項目源碼地址:https://github.com/ImagineAILab/ai-by-hand-excel.git
一、RNN
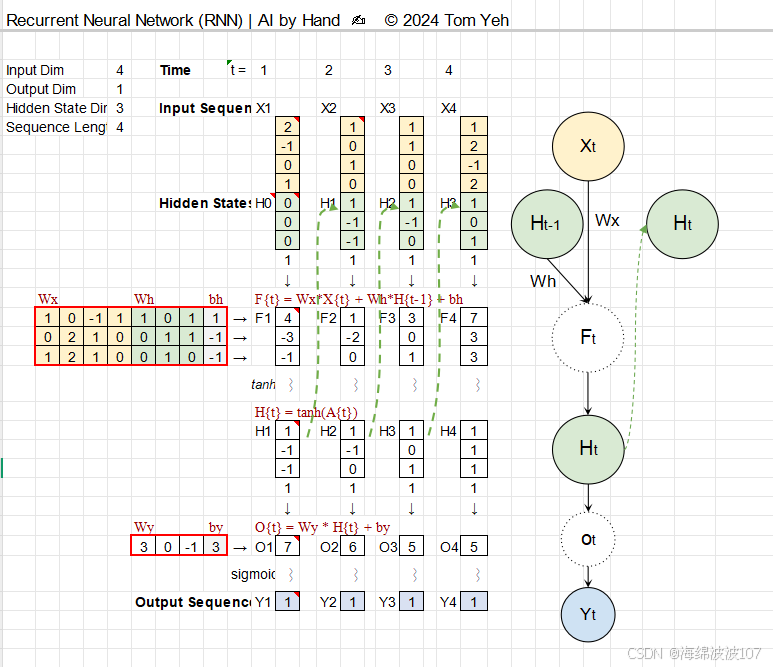
1.?RNN 的核心思想
RNN 的設計初衷是處理序列數據(如時間序列、文本、語音),其核心特點是:
-
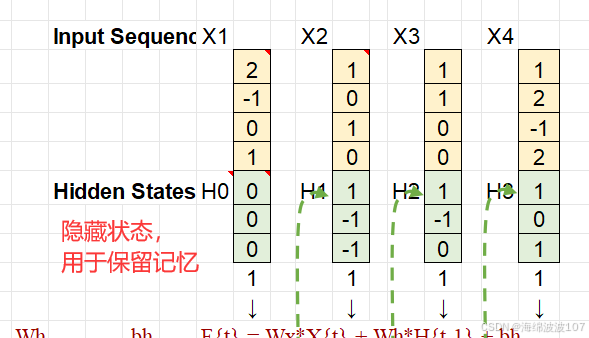
隱藏狀態(Hidden State):保留歷史信息,充當“記憶”。
-
參數共享:同一組權重在時間步間重復使用,減少參數量。
2.?RNN 的數學表達
對于一個時間步?t:
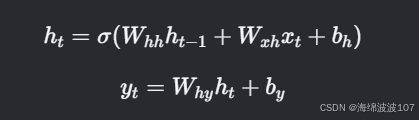
-
輸入:xt?(當前時間步的輸入向量)。
-
隱藏狀態:ht?(當前狀態),ht?1?(上一狀態)。
-
輸出:yt?(預測或特征表示)。
-
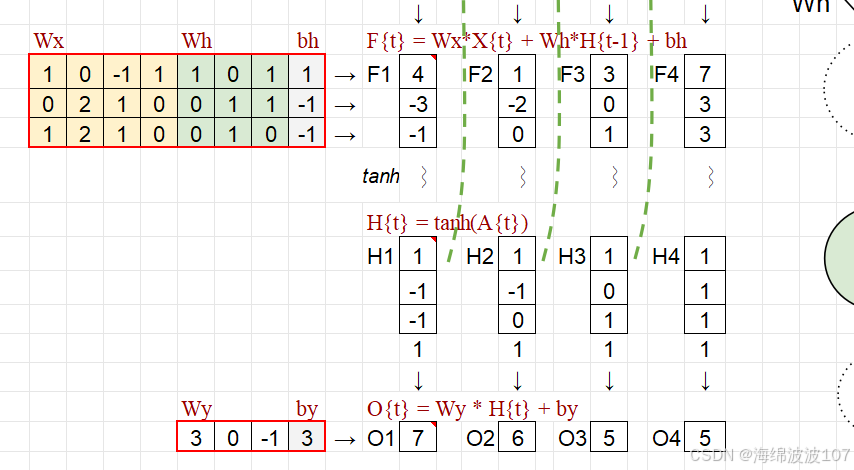
參數:權重矩陣?和偏置 ?。
-
激活函數:σ(通常為?
