實現新聞文本摘要的提取
- 1. 概述與背景
- 2.參數配置
- 3.數據準備
- 4.數據加載
- 5.主程序
- 6.預測評估
- 7.生成效果
- 8.總結
1. 概述與背景
新聞摘要生成是自然語言處理(NLP)中的一個重要任務,其目標是自動從長篇的新聞文章中提取出簡潔、準確的摘要。近年來,基于深度學習的摘要生成方法已成為主流,尤其是采用 Encoder-Decoder 架構的模型。這個架構在機器翻譯、文本摘要、文檔標注、多模態交互等領域取得了顯著的效果。
本文基于現有數據集,先將輸入的新聞文本數據和對應的標題摘要在已知詞表上序列化,然后將序列化后的輸入索引數據(作為輸入文本數據)和標簽索引數據(作為生成式文本摘要標簽)共同輸入到Encoder-Decoder模型架構中得到輸出預測的文本摘要數據,之后將輸出的預測文本摘要數據以及另一份標簽索引數據(作為真實的文本標簽)兩者使用交叉熵損失函數計算loss,最后反向傳播更新梯度。
2.參數配置
config.py
# -*- coding: utf-8 -*-"""
配置參數信息
"""
import os
import torchConfig = {"model_path": "output","input_max_length": 120,"output_max_length": 30,"epoch": 200,"batch_size": 32,"optimizer": "adam","learning_rate":1e-3,"seed":42,"vocab_size":6219,"vocab_path":"vocab.txt","train_data_path": r"sample_data.json","valid_data_path": r"sample_data.json","beam_size":5}3.數據準備
詞表文件vocab.txt詞表文件
新聞文本數據訓練和驗證數據
4.數據加載
loader.py
# -*- coding: utf-8 -*-import json
import torch
from torch.utils.data import DataLoader
"""
數據加載
"""class DataGenerator:def __init__(self, data_path, config, logger):self.config = configself.logger = loggerself.path = data_pathself.vocab = load_vocab(config["vocab_path"])self.config["vocab_size"] = len(self.vocab)self.config["pad_idx"] = self.vocab["[PAD]"]self.config["start_idx"] = self.vocab["[CLS]"]self.config["end_idx"] = self.vocab["[SEP]"]self.load()def load(self):self.data = []with open(self.path, encoding="utf8") as f:for i, line in enumerate(f):line = json.loads(line)title = line["title"]content = line["content"]self.prepare_data(title, content)return#文本到對應的index#頭尾分別加入[cls]和[sep]def encode_sentence(self, text, max_length, with_cls_token=True, with_sep_token=True):input_id = []if with_cls_token:input_id.append(self.vocab["[CLS]"])for char in text:input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))if with_sep_token:input_id.append(self.vocab["[SEP]"])input_id = self.padding(input_id, max_length)return input_id#補齊或截斷輸入的序列,使其可以在一個batch內運算def padding(self, input_id, length):input_id = input_id[:length]input_id += [self.vocab["[PAD]"]] * (length - len(input_id))return input_id#輸入輸出轉化成序列def prepare_data(self, title, content):input_seq = self.encode_sentence(content, self.config["input_max_length"], False, False) #輸入序列output_seq = self.encode_sentence(title, self.config["output_max_length"], True, False) #輸出序列gold = self.encode_sentence(title, self.config["output_max_length"], False, True) #不進入模型,用于計算lossself.data.append([torch.LongTensor(input_seq),torch.LongTensor(output_seq),torch.LongTensor(gold)])returndef __len__(self):return len(self.data)def __getitem__(self, index):return self.data[index]def load_vocab(vocab_path):token_dict = {}with open(vocab_path, encoding="utf8") as f:for index, line in enumerate(f):token = line.strip()token_dict[token] = indexreturn token_dict#用torch自帶的DataLoader類封裝數據
def load_data(data_path, config, logger, shuffle=True):dg = DataGenerator(data_path, config, logger)dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)return dl
