摘要
我們提出了基于純transformer的視頻分類模型,借鑒了這種模型在圖像分類中的成功經驗。我們的模型從輸入視頻中提取時空token,然后通過一系列transformer層進行編碼。為了處理視頻中遇到的長序列token,我們提出了幾種高效的模型變種,這些變種將輸入的空間和時間維度進行了分解。盡管基于transformer的模型通常只有在有大量訓練數據時才有效,但我們展示了如何在訓練過程中有效地正則化模型,并利用預訓練的圖像模型,在相對較小的數據集上進行訓練。我們進行了徹底的消融研究,并在多個視頻分類基準測試上取得了最先進的結果,包括Kinetics 400和600、Epic Kitchens、Something-Something v2和Moments in Time,超過了基于深度3D卷積網絡的先前方法。為了促進進一步的研究,我們在https://github.com/google-research/scenic發布了代碼。
1. 引言
基于深度卷積神經網絡的方法自AlexNet [38]以來,已經推動了視覺問題標準數據集上的最先進技術。同時,序列到序列建模(例如自然語言處理)中最突出的架構是transformer [68],它不使用卷積,而是基于多頭自注意力機制。該操作在建模長程依賴關系方面特別有效,允許模型在輸入序列的所有元素之間進行注意力操作。這與卷積的“感受野”形成鮮明對比,后者是有限的,并隨著網絡深度的增加而線性增長。
自注意力模型在自然語言處理中的成功,最近激發了計算機視覺領域的研究,嘗試將transformer集成到CNN中 [75, 7],以及一些完全替代卷積的嘗試 [49, 3, 53]。然而,直到最近,純transformer架構在圖像分類中超越了其卷積對手,這一成就出現在Vision Transformer (ViT) [18]中。Dosovitskiy 等人 [18] 緊跟[68]的原始transformer架構,并注意到其主要優勢是在大規模數據上得到體現——由于transformer缺乏卷積的一些歸納偏置(如平移不變性),它們似乎需要更多的數據 [18] 或更強的正則化 [64]。
受ViT啟發,并考慮到自注意力架構在建模視頻中的長程上下文關系時的直觀性,我們開發了幾種基于transformer的視頻分類模型。目前,性能最好的模型基于深度3D卷積架構 [8, 20, 21],這些模型是圖像分類CNN [27, 60] 的自然擴展。最近,這些模型通過在其后層引入自注意力機制,以更好地捕捉長程依賴關系 [75, 23, 79, 1]。
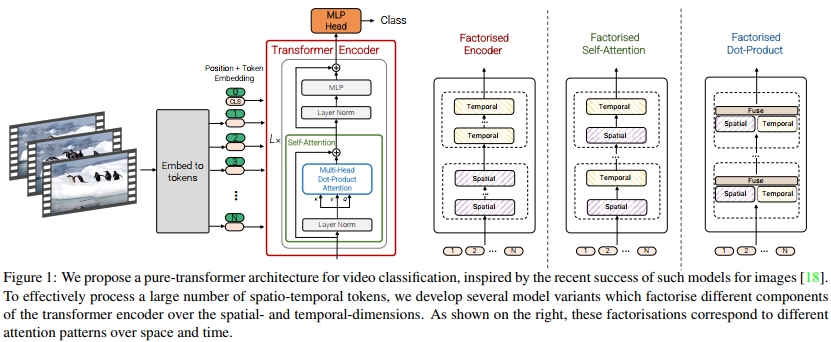
如圖1所示,我們提出了用于視頻分類的純transformer模型。該架構中執行的主要操作是自注意力,并且它是計算在從輸入視頻中提取的時空token序列上。為了有效處理視頻中可能遇到的大量時空token,我們提出了幾種沿空間和時間維度分解模型的方法,以提高效率和可擴展性。此外,為了在較小的數據集上有效訓練我們的模型,我們展示了如何在訓練過程中對模型進行正則化,并利用預訓練的圖像模型。
我們還注意到,卷積模型已經由社區開發了多年,因此與這些模型相關的“最佳實踐”已經有了很多。由于純transformer模型具有不同的特性,我們需要確定這些架構的最佳設計選擇。我們對token化策略、模型架構和正則化方法進行了徹底的消融分析。在此分析的基礎上,我們在多個標準視頻分類基準測試中取得了最先進的結果,包括Kinetics 400和600 [35]、Epic Kitchens 100 [13]、Something-Something v2 [26] 和 Moments in Time [45]。
2. 相關工作
