繼續學習字節家的VeRL,今天來看看VeRL的RL,是VeRL系列的第三篇文章(話說近期好多大事兒,我司發布了Longcat、韓立結嬰、阿里周五發布了QWen-Next都是好東西啊,學不過來了damn)
- 底層分布式能力基礎Ray(點擊查看):VeRL分布式能力的基礎,框架Ray
- VeRL的原理(點擊查看):HybridFlow
- VeRL的使用(點擊查看):普通RL(PPO)
- VeRL的使用,Agentic RL(多輪RL)
- VeRL的魔改
前兩篇文章分別介紹了VeRL的分布式基礎和其底層原理,下面就以RL的PPO為例,同時結合源碼,看看具體的使用。
安裝
- 使用docker的話,verl提供了諸多版本可以使用,例如純凈的只包含Verl/CUDA/PyTorch等依賴的base鏡像,也有整合了vLLM/SGLang/FSDP/Megatron的application鏡像
- 手動安裝的話,要從CUDA/cuDNN等基礎庫開始,一定會遇到沖突(嗯,一定…)
使用
- 首先在Ray的Head節點上執行
ray start --head --dashboard-host=0.0.0.0,之后會得到兩個address:
- 一個是集群內head/worker之間通信用的 GCS address
- 一個是提交與查看任務/資源監控/查看日志的dashboard地址(使用VSCode插件進行debug的地址也是它)
- 然后在每個Ray Worker節點上執行
ray start --address=gcs_address - 最后提交job任務
ray job submit --address=dashboard_address -- python3 -m verl.trainer.main_ppo trainer.n_gpus_per_node=8 ...就可以在dashboard里看到各種信息了
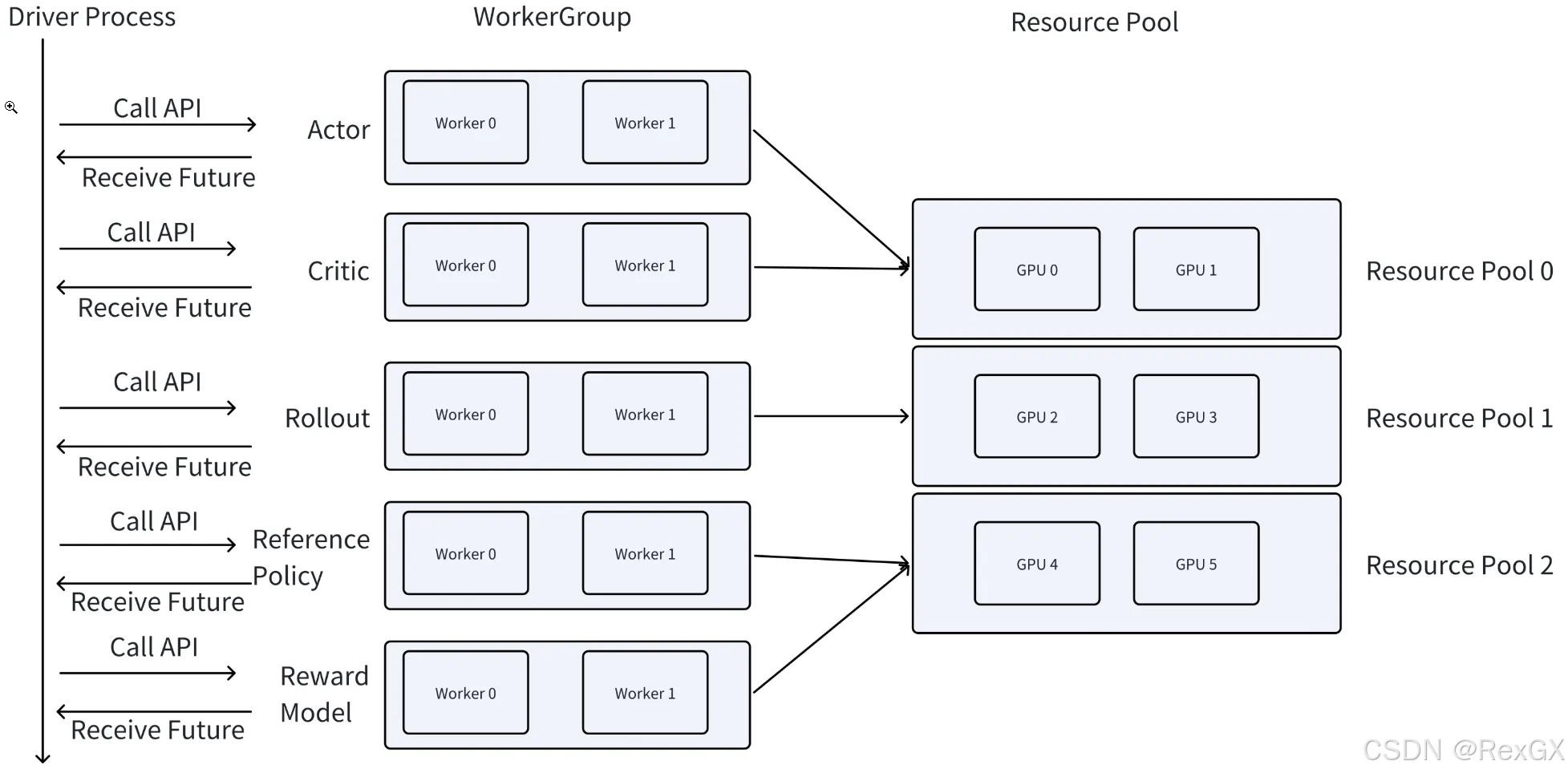
啟動后,整體架構如圖,前兩篇文章介紹過了,就不贅述了:
- 其中driver進行代表single-controller
- 其他的 actor/critic/rollout/ref/reward 那些 workers 代表 multi-controller,均對應著各自的 resource group
下面直接看源碼。
源碼
首先是入口函數,即main_ppo.py,主要做定義、初始化: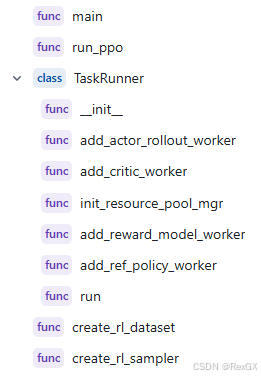
- 初始化 Ray cluster 環境
- 通過
