個人學習筆記,如有錯誤歡迎指正,也歡迎交流,其他筆記見個人空間??
強化學習 vs 監督學習
-
監督學習(Supervised Learning):你有輸入和明確的輸出標簽,例如圖像分類。
-
強化學習(Reinforcement Learning):你不知道輸出的“最佳答案”,只能通過與環境互動、收集獎勵(Reward)來學習策略。
舉例:
-
圍棋:每一步的“最優落子”可能連人類都不知道
-
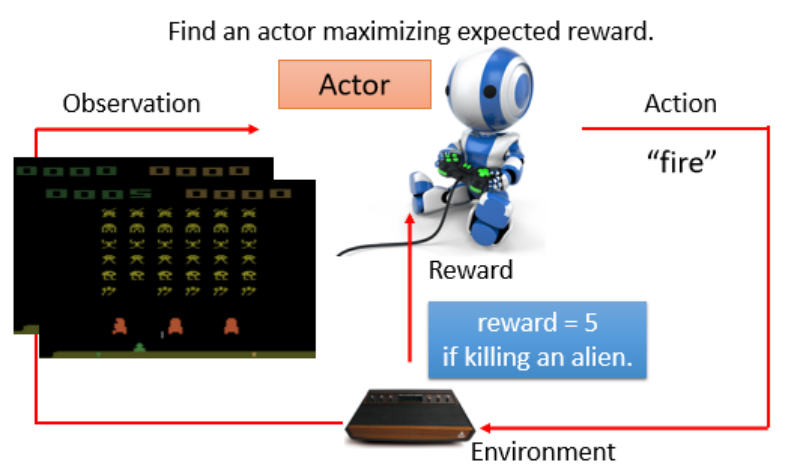
電子游戲:通過游戲畫面(Observation)作出動作(Action),根據得分獲得獎勵
強化學習的核心結構
環境(Environment)與智能體(Actor):
-
Observation:環境給智能體的輸入
-
Action:智能體輸出的行為
-
Reward:環境給予智能體的反饋
智能體的目標:最大化總獎勵(Total Reward)
?強化學習的核心步驟和深度學習其實基本一樣
Step 1:定義一個有未知參數的Function(通常稱為Policy Network)
Step 2:定義Loss(負的Total Reward)
Step 3:優化參數以最大化Reward(Optimization)
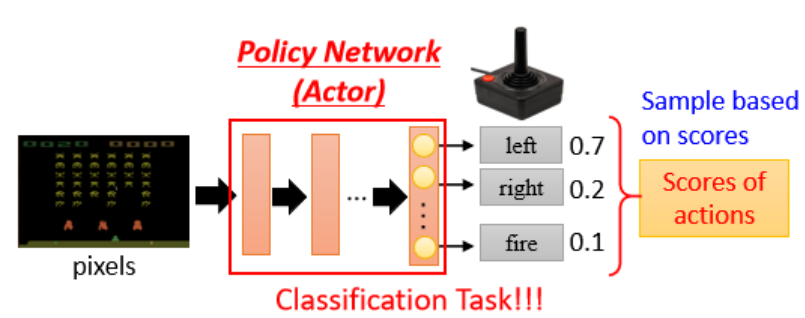
第一步:?定義一個有未知參數的函數,也就是策略函數(Policy),通常用神經網絡來表示。
希望找到一個策略函數 (policy):
-
輸入:當前環境的觀測(observation)
-
輸出:某個動作(action)或一組動作的概率
這個函數內部有很多未知參數(θ),通過訓練來確定這些參數,從而讓策略越來越聰明。例如用CNN處理圖像輸入,用MLP處理數值輸入,RNN / Transformer處理歷史軌跡,生成不同action的概率后,通常根據這個分布 進行采樣(sampling) 來選擇動作,而不是直接選擇最大值(argmax),這是為了增加策略的探索性
