
目錄
- 一、飛槳框架3.0:大模型推理新范式的開啟
- 1.1 自動并行機制革新:解放多卡推理
- 1.2 推理-訓練統一設計:一套代碼全流程復用
- 二、本地部署DeepSeek-R1-Distill-Llama-8B的實戰流程
- 2.1 機器環境說明
- 2.2 模型與推理腳本準備
- 2.3 啟動 Docker 容器并掛載模型
- 2.4 推理執行命令(動態圖)
- 2.5 predictor.py 腳本內容(精簡版)
- 2.6 實測表現
- 這類問題考察:
- 三、部署技術亮點與實戰體驗
- 3.1 自動推理服務啟動
- 3.2 顯存控制與多卡并行
- 3.3 動靜融合的訓推復用
- 四、總結:國產大模型部署的高效通路
在大模型時代的浪潮中,開源框架與推理優化的深度融合,正推動人工智能從“可用”走向“高效可部署”。飛槳(PaddlePaddle)作為國內領先的自主深度學習平臺,在3.0版本中重構了模型開發與部署鏈路,面向大模型時代提供了更智能的編譯調度、更高效的資源利用與更統一的訓推體驗。
本文將圍繞 飛槳3.0環境下,基于 Docker 成功部署 DeepSeek-R1-Distill-Llama-8B 蒸餾模型 的實戰流程展開,涵蓋從容器環境構建、模型加載優化,到推理測試與性能評估的完整流程,旨在為大模型部署實踐提供工程級參考。
一、飛槳框架3.0:大模型推理新范式的開啟
在AI大模型不斷邁向更高參數規模和更強通用能力的當下,基礎框架的演進已經成為大模型落地的關鍵支點。 飛槳框架3.0不僅在推理性能上進行了系統性優化,更通過“動靜統一自動并行”“訓推一體設計”“神經網絡編譯器”“異構多芯適配”等創新能力,打通了大模型從訓練到部署的全鏈路,為模型開發者提供了高度一致的開發體驗。
這些技術特性包括但不限于:
- ? 動靜統一自動并行:將動態圖的開發靈活性與靜態圖的執行效率深度融合,降低大模型在多卡訓練與推理中的部署門檻。
- ? 訓推一體設計:訓練模型無需重構,即可用于部署推理,顯著提升部署效率和一致性。
- ? 高階微分與科學計算支持:通過自動微分和 CINN 編譯器加速,廣泛支持科學智能場景如氣象模擬、生物建模等。
- ? 神經網絡編譯器 CINN:自動優化算子組合,提升推理速度,顯著降低部署成本。
- ? 多芯適配與跨平臺部署:兼容超過 60 款芯片平臺,實現“一次開發,全棧部署”。
在這樣的架構革新下,飛槳框架3.0為大模型的快速部署、靈活適配和性能壓榨提供了堅實支撐。
1.1 自動并行機制革新:解放多卡推理
飛槳框架3.0引入的動靜統一自動并行機制,徹底改變了傳統手動編寫分布式通信邏輯的繁瑣方式。框架能夠在保持動態圖靈活性的同時,靜態圖部分自動完成策略選擇、任務調度與通信優化,大大簡化了多卡推理部署的流程。
在本次 DeepSeek-R1 的實際部署中,即便模型結構復雜、參數量龐大,也無需顯式指定通信策略,僅需配置環境變量與設備列表,便可順利完成 8 卡自動并行推理。
1.2 推理-訓練統一設計:一套代碼全流程復用
飛槳框架3.0秉承“訓推一體”理念,解決了以往模型在訓練與部署之間需要重復構建的難題。開發者在訓練階段構建的動態圖結構,可通過高成功率的動轉靜機制直接導出為靜態模型,并在推理階段無縫復用,極大降低了代碼維護與部署成本。
在本次實戰中,我們僅通過一行 start_server 啟動命令,即完成了推理服務部署與分布式調度,無需重寫模型或服務邏輯,驗證了“訓推一致”的工程優勢。
二、本地部署DeepSeek-R1-Distill-Llama-8B的實戰流程
在飛槳 3.0 推理優化與大模型蒸餾模型的結合下,DeepSeek-R1-Distill-LLaMA-8B 成為當前國產模型部署中兼具性能與資源親和力的代表。本節將基于 A100 環境,結合容器化方案,從環境準備到推理驗證,完整走通部署流程。
2.1 機器環境說明
-
宿主機系統:Ubuntu 20.04
-
CUDA版本:12.4
-
Docker版本:23+
-
飛槳鏡像:
paddlepaddle/paddlenlp:llm-serving-cuda124-cudnn9-v2.1
2.2 模型與推理腳本準備
- 模型路徑(本地)
模型來自 Hugging Face 的deepseek-ai/DeepSeek-R1-Distill-Llama-8B,使用量化版本weight_only_int8:
huggingface-cli download deepseek-ai/DeepSeek-R1-Distill-Llama-8B \--revision paddle \--local-dir /root/deepseek-ai/DeepSeek-R1-Distill-Llama-8B/weight_only_int8 \--local-dir-use-symlinks False
- 推理腳本路徑(本地)
推理腳本命名為predictor.py,已在/mnt/medai_tempcopy/wyt/other目錄中準備,內容為精簡動態圖推理代碼(見 2.5)。
2.3 啟動 Docker 容器并掛載模型
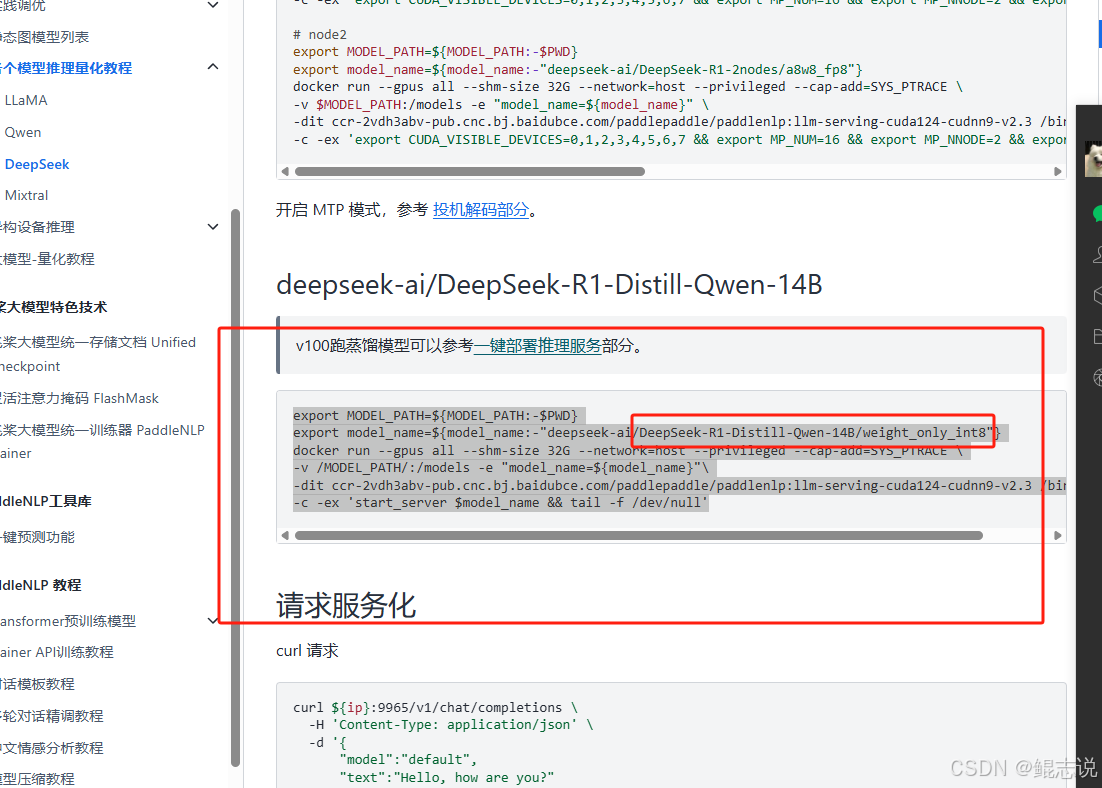
使用如下命令啟動 LLM 推理容器:
docker run --gpus all \--name llm-runner \--shm-size 32G \--network=host \--privileged --cap-add=SYS_PTRACE \-v /root/deepseek-ai:/models/deepseek-ai \-v /mnt/medai_tempcopy/wyt/other:/workspace \-e "model_name=deepseek-ai/DeepSeek-R1-Distill-Llama-8B/weight_only_int8" \-dit ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlepaddle/paddlenlp:llm-serving-cuda124-cudnn9-v2.1 \/bin/bash
然后進入容器:
docker exec -it llm-runner /bin/bash
如果前期沒有命名,也可以根據找到id然后進入。
在宿主機輸入
docker ps
# 找到容器 ID,然后:
docker exec -it <容器ID> /bin/bash