@ray.remote定義了一個 遠程執行的class TaskRunner - 定義
actor/rollout worker:通過配置指定使用fsdp、megatron,并構建mapping,role_worker_mapping[Role.ActorRollout] = ray.remote(actor_rollout_cls) - 定義
criticworker - 將上述兩個
worker映射到resourece資源上:mapping[Role.ActorRollout] = global_pool_id、mapping[Role.Critic] = global_pool_id - 定義
rewardworker:role_worker_mapping[Role.RewardModel] = ray.remote(RewardModelWorker)的同時映射資源mapping[Role.RewardModel] = "global_pool" - 定義
refworker:role_worker_mapping[Role.RefPolicy] = ray.remote(ref_policy_cls)的同時映射資源mapping[Role.RefPolicy] = "global_pool" - 執行PPO workflow:加載模型、準備dataset、構建RayPPOTrainer、執行
RayPPOTrainer.init_workers()、執行RayPPOTrainer.fit()
# Initialize the PPO trainer.
trainer = RayPPOTrainer(config=config,tokenizer=tokenizer,processor=processor,role_worker_mapping=self.role_worker_mapping,resource_pool_manager=resource_pool_manager,ray_worker_group_cls=ray_worker_group_cls,reward_fn=reward_fn,val_reward_fn=val_reward_fn,train_dataset=train_dataset,val_dataset=val_dataset,collate_fn=collate_fn,train_sampler=train_sampler,
)
# Initialize the workers of the trainer.
trainer.init_workers()
