?int 與 Integer 的區別是什么?若創建數量龐大的數字時使用 Integer,會對重復數字創建新對象嗎?
int 是 Java 中的基本數據類型,直接存儲數值,占用 4 個字節,默認值為 0,不需要通過 new 關鍵字創建,也不具備對象的特性,不能調用方法。而 Integer 是 int 的包裝類,屬于引用數據類型,存儲的是對象的引用(地址),默認值為 null,需要通過 new 關鍵字或自動裝箱創建,具備對象的特性,可以調用諸如 intValue()、compareTo() 等方法。
從使用場景來看,int 適用于簡單的數值運算、局部變量等場景,因為它在內存占用和訪問效率上更有優勢;Integer 則適用于需要對象特性的場景,比如作為集合(如 ArrayList<Integer>)的元素、泛型參數、反射調用等,因為集合和泛型不能直接使用基本數據類型。
關于創建數量龐大的數字時 Integer 是否對重復數字創建新對象,這涉及到 Integer 的緩存機制。Java 為了提高性能和減少內存占用,在 Integer 類中實現了一個緩存機制(IntegerCache),默認緩存了從 -128 到 127 之間的整數對象。當使用自動裝箱(如 Integer i = 100)或 valueOf() 方法創建這個范圍內的 Integer 對象時,會直接從緩存中獲取已存在的對象,而不會創建新對象;當數值超出這個范圍時,會創建新的 Integer 對象。例如:
Integer a = 100;
Integer b = 100;
System.out.println(a == b); // 輸出 true,因為從緩存獲取Integer c = 200;
Integer d = 200;
System.out.println(c == d); // 輸出 false,因為創建了新對象
不過,這個緩存范圍的上限(127)可以通過 JVM 參數?-XX:AutoBoxCacheMax=<size>?進行調整,但下限(-128)是固定的。
面試關鍵點:基本數據類型與包裝類的本質區別、自動裝箱/拆箱的原理、Integer 緩存機制的范圍和應用場景。
記憶法:可以通過“基值引對,緩存區間”來記憶,“基值”指 int 是基本數據類型存儲數值,“引對”指 Integer 是引用類型存儲對象引用,“緩存區間”則記住 -128 到 127 這個核心范圍。
String、StringBuilder、StringBuffer 的區別是什么?為什么阿里巴巴編程規約中不建議在 for 循環體里寫str += "a"這種代碼?
String、StringBuilder、StringBuffer 都是 Java 中用于處理字符串的類,但它們在可變性、線程安全性和性能上有顯著區別。
String 是不可變的(immutable),其底層是一個被 final 修飾的 char 數組(JDK 9 及以上改為 byte 數組),這意味著一旦創建 String 對象,其內容就無法修改。每次對 String 進行拼接、截取等操作時,都會創建新的 String 對象,原對象不會改變。這種特性使得 String 適合存儲不常修改的字符串,但頻繁修改時會產生大量無用對象,影響性能和內存。
StringBuilder 是可變的(mutable),底層也是一個 char 數組(或 byte 數組),但沒有被 final 修飾,其內部提供了 append()、insert() 等方法直接修改數組內容,不會創建新對象。它不具備線程安全特性,多個線程同時操作時可能出現數據不一致的問題,但由于避免了同步開銷,執行效率較高,適合單線程環境下頻繁修改字符串的場景。
StringBuffer 同樣是可變的,功能與 StringBuilder 基本一致,但它的所有方法都被 synchronized 修飾,具備線程安全特性。不過,同步機制會帶來額外的性能開銷,因此效率低于 StringBuilder,適合多線程環境下需要修改字符串的場景。
阿里巴巴編程規約不建議在 for 循環體里寫?str += "a"?這種代碼,核心原因與 String 的不可變性有關。在循環中使用?+=?拼接字符串時,每次拼接都會創建一個新的 String 對象,循環次數越多,產生的無用對象就越多,不僅會占用大量內存,還會增加垃圾回收的負擔,嚴重影響程序性能。例如,一個循環 1000 次的拼接操作,會創建 1000 個左右的 String 對象。
而如果使用 StringBuilder,通過 append() 方法進行拼接,整個過程只會創建一個 StringBuilder 對象,所有修改都在該對象內部完成,能顯著提升性能。示例如下:
// 不推薦的寫法
String str = "";
for (int i = 0; i < 1000; i++) {str += "a"; // 每次都會創建新的String對象
}// 推薦的寫法
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 1000; i++) {sb.append("a"); // 僅在一個對象上操作
}
String result = sb.toString();
面試關鍵點:三者的可變性、線程安全性對比;String 不可變性的底層原因;循環中字符串拼接的性能問題及優化方案。
記憶法:可以用“String 不變,Build 快不安全,Buffer 慢但安全,循環拼接用 Build”來記憶,既區分了三者的核心特性,也記住了循環中的最佳實踐。
Java 的 4 個訪問修飾符(public、protected、default、private)的作用是什么?類可以使用哪些訪問修飾符?為什么?
Java 中的 4 個訪問修飾符用于控制類、方法、字段等成員的訪問權限,從權限由大到小依次為 public、protected、default(缺省,即不寫修飾符)、private,具體作用如下:
public:具有最大的訪問權限,被其修飾的成員可以在任何地方被訪問,無論是否在同一個類、同一個包或不同包中。例如,一個 public 修飾的類,其所有 public 成員在項目的任何類中都可直接訪問。
protected:被修飾的成員可以在本類、同一個包中的其他類,以及不同包中的子類中訪問。需要注意的是,不同包中的非子類無法訪問 protected 成員。例如,類 A 有一個 protected 方法,包外的類 B 繼承了 A,則 B 可以訪問 A 的該方法,但包外的非子類 C 不能訪問。
default(缺省):當成員沒有顯式指定訪問修飾符時,默認使用該權限。被修飾的成員只能在本類和同一個包中的其他類中訪問,不同包中的類(包括子類)都無法訪問。
private:具有最小的訪問權限,被修飾的成員只能在當前類內部被訪問,同一個包中的其他類、不同包的類(包括子類)都無法直接訪問。通常用于封裝類的私有字段,通過 public 的 getter/setter 方法間接訪問,以保證數據的安全性。
關于類可以使用的訪問修飾符,只有 public 和 default 兩種。這是因為類的訪問修飾符需要考慮類的可見范圍:
- public 修飾的類可以被項目中所有的類訪問,適合作為對外提供功能的接口或公共類。
- default 修飾的類(即缺省)只能被同一個包中的類訪問,適合作為包內部的輔助類,對外隱藏實現細節。
而 protected 和 private 不能用于修飾類,原因如下:protected 的設計初衷是允許子類訪問父類的成員,若用于修飾類,在不同包中只有子類可訪問,但類的繼承關系并不能限制類本身的可見性,邏輯上不成立;private 修飾的類只能在自身內部被訪問,而類本身需要被其他類引用才能發揮作用,private 會導致類無法被外部使用,失去了存在的意義。
面試關鍵點:4 個訪問修飾符的權限范圍對比;類與類成員在訪問修飾符使用上的區別及原因;訪問修飾符在封裝和代碼安全性中的作用。
記憶法:可以通過“公全保包子,缺省同包友,私有僅自身;類修飾,公缺省,保護私有不可用”來記憶,前半句描述 4 個修飾符的權限范圍,后半句明確類的可用修飾符及原因。
Object 類中包含哪些常用方法?
Object 類是 Java 中所有類的根類,任何類都直接或間接繼承自 Object 類,因此它包含的方法是所有 Java 對象都具備的基礎功能,常用方法如下:
getClass():返回當前對象的運行時類(Class 對象)。該方法是 final 修飾的,無法被重寫。通過它可以獲取對象的類信息,如類名、父類、實現的接口等,常用于反射機制。例如:obj.getClass().getName()?可獲取對象所屬類的全限定名。
hashCode():返回對象的哈希碼值(int 類型)。哈希碼通常用于哈希表(如 HashMap、HashSet)中,作為對象的存儲索引,提高查找效率。默認實現是根據對象的內存地址計算的,但子類可以重寫該方法,通常與 equals() 方法一起重寫,以保證“相等的對象必須有相等的哈希碼”。
equals(Object obj):判斷當前對象與參數 obj 是否“相等”。默認實現是?return (this == obj),即比較兩個對象的內存地址(引用是否相同)。但實際業務中,通常需要重寫該方法來定義對象的邏輯相等(如兩個對象的屬性值相同則認為相等),重寫時需遵循自反性、對稱性、傳遞性等規則。
clone():創建并返回當前對象的一個副本(克隆對象)。該方法是 protected 修飾的,子類若要使用需重寫并改為 public 修飾,且類需實現 Cloneable 接口(否則會拋出 CloneNotSupportedException)。克隆分為淺克隆和深克隆,默認是淺克隆(僅復制對象本身及基本類型字段,引用類型字段仍指向原對象)。
toString():返回對象的字符串表示形式。默認實現是?getClass().getName() + "@" + Integer.toHexString(hashCode()),即類名@哈希碼的十六進制形式。實際開發中通常重寫該方法,返回對象的關鍵屬性信息,方便日志打印和調試。
notify():喚醒在此對象的監視器上等待的單個線程。若有多個線程等待,隨機選擇一個喚醒,該線程需重新獲取對象的鎖才能繼續執行。
notifyAll():喚醒在此對象的監視器上等待的所有線程,這些線程會競爭獲取對象的鎖,最終只有一個線程能獲得鎖并繼續執行,其他線程繼續等待。
wait():使當前線程進入等待狀態,釋放對象的鎖,并在其他線程調用該對象的 notify() 或 notifyAll() 方法時被喚醒,或等待指定時間后自動喚醒。該方法有三個重載版本:wait()(無限期等待)、wait(long timeout)(等待指定毫秒數)、wait(long timeout, int nanos)(更精確的等待時間)。
finalize():當垃圾回收器確定對象不再被引用時,會調用該方法進行資源清理。但該方法的執行時間不確定,且 Java 9 及以上已標記為過時(deprecated),不推薦使用,通常用 try-with-resources 或顯式的 close() 方法替代。
面試關鍵點:各方法的功能和使用場景;hashCode() 與 equals() 的關系;clone() 的克隆機制;wait() 與 notify()/notifyAll() 在多線程通信中的作用。
記憶法:可以用“類信 getClass,哈希 equals 辨,克隆 clone 制副本,toString 顯信息,notify 喚醒 wait 眠,finalize 回收前”來記憶,每句對應一個核心方法的功能,便于快速聯想。
Object 類中的 equals () 和 hashCode () 默認實現是什么?重寫 equals () 但不重寫 hashCode () 會有什么問題?
Object 類中 equals() 方法的默認實現是比較兩個對象的引用是否相同,即判斷兩個對象是否指向同一塊內存地址,其源碼大致為:public boolean equals(Object obj) { return (this == obj); }。這里的?==?對于基本數據類型是比較值,對于引用數據類型就是比較內存地址。
hashCode() 方法的默認實現是根據對象的內存地址計算出一個整數哈希碼值,源碼通常通過本地方法(native method)實現,如?public native int hashCode();。這意味著不同內存地址的對象,其默認哈希碼一般不同;同一對象(內存地址不變)的哈希碼始終相同。
在 Java 中,hashCode() 和 equals() 存在一個重要的約定:如果兩個對象通過 equals() 方法判斷為相等(返回 true),那么它們的 hashCode() 方法必須返回相同的哈希碼;反之,兩個對象的 hashCode() 返回相同的哈希碼,它們的 equals() 不一定返回 true(哈希沖突允許存在)。
若重寫了 equals() 但沒有重寫 hashCode(),會違反上述約定,引發一系列問題,尤其是在使用哈希表(如 HashMap、HashSet、HashTable 等)時:
當兩個對象通過重寫的 equals() 方法判斷為相等時,由于未重寫 hashCode(),它們的默認哈希碼可能不同(因為內存地址不同)。在 HashMap 中,對象的存儲位置由 hashCode() 計算的哈希值決定,這會導致兩個相等的對象被存入不同的桶中。此時,當使用 containsKey() 或 contains() 等方法查找對象時,可能無法找到預期的對象,因為哈希表會先根據 hashCode() 定位桶,再在桶內通過 equals() 比較,而兩個相等的對象可能在不同的桶中,導致查找失敗。
例如:
class Person {private String name;public Person(String name) {this.name = name;}// 重寫equals(),認為name相同則對象相等@Overridepublic boolean equals(Object obj) {if (this == obj) return true;if (obj == null || getClass() != obj.getClass()) return false;Person person = (Person) obj;return name.equals(person.name);}// 未重寫hashCode()
}public class Test {public static void main(String[] args) {Person p1 = new Person("Alice");Person p2 = new Person("Alice");System.out.println(p1.equals(p2)); // 輸出true,認為相等HashMap<Person, Integer> map = new HashMap<>();map.put(p1, 1);System.out.println(map.get(p2)); // 輸出null,因為p1和p2哈希碼不同,get(p2)找不到}
}
上述代碼中,p1 和 p2 通過 equals() 判斷為相等,但由于未重寫 hashCode(),它們的哈希碼不同,導致 p2 無法從 HashMap 中獲取到 p1 存入的值,違背了哈希表的設計邏輯。
面試關鍵點:equals() 和 hashCode() 的默認實現邏輯;兩者的約定關系;未同時重寫時在哈希表中的問題;重寫時的最佳實踐(如基于相同字段計算哈希碼)。
記憶法:可以用“默認 equals 比地址,hashCode 隨地址;重寫 equals 必重寫 hashCode,否則哈希表找不著”來記憶,突出兩者的關聯和不同步重寫的后果。
final 關鍵字和 finally 關鍵字的區別是什么?
final 和 finally 是 Java 中功能完全不同的關鍵字,主要區別體現在作用、使用場景和語法上。
final 關鍵字用于限制程序元素的可變性,可修飾類、方法和變量,分別產生不同的約束:修飾類時,該類不能被繼承(如 String 類被 final 修飾,無法創建其子類);修飾方法時,該方法不能被子類重寫(可防止方法實現被篡改);修飾變量時,變量一旦被賦值就不能再修改(對于基本類型,值不可變;對于引用類型,引用地址不可變,但對象內容可修改)。例如:
// final修飾類,不可繼承
final class FinalClass {}// final修飾方法,不可重寫
class Parent {final void finalMethod() {}
}
class Child extends Parent {// 編譯錯誤,無法重寫final方法// void finalMethod() {}
}// final修飾變量,不可修改
class Test {final int num = 10;void changeNum() {// 編譯錯誤,無法修改final變量// num = 20;}
}
finally 關鍵字僅用于異常處理機制,與 try 語句塊配合使用,用于定義無論是否發生異常都必須執行的代碼塊。通常用于釋放資源(如關閉文件流、數據庫連接等),確保資源不會因異常而泄漏。例如:
FileInputStream fis = null;
try {fis = new FileInputStream("file.txt");// 讀取文件操作
} catch (IOException e) {e.printStackTrace();
} finally {// 無論是否發生異常,都關閉流if (fis != null) {try {fis.close();} catch (IOException e) {e.printStackTrace();}}
}
需要注意,finally 唯一不執行的情況是在 try 或 catch 塊中調用了 System.exit(0)(終止虛擬機),此時程序直接退出,finally 塊不會執行。
面試關鍵點:final 對類、方法、變量的不同約束;finally 在異常處理中的作用及執行時機;兩者在語法和功能上的本質區別。
記憶法:可通過“final 定不可變,類不繼、法不重、量不改;finally 保執行,資源釋放離不了”來記憶,清晰區分兩者的核心特性。
Java 的異常體系結構是怎樣的?項目中如何使用異常?受檢異常和非受檢異常的區別是什么?(舉例:運行時異常如 NullPointerException,非運行時異常如 IOException)
Java 的異常體系以 Throwable 為根類,所有異常和錯誤都直接或間接繼承自該類,體系結構可分為兩大分支:
一是 Error,代表程序無法處理的嚴重錯誤,通常由 JVM 拋出,如 OutOfMemoryError(內存溢出)、StackOverflowError(棧溢出)等。這類錯誤發生時,程序一般會終止,開發者無需捕獲或處理,因為通常無法通過代碼修復。
二是 Exception,代表程序可以處理的異常,是開發者需要關注的核心。Exception 又分為兩類:受檢異常(Checked Exception)和非受檢異常(Unchecked Exception)。
受檢異常是指除 RuntimeException 及其子類之外的 Exception 子類(如 IOException、SQLException 等)。編譯器會強制要求開發者處理這類異常,要么通過 try-catch 塊捕獲,要么在方法上用 throws 聲明拋出,否則編譯不通過。例如,讀取文件時可能拋出的 IOException 就是受檢異常,必須顯式處理。
非受檢異常即 RuntimeException 及其子類(如 NullPointerException、IndexOutOfBoundsException、IllegalArgumentException 等)。這類異常通常由程序邏輯錯誤導致,編譯器不強制要求處理,開發者可根據需要選擇捕獲或拋出。例如,調用 null 對象的方法會拋出 NullPointerException,屬于非受檢異常。
項目中使用異常需遵循以下原則:避免濫用異常(不應用異常控制正常流程);具體明確(捕獲特定異常而非籠統的 Exception);不吞異常(避免空的 catch 塊,至少記錄日志);傳遞有意義的信息(異常信息應清晰描述錯誤原因);資源釋放放在 finally 或使用 try-with-resources。例如:
// 合理使用異常示例
public String readFile(String path) throws IOException { // 聲明受檢異常try (BufferedReader br = new BufferedReader(new FileReader(path))) { // try-with-resources自動釋放資源return br.readLine();} catch (FileNotFoundException e) { // 捕獲特定異常log.error("文件未找到: {}", path, e); // 記錄日志throw new RuntimeException("讀取文件失敗: 文件不存在", e); // 包裝異常并拋出}
}
受檢異常和非受檢異常的核心區別:受檢異常在編譯期檢查,必須顯式處理;非受檢異常在運行期發生,編譯期不強制處理。前者通常與外部資源交互相關(如 IO、數據庫操作),后者多與程序邏輯錯誤相關(如空指針、數組越界)。
面試關鍵點:異常體系的層級結構;Error 與 Exception 的區別;受檢與非受檢異常的判斷標準及處理差異;項目中異常處理的最佳實踐。
記憶法:可通過“Throwable 為根,Error 嚴重 Exception 可處理;受檢編譯必處理,非受運行邏輯錯”來記憶,快速梳理體系和核心區別。
什么是 Java 反射機制?框架中哪些地方用到了反射?

