嘿,各位!今天咱們要來一場超級酷炫的多模態 Transformer 冒險之旅!想象一下,讓一個模型既能看懂圖片,又能理解文字,然后還能生成有趣的回答。聽起來是不是很像超級英雄的超能力?別急,咱們這就來實現它!
🧠 向所有學習者致敬!
“學習不是裝滿一桶水,而是點燃一把火。” —— 葉芝
我的博客主頁: https://lizheng.blog.csdn.net
🌐 歡迎點擊加入AI人工智能社區!
🚀 讓我們一起努力,共創AI未來! 🚀
好的!讓我來完成這個任務,我會用幽默風趣的筆觸把這篇文檔翻譯成符合 CSDN 博文要求的 Markdown 格式。現在就讓我們開始吧!Step 0: 準備工作 —— 導入庫、加載模型、定義數據、設置視覺模型
Step 0.1: 導入所需的庫
在這一部分,咱們要準備好所有需要的工具,就像準備一場冒險的裝備一樣。我們需要 torch 和它的子模塊(nn、F、optim),還有 torchvision 來獲取預訓練的 ResNet 模型,PIL(Pillow)用來加載圖片,math 用來做些數學計算,os 用來處理文件路徑,還有 numpy 來創建一些虛擬的圖片數據。這些工具就像是咱們的瑞士軍刀,有了它們,咱們就能搞定一切!
import torch
import torch.nn as nn
from torch.nn import functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from PIL import Image
import math
import os
import numpy as np # 用來創建虛擬圖片
為了保證代碼的可重復性,咱們還設置了隨機種子,這樣每次運行代碼的時候都能得到一樣的結果。這就好像是給代碼加了一個“魔法咒語”,讓每次運行都像復制粘貼一樣穩定。
torch.manual_seed(42) # 使用不同的種子會有不同的結果
np.random.seed(42)
接下來,咱們檢查一下 PyTorch 和 Torchvision 的版本,確保一切正常。這就好像是在出發前檢查一下裝備是否完好。
print(f"PyTorch version: {torch.__version__}")
print(f"Torchvision version: {torchvision.__version__}")
print("Libraries imported.")
最后,咱們設置一下設備(如果有 GPU 就用 GPU,沒有就用 CPU)。這就好像是給代碼選擇了一個超級加速器,讓運行速度飛起來!
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f"Using device: {device}")
Step 0.2: 加載預訓練的文本模型
咱們之前訓練了一個字符級的 Transformer 模型,現在要把它的權重和配置加載過來,這樣咱們的模型就有了處理文本的基礎。這就像是給咱們的多模態模型注入了一顆強大的文本處理“心臟”。
model_load_path = 'saved_models/transformer_model.pt'
if not os.path.exists(model_load_path):raise FileNotFoundError(f"Error: Model file not found at {model_load_path}. Please ensure 'transformer2.ipynb' was run and saved the model.")loaded_state_dict = torch.load(model_load_path, map_location=device)
print(f"Loaded state dictionary from '{model_load_path}'.")
從加載的模型中,咱們提取了超參數(比如 vocab_size、d_model、n_layers 等)和字符映射表(char_to_int 和 int_to_char)。這些參數就像是模型的“基因”,決定了它的行為和能力。
config = loaded_state_dict['config']
loaded_vocab_size = config['vocab_size']
d_model = config['d_model']
n_heads = config['n_heads']
n_layers = config['n_layers']
d_ff = config['d_ff']
loaded_block_size = config['block_size'] # 文本模型的最大序列長度
d_k = d_model // n_headschar_to_int = loaded_state_dict['tokenizer']['char_to_int']
int_to_char = loaded_state_dict['tokenizer']['int_to_char']
Step 0.3: 定義特殊標記并更新詞匯表
為了讓模型能夠處理多模態數據,咱們需要添加一些特殊的標記:
<IMG>:用來表示圖像輸入的占位符。<PAD>:用來填充序列,讓序列長度一致。<EOS>:表示句子結束的標記。
這就像是給模型的詞匯表添加了一些新的“魔法單詞”,讓模型能夠理解新的概念。
img_token = "<IMG>"
pad_token = "<PAD>"
eos_token = "<EOS>" # 句子結束標記
special_tokens = [img_token, pad_token, eos_token]
接下來,咱們把這些特殊標記添加到現有的字符映射表中,并更新詞匯表的大小。這就像是給模型的詞匯表擴容,讓它能夠容納更多的“魔法單詞”。
current_vocab_size = loaded_vocab_size
for token in special_tokens:if token not in char_to_int:char_to_int[token] = current_vocab_sizeint_to_char[current_vocab_size] = tokencurrent_vocab_size += 1vocab_size = current_vocab_size
pad_token_id = char_to_int[pad_token] # 保存 PAD 標記的 ID,后面要用
Step 0.4: 定義樣本多模態數據
咱們創建了一個小的、虛擬的(圖像,提示,回答)三元組數據集。為了簡單起見,咱們用 PIL/Numpy 生成了一些虛擬圖片(比如純色的方塊和圓形),并給它們配上了一些描述性的提示和回答。這就像是給模型準備了一些“練習題”,讓它能夠學習如何處理圖像和文本的組合。
sample_data_dir = "sample_multimodal_data"
os.makedirs(sample_data_dir, exist_ok=True)image_paths = {"red": os.path.join(sample_data_dir, "red_square.png"),"blue": os.path.join(sample_data_dir, "blue_square.png"),"green": os.path.join(sample_data_dir, "green_circle.png") # 加入形狀變化