第二步:?定義Loss
在強化學習中,我們沒有 Ground Truth 標簽,但依然需要定義一個目標 ——即使不能說“動作a對還是錯”,但我們知道做完這個動作之后是否有獎勵(Reward)。
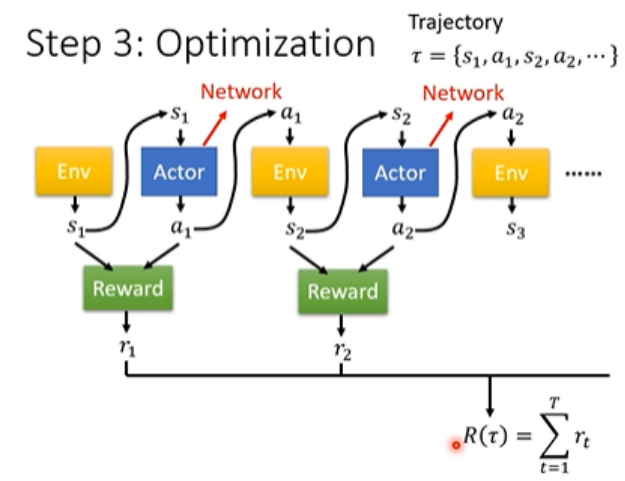
與環境交互(Episode):
-
一個智能體從初始狀態開始,連續做出動作(Action)
-
每個動作會得到一個即時獎勵(Reward),如 r1,r2,...,rT
-
所有獎勵累加得到:R=r1?+r2?+?+rT?這個 R 又被稱為 Return 或 Total Reward
目標(Objective):
-
我們希望找到策略參數 θ,使得這個總獎勵 R越大越好
轉換為損失函數:
-
強化學習中不像監督學習有明確的 Loss
-
所以我們把“最大化獎勵”變成“最小化負的獎勵”:Loss=?R
第三步:優化參數?
問題是則不是一個一般的優化問題,難點:
1、Actor輸出是隨機采樣的?
2、Environment是不可導黑盒子,不能反向傳播
3、Reward是延遲的,無法直接分配“哪個動作貢獻了多少”
Policy Gradient
一種解決RL優化問題的經典方法,核心思想如下:
-
把Actor當作一個分類器
-
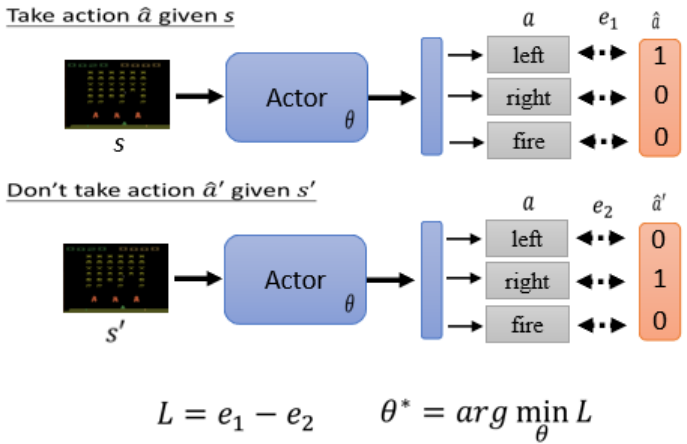
用類似Cross-entropy的Loss定義行為偏好(a和
的交叉熵作為loss,希望采取
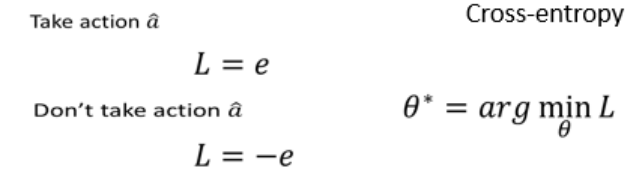
?????????如下希望看到 s 時采取,看到 s' 時不采取?