Java 反射機制是指程序在運行時可以動態獲取類的信息(如類名、父類、接口、方法、字段等),并能動態調用類的方法、訪問或修改字段的能力。這種動態性打破了編譯期的類型約束,允許程序在運行時操作未知類型的對象。
反射的實現依賴于 Java 提供的 java.lang.reflect 包,核心類包括:Class(代表類的字節碼對象,是反射的入口)、Method(代表類的方法)、Field(代表類的字段)、Constructor(代表類的構造方法)等。通過這些類,可完成反射的核心操作:獲取 Class 對象(如 Class.forName("com.example.User")、user.getClass()、User.class);獲取類的成員(如 getMethods() 獲取所有公共方法、getDeclaredFields() 獲取所有字段);調用方法(如 method.invoke(obj, args));訪問或修改字段(如 field.set(obj, value))。
例如,通過反射創建對象并調用方法:
class User {private String name;public User(String name) {this.name = name;}public void sayHello() {System.out.println("Hello, " + name);}
}public class ReflectionDemo {public static void main(String[] args) throws Exception {// 獲取Class對象Class<?> userClass = Class.forName("User");// 獲取構造方法并創建對象Constructor<?> constructor = userClass.getConstructor(String.class);Object user = constructor.newInstance("Alice");// 獲取方法并調用Method sayHelloMethod = userClass.getMethod("sayHello");sayHelloMethod.invoke(user); // 輸出:Hello, Alice}
}
反射在眾多框架中被廣泛使用,是框架實現靈活性和動態性的核心技術:
Spring 框架的 IOC(控制反轉)容器通過反射創建對象:當 Spring 啟動時,解析配置文件或注解(如 @Component),獲取類的全限定名,通過 Class.forName() 加載類,再用反射調用構造方法創建對象,存入容器中管理。
MyBatis 框架的 SQL 映射:MyBatis 解析 Mapper 接口和 XML 配置后,通過反射動態生成接口的代理對象;在結果集映射時,使用反射將數據庫字段值設置到 Java 對象的對應字段中。
JUnit 測試框架:如 @Test 注解,JUnit 運行時通過反射掃描類中帶有 @Test 的方法,并動態調用這些方法執行測試。
注解處理器:許多框架(如 Lombok、Spring Boot)通過反射解析類、方法上的注解(如 @Data、@Controller),根據注解信息生成代碼或執行特定邏輯。
面試關鍵點:反射的定義和核心類;反射的基本操作(獲取 Class 對象、調用方法等);反射在主流框架中的具體應用;反射的優缺點(靈活性高但性能略低、破壞封裝性)。
記憶法:可通過“反射運行時,探類獲信息,調方法改屬性,框架動態靠它起”來記憶,概括反射的核心能力和應用場景。
什么是 Java 泛型?泛型擦除是什么意思?List<int> list = new ArrayList()這種寫法有什么問題?
Java 泛型是 JDK 5 引入的特性,允許在定義類、接口、方法時指定類型參數(即參數化類型),使代碼能操作多種數據類型而無需重復編寫,同時在編譯期提供類型安全檢查,避免運行時的 ClassCastException。
泛型的核心作用是“參數化類型”,例如定義泛型類:
// 泛型類,T為類型參數
class Box<T> {private T value;public T getValue() { return value; }public void setValue(T value) { this.value = value; }
}// 使用時指定具體類型
Box<String> stringBox = new Box<>();
stringBox.setValue("Hello");
String str = stringBox.getValue(); // 無需強制轉換,編譯期檢查類型
泛型擦除是指 Java 泛型僅在編譯期有效,編譯后字節碼中會移除泛型的類型參數信息,替換為原始類型(即泛型類定義時的上限類型,若無上限則為 Object)。例如,編譯后的 Box<String> 和 Box<Integer> 都會被擦除為 Box(原始類型),這是因為 Java 為了兼容泛型引入前的代碼而采用的“偽泛型”實現。
泛型擦除會導致一些現象:運行時無法獲取泛型的具體類型(如 list.getClass() == ArrayList.class,無論泛型參數是什么);泛型數組創建受限(如 new T[] 不允許,需強制轉換);靜態方法中不能使用類的泛型參數(因為靜態成員屬于類,而泛型參數與實例相關)。
List<int> list = new ArrayList()?這種寫法存在兩個問題:
一是泛型參數不支持基本數據類型。Java 泛型的類型參數必須是引用類型(如 Integer、String),而 int 是基本數據類型,無法作為泛型參數。這是因為泛型擦除后會使用 Object 或上限類型存儲數據,而基本數據類型不繼承自 Object,無法直接存儲,需通過包裝類(如 Integer)實現。正確寫法應為?List<Integer> list = new ArrayList<>()。
二是未使用菱形語法(Diamond Operator),雖然在 JDK 7 及以上允許右側省略泛型參數(即?new ArrayList<>()),但左側聲明了泛型而右側未明確時,仍能編譯通過(兼容舊代碼),但可能失去部分類型安全檢查。更規范的寫法是兩側保持一致,即?List<Integer> list = new ArrayList<>()。
面試關鍵點:泛型的定義和作用;泛型擦除的概念及影響;泛型對基本數據類型的限制;泛型在集合、方法中的應用。
記憶法:可通過“泛型參數化,編譯保安全;擦除去類型,基本不用包裝換”來記憶,涵蓋泛型的核心特性和常見問題。
什么是 Java 注解?注解有哪些常見用途?
Java 注解(Annotation)是 JDK 5 引入的一種特殊標記,用于為代碼(類、方法、字段等)提供元數據(描述數據的數據)。注解本身不直接影響代碼的執行邏輯,但可通過工具(編譯器、框架等)在編譯期或運行時解析這些元數據,從而實現特定功能。
注解的定義與接口類似,需使用 @interface 關鍵字,可包含成員變量(以方法形式聲明),并可通過元注解(修飾注解的注解)指定其保留策略、適用目標等。常見的元注解包括:
- @Retention:指定注解的保留階段,有 SOURCE(僅編譯期保留,如 @Override)、CLASS(編譯期保留到字節碼,默認)、RUNTIME(保留到運行時,可通過反射獲取,如 @Controller)。
- @Target:指定注解可修飾的元素(如 TYPE 用于類、METHOD 用于方法、FIELD 用于字段等)。
- @Inherited:允許子類繼承父類的注解。
- @Documented:注解會被包含在 Javadoc 文檔中。
例如,定義一個簡單的注解:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
public @interface Log {String value() default "操作日志"; // 注解成員,默認值為"操作日志"
}
注解的常見用途包括:
編譯期檢查與提示:編譯器可通過注解檢測代碼錯誤或提供提示。例如 @Override 用于標記方法重寫父類方法,若方法簽名與父類不一致,編譯器會報錯;@Deprecated 標記過時的類或方法,使用時編譯器會警告。
框架配置與依賴注入:主流框架(如 Spring、Spring Boot)大量使用注解簡化配置。例如 @Controller 標記控制器類,@Service 標記服務類,Spring 會自動掃描并管理這些類的實例;@Autowired 實現依賴注入,自動裝配所需對象。
生成文檔與代碼:通過注解可生成 Javadoc 文檔(如 @param、@return 描述方法參數和返回值),或通過工具(如 Lombok)根據注解生成代碼(如 @Data 自動生成 getter、setter、toString 等方法)。
測試框架標記:測試框架(如 JUnit)用注解標記測試方法。例如 JUnit 的 @Test 標記測試方法,框架運行時會自動執行這些方法;@BeforeEach 標記測試前的初始化方法。
運行時動態處理:通過反射在運行時解析注解,執行特定邏輯。例如自定義 @Log 注解,結合 AOP 實現方法調用日志的自動記錄,無需手動編寫日志代碼。
面試關鍵點:注解的定義和元注解的作用;注解的保留策略;注解在編譯期和運行時的應用場景;常見內置注解和框架注解的示例。
記憶法:可通過“注解是標簽,元數據來帶;編譯查錯誤,框架配依賴,文檔代碼生,測試運行改”來記憶,涵蓋注解的本質和主要用途。
對面向對象的理解是什么?(圍繞封裝、繼承、多態等核心特性說明)
面向對象是一種以“對象”為核心的編程范式,通過抽象現實世界中的實體及其關系,將數據和操作數據的方法封裝在一起,強調“做什么”而非“怎么做”,核心特性包括封裝、繼承和多態,它們相互配合實現代碼的復用、擴展和維護性。
封裝是面向對象的基礎,指將對象的屬性(數據)和方法(操作)捆綁在一起,隱藏內部實現細節,僅通過公共接口與外部交互。通過訪問修飾符(private、protected、public等)控制屬性和方法的可見性,例如將類的字段設為private,僅允許通過public的getter/setter方法訪問或修改,確保數據的安全性和一致性。例如:
class Person {private String name; // 私有字段,外部無法直接訪問private int age;// 公共方法,提供訪問接口public String getName() { return name; }public void setName(String name) {if (name != null && !name.isEmpty()) { // 加入校驗邏輯this.name = name;}}
}
繼承是指子類通過extends關鍵字繼承父類的屬性和方法,實現代碼復用,同時子類可新增特性或重寫父類方法以適應自身需求。繼承體現“is-a”關系(如“學生是一種人”),但需避免過度繼承導致的耦合性過高。例如:
class Animal {void eat() { System.out.println("動物進食"); }
}
class Dog extends Animal {@Override // 重寫父類方法void eat() { System.out.println("狗吃骨頭"); }void bark() { System.out.println("狗叫"); } // 新增方法
}
多態是指同一行為(方法調用)在不同對象上有不同實現,通過“父類引用指向子類對象”實現。多態允許程序在運行時根據實際對象類型動態調用對應方法,提高代碼的靈活性和擴展性。多態的實現依賴于繼承(或接口實現)和方法重寫,例如:
Animal animal = new Dog(); // 父類引用指向子類對象
animal.eat(); // 運行時調用Dog的eat(),輸出“狗吃骨頭”
此外,面向對象還包括抽象(通過抽象類和接口定義規范,不關注具體實現)、組合(“has-a”關系,如“汽車有發動機”,比繼承更靈活)等思想。這些特性共同作用,使代碼更貼近現實邏輯、易于維護和擴展,是大型軟件開發的主流范式。
面試關鍵點:封裝的實現方式及意義;繼承的優缺點和適用場景;多態的實現原理(動態綁定)及實際價值;抽象與組合在面向對象中的作用。
記憶法:可通過“封裝藏細節,繼承復用加擴展,多態同調異實現,抽象定規范”來記憶,概括核心特性的本質和關系。
什么是 Java 的單例模式?常見的單例模式實現方式有哪些?
Java的單例模式是一種創建型設計模式,確保一個類在整個應用中只有一個實例,并提供一個全局訪問點,避免頻繁創建對象導致的資源浪費(如配置類、工具類、線程池等場景)。單例模式的核心是限制類的實例化次數,通常通過私有構造方法防止外部創建對象,再提供靜態方法返回唯一實例。
常見的單例模式實現方式及特點如下:
- 餓漢式:類加載時就創建實例,天然線程安全,但可能提前占用資源。
public class Singleton {// 類加載時初始化實例private static final Singleton INSTANCE = new Singleton();// 私有構造方法,防止外部實例化private Singleton() {}// 全局訪問點public static Singleton getInstance() {return INSTANCE;}
}
- 懶漢式(線程不安全):延遲初始化,第一次調用時創建實例,但多線程環境下可能創建多個實例,僅適用于單線程。
public class Singleton {private static Singleton instance;private Singleton() {}// 線程不安全,多線程同時調用可能創建多個實例public static Singleton getInstance() {if (instance == null) {instance = new Singleton();}return instance;}
}
- 懶漢式(線程安全,同步方法):通過synchronized修飾getInstance()方法保證線程安全,但每次調用都加鎖,性能較差。
public static synchronized Singleton getInstance() {if (instance == null) {instance = new Singleton();}return instance;
}
- 雙重檢查鎖(DCL):優化同步效率,僅在實例未創建時加鎖,且使用volatile防止指令重排序導致的半初始化問題,兼顧懶加載和線程安全。
public class Singleton {// volatile防止指令重排序private static volatile Singleton instance;private Singleton() {}public static Singleton getInstance() {if (instance == null) { // 第一次檢查,避免頻繁加鎖synchronized (Singleton.class) {if (instance == null) { // 第二次檢查,防止多線程同時通過第一次檢查instance = new Singleton();}}}return instance;}
}
- 靜態內部類:利用類加載機制實現懶加載和線程安全(靜態內部類僅在被調用時加載),性能優,是推薦的實現方式。
public class Singleton {private Singleton() {}// 靜態內部類,僅在getInstance()調用時加載private static class SingletonHolder {private static final Singleton INSTANCE = new Singleton();}public static Singleton getInstance() {return SingletonHolder.INSTANCE;}
}
- 枚舉:天然防止反射和序列化破壞單例(枚舉的構造方法由JVM控制,無法通過反射實例化),實現簡單且絕對安全。
public enum Singleton {INSTANCE; // 唯一實例// 枚舉中可定義方法public void doSomething() {}
}
面試關鍵點:各實現方式的線程安全性、懶加載特性、性能差異;防止反射和序列化破壞單例的方法;不同場景下的選擇(如簡單場景用餓漢式,需懶加載用靜態內部類或DCL,安全性優先用枚舉)。
記憶法:可通過“餓漢加載早安全,懶漢懶加載需同步,雙重檢查鎖效率高,靜態內部類推薦,枚舉防破壞最佳”來記憶,快速區分各實現的核心特點。
Java 中的 BIO、NIO、AIO 分別是什么?它們的區別和應用場景是什么?
Java中的BIO、NIO、AIO是三種IO模型,分別對應阻塞IO、非阻塞IO、異步IO,核心區別在于處理IO操作時的阻塞特性和線程使用方式,適用于不同的并發場景。
BIO(Blocking IO,阻塞IO)是Java最早的IO模型,基于流(InputStream/OutputStream)操作,特點是“同步阻塞”:當線程執行read()或write()操作時,若數據未準備好(如網絡數據未到達),線程會被阻塞,直到操作完成才繼續執行。每個連接需要一個獨立線程處理,若并發量大,會創建大量線程,導致CPU和內存資源耗盡,性能低下。例如傳統的Socket編程:
// BIO示例:一個線程處理一個連接
ServerSocket serverSocket = new ServerSocket(8080);
while (true) {Socket socket = serverSocket.accept(); // 阻塞,等待連接new Thread(() -> {try (InputStream in = socket.getInputStream()) {byte[] buffer = new byte[1024];in.read(buffer); // 阻塞,等待數據} catch (IOException e) {e.printStackTrace();}}).start();
}
NIO(Non-blocking IO,非阻塞IO)是JDK 1.4引入的IO模型,基于通道(Channel)和緩沖區(Buffer),核心是“同步非阻塞”:通過Selector(多路復用器)管理多個通道,一個線程可處理多個連接。當通道上的IO操作未就緒時,線程不會阻塞,可處理其他通道;當操作就緒時,Selector通知線程處理。NIO避免了大量線程創建,適合高并發場景,核心組件包括:
- Channel:雙向通道(如SocketChannel、ServerSocketChannel),可讀寫數據。
- Buffer:數據容器(如ByteBuffer),通道的數據需通過緩沖區傳輸。
- Selector:監聽通道的事件(如連接就緒、讀就緒、寫就緒),實現多路復用。
// NIO核心流程示意
Selector selector = Selector.open();
ServerSocketChannel serverChannel = ServerSocketChannel.open();
serverChannel.configureBlocking(false); // 設置非阻塞
serverChannel.register(selector, SelectionKey.OP_ACCEPT); // 注冊接受連接事件while (true) {selector.select(); // 阻塞,等待事件就緒(可設置超時)Set<SelectionKey> keys = selector.selectedKeys();for (SelectionKey key : keys) {if (key.isAcceptable()) {// 處理新連接} else if (key.isReadable()) {// 處理讀操作}keys.remove(key);}
}
AIO(Asynchronous IO,異步IO)是JDK 1.7引入的IO模型,基于“異步非阻塞”:線程發起IO操作后立即返回,無需等待操作完成;當IO操作完成(或失敗)時,系統通過回調函數通知線程處理結果,全程不阻塞線程。AIO更適合IO密集型場景,尤其是對響應時間要求不高的大文件操作。
三者的核心區別:
- 阻塞性:BIO是阻塞的,NIO在Selector.select()時可能阻塞但可設置超時,AIO全程非阻塞。
- 線程效率:BIO一個連接一個線程,效率低;NIO一個線程處理多個連接,效率高;AIO依賴回調,線程利用率最高。
- 編程復雜度:BIO簡單直接,NIO需理解Selector和通道,AIO基于Future和回調,復雜度最高。
應用場景:BIO適用于連接數少、數據傳輸快的場景(如簡單的內部服務);NIO適用于高并發、數據傳輸頻繁的場景(如Netty框架、即時通訊);AIO適用于IO操作耗時較長、并發量高的場景(如大文件上傳下載、分布式存儲)。
面試關鍵點:三種IO模型的阻塞特性;NIO的核心組件(Channel、Buffer、Selector)及工作原理;AIO與NIO的本質區別;不同模型的適用場景及性能對比。
記憶法:可通過“BIO阻塞單連接一線程,NIO非阻塞Selector管多線,AIO異步等回調不阻塞”來記憶,概括三者的核心差異和工作方式。
啟動兩個 Java 進程,它們的 JVM 是共享的嗎?