tanh?或?ReLU)。
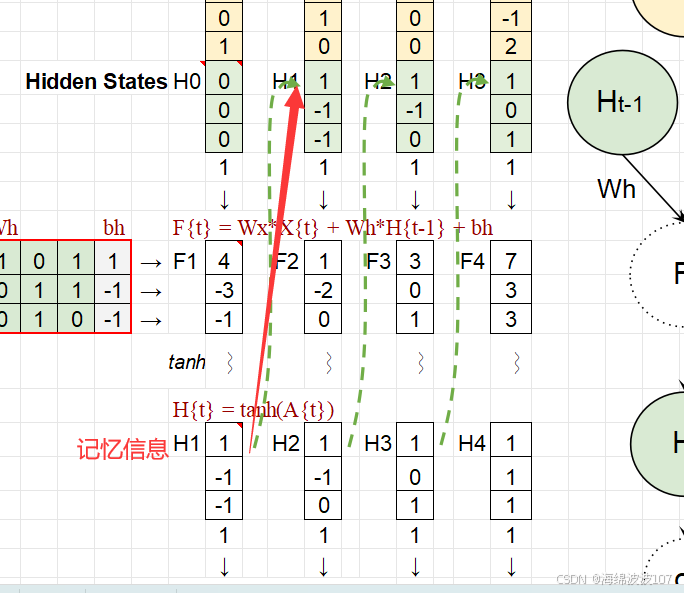
更新隱藏狀態的核心操作
數學本質:非線性變換
-
At??是當前時間步的“未激活狀態”,即隱藏狀態的線性變換結果(上一狀態?ht?1??和當前輸入?xt??的加權和)。
-
?tanh?是雙曲正切激活函數,將?At??映射到?[-1, 1]?的范圍內:
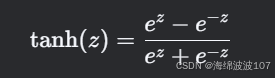
-
作用:引入非線性,使RNN能夠學習復雜的序列模式。如果沒有非線性,堆疊的RNN層會退化為單層線性變換。
梯度穩定性
-
tanh?tanh?的導數為:

-
梯度值始終小于等于1,能緩解梯度爆炸(但可能加劇梯度消失)。
-
相比Sigmoid(導數最大0.25),tanh?tanh?的梯度更大,訓練更穩定。
3.?RNN 的工作流程
前向傳播
-
初始化隱藏狀態??0h0?(通常為零向量)。
-
按時間步迭代計算:
-
結合當前輸入?xt??和上一狀態?ht?1??更新狀態?ht?。
-
根據ht??生成輸出?yt?。
-
反向傳播(BPTT)
通過時間反向傳播(Backpropagation Through Time, BPTT)計算梯度:
-
沿時間軸展開RNN,類似多層前饋網絡。
-
梯度需跨時間步傳遞,易導致梯度消失/爆炸。
4.?RNN 的典型結構
(1) 單向RNN(Vanilla RNN)
-
信息單向流動(過去→未來)。
-
只能捕捉左側上下文。
(2) 雙向RNN(Bi-RNN)
-
兩個獨立的RNN分別從左到右和從右到左處理序列。
-
最終輸出拼接或求和,捕捉雙向依賴。
(3) 深度RNN(Stacked RNN)
-
多個RNN層堆疊,高層處理低層的輸出序列。
-
增強模型表達能力。
5.?RNN 的局限性
