Laplacian Pyramid Network With HybridEncoder and Edge Guidance for RemoteSensing Change Detection
0、摘要
遙感變化檢測(CD)是觀測和分析動態土地覆蓋變化的一項關鍵任務。許多基于深度學習的CD方法表現出強大的性能,但它們的有效性受到編碼器選擇和準確劃定變化區域邊緣的挑戰的影響。在本文中,我們提出了一種混合編碼器和邊緣引導的拉普拉斯金字塔網絡(HE-LPNet)來解決這些問題。具體來說,混合編碼器結合了卷積神經網絡和變壓器的優勢,從而提取出更細粒度的特征。同時,混合編碼器結合了視覺基礎模型,從而增強了整體模型的泛化。 除了特征提取,圖像被處理以生成拉普拉斯金字塔,然后與混合編碼器提取的特征融合,以增強像素級的顯著特征。在解碼器階段,加權引導注意力被設計為選擇性地將通道和空間注意力應用于融合特征,提高網絡區分變化區域的能力。此外,我們提出了邊緣引導損失來捕獲變化區域的邊緣信息。為了驗證所提出的HE-LPNet的有效性,在三個高分辨率遙感CD數據集上進行了廣泛的實驗。實驗結果表明,我們的方法優于其他最先進的CD方法。
索引術語-變化檢測(CD)、邊緣引導、混合編碼器、拉普拉斯金字塔(LP)、遙感(RS)imag
1、引言
????????遙感變化檢測的目的是識別同一地理區域在不同時間段[1]、[2]拍攝的兩幅圖像之間的變化,這一過程在火災檢測、環境監測[3]、災害監測[4]、城市變化分析[5]和土地管理[6]等不同領域具有重要意義。然而,由于光照變化、配準錯誤、對象比例變化和類別不平衡等各種不利條件,處理這項任務是具有挑戰性的。?因此,已經提出了許多方法來緩解這些問題,包括使用先進的深度學習技術[7]。
????????近年來,卷積神經網絡(CNN)在計算機視覺[8]、[9]、[10]以及遙感CD[11]、[12]、[13]、[14]、[15]、[16]、[17]等領域得到了廣泛的應用。大多數CD方法依賴于聯合國技術評估委員會[11]或其各種改編[13]、[15]、[18]。與傳統方法相比,這些方法具有多種優勢,例如更高的精確度、增強的降噪能力和更好的泛化能力[19]。同時,在自然語言處理領域,基于自我注意機制的轉換器[20]也取得了顯著的成功。視覺轉換器(VIT)[21]代表了將變壓器編碼器應用于圖像分類領域的第一次嘗試,展示了與傳統CNN方法相當的性能。該轉換器具有遠程信息交互和語義表示能力,已在CD中得到應用。雙時相圖像轉換器(BIT)[22]代表了將該轉換器應用于遙感CD的開創性工作,它使用雙時相轉換器來捕獲時空上下文。隨后,許多變壓器架構,如SwinSUNet[23]、ChangeFormer[24]、TransUNetCD[25]和輕量級結構感知轉換器(LSAT)[26]被提出以應對遙感CD的挑戰,表現出穩健的性能。
????????近年來,視覺基礎模型在計算機視覺領域引起了廣泛的關注。一個值得注意的例子是任意分割模型(SAM)[27],這是一個視覺基礎模型,以其在圖像分割中的卓越性能而聞名。SAM獨特的設計使其能夠在用戶提供的提示指導下,準確地分割圖像中任何特定的感興趣對象,從而提供更高的靈活性和適應性。SAM獨特的架構有助于跨不同場景進行更準確的細分,超越了專業模型的能力。雖然SAM在自然圖像上表現出穩健的性能,但最近的研究表明,當應用于遙感圖像時,其有效性有所下降[28]。這一下降是由于自然圖像和遙感圖像之間的數據域差距很大,導致遙感領域內不同數據集和模式的分割性能不一致。雖然在遙感領域已經提出了幾種基于SAM的方法[28],[29],其在遙感CD背景下的充分探索仍然不完整。
????????現有的CD遙感方法具有一定的解決問題的能力,但仍存在一些不足之處,需要進一步探索。首先,如圖1所示,高分辨率遙感圖像中變化目標的大小差異很大,從汽車這樣的微小變化到農田等更大的變化。然而,現有的大多數CD方法只使用基于CNN或轉換器體系結構的特征提取,這帶來了一些挑戰。基于CNN的方法中卷積的局部化性質限制了它們捕獲遠程依賴關系的能力。由于其有限的空間范圍,小的卷積核將網絡的注意力引導到局部特征上,無意中將廣泛的全局特征降級為次要位置。對于遙感CD,由于變化區域的大小變化很大,可靠的檢測需要遠距離的全球信息。雖然基于轉換器的方法擅長對長期依賴關系進行建模,但它們往往通過將圖像轉換為一維符號來忽略空間信息。盡管在Transformers中包含了位置編碼,但這些方法在實現穩健的局部特征學習方面仍然面臨挑戰,并且無法捕獲多尺度通道特征依賴。因此,有必要探索CNN和Transform在特征提取中的結合,以發揮它們各自的優勢。其次,盡管目前的遙感圖像表現出足夠的清晰度,但與自然圖像相比,它們仍然存在不足。這一不足之處使準確劃定變化區邊界變得復雜。一些文獻[30]、[31]、[32]使用多層特征融合來應對這一挑戰。然而,如前所述,僅依靠CNN或變換作為特征提取工具是有缺點的,特別是在提取特征時沒有充分考慮邊緣信息。因此,這些方法不能提供全面的解決方案。
????????為了解決上述問題,在本文中,我們提出了一種具有混合編碼器的拉普拉斯金字塔(LP)網絡和邊緣引導(HE-LPNet)。具體來說,我們首先提出了一種高效的混合編碼器,它將CNN的強感應偏差與多尺度注意力(MSA)和Transform的標記化注意力相結合。這使得能夠從不同方面聚合特征提取能力。為了利用VFM對于CD的能力,同時保留足夠的可學習參數(Params)以促進域適配,我們采用MobileSAM[34]作為混合編碼器中的transformer模塊。MobileSAM是SAM的提煉版本。在特征提取之后,還對原始的雙時間圖像進行處理以獲得LP[35]。 LP在不同層次上保留了圖像的像素級顯著特征。通過將顯著特征與編碼器提取的特征相結合,可以更好地恢復變化的細節。此外,加權引導注意力(WGA)被設計用于選擇性地將通道和空間注意力應用于融合特征,進一步細化變化目標的定位。最后,采用邊緣引導損失來約束變化區域的邊界,從而使變化形狀的過渡更加平滑,提高檢測精度。本文的主要貢獻如下。
1)我們提出了一種混合編碼器,它結合了CNN的感應偏差和變壓器的遠程依賴性來增強特征表示。同時,混合編碼器集成了MobileSAM以提高模型的泛化能力。
2)我們使用LP在雙時間圖像中獲得像素級顯著特征,這有助于補償變化目標的詳細信息。
3)在解碼器階段,WGAis設計基于不同目標的加權來實現注意力,使模型能夠更準確地定位變化區域。
4)利用邊緣引導損失來約束變化區域的邊界,便于檢索具有平滑邊緣的變化建筑物的形狀和細節
本文的其余部分組織如下。第二節提供了最相關研究的簡明概述。第三節詳細介紹了提議的HE-LPNet。第四節對實驗結果、討論和模型評估進行了全面分析。第五節對本文提出的方法進行了批判性探索。最后,第六節對本文進行了總結。?