啟動兩個Java進程時,它們的JVM是完全獨立的,不存在共享關系。這是由操作系統的進程隔離特性和JVM的運行機制共同決定的。
從進程本質來看,每個Java程序的啟動都會觸發操作系統創建一個獨立的進程(通過java命令),而每個進程對應一個獨立的JVM實例。操作系統會為每個進程分配獨立的內存空間(虛擬地址空間),進程之間的內存無法直接訪問,確保了進程的隔離性。JVM作為進程內的運行時環境,其所有組成部分(如堆、方法區、虛擬機棧、本地方法棧、程序計數器等內存區域)都屬于所屬進程的私有內存,兩個Java進程的JVM內存區域完全隔離,彼此無法共享數據。例如,一個進程中修改的靜態變量,在另一個進程中不會受到任何影響。
從JVM的運行機制來看,每個JVM實例有自己獨立的類加載器體系(如 Bootstrap ClassLoader、Extension ClassLoader、Application ClassLoader),即使加載同一個類(如java.lang.String),在兩個JVM中也會生成不同的Class對象(盡管字節碼相同,但內存地址不同)。此外,每個JVM有自己的線程管理系統、垃圾回收器、即時編譯器(JIT)等組件,這些組件的運行狀態和數據也完全獨立,不會相互干擾。
舉例來說,同時啟動兩個Java程序(如兩個Spring Boot應用),它們會在操作系統中顯示為兩個獨立的進程(可通過任務管理器或ps命令查看),各自占用獨立的CPU和內存資源。當一個進程崩潰或被終止時,另一個進程不受影響,這也印證了JVM的獨立性。
需要注意的是,若兩個Java進程需要通信,不能直接通過內存共享,必須通過進程間通信(IPC)機制,如Socket網絡通信、共享文件、消息隊列(如RabbitMQ)等。
面試關鍵點:Java進程與JVM的一一對應關系;進程隔離對JVM內存和組件的影響;跨進程通信的必要性及方式。
記憶法:可通過“一進程一JVM,內存組件各獨立,互不相干需通信”來記憶,明確兩個Java進程的JVM無共享關系。
C++ 的模板和 Java 的泛型有什么區別?
C++的模板和Java的泛型都用于實現代碼復用(編寫與類型無關的通用代碼),但兩者在實現機制、類型處理、功能范圍等方面有本質區別,核心差異源于C++的“編譯期實例化”和Java的“泛型擦除”機制。
實現機制不同:C++模板是“編譯期多態”,編譯器會為每個模板參數的具體類型生成獨立的代碼(模板實例化)。例如,
template <class T> class Box在使用Box<int>和Box<string>時,編譯器會分別生成針對int和string的Box類代碼,兩者是完全不同的類型。而Java泛型采用“類型擦除”機制,編譯后泛型的類型參數會被擦除(替換為上限類型,無上限則為Object),例如Box<Integer>和Box<String>編譯后都會被擦除為Box(原始類型),字節碼中不保留泛型參數信息,僅在編譯期進行類型檢查。類型支持不同:C++模板支持所有類型(基本類型、自定義類型、指針等),無需包裝。例如
template <class T> T add(T a, T b)可直接用于add(1, 2)(int類型)。而Java泛型不支持基本數據類型,必須使用對應的包裝類(如int需用Integer),因為類型擦除后會用Object存儲數據,而基本類型不繼承自Object。因此List<int>是非法的,必須寫成List<Integer>。類型檢查時機不同:C++模板的類型檢查在實例化階段(編譯期),針對具體類型檢查方法是否兼容。例如
Box<int>調用append("str")會在編譯期報錯,因為int類型不支持字符串操作。Java泛型的類型檢查在編譯期(基于泛型參數),但運行時由于類型擦除,無法獲取泛型參數信息(如list.getClass() == ArrayList.class,與泛型參數無關),可能出現運行時類型轉換錯誤(需顯式強制轉換)。靈活性與功能范圍不同:C++模板支持“模板元編程”,可在編譯期執行計算(如編譯期求階乘),甚至生成代碼,功能更強大但復雜度高。Java泛型受類型擦除限制,無法在運行時獲取泛型參數類型,不支持模板特化(為特定類型提供不同實現)等高級特性,功能相對簡單但更安全。
繼承關系不同:C++中模板實例化的不同類型之間無繼承關系,
Box<int>和Box<string>是完全獨立的類,無法相互賦值。Java中Box<Integer>和Box<String>擦除后都是Box,但編譯器會阻止Box<Integer> = Box<String>的賦值(泛型安全性檢查)。
面試關鍵點:實現機制(實例化vs擦除)的核心差異;對基本類型的支持;類型檢查的時機和方式;功能范圍的差異(如模板元編程)。
記憶法:可通過“C++模板編譯實例化,類型全支持,元編程強;Java泛型擦除,基本用包裝,運行無類型”來記憶,清晰區分兩者的核心區別。
C++ 和 Java 的內存模型有什么區別?(可從內存分區、垃圾回收(引用計數與可達性分析)、垃圾回收器、對象生命周期等方面說明)
C++ 和 Java 的內存模型在設計理念和實現機制上存在顯著差異,主要體現在內存分區、垃圾回收、對象生命周期等方面,這些差異源于 C++ 對性能和靈活性的追求,以及 Java 對安全性和開發效率的側重。
從內存分區來看,C++ 的內存分區主要包括:棧(存儲局部變量、函數參數等,由編譯器自動分配和釋放)、堆(動態分配的內存,需手動管理,如?new?分配、delete?釋放)、全局/靜態存儲區(存儲全局變量和靜態變量,程序啟動時分配,結束時釋放)、常量存儲區(存儲字符串常量等,只讀)。而 Java 的內存模型基于 JVM 定義,主要包括:方法區(存儲類信息、常量、靜態變量等,JDK 8 后改為元空間,使用本地內存)、堆(存儲對象實例,是垃圾回收的主要區域)、虛擬機棧(存儲方法調用的棧幀,包含局部變量表、操作數棧等)、本地方法棧(類似虛擬機棧,用于本地方法調用)、程序計數器(記錄當前線程執行的字節碼地址)。兩者的核心區別是 Java 內存分區由 JVM 嚴格管理,而 C++ 內存分區更依賴操作系統和編譯器,開發者對內存的直接控制更強。
在垃圾回收方面,C++ 沒有內置的自動垃圾回收機制,內存管理完全由開發者負責:通過?new?分配的堆內存必須手動用?delete?釋放,否則會導致內存泄漏;部分場景下(如智能指針?shared_ptr)會使用引用計數算法(記錄對象被引用的次數,為 0 時自動釋放),但這屬于庫實現而非語言原生特性,且無法解決循環引用問題(如兩個對象相互引用,引用計數始終不為 0,導致內存泄漏)。Java 則內置自動垃圾回收機制,核心是通過可達性分析算法判斷對象是否存活:以 GC Roots(如虛擬機棧中的引用、靜態變量等)為起點,遍歷對象引用鏈,不可達的對象被標記為可回收。這種方式能解決循環引用問題,且無需開發者手動干預,降低了內存管理錯誤的風險。
垃圾回收器的支持也不同:C++ 沒有語言級別的垃圾回收器,所有內存釋放依賴手動操作或第三方庫;Java 則提供了多種垃圾回收器,針對不同場景優化,如 SerialGC(單線程回收,適合單CPU環境)、ParallelGC(多線程回收,注重吞吐量)、CMS(并發標記清除,注重響應時間)、G1(區域化分代式,平衡吞吐量和響應時間)、ZGC/Shenandoah(低延遲回收器,適合大堆場景)等,開發者可根據應用需求選擇。
對象生命周期方面,C++ 對象的生命周期完全由開發者控制:棧上的對象隨作用域結束自動銷毀;堆上的對象需顯式調用?delete,否則會一直存在(直到程序結束),可能導致內存泄漏。Java 對象的生命周期由 JVM 管理:對象在堆上創建,當被判定為不可達時,由垃圾回收器自動回收,開發者無需關心釋放時機,但需注意避免內存泄漏(如長期持有無用對象的引用,導致對象無法被回收)。
面試關鍵點:內存分區的具體差異;垃圾回收機制(引用計數 vs 可達性分析)的優缺點;垃圾回收器的有無及種類;對象生命周期管理的責任主體。
記憶法:可通過“C++ 手動管內存,分區依賴系統,回收靠手動或計數;Java 自動管內存,JVM 分區,可達性分析加多種回收器”來記憶,概括核心區別。
代碼題:如何將 IPv4 地址轉換為 int32 類型?
IPv4 地址由 4 個 0-255 的整數( octet,八位組)組成,格式為?x1.x2.x3.x4(如?192.168.1.1)。轉換為 int32 類型(32 位整數)的核心思路是:將每個八位組轉換為 8 位二進制數,按順序拼接成 32 位二進制數,再轉換為十進制整數(網絡字節序通常為大端序,即高位字節在前)。
實現步驟包括:
- 驗證輸入合法性:IPv4 地址必須由 4 個八位組組成,每個組的值在 0-255 之間,否則拋出異常。
- 拆分地址:按?
.?分割字符串,得到 4 個字符串元素。 - 轉換為整數:將每個字符串元素轉換為整數,檢查是否在 0-255 范圍內。
- 拼接為 32 位整數:將第一個八位組左移 24 位,第二個左移 16 位,第三個左移 8 位,第四個不位移,然后通過按位或(|)拼接。
代碼示例如下:
public class IPv4ToInt32 {public static int ipv4ToInt32(String ipAddress) {// 驗證輸入不為空if (ipAddress == null || ipAddress.isEmpty()) {throw new IllegalArgumentException("IPv4地址不能為空");}// 按"."拆分String[] octets = ipAddress.split("\\.");// 檢查是否有4個八位組if (octets.length != 4) {throw new IllegalArgumentException("無效的IPv4地址格式");}int result = 0;for (int i = 0; i < 4; i++) {try {// 轉換為整數int octet = Integer.parseInt(octets[i]);// 檢查范圍if (octet < 0 || octet > 255) {throw new IllegalArgumentException("八位組值超出范圍(0-255)");}// 左移并拼接(大端序)result |= (octet << (24 - i * 8));} catch (NumberFormatException e) {throw new IllegalArgumentException("八位組不是有效整數", e);}}return result;}public static void main(String[] args) {// 測試案例System.out.println(ipv4ToInt32("0.0.0.0")); // 輸出 0System.out.println(ipv4ToInt32("255.255.255.255")); // 輸出 -1(32位全1的補碼表示)System.out.println(ipv4ToInt32("192.168.1.1")); // 輸出 3232235777}
}
關鍵說明:
- 拆分時需用?
\\.(轉義),因為?.?在正則中是通配符。 - 左移計算:第一個八位組(x1)是最高位,左移 24 位;x2 左移 16 位;x3 左移 8 位;x4 不左移,確保 32 位的正確拼接。
- 異常處理:覆蓋輸入為空、格式錯誤、數值越界、非整數等情況,保證健壯性。
- 對于?
255.255.255.255,32 位全為 1,在 Java 中 int 是有符號的,因此表示為 -1(補碼規則)。
面試關鍵點:輸入驗證的全面性;位運算的正確應用(左移和按位或);對有符號整數的理解(如全 1 表示 -1)。
記憶法:可通過“四分驗范圍,左移拼 32,大端高位前”來記憶,概括轉換的核心步驟。
介紹 Java 中常用的集合類有哪些?
Java 中的集合類位于?java.util?包下,用于存儲和操作多個對象,主要分為 Collection 和 Map 兩大體系,Collection 存儲單列元素,Map 存儲鍵值對(雙列元素),常用類及其特點如下:
Collection 接口下的主要分支包括 List、Set、Queue:
List 接口:存儲有序、可重復的元素,允許通過索引訪問,常用實現類有:
- ArrayList:底層基于動態數組實現,支持隨機訪問(get/set 操作效率高,時間復雜度 O(1)),但插入/刪除元素(尤其是中間位置)需移動元素,效率較低(O(n));初始容量為 10,擴容時通常變為原來的 1.5 倍,適合查詢頻繁、增刪少的場景。
- LinkedList:底層基于雙向鏈表實現,不支持隨機訪問(查詢需遍歷,O(n)),但插入/刪除元素(已知位置時)僅需修改指針,效率高(O(1));還實現了 Deque 接口,可作為雙端隊列使用,適合增刪頻繁(尤其是首尾)、查詢少的場景。
- Vector:與 ArrayList 類似(動態數組),但方法被 synchronized 修飾,是線程安全的;擴容時默認變為原來的 2 倍,效率較低,已被 ConcurrentHashMap 等更高效的線程安全集合替代,不推薦在新代碼中使用。
Set 接口:存儲無序、不可重復的元素(基于 equals() 和 hashCode() 判斷唯一性),常用實現類有:
- HashSet:底層基于 HashMap 實現(將元素作為 HashMap 的 key,value 為固定對象),無序,查詢、添加、刪除效率高(平均 O(1)),適合無需排序的去重場景。
- LinkedHashSet:繼承自 HashSet,底層通過 LinkedHashMap 實現,保留元素的插入順序(通過鏈表維護),性能略低于 HashSet,適合需要保持插入順序的去重場景。
- TreeSet:底層基于紅黑樹(一種自平衡二叉搜索樹)實現,元素會按自然順序或自定義比較器(Comparator)排序,查詢、添加、刪除效率為 O(log n),適合需要排序的場景。
Queue 接口:用于存儲待處理的元素,遵循先進先出(FIFO)原則,常用實現類有:
- LinkedList:實現了 Queue 接口,可作為普通隊列(add/offer 入隊,remove/poll 出隊)或雙端隊列(Deque)使用。
- PriorityQueue:底層基于二叉堆實現,元素按自然順序或自定義比較器排序,出隊時總是返回最小(或最大)元素,是一種優先級隊列,不遵循 FIFO。
- ArrayBlockingQueue:基于數組的有界阻塞隊列,多線程環境下可用于生產者-消費者模型,支持阻塞等待。
Map 接口:存儲鍵值對(key-value),key 不可重復(通過 equals() 和 hashCode() 判斷),value 可重復,常用實現類有:
- HashMap:底層基于數組+鏈表/紅黑樹實現(JDK 8 后,當鏈表長度超過 8 且數組容量≥64 時,鏈表轉為紅黑樹),key 無序,查詢、添加、刪除效率高(平均 O(1));key 和 value 都可為 null,是非線程安全的,適合單線程下的鍵值對存儲。
- LinkedHashMap:繼承自 HashMap,通過鏈表維護 key 的插入順序或訪問順序(可設置為 LRU 緩存),性能略低于 HashMap,適合需要保持鍵順序的場景。
- TreeMap:底層基于紅黑樹實現,key 按自然順序或自定義比較器排序,查詢、添加、刪除效率為 O(log n);key 不能為 null,適合需要按鍵排序的場景。
- Hashtable:與 HashMap 類似,但方法被 synchronized 修飾,是線程安全的;key 和 value 都不能為 null,效率較低,已被 ConcurrentHashMap 替代。
- ConcurrentHashMap:線程安全的 HashMap 實現,JDK 7 基于分段鎖,JDK 8 基于 CAS + synchronized,并發性能優于 Hashtable,適合多線程環境。
面試關鍵點:各集合類的底層實現(數組、鏈表、紅黑樹、哈希表等);性能特點(時間復雜度);線程安全性;適用場景的選擇。
記憶法:可通過“List 有序可重復(Array 查快,Linked 增刪快),Set 無序去重(Hash 快,Linked 保序,Tree 排序),Map 鍵值對(Hash 快,Linked 保序,Tree 排序,Concurrent 線程安全)”來記憶,快速梳理核心類的特點。
ArrayList 和 LinkedList 的底層實現是什么?它們的使用場景有什么區別?在處理大數據時該如何選擇?
ArrayList 和 LinkedList 是 Java 中 List 接口的兩種主要實現,底層實現機制不同,導致它們在性能和適用場景上有顯著差異。
ArrayList 的底層實現是動態數組(可自動擴容的數組)。它維護一個?elementData?數組存儲元素,初始容量默認為 10(可通過構造方法指定)。當元素數量超過當前容量時,會觸發擴容:創建一個新數組(通常為原容量的 1.5 倍,計算方式為?oldCapacity + (oldCapacity >> 1)),并將原數組元素復制到新數組中。這種結構使得 ArrayList 支持隨機訪問(通過索引直接定位元素),因此?get(int index)?和?set(int index, E element)?操作效率極高,時間復雜度為 O(1)。但插入(add(int index, E element))和刪除(remove(int index))元素時,需要移動目標位置后的所有元素(復制操作),時間復雜度為 O(n),且元素越多,效率越低;此外,擴容時的數組復制也會帶來額外性能開銷。
LinkedList 的底層實現是雙向鏈表(每個節點包含前驅指針?prev、后繼指針?next?和數據?item)。鏈表節點在內存中不連續存儲,通過指針關聯。這種結構使得 LinkedList 不支持隨機訪問,get(int index)?操作需要從鏈表頭或尾(根據索引位置選擇更近的一端)遍歷到目標節點,時間復雜度為 O(n)。但插入和刪除元素時,只需修改目標節點前后的指針(無需移動其他元素),若已知節點位置(如通過迭代器定位),時間復雜度可降至 O(1);此外,LinkedList 無需擴容,內存占用隨元素數量動態變化(每個節點額外存儲兩個指針,內存 overhead 略高)。
兩者的使用場景區別主要基于操作類型:
- ArrayList 適合“查詢頻繁、增刪少”的場景,尤其是需要通過索引隨機訪問元素的情況(如存儲用戶列表,頻繁根據索引查詢用戶信息)。
- LinkedList 適合“增刪頻繁(尤其是中間位置或首尾)、查詢少”的場景,或需要作為隊列/雙端隊列使用的情況(如實現消息隊列,頻繁在首尾添加/移除消息)。
處理大數據時的選擇需綜合考慮具體操作:
- 若大數據場景以隨機訪問(如按索引查詢)為主,即使數據量大,ArrayList 仍是更好的選擇,因為 O(1) 的查詢效率在大數據量下優勢明顯,且數組的連續內存布局有利于 CPU 緩存(局部性原理),進一步提升性能;但需注意初始容量設置(如預估數據量并在構造時指定,減少擴容次數)。
- 若大數據場景以頻繁插入/刪除為主(尤其是中間位置),LinkedList 更合適,因為其增刪操作的時間復雜度不受數據量影響(僅與操作位置相關);但需注意,若需要頻繁查詢定位元素位置,LinkedList 的 O(n) 查詢會成為瓶頸,此時可能需要結合哈希表等結構優化。
此外,內存占用也是考量因素:ArrayList 的數組可能存在未使用的容量(擴容預留),導致內存浪費;LinkedList 的每個節點額外占用兩個指針的內存,總內存消耗可能更高(尤其數據量極大時)。
面試關鍵點:底層數據結構(動態數組 vs 雙向鏈表);核心操作的時間復雜度;適用場景的判斷依據;大數據場景下的選擇邏輯(結合操作類型和內存)。
記憶法:可通過“ArrayList 數組查快增刪慢,LinkedList 鏈表查慢增刪快;大數據查多選前者,增刪多選后者”來記憶,概括核心差異和選擇原則。
ArrayList 是線程安全的嗎?為什么?