(1) 梯度消失/爆炸
-
長序列中,梯度連乘導致指數級衰減或增長。
-
后果:難以學習長期依賴(如文本中相距很遠的詞關系)。
(2) 記憶容量有限
-
隱藏狀態維度固定,可能丟失早期信息。
(3) 計算效率低
-
無法并行處理序列(必須逐時間步計算)。
6.?RNN 的代碼實現(PyTorch)
import torch.nn as nnclass VanillaRNN(nn.Module):def __init__(self, input_size, hidden_size, output_size):super().__init__()self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):# x: [batch_size, seq_len, input_size]out, h_n = self.rnn(x) # out: 所有時間步的輸出y = self.fc(out[:, -1, :]) # 取最后一個時間步return y7.?RNN vs. 其他序列模型
| 特性 | RNN/LSTM | Transformer | Mamba |
|---|---|---|---|
| 長序列處理 | 中等(依賴門控) | 差(O(N2)) | 優(O(N)) |
| 并行化 | 不可并行 | 完全并行 | 部分并行 |
| 記憶機制 | 隱藏狀態 | 全局注意力 | 選擇性狀態 |
8.?RNN 的應用場景
-
文本生成:字符級或詞級預測。
-
時間序列預測:股票價格、天氣數據。
-
語音識別:音頻幀序列轉文本。
二、mamba
1.?Mamba 的誕生背景
Mamba(2023年由Albert Gu等人提出)是為了解決傳統序列模型(如RNN、Transformer)的兩大痛點:
-