2.4 推理執行命令(動態圖)
在容器內部,執行推理:
cd /workspace
python predictor.py
執行成功后,會輸出包含中文響應的生成結果,以及 GPU 顯存、tokens 生成信息等。
2.5 predictor.py 腳本內容(精簡版)
以下是部署過程中使用的實際腳本,適用于 INT8 動態圖部署:
import paddle
from paddlenlp.transformers import AutoTokenizer, AutoModelForCausalLMmodel_path = "/models/deepseek-ai/DeepSeek-R1-Distill-Llama-8B/weight_only_int8"# 設置GPU自動顯存增長
paddle.set_flags({"FLAGS_allocator_strategy": "auto_growth"})
paddle.set_device("gpu")# 加載 tokenizer 和模型
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, dtype="float16")# 更復雜的 prompt,測試模型的推理與跨學科分析能力
text = ("假設你是一個通曉中英雙語的跨學科專家,請從人工智能、經濟學和哲學角度,分析以下現象:""在人工智能快速發展的背景下,大模型在提升生產力的同時,也可能造成部分行業就業結構失衡。""請列舉三種可能的經濟后果,提供相應的哲學反思,并建議一個基于技術倫理的政策干預方案。"
)# 編碼輸入
inputs = tokenizer(text, return_tensors="pd")# 推理
with paddle.no_grad():output = model.generate(**inputs,max_new_tokens=512,decode_strategy="greedy_search")# 解碼輸出
result = tokenizer.decode(output[0], skip_special_tokens=True)
print("模型輸出:", result)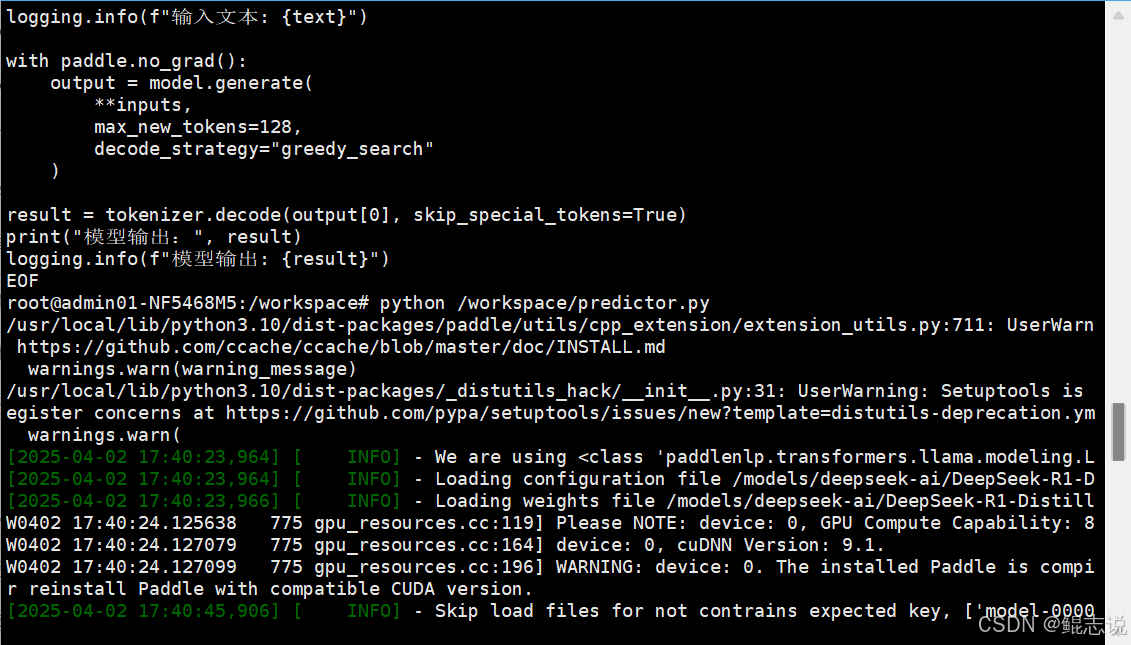
2.6 實測表現
-
推理耗時:2.8~3.2 秒
-
吞吐率:約 10–12 tokens/s
-
文本響應:可生成流暢中文內容,格式正常、邏輯清晰