二、相關工作
A.基于深度學習的CD方法
????????為了解決不相關的變化和復雜的對象,最近研究的很大一部分旨在提高CNN的泛化能力。U形架構,尤其是編碼器-解碼器結構,因其有效的上下文建模能力而在遙感CD中很受歡迎。Daudt et al.[11]通過對雙時態圖像的輸入法和跳過連接的探索,介紹了三種不同的基于U-net的模型,即FC-早期融合(EF)、FC-Siam-conc和FC-Siam-diff。在遙感CD中,確定不斷變化的對象的大小具有挑戰性。因此,使用不同大小的感受野進行變化識別至關重要。雷等人[30]引入了一個金字塔池模塊,該模塊巧妙地集成了來自多個卷積層的特征,有效地探索了圖像上下文。該模塊在更廣泛的感受野和上下文的有效利用之間取得了平衡,從而提高了性能。侯等人[19]設計了一個動態初始模塊,將時間數據合并到光盤中。Chen等人[31]設計了一個非局部特征金字塔網絡,用于有效提取和融合多尺度特征。為了穩健地融合雙時間特征,他們構建了一個基于密集連接的特征融合模塊。 雷等人[32]精心設計了一種解耦卷積方法,該方法巧妙地抓住了改變實體的多尺度特征,采用循環機制進行多尺度特征提取。黃等人提出了SEIFNet[36],該方法為時空差異增強模塊設計了一種雙分支結構,以捕捉雙時空圖像的變化特征。通過自適應上下文融合模塊,SEIFNet集成了層間特征,以更好地重建詳細的對象信息。此外,探索并實施了許多策略來拓寬接受領域,包括采用更深層次的網絡架構[37],利用擴張卷積技術[38],以及結合多樣化的注意力機制[14],[16],[37],[39]。
????????憑借驚人的語義表示能力,Transform[20]在各種CV任務中匹配或超過CNN的性能。這些任務包括圖像分類[21]、[40]、[41]、目標檢測[42]、語義分割[40]、[42]、圖像生成[43]、[44]和超分辨率[45]、[46]。Chen等人提出了BIT[22],用于對時空上下文進行高效和有效的建模。該模型包括一個具有變壓器編碼器和兩個變壓器解碼器的輕量級結構。Song等人[47]利用一系列swin-變壓器[41]模塊為每個圖像合成從CNN獲得的多級特征圖。 他們隨后計算雙時間圖像之間的差異特征。Zhang et al.[23]引入了SwinSUNet,這是一個包含編碼器、融合器和解碼器的框架,所有這些組件都使用swin轉換器[41]塊作為其基本單元。Bandara等人引入了ChangeForm[24],這是一種在暹羅架構的上下文中融合分層變壓器編碼器和多層感知器(MLP)解碼器的模型。這樣的集成框架擅長捕捉復雜的多尺度和遠程細節,這對于精確執行CD任務至關重要。雷等人[26]提出了LSAT,其中包括一個具有線性復雜性的跨維度交互式自我注意模塊,以減少計算負擔。 他們還引入了結構感知增強模塊,用于細化差分特征和聚合細節,實現雙時空遙感圖像的雙重增強。
????????然而,上述大多數方法中的特征提取器主要基于CNN或變壓器架構,這導致提取的特征具有不可避免的缺陷。我們提出了一種混合編碼器,將CNN的感應偏差與變壓器的遠程依賴相結合,以增強特征表示。
????????近年來,遙感圖像分辨率的提高使得更多特征的檢測成為可能,從而對CD模型的準確性提出了更高的要求。變化區域的邊緣檢測已經成為一個緊迫的挑戰。HFANet[48]通過利用高頻信息來增強特征定位并提高變化邊界的準確性來解決這一問題。類似地,白等人[49]提出了EGRCNN,這是一種深度學習框架,將邊緣估計與建筑變化預測相結合,以實現精細的邊緣檢測。然而,現有的邊緣檢測方法傾向于增加模型復雜性,同時努力解決噪聲放大和泛化受限等問題。 我們提出的邊緣引導損失使用預測映射和標簽映射直接計算損失,從而減少計算開銷,同時提供顯著的性能改進。
B.拉普拉斯金字塔
????????LP[35]是圖像處理中成熟的算法。LP方法的核心概念需要將圖像線性解剖成一系列高低頻分量,從而允許精確重建原始圖像[35]。在尺寸為h×w的任意圖像I0的情況下,LP通過計算低通預測I1😍R h 2×w 2來啟動。此計算中的每個像素代表其相鄰像素的加權平均值,由固定內核確定。為了實現可逆重建,LP記錄高頻殘差h0=I0?^I0,其中^I0表示從I1導出的上采樣圖像。 為了進一步降低采樣率和圖像分辨率,LP順序地將這些操作應用于I1,從而產生一系列高低頻分量。LP已經在各種低級任務中展示了與神經網絡結合的成功。一些研究人員從其巧妙的結構中汲取靈感,將其整體架構或特定的分解組件與深度學習技術相結合。示例包括超分辨率[50]、深度估計[51]和樣式轉換[52]中的應用。我們的目標是利用LP中固有的像素級顯著性特征來增強變化目標的詳細信息,并實現更精細的CD。