}# 創建紅色方塊
img_red = Image.new('RGB', (64, 64), color = 'red')
img_red.save(image_paths["red"])
# 創建藍色方塊
img_blue = Image.new('RGB', (64, 64), color = 'blue')
img_blue.save(image_paths["blue"])
# 創建綠色圓形(用 PIL 的繪圖功能近似繪制)
img_green = Image.new('RGB', (64, 64), color = 'white')
from PIL import ImageDraw
draw = ImageDraw.Draw(img_green)
draw.ellipse((4, 4, 60, 60), fill='green', outline='green')
img_green.save(image_paths["green"])
接下來,咱們定義了一些數據樣本,每個樣本包括一個圖片路徑、一個提示和一個回答。這就像是給模型準備了一些“問答對”,讓它能夠學習如何根據圖片和提示生成正確的回答。
sample_training_data = [{"image_path": image_paths["red"], "prompt": "What color is the shape?", "response": "red." + eos_token},{"image_path": image_paths["blue"], "prompt": "Describe the image.", "response": "a blue square." + eos_token},{"image_path": image_paths["green"], "prompt": "What shape is shown?", "response": "a green circle." + eos_token},{"image_path": image_paths["red"], "prompt": "Is it a circle?", "response": "no, it is a square." + eos_token},{"image_path": image_paths["blue"], "prompt": "What is the main color?", "response": "blue." + eos_token},{"image_path": image_paths["green"], "prompt": "Describe this.", "response": "a circle, it is green." + eos_token}
]
Step 0.5: 加載預訓練的視覺模型(特征提取器)
咱們從 torchvision 加載了一個預訓練的 ResNet-18 模型,并移除了它的最后分類層(fc)。這就像是給模型安裝了一個“視覺眼睛”,讓它能夠“看”圖片并提取出有用的特征。
vision_model = torchvision.models.resnet18(weights=torchvision.models.ResNet18_Weights.DEFAULT)
vision_feature_dim = vision_model.fc.in_features # 獲取原始 fc 層的輸入維度
vision_model.fc = nn.Identity() # 替換分類器為恒等映射
vision_model = vision_model.to(device)
vision_model.eval() # 設置為評估模式
Step 0.6: 定義圖像預處理流程
在把圖片喂給 ResNet 模型之前,咱們需要對圖片進行預處理。這就像是給圖片“化妝”,讓它符合模型的口味。咱們用 torchvision.transforms 來定義一個預處理流程,包括調整圖片大小、裁剪、轉換為張量并歸一化。
image_transforms = transforms.Compose([transforms.Resize(256), # 調整圖片大小,短邊為 256transforms.CenterCrop(224), # 中心裁剪 224x224 的正方形transforms.ToTensor(), # 轉換為 PyTorch 張量(0-1 范圍)transforms.Normalize(mean=[0.485, 0.456, 0.406], # 使用 ImageNet 的均值std=[0.229, 0.224, 0.225]) # 使用 ImageNet 的標準差
])
Step 0.7: 定義新的超參數
咱們定義了一些新的超參數,專門用于多模態設置。這就像是給模型設置了一些新的“規則”,讓它知道如何處理圖像和文本的組合。
block_size = 64 # 設置多模態序列的最大長度
num_img_tokens = 1 # 使用 1 個 <IMG> 標記來表示圖像特征
learning_rate = 3e-4 # 保持 AdamW 的學習率不變
batch_size = 4 # 由于可能占用更多內存,減小批量大小
epochs = 2000 # 增加訓練周期
eval_interval = 500
最后,咱們重新創建了一個因果掩碼,以適應新的序列長度。這就像是給模型的注意力機制設置了一個“遮擋板”,讓它只能看到它應該看到的部分。
causal_mask = torch.tril(torch.ones(block_size, block_size, device=device)).view(1, 1, block_size, block_size)
Step 1: 數據準備用于多模態訓練
Step 1.1: 提取樣本數據的圖像特征
咱們遍歷 sample_training_data,對于每個唯一的圖像路徑,加載圖像,應用定義的變換,并通過凍結的 vision_model 獲取特征向量。這就像是給每個圖像提取了一個“特征指紋”,讓模型能夠理解圖像的內容。
extracted_image_features = {} # 用來存儲 {image_path: feature_tensor}unique_image_paths = set(d["image_path"] for d in sample_training_data)
print(f"Found {len(unique_image_paths)} unique images to process.")for img_path in unique_image_paths:try:img = Image.open(img_path).convert('RGB') # 確保圖像是 RGB 格式except FileNotFoundError:print(f"Error: Image file not found at {img_path}. Skipping.")continueimg_tensor = image_transforms(img).unsqueeze(0).to(device) # 應用預處理并添加批量維度with torch.no_grad():feature_vector = vision_model(img_tensor) # 提取特征向量extracted_image_features[img_path] = feature_vector.squeeze(0) # 去掉批量維度并存儲print(f" Extracted features for '{os.path.basename(img_path)}', shape: {extracted_image_features[img_path].shape}")