ArrayList 不是線程安全的。這是因為 ArrayList 的內部方法(如?add()、remove()、get()?等)沒有任何同步機制(如?synchronized?修飾或 CAS 操作),在多線程并發修改或讀寫時,可能導致數據不一致、索引越界甚至程序崩潰。
具體來說,多線程環境下使用 ArrayList 可能出現以下問題:
數據覆蓋:當多個線程同時執行?
add()?操作時,可能導致元素被覆蓋。add()?方法的核心邏輯是先檢查容量,再將元素放入?elementData[size++]。若兩個線程同時讀取到相同的?size?值,會將元素寫入同一個位置,后寫入的元素會覆蓋先寫入的元素,導致數據丟失。數組越界(IndexOutOfBoundsException):擴容過程中可能出現此問題。當線程 A 執行?
add()?時發現需要擴容,開始復制元素到新數組;此時線程 B 也執行?add(),讀取到的仍是舊數組的容量,若舊數組已被線程 A 標記為擴容,線程 B 可能在舊數組中執行?elementData[size++],而舊數組的容量已不足,導致越界異常。迭代器 fail-fast(快速失敗):當一個線程在迭代 ArrayList 時,另一個線程修改了 ArrayList 的結構(如添加、刪除元素),迭代器會檢測到?
modCount(修改次數計數器)的變化,拋出?ConcurrentModificationException。這是 ArrayList 的一種保護機制,但并非解決線程安全的方案。
示例代碼(多線程下的問題):
import java.util.ArrayList;
import java.util.List;public class ArrayListThreadSafety {public static void main(String[] args) {List<Integer> list = new ArrayList<>();// 多個線程同時添加元素Runnable task = () -> {for (int i = 0; i < 1000; i++) {list.add(i);}};Thread t1 = new Thread(task);Thread t2 = new Thread(task);t1.start();t2.start();try {t1.join();t2.join();} catch (InterruptedException e) {e.printStackTrace();}// 預期大小為2000,實際可能小于2000(數據丟失)System.out.println("實際大小:" + list.size());}
}
上述代碼中,兩個線程各添加 1000 個元素,預期結果為 2000,但實際結果往往小于 2000,體現了 ArrayList 的線程不安全。
若需要線程安全的 List 實現,可選擇:
- Vector:方法被?
synchronized?修飾,線程安全,但性能較低(全表鎖)。 Collections.synchronizedList(new ArrayList<>()):通過包裝器模式,為 ArrayList 的方法添加同步鎖,性能略高于 Vector。CopyOnWriteArrayList(JUC 包):寫入時復制新數組,讀取無鎖,適合讀多寫少的場景,性能優異。
面試關鍵點:ArrayList 線程不安全的具體表現(數據覆蓋、越界、快速失敗);底層原因(無同步機制);線程安全的替代方案及適用場景。
記憶法:可通過“ArrayList 無同步,多線程用出問題,數據丟、會越界,安全用 Vector 或同步包裝,讀多寫少 CopyOnWrite”來記憶,明確其線程安全性及解決方案。
HashSet 的底層實現原理是什么?它是線程安全的嗎?
HashSet 的底層是通過 HashMap 實現的,其核心是利用 HashMap 中 key 的唯一性來保證 HashSet 中元素的不可重復特性。具體來說,HashSet 內部維護了一個 HashMap 實例,當向 HashSet 中添加元素時,實際上是將該元素作為 key 存入底層的 HashMap 中,而 value 則是一個固定的靜態對象(通常是?new Object(),稱為“ PRESENT ”)。由于 HashMap 的 key 不允許重復(重復時會覆蓋 value),因此 HashSet 自然實現了元素的去重功能。
HashSet 的核心方法(如?add()、contains()、remove())均通過調用底層 HashMap 的對應方法實現:
add(E e)?方法:調用?map.put(e, PRESENT),若返回 null 表示添加成功(元素不存在),若返回 PRESENT 表示元素已存在(添加失敗)。contains(Object o)?方法:調用?map.containsKey(o),判斷元素是否存在。remove(Object o)?方法:調用?map.remove(o),移除對應的 key 并返回是否成功。
例如,HashSet 的?add?方法簡化源碼如下:
public class HashSet<E> {private transient HashMap<E, Object> map;private static final Object PRESENT = new Object();public boolean add(E e) {return map.put(e, PRESENT) == null;}
}
關于線程安全性,HashSet 不是線程安全的。因為其底層依賴的 HashMap 本身是非線程安全的,在多線程環境下,若同時對 HashSet 進行添加、刪除等操作,可能導致數據不一致(如元素丟失、重復)或拋出?ConcurrentModificationException(快速失敗機制)。例如,兩個線程同時添加元素時,可能因底層 HashMap 的?put?操作無同步保護,導致相同元素被重復插入,或鏈表/紅黑樹結構被破壞。
若需要線程安全的 Set 實現,可選擇:
Collections.synchronizedSet(new HashSet<>()):通過同步包裝器為所有方法添加同步鎖,保證線程安全,但性能較低。CopyOnWriteArraySet:基于?CopyOnWriteArrayList?實現,寫入時復制新數組,讀取無鎖,適合讀多寫少的場景,并發性能優異。
面試關鍵點:HashSet 基于 HashMap 的實現細節(key 存儲元素,固定 value);線程不安全的原因(依賴非線程安全的 HashMap);線程安全的替代方案及適用場景。
記憶法:可通過“HashSet 底層靠 HashMap,元素作 key 去重,線程不安全需包裝”來記憶,概括核心實現和安全性特點。
HashMap 的底層數據結構是什么?為什么要用紅黑樹而不是其他樹?
HashMap 的底層數據結構在 JDK 8 及之后為“數組 + 鏈表 + 紅黑樹”的組合結構,JDK 7 及之前則是“數組 + 鏈表”。這種演進是為了優化哈希沖突時的查詢性能。
具體來說,HashMap 以數組(稱為“哈希桶”)作為主體,數組的每個元素是一個鏈表或紅黑樹的頭節點。當添加元素時,先通過 key 的哈希值計算數組索引(hash & (n-1),n 為數組容量),將元素放入對應索引的位置:
- 若該位置為空,直接存儲元素(作為鏈表頭節點)。
- 若該位置已有元素(哈希沖突),則將新元素加入鏈表尾部。
- 當鏈表長度超過閾值(默認 8)且數組容量不小于 64 時,鏈表會轉換為紅黑樹,以優化查詢效率。
選擇紅黑樹而非其他樹(如 AVL 樹、完全二叉樹、B 樹等)的原因主要有以下幾點:
平衡性能與維護成本的平衡:紅黑樹是一種自平衡二叉搜索樹,通過一系列規則(如節點顏色為紅或黑、根節點為黑、葉子節點為黑、紅節點的子節點為黑、任意節點到葉子節點的黑節點數相同)保證樹的高度近似平衡(最大高度為 2log(n+1))。相比 AVL 樹(要求左右子樹高度差不超過 1),紅黑樹的平衡條件更寬松,插入和刪除時的旋轉操作更少,維護成本更低,適合 HashMap 中頻繁插入、刪除元素的場景。
查詢效率穩定:紅黑樹的查詢、插入、刪除時間復雜度均為 O(log n),遠優于鏈表的 O(n)。當哈希沖突導致鏈表過長時,轉為紅黑樹能顯著提升查詢性能。而完全二叉樹不保證平衡性,極端情況下可能退化為鏈表;B 樹多用于磁盤存儲(如數據庫索引),節點可存儲多個元素,不適合 HashMap 內存中的節點結構。
內存占用合理:紅黑樹每個節點僅需額外存儲一個顏色標記(紅或黑),內存開銷較小。相比之下,AVL 樹需要存儲平衡因子(整數),內存占用更高,對于 HashMap 這種可能包含大量節點的數據結構,紅黑樹更具優勢。
適配哈希沖突的特性:哈希沖突導致的鏈表長度通常不會特別長(根據泊松分布,鏈表長度達到 8 的概率極低),紅黑樹在這種中等規模的節點數量下,性能表現穩定,既能避免鏈表的低效,又無需像更復雜的樹結構那樣付出過高的維護成本。
面試關鍵點:HashMap 數據結構的演進(數組+鏈表到數組+鏈表+紅黑樹);紅黑樹的平衡特性與性能優勢;與其他樹結構的對比(尤其是 AVL 樹)。
記憶法:可通過“HashMap 結構數組鏈,長鏈轉紅黑樹;紅黑樹平衡易維護,log n 效率穩,勝 AVL 少旋轉”來記憶,概括數據結構及紅黑樹的優勢。
HashMap 中插入一個元素的過程是怎樣的?
HashMap 插入元素(put(K key, V value))的過程涉及哈希計算、索引定位、沖突處理、結構轉換(鏈表轉紅黑樹)和擴容等步驟,具體如下:
計算 key 的哈希值:首先調用 key 的?
hashCode()?方法獲取原始哈希值,再通過 HashMap 內部的?hash()?方法進行擾動處理(對原始哈希值進行高位運算,如?(h = key.hashCode()) ^ (h >>> 16)),目的是將高位哈希值融入低位,減少哈希沖突(尤其在數組容量較小時,保證高位信息也能影響索引計算)。計算數組索引:根據擾動后的哈希值和當前數組容量(n),通過?
(n - 1) & hash?計算元素在數組中的索引位置(等價于?hash % n,但位運算效率更高)。數組容量始終為 2 的冪次方,確保?n - 1?的二進制全為 1,使索引分布更均勻。檢查目標位置是否為空:
- 若數組對應索引位置為空(即?
table[index] == null),直接創建新節點(Node)并放入該位置,插入完成。 - 若不為空,說明發生哈希沖突,需進一步處理。
- 若數組對應索引位置為空(即?
處理哈希沖突:
- 首先判斷該位置的頭節點是否與待插入 key 相同(判斷標準:
hash 值相等?且?(key == 頭節點 key 或 key.equals(頭節點 key)))。若相同,直接替換該節點的 value,插入完成。 - 若頭節點不同,判斷該位置的結構是鏈表還是紅黑樹:
- 若是紅黑樹(TreeNode),調用紅黑樹的插入方法(
putTreeVal),按紅黑樹規則插入新節點,若存在相同 key 則替換 value。 - 若是鏈表(Node),遍歷鏈表尋找與待插入 key 相同的節點:
- 若找到,替換其 value。
- 若未找到,在鏈表尾部插入新節點(JDK 8 后為尾插法,避免 JDK 7 頭插法的循環鏈表問題)。
- 若是紅黑樹(TreeNode),調用紅黑樹的插入方法(
- 首先判斷該位置的頭節點是否與待插入 key 相同(判斷標準:
鏈表轉紅黑樹檢查:插入新節點后,若鏈表長度超過閾值(默認 8),則調用?
treeifyBin?方法嘗試將鏈表轉為紅黑樹。但轉樹前會先檢查數組容量,若容量小于 64(MIN_TREEIFY_CAPACITY),則先進行擴容(而非轉樹),因為小容量下擴容更能有效分散元素;若容量≥64,則將鏈表轉為紅黑樹。擴容檢查:插入完成后,判斷當前元素數量(size)是否超過閾值(
capacity * loadFactor,默認容量 16 * 負載因子 0.75 = 12)。若超過,觸發擴容:- 新容量為原容量的 2 倍(保證仍是 2 的冪次方)。
- 創建新數組,將原數組中的元素重新計算索引后遷移到新數組(紅黑樹可能拆分為鏈表或保持樹結構)。
- 替換原數組為新數組,完成擴容。
示例流程簡化代碼(核心邏輯):
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);
}final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length; // 初始化數組if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null); // 位置為空,直接插入else {Node<K,V> e; K k;if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))e = p; // 頭節點相同,標記待替換else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); // 紅黑樹插入else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null); // 鏈表尾部插入if (binCount >= TREEIFY_THRESHOLD - 1) // 鏈表長度達標treeifyBin(tab, hash); // 嘗試轉紅黑樹break;}if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))break; // 找到相同key,退出循環p = e;}}if (e != null) { // 存在相同key,替換valueV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize(); // 擴容afterNodeInsertion(evict);return null;
}
面試關鍵點:哈希值計算與索引定位的細節;哈希沖突的處理方式(鏈表 vs 紅黑樹);鏈表轉紅黑樹的條件;擴容的觸發機制與過程。
記憶法:可通過“哈希擾動算索引,空位直接插,沖突查鏈樹;同 key 則替換,異 key 尾插入;鏈長超 8 且容量夠,轉紅黑樹;size 超閾值就擴容”來記憶,概括插入的核心步驟。
若向 HashMap 中兩次 put 同一個 key 的元素,最終會有幾個元素?HashMap 是如何比較 key 的?(需結合 == 和 equals () 的區別說明)
向 HashMap 中兩次 put 同一個 key 的元素,最終只會保留一個元素(key 唯一),第二次 put 的 value 會覆蓋第一次的 value。這是因為 HashMap 的 key 具有唯一性,重復 put 同一 key 時,會執行“替換”邏輯而非“新增”。
HashMap 比較兩個 key 是否相同的邏輯是“兩步校驗”,需同時滿足以下兩個條件:
- 兩個 key 的哈希值(通過?
hashCode()?計算并經擾動處理后)必須相等。 - 兩個 key 要么是同一個對象(
==?比較為 true),要么通過?equals()?方法比較為 true。
具體來說,當插入新 key 時,HashMap 會先計算新 key 與已有 key 的哈希值:若哈希值不同,直接判定為不同 key;若哈希值相同,再通過?==?比較引用地址(是否為內存中同一個對象),若?==?為 true 則判定為相同 key;若?==?為 false,則調用?equals()?方法比較,若返回 true 則判定為相同 key,否則為不同 key。
這里需要明確?==?和?equals()?的區別:
==:對于基本數據類型,比較的是值;對于引用數據類型,比較的是內存地址(是否指向同一個對象)。equals():是 Object 類的方法,默認實現為?return (this == obj)(即比較引用地址),但很多類(如 String、Integer 等)會重寫?equals()?方法,使其比較對象的邏輯內容(如 String 的?equals()?比較字符序列是否相同)。
例如:
HashMap<String, Integer> map = new HashMap<>();
map.put(new String("a"), 1);
map.put(new String("a"), 2); // 兩次put的key是不同對象(new了兩次)System.out.println(map.size()); // 輸出1,因為兩個key的hash值相同且equals為true
System.out.println(map.get("a")); // 輸出2,第二次的value覆蓋了第一次
上述代碼中,兩個?new String("a")?是不同對象(==?為 false),但它們的哈希值相同("a".hashCode()?相同),且?equals()?比較為 true(內容相同),因此被判定為同一 key,第二次 put 會覆蓋 value。
反之,若兩個 key 的?hashCode()?不同,即使?equals()?為 true,也會被判定為不同 key(如重寫?equals()?但未重寫?hashCode()?的類),這會違反 HashMap 的設計約定,導致相同邏輯的 key 被重復存儲。
面試關鍵點:重復 put 同一 key 的結果(覆蓋 value);key 比較的兩步校驗(哈希值 +?==/equals());==?與?equals()?的本質區別;重寫?equals()?必須重寫?hashCode()?的原因。
記憶法:可通過“同 key 兩次 put,最終留一個,value 被覆蓋;比較 key 先看 hash,再看 == 或 equals,二者缺一不可”來記憶,概括核心邏輯和比較規則。
HashMap 中鏈表轉紅黑樹的兩個條件是什么?為什么要設置這樣的數據條件?
HashMap 中鏈表轉為紅黑樹需要同時滿足兩個條件:
- 鏈表的長度超過閾值?
TREEIFY_THRESHOLD(默認值為 8)。 - 數組的容量不小于?
MIN_TREEIFY_CAPACITY(默認值為 64)。
只有同時滿足這兩個條件,鏈表才會轉換為紅黑樹;若鏈表長度達標但數組容量不足 64,則不會轉樹,而是觸發擴容(數組容量翻倍),通過重新計算索引分散元素,縮短鏈表長度。
設置這兩個條件的原因與哈希沖突的特性、性能平衡及工程實踐密切相關:
鏈表長度閾值(8)的設計依據:HashMap 作者通過泊松分布計算得出,在理想哈希函數和隨機哈希值的情況下,鏈表長度為 8 的概率極低(約為 0.00000006),這意味著鏈表長度達到 8 通常是哈希沖突較嚴重的異常情況(如 key 的哈希函數設計不合理,導致哈希值分布不均)。此時鏈表的查詢效率已降至 O(n),轉為紅黑樹(O(log n))能顯著提升查詢性能,平衡哈希沖突帶來的性能損失。同時,閾值設為 8 而非更小(如 4),是為了避免頻繁在鏈表和紅黑樹之間轉換(樹轉鏈表的閾值為 6,存在緩沖區間),減少結構轉換的額外開銷。
數組容量閾值(64)的設計目的:當數組容量較小時(如 16),鏈表過長更可能是因為數組容量不足導致的哈希碰撞集中(而非哈希函數問題)。此時,通過擴容(將容量翻倍至 32、64 等)能更高效地分散元素——擴容后索引重新計算(
hash & (newCap - 1)),原鏈表中的元素會被分散到不同的新索引位置,自然縮短鏈表長度。相比之下,在小容量數組中轉紅黑樹的收益有限(樹結構本身有額外內存開銷),且后續擴容時樹的拆分也會增加復雜度。因此,設置容量閾值 64,確保只有當數組容量足夠大(哈希表已具備一定規模),且鏈表仍過長時,才進行轉樹操作,兼顧性能和資源消耗。
此外,紅黑樹轉鏈表的閾值為 6(UNTREEIFY_THRESHOLD),與轉樹閾值 8 形成緩沖區間,避免鏈表長度在 8 附近波動時(如頻繁插入刪除)導致樹與鏈表的頻繁轉換,進一步優化性能。
面試關鍵點:鏈表轉紅黑樹的兩個條件(長度 8 + 容量 64);泊松分布對閾值 8 的影響;容量閾值 64 的設計初衷(優先擴容而非轉樹);緩沖區間(8→6)的作用。
記憶法:可通過“鏈長超 8 且容量夠 64,鏈表轉紅黑樹;小容量先擴容,大概率碰 8 才轉樹,緩沖區間防抖動”來記憶,概括條件及設計原因。
HashMap 的擴容機制是怎樣的?擴容過程中的頭插法和尾插法有什么區別?