C.視覺基礎模型
????????利用大規模模型作為各種專門任務的基礎是當代機器學習中的一種常見策略。這種方法利用了大量的數據集,并利用了豐富的計算資源,使各種任務都有了顯著的進步。著名的模型,如來自轉換器的雙向編碼器表示[53]、生成式預先訓練的轉換器和SAM[27],在針對文本分類、對象檢測和語義分割等特定任務進行微調時已被證明是非常有效的。這些模型利用遷移學習的好處,允許將學習的特征應用于新任務,并減少對大量數據和計算資源的需求。
????????SAM作為一種視覺基礎模型脫穎而出,因其在圖像分割方面的卓越表現而得到認可。為了將SAM應用于在遙感應用方面,已有相當多的研究人員進行了嘗試。Chen等人[28]介紹了RS提示器,這是一個從編碼器的中間層提取特征以構成提示器輸入的模型。提示器生成包含語義類別信息的提示。丁等人[29]提出了SAM-CD,它使用凍結的Fast-SAM[54]作為編碼器,并進一步完善了專門為CD量身定做的多級特征提取和結果預測組件。在本文中,我們將Mobile-SAM[34]整合到混合編碼器中,以利用VFM的健壯性能并增強模型的泛化能力。
三、方法
A.體系結構概述
????????本文提出的HE-LPNet是一個端到端的共享權重遙感CD深度學習網絡,其總體結構如圖2所示。
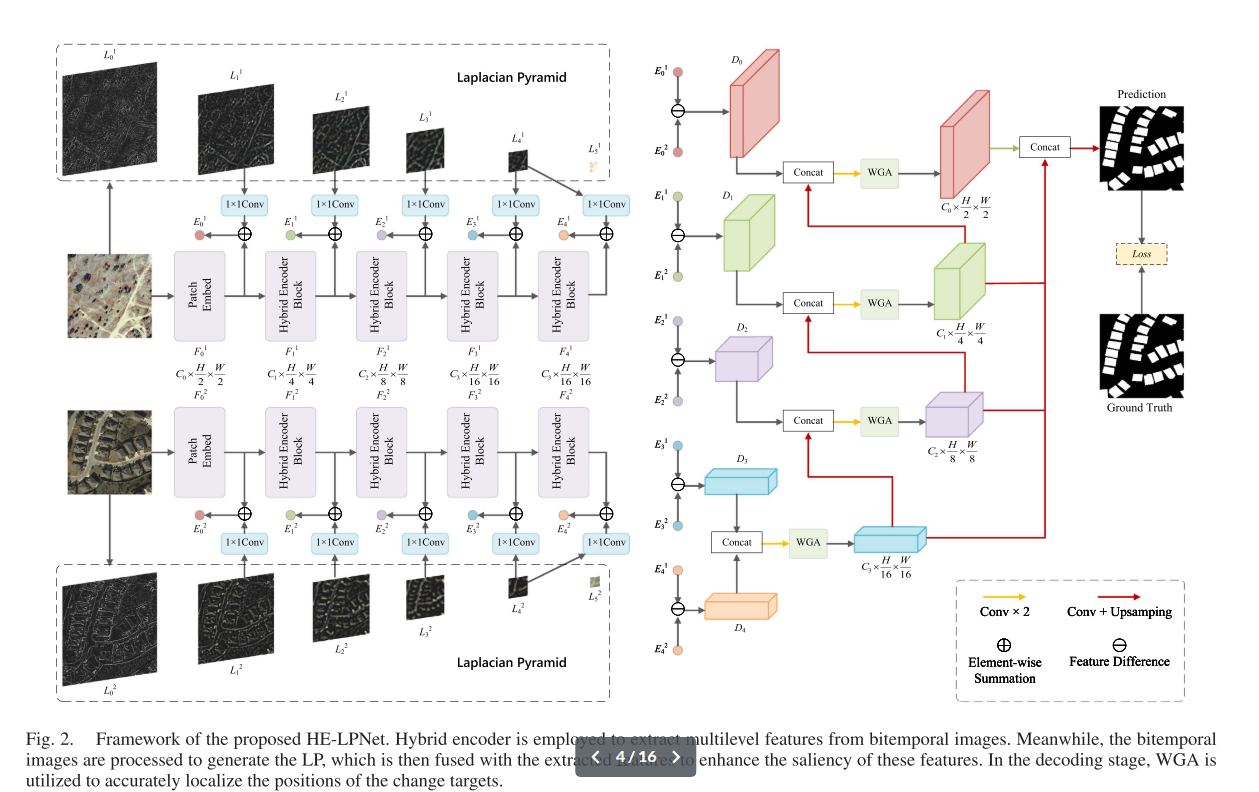
圖2.所提出的HE-LPNet框架。混合編碼器用于從雙時態圖像中提取多級特征。同時,對雙時態圖像進行處理以生成LP,然后將其與提取的特征融合以增強這些特征的顯著性。在解碼階段,利用WGA準確定位變化目標的位置
????????具體來說,在編碼階段,我們將雙時空遙感圖像饋送到混合編碼器中以提取多尺度特征。遵循UNet[11]的設計,混合編碼器的結構由四個階段組成。給定輸入圖像T1、T2😍RC×H×W、C、H和W分別表示圖像的通道數、高度和寬度。遵循ViT[21],使用卷積詞干進行補丁嵌入,該詞干由兩個卷積層實現。這得到的輸出,表示為F1 0,F2 0😍RC0×H 2×W 2,然后通過混合編碼器的四個階段進行處理以獲得層次特征。鑒于遙感圖像的分辨率與標準圖像相比明顯較低,最后階段取消了下采樣操作,以保持輸出特征分辨率與第三階段一致。在這些階段,特征圖的空間分辨率相對于初始輸入分辨率依次降低到{1/4,1/8,1/16,1/16}的比例。 我們將Stastei的輸出表示為F1 i,F2 i😍RCi×H 2i+1×W 2i+1,i😍{1,2,3},F1 4,F2 4的輸出維數為相同的F1 3,F2 3。同時,對雙時相遙感圖像進行處理,生成LP,表示為L1 i,L2 i,i😍{0,1,2,3,4,5}。隨后,將金字塔圖像的各個級別與混合編碼器輸出特征的不同級別融合,以獲得增強特征E1 i,E2 i,i😍{0,1,2,3,4}。
????????在解碼階段,我們采用特征差分方法,對來自兩個不同時間段的增強特征進行元素減法運算,然后進行赦免運算,得到表示為Di, i😍{0,1,2,3,4}的時間差分特征。時間差分特征將從深層到淺層進行級聯和上采樣。然后將級聯特征的每一層輸入到WGA中,以精確定位變化目標。每一層的結果特征也被均勻上采樣以匹配最淺特征的維度,完成最終預測。
B.混合編碼器
????????卷積的內在局限性在于它的內在局部性,使其不足以建模長期依賴關系。此外,變壓器產生的單尺度特征僅依賴于標記化注意力,忽略了相互關系。因此,這種方法被證明不足以有效處理遙感圖像中涉及多尺度區域的情況。為了解決上述挑戰,我們引入了一種混合編碼器,它包括一個MSA塊、一個卷積塊和一個變壓器塊,如圖3所示。
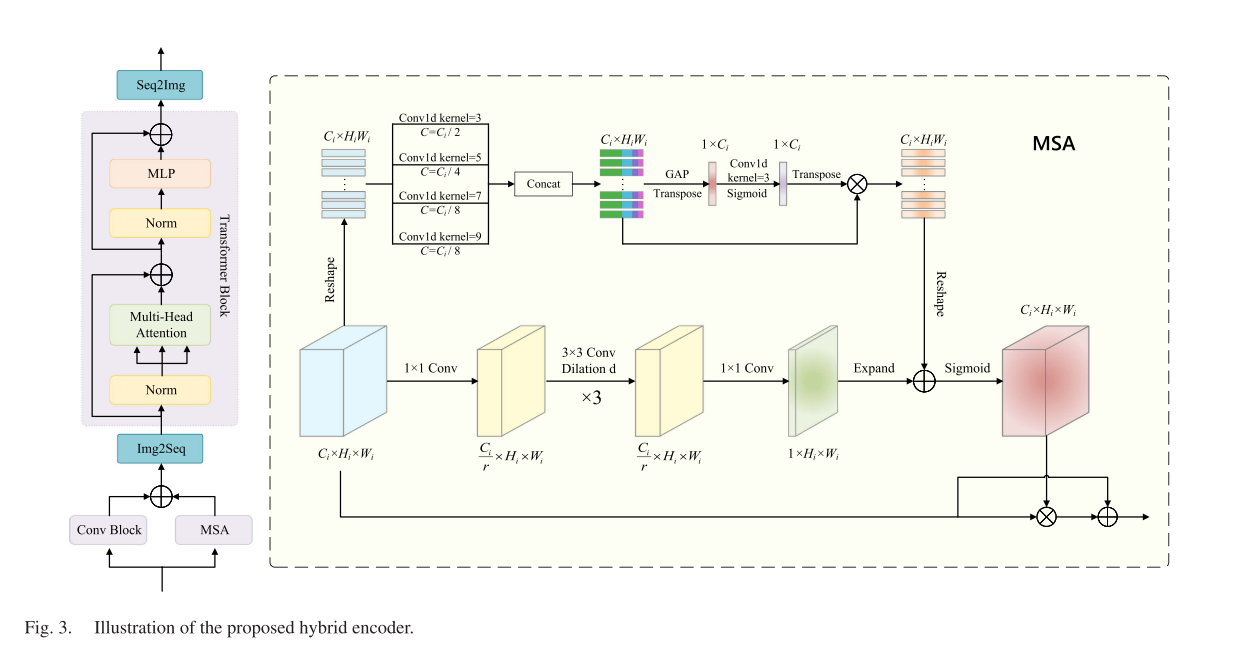
? ??1)多尺度注意力:提出的MSA用于補充卷積和轉換器塊未捕獲的部分信道和空間依賴關系。
????????對于通道注意力分支,對輸入特征Fi進行初始重構,得到F i😍RCi×HiWi,F i隨后進行不同核大小的一維卷積運算,以提取不同感受野下的通道信息。由于遙感圖像中特征的分辨率較低,低級感受野包含了廣泛的信息。我們為shallowhigh-resolution特征建立了四個不同尺度的卷積塊。同時,我們將卷積塊的輸出通道設置為Ci/2、Ci/4、Ci/8、Ci/8,作為權重。這種設計使通道注意力能夠集中在局部信息和廣泛的信息上,如圖3所示。 對于剩余的低分辨率特征圖,我們建立核大小為1和3的兩尺度卷積塊,以及輸出通道Ci/2、Ci/2。不同卷積塊的輸出隨后被級聯以獲得Fm i,過程可以表述為