長序列效率問題:Transformer的Self-Attention計算復雜度為?O(N2),難以處理超長序列(如DNA、音頻)。
-
狀態壓縮的局限性:RNN(如LSTM)雖能線性復雜度?O(N),但隱藏狀態難以有效捕捉長期依賴。
Mamba的核心創新:選擇性狀態空間模型(Selective SSM),結合了RNN的效率和Transformer的表達力。
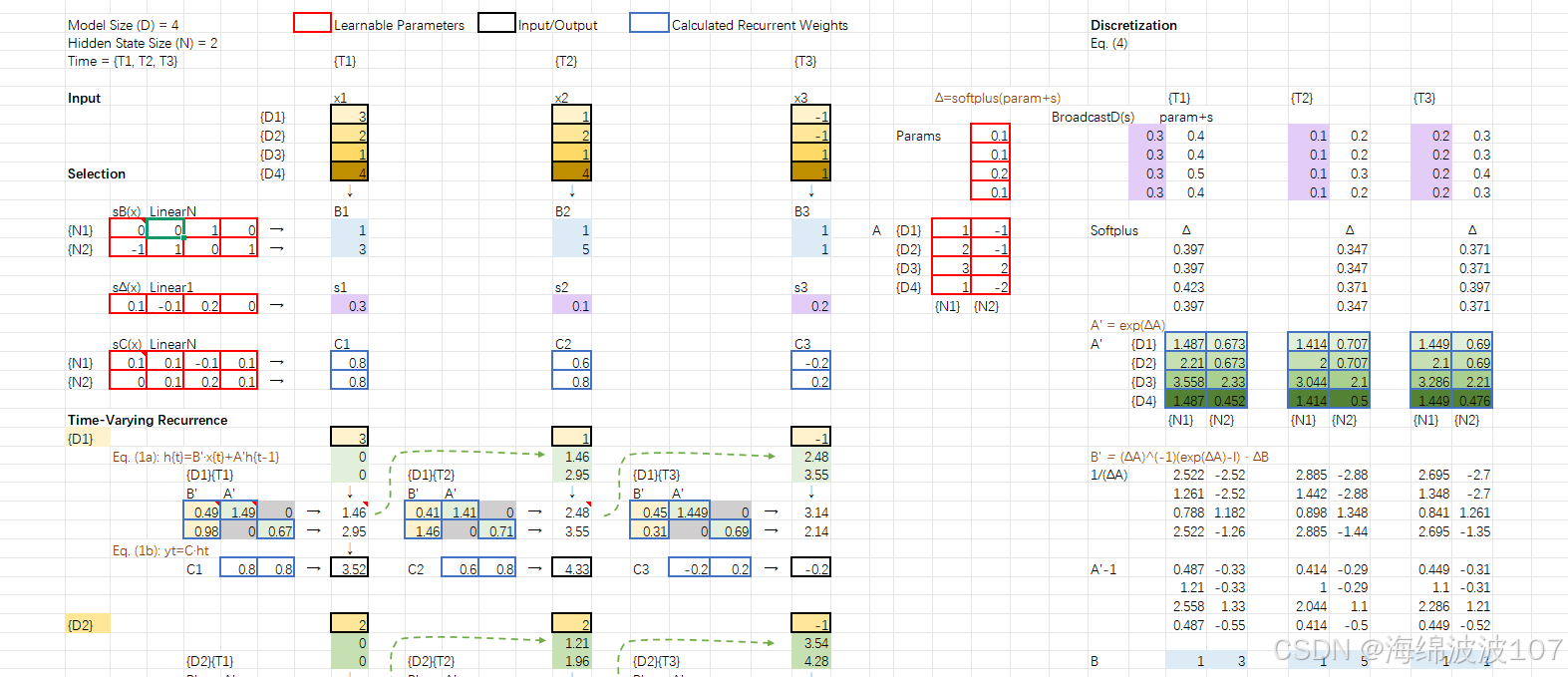
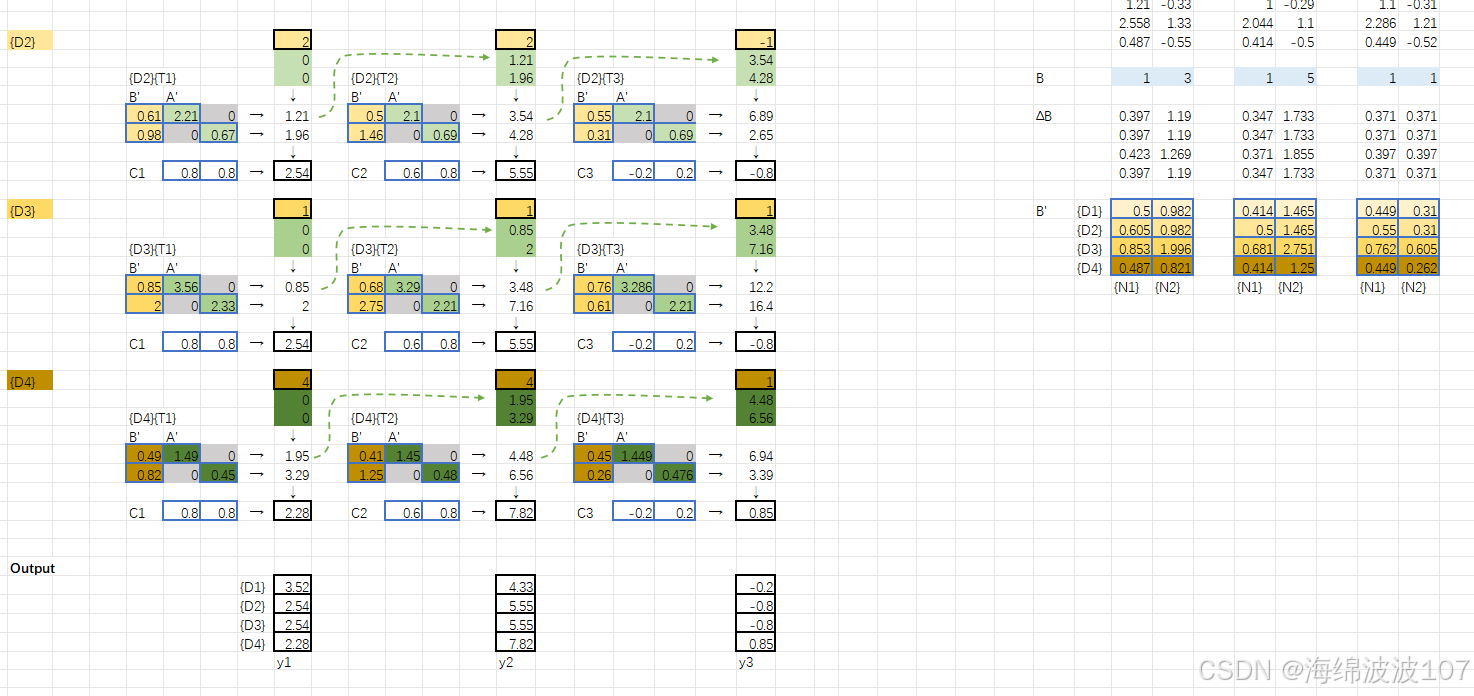
2.?狀態空間模型(SSM)基礎
Mamba基于結構化狀態空間序列模型(S4),其核心是線性時不變(LTI)系統:
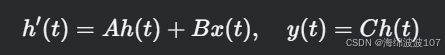
-
h(t):隱藏狀態
-
A(狀態矩陣)、B(輸入矩陣)、C(輸出矩陣)
-
離散化(通過零階保持法):
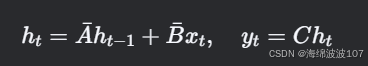
其中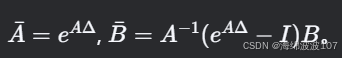
關鍵特性:
-
線性復雜度?O(N)(類似RNN)。
-
理論上能建模無限長依賴(通過HiPPO初始化?A)。
3.?Mamba 的核心改進:選擇性(Selectivity)
傳統SSM的局限性:A,B,C?與輸入無關,導致靜態建模能力。
Mamba的解決方案:讓參數動態依賴于輸入(Input-dependent),實現“選擇性關注”重要信息。
選擇性SSM的改動:
-
動態參數化:
-
B,?C,?ΔΔ?由輸入xt??通過線性投影生成:
-
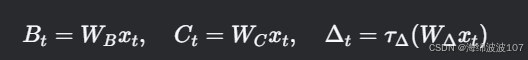
- 這使得模型能過濾無關信息(如文本中的停用詞)。
-
硬件優化:
-