‘,則L=e1-e2。
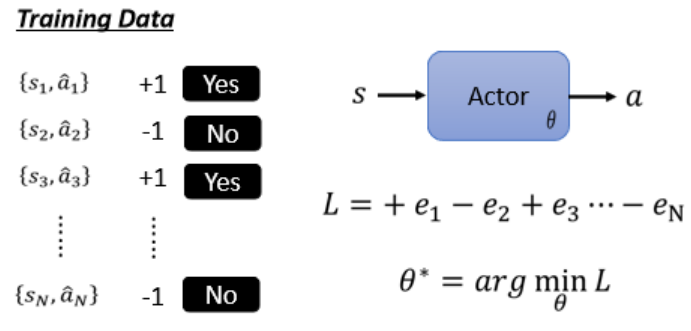
?????????????????????????????????????????????????????????(需要收集大量s,a的一對一對的數據)
-
設定希望Actor采取or避免的行為,并賦予不同權重(An),代表采取/避免某行動的“意愿”有多強。
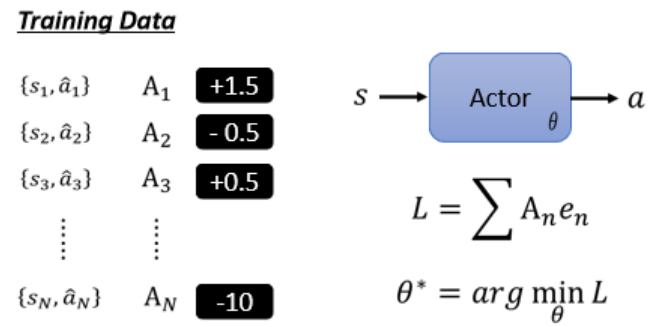
-
再用梯度下降去優化Actor網絡參數,使行為更符合期望
現在的問題在于怎么定義a的好壞
初級的思路就是直接用當前時間步的 Reward來評估當前 Action?的好壞,如果r>0就認為 Action 是好的,問題是忽視了當前動作對未來的長期影響,導致“短視近利”的策略
由此產生第二個版本的想法:a有多好取決于a之后收到的所有Reward,通通加起來得到一個累計獎勵G(Total Future Reward)。
優點:考慮到動作的長期影響
問題:游戲太長時,早期動作對后期獎勵影響不明顯,不一定是這一步的動作導致后面好的結果,導致歸因失真
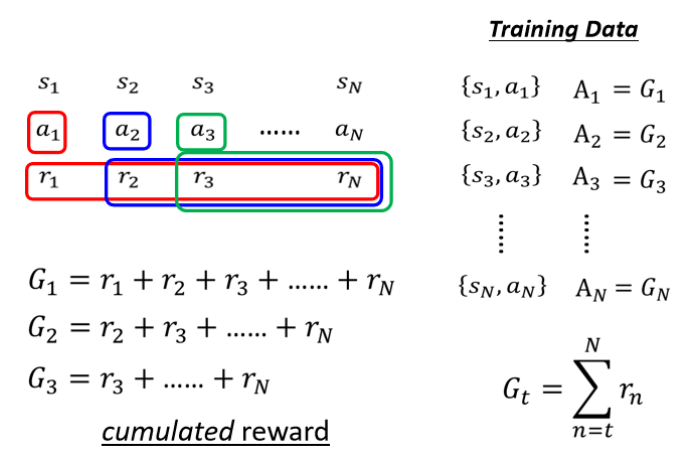
?由此產生第三個版本的想法:引入折扣因子(Discount Factor)
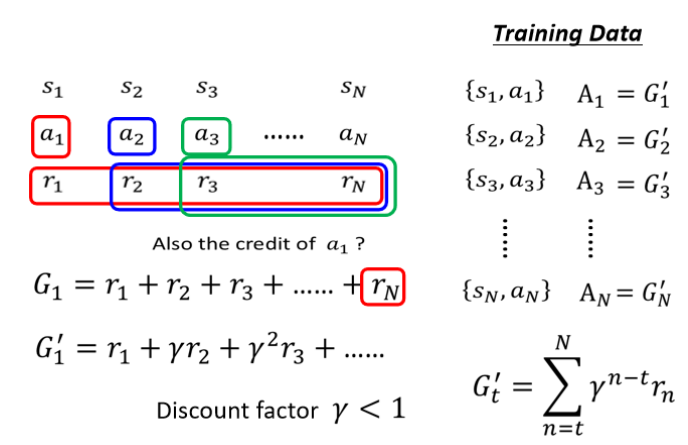