輸入數據和標簽的編碼主要通過 encode_sentence 方法實現。具體來說,輸入數據(如新聞內容)和標簽(如新聞標題)都需要轉化為對應的索引序列,以便供模型進行訓練。編碼過程如下:
-
輸入數據(
content)編碼:encode_sentence方法將新聞內容轉換為詞匯表中的索引序列。首先,如果需要,添加[CLS]標記作為序列的開始,然后遍歷文本中的每個字符,將其映射為詞匯表中的索引,如果詞匯表中沒有該字符,則使用[UNK](未知詞)表示。最后,如果需要,添加[SEP]標記作為序列的結束。生成的索引序列會通過padding方法填充或截斷至預設的最大長度。 -
標簽數據(
title)編碼:標簽(即標題)也會通過encode_sentence方法進行編碼,步驟與輸入數據類似,因為標題是需要預測生成表示要輸出的序列,因此會包含[CLS]標記作為開頭,不包含[SEP],以區分輸入和輸出。 -
計算損失的
gold序列:在訓練中,為了計算損失,gold序列會與輸出序列相似,作為真實的標簽,在它后面包含[SEP]標記和輸出序列對齊,作為模型訓練時的目標序列。 -
生成解碼過程:模型訓練完畢后,
Decoder會根據輸入的Encoder編碼向量及輸出序列的第一個標記CLS輸出第一個預測的token,根據輸入的Encoder編碼向量及輸出序列(第一個標記CLS+生成的前一個token)輸出第二個預測token,之后再根據輸入的Encoder編碼向量及輸出序列(第一個標記CLS+生成的前2個token)輸出第三個預測token,以此類推。直到輸出最后一個預測的token為SEP時,生成解碼過程結束。 -
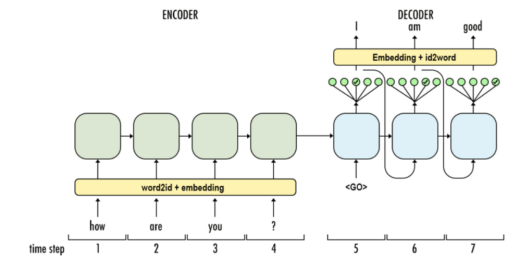
通過這樣的編碼方式,輸入數據和標簽數據被轉化為整數索引序列,并進行填充或截斷,以確保它們具有相同的長度,從而可以批量處理并輸入到模型進行訓練。
5.主程序
# -*- coding: utf-8 -*-
import sys
import torch
import random
import os
import numpy as np
import time
import logging
import json
from config import Config
from evaluate import Evaluator
from loader import load_data#這個transformer是本文件夾下的代碼,和我們之前用來調用bert的transformers第三方庫是兩回事
from transformer.Models import Transformerlogging.basicConfig(level = logging.INFO,format = '%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)"""
模型訓練主程序
"""# seed = Config["seed"]
# random.seed(seed)
# np.random.seed(seed)
# torch.manual_seed(seed)
# torch.cuda.manual_seed_all(seed)def choose_optimizer(config, model):optimizer = config["optimizer"]learning_rate = config["learning_rate"]if optimizer == "adam":return torch.optim.Adam(model.parameters(), lr=learning_rate)elif optimizer == "sgd":return torch.optim.SGD(model.parameters(), lr=learning_rate)def main(config):#創建保存模型的目錄if not os.path.isdir(config["model_path"]):os.mkdir(config["model_path"])#加載模型logger.info(json.dumps(config, ensure_ascii=False, indent=2))model = Transformer(config["vocab_size"], config["vocab_size"], 0, 0,d_word_vec=128, d_model=128, d_inner=256,n_layers=1, n_head=2, d_k=64, d_v=64,)# 標識是否使用gpucuda_flag = torch.cuda.is_available()if cuda_flag:logger.info("gpu可以使用,遷移模型至gpu")model = model.cuda()#加載優化器optimizer = choose_optimizer(config, model)# 加載訓練數據train_data = load_data(config["train_data_path"], config, logger)#加載效果測試類evaluator = Evaluator(config, model, logger)#加載lossloss_func = torch.nn.CrossEntropyLoss(ignore_index=0)#訓練for epoch in range(config["epoch"]):epoch += 1model.train()if cuda_flag:model.cuda()logger.info("epoch %d begin" % epoch)train_loss = []for index, batch_data in enumerate(train_data):if cuda_flag:batch_data = [d.cuda() for d in batch_data]input_seq, target_seq, gold = batch_datapred = model(input_seq, target_seq)loss = loss_func(pred, gold.view(-1))train_loss.append(float(loss))loss.backward()optimizer.step()optimizer.zero_grad()logger.info("epoch average loss: %f" % np.mean(train_loss))evaluator.eval(epoch)model_path = os.path.join(config["model_path"], "epoch_%d.pth" % epoch)torch.save(model.state_dict(), model_path)returnif __name__ == "__main__":main(Config)
主程序主要實現了基于Transformer架構的模型訓練過程。