目錄
一、Memory架構設計解析
1. 核心組件關系圖
2. 代碼中的關鍵實現
二、對話記憶的工程實現
1. 消息結構化存儲
2. 動態提示組裝機制
三、Memory類型選型指南
四、生產環境優化實踐
1. 記憶容量控制
2. 記憶分片策略
3. 記憶檢索增強
五、典型問題調試技巧
1. 記憶丟失問題排查
.2. 消息類型不匹配修復
六、擴展應用場景
1. 個性化對話系統
2. 多模態記憶存儲
示例代碼關鍵方法對照表
1、庫名解析
2、ConversationBufferMemory關鍵參數
3、LLMChain()關鍵參數
示例代碼

在AI對話系統開發中,讓模型記住上下文如同賦予機器"短期記憶",這是構建連貫交互體驗的關鍵。本文通過剖析一個完整的多輪對話實現案例,揭示LangChain的Memory模塊如何突破大模型的"金魚記憶"困境。
一、Memory架構設計解析
1. 核心組件關系圖

2. 代碼中的關鍵實現
# 記憶存儲初始化(對話歷史容器)
chat_memory = ConversationBufferMemory(memory_key="chat_history", # 存儲標識符return_messages=True # 保持消息對象結構
)# 記憶系統與鏈的整合
memory_chain = LLMChain(llm=qwen,prompt=prompt,memory=chat_memory # 記憶注入
)二、對話記憶的工程實現
1. 消息結構化存儲
# 典型記憶存儲結構
[HumanMessage(content="你好"),AIMessage(content="您好!有什么可以幫助您?"),HumanMessage(content="講個笑話"),AIMessage(content="為什么程序員總分不清萬圣節和圣誕節?因為Oct31==Dec25!")
]-
設計優勢:保留原始消息類型,支持角色區分化處理
2. 動態提示組裝機制
# 運行時實際發生的提示拼接
final_prompt = [SystemMessage(content="你是一個專業的聊天AI"),HumanMessage(content="你好"),AIMessage(content="您好!有什么可以幫助您?"),HumanMessage(content="講個笑話")
]-
技術價值:使模型始終在完整對話上下文中生成響應
三、Memory類型選型指南
| Memory類型 | 存儲原理 | 適用場景 | 代碼示例 |
|---|---|---|---|
| ConversationBufferMemory | 完整保存所有對話記錄 | 短對話調試 | return_messages=True |
| ConversationBufferWindowMemory | 僅保留最近K輪對話 | 移動端輕量化應用 | k=3 |
| ConversationSummaryMemory | 存儲摘要而非原始對話 | 長文檔分析 | summary_prompt=... |
| CombinedMemory | 混合多種存儲策略 | 復雜對話系統 | memories=[buffer, summary] |
四、生產環境優化實踐
1. 記憶容量控制
from langchain.memory import ConversationBufferWindowMemory# 保留最近3輪對話
optimized_memory = ConversationBufferWindowMemory(k=3,memory_key="chat_history",return_messages=True
)-
避免問題:GPT-3.5的4k token限制下,防止長對話溢出
2. 記憶分片策略
class ChunkedMemory:def save_context(self, inputs, outputs):# 將長對話分段存儲chunk_size = 500 # 按token計算self.chunks = split_text(inputs['question'], chunk_size)-
應用場景:法律咨詢、醫療問診等長文本領域
3. 記憶檢索增強
from langchain.retrievers import TimeWeightedVectorStoreRetriever# 基于時間權重的記憶檢索
retriever = TimeWeightedVectorStoreRetriever(vectorstore=FAISS(),memory_stream=chat_memory.load_memory_variables({})['chat_history']
)-
技術價值:優先召回相關性高且較近期的對話
五、典型問題調試技巧
1. 記憶丟失問題排查
# 打印記憶狀態
print(chat_memory.load_memory_variables({}))
