文章目錄
- 前言
- 一、下載Hadoop安裝包及bin目錄
- 1. 下載Hadoop安裝包
- 2. 下載Hadoop的bin目錄
- 二、安裝Hadoop
- 1. 解壓Hadoop安裝包
- 2. 解壓Hadoop的Windows工具包
- 三、配置Hadoop
- 1. 配置Hadoop環境變量
- 1.1 打開系統屬性設置
- 1.2 配置環境變量
- 1.3 驗證環境變量是否配置成功
- 2. 修改Hadoop配置文件
- 2.2 修改 core-site.xml 配置文件
- 2.3 修改 hdfs-site.xml 配置文件
- 3.4 修改 mapred-site.xml 配置文件
- 3.5 修改 yarn-site.xml 配置文件
- 3. 格式化HDFS(Hadoop分布式文件系統)
- 4. 復制timelineservice目錄
- 5. Hadoop啟動和停止
- 5.1 啟動 Hadoop
- 5.2 停止 hadoop 集群
前言
Hadoop作為大數據領域的基石框架,在數據存儲與處理方面展現出了卓越的性能與強大的擴展性,為海量數據的高效管理與分析提供了有力支撐。在當今數字化浪潮席卷全球,數據量呈爆發式增長的時代背景下,掌握Hadoop的安裝與配置技能顯得尤為重要,它是開啟大數據世界大門的一把關鍵鑰匙。無論是企業希望從繁雜的數據中挖掘商業價值,還是科研人員致力于數據分析以推動學術研究進展,Hadoop都能發揮其獨特的優勢。本文將以清晰明了的步驟,詳細闡述在特定環境下Hadoop的安裝與配置過程,旨在幫助讀者順利搭建起Hadoop運行環境,為后續深入探索大數據技術奠定堅實基礎。
一、下載Hadoop安裝包及bin目錄
1. 下載Hadoop安裝包
華為云鏡像站下載:https://mirrors.huaweicloud.com/repository/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
2. 下載Hadoop的bin目錄
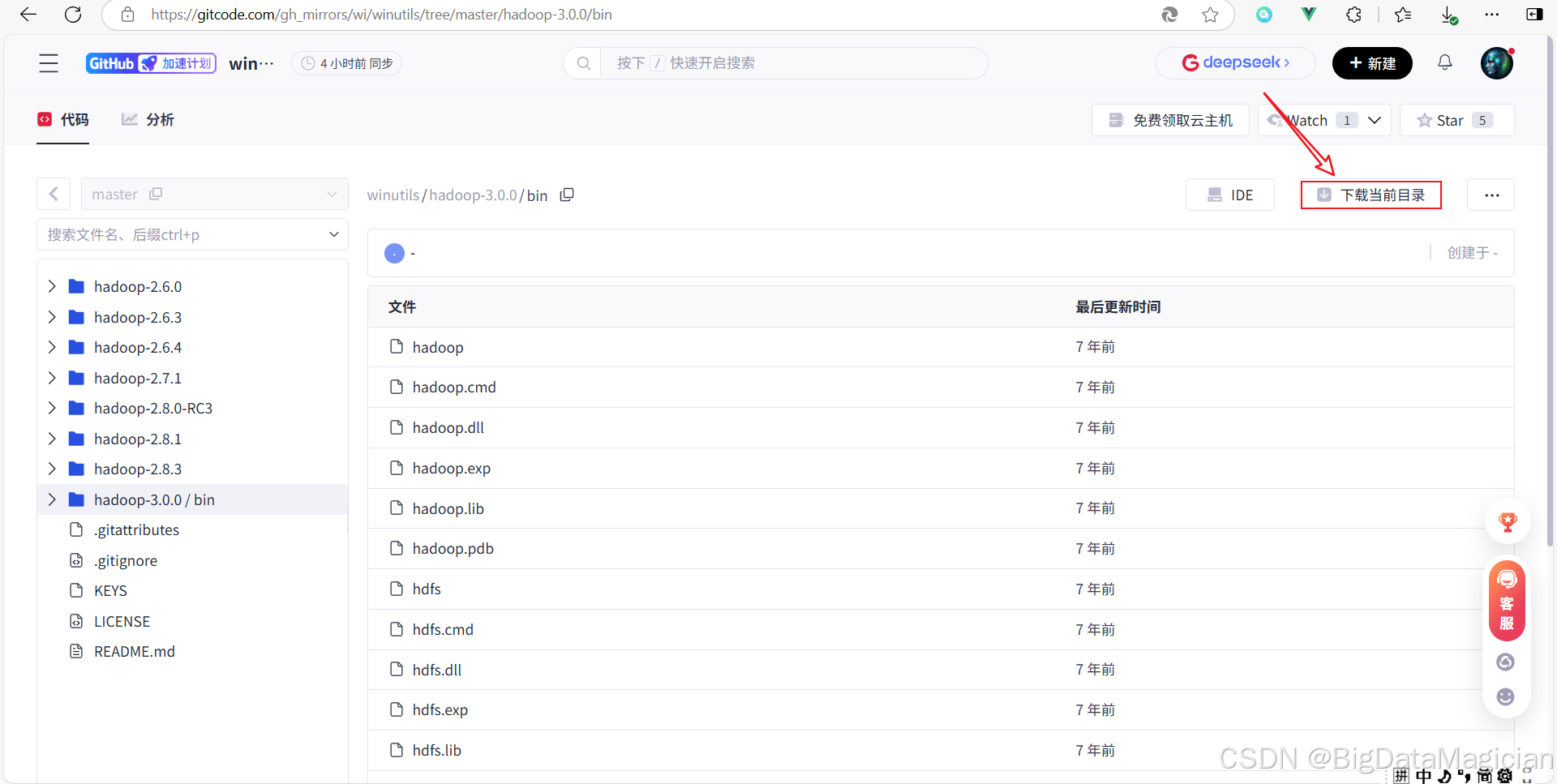
下載Hadoop的bin目錄地址:https://gitcode.com/gh_mirrors/wi/winutils/tree/master/hadoop-3.0.0/bin