# Start the training process.
trainer.fit()
然后執行的是核心的RayPPOTrainer,主要就是倆函數,一個是init_workers(),一個是fit() 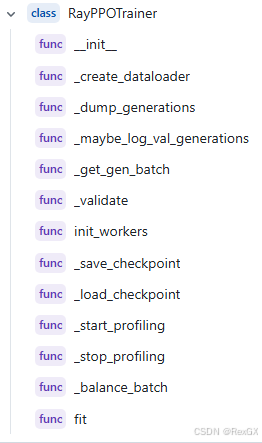
先看init_workers():
- 根據config配置的資源創建
resource pool - 創建
hybrid_engine,這是actor和rollout的 colocate的復合體
resource_pool = self.resource_pool_manager.get_resource_pool(Role.ActorRollout)
actor_rollout_cls = RayClassWithInitArgs(cls=self.role_worker_mapping[Role.ActorRollout],config=self.config.actor_rollout_ref,role="actor_rollout",
)
self.resource_pool_to_cls[resource_pool]["actor_rollout"] = actor_rollout_cls
- 創建
critic
resource_pool = self.resource_pool_manager.get_resource_pool(Role.Critic)
critic_cfg = omega_conf_to_dataclass(self.config.critic)
critic_cls = RayClassWithInitArgs(cls=self.role_worker_mapping[Role.Critic], config=critic_cfg)
self.resource_pool_to_cls[resource_pool]["critic"] = critic_cls
- 創建
ref
resource_pool = self.resource_pool_manager.get_resource_pool(Role.RefPolicy)
ref_policy_cls = RayClassWithInitArgs(self.role_worker_mapping[Role.RefPolicy],config=self.config.actor_rollout_ref,role="ref",
)
self.resource_pool_to_cls[resource_pool]["ref"] = ref_policy_cls
- 創建
reward,下面設置用的是reward model非function:
resource_pool = self.resource_pool_manager.get_resource_pool(Role.RewardModel)
rm_cls = RayClassWithInitArgs(self.role_worker_mapping[Role.RewardModel], config=self.config.reward_model)
self.resource_pool_to_cls[resource_pool]["rm"] = rm_cls
- 創建各自的
wroker group,WorkerGroup是一組Wroker的抽象集合,使得driver可以和底層的多個worker進行交互:
