文章目錄
- 一、網頁解析技術介紹
- 二、Beautiful Soup庫
- 1. Beautiful Soup庫介紹
- 2. Beautiful Soup庫幾種解析器比較
- 3. 安裝Beautiful Soup庫
- 3.1 安裝 Beautiful Soup 4
- 3.2 安裝解析器
- 4. Beautiful Soup使用步驟
- 4.1 創建Beautiful Soup對象
- 4.2 獲取標簽
- 4.2.1 通過標簽名獲取
- 4.2.2 通過find()方法獲取
- 4.2.3 通過find_all()方法獲取
- 4.2.4 CSS選擇器介紹
- 4.2.5 通過select_one()方法獲取
- 4.2.6 通過select()方法獲取
- 4.3 提取數據
- 4.3.1 獲取標簽間的內容
- 4.3.2 獲取標簽屬性的值
- 三、實戰:解析豆瓣讀書中小說的網頁
- 1. 提取網頁數據
- 2. 保存數據到csv文件
一、網頁解析技術介紹
網頁解析技術是爬蟲獲取數據的核心環節,指從網頁的HTML/XML等源代碼中提取目標信息(如文本、鏈接、圖片、表格數據等)的過程。
二、Beautiful Soup庫
1. Beautiful Soup庫介紹
Beautiful Soup 是 Python 中一款功能強大的 HTML/XML 解析庫,它能夠將復雜的網頁源代碼轉換為結構化的樹形文檔(Parse Tree),并提供簡單直觀的 API 供開發者遍歷、搜索和提取其中的元素與數據。
其核心優勢在于:
- 強大的容錯能力:能夠處理不規范的 HTML 代碼(如標簽未閉合、屬性缺失、嵌套混亂等),自動修復語法錯誤,生成可解析的結構,非常適合爬取實際場景中格式混亂的網頁。
- 直觀的操作方式:支持通過標簽名、類名(
class)、ID、屬性等多種方式定位元素,語法貼近自然語言,即使是非前端開發背景的開發者也能快速上手。 - 靈活的解析支持:可搭配不同的解析器(如 Python 標準庫的
html.parser、lxml、html5lib等),兼顧解析速度、兼容性和功能需求。 - 豐富的功能擴展:提供遍歷文檔樹、搜索文檔樹、修改文檔結構等功能,不僅能提取數據,還能對網頁內容進行二次處理。
Beautiful Soup 廣泛應用于網絡爬蟲、數據挖掘、網頁內容分析等場景,是 Python 爬蟲生態中處理網頁解析的核心工具之一。
2. Beautiful Soup庫幾種解析器比較
Beautiful Soup 本身不直接解析網頁,而是依賴第三方解析器完成 HTML/XML 的解析工作。不同解析器在速度、容錯性和功能上存在差異,選擇合適的解析器能提升解析效率和兼容性。
以下是常用解析器的對比:
| 解析器 | 依賴庫 | 適用場景 | 優點 | 缺點 |
|---|---|---|---|---|
| html.parser | Python 標準庫(內置) | 輕量場景、對解析速度要求不高的情況 | 無需額外安裝,兼容性好(支持 Python 2.7+ 和 3.2+) | 解析速度較慢,對復雜不規范 HTML 的容錯性一般 |
| lxml (HTML) | lxml 庫 | 追求解析速度和容錯性的常規 HTML 解析場景 | 解析速度極快,對不規范 HTML 的修復能力強 | 需要額外安裝 lxml 庫(C 語言編寫,安裝可能依賴系統環境) |
| lxml (XML) | lxml 庫 | XML 文檔解析或需要嚴格 XML 語法支持的場景 | 支持 XML 特有語法,解析速度快,容錯性強 | 需安裝 lxml 庫,僅適用于 XML 格式文檔 |
| html5lib | html5lib 庫 | 需完全模擬瀏覽器解析行為的場景 | 對不規范 HTML 的容錯性最強(完全遵循 HTML5 標準) | 解析速度最慢,需要額外安裝 html5lib 庫 |
3. 安裝Beautiful Soup庫
Beautiful Soup 庫的安裝過程簡單,支持通過 Python 包管理工具 pip 快速安裝,同時需根據需求安裝對應的解析器。
3.1 安裝 Beautiful Soup 4
Beautiful Soup 目前最新穩定版本為 Beautiful Soup 4(簡稱 bs4),安裝命令如下:
pip install beautifulsoup4 -i https://mirrors.aliyun.com/pypi/simple/
3.2 安裝解析器
根據前文的解析器對比,推薦安裝 lxml 解析器(兼顧速度和容錯性):
pip install lxml -i https://mirrors.aliyun.com/pypi/simple/
若需要 html5lib 解析器(用于極端不規范網頁),安裝命令如下:
pip install html5lib -i https://mirrors.aliyun.com/pypi/simple/
4. Beautiful Soup使用步驟
使用 Beautiful Soup 解析網頁的核心流程為:創建Beautiful Soup對象 --> 獲取標簽 --> 提取數據。
4.1 創建Beautiful Soup對象
創建Beautiful Soup對象是使用該庫解析網頁的第一步,通過將網頁內容(HTML/XML)和解析器傳入BeautifulSoup類,生成一個可操作的樹形文檔對象。這個對象封裝了網頁的所有元素和結構,提供了豐富的方法用于遍歷、搜索和提取數據。
基本語法:
from bs4 import BeautifulSoup# 創建Beautiful Soup對象
soup = BeautifulSoup(markup, features, **kwargs)
Beautiful Soup類構造方法的參數說明:
| 參數名 | 類型 | 作用描述 | 必選 | 示例值 |
|---|---|---|---|---|
markup | 字符串/文件對象 | 待解析的HTML/XML內容,可來源于網絡響應文本或本地文件內容 | 是 | response.text(網絡響應文本)、open("page.html")(本地文件對象) |
features | 字符串 | 指定解析器類型,決定使用哪種解析器處理markup內容 | 是 | "lxml"、"html.parser"、"html5lib" |
builder | 解析器構建器 | 自定義解析器構建器(高級用法,通常無需設置) | 否 | lxml.html.HTMLParser() |
parse_only | 解析過濾器 | 限制只解析指定標簽(提升效率),需配合SoupStrainer使用 | 否 | SoupStrainer("div", class_="content")(只解析class為content的div) |
from_encoding | 字符串 | 指定markup的編碼格式(自動檢測失敗時手動指定) | 否 | "utf-8"、"gbk" |
exclude_encodings | 列表 | 排除可能的編碼格式(用于優化編碼檢測) | 否 | ["ISO-8859-1", "windows-1252"] |
element_classes | 字典 | 自定義標簽類(高級用法,用于擴展標簽功能) | 否 | {"div": MyDivClass, "a": MyATagClass} |
示例:創建Beautiful Soup對象
from bs4 import BeautifulSoupsoup = BeautifulSoup(markup=open(file='./豆瓣讀書/小說/0.html', mode='r', encoding='utf-8'), features='lxml')
4.2 獲取標簽
4.2.1 通過標簽名獲取
直接通過標簽名稱(如 title、div、a 等)訪問網頁中的第一個匹配標簽,適用于獲取頁面中唯一或首個出現的標簽。
語法:
tag = soup.標簽名 # 獲取第一個匹配的標簽
示例: 獲取title標簽
from bs4 import BeautifulSoupsoup = BeautifulSoup(markup=open(file='./豆瓣讀書/小說/0.html', mode='r', encoding='utf-8'), features='lxml')title_tag = soup.title
print(title_tag)
打印結果如下圖所示:

4.2.2 通過find()方法獲取
