目錄
- 打造AI應用基礎設施:Milvus向量數據庫部署與運維
- 1. Milvus介紹
- 1.1 什么是向量數據庫?
- 1.2 Milvus主要特點
- 2. Milvus部署方案對比
- 2.1 Milvus Lite
- 2.2 Milvus Standalone
- 2.3 Milvus Distributed
- 2.4 部署方案對比表
- 3. Milvus部署操作命令實戰
- 3.1 Milvus Lite部署
- 3.2 Milvus Standalone Docker部署
- 3.3 Milvus Distributed Kubernetes部署
- 3.3.1 使用Helm安裝Milvus Operator
- 3.3.2 使用kubectl安裝Milvus Operator
- 3.3.3 部署Milvus集群
- 3.3.4 檢查Milvus集群狀態
- 3.3.5 端口轉發以便本地訪問
- 3.3.6 卸載Milvus集群
- 4. Milvus部署后的使用
- 4.1 基本概念
- 4.1.1 集合(Collection)
- 4.1.2 模式(Schema)和字段(Fields)
- 4.1.3 主鍵(Primary Key)和自動ID(AutoId)
- 4.2 Python代碼示例
- 4.3 基本操作流程
- 4.4 高級功能
- 5. Milvus運維方案
- 5.1 Prometheus監控
- 5.1.1 部署Prometheus監控服務
- 5.1.2 為Milvus啟用ServiceMonitor
- 5.2 可視化和管理工具
- 5.3 備份和恢復
- 5.4 集群擴容
- 5.5 升級Milvus版本
- 6. 總結
- 參考資料
打造AI應用基礎設施:Milvus向量數據庫部署與運維
1. Milvus介紹
Milvus是一款高性能、可擴展的開源向量數據庫,專為管理和檢索向量數據而設計。它支持從Jupyter Notebook本地演示到處理數十億向量的大規模Kubernetes集群的各種規模用例。
1.1 什么是向量數據庫?
向量數據庫是專門設計用于存儲、管理和檢索向量嵌入(embeddings)的數據庫系統。在AI和機器學習領域,向量嵌入是將文本、圖像、音頻等轉換為數值向量的過程,這些向量可以用于相似性搜索。Milvus可以高效地執行相似性搜索操作,是AI應用(如語義搜索、推薦系統、圖像識別等)的理想選擇。
1.2 Milvus主要特點
- 高性能:支持數十億規模的向量管理和高效的相似性搜索
- 可擴展:提供從輕量級到分布式集群的多種部署方案
- 多模態支持:支持多種數據類型,包括稠密向量、稀疏向量、二進制向量等
- 高級搜索能力:支持ANN搜索、元數據過濾、范圍搜索、混合搜索等
- 靈活部署:提供多種部署模式,適應不同規模和場景的需求
- 開源生態:擁有豐富的工具和集成選項,如WebUI、備份工具等
2. Milvus部署方案對比
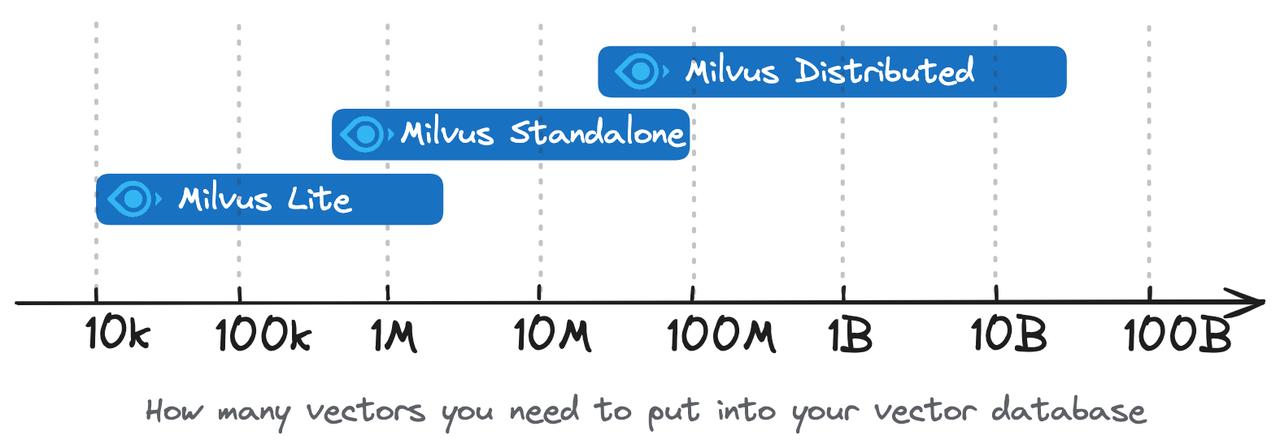
目前,Milvus提供了三種主要的部署選項:Milvus Lite、Milvus Standalone和Milvus Distributed。
2.1 Milvus Lite
Milvus Lite是一個Python庫,可以直接導入到應用程序中。作為Milvus的輕量級版本,它非常適合在Jupyter Notebook中快速原型設計或在資源有限的智能設備上運行。
特點:
- 輕量級,僅需通過pip安裝
- 適用于小型數據集(建議不超過幾百萬向量)
- 簡單易用,適合快速原型設計和學習
- 與其他Milvus部署模式共享相同的API
適用場景:
- 快速原型開發(RAG演示、AI聊天機器人、多模態搜索等)
- Jupyter Notebook或Google Colab環境
- 邊緣設備上的本地搜索
- 處理私密或敏感數據
2.2 Milvus Standalone
Milvus Standalone是單機服務器部署。所有組件都打包到一個Docker鏡像中,便于部署。
特點:
- 單一Docker鏡像,部署簡便
- 適合中等規模數據集(可擴展至1億向量)
- 通過主從復制支持高可用性
- 比集群部署需要更少的DevOps工作
適用場景:
- 早期生產環境
- 產品市場適應性測試階段
- 靈活性比可擴展性更重要的場景
- 中等規模的生產部署
2.3 Milvus Distributed
Milvus Distributed可以部署在Kubernetes集群上,具有云原生架構,攝取負載和搜索查詢由獨立節點單獨處理,允許關鍵組件冗余。
特點:
- 高可擴展性和高可用性
- 靈活定制每個組件的資源分配
- 適合大規模數據集(從1億到數百億向量)