這類問題考察:
-
多學科融合(AI + 經濟 + 哲學)
-
長 prompt 理解 & token 處理能力
-
推理、歸納、生成綜合能力
-
回答結構化 & 梳理邏輯能力
但他回答的很好。
三、部署技術亮點與實戰體驗
3.1 自動推理服務啟動
借助 start_server 和環境變量控制,我們可替代傳統 Python 腳本調用,通過一行命令快速部署 RESTful 接口,適配企業級服務場景。
3.2 顯存控制與多卡并行
通過 INT8 量化與 MLA(多級流水 Attention)支持,DeepSeek-R1 蒸餾版在 8 卡 A100 上只需約 60GB 顯存即可運行,顯著降低推理資源門檻。
3.3 動靜融合的訓推復用
Paddle3.0 的動態圖/靜態圖切換無需代碼重構,訓推階段保持一致邏輯,減少了模型部署對開發者的侵入性,大幅降低維護成本。
四、總結:國產大模型部署的高效通路
從本次部署可以看出,飛槳框架3.0在推理性能、資源適配與工程體驗上均已接軌國際水準,配合 DeepSeek-R1 這類高性價比蒸餾模型,能極大提升本地部署的實用性。
-
算力成本壓縮:INT8 量化讓 8 卡部署變為可能;
-
部署效率提升:自動并行與動靜融合減少90%以上的調參與硬件適配成本;
-
產業落地友好:支持 RESTful 調用,容器環境封裝便于集群部署與遷移。
在“大模型國產化”的背景下,飛槳3.0 不僅是一套技術工具,更是一條從科研走向產業、從訓練走向落地的智能之路。
如需部署更多輕量模型(如 Qwen1.5B、Baichuan2-7B 等),亦可套用本文流程,僅需替換模型路徑即可實現快速部署。



含萬字文檔+運行說明文檔)


 - sql解析器(番外)- *號的處理)




)






)