Step 1.2: 對提示和回答進行分詞
咱們用更新后的 char_to_int 映射(現在包括 <IMG>、<PAD>、<EOS>)將文本提示和回答轉換為整數 ID 序列。這就像是把文本翻譯成模型能夠理解的“數字語言”。
tokenized_samples = []
for sample in sample_training_data:prompt_ids = [char_to_int[ch] for ch in sample["prompt"]]response_text = sample["response"]if response_text.endswith(eos_token):response_text_without_eos = response_text[:-len(eos_token)]response_ids = [char_to_int[ch] for ch in response_text_without_eos] + [char_to_int[eos_token]]else:response_ids = [char_to_int[ch] for ch in response_text]tokenized_samples.append({"image_path": sample["image_path"],"prompt_ids": prompt_ids,"response_ids": response_ids})
Step 1.3: 創建填充的輸入/目標序列和掩碼
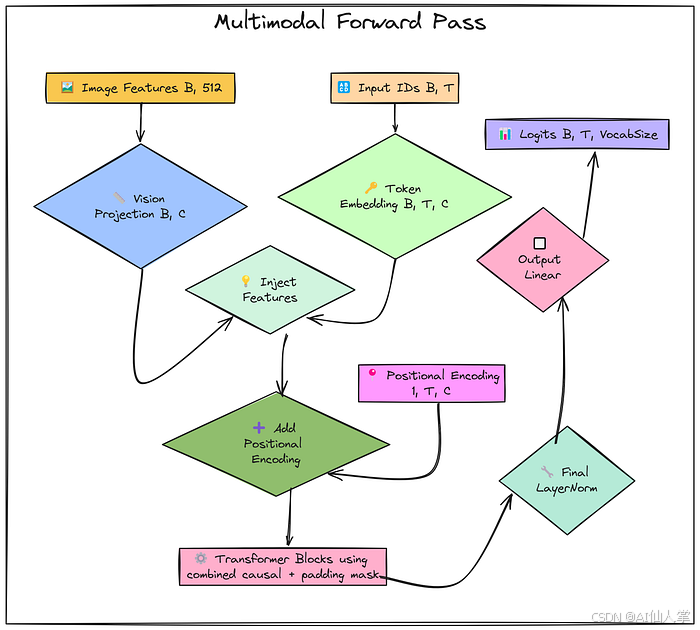
咱們把圖像表示、分詞后的提示和分詞后的回答組合成一個輸入序列,為 Transformer 準備。這就像是把圖像和文本“打包”成一個序列,讓模型能夠同時處理它們。
prepared_sequences = []
ignore_index = -100 # 用于 CrossEntropyLoss 的忽略索引for sample in tokenized_samples:img_ids = [char_to_int[img_token]] * num_img_tokensinput_ids_no_pad = img_ids + sample["prompt_ids"] + sample["response_ids"][:-1] # 輸入預測回答target_ids_no_pad = ([ignore_index] * len(img_ids)) + ([ignore_index] * len(sample["prompt_ids"])) + sample["response_ids"]current_len = len(input_ids_no_pad)pad_len = block_size - current_lenif pad_len < 0:print(f"Warning: Sample sequence length ({current_len}) exceeds block_size ({block_size}). Truncating.")input_ids = input_ids_no_pad[:block_size]target_ids = target_ids_no_pad[:block_size]pad_len = 0current_len = block_sizeelse:input_ids = input_ids_no_pad + ([pad_token_id] * pad_len)target_ids = target_ids_no_pad + ([ignore_index] * pad_len)attention_mask = ([1] * current_len) + ([0] * pad_len)prepared_sequences.append({"image_path": sample["image_path"],"input_ids": torch.tensor(input_ids, dtype=torch.long),"target_ids": torch.tensor(target_ids, dtype=torch.long),"attention_mask": torch.tensor(attention_mask, dtype=torch.long)})
最后,咱們把所有的序列組合成張量,方便后續的批量處理。這就像是把所有的“練習題”打包成一個整齊的“試卷”。
all_input_ids = torch.stack([s['input_ids'] for s in prepared_sequences])
all_target_ids = torch.stack([s['target_ids'] for s in prepared_sequences])
all_attention_masks = torch.stack([s['attention_mask'] for s in prepared_sequences])
all_image_paths = [s['image_path'] for s in prepared_sequences]
Step 2: 模型調整和初始化
Step 2.1: 重新初始化嵌入層和輸出層
由于咱們添加了特殊標記(<IMG>、<PAD>、<EOS>),詞匯表大小發生了變化。這就像是給模型的詞匯表“擴容”,咱們需要重新初始化嵌入層和輸出層,以適應新的詞匯表大小。
new_token_embedding_table = nn.Embedding(vocab_size, d_model).to(device)
original_weights = loaded_state_dict['token_embedding_table']['weight'][:loaded_vocab_size, :]
with torch.no_grad():new_token_embedding_table.weight[:loaded_vocab_size, :] = original_weights
token_embedding_table = new_token_embedding_table
輸出層也需要重新初始化,以適應新的詞匯表大小。
new_output_linear_layer = nn.Linear(d_model, vocab_size).to(device)
original_out_weight = loaded_state_dict['output_linear_layer']['weight'][:loaded_vocab_size, :]