距離 at 越遠的 r 對于 at 就越“不重要”,因為?γ?指數項會變大。
優點:距離當前動作越近的獎勵權重越高;解決遠期獎勵歸因問題
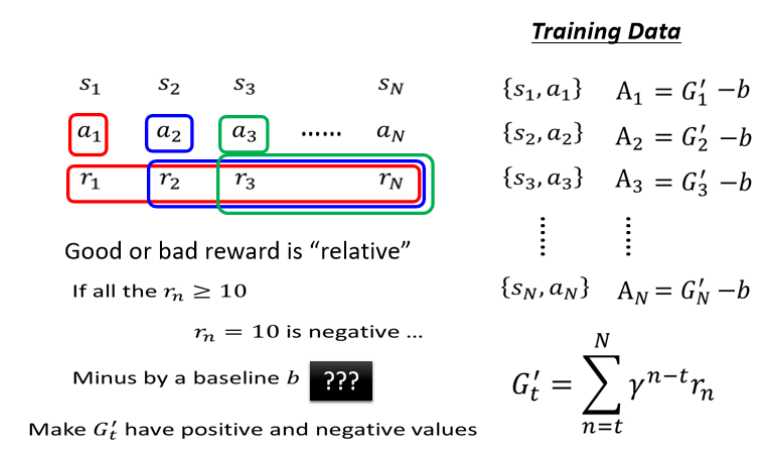
第四個版本:如果所有 Gt′? 都是正的,即使有些表現差的動作也被當作“ 好 ”進一步,因此需要做標準化,?引入基線(Baseline) b,將 Gt′?b 作為最終評價量 At。
-
目的是讓評價結果“有正有負”,使訓練更穩定、更有區分度
-
b?可設為均值、滑動平均、甚至預測的值(將引出 Critic)
Policy Gradient 實際操作流程?
-
初始化策略網絡(Actor)參數 θ
-
收集數據:用當前策略與環境交互,采樣出多個 (state, action) 對
-
評估每個動作的好壞:計算 At,可以是版本 1~4 中任一種
-
定義 Loss:例如交叉熵加權 At
-
梯度上升更新Actor參數
-
重新收集數據:由于策略已改變,必須用新的策略重新采樣(On-policy),重新收集數據

On-policy vs Off-policy
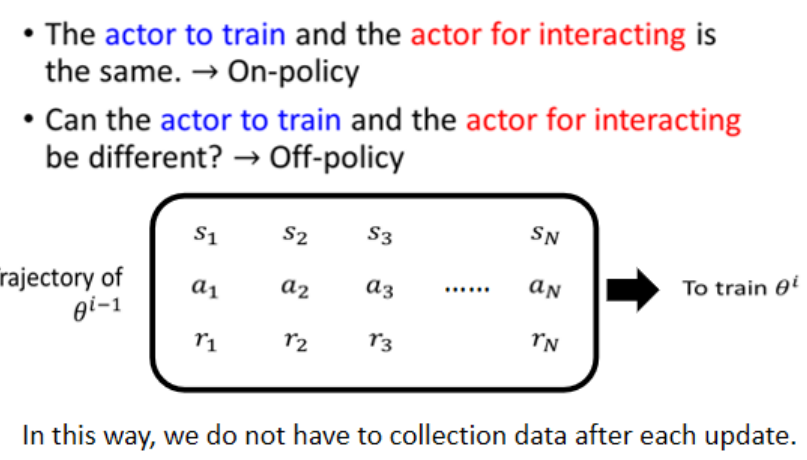
Off-policy 的代表方法:PPO(Proximal Policy Optimization),PPO 允許一定程度上“借用”舊策略的數據,同時控制策略變化幅度?
