OPPO搜廣推一面面經
一、介紹一下PLE模型
在多任務學習(Multi-Task Learning, MTL)中,多個任務共享部分模型結構,以提升整體效果。然而,不同任務間存在 任務沖突(Task Conflict) 問題,即不同任務對參數的優化方向不一致,導致性能下降。
論文:Tang, Hongyan, et al. “Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations.” RecSys 2020.
PLE 的核心思想是:
通過引入多個專家網絡(Experts)并區分共享專家與特定任務專家,結合門控機制(Gating Network)實現任務間知識共享與隔離的平衡。
1.1. 核心架構
- 專家網絡(Experts):
- Shared Experts:供所有任務共享
- Task-Specific Experts:只供特定任務使用
- 門控網絡(Gating Network):
- 每個任務都有自己的門控網絡,決定該任務在當前層中應從哪些專家中獲取信息
- 輸出為每個專家的加權系數
- 塔結構(Tower):
- 每個任務最終仍保留獨立的塔(MLP),用于完成最終預測
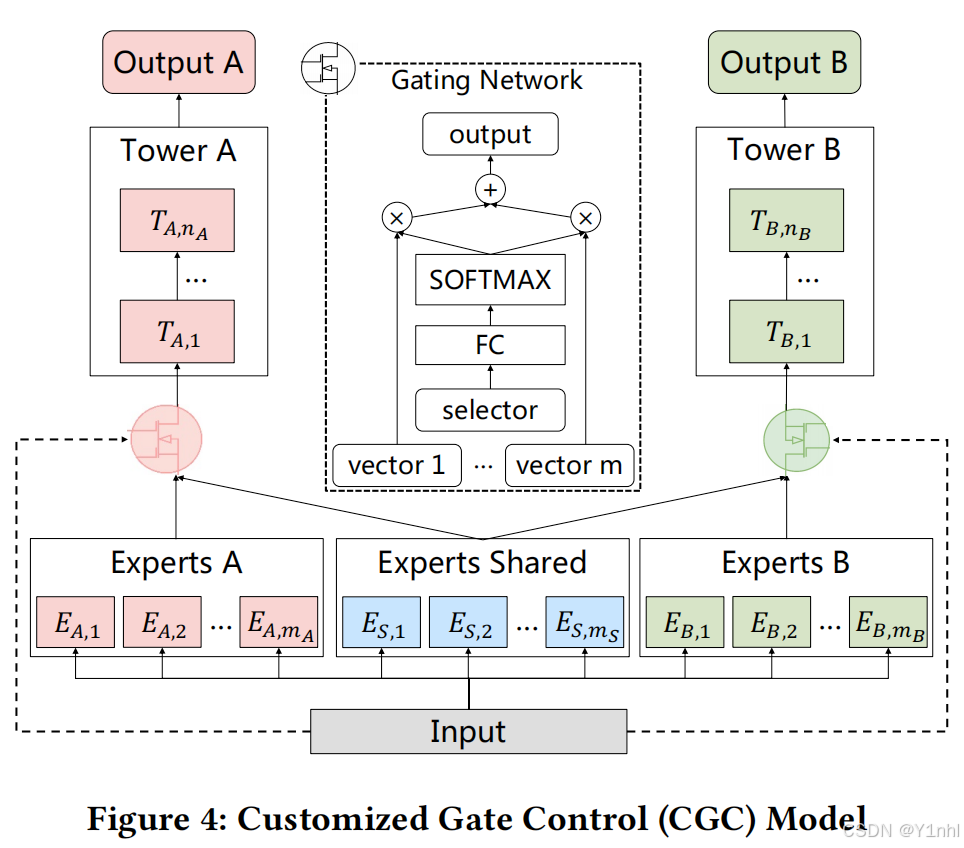