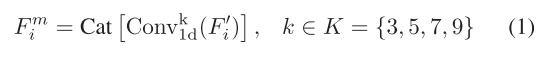
其中,Convk 1d(·)表示核大小為k的一維卷積,而Cat[·]表示特征級聯操作。級聯的通道特征FMi經歷全局平均池的初始步驟,隨后進行轉置。隨后,我們使用大小為3的核進行一維卷積,然后用Sigmoid函數激活輸出。最后,在轉置后,與FM i進行逐個元素的乘法,以獲得最終的信道關注度FC i。這一過程可以描述為
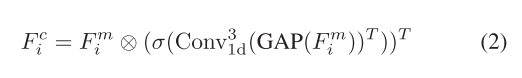
?其中,GAP(·)表示全局平均池化運算,(·)T表示轉置運算,σ(·)表示Sigmoid函數,?表示元素乘法。
??????空間注意力分支主要作為一個額外的補充,為更大的感受野提供空間信息。這是必不可少的,因為與MSA平行的卷積塊提取豐富的局部信息。輸入特征Fi首先通過1×1卷積進行壓縮,以減少通道數,從而產生Fp i😍R Ci r×Hi×Wi。隨后,壓縮特征進行3×3卷積,膨脹值為ofd,以提取空間信息。該步驟重復三次。在上述每個卷積之后,應用批量歸一化和整流線性單元(ReLU)激活。最后,采用1×1卷積獲得最終的空間注意力Fs i。 這個過程可以表示為
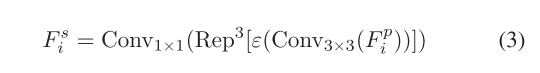
其中Conv3×3(·)和Conv1×1(·)分別表示3×3和1×1卷積層,. ε(·) 表示批量。規范化和ReLU激活。Repi[·]表示重復相同的操作i次。
????????在獲得通道注意Fc i和空間注意Fi后,由于這兩個注意圖的形狀不同,我們分別進行了整形和擴展操作,以恢復RCI×Hi×Wi的兩個注意。隨后,通過元素求和和Sigmoid運算,我們將兩者結合起來,得到了MSA?Fi。最后,我們在原始輸入特征Fi和MSA?Fi之間執行逐個元素的乘法。然后將得到的結果與原始輸入特征通過元素求和進行組合,得到最終的輸出特征FMSA i。這一過程可以用公式表示
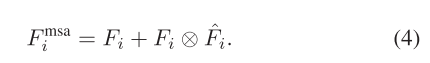
?2)卷積塊:利用卷積塊提取局部空間特征,對空間信息進行編碼。為了實現這一目標,混合編碼器采用原始的ResNet-18[8]結構作為卷積塊。具體地,輸入特征Fi被饋送到現有卷積層中,從而產生具有編碼的位置信息的局部特征Fi。
3)轉換器塊:轉換器塊采用堆疊的自我關注層,在全局語義信息建模方面具有優勢,使其能夠捕獲長期依賴關系。為了將來自卷積塊的局部提取的空間信息和來自MSA的注意信息輸入到變換器塊中,我們使用逐個元素求和的方法將多尺度特征FMSA i和局部內容特征Fl i整合在一起,然后將它們轉換成序列形式作為變換器塊的輸入。這個過程可以表示為
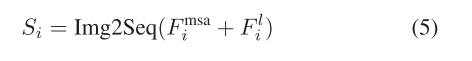
其中,Img2Seq表示將特征映射轉換為一維序列的整形操作。遵循[20]中概述的架構,每個變壓器模塊通常由一個多頭自關注(MHSA)模塊和一個包含兩個線性變換和高斯誤差線性單元[55]激活的MLP網絡組成。在各模塊運行前,先進行層歸一化(LN),各模塊之間通過殘差連接架構連接。對最終的特征序列進行變換,得到輸出特征Fi+1,I級變換模塊表示為
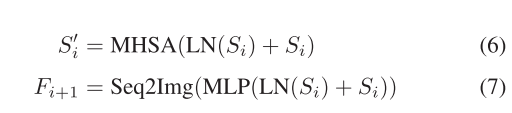
其中Seq2Img表示Img2Seq的反向操作。我們的變壓器塊是MobileSAM[34]使用的TinyViT[56],其中MobileSAM是從SAM[27]中提煉出來的。由于TinyViT中的參數較少,即使利用預訓練的MobileSAM模型,也可以對整個模型進行端到端訓練,而無需凍結模塊進行額外的微調。這賦予了VFM強大的泛化能力,有助于更精確地提取CD所需的特征。
C. LP功能增強
????????如第II-B節所述,LP可以捕獲圖像的高頻和低頻分量,包括圖像中不同域的屬性。在這種情況下,圖像的亮度和顏色信息表現在低頻分量中,而內容細節與高頻分量相關聯。在遙感圖像編碼中,變化與圖像的內容細節聯系更緊密,而亮度和顏色包含的信息量較少,對圖像編碼的影響有限,因此我們利用LP高頻信息中包含的像素級顯著特征來補充混合編碼器在不同層次上提取的特征。這反過來又使模型能夠實現對變化區域的更精細的分割。