# 期望輸出:
# {'chat_history': [HumanMessage(...), AIMessage(...)]}.2. 消息類型不匹配修復
# 錯誤現象:TypeError: sequence item 0: expected str instance, HumanMessage found
# 解決方案:確保Memory配置return_messages=True?3. 長對話性能優化
# 監控內存使用
pip install memory_profiler
mprof run python chat_app.py六、擴展應用場景
1. 個性化對話系統
# 用戶畫像記憶
profile_memory = ConversationBufferMemory(memory_key="user_profile",input_key=["age", "occupation"]
)# 組合記憶體系
combined_memory = CombinedMemory(memories=[chat_memory, profile_memory])2. 多模態記憶存儲
from langchain_core.messages import ImageMessage# 支持圖片記憶
chat_memory.save_context({"question": "分析這張圖片"},{"output": ImageMessage(content=image_bytes)}
)?3. 記憶持久化方案
# SQLite存儲實現
from langchain.memory import SQLiteMemorypersistent_memory = SQLiteMemory(database_path="chat.db",session_id="user123"
)?結語:
通過合理運用Memory組件,開發者可以構建出具備以下能力的智能對話系統:
? 30輪以上連貫對話
? 個性化上下文感知
? 長期用戶畫像記憶
? 跨會話狀態保持
工作流程圖
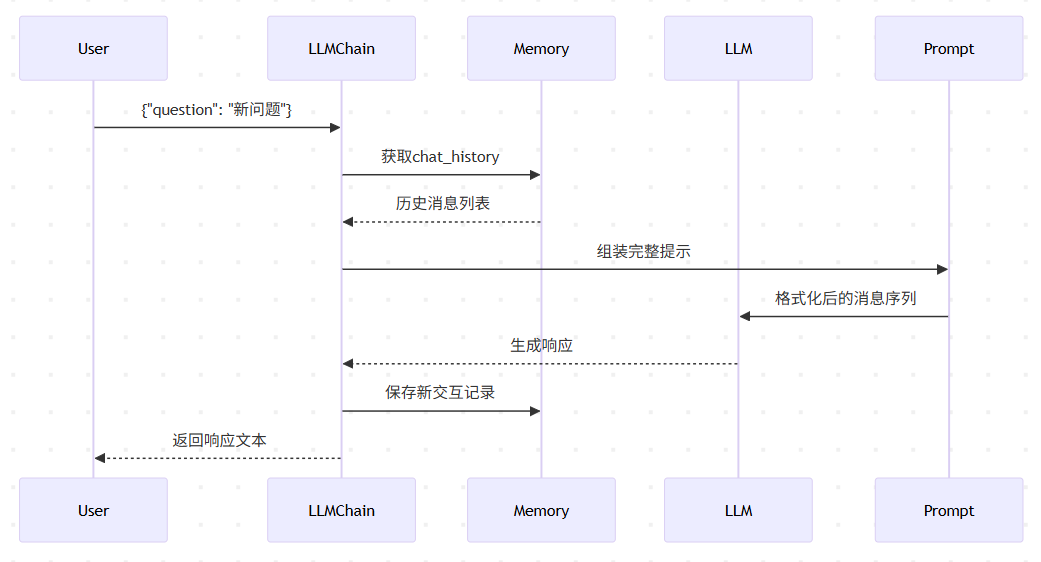
?
示例代碼關鍵方法對照表
1、庫名解析
| 方法/類名 | 所屬模塊 | 核心功能 |
|---|---|---|
ChatPromptTemplate | langchain.prompts | 多角色提示模板構建 |
SystemMessagePromptTemplate | langchain.prompts | 系統角色提示定義 |
MessagesPlaceholder | langchain.prompts | 動態消息占位符 |
HumanMessagePromptTemplate | langchain.prompts | 用戶消息格式化 |
ConversationBufferMemory | langchain.memory | 對話歷史緩沖存儲 |
LLMChain | langchain.chains | 語言模型執行流水線 |
2、ConversationBufferMemory關鍵參數
| 參數名 | 類型 | 作用說明 | 默認值 |
|---|---|---|---|
memory_key | str | 記憶字典的鍵名 | "history" |
return_messages | bool | 是否返回Message對象 | False |
input_key | str | 輸入項的鍵名 | None |
return_messages=True
-
必要性:
-
MessagesPlaceholder需要Message對象列表(而不僅是字符串) -
保持消息類型信息(系統/人類/AI消息)
-
-
對比實驗:
設置 輸入格式 是否可用 return_messages=TrueMessage對象列表 ? return_messages=False純文本字符串 ?
3、LLMChain()關鍵參數
-
核心參數:
參數 類型 作用說明 llmBaseLanguageModel 語言模型實例 promptBasePromptTemplate 提示模板 memoryBaseMemory 記憶系統 verbosebool 是否打印執行日志
示例代碼
代碼說明:
該代碼實現了一個基于LangChain的帶記憶功能的智能對話系統,主要演示以下核心能力:
1. **對話記憶管理** ?
?通過`ConversationBufferMemory`實現對話歷史的持久化存儲,突破大模型單次請求的上下文限制,支持連續多輪對話。2. **提示工程架構** ?
? ?采用分層提示模板設計:
? ?- 系統消息固化AI角色設定
? ?- `MessagesPlaceholder`動態注入歷史對話
? ?- 用戶消息模板接收即時輸入3. **服務集成方案** ?
? ?對接阿里云靈積平臺(DashScope)的千問大模型,演示:
? ?- 第三方模型API調用
? ?- 參數調優(temperature=0增強確定性)4. **執行流水線封裝** ?
? ?使用`LLMChain`將提示工程、記憶系統、模型調用封裝為可復用組件,體現LangChain模塊化設計思想。完整技術棧涵蓋環境變量管理、類型化消息處理、交互式調試等工程實踐。