進入下載網站后,點擊下載當前目錄,如下圖所示。
二、安裝Hadoop
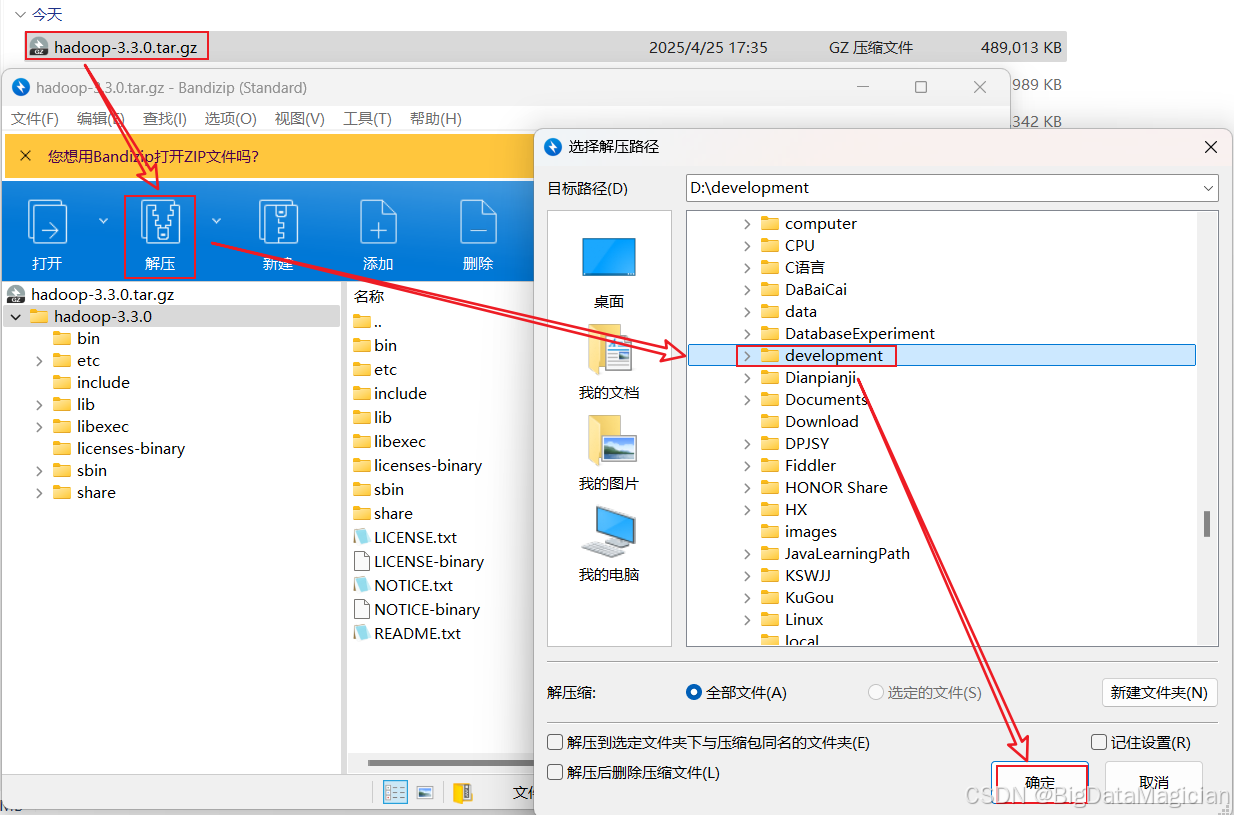
1. 解壓Hadoop安裝包
雙擊下載好的安裝包,點擊解壓,選則解壓路徑,然后點擊確定,如下圖所示。
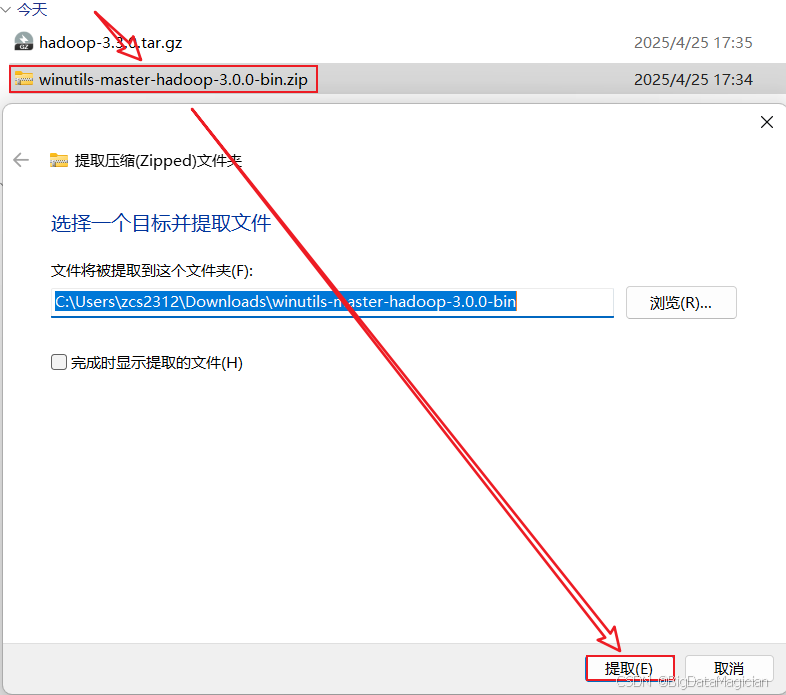
2. 解壓Hadoop的Windows工具包
解壓Hadoop的Windows工具包到下載目錄,如下圖所示。
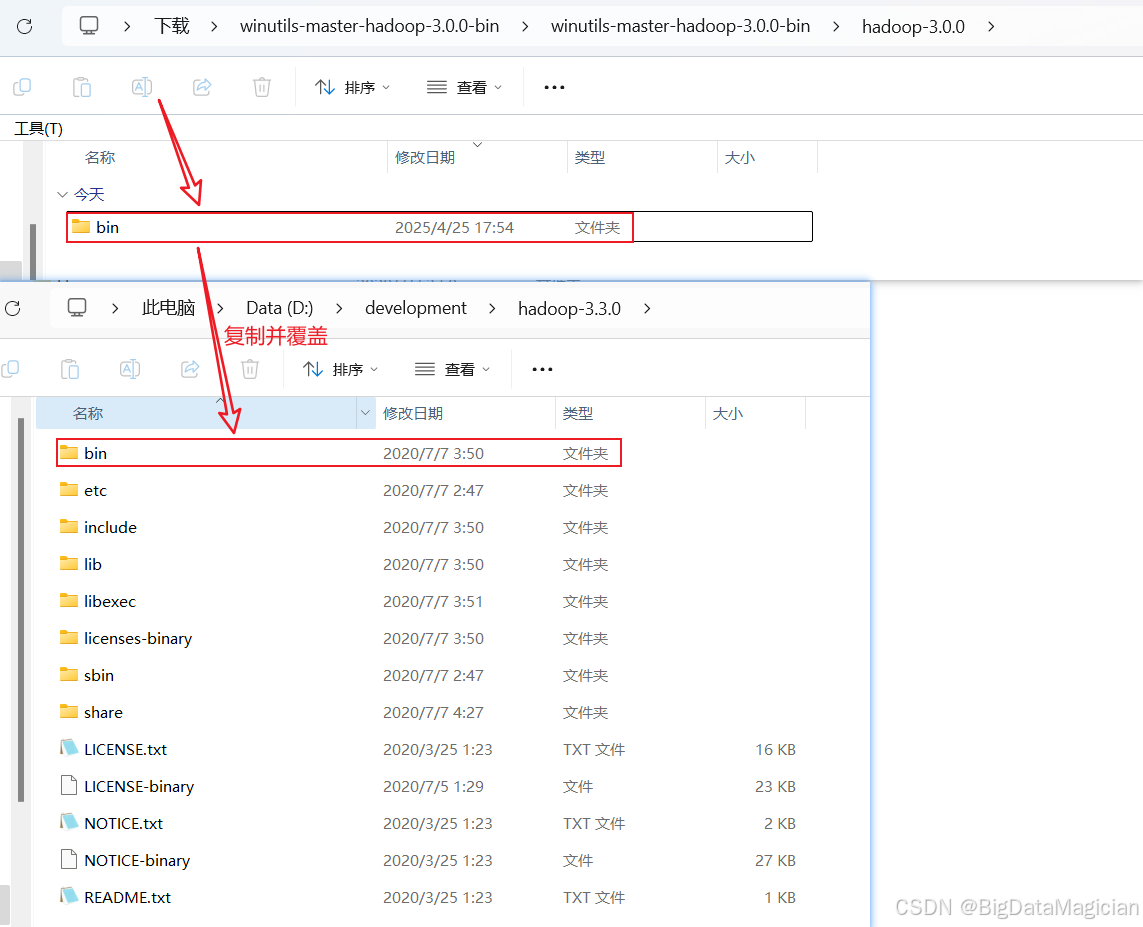
把Hadoop的Windows工具包中的bin目錄復制到解壓后的Hadoop目錄,覆蓋原有的bin目錄,如下圖所示。
三、配置Hadoop
1. 配置Hadoop環境變量
1.1 打開系統屬性設置
- 右鍵點擊“
此電腦”,選擇“屬性”,點擊“高級系統設置”。 - 在彈出的“
系統屬性”窗口中,點擊“環境變量”。

1.2 配置環境變量
在環境變量頁面點擊新建,輸入變量名和變量值(變量名為HADOOP_HOME,變量值為解壓后的hadoop目錄),然后點擊確定,如下圖所示。