HashMap 的擴容機制是指當元素數量超過閾值時,通過擴大數組容量來減少哈希沖突、優化性能的過程,核心目的是分散密集的元素,避免鏈表或紅黑樹過長導致查詢效率下降。
擴容的觸發條件是:當 HashMap 中元素數量(size)超過閾值(threshold = 容量 × 負載因子,默認容量 16 × 0.75 = 12)時,觸發擴容。若數組未初始化(第一次插入元素),也會觸發擴容(初始化為默認容量 16)。
擴容的具體過程如下:
- 計算新容量:新容量為原容量的 2 倍(保證始終是 2 的冪次方,如 16→32、32→64 等),這是為了通過?
(n-1) & hash?計算索引時,利用高位哈希值,使元素分布更均勻。 - 計算新閾值:新閾值為新容量 × 負載因子(默認 0.75)。
- 創建新數組:按新容量創建一個更大的數組(newTab)。
- 遷移元素:將原數組(oldTab)中的元素重新計算索引后遷移到新數組,具體分為三種情況:
- 若原位置是單個節點(非鏈表/紅黑樹),直接計算新索引并放入新數組。
- 若原位置是紅黑樹(TreeNode),則拆分紅黑樹:根據新索引規則,將樹節點分為兩個子樹,若子樹長度≤6,則轉為鏈表,否則保持紅黑樹。
- 若原位置是鏈表(Node),則遍歷鏈表,將節點按新索引規則分為兩個子鏈表(低位鏈表和高位鏈表),分別放入新數組的對應位置。
- 替換引用:將新數組賦值給 HashMap 的 table 變量,更新容量和閾值,完成擴容。
擴容過程中的頭插法和尾插法是 JDK 7 與 JDK 8 中遷移鏈表元素時的不同實現方式,核心區別如下:
頭插法(JDK 7 及之前):遷移鏈表時,將原鏈表的節點按“頭插”方式放入新數組的對應位置,即新節點插入到新鏈表的頭部。這種方式會導致鏈表反轉(原鏈表順序與新鏈表順序相反)。在多線程環境下,若同時擴容,可能因鏈表反轉形成循環鏈表,導致查詢時陷入死循環(如線程 A 遷移到一半,線程 B 插入節點,修改指針形成環)。
尾插法(JDK 8 及之后):遷移鏈表時,保持原鏈表的順序,將節點按“尾插”方式放入新數組的對應位置,即新節點插入到新鏈表的尾部。這種方式不會改變鏈表順序,避免了多線程擴容時的循環鏈表問題(但 HashMap 仍非線程安全,只是解決了該特定問題)。
示例(鏈表遷移對比):
- 原鏈表:A → B → C(索引 i)
- 頭插法遷移后(新索引 j):C → B → A(順序反轉)
- 尾插法遷移后(新索引 j):A → B → C(順序不變)
面試關鍵點:擴容的觸發條件與容量計算;元素遷移的三種場景(單節點、鏈表、紅黑樹);頭插法與尾插法的區別(順序、線程安全隱患);JDK 版本差異對擴容的影響。
記憶法:可通過“容量超閾值則擴容,新容原 2 倍,遷移元素分三類;頭插反轉易成環,尾插保序更安全”來記憶,概括擴容機制及兩種插入方式的核心差異。
若向 HashMap 中存入 1 億個數據,會一次性 rehash 完成嗎?什么是漸進式 rehash?其實現原理是什么?
向 HashMap 中存入 1 億個數據時,會觸發多次擴容,且每次擴容都會一次性完成 rehash(重新計算所有元素的索引并遷移),不會分階段進行。這是因為 HashMap 是單線程設計,擴容過程是阻塞式的:一旦觸發擴容,當前線程會暫停其他操作,直到所有元素遷移完成,才能繼續處理后續請求。對于 1 億個數據,單次擴容的 rehash 操作會消耗大量 CPU 和時間,可能導致程序長時間卡頓,甚至影響服務可用性。
漸進式 rehash 并非 HashMap 的特性,而是 ConcurrentHashMap(JDK 7)為解決大規模數據擴容時的性能問題而設計的機制,目的是避免一次性 rehash 帶來的長時間阻塞,實現“邊服務邊遷移”。
漸進式 rehash 的核心原理是將數據遷移過程分散到多次操作中,而非一次性完成,具體實現如下:
- 雙數組共存:觸發擴容時,ConcurrentHashMap 會創建一個新數組(新容量為原容量的 2 倍),但不立即遷移所有數據,而是同時保留舊數組和新數組(通過?
sizeCtl?標記擴容狀態)。 - 分步遷移:每次執行?
put、get、remove?等操作時,會順帶遷移一部分數據(如遷移舊數組中一個段的元素)。遷移時,先鎖定該段,將元素重新計算索引后放入新數組,完成后標記該段已遷移。 - 讀寫兼容:查詢操作時,會先檢查新數組,若未找到則查詢舊數組;插入操作時,直接插入新數組(確保新數據只進入新數組);刪除操作時,若元素在舊數組中,遷移后再刪除。
- 完成遷移:當舊數組中的所有元素都遷移到新數組后,用新數組替換舊數組,釋放舊數組內存,擴容完成。
這種機制將一次性大量遷移的開銷分散到多次操作中,避免了單線程阻塞,保證了高并發場景下的服務可用性。例如,存入 1 億個數據時,ConcurrentHashMap 會在多次?put?操作中逐步完成遷移,而非一次性阻塞處理。
需要注意的是,JDK 8 中的 ConcurrentHashMap 摒棄了分段鎖,采用 CAS + synchronized 實現同步,其擴容機制雖仍有優化,但不再是嚴格意義上的漸進式 rehash,而是通過多線程協助遷移(每個線程負責一部分桶)來提高效率。
面試關鍵點:HashMap 一次性 rehash 的特性及問題;漸進式 rehash 的設計目的(避免阻塞);ConcurrentHashMap 漸進式 rehash 的核心實現(雙數組、分步遷移、讀寫兼容);JDK 版本差異對 rehash 機制的影響。
記憶法:可通過“HashMap 存億級,一次性 rehash 阻塞;漸進式 rehash 屬并發,雙數組分步遷,邊服務邊完成”來記憶,明確兩種 rehash 機制的差異。
HashMap 是線程安全的嗎?如何保證 HashMap 的線程安全?
HashMap 不是線程安全的。其底層實現(數組 + 鏈表 + 紅黑樹)和方法(如?put、remove?等)均未提供同步機制,在多線程環境下并發讀寫或修改時,可能出現數據不一致、異常甚至程序崩潰,具體表現為:
- 數據覆蓋:多線程同時執行?
put?操作時,可能因同時計算出相同索引且均判斷該位置為空,導致后插入的元素覆蓋先插入的元素,造成數據丟失。 - 鏈表循環:JDK 7 及之前使用頭插法擴容,多線程并發擴容時,可能因鏈表反轉形成循環鏈表,導致后續查詢操作陷入死循環。
- 快速失敗(ConcurrentModificationException):一個線程迭代 HashMap 時,另一個線程修改其結構(如添加/刪除元素),迭代器會檢測到?
modCount?變化并拋出異常。 - 尺寸不準確:多線程并發修改時,
size?字段的更新可能丟失(如兩個線程同時執行?size++,最終結果可能比實際少 1)。
保證 HashMap 線程安全的常用方式有以下三種,各有特點:
使用?
Collections.synchronizedMap(new HashMap<>()):通過包裝器模式,為 HashMap 的所有方法添加同步鎖(synchronized?塊,鎖對象為包裝器本身),使每個方法執行時都需獲取鎖,從而保證線程安全。優點是實現簡單,適用于并發量低的場景;缺點是全表鎖導致并發性能差(多線程無法同時操作),且迭代時仍需手動同步(否則可能拋出?ConcurrentModificationException)。使用 HashTable:HashTable 是早期的線程安全哈希表實現,其所有方法都被?
synchronized?修飾(鎖對象為 this),本質是全表鎖。優點是無需額外處理,直接使用;缺點是與?synchronizedMap?類似,并發性能低,且不允許?null?作為 key 或 value,功能受限,已逐漸被 ConcurrentHashMap 替代。使用 ConcurrentHashMap(推薦):JUC 包提供的高效線程安全哈希表,針對并發場景優化:
- JDK 7 采用分段鎖(Segment),將數組分為多個段,每個段獨立加鎖,多線程可同時操作不同段,并發性能大幅提升。
- JDK 8 摒棄分段鎖,采用 CAS 操作 +?
synchronized?關鍵字(只鎖定鏈表頭或紅黑樹節點),進一步減少鎖競爭,性能更優。
優點是并發性能高(支持多線程同時讀寫),允許?null?作為 value(key 仍不允許),支持原子操作(如?putIfAbsent);缺點是實現復雜,內存占用略高,適用于高并發場景。
示例(使用 ConcurrentHashMap):
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;public class SafeHashMap {public static void main(String[] args) {Map<String, Integer> map = new ConcurrentHashMap<>();// 多線程并發操作Runnable task = () -> {for (int i = 0; i < 1000; i++) {map.put(Thread.currentThread().getName() + i, i);}};new Thread(task).start();new Thread(task).start();}
}
面試關鍵點:HashMap 線程不安全的具體表現;三種線程安全方案的實現原理與優缺點;ConcurrentHashMap 的并發優化機制(分段鎖 vs CAS + synchronized);不同并發場景下的方案選擇。
記憶法:可通過“HashMap 線程不安全,并發操作出問題;同步包裝全表鎖,HashTable 老性能低;ConcurrentHashMap 最推薦,分段或 CAS 高并發”來記憶,概括安全性問題及解決方案。
HashTable、SynchronizedMap 和 ConcurrentHashMap 的區別是什么?HashTable 如何保證線程安全?ConcurrentHashMap 如何實現線程安全?
HashTable、SynchronizedMap 和 ConcurrentHashMap 都是線程安全的哈希表實現,但在同步機制、性能、功能支持等方面有顯著區別,具體如下:
三者的核心區別:
同步機制與性能:
- HashTable:所有方法(如?
put、get)均被?synchronized?修飾,本質是“全表鎖”(鎖對象為當前 HashTable 實例)。任何時刻只有一個線程能操作整個哈希表,并發性能極低。 - SynchronizedMap:通過?
Collections.synchronizedMap()?包裝普通 Map 生成,內部使用同步塊(鎖對象為包裝器或指定的鎖對象),同樣是“全表鎖”。與 HashTable 相比,靈活性略高(可指定鎖對象),但并發性能相同(仍為單線程獨占)。 - ConcurrentHashMap:JDK 7 采用“分段鎖”(將數組分為多個 Segment,每個 Segment 獨立加鎖),多線程可同時操作不同 Segment,并發性能大幅提升;JDK 8 摒棄分段鎖,采用“CAS 操作 + synchronized”(只鎖定鏈表頭或紅黑樹節點),進一步減少鎖競爭,性能更優,支持更高并發。
- HashTable:所有方法(如?
功能限制:
- HashTable:不允許?
null?作為 key 或 value(會拋出?NullPointerException)。 - SynchronizedMap:允許?
null(取決于底層 Map,如包裝 HashMap 時允許?null)。 - ConcurrentHashMap:允許?
null?作為 value,但不允許?null?作為 key(避免?null?引發的歧義,如?get(null)?無法區分 key 不存在還是 value 為?null)。
- HashTable:不允許?
迭代安全性:
- HashTable 和 SynchronizedMap:迭代時若結構被修改(如添加/刪除元素),可能拋出?
ConcurrentModificationException(快速失敗),需手動同步迭代過程。 - ConcurrentHashMap:迭代器是“弱一致性”的,不會拋出?
ConcurrentModificationException,迭代時能看到已提交的修改,但可能看不到迭代過程中的新修改。
- HashTable 和 SynchronizedMap:迭代時若結構被修改(如添加/刪除元素),可能拋出?
原子操作支持:
- HashTable 和 SynchronizedMap:不支持原子操作(如?
putIfAbsent),需手動加鎖實現。 - ConcurrentHashMap:內置多種原子操作(如?
putIfAbsent、remove、replace?等),無需額外同步。
- HashTable 和 SynchronizedMap:不支持原子操作(如?
HashTable 保證線程安全的方式:HashTable 的所有公開方法(如?put、get、remove?等)都被?synchronized?關鍵字修飾,例如:
public synchronized V put(K key, V value) {// 實現邏輯
}
這意味著任何線程調用這些方法時,都必須先獲取 HashTable 實例的鎖,同一時間只有一個線程能執行這些方法,從而保證了操作的原子性和可見性。但這種全表鎖的設計導致并發性能極差,多線程環境下效率低下。
ConcurrentHashMap 實現線程安全的方式因 JDK 版本而異:
- JDK 7:基于“分段鎖(Segment)”實現。Segment 繼承自?
ReentrantLock,每個 Segment 管理數組中的一部分桶。當操作某個桶時,只需鎖定對應的 Segment,其他 Segment 可被其他線程訪問。例如?put?操作時,先計算 key 所在的 Segment,獲取該 Segment 的鎖,完成操作后釋放鎖。這種方式允許多線程同時操作不同 Segment,大幅提升并發性能。 - JDK 8:摒棄分段鎖,采用“CAS 操作 + synchronized”實現。數組中的每個桶(鏈表頭或紅黑樹節點)作為鎖對象:
- 對于?
put?操作,若桶為空,通過 CAS 直接插入節點;若桶非空,對桶的頭節點加?synchronized?鎖,再執行插入、替換等操作。 - 對于?
get?操作,無需加鎖(依賴?volatile?保證可見性),直接讀取。
這種方式鎖粒度更細(從 Segment 縮小到單個桶),鎖競爭進一步減少,性能優于分段鎖,同時支持多線程協助擴容(每個線程負責一部分桶的遷移)。
- 對于?
面試關鍵點:三者在同步機制和性能上的核心差異;HashTable 的全表鎖實現;ConcurrentHashMap 在 JDK 7 和 JDK 8 中的線程安全機制;功能限制(如 null 支持)和迭代特性的區別。
記憶法:可通過“HashTable 全表鎖,性能低禁 null;SynchronizedMap 同鎖表,略靈活;ConcurrentHashMap 分段或 CAS,高并發支持原子操”來記憶,概括三者的核心區別。
HashMap 和 LinkedHashMap 的區別是什么?
HashMap 和 LinkedHashMap 都是 Java 中常用的哈希表實現,LinkedHashMap 繼承自 HashMap,在其基礎上增加了對元素順序的維護,兩者的核心區別體現在底層結構、迭代順序、性能和適用場景上。
底層結構不同:HashMap 的底層是“數組 + 鏈表 + 紅黑樹”,僅通過哈希值和索引管理元素,不維護元素的順序關系。LinkedHashMap 在 HashMap 結構的基礎上,額外維護了一個雙向鏈表(稱為“訪問鏈”),每個節點除了存儲 key、value、哈希值和 next 指針(用于哈希桶)外,還包含?
before?和?after?指針,用于鏈接前一個和后一個節點,從而記錄元素的插入順序或訪問順序。迭代順序不同:HashMap 的迭代順序是不確定的(與插入順序無關,取決于哈希值和擴容情況),每次迭代可能得到不同的順序。LinkedHashMap 的迭代順序是確定的,有兩種模式:
- 插入順序(默認):迭代順序與元素的插入順序一致,即先插入的元素先被迭代到。
- 訪問順序(通過構造方法?
LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder)?設置?accessOrder = true?啟用):每次調用?get?或?put?方法訪問元素時,該元素會被移到雙向鏈表的尾部,迭代順序為“最近最少訪問(LRU)”順序,適用于實現緩存。
示例(迭代順序對比):
// HashMap 迭代順序不確定
Map<String, Integer> hashMap = new HashMap<>();
hashMap.put("a", 1);
hashMap.put("b", 2);
hashMap.put("c", 3);
hashMap.forEach((k, v) -> System.out.print(k)); // 可能輸出 "bca" 等任意順序// LinkedHashMap 插入順序
Map<String, Integer> linkedHashMap1 = new LinkedHashMap<>();
linkedHashMap1.put("a", 1);
linkedHashMap1.put("b", 2);
linkedHashMap1.put("c", 3);
linkedHashMap1.forEach((k, v) -> System.out.print(k)); // 輸出 "abc"(與插入順序一致)// LinkedHashMap 訪問順序
Map<String, Integer> linkedHashMap2 = new LinkedHashMap<>(16, 0.75f, true);
linkedHashMap2.put("a", 1);
linkedHashMap2.put("b", 2);
linkedHashMap2.get("a"); // 訪問 "a",移到尾部
linkedHashMap2.forEach((k, v) -> System.out.print(k)); // 輸出 "ba"("a" 被訪問后移到尾部)
性能差異:LinkedHashMap 由于需要維護雙向鏈表,插入、刪除元素時需額外更新?
before?和?after?指針,性能略低于 HashMap(尤其是數據量較大時)。查詢操作的性能兩者相近(均依賴哈希值定位,時間復雜度 O(1) 或 O(log n)),但 LinkedHashMap 的迭代操作效率更高(直接遍歷雙向鏈表,無需遍歷整個哈希桶數組)。適用場景不同:HashMap 適用于無需關注元素順序、追求插入和查詢高效的場景(如存儲鍵值對配置、快速查找數據)。LinkedHashMap 適用于需要保持元素順序的場景:
- 插入順序:如日志記錄(按時間順序存儲)、需要按插入順序遍歷的場景。
- 訪問順序:如實現 LRU(最近最少使用)緩存(通過重寫?
removeEldestEntry?方法,當元素數量超過閾值時,自動移除最久未訪問的元素)。
其他細節:兩者的初始容量、負載因子、擴容機制、哈希沖突處理方式(鏈表轉紅黑樹)完全一致,因為 LinkedHashMap 復用了 HashMap 的核心邏輯,僅在元素插入、訪問、刪除時額外維護雙向鏈表。
面試關鍵點:底層結構的差異(雙向鏈表的存在);迭代順序的確定性(插入順序 vs 訪問順序);性能對比(LinkedHashMap 的額外開銷);LRU 緩存的實現(LinkedHashMap 的訪問順序模式)。
記憶法:可通過“HashMap 無序快,LinkedHashMap 有序(插入/訪問)稍慢;鏈表維護順序,適用需序或緩存”來記憶,概括兩者的核心區別和適用場景。
CopyOnWriteArrayList 和 ConcurrentLinkedQueue 的底層實現是什么?
