_old=h)
7.9 策略網絡與價值網絡的關系
(1) 參數共享
- 共享LSTM:策略和價值頭共用同一LSTM提取的時序特征,減少計算量并提升穩定性。
- 分離梯度:策略頭和價值頭的梯度獨立回傳,但LSTM的梯度是兩者的加權和
(2) 聯合優化目標
總損失函數結合策略損失、值函數損失和熵正則化:
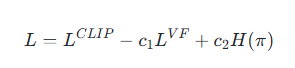
- LCLIPL^{CLIP}LCLIP:PPO的策略裁剪損失(基于動作概率和優勢值)。
- LVFL^{VF}LVF:值函數的均方誤差損失 (V(s_t) - R_t)^2。
- H(π)H(π)H(π):策略熵(鼓勵探索),通過策略頭的Softmax輸出計算。
(3)若策略網絡和價值網絡完全獨立(非共享LSTM):
- 優點:避免任務沖突(如價值擬合可能干擾策略學習)。
- 缺點:
參數翻倍,訓練更慢。
時序特征需分別學習,效率低。
論文選擇:共享LSTM更適合樣本效率要求高的強化學習任務。

)
,Matlab完整源碼)




![[Rust 基礎課程]使用 Cargo 創建 Hello World 項目](http://pic.xiahunao.cn/[Rust 基礎課程]使用 Cargo 創建 Hello World 項目)

)
操作方法和屬性匯總詳解和代碼示例)

:實現一個音樂列表的頁面)
 47(題目+回答))
)
)