聽起來有點暈,李老師在課上也沒有細說,查資料后我的理解Off-policy 強化學習的本質是:
“我(要訓練的策略)不是親自去做,而是看別人做,再從別人的經驗中學習。”
類比總結和On-policy的區別就是:
-
On-policy:每更新一次策略,就必須重新采數據,慢又貴。
-
Off-policy:每次都用別人的策略來采集數據,然后訓練你的模型(比如別人開車時采集的數據記錄),但是你不能完全照搬別人的操作(因為別人的車可能技術更好),所以你要用算法糾正行為差異 。
這里有一些疑問需要解答,先了解兩個概念:
行為策略:用來與環境交互、采集數據,不一定更新(通常固定)
目標策略:是你真正想要訓練的策略,不斷更新
疑問:如果行為策略不更新,那它的采樣是不是就會重復、沒有意義?為什么還能學?
答案是:不會。
即使行為策略是“固定的”,你從它那里采樣的經驗軌跡每次也會不同,原因有兩個:1. 環境是動態的 / 有隨機性,行為策略+環境共同決定采樣軌跡,所以軌跡是多樣的;2.行為策略本身是“隨機策略”,行為策略即便固定,也有采樣上的隨機性
?
Critic
Critic 的概念
Critic 的作用是評估當前策略(Actor)的好壞,即預測在某個狀態下,采用該 Actor 后可能獲得的累積回報(Discounted Cumulative Reward),注意是個期望值,因為actor本身是有隨機性
![]()
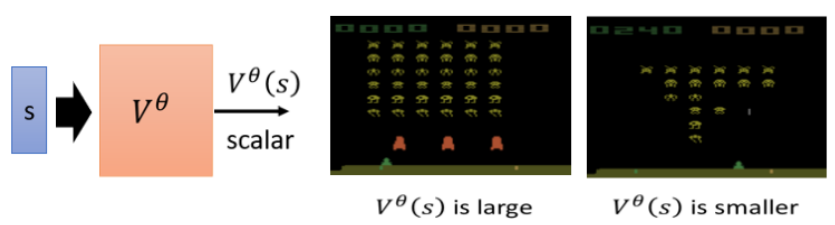
如何訓練 Value Function(Critic)