視頻理解的架構與圖像識別的進展相一致。早期的視頻研究使用手工提取的特征來編碼外觀和運動信息 [41, 69]。AlexNet 在 ImageNet [38, 16] 上的成功最初促使了 2D 圖像卷積網絡 (CNN) 被用于視頻處理,形成了“二流”網絡 [34, 56, 47]。這些模型分別處理 RGB 幀和光流圖像,然后在最后進行融合。隨著像 Kinetics [35] 這樣的更大視頻分類數據集的出現,推動了時空 3D CNN 的訓練 [8, 22, 65],這些模型擁有顯著更多的參數,因此需要更大的訓練數據集。由于 3D 卷積網絡比圖像卷積網絡需要更多的計算,許多架構在空間和時間維度上對卷積進行了分解,或使用了分組卷積 [59, 66, 67, 81, 20]。我們也利用了視頻的空間和時間維度的分解來提高效率,但是在基于 transformer 的模型中進行的。
與此同時,在自然語言處理 (NLP) 領域,Vaswani 等人 [68] 通過用只包含自注意力、層歸一化和多層感知機 (MLP) 操作的 transformer 網絡替代卷積和遞歸網絡,取得了最先進的結果。目前,NLP 領域的最先進架構 [17, 52] 仍然是基于 transformer 的,并且已被擴展到 Web 規模的數據集 [5]。為了減少處理更長序列時自注意力的計算成本,許多 transformer 變體也被提出 [10, 11, 37, 62, 63, 73],并且為了提高參數效率 [40, 14],這些變體在許多任務中得到了應用。盡管自注意力在計算機視覺中得到了廣泛應用,但與此不同的是,它通常被集成到網絡的后期階段或通過殘差塊 [30, 6, 9, 57] 來增強 ResNet 架構中的一層 [27]。
雖然之前的工作曾試圖在視覺架構中替代卷積 [49, 53, 55],但直到最近,Dosovitskiy 等人 [18] 通過他們的 ViT 架構表明,類似于 NLP 中使用的純 transformer 網絡,也可以在圖像分類中取得最先進的結果。作者展示了這種模型只有在大規模數據集下才有效,因為 transformer 缺乏卷積網絡的一些歸納偏置(如平移不變性),因此需要比常見的 ImageNet ILSVRC 數據集 [16] 更大的數據集來進行訓練。ViT 激發了社區中的大量后續工作,我們注意到有一些同時的研究嘗試將其擴展到計算機視覺中的其他任務 [71, 74, 84, 85],以及提高其數據效率的研究 [64, 48]。特別是,文獻 [4, 46] 也提出了用于視頻的 transformer 模型。
本文中,我們開發了用于視頻分類的純 transformer 架構。我們提出了幾種模型變體,其中包括通過分解輸入視頻的空間和時間維度來提高效率的變體。我們還展示了如何利用額外的正則化和預訓練模型來應對視頻數據集不像 ViT 最初訓練的圖像數據集那樣龐大的問題。此外,我們在五個流行數據集上超越了最先進的技術。
3. 視頻 Vision Transformer
我們首先在第 3.1 節簡要介紹最近提出的 Vision Transformer [18],然后在第 3.2 節討論兩種從視頻中提取 token 的方法。最后,我們在第 3.3 和第 3.4 節中提出幾種用于視頻分類的基于 transformer 的架構。
3.1 Vision Transformer (ViT) 概述
Vision Transformer(ViT)[18] 將 [68] 中的 transformer 架構最小化修改后應用于處理二維圖像。具體而言,ViT 從圖像中提取 N N N個不重疊的圖像 patch, x i ∈ R h × w x_i \in \mathbb{R}^{h \times w} xi?∈Rh×w,對其進行線性投影后展開為一維 token z i ∈ R d z_i \in \mathbb{R}^d zi?∈Rd。輸入到后續 transformer 編碼器中的 token 序列為:
z = [ z c l s , E x 1 , E x 2 , … , E x N ] + p , (1) \mathbf{z} = [z_{cls}, \mathbf{E}x_1, \mathbf{E}x_2, \ldots, \mathbf{E}x_N] + \mathbf{p}, \tag{1} z=[zcls?,Ex1?,Ex2?,…,ExN?]+p,(1)