from langchain.chat_models import ChatOpenAI
from langchain.prompts import (ChatPromptTemplate,MessagesPlaceholder,SystemMessagePromptTemplate,HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
import os
from dotenv import load_dotenv#一、加載配置環境
load_dotenv()# 二、初始化ChatOpenAI模型
llm = ChatOpenAI(model="qwen-max",api_key=os.getenv("DASHSCOPE_API_KEY"),openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1",temperature=0
)# 三、創建對話提示模板
prompt = ChatPromptTemplate(messages=[SystemMessagePromptTemplate.from_template("You are a nice chatbot having a conversation with a human."),# 這里的`variable_name`必須與記憶中的對應MessagesPlaceholder(variable_name="chat_history"),HumanMessagePromptTemplate.from_template("{question}")]
)#四、定義歷史消息存儲
# 注意我們設置`return_messages=True`以適配MessagesPlaceholder
# 注意`"chat_history"`與MessagesPlaceholder名稱對應
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)#五、創建LLMChain實例,用于處理對話
conversation = LLMChain(llm=llm,prompt=prompt,verbose=True,memory=memory
)#六、定義模擬歷史對話消息
# 注意我們只傳入`question`變量 - `chat_history`由記憶填充
conversation({"question": "你好"})
conversation({"question":"你能給我講一個蘋果和醫生的笑話嗎?"})
conversation({"question":"說得好,再講一個"})
conversation({"question":"講一個葫蘆娃的笑話"})#七、問題輸入執行
while True:question = input("請輸入問題:")if question.lower() == "exit":response = conversation({"question": "再見"}) # 主動觸發結束語print(response['text'])breakresponse = conversation({"question": question})print(response['text']) # 確保輸出模型響應運行結果
> Entering new LLMChain chain...
Prompt after formatting:
System: You are a nice chatbot having a conversation with a human.
Human: 你好
AI: 你好!有什么可以幫助你的嗎?
Human: 你能給我講一個蘋果和醫生的笑話嗎?
AI: 當然可以,這里有一個經典的笑話:為什么醫生建議每天吃一個蘋果?
因為醫生需要錢買房子!(實際上原話是 "An apple a day keeps the doctor away",意思是“一天一個蘋果,醫生遠離我”,但這個版本更幽默一些。)
希望這能讓你會心一笑!
Human: 說得好,再講一個
AI: 好的,再來一個蘋果和醫生的笑話:為什么蘋果不喜歡去看醫生?
因為每次醫生都會說:“你看起來有點核(核心)問題!”
希望這個也能讓你笑一笑!
Human: 講一個葫蘆娃的笑話
AI: 當然可以,這里有一個關于葫蘆娃的笑話:為什么葫蘆娃們總是穿肚兜?
希望這個笑話能讓你開心一笑!
Human: 回答我剛剛的問題> Finished chain.
好的,再來一個關于葫蘆娃的笑話為什么葫蘆娃們每次都能找到爺爺?
因為不管他們被妖怪抓到哪里,只要喊一聲“爺爺,救我!”爺爺就能立刻感應到他們的位置。這大概是因為葫蘆娃和爺爺之間有特殊的“GPS”吧!
希望這個笑話能讓你笑一笑!
請輸入問題:
說明:主要看最后一個問題“回答我剛剛的問題”,可以發現大模型能夠根據歷史對話再去講述關于葫蘆娃的笑話。這也就說明成功實現了Memory記憶功能。?






)





)




)