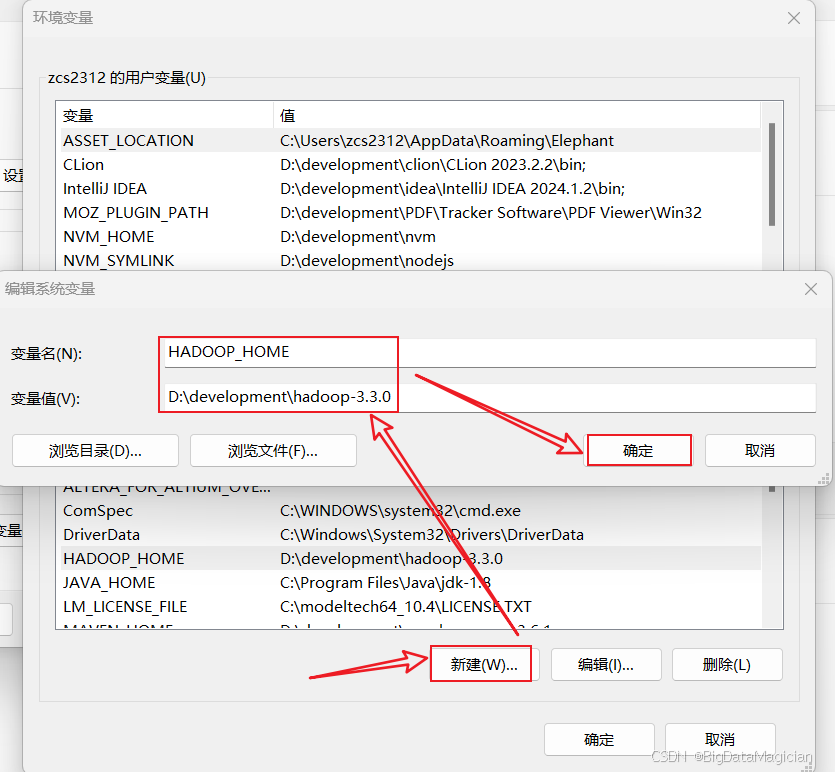
路徑變量配置步驟如下圖所示。
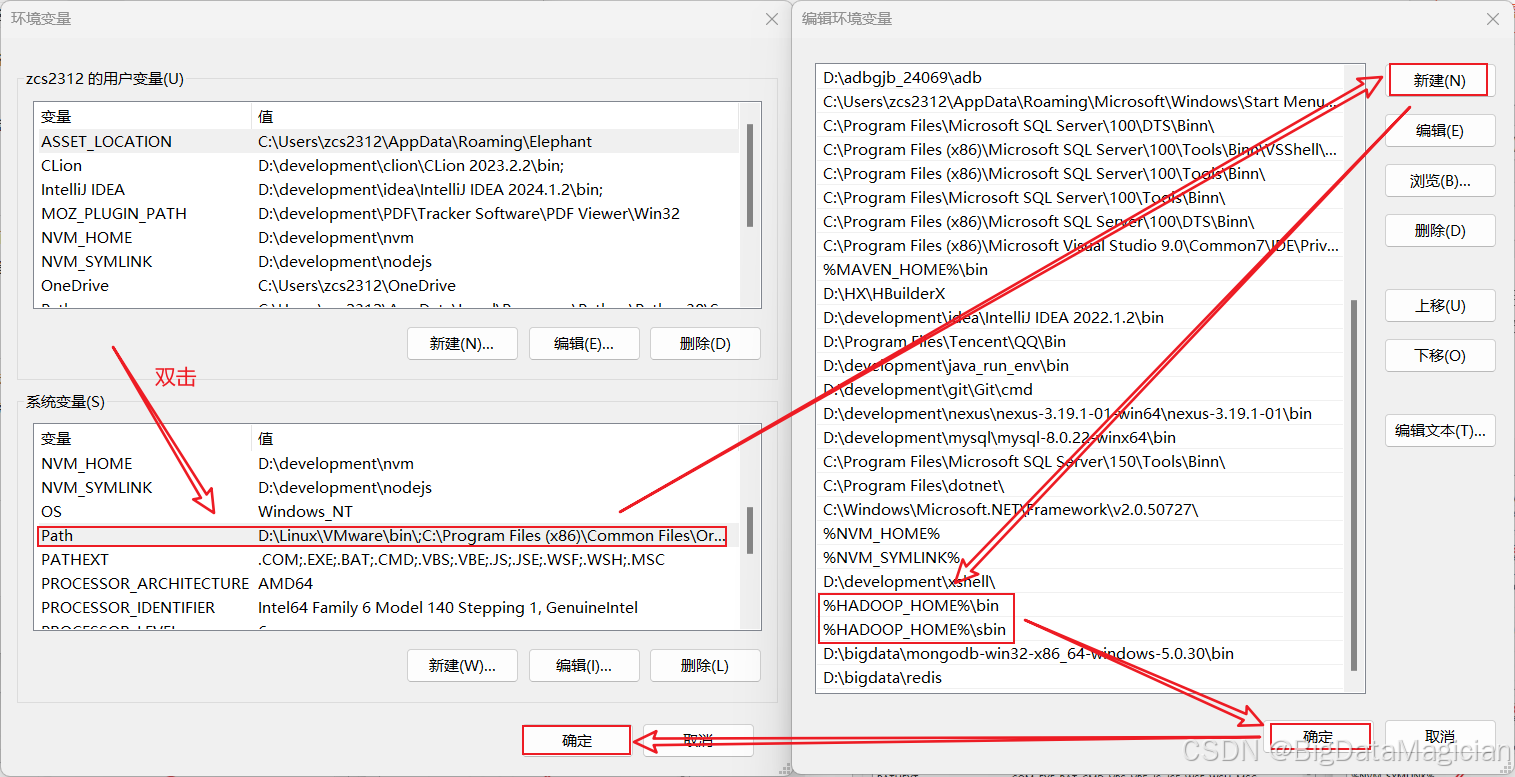
1.3 驗證環境變量是否配置成功
打開一個新的命令提示符窗口(cmd),輸入 hadoop version 來驗證hadoop環境變量是否正確配置。如果顯示了版本信息,則說明環境變量配置成功。
配置成功如下圖所示:

注意:
如出現如下圖所示的異常,說明jdk路徑在C盤,需要使用C:\PROGRA~1或"C:\Program Files"代替C:\Program Files。

解決方法:
把D:\development\hadoop-3.3.0\etc\hadoop\hadoop-env.cmd文件中set JAVA_HOME=%JAVA_HOME%修改為set JAVA_HOME=C:\PROGRA~1\Java\jdk-1.8。
2. 修改Hadoop配置文件
2.2 修改 core-site.xml 配置文件