????????以輸入圖像T1為例,如圖2所示,在將該圖像送入混合編碼器以提取多尺度特征的同時,還將其分解為LP,從而產生表示高頻分量的集合High1=[L1 0, L1 1,L1 2,L1 3,L1 4]和表示低頻分量的集合L1 5。High1的分量分辨率從H×W逐漸降低到H 16×W 16。根據[35],High1在垂直方向上高度去相關,大多數像素強度接近0,除了細節紋理保留了重要值。 我們利用高頻集High1中對應于多尺度特征F1 i分辨率的分量。首先,我們使用1×1卷積壓縮High1的通道。隨后,經過與可學習的自適應參數Pj相乘,并與混合編碼器提取的特征進行元素求和,我們得到了增強特征E1 i。這個過程可以表示為
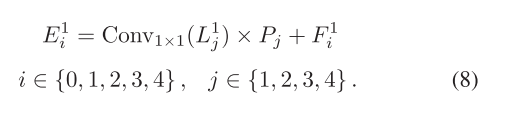
注意,在上述方程中,當i設置為0時,j應該設置為1,依此類推。由于F1 4與F1 3具有相同的維度,F1 4仍然對應于L1 4和P4
D.權重引導的注意力
????????來自不同層次的特征封裝了獨特的信息。然而,如果沒有適當的指導,多層特征的融合可能會導致信息干擾,從而影響檢測性能。我們提出了加權遺傳算法,它根據每個通道在空間維度上的標準差為每個像素分配不同的權重,以實現選擇性注意,如圖4所示。具體地說,給定串聯和融合的特征DF I∈RCI×Hi×Wi,I∈{0,1,2,3},首先對該特征進行重塑以獲得D I∈Rci×HiWi。隨后,沿著展平的空間維度計算標準差,然后應用Sigmoid運算來為每個通道分配相應的權重,從而產生W∈RCI。這一過程可以用公式表示
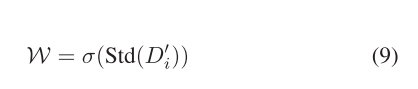
其中,std(·)表示標準差運算。然后,W首先被擴展以匹配Df i的維度,以獲得W?。然后,在W?和df i之間執行逐個元素的乘法,并且結果被逐個元素地與df i相加,從而得到權重引導特征dg i。這一過程可以用公式表示
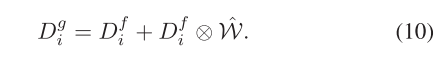
權重引導的特征Dg i將被饋送到不同的分支中,以獲得通道注意力和空間注意力。對于通道注意力分支,Dg i首先進行全局平均池化并扁平化。然后,它經歷一個線性層,將通道數壓縮到CθR Ci r。C然后通過兩個線性層,而不改變通道數和一個線性層,將通道數恢復到Ci,導致最終的通道注意力Dgc i。除了最后一個線性層,在每個線性層之后應用批量歸一化和ReLU激活。該過程可以制定為
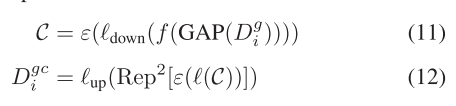
其中f(·)表示平坦操作。(·)表示線性層,而up(·)和down(·)分別表示通道數的增加和減少。
????????對于空間注意力分支,Dg i最初通過1×1卷積壓縮,以將通道減少到Ci r,從而產生Dgr i。隨后,將壓縮后的特征饋送到四個并行的3×3卷積層中,每個卷積層的輸出通道為Ci 4r。這些卷積層的膨脹值分別設置為1、2、3和4。這些卷積層被用來整合來自不同感受野的特征。沿著通道維度連接來自四層的輸出,并通過1×1卷積獲得最終的空間注意力Dgs i。 除最后1×1卷積層外,在每個卷積層之后應用批量歸一化和ReLU激活。該過程可以制定為
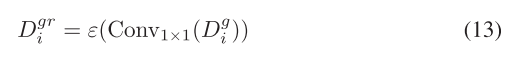
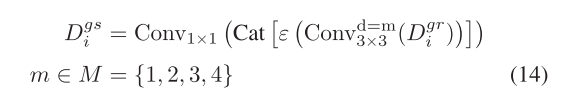
其中Convd=m 3×3(·)表示具有膨脹值m的3×3卷積層。
????????我們以類似于MSA的方式獲得最終的輸出特征。將通道注意力Dgc i和空間注意力Dgs i擴展到RCi×Hi×Wi,并使用sigmoid的元素求和獲得注意力特征Dgg i。最后,我們通過以下表達式獲得輸出特征Dwga i
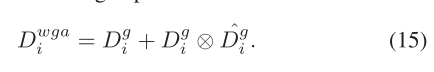
E.損失函數
1)邊緣引導損失:雖然我們使用LP來補充像素級顯著性特征,但圖像的形狀細節在編碼過程中不可避免地丟失。因此,在[57]的激勵下,我們開發了一種邊緣引導損失,以增強對變化邊緣的關注,從而準確地分割變化區域。具體來說,我們首先計算預測圖像和地面實況之間相對于它們對應的局部最大池化結果的差異,該操作增強了兩者的邊緣信息。隨后,我們計算了上述結果之間的L2距離,以實現約束并減少它們之間的差異。邊緣引導損失可以表示為?
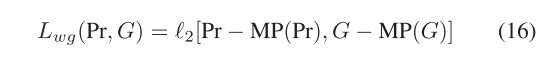
其中,MP(·)表示最大合并操作,2[·]表示L2距離。PR表示預測的變化圖,而G表示相應的地面事實。
?2)二值交叉熵(BCE)損失和骰子損失:在遙感CD中,網絡的訓練面臨著顯著的類不平衡問題,其中負像素數遠遠超過正像素數。這種不平衡會導致不充分的優化,使網絡容易陷入目標函數的局部極小值。為了解決這個問題,我們使用了BCE Lbce和Dice Lost。