- 企業級生產環境的首選
適用場景:
- 大規模生產部署
- 數據規模超出單臺服務器容量的業務
- 需要定制化負載處理的環境(如高讀取、低寫入或高寫入、低讀取)
2.4 部署方案對比表
| 特性 | Milvus Lite | Milvus Standalone | Milvus Distributed |
|---|---|---|---|
| 部署方式 | Python庫 | Docker容器 | Kubernetes集群 |
| 適用數據規模 | 數百萬向量 | 高達1億向量 | 1億至數百億向量 |
| SDK支持 | Python、gRPC | Python、Go、Java、Node.js、C#、RESTful | Python、Java、Go、Node.js、C#、RESTful |
| 資源要求 | 最低 | 中等 | 高 |
| 運維復雜度 | 簡單 | 中等 | 復雜 |
| 一致性級別 | 強一致性 | 強一致性、有界陳舊、會話一致性、最終一致性 | 強一致性、有界陳舊、會話一致性、最終一致性 |
| 高級數據管理 | 不支持 | 訪問控制、分區、分區鍵 | 訪問控制、分區、分區鍵、物理資源分組 |
3. Milvus部署操作命令實戰
3.1 Milvus Lite部署
Milvus Lite作為Python庫,部署非常簡單:
# 安裝pymilvus(包含Milvus Lite)
pip install -U pymilvus# 在Python代碼中使用
from pymilvus import MilvusClient# 使用本地文件初始化Milvus Lite實例
client = MilvusClient("./milvus_demo.db")
3.2 Milvus Standalone Docker部署
Milvus提供了一個安裝腳本,可以輕松地將其作為Docker容器安裝:
# 下載安裝腳本
curl -sfL https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh -o standalone_embed.sh# 啟動Docker容器
bash standalone_embed.sh start
安裝后:
- Milvus容器在端口19530上啟動
- 一個嵌入式etcd與Milvus一起安裝在同一容器中,端口為2379
- 可通過修改當前文件夾中的user.yaml文件來更改默認Milvus配置
- Milvus數據卷映射到當前文件夾中的volumes/milvus目錄
停止和刪除Milvus:
# 停止Milvus
bash standalone_embed.sh stop# 刪除Milvus數據
bash standalone_embed.sh delete
升級Milvus版本:
# 升級Milvus
bash standalone_embed.sh upgrade
3.3 Milvus Distributed Kubernetes部署
使用Milvus Operator在Kubernetes上部署Milvus集群:
3.3.1 使用Helm安裝Milvus Operator
helm install milvus-operator \-n milvus-operator --create-namespace \--wait --wait-for-jobs \https://github.com/zilliztech/milvus-operator/releases/download/v1.2.0/milvus-operator-1.2.0.tgz
3.3.2 使用kubectl安裝Milvus Operator
kubectl apply -f https://raw.githubusercontent.com/zilliztech/milvus-operator/main/deploy/manifests/deployment.yaml
3.3.3 部署Milvus集群
kubectl apply -f https://raw.githubusercontent.com/zilliztech/milvus-operator/main/config/samples/milvus_cluster_default.yaml
3.3.4 檢查Milvus集群狀態
kubectl get milvus my-release -o yaml
3.3.5 端口轉發以便本地訪問
# 轉發Milvus服務端口
kubectl port-forward service/my-release-milvus 27017:19530# 轉發WebUI端口
kubectl port-forward service/my-release-milvus 27018:9091