修改hadoop核心配置文件D:\development\hadoop-3.3.0\etc\hadoop\core-site.xml,內容如下所示。
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定Hadoop集群的默認文件系統名稱 --><property><name>fs.defaultFS</name><value>hdfs://127.0.0.1:9000</value></property>
</configuration>
2.3 修改 hdfs-site.xml 配置文件
修改hdfs的配置文件D:\development\hadoop-3.3.0\etc\hadoop\hdfs-site.xml,內容如下所示。
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.secondary.http-address</name><value>127.0.0.1:9868</value></property><property> <name>dfs.namenode.name.dir</name> <value>/D:/development/hadoop-3.3.0/data/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/D:/development/hadoop-3.3.0/data/datanode</value> </property>
</configuration>
3.4 修改 mapred-site.xml 配置文件
修改mapreduce的配置文件D:\development\hadoop-3.3.0\etc\hadoop\mapred-site.xml,內容如下所示。
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
3.5 修改 yarn-site.xml 配置文件
修改yarn的配置文件D:\development\hadoop-3.3.0\etc\hadoop\yarn-site.xml,內容如下所示。
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>1024</value></property><property><name>yarn.nodemanager.resource.cpu-vcores</name><value>1</value></property></configuration>
3. 格式化HDFS(Hadoop分布式文件系統)
執行如下命令格式化Hadoop分布式文件系統HDFS。
hdfs namenode -format
格式化成功如下圖所示,會提示我們存儲目錄 D:\development\hadoop-3.3.0\data\namenode 已經成功格式化。
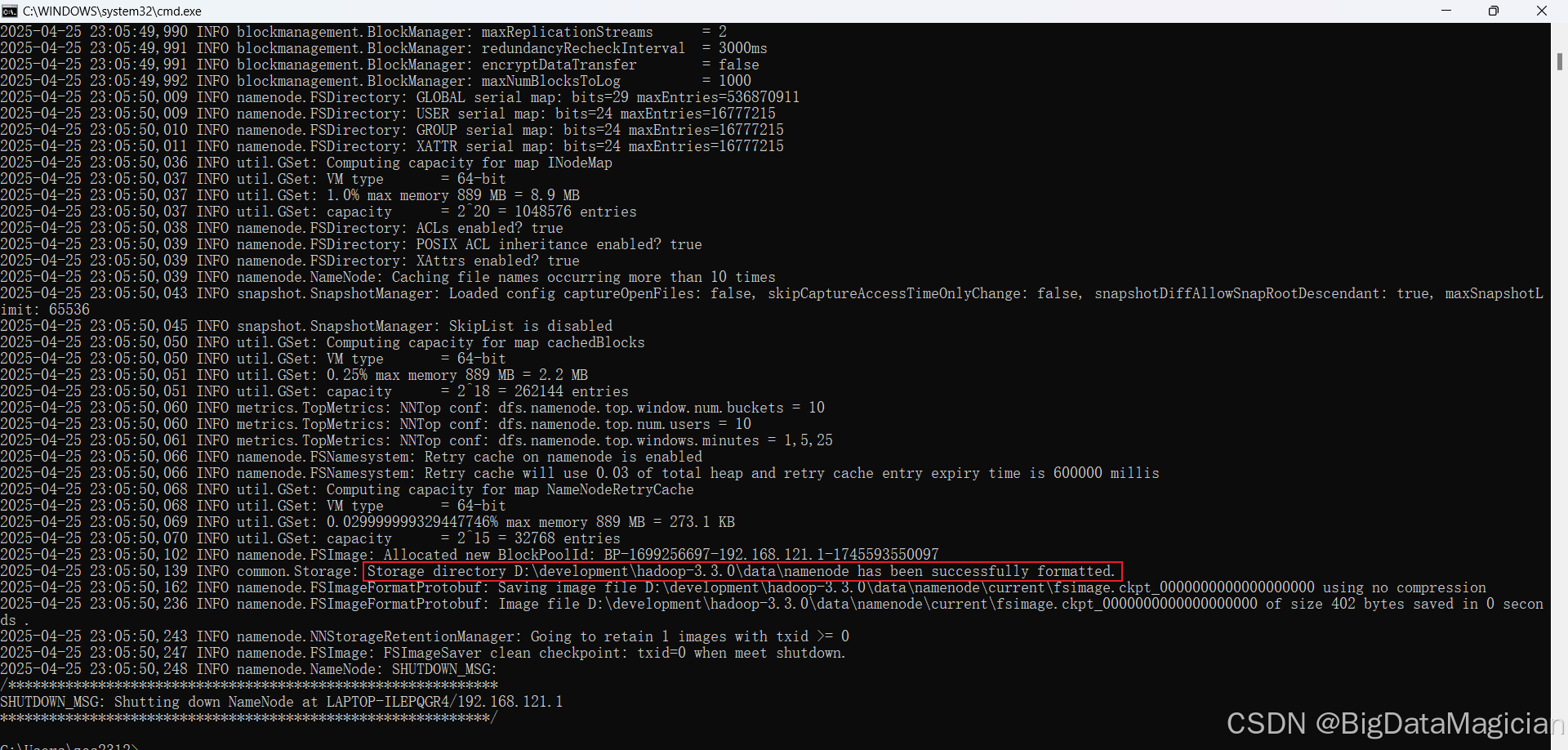
4. 復制timelineservice目錄
把D:\development\hadoop-3.3.0\share\hadoop\yarn\timelineservice目錄下的jar包復制到上級目錄,如下圖所示。
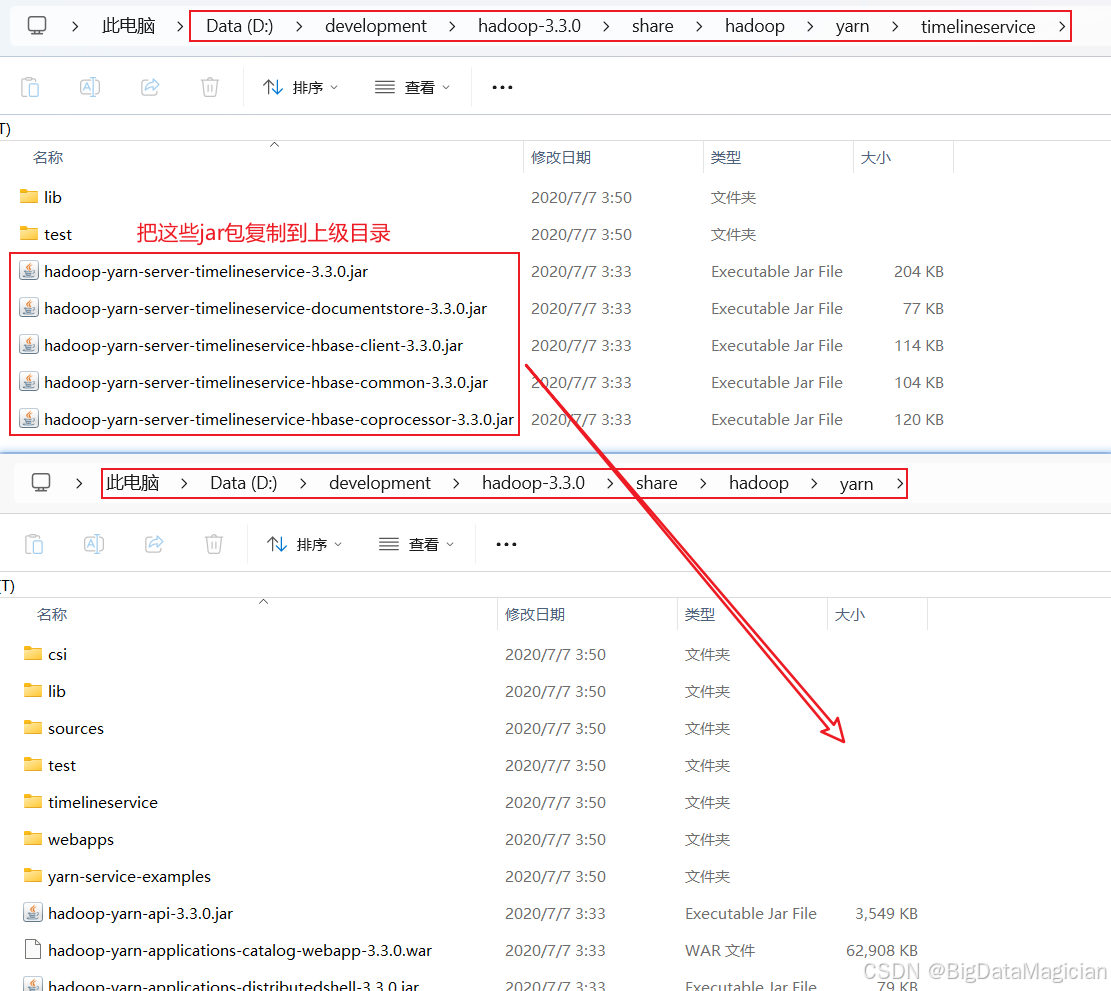
5. Hadoop啟動和停止
5.1 啟動 Hadoop
在cmd中執行如下命令啟動Hadoop。