find() 方法用于在文檔樹中查找第一個符合條件的標簽,支持通過標簽名、屬性、文本內容等多條件篩選,靈活性遠高于直接通過標簽名獲取。
語法:
tag = soup.find(name, attrs, recursive, string, **kwargs)
參數說明:
| 參數名 | 類型 | 作用描述 | 示例值 |
|---|---|---|---|
name | 字符串/列表 | 指定標簽名稱,可傳入單個標簽名或多個標簽名的列表(匹配任一標簽)。 | name="a"(查找<a>標簽)、name=["div", "p"](查找<div>或<p>) |
attrs | 字典 | 通過標簽屬性篩選,鍵為屬性名,值為屬性值(支持正則匹配)。 | attrs={"class": "info"}(查找class為info的標簽) |
recursive | 布爾值 | 是否遞歸查找所有子節點,True(默認)表示搜索所有后代節點,False僅搜索直接子節點。 | recursive=False(僅查找直接子節點) |
string | 字符串/正則 | 按標簽內的文本內容篩選,支持字符串完全匹配或正則表達式匹配。 | string="科幻小說"、string=re.compile(r"小說") |
** kwargs | 關鍵字參數 | 直接傳入屬性名作為參數(簡化寫法,等價于attrs),如class_、id等。 | class_="rating_nums"(查找class為rating_nums的標簽) |
示例: 獲取第一個出版社所在的標簽。
from bs4 import BeautifulSoupsoup = BeautifulSoup(markup=open(file='./豆瓣讀書/小說/0.html', mode='r', encoding='utf-8'), features='lxml')tag = soup.find(name='div', attrs={"class": "pub"})
print(tag)
打印結果如下圖所示:

4.2.3 通過find_all()方法獲取
find_all() 方法用于在文檔樹中查找所有符合條件的標簽,返回一個包含所有匹配結果的列表,是批量提取數據的核心方法。
語法:
tag_list = soup.find_all(name, attrs, recursive, string, limit, **kwargs)
參數說明:
| 參數名 | 類型 | 作用描述 | 示例值 |
|---|---|---|---|
name | 字符串/列表 | 同 find(),指定標簽名稱或標簽名列表。 | name="a"(獲取所有<a>標簽) |
attrs | 字典 | 同 find(),通過屬性篩選標簽。 | attrs={"id": "content"}(獲取id為content的所有標簽) |
recursive | 布爾值 | 同 find(),是否遞歸查找所有子節點。 | recursive=True(默認,搜索所有后代節點) |
string | 字符串/正則 | 同 find(),按文本內容篩選,返回包含匹配文本的節點列表。 | string=re.compile(r"評分")(獲取所有含“評分”文本的節點) |
limit | 整數 | 限制返回結果的數量,僅返回前 limit 個匹配標簽。 | limit=5(僅返回前5個匹配結果) |
** kwargs | 關鍵字參數 | 同 find(),直接傳入屬性名作為參數(如 class_、id)。 | class_="title"(獲取所有class為title的標簽) |
示例: 獲取前5個出版社所在的標簽。
from bs4 import BeautifulSoupsoup = BeautifulSoup(markup=open(file='./豆瓣讀書/小說/0.html', mode='r', encoding='utf-8'), features='lxml')tag = soup.find_all(name='div', attrs={"class": "pub"}, limit=5)
print(tag)
打印結果如下圖所示:

4.2.4 CSS選擇器介紹