3.3.6 卸載Milvus集群
kubectl delete milvus my-release
4. Milvus部署后的使用
4.1 基本概念
4.1.1 集合(Collection)
集合是Milvus中的基本數據組織單位,類似于關系數據庫中的表。集合是具有固定列和可變行的二維表。每列代表一個字段,每行代表一個實體。
4.1.2 模式(Schema)和字段(Fields)
模式定義了集合中字段的屬性(如數據類型、向量維度等)。每個字段都有各種約束屬性,如數據類型和向量字段的維度。
4.1.3 主鍵(Primary Key)和自動ID(AutoId)
主鍵字段用于區分實體,每個值在全局范圍內是唯一的。主鍵字段只接受整數或字符串。如果啟用了AutoId,Milvus將在數據插入時自動生成這些值。
4.2 Python代碼示例
以下是使用Milvus進行文本搜索的簡單演示:
from pymilvus import MilvusClient
import numpy as np# 連接到Milvus
client = MilvusClient("./milvus_demo.db") # Milvus Lite本地文件
# 或者連接到Milvus服務器
# client = MilvusClient(uri="http://localhost:19530", token="username:password")# 創建集合
client.create_collection(collection_name="demo_collection",dimension=384 # 本例中向量維度為384
)# 示例文本
docs = ["Artificial intelligence was founded as an academic discipline in 1956.","Alan Turing was the first person to conduct substantial research in AI.","Born in Maida Vale, London, Turing was raised in southern England.",
]# 生成示例向量(實際應用中應使用真實的嵌入模型)
vectors = [[ np.random.uniform(-1, 1) for _ in range(384) ] for _ in range(len(docs)) ]
data = [ {"id": i, "vector": vectors[i], "text": docs[i], "subject": "history"} for i in range(len(vectors)) ]# 插入數據
res = client.insert(collection_name="demo_collection",data=data
)# 執行帶過濾條件的搜索
res = client.search(collection_name="demo_collection",data=[vectors[0]],filter="subject == 'history'",limit=2,output_fields=["text", "subject"],
)
print(res)# 查詢匹配過濾表達式的所有實體
res = client.query(collection_name="demo_collection",filter="subject == 'history'",output_fields=["text", "subject"],
)
print(res)# 刪除數據
res = client.delete(collection_name="demo_collection",filter="subject == 'history'",
)
print(res)
4.3 基本操作流程
- 創建集合:定義向量和標量字段的集合模式
- 插入數據:將向量和元數據插入集合
- 創建索引:為向量字段創建索引以加速搜索
- 加載集合:將集合加載到內存中以準備搜索
- 執行搜索/查詢:執行相似度搜索或基于標量條件的查詢
- 釋放集合:不使用時釋放內存資源
4.4 高級功能
- 分區(Partition):集合的子集,共享相同的字段集,每個分區包含實體的子集
- 分片(Shard):集合的水平切片,每個分片對應一個數據輸入通道
- 別名(Alias):為集合創建別名,便于管理
- 一致性級別:定義跨數據節點和副本的數據一致性級別
5. Milvus運維方案
5.1 Prometheus監控
Milvus支持使用Prometheus進行監控,提供了各組件的指標,可通過http://<component-host>:9091/metrics端點導出。