start-all.cmd

訪問 HDFS(NameNode)的 Web UI 頁面
在啟動hadoop集群后,在瀏覽器輸入http://127.0.0.1:9870進行訪問,如下圖。
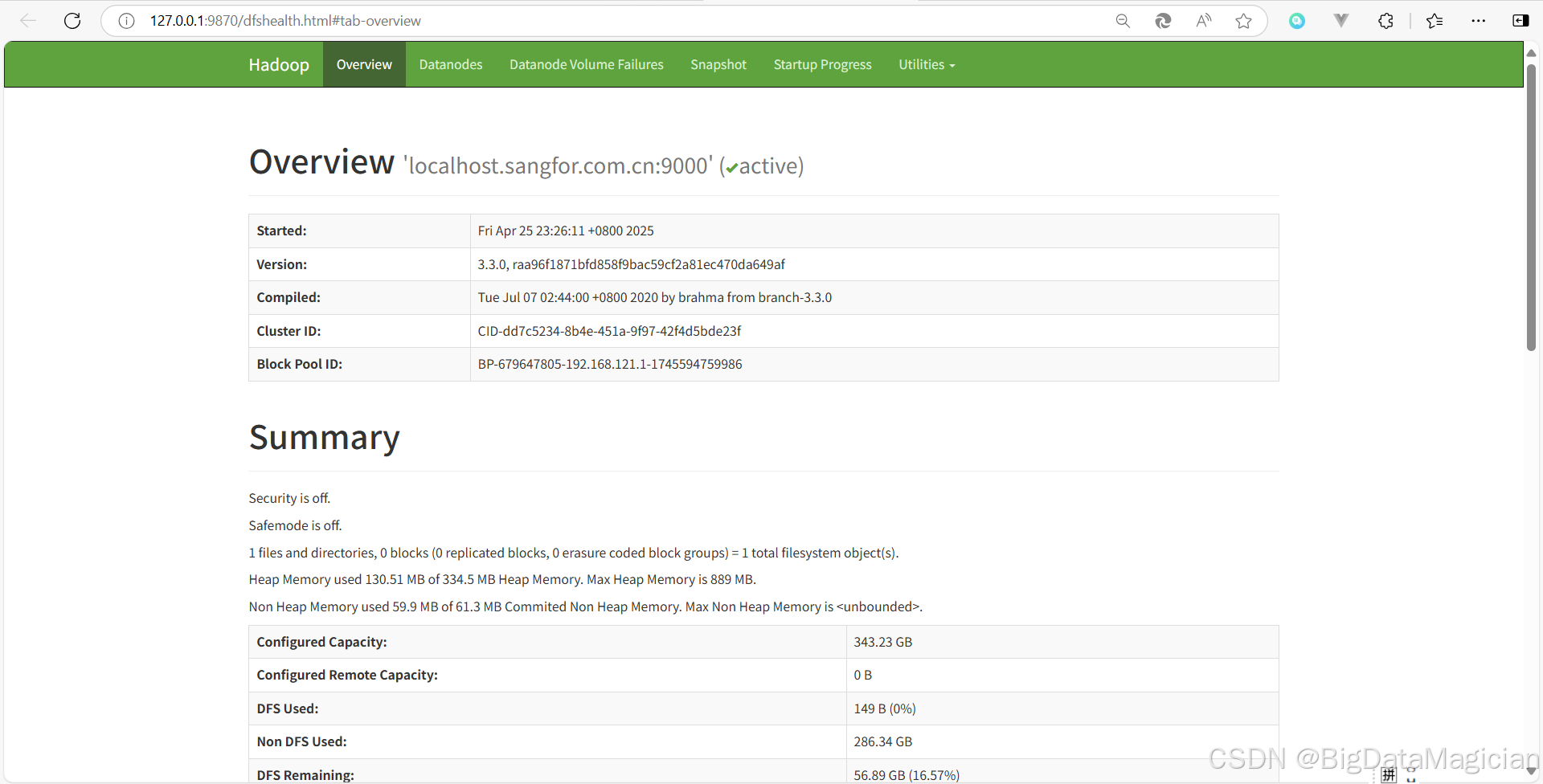
檢查DataNode是否正常,正常如下圖所示。

訪問 YARN 的 Web UI 頁面
在啟動hadoop集群后,在瀏覽器輸入http://127.0.0.1:8088進行訪問,如下圖。
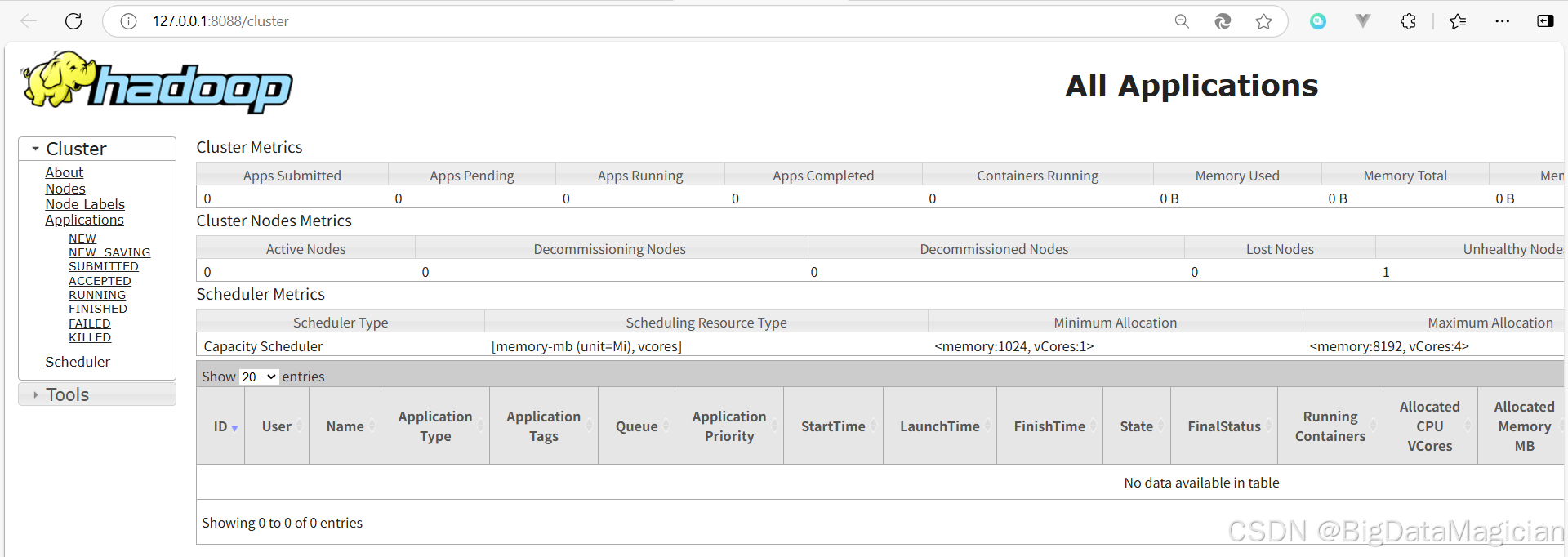
5.2 停止 hadoop 集群
在cmd中執行如下命令啟動Hadoop。
stop-all.cmd
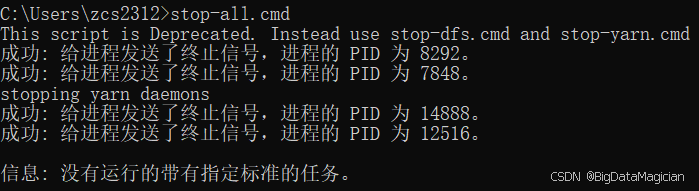









)




)
概述)
STOMP: Stochastic Trajectory Optimization for Motion Planning)
 -RGBLED控制、定時器輸入捕獲、主從定時器移相控制-STM32CubeMX)