CSS選擇器是一種通過標簽名、類名、ID、屬性等規則定位HTML元素的語法,廣泛應用于前端開發和網頁解析。Beautiful Soup的select()和select_one()方法支持CSS選擇器語法,以下是常用選擇器規則:
| 選擇器類型 | 語法示例 | 描述說明 |
|---|---|---|
| 標簽選擇器 | div | 匹配所有<div>標簽 |
| 類選擇器 | .info | 匹配所有class="info"的標簽 |
| ID選擇器 | #content | 匹配id="content"的標簽(ID唯一) |
| 屬性選擇器 | a[href] | 匹配所有包含href屬性的<a>標簽 |
| 屬性值選擇器 | a[href="https://example.com"] | 匹配href屬性值為指定URL的<a>標簽 |
| 屬性包含選擇器 | a[href*="book"] | 匹配href屬性值包含"book"的<a>標簽 |
| 層級選擇器 | div.info h2 | 匹配class="info"的<div>下的所有<h2>標簽 |
| 直接子元素選擇器 | div > p | 匹配<div>的直接子元素<p>(不包含嵌套子元素) |
| 相鄰兄弟選擇器 | h2 + p | 匹配<h2>后面緊鄰的第一個<p>標簽 |
| 偽類選擇器 | li:nth-child(2) | 匹配父元素中第2個<li>子元素 |
4.2.5 通過select_one()方法獲取
select_one()方法通過CSS選擇器語法查找第一個符合條件的標簽,返回單個標簽對象(而非列表),適用于獲取唯一或首個匹配的元素。
語法:
from bs4 import BeautifulSoupsoup = BeautifulSoup(markup=open(file='./豆瓣讀書/小說/0.html', mode='r', encoding='utf-8'), features='lxml')tag = soup.select_one(selector='div .info > .pub')
print(tag)
參數說明:
| 參數名 | 類型 | 作用描述 | 示例值 |
|---|---|---|---|
selector | 字符串 | CSS選擇器規則,支持上述所有選擇器語法。 | div.info h2 a(匹配class為info的div下的h2內的a標簽) |
namespaces | 字典 | 命名空間映射(用于XML文檔解析,HTML解析中通常無需設置)。 | {"html": "http://www.w3.org/1999/xhtml"} |
** kwargs | 關鍵字參數 | 傳遞給解析器的額外參數(高級用法,一般無需設置)。 | - |
示例: 獲取第一個出版社所在的標簽。
tag = soup.find(name='div', attrs={"class": "pub"})
print(tag)
打印結果如下圖所示:
4.2.6 通過select()方法獲取
select()方法通過CSS選擇器語法查找所有符合條件的標簽,返回包含所有匹配結果的列表,是批量提取數據的常用方法。
語法:
tag_list = soup.select(selector, namespaces=None, limit=None,** kwargs)
參數說明:
| 參數名 | 類型 | 作用描述 | 示例值 |
|---|---|---|---|
selector | 字符串 | 同select_one(),CSS選擇器規則。 | span.rating_nums(匹配class為rating_nums的span標簽) |
namespaces | 字典 | 同select_one(),命名空間映射(HTML解析中通常無需設置)。 | - |
limit | 整數 | 限制返回結果數量,僅返回前limit個匹配標簽(默認返回所有)。 | limit=3(僅返回前3個匹配結果) |
**kwargs | 關鍵字參數 | 傳遞給解析器的額外參數(一般無需設置)。 | - |
示例: 獲取前5個出版社所在的標簽。
from bs4 import BeautifulSoupsoup = BeautifulSoup(markup=open(file='./豆瓣讀書/小說/0.html', mode='r', encoding='utf-8'), features='lxml')tag = soup.select(selector='div .info > .pub', limit=5)