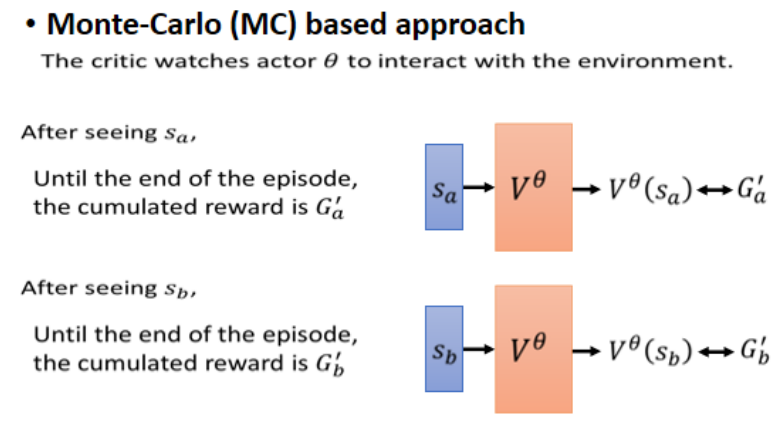
蒙特卡洛Monte-Carlo(MC)方法:
-
完整地讓 Actor 玩一整局游戲,記錄每個狀態對應最終獲得的 G 值(實際累積回報),然后訓練 Critic 預測這些 G。
-
優點:簡單直觀。
-
缺點:需要完整回合,游戲太長或無終點時不適用。
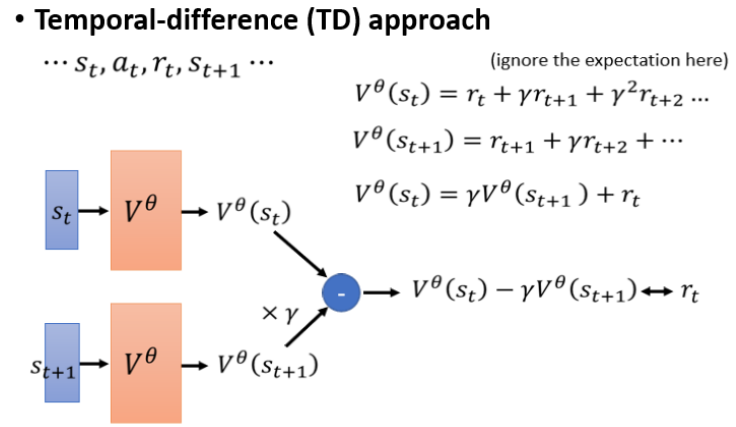
時序差分Temporal-Difference(TD)方法:
-
使用部分軌跡更新估值。核心思想是:在不知道最終結果的情況下,通過當前獎勵和下一步的估計結果來更新當前估計值
-
優點:無需完整回合,適合長或無限游戲。
-
缺點:更新可能有偏差。
MCvsTD
-
MC 使用真實累積獎勵訓練,更新慢但準確。
-
TD 使用估計值更新,快速但可能偏差。
-
沒有絕對對錯,取決于假設和實際需求。
舉例:觀察某一個 Actor跟環境互動玩了某一個游戲八次,當然這邊為了簡化計算,我們假設這些游戲都非常簡單,都一個回合,就到兩個回合就結束了。從下圖V(sa)的算法就可以看出MC和TD的區別

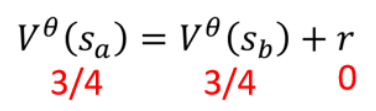

Critic 如何幫助訓練 Actor
前面提到需要做標準化,?引入基線(Baseline) b,讓評價結果“有正有負”,將 Gt′?b 作為最終評價量 At。這里b取多少本來是不知道的,現在可以確定了,b就是Critic估計的Actor后可能獲得的累積回報V,注意這個只是一個期望值,因為Actor本身是有隨機性的