original_out_bias = loaded_state_dict['output_linear_layer']['bias'][:loaded_vocab_size]
with torch.no_grad():new_output_linear_layer.weight[:loaded_vocab_size, :] = original_out_weightnew_output_linear_layer.bias[:loaded_vocab_size] = original_out_bias
output_linear_layer = new_output_linear_layer
Step 2.2: 初始化視覺投影層
咱們創建了一個新的線性層,用來將提取的圖像特征投影到 Transformer 的隱藏維度(d_model)。這就像是給圖像特征和文本特征之間架起了一座“橋梁”,讓它們能夠互相理解。
vision_projection_layer = nn.Linear(vision_feature_dim, d_model).to(device)
Step 2.3: 加載現有的 Transformer 塊層
咱們從加載的狀態字典中重新加載 Transformer 塊的核心組件(LayerNorms、QKV/Output Linears for MHA、FFN Linears)。這就像是把之前訓練好的模型的“核心部件”重新組裝起來。
layer_norms_1 = []
layer_norms_2 = []
mha_qkv_linears = []
mha_output_linears = []
ffn_linear_1 = []
ffn_linear_2 = []for i in range(n_layers):ln1 = nn.LayerNorm(d_model).to(device)ln1.load_state_dict(loaded_state_dict['layer_norms_1'][i])layer_norms_1.append(ln1)qkv_linear = nn.Linear(d_model, 3 * d_model, bias=False).to(device)qkv_linear.load_state_dict(loaded_state_dict['mha_qkv_linears'][i])mha_qkv_linears.append(qkv_linear)output_linear_mha = nn.Linear(d_model, d_model).to(device)output_linear_mha.load_state_dict(loaded_state_dict['mha_output_linears'][i])mha_output_linears.append(output_linear_mha)ln2 = nn.LayerNorm(d_model).to(device)ln2.load_state_dict(loaded_state_dict['layer_norms_2'][i])layer_norms_2.append(ln2)lin1 = nn.Linear(d_model, d_ff).to(device)lin1.load_state_dict(loaded_state_dict['ffn_linear_1'][i])ffn_linear_1.append(lin1)lin2 = nn.Linear(d_ff, d_model).to(device)lin2.load_state_dict(loaded_state_dict['ffn_linear_2'][i])ffn_linear_2.append(lin2)
最后,咱們加載了最終的 LayerNorm 和位置編碼。這就像是給模型的“大腦”安裝了最后的“保護層”。
final_layer_norm = nn.LayerNorm(d_model).to(device)
final_layer_norm.load_state_dict(loaded_state_dict['final_layer_norm'])
positional_encoding = loaded_state_dict['positional_encoding'].to(device)
Step 2.4: 定義優化器和損失函數
咱們收集了所有需要訓練的參數,包括新初始化的視覺投影層和重新調整大小的嵌入/輸出層。這就像是給模型的“訓練引擎”添加了所有的“燃料”。
all_trainable_parameters = list(token_embedding_table.parameters())
all_trainable_parameters.extend(list(vision_projection_layer.parameters()))
for i in range(n_layers):all_trainable_parameters.extend(list(layer_norms_1[i].parameters()))all_trainable_parameters.extend(list(mha_qkv_linears[i].parameters()))all_trainable_parameters.extend(list(mha_output_linears[i].parameters()))all_trainable_parameters.extend(list(layer_norms_2[i].parameters()))all_trainable_parameters.extend(list(ffn_linear_1[i].parameters()))all_trainable_parameters.extend(list(ffn_linear_2[i].parameters()))
all_trainable_parameters.extend(list(final_layer_norm.parameters()))
all_trainable_parameters.extend(list(output_linear_layer.parameters()))
接下來,咱們定義了 AdamW 優化器來管理這些參數,并定義了 Cross-Entropy 損失函數,確保忽略填充標記和非目標標記(比如提示標記)。這就像是給模型的訓練過程設置了一個“指南針”,讓它知道如何朝著正確的方向前進。
optimizer = optim.AdamW(all_trainable_parameters, lr=learning_rate)
criterion = nn.CrossEntropyLoss(ignore_index=ignore_index)
Step 3: 多模態訓練循環(內聯)
Step 3.1: 訓練循環結構
咱們開始訓練模型啦!在每個訓練周期中,咱們隨機選擇一批數據,提取對應的圖像特征、輸入 ID、目標 ID 和注意力掩碼,然后進行前向傳播、計算損失、反向傳播和參數更新。這就像是讓模型在“訓練場”上反復練習,直到它能夠熟練地處理圖像和文本的組合。