其中 E \mathbf{E} E表示線性投影操作,其本質等價于一個 2D 卷積。如圖 1 所示,一個可學習的分類 token z c l s z_{cls} zcls?會被加在序列開頭,并在 transformer 編碼器的最終層中作為分類器使用的最終表示 [17]。另外,為了保留位置信息,還會為 token 加上可學習的位置編碼 p ∈ R N × d \mathbf{p} \in \mathbb{R}^{N \times d} p∈RN×d,因為 transformer 中的 self-attention 機制本身對序列位置順序是不敏感的(permutation invariant)。
這些 token 隨后會被輸入到一個由 L L L層 transformer 構成的編碼器中。每一層 l l l包括多頭自注意力(Multi-Headed Self-Attention, MSA)[68]、層歸一化(Layer Normalisation, LN)[2] 和 MLP 模塊,其計算方式如下:
y ? = M S A ( L N ( z ? ) ) + z ? z ? + 1 = M L P ( L N ( y ? ) ) + y ? (3) \begin{array}{r} \mathbf{y}^{\ell} = \mathbf{MSA}(\mathbf{LN}(\mathbf{z}^{\ell})) + \mathbf{z}^{\ell} \\ \mathbf{z}^{\ell + 1} = \mathbf{MLP}(\mathbf{LN}(\mathbf{y}^{\ell})) + \mathbf{y}^{\ell} \end{array} \tag{3} y?=MSA(LN(z?))+z?z?+1=MLP(LN(y?))+y??(3)
其中 MLP 由兩個線性層和一個 GELU 非線性激活函數 [28] 構成。在整個網絡的所有層中,token 的維度 d d d保持不變。
最后,如果在輸入序列中添加了分類 token z c l s z_{cls} zcls?,則將其在第 L L L層輸出的表示 z c l s L ∈ R d z_{cls}^{L} \in \mathbb{R}^d zclsL?∈Rd輸入至一個線性分類器進行分類;如果沒有添加分類 token,則采用所有 token 的全局平均池化作為輸入。
由于 transformer 架構 [68] 是一種靈活的結構,能夠處理任意 token 序列 z ∈ R N × d \mathbf{z} \in \mathbb{R}^{N \times d} z∈RN×d,接下來我們將介紹用于視頻 token 化的策略。
3.2 視頻片段嵌入
我們考慮兩種簡單的方法將視頻 V ∈ R T × H × W × C \mathbf{V} \in \mathbb{R}^{T \times H \times W \times C} V∈RT×H×W×C映射到一個 token 序列 z ~ ∈ R n t × n h × n w × d \tilde{\mathbf{z}} \in \mathbb{R}^{n_t \times n_h \times n_w \times d} z~∈Rnt?×nh?×nw?×d。然后我們添加位置嵌入并重新形狀調整為 R N × d \mathbb{R}^{N \times d} RN×d,以得到輸入到 transformer 的 z z z。
均勻幀采樣
如圖 2 所示,將輸入視頻 token 化的一個簡單方法是從輸入視頻片段中均勻采樣 n t n_t nt?幀,使用與 ViT [18] 相同的方法獨立嵌入每一幀 2D 圖像,并將這些 token 連接在一起。具體而言,如果每一幀中提取 n h ? n w n_h \cdot n_w nh??nw?<



)
概述)
STOMP: Stochastic Trajectory Optimization for Motion Planning)
 -RGBLED控制、定時器輸入捕獲、主從定時器移相控制-STM32CubeMX)












 | IoU GIoU DIoU CIoU EIoU Focal-EIoU)