1.2. CGC(Customized Gate Control)結構
- 為了解決任務之間的“蹺蹺板”效應或負遷移效應,MMoE引入了任務獨有的gate(expert是共享的,但gate是任務獨有的,即不同任務通過gate共享相同的expert)
- CGC在共享expert之外,新增了task specific expert,即每個任務單獨的expert,這些expert是專門用于對應任務的優化的。CGC既能享受到共享特征帶來的好處,也有專有的expert為不同任務提供獨自的優化空間。每一個任務的Tower網絡都獲取相應任務獨享的專家網絡輸出和共享的專家網絡輸出
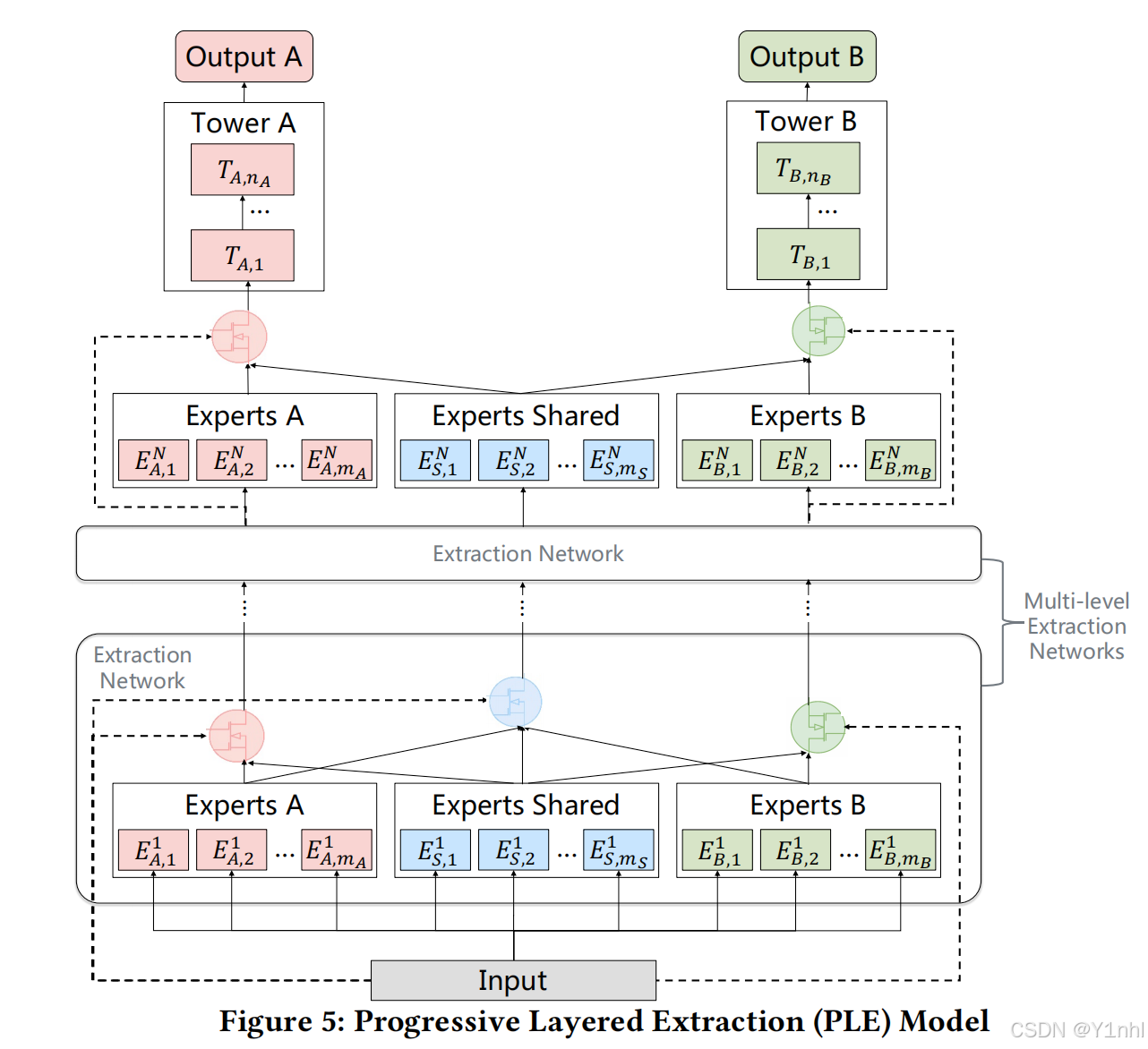
1.3. PLE就是Extraction Network + 多層CGC的架構
CGC中門控網絡的個數等于任務的個數,而Extraction Network中除了對應任務的門控網絡外,還有一個共享的門控網絡。高層Extraction Network的輸入不是原始的輸入,而是包含更抽象語義的底層Extraction Network的門控融合輸出。
Extraction Network結構 + CGC結構 如下圖:
二、模型一般用什么優化器來訓練,Adam優化器的原理,用過哪些優化器,有過對參數的調整嗎?