losses = []for epoch in range(epochs):indices = torch.randint(0, num_sequences_available, (batch_size,))xb_ids = all_input_ids[indices].to(device)yb_ids = all_target_ids[indices].to(device)batch_masks = all_attention_masks[indices].to(device)batch_img_paths = [all_image_paths[i] for i in indices.tolist()]try:batch_img_features = torch.stack([extracted_image_features[p] for p in batch_img_paths]).to(device)except KeyError as e:print(f"Error: Missing extracted feature for image path {e}. Ensure Step 1.1 completed correctly. Skipping epoch.")continueB, T = xb_ids.shapeC = d_modelprojected_img_features = vision_projection_layer(batch_img_features)projected_img_features = projected_img_features.unsqueeze(1)text_token_embeddings = token_embedding_table(xb_ids)combined_embeddings = text_token_embeddings.clone()combined_embeddings[:, 0:num_img_tokens, :] = projected_img_featurespos_enc_slice = positional_encoding[:, :T, :]x = combined_embeddings + pos_enc_slicepadding_mask_expanded = batch_masks.unsqueeze(1).unsqueeze(2)combined_attn_mask = causal_mask[:,:,:T,:T] * padding_mask_expandedfor i in range(n_layers):x_input_block = xx_ln1 = layer_norms_1[i](x_input_block)qkv = mha_qkv_linears[i](x_ln1)qkv = qkv.view(B, T, n_heads, 3 * d_k).permute(0, 2, 1, 3)q, k, v = qkv.chunk(3, dim=-1)attn_scores = (q @ k.transpose(-2, -1)) * (d_k ** -0.5)attn_scores_masked = attn_scores.masked_fill(combined_attn_mask == 0, float('-inf'))attention_weights = F.softmax(attn_scores_masked, dim=-1)attention_weights = torch.nan_to_num(attention_weights)attn_output = attention_weights @ vattn_output = attn_output.permute(0, 2, 1, 3).contiguous().view(B, T, C)mha_result = mha_output_linears[i](attn_output)x = x_input_block + mha_resultx_input_ffn = xx_ln2 = layer_norms_2[i](x_input_ffn)ffn_hidden = ffn_linear_1[i](x_ln2)ffn_activated = F.relu(ffn_hidden)ffn_output = ffn_linear_2[i](ffn_activated)x = x_input_ffn + ffn_outputfinal_norm_output = final_layer_norm(x)logits = output_linear_layer(final_norm_output)B_loss, T_loss, V_loss = logits.shapeif yb_ids.size(1) != T_loss:if yb_ids.size(1) > T_loss:targets_reshaped = yb_ids[:, :T_loss].contiguous().view(-1)else:padded_targets = torch.full((B_loss, T_loss), ignore_index, device=device)padded_targets[:, :yb_ids.size(1)] = yb_idstargets_reshaped = padded_targets.view(-1)else:targets_reshaped = yb_ids.view(-1)logits_reshaped = logits.view(-1, V_loss)loss = criterion(logits_reshaped, targets_reshaped)optimizer.zero_grad()if not torch.isnan(loss) and not torch.isinf(loss):loss.backward()optimizer.step()else:print(f"Warning: Invalid loss detected (NaN or Inf) at epoch {epoch+1}. Skipping optimizer step.")loss = Noneif loss is not None:current_loss = loss.item()losses.append(current_loss)if epoch % eval_interval == 0 or epoch == epochs - 1:print(f" Epoch {epoch+1}/{epochs}, Loss: {current_loss:.4f}")elif epoch % eval_interval == 0 or epoch == epochs - 1:print(f" Epoch {epoch+1}/{epochs}, Loss: Invalid (NaN/Inf)")
最后,咱們繪制了訓練損失曲線,以直觀地展示模型的訓練過程。這就像是給模型的訓練過程拍了一張“進度照”,讓咱們能夠清楚地看到它的進步。
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 3))
plt.plot(losses)
plt.title("Training Loss Over Epochs")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.grid(True)