for resource_pool, class_dict in self.resource_pool_to_cls.items():worker_dict_cls = create_colocated_worker_cls(class_dict=class_dict)wg_dict = self.ray_worker_group_cls(resource_pool=resource_pool,ray_cls_with_init=worker_dict_cls,**wg_kwargs,)spawn_wg = wg_dict.spawn(prefix_set=class_dict.keys())all_wg.update(spawn_wg)if self.use_critic:self.critic_wg = all_wg["critic"]self.critic_wg.init_model()if self.use_reference_policy and not self.ref_in_actor: # 需要關注self.ref_policy_wg = all_wg["ref"]self.ref_policy_wg.init_model()if self.use_rm:self.rm_wg = all_wg["rm"]self.rm_wg.init_model()
這里需要注意的是:
actor和rollout進行colocate的目的:是在rollout和train兩個階段間高效更新參數權重- 但是否也同樣也
colocate ref,取決于是否用了LoRA,因為ref和actor它們的base基座模型一樣,只不過actorlora多了一層lora的適配層,也就是BA矩陣,所以如果用LoRA,可以把rollout/actor/ref同時colocate到一起,更省資源
之后再看fit(),其實就是標準的PPO實現了,下面提取出關鍵信息:
for prompt in dataloader:output = actor_rollout_ref_wg.generate_sequences(prompt) # old_log_prob = actor_rollout_ref_wg.compute_log_prob(output)ref_log_prob = actor_rollout_ref_wg.compute_ref_log_prob(output)values = critic_wg.compute_values(output)rewards = reward_wg.compute_scores(output)advantages = compute_advantages(values, rewards)output = output.union(old_log_prob).union(ref_log_prob).union(values).union(rewards).union(advantages)actor_rollout_ref_wg.update_actor(output)critic.update_critic(output)
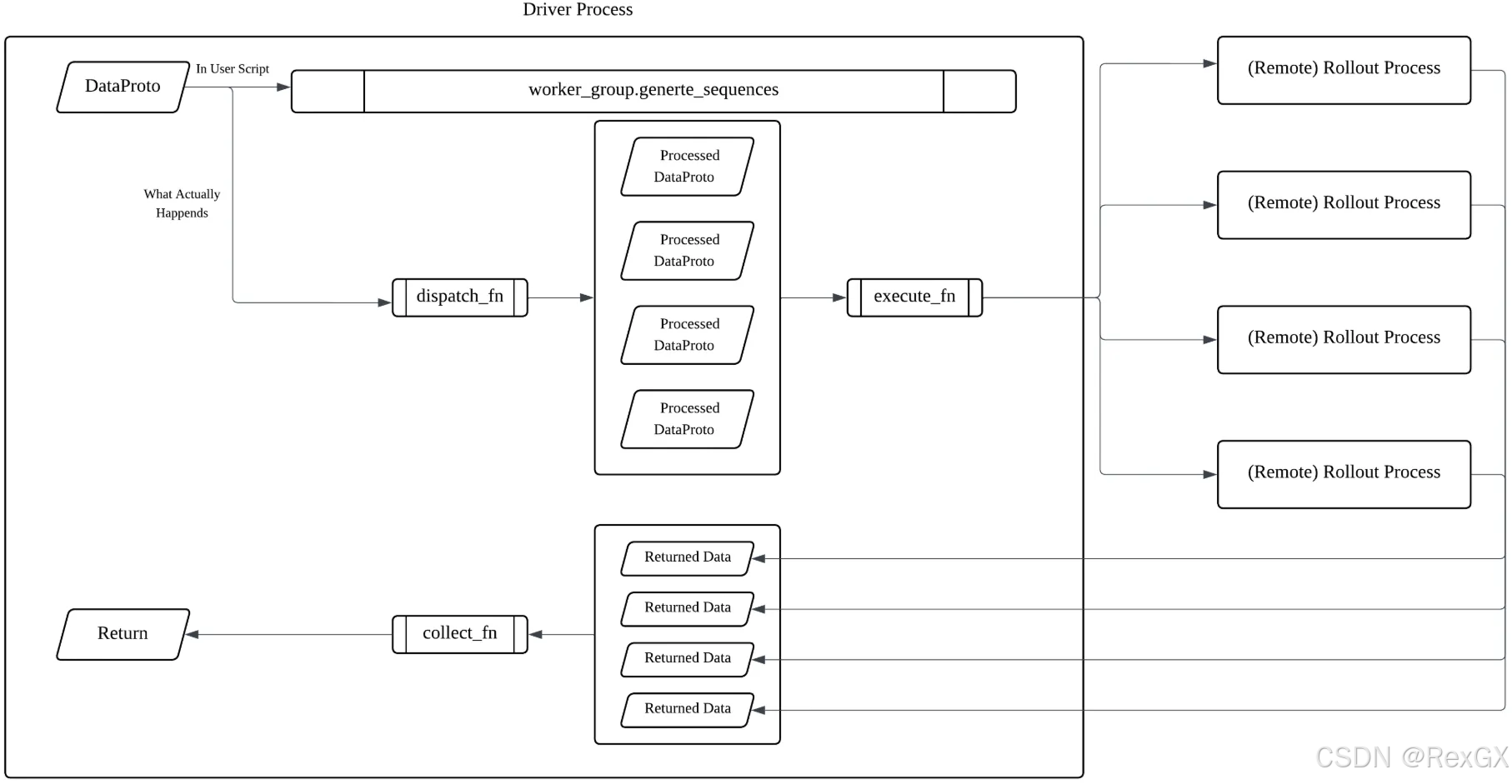
另外,關于driver和wroker的數據交互,大致可以分成3步:
driver把數據按DP數量進行切分- 把數據分發給每個
worker - 每個
worker再將執行的結果進行整合,所以VeRL這里搞了一個語法糖@register
class ActorRolloutRefWorker(Worker):@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)def generate_sequences(self, prompts: DataProto):prompts = prompts.to(torch.cuda.current_device())
上面的注解@register裝飾了方法generate_sequence,包含了 dispatch_mode對應的:
dispatch_func:把輸入dispatch到worker group中的各個workercollect_func:把worker group的各個worker的response collect到一起
下篇文章介紹下如何使用VeRL進行Agentic RL,也就是多輪RL。



)

)


)
-渲染列表)



![[硬件電路-212]:電流的本質確實是電子的移動](http://pic.xiahunao.cn/[硬件電路-212]:電流的本質確實是電子的移動)





)