選擇性導致無法卷積化(傳統SSM的優勢),但Mamba設計了一種并行掃描算法,在GPU上高效計算。
-
4.?Mamba 的架構設計
Mamba模型由多層?Mamba Block?堆疊而成,每個Block包含:
-
選擇性SSM層:處理序列并捕獲長期依賴。
-
門控MLP(如GeLU):增強非線性。
-
殘差連接:穩定深層訓練。
(示意圖:輸入 → 選擇性SSM → 門控MLP → 輸出)
Time-Varying Recurrence(時變遞歸)

作用
打破傳統SSM的時不變性(Time-Invariance),使狀態轉移動態適應輸入序列。
-
傳統SSM的離散化參數?Aˉ,Bˉ?對所有時間步相同(LTI系統)。
-
Mamba的遞歸過程是時變的(LTV系統),狀態更新依賴當前輸入。
實現方式
-
離散化后的參數?Aˉt?,Bˉt??由?Δt??動態控制:
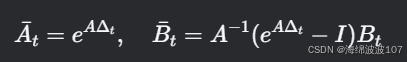
-
-
Δt??大:狀態更新慢(保留長期記憶)。
-
Δt??小:狀態更新快(捕捉局部特征)。
-
-
效果:模型可以靈活調整記憶周期(例如,在文本中保留重要名詞,快速跳過介詞)。
關鍵點
-
時變性是選擇性的直接結果,因為?Δt?,Bt?,Ct??均依賴輸入。
Discretization(離散化)
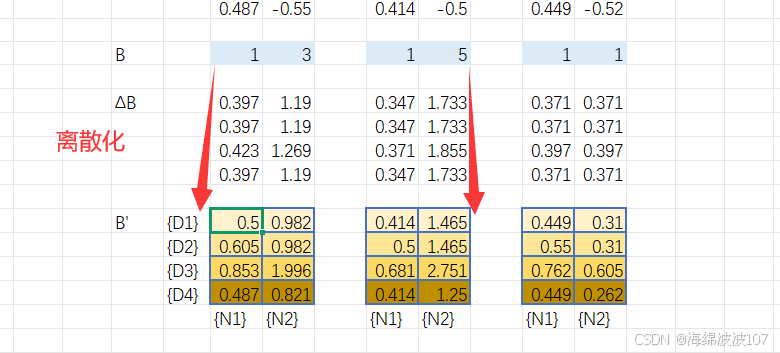
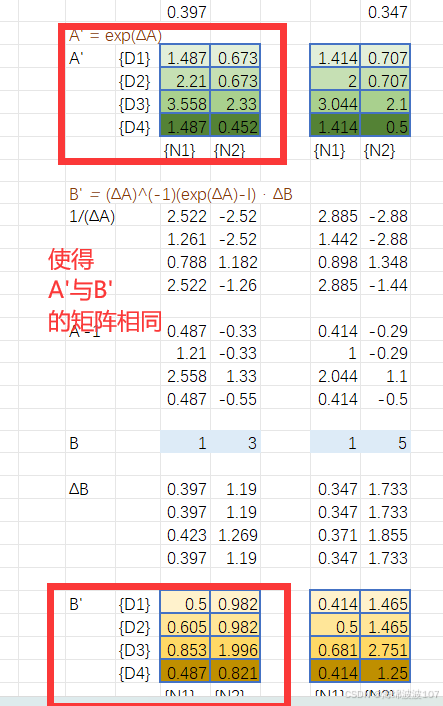
作用
將連續時間的狀態空間方程(微分方程)轉換為離散時間形式,便于計算機處理。
-
連續SSM:
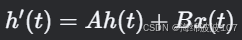
-
離散SSM:

實現方式
-
使用零階保持法(ZOH)離散化:
總結
-