CopyOnWriteArrayList 和 ConcurrentLinkedQueue 都是 Java 并發包(java.util.concurrent)中線程安全的集合類,分別針對 List 和 Queue 場景設計,底層實現各有特點,核心是通過無鎖或輕量級同步機制保證高并發性能。
CopyOnWriteArrayList 的底層實現基于“寫時復制(Copy-On-Write)”的動態數組。它維護一個 volatile 修飾的數組(array),確保讀操作的可見性。核心思想是:讀操作無需加鎖,直接訪問當前數組;寫操作(如 add、set、remove 等)時,不直接修改原數組,而是創建一個新數組,將原數組元素復制到新數組后再執行修改,最后用新數組替換原數組(通過 volatile 保證其他線程可見)。具體實現如下:
- 讀操作(get):直接返回?
array[index],無鎖,性能極高。 - 寫操作(add):先獲取獨占鎖(ReentrantLock),防止多線程同時寫操作導致的數組不一致;然后復制原數組到新數組(新容量 = 原容量 + 1);在新數組中添加元素;最后將?
array?引用指向新數組;釋放鎖。 - 迭代器:基于創建時的數組快照進行迭代,不反映后續修改,因此不會拋出 ConcurrentModificationException,是“弱一致性”迭代器。
簡化代碼示例(add 方法核心邏輯):
public class CopyOnWriteArrayList<E> {private transient volatile Object[] array;private final ReentrantLock lock = new ReentrantLock();public boolean add(E e) {final ReentrantLock lock = this.lock;lock.lock(); // 加鎖,保證寫操作原子性try {Object[] elements = getArray();int len = elements.length;Object[] newElements = Arrays.copyOf(elements, len + 1); // 復制原數組newElements[len] = e; // 添加新元素setArray(newElements); // 替換原數組return true;} finally {lock.unlock(); // 釋放鎖}}
}
ConcurrentLinkedQueue 的底層實現是基于單向鏈表的無鎖隊列,采用“CAS(Compare-And-Swap)”操作保證線程安全,適用于高并發的生產者-消費者場景。其核心結構包括:
- 頭節點(head)和尾節點(tail),均為 volatile 修飾,確保可見性。
- 每個節點(Node)包含元素(item)和 next 指針(指向后繼節點),next 用 volatile 修飾。
核心操作(入隊 offer 和出隊 poll)均通過 CAS 實現,無需加鎖:
- 入隊(offer):從尾節點開始,通過 CAS 將新節點設置為當前尾節點的 next,若成功則嘗試更新尾節點(允許尾節點滯后,減少 CAS 操作)。
- 出隊(poll):從頭節點開始,通過 CAS 將頭節點的 item 設為 null(標記刪除),若成功則更新頭節點為下一個節點。
CAS 操作依賴 Unsafe 類的 native 方法,通過硬件級別的原子操作保證多線程下的原子性,避免了鎖競爭帶來的性能開銷。由于無鎖設計,多個線程可同時進行入隊和出隊操作,并發性能優異,但迭代器同樣是弱一致性(可能看不到最新修改)。
面試關鍵點:CopyOnWriteArrayList 的寫時復制機制(讀無鎖、寫加鎖復制);ConcurrentLinkedQueue 的無鎖 CAS 實現;兩者的弱一致性迭代器特性;適用場景(CopyOnWriteArrayList 適合讀多寫少,ConcurrentLinkedQueue 適合高并發隊列操作)。
記憶法:可通過“CopyOnWrite 寫復制,讀快寫慢加鎖;ConcurrentLinkedQueue 無鎖 CAS,高并發隊列頂呱呱”來記憶,概括兩者的核心實現和特點。
什么是線程安全?Java 中有哪幾種方式可以保證線程安全?
線程安全是指在多線程環境下,無論操作系統如何調度線程,多個線程對共享資源的并發操作都能保證結果的正確性(與單線程執行結果一致),不會出現數據不一致、邏輯錯誤或異常。線程安全的核心是解決共享資源的競爭問題,確保操作的原子性、可見性和有序性。
Java 中保證線程安全的方式主要有以下幾種,各有適用場景:
- 使用 synchronized 關鍵字:synchronized 是 Java 內置的同步機制,可修飾方法或代碼塊,通過獲取對象的監視器鎖(monitor)保證同一時間只有一個線程執行同步代碼,實現操作的原子性。同時,synchronized 能保證可見性(釋放鎖時將修改刷新到主內存,獲取鎖時從主內存加載最新值)和有序性(禁止指令重排序)。例如:
// 修飾方法
public synchronized void increment() {count++;
}// 修飾代碼塊
public void update() {synchronized (this) {// 同步操作}
}
優點是使用簡單,無需手動釋放鎖;缺點是鎖粒度較粗(可能導致并發性能低),無法中斷等待鎖的線程。
- 使用 volatile 關鍵字:volatile 用于修飾變量,保證變量的可見性(一個線程修改后,其他線程能立即看到最新值)和有序性(禁止指令重排序),但不保證原子性。適用于變量被多個線程讀取、但只有一個線程修改的場景(如狀態標記):
private volatile boolean isRunning = true;public void stop() {isRunning = false; // 線程 A 修改
}public void run() {while (isRunning) { // 線程 B 能立即看到修改// 執行任務}
}
- 使用 JUC 中的鎖(如 ReentrantLock):ReentrantLock 是可重入鎖,提供比 synchronized 更靈活的功能,如可中斷鎖、超時獲取鎖、公平鎖/非公平鎖選擇、條件變量(Condition)等。通過?
lock()?獲取鎖,unlock()?釋放鎖(需在 finally 中執行):
private final ReentrantLock lock = new ReentrantLock();public void operation() {lock.lock();try {// 同步操作} finally {lock.unlock();}
}
優點是鎖粒度可控,功能豐富,適合復雜同步場景;缺點是需手動釋放鎖,易因遺漏導致死鎖。
- 使用原子類(如 AtomicInteger):原子類基于 CAS 操作實現,提供線程安全的原子操作(如自增、賦值等),無需加鎖,性能優于鎖機制。常用類有 AtomicInteger、AtomicLong、AtomicReference 等:
private AtomicInteger count = new AtomicInteger(0);public void increment() {count.incrementAndGet(); // 原子自增,等價于 count++
}
適用于簡單的計數器、狀態標記等場景,不適合復雜的復合操作。
使用線程安全的集合:如 ConcurrentHashMap、CopyOnWriteArrayList、ConcurrentLinkedQueue 等,內部通過鎖分段、CAS、寫時復制等機制保證線程安全,無需手動同步,適合高并發場景。
使用 ThreadLocal:ThreadLocal 為每個線程提供獨立的變量副本,避免共享資源競爭,本質是“以空間換時間”。適用于變量需線程隔離的場景(如數據庫連接、Session 管理):
private ThreadLocal<Connection> connectionThreadLocal = ThreadLocal.withInitial(() -> {return DriverManager.getConnection(url, user, password);
});// 線程獲取自己的連接
Connection conn = connectionThreadLocal.get();
- 不可變對象:若對象創建后狀態不可修改(如 String、Integer),則天然線程安全,因為無需擔心被修改。可通過 final 關鍵字修飾類、字段,且不提供 setter 方法實現。
面試關鍵點:線程安全的核心定義(原子性、可見性、有序性);各種線程安全方式的實現原理(synchronized 監視器鎖、volatile 內存語義、CAS 操作等);不同方式的適用場景及優缺點對比。
記憶法:可通過“同步鎖(synchronized/ReentrantLock)保原子,volatile 保可見有序,原子類 CAS 高性能,線程安全集合免手動,ThreadLocal 隔離變量,不可變對象天然安”來記憶,概括主要方式及核心作用。
進程和線程的區別是什么?
進程和線程是操作系統中調度和資源管理的基本單位,兩者既有聯系又有本質區別,核心差異體現在資源占用、調度方式、通信機制等方面。
從定義來看,進程是程序的一次執行過程,是操作系統進行資源分配和調度的獨立單位;線程是進程的一個執行單元,是操作系統進行任務調度的基本單位,一個進程可以包含多個線程,線程共享進程的資源。
具體區別如下:
資源占用:進程擁有獨立的資源空間,包括內存(代碼段、數據段、堆)、文件描述符、IO 設備等,進程間的資源不共享,切換時需保存和恢復整個進程的資源狀態,開銷較大。線程不擁有獨立資源,共享所屬進程的內存、文件描述符等資源,僅擁有獨立的棧空間、程序計數器和寄存器,資源占用少,切換時只需保存線程私有數據,開銷遠小于進程。
調度粒度:操作系統調度的基本單位是線程,而非進程。同一進程內的線程切換由進程內的線程調度器管理,無需切換地址空間,速度更快;不同進程間的切換需要操作系統介入,涉及地址空間切換,速度較慢。因此,線程的調度效率遠高于進程。
生命周期:進程的生命周期包括創建、就緒、運行、阻塞、終止,創建和終止的開銷大(需分配和釋放資源)。線程的生命周期與進程類似,但創建和終止僅需初始化或釋放私有數據,開銷小。一個進程終止時,其所有線程會被強制終止;而線程終止不會影響同進程的其他線程。
通信機制:進程間通信(IPC)需通過操作系統提供的機制,如管道、消息隊列、共享內存、信號量、Socket 等,由于資源隔離,通信復雜且效率低。線程間通信簡單,可直接通過共享進程內的變量(如全局變量、堆內存)實現,也可使用線程同步機制(如鎖、信號量)協調訪問,通信效率高。
獨立性:進程是獨立的執行單位,一個進程崩潰通常不會影響其他進程(操作系統隔離)。線程依賴于進程,同一進程內的線程共享資源,一個線程崩潰可能導致整個進程崩潰(如內存訪問錯誤),獨立性低。
并發性:多進程和多線程都能實現并發,但線程的并發粒度更細。在多核 CPU 上,多線程可真正并行執行(同一進程的線程分配到不同核心);多進程也可并行,但資源開銷更大。
舉例來說,打開一個瀏覽器是一個進程,瀏覽器中的每個標簽頁可視為一個線程:標簽頁共享瀏覽器的網絡連接、緩存等資源,切換標簽頁(線程切換)快速,一個標簽頁崩潰可能導致瀏覽器整體崩潰;而同時打開瀏覽器和文本編輯器則是兩個獨立進程,資源不共享,一個崩潰不影響另一個。
面試關鍵點:資源占用的獨立性(進程獨立 vs 線程共享);調度粒度和開銷(線程更輕量);通信機制的復雜度;獨立性和故障影響范圍;并發性的實現差異。
記憶法:可通過“進程資源獨,線程共享父;進程調度重,線程切換輕;進程通信難,線程共享簡;進程獨立強,線程同存亡”來記憶,概括核心區別。
操作系統中線程的狀態有哪些?各狀態之間如何轉換?Java 中線程的狀態有哪些?各狀態之間如何轉換?
操作系統和 Java 中的線程狀態定義及轉換邏輯不同,前者是操作系統內核級的狀態描述,后者是 Java 語言層面基于內核狀態的抽象,具體如下:
操作系統中線程的狀態:
操作系統內核通常將線程狀態分為以下幾種:
- 就緒(Ready):線程已獲取除 CPU 外的所有資源,等待操作系統調度分配 CPU 時間片。
- 運行(Running):線程正在 CPU 上執行,占用 CPU 資源。
- 阻塞(Blocked):線程因等待某種資源(如 I/O 完成、鎖釋放、信號量)而暫停執行,不占用 CPU。阻塞可細分為:
- I/O 阻塞:等待 I/O 操作完成(如磁盤讀寫、網絡請求)。
- 鎖阻塞:等待其他線程釋放鎖。
- 信號量阻塞:等待信號量觸發。
- 終止(Terminated):線程執行完成或被強制終止,生命周期結束。
狀態轉換:
- 就緒 → 運行:操作系統調度器從就緒隊列中選擇線程,分配 CPU 時間片。
- 運行 → 就緒:時間片用完或被更高優先級線程搶占,線程回到就緒隊列。
- 運行 → 阻塞:線程執行過程中請求資源(如 I/O、鎖),資源未就緒時進入阻塞狀態。
- 阻塞 → 就緒:等待的資源就緒(如 I/O 完成、鎖釋放),線程從阻塞隊列進入就緒隊列,等待調度。
- 運行 → 終止:線程執行完 run 方法或被中斷(如調用 stop())。
Java 中線程的狀態:
Java 中線程狀態定義在?Thread.State?枚舉中,共 6 種,是對操作系統狀態的更高層次抽象:
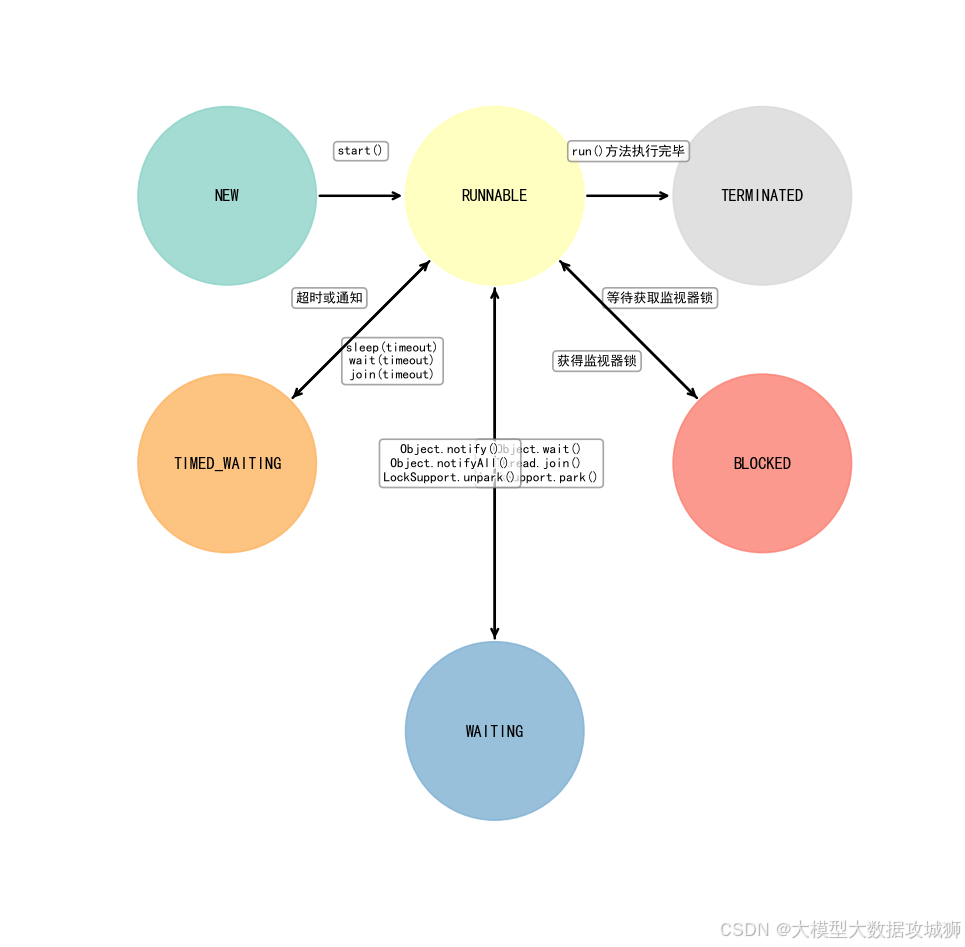
- NEW(新建):線程對象已創建,但未調用?
start()?方法,尚未啟動。 - RUNNABLE(可運行):線程已啟動,包含兩種情況:
- 正在 CPU 上執行(對應操作系統的運行狀態)。
- 等待 CPU 調度(對應操作系統的就緒狀態)。
- BLOCKED(阻塞):線程等待獲取 synchronized 監視器鎖(如嘗試進入 synchronized 方法/塊,而鎖被其他線程持有)。
- WAITING(等待):線程無限期等待其他線程的特定操作(如?
Object.wait()、Thread.join()、LockSupport.park()),需被其他線程喚醒(如?Object.notify())。 - TIMED_WAITING(超時等待):線程等待指定時間(如?
Thread.sleep(long)、Object.wait(long)、Thread.join(long)),時間到后自動喚醒或被提前喚醒。 - TERMINATED(終止):線程執行完成(run 方法結束)或被異常終止。
狀態轉換:
- NEW → RUNNABLE:調用?
start()?方法,線程啟動,進入可運行狀態。 - RUNNABLE → BLOCKED:線程嘗試獲取 synchronized 鎖,若鎖被占用,則進入阻塞狀態;獲取鎖后從 BLOCKED → RUNNABLE。
- RUNNABLE → WAITING:執行?
Object.wait()(無參)、Thread.join()(無參)等,進入等待狀態;被其他線程調用?notify()/notifyAll()?或 join 的線程終止,從 WAITING → RUNNABLE。 - RUNNABLE → TIMED_WAITING:執行?