BCE損失可以表述為
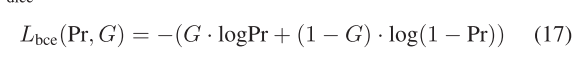
其中·表示點積操作。骰子損失可以表示為
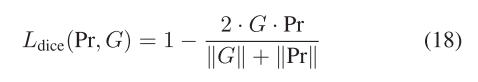
其中·表示1范數。
最終的損失函數是通過對上述三個損失函數求和得到的
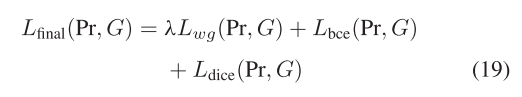
四、實驗
在我們的實驗中,我們使用了三個用于遙感CD的標準數據集。這些數據集的綜合詳細信息如下?。
1)學習、視覺和遙感(LEVIR-CD):該數據集包含從Google Earth API獲得的637對圖像對,每張圖像的大小為1024×1024像素,空間分辨率為0.5 m。數據集的主要焦點是建筑物的變化,包括新建和毀壞的建筑物。我們將圖像裁剪成大小為256×256的不重疊補丁。因此,LEVIR-C分別為訓練、驗證和測試階段使用7120、1024和2048對圖像補丁[58]。
2)中山大學(SYSU-CD):該數據集包含20000對雙時空遙感圖像塊,每個塊的空間尺寸為256×256,空間分辨率為0.5 m,用于訓練、驗證和測試的官方分割設置為6:2:2的比例,該數據集涵蓋了廣泛的各種復雜變化情景,包括道路擴張、新的城市結構的出現、植被的改變、郊區的增長以及建設項目的準備基礎工作等實例[16]。
3)季節變化檢測(SVCD):該數據集由從Google地球獲得的七對季節變化圖像組成,其空間分辨率從每像素3到100厘米不等。該數據集側重于不包括季節變化的物體變化。為了便于訓練,原始圖像被分成小塊,每個塊測量256×256,并應用隨機旋轉。以這種方式,該數據集總共包含16000對圖像對,其中10000對用于訓練,3000對用于驗證,3000對用于測試[33]。
B.實驗設置
1)實施細節:建議的HE-LPNet使用PyTorch框架[59]實施,并從頭開始訓練。我們采用了一套數據增強策略來輸入圖像,包括隨機水平翻轉、選擇性裁剪和時間洗牌。我們使用Adam優化器[60]訓練我們的網絡,動量為0.9,權重衰減為0.0001,Paramsβ1,β2分別為0.9和0.99。我們將初始學習率設置為0.0005,批量大小為32,參數λ為0.02。對于LEVIR-CD數據集和SYSU-CD數據集,模型被訓練40000次迭代。對于SVCD數據集,模型被訓練80000次迭代以實現足夠的收斂。 所有實驗均在配備Intel(R)Xeon(R)Gold 5218 CPU(2.30 GHz)和GeForce RTX 3090 GPU(24 GB內存)的系統上進行。
2)評估指標:在實驗中,我們使用5個指標來評估模型的性能:精度(Pre)、召回率(Rec)、F1-得分(F1)、IoU和kappa系數(Kappa)。預度量正確識別陽性樣本的能力,而記錄度量捕獲所有陽性樣本的能力。F1是Pre和Rec的平衡度量。IoU度量預測和地面實況區域之間的重疊,而Kappa度量預測和地面實況標簽之間的一致性。這些指標描述如下:

其中TP、FP、TN和FN分別表示真陽性、假陽性、真陰性和假陰性的數量。Kappa中的P表示參考數據和預測結果之間隨機一致的理論可能性,可以在數學上表示為
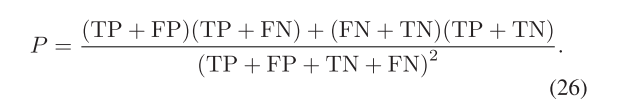
C.與最先進技術(SOTA)的比較
????????為了評估我們的HELPNet的有效性和效率,我們選擇了幾個SOTA模型作為競爭對手,包括基于CNN的方法:FC-EF[11]、FC-SD[11]、FC-SC[11]、SNUNet[37]、A2Net[61]、Changer[62]、SEIFNet[36]和三種基于變壓器的方法:BIT[22]、ChangeForm[24]、TLFFNet[63]。我們使用它們公開可用的代碼和默認參數來重現這些模型,以確保比較的公平性。
????????給出了三個遙感CD數據集上各種方法的定量評價比較???在表I中,包括Prec、Rec、F1、IoU和Kappa。我們采用兩個指標來評估網絡的空間復雜度和計算成本:浮點運算(FLOPs)的數量和模型Params的數量。FLOPs指標顯著反映了網絡推理階段的能量消耗,而Params的數量與模型的存儲需求相關。圖5-7展示了三個數據集上不同方法的可視化比較。為了更好地可視化,我們使用不同的顏色來表示真陽性(白色)、假陽性(紅色)、真陰性(黑色)和假陰性(藍色)。