print(tag)
打印結果如下圖所示:
4.3 提取數據
獲取標簽后,下一步是從標簽中提取所需數據,主要包括標簽間的文本內容和標簽的屬性值(如鏈接、圖片地址等)。
4.3.1 獲取標簽間的內容
標簽間的內容通常是網頁中顯示的文本(如標題、描述、評分等),Beautiful Soup 提供了多種屬性用于獲取不同格式的文本內容,適用于不同場景:
| 屬性名 | 描述說明 | 示例代碼 | 示例結果(假設標簽為<p>hello <b>world</b></p>) |
|---|---|---|---|
text | 返回標簽內所有文本的拼接字符串,自動忽略標簽嵌套結構,僅保留文本內容。 | tag.text | hello world |
string | 僅當標簽內只有純文本(無嵌套標簽)時返回文本,否則返回None。 | tag.string | None(因存在<b>嵌套標簽) |
strings | 返回一個生成器,包含標簽內所有文本片段(包括嵌套標簽中的文本),保留分隔符。 | list(tag.strings) | ['hello ', 'world'] |
stripped_strings | 類似strings,但會自動去除每個文本片段的首尾空白字符,并過濾空字符串。 | list(tag.stripped_strings) | ['hello', 'world'] |
示例:提取標簽中的內容
from bs4 import BeautifulSoupsoup = BeautifulSoup(markup=open(file='./豆瓣讀書/小說/0.html', mode='r', encoding='utf-8'), features='lxml')# 使用 CSS 選擇器查找第一個 class="subject-item" 的標簽(通常是一個 <li> 或 <div>)
# soup.select_one() 返回匹配的第一個 Tag 對象,如果沒有匹配則返回 None
li_tag = soup.select_one('.subject-item')# 打印該標簽及其所有子標簽中的**全部文本內容**
# .text 屬性會遞歸獲取標簽內所有字符串,并自動用空格連接
# 注意:可能包含多個空格、換行或制表符等空白字符
print(li_tag.text)# 遍歷 li_tag 下的所有**直接和嵌套的字符串內容**(包括空白字符)
# .strings 是一個生成器,返回所有文本節點(包含空白、換行等)
# 輸出時會看到原始的縮進、換行等格式
for string in li_tag.strings:print(string)# 遍歷 li_tag 下的所有**去除了首尾空白的非空字符串**
# .stripped_strings 是一個生成器,功能類似 .strings
# 但會對每個字符串調用 .strip(),去除兩端空白,并跳過空字符串
# 更適合提取“干凈”的文本內容
for string in li_tag.stripped_strings:print(string)# 使用更精確的 CSS 選擇器查找書籍出版信息
# 選擇路徑:div 下 class="info" 的元素 > 其直接子元素 class="pub"
# 通常用于匹配圖書的“作者 / 出版社 / 出版年份”等信息
tag = soup.select_one(selector='div .info > .pub')# 獲取該標簽的**直接文本內容**(不包括子標簽的文本)
# .string 表示標簽的直接內容(如果標簽只有一個子字符串)
# .strip() 去除字符串首尾的空白、換行等字符
# 最終得到干凈的出版信息文本
print(tag.string.strip())
4.3.2 獲取標簽屬性的值
HTML標簽通常包含屬性(如<a href="url">中的href、<img src="path">中的src),這些屬性值是提取鏈接、圖片地址、類名等信息的關鍵。
直接通過屬性名訪問
語法:tag["屬性名"]