Thread.sleep(1000)、Object.wait(1000)?等帶超時的方法,進入超時等待;時間到或被提前喚醒,從 TIMED_WAITING → RUNNABLE。 - RUNNABLE → TERMINATED:線程執行完 run 方法或被強制終止(如?
stop(),已廢棄)。
核心區別:操作系統的“阻塞”包含所有資源等待,而 Java 的 BLOCKED 僅特指等待 synchronized 鎖;Java 的 RUNNABLE 合并了操作系統的就緒和運行狀態,更簡潔。
面試關鍵點:操作系統線程狀態的四態模型及轉換;Java 線程的 6 種狀態(尤其是 BLOCKED、WAITING、TIMED_WAITING 的區別);狀態轉換的觸發條件(如方法調用、鎖競爭)。
記憶法:操作系統線程狀態可記為“就緒等 CPU,運行占 CPU,阻塞等資源,終止已結束”;Java 線程狀態可記為“NEW 未啟動,RUNNABLE 可運行,BLOCKED 等鎖,WAITING 等通知,TIMED_WAITING 限時等,TERMINATED 已終止”。
一個線程在等待獲取 synchronized 鎖時,該線程處于什么狀態?
一個線程在等待獲取 synchronized 鎖時,處于 BLOCKED(阻塞)狀態。這是 Java 線程狀態中對“等待監視器鎖”場景的明確定義,區別于其他等待狀態(如 WAITING 或 TIMED_WAITING)。
具體來說,當線程 A 嘗試進入一個 synchronized 方法或代碼塊時,若該鎖已被線程 B 持有,線程 A 無法立即獲取鎖,會被放入該鎖的“阻塞隊列”中,此時線程 A 的狀態從 RUNNABLE 轉換為 BLOCKED。直到線程 B 釋放鎖(退出 synchronized 方法/塊),操作系統會從阻塞隊列中喚醒一個線程(通常是隨機的),使其重新嘗試獲取鎖,成功后狀態從 BLOCKED 轉換為 RUNNABLE。
需要明確 BLOCKED 狀態與其他等待狀態的區別:
- BLOCKED 僅針對 synchronized 鎖的等待,是“被動等待”(等待其他線程釋放鎖)。
- WAITING 狀態是線程主動調用無參的?
Object.wait()、Thread.join()?等方法后進入的狀態,需等待其他線程主動喚醒(如?notify()),等待的是“通知”而非“鎖”。 - TIMED_WAITING 狀態是線程調用帶超時參數的方法(如?
Thread.sleep(1000)、Object.wait(1000))后進入的狀態,等待時間到后自動喚醒,或被提前喚醒,等待的是“時間”或“通知”。
示例代碼(展示 BLOCKED 狀態):
public class BlockedStateDemo {public static void main(String[] args) throws InterruptedException {Object lock = new Object();// 線程1持有鎖Thread t1 = new Thread(() -> {synchronized (lock) {try {Thread.sleep(5000); // 持有鎖5秒} catch (InterruptedException e) {e.printStackTrace();}}});// 線程2嘗試獲取鎖,會進入BLOCKED狀態Thread t2 = new Thread(() -> {synchronized (lock) { // 嘗試獲取鎖System.out.println("線程2獲取到鎖");}});t1.start();Thread.sleep(1000); // 確保t1先獲取鎖t2.start();Thread.sleep(1000);// 此時t2處于BLOCKED狀態System.out.println("t2狀態:" + t2.getState()); // 輸出 BLOCKED}
}
上述代碼中,t1 先獲取鎖并持有 5 秒,t2 啟動后嘗試獲取同一把鎖,因鎖被占用而進入 BLOCKED 狀態,直到 t1 釋放鎖后,t2 才能獲取鎖并繼續執行。
面試關鍵點:BLOCKED 狀態的定義(等待 synchronized 鎖);與 WAITING、TIMED_WAITING 狀態的區別;觸發 BLOCKED 狀態的場景(競爭 synchronized 鎖)。
記憶法:可通過“等 synchronized 鎖,狀態是 BLOCKED;等通知是 WAITING,限時等是 TIMED_WAITING”來記憶,明確不同等待場景對應的線程狀態。
調用線程的 start () 方法后再調用一次會發生什么?
調用線程的?start()?方法后再調用一次會拋出?IllegalThreadStateException?異常。這是由線程的生命周期規則決定的,start()?方法的核心作用是啟動線程,使其從?NEW?狀態進入?RUNNABLE?狀態,而一個線程只能被啟動一次。
線程的生命周期中,start()?方法的執行邏輯包含對線程狀態的嚴格檢查。當線程對象被創建時,初始狀態為?NEW(尚未調用?start())。第一次調用?start()?時,JVM 會檢查狀態是否為?NEW,若是則啟動線程(調用底層?start0()?native 方法,由操作系統創建實際的線程實體),并將狀態從?NEW?轉換為?RUNNABLE。一旦線程狀態脫離?NEW(無論后續是?RUNNABLE、BLOCKED、TERMINATED?等),再次調用?start()?時,JVM 會檢測到狀態非?NEW,直接拋出?IllegalThreadStateException,阻止重復啟動。
從底層實現看,Thread?類的?start()?方法源碼(簡化)如下:
public synchronized void start() {if (threadStatus != 0) // threadStatus 為 0 表示 NEW 狀態throw new IllegalThreadStateException();// 加入線程組等操作start0(); // native 方法,啟動線程
}
其中?threadStatus?是線程的狀態標識,初始值為 0(NEW?狀態),start()?方法通過?synchronized?保證線程安全,且僅允許?threadStatus?為 0 時執行?start0()。
需要注意,線程執行完畢后狀態變為?TERMINATED,此時即使再次調用?start(),同樣會因狀態非?NEW?而拋出異常。若需重復執行相同任務,需重新創建線程對象(處于?NEW?狀態)并調用?start()。
示例代碼驗證:
public class RepeatStartDemo {public static void main(String[] args) {Thread thread = new Thread(() -> {System.out.println("線程執行");});thread.start(); // 第一次啟動,正常執行try {Thread.sleep(1000); // 等待線程執行完畢} catch (InterruptedException e) {e.printStackTrace();}try {thread.start(); // 第二次啟動,拋出異常} catch (IllegalThreadStateException e) {System.out.println("異常:" + e.getMessage()); // 輸出異常信息}}
}
上述代碼中,線程第一次啟動后執行完畢(狀態為?TERMINATED),第二次調用?start()?會觸發?IllegalThreadStateException。
面試關鍵點:線程生命周期中?start()?方法的狀態檢查機制;IllegalThreadStateException?的觸發條件;線程只能啟動一次的底層原因(threadStatus?標識和?start0()?native 方法的調用限制)。
記憶法:可通過“線程啟動靠 start,一次啟動終生效;狀態脫離 NEW 后,再調用就拋異常”來記憶,明確?start()?方法的調用限制和異常原因。
從操作系統層面看,兩個線程可以訪問同一個數據嗎?如果一個線程崩潰了,會影響整個進程的運行嗎?
從操作系統層面看,兩個線程可以訪問同一個數據。因為線程是進程的執行單元,同一進程內的所有線程共享該進程的地址空間(包括代碼段、數據段、堆內存等),這意味著線程間無需額外機制即可直接訪問進程的共享資源(如全局變量、堆上的對象等)。例如,進程中的兩個線程可同時讀寫堆內存中的同一個數組,或訪問全局變量。這種共享特性是線程高效通信的基礎,但也帶來了線程安全問題(如數據競爭),需通過同步機制(如鎖、信號量)保證操作的原子性。
一個線程崩潰是否影響整個進程,取決于崩潰的原因:
- 若線程因邏輯錯誤(如空指針異常、數組越界)崩潰,通常只會導致該線程終止,不會直接影響同進程的其他線程。這是因為現代操作系統會為線程設置異常處理機制,當線程觸發未捕獲的異常時,操作系統會終止該線程,但進程的其他線程仍可繼續運行。例如,Java 中一個線程拋出?
NullPointerException?未被捕獲,會導致該線程終止,但 JVM 進程和其他線程不受影響。 - 若線程因嚴重錯誤(如訪問非法內存地址、棧溢出、硬件錯誤)崩潰,可能導致整個進程終止。因為這些錯誤會破壞進程的共享資源(如內存空間被污染、進程的核心數據結構損壞),操作系統為避免進一步的系統級風險,會終止整個進程及其所有線程。例如,C 語言中線程執行?
*(int*)0 = 0(寫入空指針地址)會觸發內存訪問錯誤,操作系統會發送信號終止整個進程。
核心原因是線程與進程的資源關系:線程共享進程的地址空間和核心資源,線程的崩潰若局限于自身私有數據(如棧空間的局部錯誤),則影響范圍有限;若涉及共享資源的破壞,則會牽連整個進程。
舉例說明:
- 安全崩潰場景:線程 A 因?
ArrayIndexOutOfBoundsException?終止,線程 B 仍可繼續訪問共享的全局變量,進程正常運行。 - 致命崩潰場景:線程 A 因緩沖區溢出改寫了進程的代碼段,導致進程的指令集被破壞,操作系統檢測到后終止整個進程,線程 B 也隨之終止。
面試關鍵點:線程共享進程資源的特性(可直接訪問同一數據);線程崩潰對進程的影響取決于崩潰原因(邏輯錯誤 vs 資源破壞);線程與進程的資源依賴關系。
記憶法:可通過“線程共享進程資源,同數據可共訪問;線程崩潰看原因,邏輯錯僅自斃,壞共享殺全進程”來記憶,概括核心結論。
synchronized 關鍵字的使用方法是什么?其底層實現原理是什么?(需涉及對象頭、鎖池、等待池)
synchronized?是 Java 中用于保證線程安全的關鍵字,通過實現同步機制防止多線程并發訪問共享資源時的數據不一致。其使用方法和底層實現如下:
使用方法:
synchronized?可用于修飾方法或代碼塊,具體有三種形式:
- 修飾實例方法:鎖對象為當前實例(
this),同一實例的多個同步方法共享一把鎖,不同實例的鎖相互獨立。public synchronized void instanceMethod() {// 同步代碼 } - 修飾靜態方法:鎖對象為當前類的 Class 對象(如?
Xxx.class),所有靜態同步方法共享同一把鎖(類級別的鎖)。public static synchronized void staticMethod() {// 同步代碼 } - 修飾代碼塊:顯式指定鎖對象(可為任意對象),靈活性更高,可縮小同步范圍,減少鎖競爭。
public void blockMethod() {synchronized (lockObject) { // lockObject 為指定的鎖對象// 同步代碼} }
底層實現原理:
synchronized?的底層依賴 JVM 的監視器鎖(monitor)機制,核心涉及對象頭、鎖池和等待池:
對象頭(Object Header):Java 對象在內存中的布局包括對象頭、實例數據和對齊填充,其中對象頭是實現?
synchronized?的關鍵。對象頭由兩部分組成:- Mark Word:存儲對象的運行時狀態,如哈希碼、GC 分代年齡、鎖狀態(無鎖、偏向鎖、輕量級鎖、重量級鎖)、持有鎖的線程 ID 等。鎖的狀態信息就存儲在這里,是?
synchronized?實現的核心數據結構。 - 類型指針(Klass Pointer):指向對象所屬類的元數據(方法區中的 Class 對象),確定對象的類型。
例如,在重量級鎖狀態下,Mark Word 會存儲指向監視器(monitor)的指針,通過監視器實現鎖的管理。
- Mark Word:存儲對象的運行時狀態,如哈希碼、GC 分代年齡、鎖狀態(無鎖、偏向鎖、輕量級鎖、重量級鎖)、持有鎖的線程 ID 等。鎖的狀態信息就存儲在這里,是?
監視器(monitor):每個 Java 對象都關聯一個監視器(可理解為一種同步工具),監視器內部維護兩個隊列:
- 鎖池(Entry Set):存放等待獲取鎖的線程。當線程嘗試獲取?
synchronized?鎖時,若鎖已被其他線程持有,該線程會被放入鎖池,進入?BLOCKED?狀態,等待鎖釋放。 - 等待池(Wait Set):存放調用?
wait()?方法后釋放鎖的線程。線程獲取鎖后,若執行?wait(),會釋放鎖并進入等待池,進入?WAITING?狀態,需等待其他線程調用?notify()?或?notifyAll()?喚醒,喚醒后線程會從等待池轉移到鎖池,重新競爭鎖。
- 鎖池(Entry Set):存放等待獲取鎖的線程。當線程嘗試獲取?
同步過程:
- 線程進入?
synchronized?代碼時,需先獲取鎖:通過 CAS 操作嘗試修改對象頭 Mark Word 中的鎖狀態,若成功(鎖未被持有),則持有鎖并執行代碼;若失敗(鎖已被持有),則進入鎖池(BLOCKED?狀態)。 - 線程執行?
wait()?方法時,釋放鎖,從運行狀態進入等待池(WAITING?狀態)。 - 其他線程執行?
notify()?時,從等待池喚醒一個線程,使其進入鎖池競爭鎖;執行?notifyAll()?時,喚醒等待池所有線程,全部進入鎖池競爭鎖。 - 線程退出?
synchronized?代碼時,釋放鎖,JVM 從鎖池喚醒一個線程,使其有機會獲取鎖。
- 線程進入?
例如,當線程 A 持有鎖執行同步代碼時,線程 B 嘗試獲取鎖會進入鎖池(BLOCKED);若線程 A 調用?wait(),則釋放鎖并進入等待池(WAITING),線程 B 可獲取鎖;線程 A 被?notify()?喚醒后,進入鎖池等待重新獲取鎖。
面試關鍵點:synchronized?的三種使用形式(實例方法、靜態方法、代碼塊);對象頭的結構(Mark Word 的作用);監視器的鎖池和等待池的區別及轉換;同步過程的鎖獲取與釋放邏輯。
記憶法:可通過“synchronized 三用法,實例靜態代碼塊;底層依賴監視器,對象頭存鎖狀態;鎖池等鎖 BLOCKED,等待池等 notify,wait 放鎖入等待”來記憶,概括使用方法和底層機制。
Java 對 synchronized 做了哪些優化?(圍繞偏向鎖、輕量級鎖、重量級鎖的升級過程說明)
Java 對?synchronized?的優化主要體現在鎖的分級實現上,通過引入偏向鎖、輕量級鎖和重量級鎖,根據競爭程度動態調整鎖的類型,減少鎖競爭帶來的性能開銷。這三種鎖的升級過程是“無鎖 → 偏向鎖 → 輕量級鎖 → 重量級鎖”,不可逆(除偏向鎖可被撤銷外),具體如下:
1. 偏向鎖(Biased Locking):
適用場景:無實際競爭,且只有一個線程多次獲取鎖。
核心原理:鎖會偏向于第一個獲取它的線程,減少無競爭情況下的 CAS 操作開銷。當線程第一次獲取鎖時,通過 CAS 將線程 ID 記錄在對象頭的 Mark Word 中(偏向模式),之后該線程再次獲取鎖時,無需 CAS 操作,僅需判斷 Mark Word 中的線程 ID 是否為當前線程 ID,若一致則直接進入同步代碼,幾乎無開銷。
2. 輕量級鎖:
適用場景:有輕微競爭(多個線程交替獲取鎖,無長時間持有)。
升級觸發:當有第二個線程嘗試獲取偏向鎖時,偏向鎖會被撤銷(需等待全局安全點,暫停持有偏向鎖的線程),升級為輕量級鎖。
核心原理:線程獲取輕量級鎖時,會在棧幀中創建鎖記錄(Lock Record),存儲對象頭的 Mark Word 副本,然后通過 CAS 將對象頭的 Mark Word 替換為指向鎖記錄的指針(稱為“加鎖”)。若 CAS 成功,線程獲取鎖;若 CAS 失敗(表示存在競爭),則嘗試自旋(忙等)獲取鎖,避免立即升級為重量級鎖。
3. 重量級鎖:
適用場景:競爭激烈(多個線程同時爭搶鎖,或線程持有鎖時間長)。
升級觸發:輕量級鎖的自旋達到一定次數(或自旋線程數超過 CPU 核心數的一半),自旋失敗,此時輕量級鎖膨脹為重量級鎖。
核心原理:依賴操作系統的互斥量(mutex)實現,線程獲取重量級鎖時,若鎖被占用,線程會進入內核態阻塞(放入鎖池,狀態為?BLOCKED),不再自旋,減少 CPU 浪費。但內核態與用戶態切換開銷大,性能較低。
升級過程詳解:
- 初始狀態:對象剛創建時,處于無鎖狀態,Mark Word 存儲哈希碼和 GC 年齡。
- 偏向鎖獲取:第一個線程獲取鎖,通過 CAS 將線程 ID 寫入 Mark Word,進入偏向模式。
- 偏向鎖撤銷與輕量級鎖升級:第二個線程嘗試獲取鎖,JVM 檢查到競爭,撤銷偏向鎖(需停頓線程,更新 Mark Word),兩個線程分別在棧幀創建鎖記錄,通過 CAS 競爭 Mark Word 的鎖記錄指針,成功者獲取輕量級鎖。
- 輕量級鎖膨脹:若 CAS 競爭失敗(如第三個線程參與競爭),線程進入自旋;自旋次數耗盡(或競爭加劇),輕量級鎖升級為重量級鎖,Mark Word 指向監視器(monitor),未獲取鎖的線程進入鎖池阻塞。
優化效果:通過分級鎖,在無競爭或輕微競爭時避免重量級鎖的高開銷,僅在激烈競爭時使用重量級鎖,平衡了同步安全性和性能。例如,單線程頻繁訪問同步代碼時,偏向鎖幾乎無開銷;多線程交替訪問時,輕量級鎖的自旋減少阻塞;高并發爭搶時,重量級鎖保證同步但犧牲部分性能。
面試關鍵點:三種鎖的適用場景;升級觸發條件(偏向鎖撤銷、輕量級鎖膨脹的原因);各階段鎖的實現原理(偏向鎖的線程 ID 記錄、輕量級鎖的 CAS 與自旋、重量級鎖的互斥量);優化帶來的性能提升邏輯。
記憶法:可通過“無鎖開始,單線程偏;多線程來,輕量自旋;競爭激烈,重量阻塞;鎖升級不可逆,按需選類型”來記憶,概括鎖升級的過程和核心邏輯。
synchronized 是在什么公共資源上加鎖?創建一個 Java 對象時,除了屬性值,還有什么部分?synchronized 鎖定的數據存儲在對象的哪里?