Selection:賦予模型動態過濾能力,是Mamba的核心創新。
-
Time-Varying Recurrence:通過時變遞歸實現自適應記憶。
-
Discretization:將連續理論落地為可計算的離散操作。
5.?為什么Mamba比Transformer更高效?
| 特性 | Transformer | Mamba |
|---|---|---|
| 計算復雜度 | O(N2) | O(N) |
| 長序列支持 | 內存受限 | 輕松處理百萬長度 |
| 并行化 | 完全并行 | 需自定義并行掃描 |
| 動態注意力 | 顯式Self-Attention | 隱式通過選擇性SSM |
優勢場景:
-
超長序列(基因組、音頻、視頻)
-
資源受限設備(邊緣計算)
6.?代碼實現片段(PyTorch風格)
class MambaBlock(nn.Module):def __init__(self, dim):self.ssm = SelectiveSSM(dim) # 選擇性SSMself.mlp = nn.Sequential(nn.Linear(dim, dim*2),nn.GELU(),nn.Linear(dim*2, dim)def forward(self, x):y = self.ssm(x) + x # 殘差連接y = self.mlp(y) + y # 門控MLPreturn y7.?Mamba的局限性
-
訓練穩定性:選擇性SSM需要謹慎的參數初始化。
-
短序列表現:可能不如Transformer在短文本上的注意力精準。
-
生態支持:目前庫(如
mamba-ssm)不如Transformer成熟。


】解鎖家政平臺上線密碼:服務器選型與配置全攻略)
:設備模型 ≈ 運行時的適配器機制)




boot文件夾內容)
—— 最佳實踐之性能)







)