plt.show()
Step 4: 多模態生成(內聯)
Step 4.1: 準備輸入圖像和提示
咱們選擇了一個圖像(比如綠色圓形)和一個文本提示(比如“Describe this image:”),對圖像進行預處理,提取其特征,并將其投影到訓練好的視覺投影層。這就像是給模型準備了一個“輸入套餐”,讓它能夠根據圖像和提示生成回答。
test_image_path = image_paths["green"]
test_prompt_text = "Describe this image: "
接下來,咱們對圖像進行預處理,提取特征,并將其投影到訓練好的視覺投影層。
try:test_img = Image.open(test_image_path).convert('RGB')test_img_tensor = image_transforms(test_img).unsqueeze(0).to(device)with torch.no_grad():test_img_features_raw = vision_model(test_img_tensor)vision_projection_layer.eval()with torch.no_grad():test_img_features_projected = vision_projection_layer(test_img_features_raw)print(f" Processed image: '{os.path.basename(test_image_path)}'")print(f" Projected image features shape: {test_img_features_projected.shape}")
except FileNotFoundError:print(f"Error: Test image not found at {test_image_path}. Cannot generate.")test_img_features_projected = None
最后,咱們對提示進行分詞,并將其與圖像特征組合成初始上下文。這就像是把圖像和提示“打包”成一個序列,讓模型能夠開始生成回答。
img_id = char_to_int[img_token]
prompt_ids = [char_to_int[ch] for ch in test_prompt_text]
initial_context_ids = torch.tensor([[img_id] * num_img_tokens + prompt_ids], dtype=torch.long, device=device)
print(f" Tokenized prompt: '{test_prompt_text}' -> {initial_context_ids.tolist()}")
Step 4.2: 生成循環(自回歸解碼)
咱們開始生成回答啦!在每個步驟中,咱們準備當前的輸入序列,提取嵌入,注入圖像特征,添加位置編碼,創建注意力掩碼,然后通過 Transformer 塊進行前向傳播。這就像是讓模型根據當前的“輸入套餐”生成下一個“魔法單詞”。
generated_sequence_ids = initial_context_ids
with torch.no_grad():for _ in range(max_new_tokens):current_ids_context = generated_sequence_ids[:, -block_size:]B_gen, T_gen = current_ids_context.shapeC_gen = d_modelcurrent_token_embeddings = token_embedding_table(current_ids_context)gen_combined_embeddings = current_token_embeddingsif img_id in current_ids_context[0].tolist():img_token_pos = 0gen_combined_embeddings[:, img_token_pos:(img_token_pos + num_img_tokens), :] = test_img_features_projectedpos_enc_slice_gen = positional_encoding[:, :T_gen, :]x_gen = gen_combined_embeddings + pos_enc_slice_gengen_causal_mask = causal_mask[:,:,:T_gen,:T_gen]for i in range(n_layers):x_input_block_gen = x_genx_ln1_gen = layer_norms_1[i](x_input_block_gen)qkv_gen = mha_qkv_linears[i](x_ln1_gen)qkv_gen = qkv_gen.view(B_gen, T_gen, n_heads, 3 * d_k).permute(0, 2, 1, 3)q_gen, k_gen, v_gen = qkv_gen.chunk(3, dim=-1)attn_scores_gen = (q_gen @ k_gen.transpose(-2, -1)) * (d_k ** -0.5)attn_scores_masked_gen = attn_scores_gen.masked_fill(gen_causal_mask == 0, float('-inf'))attention_weights_gen = F.softmax(attn_scores_masked_gen, dim=-1)attention_weights_gen = torch.nan_to_num(attention_weights_gen)attn_output_gen = attention_weights_gen @ v_genattn_output_gen = attn_output_gen.permute(0, 2, 1, 3).contiguous().view(B_gen, T_gen, C_gen)mha_result_gen = mha_output_linears[i](attn_output_gen)x_gen = x_input_block_gen + mha_result_genx_input_ffn_gen = x_genx_ln2_gen = layer_norms_2[i](x_input_ffn_gen)ffn_hidden_gen = ffn_linear_1[i](x_ln2_gen)ffn_activated_gen = F.relu(ffn_hidden_gen)ffn_output_gen = ffn_linear_2[i](ffn_activated_gen)x_gen = x_input_ffn_gen + ffn_output_genfinal_norm_output_gen = final_layer_norm(x_gen)logits_gen = output_linear_layer(final_norm_output_gen)logits_last_token = logits_gen[:, -1, :]probs = F.softmax(logits_last_token, dim=-1)next_token_id = torch.multinomial(probs, num_samples=1)generated_sequence_ids = torch.cat((generated_sequence_ids, next_token_id), dim=1)if next_token_id.item() == eos_token_id:print(" <EOS> token generated. Stopping.")breakelse:print(f" Reached max generation length ({max_new_tokens}). Stopping.")