????????1)LEVIR-CD上的實驗結果:通過定量比較,我們可以觀察到我們提出的HE-LPNet在Rec方面略遜于TLFFNet。然而,其他指標遠高于其他指標,表明HE-LPNet可以學習更多的變化特征并產生更高質量的變化圖。即使與最新的方法TLFFNet、SEIFNet、A2Net和Changer相比,我們的方法在F1指標上也顯示出0.11%、2.11%、0.58%和0.64%的改進。
????????圖5選擇了幾個有代表性的樣本進行直觀的定性比較。對于大規模的建筑變化,我們提出的HE-LPNet展示了準確識別變化區域,與其他方法相比,在邊界處實現了更好的性能。這歸因于精心設計的邊緣損失,使我們的方法能夠以更高的精度精確定位對象邊緣。對于小規模變化,我們的HE-LPNet在檢測預方面表現出卓越的性能,優于經常忽略這些變化的其他競爭者。這驗證了我們使用LP的有效性,它為模型提供了充足的詳細信息。
????????2)SYSU-CD上的實驗結果:由于數據標注粗糙,該數據集上所有方法的指標都相對較低。我們的方法在Prec和Rec中都沒有達到最優結果,但在F1、IoU和Kappa分數方面脫穎而出。這表明我們的方法在Prec和Rec之間實現了優越的平衡,從而提高了各種評估指標的性能。
????????在定性比較中,我們的方法在識別不同表面材料的建筑物方面表現出出色的判別能力。一些變化的區域表現出與變化前非常相似的空間特征,這往往導致其他方法無法準確檢測變化。然而,我們的方法即使在這種情況下也能準確檢測變化。總之,定性比較結果與定量比較結果,進一步證實我們提出的HE-LPNet在SYSU-CD數據集上實現了SOTA性能。
????????3)在SVCD上的實驗結果:從表1中的定量比較結果可以看出,我們提出的HE-LPNet在性能上比其他方法有了顯著的提高。與TLFFNet、SEIFNet、Change、A2Net和ChangeFormer相比,我們的方法將F1度量分別提高了0.58%、0.96%、1.07%、0.62%和0.98%。
????????當前的CD方法在SVCD數據集上表現出高精度,促使我們進行詳細的定性實驗,以比較它們在該數據集上的性能。該數據集涵蓋了廣泛的對象大小,包括廣闊的農田和道路上移動的車輛。圖7說明了HE-LPNet在準確檢測大規模變化區域邊界和小物體微小變化方面的卓越能力,超越了其他方法。HE-LPNet可以檢測具有挑戰性的物體(如汽車)的變化,這些物體在遙感圖像中通常難以識別。
????????4)TLFFNet與TLFFNet的比較:TLFFNet是一種結合了CNN和轉換器的新型CDN方法。然而,與以往的許多方法(如BIT)類似,TLFFNet只有在利用CNN完成特征提取后,才利用轉換器來提高模型的性能。這種方法限制了提取的特征,使得有效地捕獲長期依賴關系變得困難。在特征提取階段,He-LPNet集成了CNN和變換網絡,使得提取的特征既能利用CNN的感應偏差,又能利用變換的長程相關性,從而獲得更好的模型性能。
????????由于TLFFNet在WHU數據集上表現良好,我們還在該數據集上與HE-LPNet進行了比較。由于WHU數據集沒有為訓練、驗證和測試集提供預定義的拆分,我們手動劃分了數據集。為了確保公平比較,我們在WHU數據集上對HE-LPNet和TLFFNet使用相同的拆分進行了實驗。HE-LPNet的結果如下:Kappa 94.54%、IoU 90.12%、F1 94.80%、Rec 94.13%和Pre95.49%。相比之下,TLFFNet的結果為:Kappa 93.82%、IoU 88.89%、F1 94.12%、Rec 92.14%和Pre96.18%。總體而言,HE-LPNet在WHU數據集上表現出優于TLFFNet的性能。
???D.復雜性分析
基于表I中介紹的Params和FLOPs分析,可以觀察到我們的方法在這方面并不占優勢。主要原因是HE-LPNet采用混合編碼器,將卷積和轉換器架構都集成到特征提取階段,導致計算資源增加。我們盡量利用較淺的卷積層和轉換器塊,但混合編碼器仍然消耗了70%的計算資源。不同主干的詳細討論可在第IV-E1節中找到。在為本文配置的軟硬件環境下,HE-LPNet取了兩個在批量設置為1的Levir-CD數據集上處理測試集需要幾分鐘的時間,這表明盡管我們提出的方法的復雜度略高,但它仍然保持了較快的推理速度,顯示了其實用價值。
E.消融研究
為了進一步驗證所提出模型的每個模塊和分支的貢獻,本節進行了全面的燒蝕實驗。我們主要關注實驗中的三個指標: F1、IoU和Kappa,因為它們綜合評估了模型的性能。定量結果列于表II-IV,可視化結果列于圖8。? ?