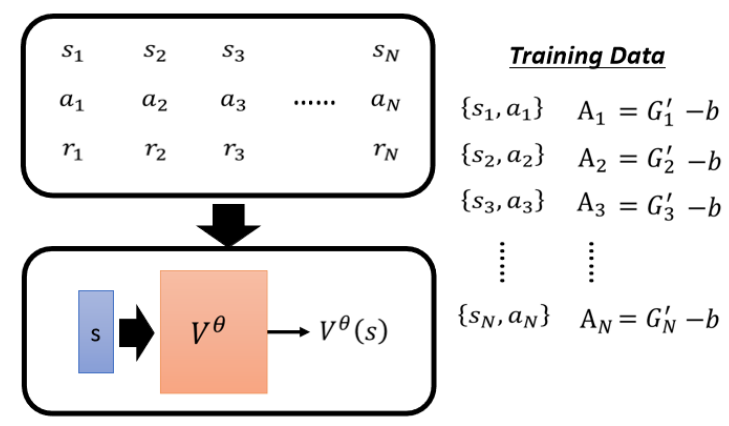
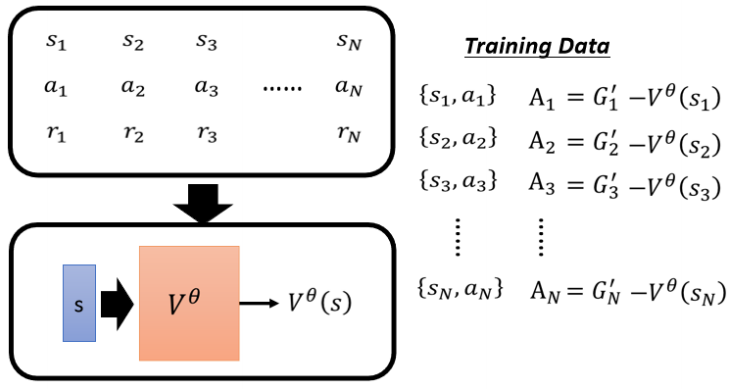
?這樣得到的At,如果大于0說明實際執行的動作 At 得到的結果好于平均值,是一個“好的動作",小于,說明該動作表現差于平均,是個“壞動作”。
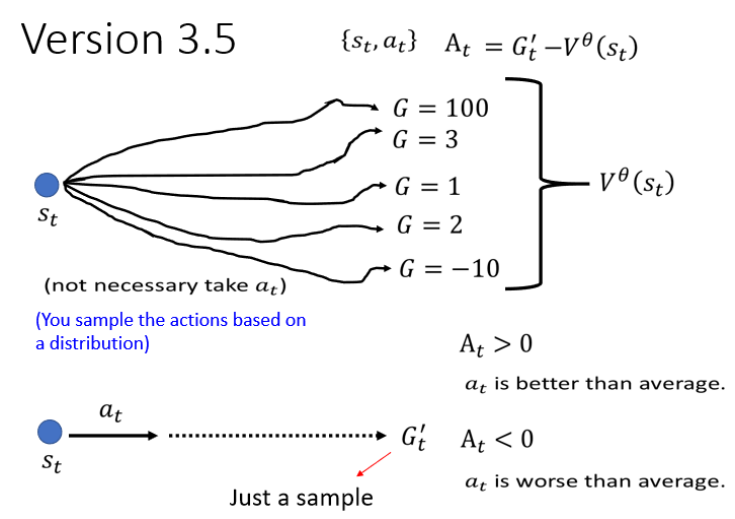
但是這種思路也不是完全沒問題,用某個狀態下的G減去平均值有可能會有極端情況,還有一種思路的用平均值減去平均值,就是:
-
用即時獎勵
?加上下一個狀態的估值 ?
來代替
,
-
這是對未來獎勵的一步估計,更快、更穩定。

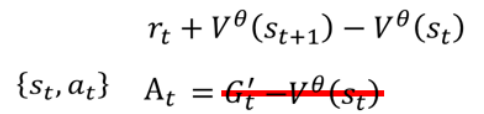
?
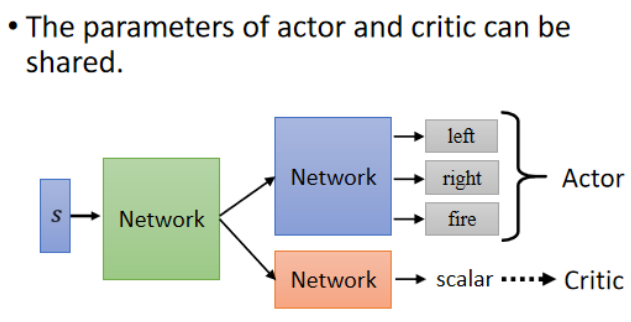
小技巧:Actor-Critic 網絡共享結構
-
Actor 和 Critic 可以共享網絡的前幾層(例如 CNN 提取特征),僅在輸出結構上有所區分:
-
Actor 輸出 action 的概率分布。
-
Critic 輸出一個標量的估值。
-
Deep Q Network (DQN):
-
Deep Q Network(DQN)是另一類強化學習方法,主要使用 Critic(Q function)來直接選動作。
-
DQN 有許多變形,如 Rainbow(融合多個改進技巧)。

)





)




)


)



)