Step 4.3: 解碼生成的序列
最后,咱們把生成的序列 ID 轉換回人類可讀的字符串。這就像是把模型生成的“魔法單詞”翻譯回人類的語言。
final_ids_list = generated_sequence_ids[0].tolist()
decoded_text = ""
for id_val in final_ids_list:if id_val in int_to_char:decoded_text += int_to_char[id_val]else:decoded_text += f"[UNK:{id_val}]"print(f"--- Final Generated Output ---")
print(f"Image: {os.path.basename(test_image_path)}")
response_start_index = num_img_tokens + len(test_prompt_text)
print(f"Prompt: {test_prompt_text}")
print(f"Generated Response: {decoded_text[response_start_index:]}")
Step 6: 保存模型狀態(可選)
為了保存咱們訓練好的多模態模型,咱們需要把所有模型組件和配置保存到一個字典中,然后用 torch.save() 保存到文件中。這就像是給模型拍了一張“全家福”,讓它能夠隨時被加載和使用。
save_dir = 'saved_models'
os.makedirs(save_dir, exist_ok=True)
save_path = os.path.join(save_dir, 'multimodal_model.pt')multimodal_state_dict = {'config': {'vocab_size': vocab_size,'d_model': d_model,'n_heads': n_heads,'n_layers': n_layers,'d_ff': d_ff,'block_size': block_size,'num_img_tokens': num_img_tokens,'vision_feature_dim': vision_feature_dim},'tokenizer': {'char_to_int': char_to_int,'int_to_char': int_to_char},'token_embedding_table': token_embedding_table.state_dict(),'vision_projection_layer': vision_projection_layer.state_dict(),'positional_encoding': positional_encoding,'layer_norms_1': [ln.state_dict() for ln in layer_norms_1],'mha_qkv_linears': [l.state_dict() for l in mha_qkv_linears],'mha_output_linears': [l.state_dict() for l in mha_output_linears],'layer_norms_2': [ln.state_dict() for ln in layer_norms_2],'ffn_linear_1': [l.state_dict() for l in ffn_linear_1],'ffn_linear_2': [l.state_dict() for l in ffn_linear_2],'final_layer_norm': final_layer_norm.state_dict(),'output_linear_layer': output_linear_layer.state_dict()
}torch.save(multimodal_state_dict, save_path)
print(f"Multi-modal model saved to {save_path}")
加載保存的多模態模型
加載保存的模型狀態字典后,咱們可以根據配置和 tokenizer 重建模型組件,并加載它們的狀態字典。這就像是把之前保存的“全家福”重新組裝起來,讓模型能夠隨時被使用。
model_load_path = 'saved_models/multimodal_model.pt'
loaded_state_dict = torch.load(model_load_path, map_location=device)
print(f"Loaded state dictionary from '{model_load_path}'.")config = loaded_state_dict['config']
vocab_size = config['vocab_size']
d_model = config['d_model']
n_heads = config['n_heads']
n_layers = config['n_layers']
d_ff = config['d_ff']
block_size = config['block_size']
num_img_tokens = config['num_img_tokens']
vision_feature_dim = config['vision_feature_dim']
d_k = d_model // n_headschar_to_int = loaded_state_dict['tokenizer']['char_to_int']
int_to_char = loaded_state_dict['tokenizer']['int_to_char']causal_mask = torch.tril(torch.ones(block_size, block_size, device=device)).view(1, 1, block_size, block_size)token_embedding_table = nn.Embedding(vocab_size, d_model).to(device)