在訓練過程中,首先通過配置文件Config獲取相關參數,并根據配置創建一個Transformer模型。訓練過程在指定的輪次(epoch)內進行,每一輪開始時,首先設定模型為訓練模式。接著,對于每個訓練批次,輸入數據(input_seq)、目標序列(target_seq)和真實標簽(gold)被送入模型中進行前向傳播,計算出模型預測值(pred)。通過交叉熵損失函數(CrossEntropyLoss)與真實標簽進行對比,得到當前批次的損失。損失值會被累積并進行反向傳播(loss.backward()),優化器更新參數(optimizer.step()),并清空梯度緩存(optimizer.zero_grad())。每一輪訓練結束后,打印出平均損失值并進行模型效果評估。
6.預測評估
evaluate.py
# -*- coding: utf-8 -*-
from loader import load_data
from collections import defaultdict
from transformer.Translator import Translator"""
模型效果測試
"""class Evaluator:def __init__(self, config, model, logger):self.config = configself.model = modelself.logger = loggerself.valid_data = load_data(config["valid_data_path"], config, logger, shuffle=False)self.reverse_vocab = dict([(y, x) for x, y in self.valid_data.dataset.vocab.items()])self.translator = Translator(self.model,config["beam_size"],config["output_max_length"],config["pad_idx"],config["pad_idx"],config["start_idx"],config["end_idx"])def eval(self, epoch):self.logger.info("開始測試第%d輪模型效果:" % epoch)self.model.eval()self.model.cpu()self.stats_dict = defaultdict(int) # 用于存儲測試結果for index, batch_data in enumerate(self.valid_data):input_seqs, target_seqs, gold = batch_datafor input_seq in input_seqs:generate = self.translator.translate_sentence(input_seq.unsqueeze(0))print("輸入:", self.decode_seq(input_seq))print("輸出:", self.decode_seq(generate))breakreturndef decode_seq(self, seq):pre_seq = []for idx in seq:if idx < 6 :continuechar = self.reverse_vocab[int(idx)]pre_seq.append(char)return "".join(pre_seq)在模型的評估過程中,驗證集數據被加載并逐批傳入模型進行推理。每一批數據中的輸入序列通過 Translator 進行翻譯,生成相應的預測輸出。預測過程通常涉及使用模型的前向傳播,將輸入序列轉化為目標語言的輸出。為了評估模型效果,生成的輸出是通過索引序列的方式進行表示,而這些索引隨后會被映射回具體的詞匯,通過反向詞匯表解碼為可讀的文本。每次翻譯后,模型的輸入和生成的輸出都會被打印出來,以便進行直觀的對比。通過反復的測試與評估,能夠逐步提高模型的準確性和生成質量。
7.生成效果
訓練200輪效果:
2025-04-19 12:44:56,206 - __main__ - INFO - epoch 200 begin
2025-04-19 12:44:57,086 - __main__ - INFO - epoch average loss: 0.416101
2025-04-19 12:44:57,086 - __main__ - INFO - 開始測試第200輪模型效果:
輸入: 阿根廷布宜諾斯艾利斯省奇爾梅斯市一服裝店,8個月內被搶了三次。最后被搶劫的經歷,更是直接讓老板心理崩潰:歹徒在搶完不久后發現衣服“搶錯了尺碼”,理直氣壯地拿著衣服到店里換,老板又不敢聲張,只好忍氣吞聲。(中國新聞網)
輸出: 阿根廷歹徒搶服裝尺碼不對拿回店里換
輸入: 就俄羅斯免費醫療話題,國家衛生計生委國際司司長任明輝表示,真正的免費醫療制度不存在。或由稅收支持,或個人和企業支付的醫療保險社會保險解決。免費醫療國家的患者看病不花錢,費用在各種稅收或繳納的保險中體現了。(網圖)
輸出: 衛生計生委國際司司長:真正的免費醫療不存在
輸入: 6月合格境外機構投資者(QFII)加快入市步伐。據中登公司發布的2013年6月份統計月報顯示,QFII基金6月份在滬深兩市分別新增開戶14、15個A股股票賬戶,這29個賬戶讓QFII在滬深兩市的總賬戶數達到465個。
輸出: 6月QFII積極入市新增開戶戶9戶
輸入: 路透社消息,一艘從利比亞橫渡地中海開往意大利的偷渡船傾覆,約400人身亡。船上載有550多名偷渡客,許多是年輕人和兒童,大部分來自撒哈拉以南非洲地區。事發后意大利海防部隊展開搜救,獲救的150人被送往意大利南部港口。
輸出: 從利比亞開往意大利:400偷渡客沉船身亡
8.總結
本文實現了一個基于 Transformer Encoder-Decoder 架構的新聞摘要生成系統。通過使用詞匯表將輸入數據和目標輸出數據轉化為索引序列,并通過交叉熵損失函數訓練模型,模型通過 Beam Search 解碼生成摘要。訓練過程中使用了多輪的模型評估和優化,使得最終模型能夠生成簡潔、準確的新聞摘要。
)


:標準庫代碼示例)
與VGG16在圖像識別中的實驗設計與思路)

)
)

—— 打造直覺化交互體驗)


)



含運行文檔)
)
)