感覺用得最多的必然是Adam了,原理介紹見【搜廣推校招面經十三】
三、深度學習怎么防止過擬合,L1和L2正則化的區別
見【搜廣推校招面經二十,搜廣推校招面經十四,搜廣推校招面經三十一】
四、排序模型和分類模型輸入是一樣的嗎,輸出有什么差別
4.1. 輸入:基本一致
排序模型(Ranking Model)和分類模型(Classification Model)在輸入特征方面是類似的,通常都是一組結構化的特征向量,反正都是二維的表格。這些特征可以包括數值型、類別型、文本向量化表示等,經過處理(如歸一化、Embedding)后送入模型。
4.2. 輸出:存在本質差異
| 項目 | 分類模型(Classification) | 排序模型(Ranking) |
|---|---|---|
| 輸出形式 | 各類別的概率或標簽 | 候選項的排序分數或排名 |
| 任務目標 | 預測所屬類別 | 判斷多個樣本之間的相對排序 |
| 應用示例 | 圖片識別:貓 / 狗 / 鳥 | 推薦系統:為用戶排序商品 |
| 損失函數常用 | CrossEntropyLoss、FocalLoss | Pairwise:Hinge loss、BPR Listwise:Softmax Cross Entropy、LambdaRank |
| 預測方式 | 選最大概率的類別 | 根據得分排序候選項 |
4.3. pointwise、pairwise、listwise建模排序模型
見【搜廣推校招面經二十九】
排序任務可以根據建模的方式分為三類:Pointwise、Pairwise 和 Listwise,主要區別在于它們如何構造訓練樣本以及如何定義損失函數。
4.3.1. Pointwise 方法
- 思想:將排序任務看作回歸或分類問題,分別對每個樣本預測一個相關性得分或標簽。
- 建模方式:
- 每個樣本是一個獨立的 query-document 對
- 預測其與 query 的相關性得分或是否點擊(0/1)
- 常用模型/損失函數:
- 回歸:MSE(Mean Squared Error)
- 分類:CrossEntropyLoss、LogLoss
- 缺點:
- 忽略了樣本之間的相對關系,排序效果可能不佳
4.3.2. Pairwise 方法
- 思想:將排序任務轉化為二分類問題,學習成對樣本的相對順序(誰排在前面)。
- 建模方式:
- 輸入為兩個文檔對 (di, dj),同屬于一個 query
- 模型學習 di 是否比 dj 更相關
- 常用模型/損失函數:
- RankNet:使用 s i g m o i d ( s c o r e i ? s c o r e j ) sigmoid(score_i - score_j) sigmoid(scorei??scorej?)