適用場景:獲取已知存在的屬性(如href、src、class等)。
示例:獲取小說名稱的鏈接
from bs4 import BeautifulSoupsoup = BeautifulSoup(markup=open(file='./豆瓣讀書/小說/0.html', mode='r', encoding='utf-8'), features='lxml')a_tag = soup.select_one(".subject-item .info a")
link = a_tag["href"]
print( link)
使用get()方法
語法:tag.get(屬性名, 默認值)
適用場景:屬性可能不存在時,避免報錯(不存在則返回None或指定的默認值)。
示例:獲取小說名稱的鏈接
from bs4 import BeautifulSoupsoup = BeautifulSoup(markup=open(file='./豆瓣讀書/小說/0.html', mode='r', encoding='utf-8'), features='lxml')a_tag = soup.select_one(".subject-item .info a")
link = a_tag.get('href')
print( link)
打印結果如下所示:
https://book.douban.com/subject/36104107/
獲取所有屬性
語法:tag.attrs
適用場景:獲取標簽的所有屬性及值(返回字典)。
示例:獲取小說名稱所在a標簽的所有屬性
from bs4 import BeautifulSoupsoup = BeautifulSoup(markup=open(file='./豆瓣讀書/小說/0.html', mode='r', encoding='utf-8'), features='lxml')a_tag = soup.select_one(".subject-item .info a")
attrs = a_tag.attrs
print(attrs)
{'href': 'https://book.douban.com/subject/36104107/', 'title': '長安的荔枝', 'onclick': "moreurl(this,{i:'0',query:'',subject_id:'36104107',from:'book_subject_search'})"}
三、實戰:解析豆瓣讀書中小說的網頁
1. 提取網頁數據
代碼如下所示:
# 導入 BeautifulSoup 用于解析 HTML 內容
from bs4 import BeautifulSoup# 導入 Path 用于跨平臺安全地操作文件和目錄路徑
from pathlib import Path# 定義 HTML 文件所在的根目錄
file_dir = Path('./豆瓣讀書')# 使用 rglob 遞歸查找目錄中所有以 .html 結尾的文件(包括子目錄)
# 例如:./豆瓣讀書/page1.html, ./豆瓣讀書/2023/page2.html 等
html_files = file_dir.rglob('*.html')# 遍歷每一個找到的 HTML 文件路徑
for file_path in html_files:# 確保當前路徑是一個文件(而非目錄)if file_path.is_file():# 使用 open() 打開文件,指定編碼為 utf-8(防止中文亂碼)# 將文件內容傳遞給 BeautifulSoup,使用 'lxml' 作為解析器(速度快、容錯性好)soup = BeautifulSoup(markup=open(file=file_path, mode='r', encoding='utf-8'),features='lxml')# 使用 CSS 選擇器查找頁面中所有 class="subject-item" 的元素# 每個 subject-item 通常代表一本書的信息(如書名、作者、評分等)subject_items = soup.select('.subject-item')# 遍歷每一本書的信息條目for subject_item in subject_items:# 獲取書籍鏈接:查找 .info 下的第一個 <a> 標簽,提取其 href 屬性href = subject_item.select_one('.info a').get('href')# 獲取書籍標題:同上,提取 <a> 標簽的 title 屬性(鼠標懸停時顯示的完整書名)title = subject_item.select_one('.info a').get('title')# 獲取出版信息:查找 .info 下 class="pub" 的元素,獲取其文本內容并去除首尾空白pub = subject_item.select_one('.info .pub').string.strip()# 獲取評分:查找 class="rating_nums" 的元素(可能是評分 8.5、9.0 等)rating = subject_item.select_one('.info .rating_nums')# 安全提取評分文本:如果元素存在且有字符串內容,則去空白;否則設為空字符串rating = rating.string.strip() if rating and rating.string else ''# 獲取評分人數:查找 class="pl" 的元素(如 "(2048人評價)")rating_num = subject_item.select_one('.info .pl').string.strip()# 獲取書籍簡介(摘要):查找 .info 的直接子元素 <p>(通常為書籍簡介)plot = subject_item.select_one('.info > p')# 安全提取簡介文本plot = plot.string.strip() if plot and plot.string else ''# 查找紙質書購買鏈接:在 .info 下 class="buy-info" 中的 <a> 標簽paper_tag = subject_item.select_one('.info .buy-info > a')# 判斷是否找到購買鏈接標簽if paper_tag:# 提取購買鏈接的 href(跳轉地址)buylinks = paper_tag.get('href')# 提取鏈接上的文字(通常是價格,如 "¥39.5")paper_price = paper_tag.string.strip()else:# 如果沒有找到購買信息,則設為空buylinks = ''paper_price = ''# 輸出提取的關鍵信息(可根據需要保存到 CSV/數據庫等)print(href, title, pub, rating_num, paper_price, buylinks)
部分打印結果如下圖所示:

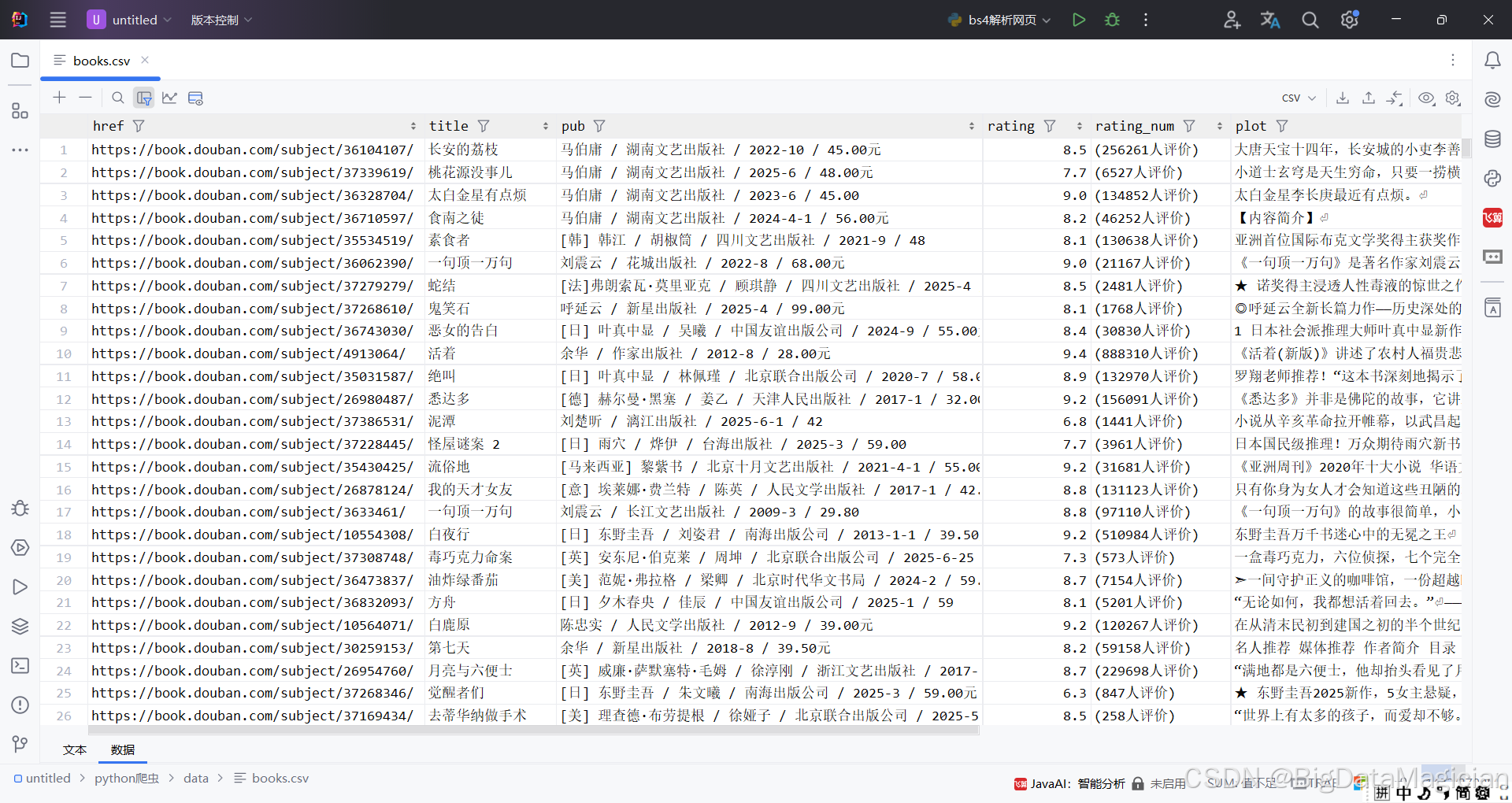
2. 保存數據到csv文件
代碼如下所示:
# 導入 BeautifulSoup 用于解析 HTML 內容
# 導入 Path 用于跨平臺安全地操作文件和目錄路徑
from pathlib import Pathimport pandas as pd
from bs4 import BeautifulSoup# 定義 HTML 文件所在的根目錄
file_dir = Path('./豆瓣讀書')# 使用 rglob 遞歸查找目錄中所有以 .html 結尾的文件(包括子目錄)
# 例如:./豆瓣讀書/page1.html, ./豆瓣讀書/2023/page2.html 等
html_files = file_dir.rglob('*.html')# 用于存儲所有書籍信息的列表(每本書是一個字典)
books = []# 遍歷每一個找到的 HTML 文件路徑