????????1)討論ofDifferentBackbones:為了檢查混合編碼器對模型的影響,我們使用幾個骨干網進行了燒蝕實驗,包括ResNet18[8]、ResNet50[8]和TinyViT[56]。此外,我們調查了基于MSA和MobileSAM的預訓練權重對模型性能的影響。結果在表II中給出。通過比較,很明顯,使用TinyViT和ResNet18作為骨干網可以減少模型的資源消耗。然而,它顯著降低了模型的性能,F1在LEVIR-CD數據集上分別下降了0.77%和0.67%。 使用ResNet50作為主干稍微提高了模型在SVCD數據集上的性能,但它導致其他兩個數據集的性能下降,同時伴隨著資源消耗的顯著增加。這表明我們的方法在資源消耗和性能之間取得了平衡。 ?
????????在不使用基于MobileSAM的預先訓練的權重的情況下,可以觀察到模型在所有三個數據集上的性能都有不同程度的下降,在Levir-CD、SYSU-CD和SVCD數據集上,F1分別下降了0.54%、2.32%和0.45%。這表明,向量機的權值可以增強模型的泛化能力。然而,即使不使用VFM的權重,我們的模型的性能也優于表I中比較的大多數方法,從而證明了我們的模型結構的優越性。表II還說明,混合編碼器中包含MSA也在一定程度上提高了性能,這表明MSA可以補償一些信道和空間信息。
????????2)LP特征增強的有效性:引入了LPI,通過利用其高頻信息中包含的像素級顯著特征來補充細節信息。為了進行LP的消融研究,我們去掉了將輸入圖像提供給LP以獲得雙分支頻率圖的步驟。在這種情況下,混合編碼器提取的特征F1 i、F2 i將直接饋送到解碼器。從表III中的結果可以看出,結合LP中的顯著特征增強了CD能力。然而,如果不加入WGA,改進是有限的,在LEVIR-CD數據集上F1、IoU和Kappa分數分別僅增加了0.07%、0.11%和0.06%。 我們認為這是因為LP為特征添加了豐富的細節信息,但模型缺乏足夠的模塊來處理和消化這些信息。它從表III中可以觀察到,加入WGA對特征進行處理后,模型的性能明顯提高,如圖8(b)和(c)所示,通過LP特征增強后,高頻信息中的像素級顯著性特征使特征能夠更好地表示關鍵區域的位置信息。
????????3)WGA的有效性:WGA根據每個通道在空間維度上的均方差為每個像素分配不同的權重,從而實現選擇性注意。為了在WGA上進行消融實驗,我們在解碼器階段去掉了這個模塊,直接對串聯的特征進行上采樣,然后將其與淺層特征相結合。與LP類似,當WGA單獨使用時,改進相對較小,但與LP結合時,導致模型的大幅增強。與不使用LP和WGA相比,兩者結合導致SYSU-CD數據集上的F1、IoU和Kappa分數分別增加了1.03%、1.51%和1.36%。 如圖8(d)和(e)所示,融合后的特征已經定位了變化區域,但噪聲仍然影響精度。通過WGA后,特征圖的主要焦點集中在變化區域,大大減少了對不相關區域的關注。
????????4)損失函數的討論:在本文中,我們采用了由邊緣引導損失、Dice損失和BCE損失組成的混合損失。為了驗證其性能,我們僅使用BCE損失、Dice損失以及這兩種損失的組合來執行實驗。 從表III中可以觀察到,僅使用BCE損失對模型性能有顯著的負面影響,僅使用Dice損失也是如此,這主要是因為CD屬于二分類任務,正負樣本數存在較大差異,因此結合這兩個損失函數可以有效提高模型性能,同時我們觀察到,在三個數據集上合并邊緣引導損失導致F1分別提高了0.31%、0.48%和0.29%,證明了邊緣引導損失的有效性,如圖9(c)所示,邊界在不使用邊緣引導損失的情況下,變化區域更加模糊。相比之下,如圖9(d)所示,加入邊緣引導損失會導致更清晰的邊界,使模型能夠更準確地描繪變化區域。
????????5)超參數的討論:表IV演示了損失函數中變化的超參數λ對實驗結果的影響,可以觀察到,在迭代次數固定的情況下,λ的不同值對實驗結果有影響,當λ較小時,邊緣引導損失對混合損失的貢獻較小,因此對模型性能的影響有限,當λ較大時,BCE損失和Dice損失的有效性被打折,導致模型性能的負面影響。因此,為了平衡各種損失函數的比例并實現最佳模型性能,我們選擇0.02作為超參數λ的值。
五、討論
雖然HE-LPNet在遙感CD中表現出有希望的性能,但有一些局限性值得進一步討論。首先,該模型在處理更復雜的場景時難以準確捕捉變化區域,如圖10所示。在存在重疊變化區域或變化難以區分的情況下,該模型的性能顯著下降。為了解決這個問題,可能需要額外的優化技術來增強模型的性能。其次,該模型仍然需要大量的oflabed數據進行訓練,這使得它難以應用于一些現實世界的場景。關鍵的解決方案在于實現增強的檢測精度,同時減少對注釋數據的依賴。 在未來的工作中,開發可以用更少樣本訓練的高效CD方法將是提高模型可用性的關鍵。
結論
在本文中,我們提出了一種新穎的具有混合編碼和LP特征增強的遙感CD的HE-LPNet。具體地說,混合編碼器將CNN的感應偏置、MSA機制和變壓器架構的優勢融合在一起,將這些優勢統一到一個模塊中。這提高了模型捕獲廣泛的、多尺度的依賴關系和詳細的局部空間特征的能力。此外,該模型還利用了LP高頻信息中包含的像素級顯著特征來補充細節信息。在解碼階段,WGA根據每個通道在空間維度上的標準差來選擇性地關注每個像素,突出顯示變化區域。最后,設計了一種邊緣引導損失,以加強對變化的關注邊緣,從而準確地分割變化區域。在具有挑戰性的數據集上進行的實驗顯示了HE-LPNet在CD上的顯著性能,在精度上超過了測試的SOTA模型。更多的消融研究進一步證明了精心設計的部件的有效性。HE-LPNet令人印象深刻的結果突顯了其利用高分辨率雙時相遙感圖像準確檢測復雜場景變化的潛力。
 - sql解析器(番外)- *號的處理)




)






)






