摘要:顏色在人類感知中起著重要作用,通常在視覺推理中提供關鍵線索。 然而,尚不清楚視覺語言模型(VLMs)是否以及如何像人類一樣感知、理解和利用顏色。 本文介紹了ColorBench,這是一個精心設計的創新基準,用于評估VLM在顏色理解方面的能力,包括顏色感知、推理和魯棒性。 通過策劃一系列不同的測試場景,并以實際應用為基礎,ColorBench評估了這些模型如何感知顏色,從基于顏色的線索中推斷含義,并在不同的顏色轉換下保持一致的性能。 通過對具有不同語言模型和視覺編碼器的32個VLM進行廣泛評估,我們的論文揭示了一些未被發現的發現:(i)縮放定律(更大的模型更好)在ColorBench上仍然成立,而語言模型比視覺編碼器起著更重要的作用。 (ii)然而,不同模型的性能差距相對較小,表明現有VLM在很大程度上忽視了顏色理解。 (iii)盡管是以視覺為中心的任務,但CoT推理提高了顏色理解的準確性和魯棒性。 (iv)ColorBench上的VLM確實利用了顏色線索,但在某些任務中它們也會誤導模型。 這些發現突出了當前VLMs的關鍵局限性,并強調了增強顏色理解的必要性。 我們的ColorBench可以作為推進多模態人工智能對人類水平顏色理解研究的基礎工具。Huggingface鏈接:Paper page,論文鏈接:2504.10514
研究背景和目的
研究背景
隨著視覺語言模型(Vision-Language Models, VLMs)的快速發展,它們在多種視覺和語言任務中展現出了強大的能力。然而,盡管VLMs在處理圖像和文本信息方面取得了顯著進展,它們在色彩理解方面的能力卻鮮有系統性評估。色彩作為視覺信息的重要組成部分,不僅影響人類的感知,還在多種視覺推理任務中提供關鍵線索。例如,在醫學圖像分析中,通過顏色識別病變區域;在藝術創作中,色彩的選擇和運用對表達情感和主題至關重要;在日常生活中,人們通過顏色快速識別物體和場景。
然而,現有VLMs在色彩理解上的表現尚不清晰。盡管一些研究嘗試通過替換文本輸入中的顏色相關詞匯來評估模型對顏色的處理能力,但這些方法往往局限于簡單的顏色識別任務,缺乏對色彩感知、推理和魯棒性的全面評估。此外,隨著VLMs在更多實際場景中的應用,如自動駕駛、遠程監控等,對模型色彩理解能力的需求也日益增長。
因此,迫切需要一個專門的基準測試來全面評估VLMs在色彩理解方面的能力,包括色彩感知、基于色彩的推理以及在不同色彩變換下的魯棒性。這樣的基準測試不僅有助于揭示現有VLMs在色彩理解上的局限性,還能為未來的模型設計和優化提供明確的方向。
研究目的
本文旨在通過引入ColorBench基準測試,全面評估VLMs在色彩理解方面的能力。具體研究目的包括:
-
構建全面的色彩理解基準測試:設計一套包含多種色彩相關任務的測試集,涵蓋色彩感知、推理和魯棒性三個核心維度,以全面評估VLMs的色彩理解能力。
-
揭示VLMs在色彩理解上的局限性:通過對多個VLMs在ColorBench上的廣泛評估,揭示現有模型在色彩理解方面的不足和局限性。
-
探索提升色彩理解能力的方法:基于ColorBench的評估結果,分析影響VLMs色彩理解能力的關鍵因素,并探討可能的改進方法。
-
推動VLMs在色彩理解方面的研究進展:通過提供ColorBench這一基礎工具,促進VLMs在色彩理解領域的研究進展,推動相關技術的發展和應用。
研究方法
基準測試設計
ColorBench基準測試包含11個色彩相關任務,涵蓋色彩感知、推理和魯棒性三個核心維度。每個任務都包含一系列圖像和文本問題,要求模型從提供的選項中選擇正確答案。
-
色彩感知:評估VLMs識別和解釋圖像中顏色的基本能力。包括顏色識別(識別圖像中特定對象的顏色)、顏色提取(提取圖像中單一顏色的RGB、HSV或HEX值)和對象識別(識別與文本輸入中描述顏色匹配的對象)。
-
色彩推理:評估VLMs基于色彩信息進行邏輯推理的能力。包括顏色比例(估計圖像中特定顏色所占的相對面積)、顏色比較(區分圖像中的多種顏色)、顏色計數(識別圖像中不同顏色的數量)、對象計數(計數與特定顏色模式匹配的對象)、顏色錯覺(在潛在錯覺環境中比較顏色)、顏色偽裝(檢測與周圍環境偽裝的對象)和顏色盲測試(識別嵌入在顏色模式中的數字或文本)。
-
色彩魯棒性:評估VLMs在不同色彩變換下保持性能穩定的能力。通過對圖像進行全局、目標區域或最大區域的重新著色,生成一系列顏色變換后的圖像,要求模型在這些變換后的圖像上保持一致的預測結果。
數據收集與準備