for file_path in html_files:# 確保當前路徑是一個文件(而非目錄)if file_path.is_file():# 使用 open() 打開文件,指定編碼為 utf-8(防止中文亂碼)# 將文件內容傳遞給 BeautifulSoup,使用 'lxml' 作為解析器(速度快、容錯性好)soup = BeautifulSoup(markup=open(file=file_path, mode='r', encoding='utf-8'),features='lxml')# 使用 CSS 選擇器查找頁面中所有 class="subject-item" 的元素# 每個 subject-item 通常代表一本書的信息(如書名、作者、評分等)subject_items = soup.select('.subject-item')# 遍歷每一本書的信息條目for subject_item in subject_items:# 獲取書籍鏈接:查找 .info 下的第一個 <a> 標簽,提取其 href 屬性href = subject_item.select_one('.info a').get('href')# 獲取書籍標題:同上,提取 <a> 標簽的 title 屬性(鼠標懸停時顯示的完整書名)title = subject_item.select_one('.info a').get('title')# 獲取出版信息:查找 .info 下 class="pub" 的元素,獲取其文本內容并去除首尾空白pub = subject_item.select_one('.info .pub').string.strip()# 獲取評分:查找 class="rating_nums" 的元素(可能是評分 8.5、9.0 等)rating = subject_item.select_one('.info .rating_nums')# 安全提取評分文本:如果元素存在且有字符串內容,則去空白;否則設為空字符串rating = rating.string.strip() if rating and rating.string else ''# 獲取評分人數:查找 class="pl" 的元素(如 "(2048人評價)")rating_num = subject_item.select_one('.info .pl').string.strip()# 獲取書籍簡介(摘要):查找 .info 的直接子元素 <p>(通常為書籍簡介)plot = subject_item.select_one('.info > p')# 安全提取簡介文本plot = plot.string.strip() if plot and plot.string else ''# 查找紙質書購買鏈接:在 .info 下 class="buy-info" 中的 <a> 標簽paper_tag = subject_item.select_one('.info .buy-info > a')# 判斷是否找到購買鏈接標簽if paper_tag:# 提取購買鏈接的 href(跳轉地址)buylinks = paper_tag.get('href')# 提取鏈接上的文字(通常是價格,如 "¥39.5")paper_price = paper_tag.string.strip()else:# 如果沒有找到購買信息,則設為空buylinks = ''paper_price = ''# 輸出提取的關鍵信息(可根據需要保存到 CSV/數據庫等)# print(href, title, pub, rating_num, paper_price, buylinks)# 將這本書的信息存為字典,加入列表books.append({'href': href,'title': title,'pub': pub,'rating': rating,'rating_num': rating_num,'plot': plot,'buylinks': buylinks,'paper_price': paper_price})
# 轉換為 DataFrame
books_df = pd.DataFrame(books)
# 創建保存目錄(如果不存在)
Path('./data').mkdir(parents=True, exist_ok=True)
# 保存為 CSV 文件
books_df.to_csv('./data/books.csv', index=False, encoding='utf-8-sig')
print(f"圖書數據已保存到:'./data/books.csv'")
保存后的部分數據如下圖所示:


 ——225 用隊列實現棧(C語言))





的方法)
)



)
![week1-[分支嵌套]公因數](http://pic.xiahunao.cn/week1-[分支嵌套]公因數)



)