token_embedding_table.load_state_dict(loaded_state_dict['token_embedding_table'])vision_projection_layer = nn.Linear(vision_feature_dim, d_model).to(device)
vision_projection_layer.load_state_dict(loaded_state_dict['vision_projection_layer'])positional_encoding = loaded_state_dict['positional_encoding'].to(device)layer_norms_1 = []
mha_qkv_linears = []
mha_output_linears = []
layer_norms_2 = []
ffn_linear_1 = []
ffn_linear_2 = []for i in range(n_layers):ln1 = nn.LayerNorm(d_model).to(device)ln1.load_state_dict(loaded_state_dict['layer_norms_1'][i])layer_norms_1.append(ln1)qkv_dict = loaded_state_dict['mha_qkv_linears'][i]has_qkv_bias = 'bias' in qkv_dictqkv = nn.Linear(d_model, 3 * d_model, bias=has_qkv_bias).to(device)qkv.load_state_dict(qkv_dict)mha_qkv_linears.append(qkv)out_dict = loaded_state_dict['mha_output_linears'][i]has_out_bias = 'bias' in out_dictout = nn.Linear(d_model, d_model, bias=has_out_bias).to(device)out.load_state_dict(out_dict)mha_output_linears.append(out)ln2 = nn.LayerNorm(d_model).to(device)ln2.load_state_dict(loaded_state_dict['layer_norms_2'][i])layer_norms_2.append(ln2)ff1_dict = loaded_state_dict['ffn_linear_1'][i]has_ff1_bias = 'bias' in ff1_dictff1 = nn.Linear(d_model, d_ff, bias=has_ff1_bias).to(device)ff1.load_state_dict(ff1_dict)ffn_linear_1.append(ff1)ff2_dict = loaded_state_dict['ffn_linear_2'][i]has_ff2_bias = 'bias' in ff2_dictff2 = nn.Linear(d_ff, d_model, bias=has_ff2_bias).to(device)ff2.load_state_dict(ff2_dict)ffn_linear_2.append(ff2)final_layer_norm = nn.LayerNorm(d_model).to(device)
final_layer_norm.load_state_dict(loaded_state_dict['final_layer_norm'])output_dict = loaded_state_dict['output_linear_layer']
has_output_bias = 'bias' in output_dict
output_linear_layer = nn.Linear(d_model, vocab_size, bias=has_output_bias).to(device)
output_linear_layer.load_state_dict(output_dict)print("Multi-modal model components loaded successfully.")
使用加載的模型進行推理
加載模型后,咱們可以用它來進行推理。這就像是讓模型根據圖像和提示生成回答,就像一個超級智能的機器人一樣。
def generate_with_image(image_path, prompt, max_new_tokens=50):"""Generate text response for an image and prompt"""token_embedding_table.eval()vision_projection_layer.eval()for i in range(n_layers):layer_norms_1[i].eval()mha_qkv_linears[i].eval()mha_output_linears[i].eval()layer_norms_2[i].eval()ffn_linear_1[i].eval()ffn_linear_2[i].eval()final_layer_norm.eval()output_linear_layer.eval()image = Image.open(image_path).convert('RGB')img_tensor = image_transforms(image).unsqueeze(0).to(device)with torch.no_grad():img_features_raw = vision_model(img_tensor)img_features_projected = vision_projection_layer(img_features_raw)img_id = char_to_int[img_token]prompt_ids = [char_to_int[ch] for ch in prompt]context_ids = torch.tensor([[img_id] + prompt_ids], dtype=torch.long, device=device)for _ in range(max_new_tokens):context_ids = context_ids[:, -block_size:]# [Generation logic goes here - follow the same steps as in Step 4.2]# [Logic to get next token]# [Logic to check for EOS and break]# [Logic to decode and return the result]
結語
通過這篇文章,咱們實現了一個端到端的多模態 Transformer 模型,能夠處理圖像和文本的組合,并生成有趣的回答。雖然這個實現比較基礎,但它展示了如何將視覺和語言信息融合在一起,為更復雜的應用奠定了基礎。希望這篇文章能激發你對多模態人工智能的興趣,讓你也能創造出自己的超級智能模型!
含萬字文檔+運行說明文檔)


 - sql解析器(番外)- *號的處理)




)






)