為了構建ColorBench基準測試,我們從多個在線基準和網站手動收集了圖像,并使用顏色提取工具生成了顏色統計數據。對于顏色提取、顏色盲測試和顏色錯覺等任務,我們使用代碼程序生成測試圖像以確保問題和答案的可控性。在初步數據收集后,我們進行了三輪人機交互式過濾過程,通過在不同VLM上進行推理并基于模型預測正確性、置信度和人工評估來丟棄挑戰性較低的樣本。
模型評估
我們對32個VLM進行了廣泛評估,這些模型涵蓋了不同的語言模型大小和架構,包括開源和專有模型。評估過程在標準化實驗設置下進行,以確保不同模型之間的公平比較。對于參數較少的開源模型(少于700億參數),我們使用單個NVIDIA A100 80GB GPU進行評估;對于參數較多的模型,我們使用四個GPU進行評估。
研究結果
總體性能
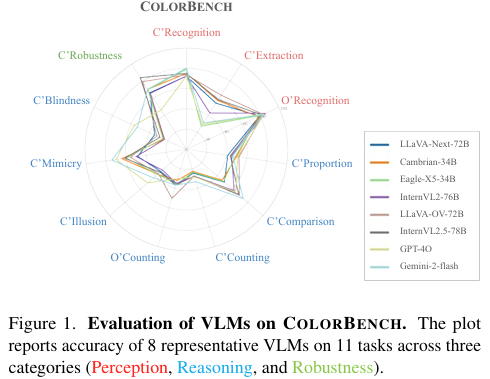
評估結果顯示,較大的模型在ColorBench上的整體表現優于較小的模型,而專有模型(如GPT-4o和Gemini-2-flash)表現最佳。然而,即使是表現最好的模型,在色彩感知和推理任務上的整體準確率也相對較低(約54%),表明現有VLMs在色彩理解方面仍存在顯著局限性。
色彩感知
在色彩感知任務中,大多數模型在顏色識別和對象識別任務上表現良好(準確率超過60%),但在顏色提取任務上表現不佳。這表明現有VLMs在直接提取顏色值方面存在困難,可能需要更多的推理步驟來得出合理答案。
色彩推理
在色彩推理任務中,模型表現差異較大。在顏色比例任務中,即使是表現最好的模型也只能達到約55%的準確率,略高于隨機猜測。在顏色比較任務中,較大模型和具有CoT提示的模型表現較好。然而,在顏色計數任務中,所有模型的表現都非常差,準確率遠低于50%。
色彩魯棒性
在色彩魯棒性任務中,只有少數幾個模型(如InternVL2.5系列的模型)超過了80%的準確率,表明大多數VLMs在不同色彩變換下保持性能穩定的能力有限。此外,我們還發現,即使只改變圖像的顏色而保持問題不變,增加推理步驟也能顯著提高模型的魯棒性。
其他發現
- 縮放定律:盡管在ColorBench上縮放定律(更大的模型更好)仍然成立,但語言模型部分比視覺編碼器部分起著更重要的作用。
- 顏色線索的利用:VLMs在大多數ColorBench任務中確實利用了顏色線索,但在顏色錯覺和偽裝任務中,顏色線索可能會誤導模型。
- CoT推理的影響:盡管CoT推理在某些任務中提高了模型的準確性和魯棒性,但在顏色錯覺任務中卻降低了模型性能。
研究局限
盡管ColorBench基準測試在評估VLMs的色彩理解能力方面取得了顯著進展,但仍存在一些局限性:
-
任務多樣性:盡管ColorBench包含了多種色彩相關任務,但可能仍未涵蓋所有可能的色彩理解場景。未來的研究可以進一步擴展任務范圍,以更全面地評估VLMs的色彩理解能力。
-
模型多樣性:盡管我們評估了多個VLMs,但可能仍未涵蓋所有現有的模型架構和變體。未來的研究可以進一步增加評估的模型數量,以更全面地了解不同模型在色彩理解方面的表現。
-
數據局限性:盡管我們努力收集多樣化的圖像數據,但某些任務的數據量可能仍然有限。未來的研究可以進一步增加數據量,以提高評估結果的可靠性和泛化能力。
-
評估指標:目前我們主要使用準確率作為評估指標,這可能無法全面反映模型在色彩理解方面的表現。未來的研究可以探索更多的評估指標,以更全面地評估模型的性能。
未來研究方向
基于ColorBench基準測試的結果和局限性,未來研究可以從以下幾個方面展開:
-
提升色彩理解能力:針對ColorBench中表現較差的任務(如顏色提取和顏色計數),探索新的模型架構和訓練方法,以提升VLMs的色彩理解能力。
-
增強色彩魯棒性:研究如何使VLMs在不同色彩變換下保持性能穩定,以提高模型在實際應用中的可靠性和魯棒性。
-
拓展任務范圍:進一步擴展ColorBench的任務范圍,涵蓋更多色彩相關的實際應用場景,以更全面地評估VLMs的色彩理解能力。
-
多模態融合:探索如何將視覺信息和語言信息更有效地融合在一起,以提升VLMs在色彩理解方面的表現。這可能涉及新的模型架構、注意力機制或訓練方法。
-
評估指標優化:研究更全面的評估指標和方法,以更準確地反映VLMs在色彩理解方面的表現。這可能包括考慮模型的響應時間、內存占用、可解釋性等因素。
綜上所述,ColorBench基準測試為評估VLMs的色彩理解能力提供了一個有價值的工具。未來的研究可以基于這一基準測試展開更深入的探索和創新,以推動VLMs在色彩理解領域的發展和應用。



)


)

)


:標準庫代碼示例)
與VGG16在圖像識別中的實驗設計與思路)

)
)

—— 打造直覺化交互體驗)