5.1.1 部署Prometheus監控服務
使用kube-prometheus部署監控服務:
# 克隆kube-prometheus倉庫
git clone https://github.com/prometheus-operator/kube-prometheus.git
cd kube-prometheus# 創建監控棧
kubectl apply --server-side -f manifests/setup
kubectl wait \--for condition=Established \--all CustomResourceDefinition \--namespace=monitoring
kubectl apply -f manifests/# 修補prometheus-k8s clusterrole以獲取Milvus指標
kubectl patch clusterrole prometheus-k8s --type=json -p='[{"op": "add", "path": "/rules/-", "value": {"apiGroups": [""], "resources": ["pods", "services", "endpoints"], "verbs": ["get", "watch", "list"]}}]'# 端口轉發Prometheus和Grafana服務
kubectl --namespace monitoring --address 0.0.0.0 port-forward svc/prometheus-k8s 9090
kubectl --namespace monitoring --address 0.0.0.0 port-forward svc/grafana 3000
5.1.2 為Milvus啟用ServiceMonitor
通過Helm參數啟用ServiceMonitor:
helm upgrade my-release milvus/milvus --set metrics.serviceMonitor.enabled=true --reuse-values
檢查ServiceMonitor資源:
kubectl get servicemonitor
5.2 可視化和管理工具
Milvus提供了多種工具來幫助可視化和管理:
-
Milvus WebUI:通過瀏覽器訪問的內置GUI工具,提供系統可觀察性和簡單的界面。可通過
http://127.0.0.1:9091/webui/訪問。 -
Milvus Backup:開源工具,用于Milvus數據備份。
-
Birdwatcher:開源工具,用于調試Milvus和動態配置更新。
-
Attu:開源GUI工具,用于直觀的Milvus管理。
5.3 備份和恢復
Milvus Lite提供了命令行工具,可以將數據導出到JSON文件中:
# 安裝帶bulk_writer的pymilvus
pip install -U "pymilvus[bulk_writer]"# 導出數據
milvus-lite dump -d ./milvus_demo.db -c demo_collection -p ./data_dir
使用導出的文件,可以通過以下方式上傳數據:
- 通過數據導入功能上傳到Zilliz Cloud
- 通過批量插入功能上傳到Milvus服務器
5.4 集群擴容
對于Milvus Distributed,可以通過修改Kubernetes配置來擴展集群:
- 調整資源請求和限制
- 增加副本數量
- 添加更多節點到Kubernetes集群
5.5 升級Milvus版本
- Milvus Standalone:使用
bash standalone_embed.sh upgrade命令 - Milvus Distributed:使用Helm或Milvus Operator進行升級
6. 總結
Milvus是一款功能強大的向量數據庫,提供了從輕量級到分布式集群的多種部署選項,適應不同規模和場景的需求。通過本博客,我們介紹了Milvus的基本概念、部署方案對比、部署操作實戰、使用方法和運維方案。
無論您是在進行快速原型設計、構建小型生產應用還是需要大規模向量搜索系統,Milvus都能提供靈活而強大的解決方案。根據您的項目階段和規模選擇合適的Milvus部署模式,可以獲得最佳的性能和資源利用效率。
參考資料
- Milvus官方文檔
- Milvus安裝概述
- Milvus Lite文檔
- Milvus集合管理
- Milvus監控指南

boot文件夾內容)
—— 最佳實踐之性能)







)





)