- BPR(Bayesian Personalized Ranking)
- Hinge loss(如 SVMRank)
- 缺點:
- 樣本數量為 O(n2),訓練成本高
4.3.3. Listwise 方法
- 思想:直接以整個候選列表為輸入,優化整個排序列表的質量。
- 建模方式:
- 訓練樣本為一個 query 對應的多個文檔列表
- 模型學習整個列表的最優排列順序
- 常用模型/損失函數:
- ListNet、ListMLE(優化列表似然)
- LambdaRank、LambdaMART(基于 NDCG 等指標的優化)
- 優點:更適合優化排序指標(如 NDCG、MAP)
4.3.4. 三種方法對比表
| 方法 | 輸入粒度 | 損失目標 | 優點 | 缺點 |
|---|---|---|---|---|
| Pointwise | 單個樣本 | 回歸/分類損失 | 實現簡單,易于訓練 | 無法建模樣本間排序關系 |
| Pairwise | 樣本對 | 相對順序損失 | 引入相對信息,排序效果好 | 樣本量大,訓練時間較長 |
| Listwise | 整個樣本列表 | 列表級排序指標 | 排序效果最佳 | 實現復雜,訓練成本高 |
五、NDCG(Normalized Discounted Cumulative Gain)計算方法
NDCG 是一種常用的排序評估指標,衡量推薦結果的相關性和排序位置。值越高,說明模型越好。其核心思想是:
- 相關性越高的項排在越前面越好
- 靠前位置的重要性更高(打折)
🔸Step 1: 計算 DCG(Discounted Cumulative Gain)
對于前 k 個推薦結果,DCG 的定義如下:
公式一(使用等級評分):
D C G @ k = ∑ i = 1 k r e l i log ? 2 ( i + 1 ) DCG@k = \sum_{i=1}^{k} \frac{rel_i}{\log_2(i + 1)} DCG@k=i=1∑k?log2?(i+1)reli??
公式二(使用指數評分,更重視高相關性):
D C G @ k = ∑ i = 1 k 2 r e l i ? 1 log ? 2 ( i + 1 ) DCG@k = \sum_{i=1}^{k} \frac{2^{rel_i} - 1}{\log_2(i + 1)} DCG@k=i=1∑k?log2?(i+1)2reli??1?
其中:
rel_i:第 i 個位置的真實相關性評分(如:點擊=1,未點擊=0,或等級評分1~5)i:排序位置,從 1 開始
🔸 Step 2: 計算 IDCG(Ideal DCG)
IDCG 是將相關性從高到低理想排序后得到的 DCG,即最優情況下的 DCG:
I D C G @ k = DCG@k?of?ideal?(sorted)?list IDCG@k = \text{DCG@k of ideal (sorted) list} IDCG@k=DCG@k?of?ideal?(sorted)?list
🔺 Step 3: 計算 NDCG(歸一化 DCG)
N D C G @ k = D C G @ k I D C G @ k NDCG@k = \frac{DCG@k}{IDCG@k} NDCG@k=IDCG@kDCG@k?
如果 IDCG@k = 0(全是 0 分相關性),通常設定 NDCG@k = 0。
示例
直接看公式可能不夠清晰,搞個例子。假設模型返回的文檔真實相關性為:
predicted ranking: [D1, D2, D3, D4, D5]
rel_scores: [3, 2, 3, 0, 1] ← rel_i
計算 DCG@5(使用公式二):
DCG@5 = (2^3 - 1)/log2(1+1) + (2^2 - 1)/log2(2+1) + (2^3 - 1)/log2(3+1) + (2^0 - 1)/log2(4+1) +(2^1 - 1)/log2(5+1)≈ 7/1 + 3/1.5849 + 7/2 + 0/2.3219 + 1/2.5849≈ 7 + 1.892 + 3.5 + 0 + 0.387≈ 12.779
理想排序的相關性:[3, 3, 2, 1, 0],計算 IDCG@5(同樣方法):
IDCG@5 ≈ 7/1 + 7/1.5849 + 3/2 + 1/2.3219 + 0/2.5849≈ 7 + 4.417 + 1.5 + 0.430 + 0≈ 13.347
根據Step3
NDCG@5 = 12.779 / 13.347 ≈ 0.957








)




)
概述)
STOMP: Stochastic Trajectory Optimization for Motion Planning)
 -RGBLED控制、定時器輸入捕獲、主從定時器移相控制-STM32CubeMX)