synchronized?是在對象的“監視器(monitor)”這一公共資源上加鎖。監視器是一種同步機制,每個 Java 對象在 JVM 中都隱式關聯一個監視器,synchronized?通過獲取和釋放監視器的所有權實現同步。當線程進入?synchronized?代碼時,需先獲取該對象的監視器所有權;退出時釋放所有權,確保同一時間只有一個線程持有監視器,從而保證同步代碼的原子性。
創建一個 Java 對象時,在內存中除了存儲屬性值(實例數據),還包括以下部分:
對象頭(Object Header):對象的核心元數據,占 8 字節(32 位 JVM)或 16 字節(64 位 JVM,默認開啟指針壓縮),包含:
- Mark Word:存儲對象的運行時狀態,如哈希碼、GC 分代年齡、鎖狀態(無鎖、偏向鎖、輕量級鎖、重量級鎖)、持有鎖的線程 ID、監視器指針等。
- 類型指針(Klass Pointer):指向對象所屬類的元數據(方法區中的 Class 對象),用于確定對象的類型,如判斷對象是否為某個類的實例。
- 數組長度(僅數組對象):若對象是數組,對象頭還會額外存儲數組的長度(4 字節)。
對齊填充(Padding):Java 對象在內存中的大小需為 8 字節的整數倍(64 位 JVM),若對象頭 + 實例數據的總大小不滿足,會通過對齊填充補充空白字節,確保內存對齊,提高 CPU 訪問效率。
synchronized?鎖定的數據存儲在對象頭的?Mark Word?中。Mark Word 是一個動態變化的字段,會根據對象的鎖狀態存儲不同信息:
- 無鎖狀態:存儲對象的哈希碼、GC 分代年齡。
- 偏向鎖狀態:存儲偏向的線程 ID、偏向時間戳、GC 分代年齡,標記為偏向模式。
- 輕量級鎖狀態:存儲指向線程棧幀中鎖記錄(Lock Record)的指針,鎖記錄中包含 Mark Word 的副本。
- 重量級鎖狀態:存儲指向監視器(monitor)的指針,通過監視器管理鎖的競爭和等待。
例如,當線程獲取重量級鎖時,Mark Word 會指向該對象關聯的監視器,監視器內部的鎖池和等待池記錄等待線程的狀態;釋放鎖時,Mark Word 可能恢復為輕量級鎖狀態(若競爭消失)或保持重量級鎖狀態(若仍有競爭)。
這種設計的核心是將鎖狀態與對象綁定,通過對象頭的 Mark Word 高效存儲鎖信息,避免額外的內存開銷,同時支持鎖的升級(偏向鎖 → 輕量級鎖 → 重量級鎖),適應不同的并發場景。
面試關鍵點:synchronized?鎖定的是對象的監視器;Java 對象的三部分組成(對象頭、實例數據、對齊填充);對象頭中 Mark Word 的作用及鎖狀態存儲;不同鎖狀態下 Mark Word 的內容差異。
記憶法:可通過“synchronized 鎖監視器,對象關聯不可離;創建對象三部分,頭(對象頭)、數(實例數據)、填充(對齊填充)要記齊;鎖信息存 Mark Word,狀態隨鎖動態變”來記憶,概括核心知識點。
ReentrantLock(Lock 接口)與 synchronized 的區別是什么?
ReentrantLock 是 Java 并發包(java.util.concurrent.locks)中實現 Lock 接口的可重入鎖,與 synchronized 同為線程安全的同步機制,但在實現原理、功能特性和使用方式上有顯著區別,具體如下:
- 鎖的獲取與釋放方式:synchronized 是隱式鎖,無需手動操作,線程進入同步代碼塊時自動獲取鎖,退出時自動釋放(包括正常退出、拋出異常),無需擔心鎖泄漏。ReentrantLock 是顯式鎖,需通過?
lock()?方法手動獲取鎖,unlock()?方法釋放鎖,且?unlock()?必須放在 finally 塊中(否則可能因異常導致鎖未釋放,引發死鎖),示例:
// synchronized 隱式釋放
public synchronized void syncMethod() {// 同步操作
}// ReentrantLock 顯式釋放
public void lockMethod() {lock.lock();try {// 同步操作} finally {lock.unlock(); // 必須手動釋放}
}
- 可中斷性:synchronized 無法中斷等待鎖的線程,線程一旦進入 BLOCKED 狀態,只能等待其他線程釋放鎖或一直阻塞。ReentrantLock 支持中斷等待鎖的線程,通過?
lockInterruptibly()?方法,線程在等待鎖時可響應中斷(如其他線程調用?interrupt()),避免無限期等待,示例:
try {lock.lockInterruptibly(); // 可被中斷的鎖獲取
} catch (InterruptedException e) {// 處理中斷邏輯
}
超時獲取鎖:ReentrantLock 可通過?
tryLock(long timeout, TimeUnit unit)?嘗試在指定時間內獲取鎖,超時未獲取則返回 false,適合避免死鎖。synchronized 無此功能,線程會一直阻塞直到獲取鎖。公平鎖支持:synchronized 只能是非公平鎖(線程獲取鎖的順序不保證,可能存在饑餓)。ReentrantLock 可通過構造函數?
new ReentrantLock(true)?創建公平鎖,保證線程按等待順序獲取鎖(需額外開銷,性能略低)。條件變量(Condition):ReentrantLock 可通過?
newCondition()?方法創建多個條件變量,實現更精細的線程間通信(如不同條件下的等待/喚醒)。synchronized 僅通過對象的?wait()、notify()、notifyAll()?實現通信,且一個對象只有一個等待池,功能單一。示例:
ReentrantLock lock = new ReentrantLock();
Condition notEmpty = lock.newCondition();
Condition notFull = lock.newCondition();// 線程1等待非空條件
notEmpty.await();
// 線程2喚醒非空條件
notEmpty.signal();
底層實現:synchronized 基于 JVM 內置的監視器鎖(monitor)實現,依賴對象頭的 Mark Word 和操作系統互斥量。ReentrantLock 基于 AQS(AbstractQueuedSynchronizer)實現,通過 volatile 修飾的狀態變量(state)和雙向隊列管理線程等待,更靈活。
性能:JDK 6 后 synchronized 引入偏向鎖、輕量級鎖等優化,性能與 ReentrantLock 接近。但在高并發且競爭激烈時,ReentrantLock 因可控制鎖粒度和公平性,性能可能更優;低并發時兩者差異不大。
面試關鍵點:顯式/隱式鎖的操作差異;可中斷、超時、公平鎖等功能特性;條件變量的靈活性;底層實現(monitor vs AQS);性能對比及適用場景。
記憶法:可通過“synchronized 隱式自管理,ReentrantLock 顯式需手動;中斷超時公平鎖,條件變量 Reentrant 強;底層 monitor 對 AQS,功能靈活選顯式”來記憶,概括核心區別。
Java 中實現鎖的方式有哪些?(對比顯式鎖與 synchronized 的差異)
Java 中實現鎖的方式多樣,可分為內置鎖、顯式鎖、原子操作及分布式鎖等,其中顯式鎖與 synchronized(內置鎖)的差異是核心考點,具體如下:
實現鎖的主要方式:
- synchronized 關鍵字:Java 內置的隱式鎖,通過修飾方法或代碼塊實現,依賴 JVM 監視器機制,自動獲取和釋放鎖,無需手動操作。
- 顯式鎖(Lock 接口實現類):如 ReentrantLock、ReentrantReadWriteLock 等,需手動調用?
lock()?和?unlock()?管理鎖,基于 AQS 實現,功能更豐富。 - 原子類(CAS 操作):如 AtomicInteger、AtomicReference 等,基于 CAS(Compare-And-Swap)實現無鎖同步,通過硬件原子操作保證線程安全。
- volatile + CAS:結合 volatile 的可見性和 CAS 的原子性,實現輕量級同步(如 ConcurrentHashMap 中的部分操作)。
- 分布式鎖:如基于 Redis、ZooKeeper 實現的跨進程鎖,用于分布式系統中多節點的同步(非 JVM 內置,依賴中間件)。
顯式鎖與 synchronized 的核心差異:
| 維度 | synchronized | 顯式鎖(如 ReentrantLock) |
|---|---|---|
| 鎖的管理方式 | 隱式(自動獲取/釋放) | 顯式(需手動調用 lock()/unlock()) |
| 可中斷性 | 不可中斷(等待鎖的線程無法響應中斷) | 可中斷(lockInterruptibly() 支持中斷) |
| 超時獲取鎖 | 不支持 | 支持(tryLock(long timeout)) |
| 公平鎖支持 | 僅非公平鎖 | 可通過構造函數指定公平/非公平 |
| 條件變量 | 單一(依賴對象的 wait()/notify()) | 多條件變量(Condition),支持精細通信 |
| 鎖類型擴展 | 僅排他鎖 | 支持讀寫鎖(ReentrantReadWriteLock) |
| 底層實現 | 基于 JVM 監視器(monitor) | 基于 AQS 框架(狀態變量 + 等待隊列) |
| 性能(高并發) | 優化后接近顯式鎖,但靈活性受限 | 競爭激烈時性能更優,鎖粒度可控 |
| 適用場景 | 簡單同步場景,代碼簡潔 | 復雜同步場景(如中斷、超時、讀寫分離) |
舉例說明差異:
- 超時獲取鎖:顯式鎖可避免死鎖,如?
if (lock.tryLock(1, TimeUnit.SECONDS)) { ... },synchronized 無此功能。 - 讀寫分離:ReentrantReadWriteLock 允許多個讀線程并發訪問,寫線程獨占,適合讀多寫少場景,synchronized 僅支持排他鎖,讀操作也會阻塞。
- 多條件等待:顯式鎖的 Condition 可實現不同條件的線程等待(如生產者-消費者模型中,分別等待“非空”和“非滿”條件),synchronized 需創建多個對象鎖才能實現類似功能。
面試關鍵點:Java 中鎖的多種實現方式;顯式鎖與 synchronized 在功能、操作、性能上的差異;不同鎖的適用場景(如讀寫鎖適合讀多寫少)。
記憶法:可通過“內置鎖隱式簡,顯式鎖手動強;中斷超時公平選,條件多組讀寫分;場景簡單用 sync,復雜功能顯式強”來記憶,概括核心差異和適用場景。
volatile 關鍵字的作用是什么?在內存層面上如何實現?它的使用場景是什么?
volatile 是 Java 中用于修飾變量的關鍵字,主要作用是保證變量的可見性和有序性,但不保證原子性,是輕量級的線程同步機制。
核心作用:
保證可見性:當一個線程修改了 volatile 修飾的變量,其他線程能立即看到該變量的最新值。在多線程環境中,線程會將變量從主內存加載到工作內存(CPU 緩存)中操作,非 volatile 變量的修改可能僅停留在工作內存,未及時刷新到主內存,導致其他線程讀取舊值。volatile 變量的修改會立即刷新到主內存,且其他線程讀取時會從主內存重新加載,避免緩存不一致。
禁止指令重排序:編譯器或 CPU 為優化性能,可能對指令重排序(不改變單線程語義的前提下調整執行順序)。volatile 變量通過內存屏障阻止重排序,確保代碼執行順序與源碼一致。例如,在雙重檢查鎖定實現單例模式時,volatile 可防止初始化對象的指令被重排序,避免其他線程獲取未完全初始化的對象。
不保證原子性:volatile 無法保證復合操作的原子性(如?
i++,包含讀取、修改、寫入三步)。多線程并發執行?i++?時,可能出現多個線程讀取同一值,導致結果錯誤。
內存層面的實現:
volatile 的可見性和有序性通過“內存屏障”(Memory Barrier)實現,JVM 會為 volatile 變量的讀寫操作插入特定的內存屏障指令,限制指令重排序并保證內存可見性:
- 寫屏障(Store Barrier):當線程寫入 volatile 變量時,會觸發寫屏障,將工作內存中的變量值刷新到主內存,并使其他線程中該變量的緩存失效(通過 MESI 緩存一致性協議)。
- 讀屏障(Load Barrier):當線程讀取 volatile 變量時,會觸發讀屏障,從主內存重新加載變量值到工作內存,確保讀取的是最新值。
- 重排序限制:寫屏障禁止之前的指令重排序到屏障之后,讀屏障禁止之后的指令重排序到屏障之前,保證指令執行順序。
使用場景:
- 狀態標記量:用于標記線程的運行狀態(如停止信號),確保一個線程修改狀態后,其他線程能立即感知。示例:
private volatile boolean isRunning = true;public void stop() {isRunning = false; // 線程 A 修改
}public void run() {while (isRunning) { // 線程 B 立即看到最新值// 執行任務}
}
- 雙重檢查鎖定(DCL)單例:防止指令重排序導致的單例對象未完全初始化問題。示例:
public class Singleton {private static volatile Singleton instance; // 必須加 volatileprivate Singleton() {}public static Singleton getInstance() {if (instance == null) { // 第一次檢查synchronized (Singleton.class) {if (instance == null) { // 第二次檢查instance = new Singleton(); // 防止重排序}}}return instance;}
}
- 與 CAS 結合實現非阻塞同步:如原子類(AtomicInteger)的內部變量 value 被 volatile 修飾,配合 CAS 操作實現線程安全的自增/自減。
面試關鍵點:volatile 的三大特性(可見性、有序性、非原子性);內存屏障的作用(刷新主內存、禁止重排序);典型使用場景(狀態標記、DCL 單例);與 synchronized 的區別(volatile 更輕量,無鎖競爭)。
記憶法:可通過“volatile 保可見,禁重排,不原子;內存屏障來實現,寫刷內存讀加載;狀態標記 DCL 用,輕量同步場景適”來記憶,概括核心作用和使用場景。
兩個線程同時寫一個 volatile 修飾的變量,第二個線程讀到的值是多少?若一個線程更新了變量,其他線程的變量副本會失效,這是如何實現的?
兩個線程同時寫一個 volatile 修飾的變量時,第二個線程讀到的值不確定,可能是第一個線程寫入的值、自己寫入的值,或其他中間值。這是因為 volatile 僅保證可見性和有序性,不保證原子性,無法避免“寫覆蓋”問題。
具體來說,變量的寫入操作(如?i = i + 1)包含三個步驟:讀取變量當前值、修改值、寫入新值。當兩個線程同時執行時,可能出現以下情況:
- 線程 A 讀取值為 0,線程 B 也讀取值為 0。
- 線程 A 計算得 1 并寫入(volatile 保證寫入主內存)。
- 線程 B 計算得 1 并寫入,覆蓋線程 A 的結果。
此時第二個線程(假設為 B)讀到的值是 1,但實際應是 2,出現數據丟失。因此,volatile 無法保證復合操作的線程安全,需結合鎖或原子類(如 AtomicInteger)解決。
一個線程更新 volatile 變量后,其他線程的變量副本會失效,這通過“緩存一致性協議”和“內存屏障”共同實現:
緩存一致性協議(如 MESI 協議):現代 CPU 采用該協議保證多個緩存(線程的工作內存)中共享變量的一致性。當一個 CPU 核心(對應線程)修改了 volatile 變量,會將該變量的緩存行標記為“無效”(Invalid)。其他 CPU 核心在讀取該變量時,會檢測到緩存行無效,放棄本地緩存的舊值,從主內存重新加載最新值,確保讀取的是更新后的數據。
內存屏障(Memory Barrier):JVM 為 volatile 變量的寫操作插入“寫屏障”,確保修改后的值立即刷新到主內存;為讀操作插入“讀屏障”,確保讀取時從主內存加載,而非本地緩存。寫屏障還會觸發 CPU 發送“緩存無效”信號,通知其他核心該變量的緩存已失效,強制它們重新同步。
例如,線程 A 寫入 volatile 變量?flag = true:
- 寫屏障觸發,
flag?的新值從線程 A 的工作內存刷新到主內存。 - CPU 發送信號,標記其他線程中?
flag?的緩存為無效。 - 線程 B 讀取?
flag?時,讀屏障觸發,檢測到緩存無效,從主內存加載?true,而非舊值?false。
這種機制保證了 volatile 變量的可見性,但無法解決并發寫入的原子性問題,因此僅適用于單寫多讀或狀態標記的場景。
面試關鍵點:volatile 不保證原子性導致的寫覆蓋問題;緩存一致性協議(MESI)的作用;內存屏障在刷新主內存和失效緩存中的作用;volatile 可見性的實現細節。
記憶法:可通過“volatile 雙寫值不定,原子操作它不行;更新變量發信號,緩存失效 others 清;主存刷新靠屏障,可見性保原子零”來記憶,概括核心結論和實現機制。
什么是 CAS 操作?其原理是什么?在操作系統層面如何實現?
CAS(Compare-And-Swap,比較并交換)是一種無鎖同步機制,通過原子操作實現多線程環境下的變量更新,無需使用鎖,能減少線程阻塞帶來的開銷。
CAS 的定義:CAS 操作包含三個操作數——內存地址(V)、預期值(A)和新值(B)。操作邏輯是:若內存地址 V 中的值等于預期值 A,則將該值更新為 B;否則不做任何操作。整個過程是原子性的,不會被其他線程中斷,最終返回操作是否成功(或內存中的實際值)。
核心原理:CAS 基于樂觀鎖思想,假設并發操作不會頻繁沖突,因此不預先加鎖,而是通過原子操作直接嘗試更新,若失敗則重試(自旋),直到成功或放棄。這種方式避免了鎖競爭導致的線程阻塞,適合競爭不激烈的場景。
Java 中通過?sun.misc.Unsafe?類的 native 方法實現 CAS,如?compareAndSwapInt(Object o, long offset, int expected, int x),其中:
o?是目標對象,offset?是變量在對象內存中的偏移量(確定 V 的位置)。expected?是預期值(A),x?是新值(B)。
示例(模擬 CAS 自增):
public class CASDemo {private static final Unsafe unsafe = Unsafe.getUnsafe();private static final long valueOffset;private volatile int value;static {try {valueOffset = unsafe.objectFieldOffset(CASDemo.class.getDeclaredField("value"));} catch (Exception e) {throw new Error(e);}}public int incrementAndGet() {int current;do {current = value; // 讀取當前值(A)} while (!unsafe.compareAndSwapInt(this, valueOffset, current, current + 1)); // CAS 嘗試更新return current + 1;}
}
上述代碼中,incrementAndGet?方法通過循環 CAS 實現原子自增:讀取當前值,若 CAS 失敗(說明值被其他線程修改),則重新讀取并重試,直到成功。
操作系統層面的實現:
CAS 的原子性依賴底層 CPU 指令支持,不同架構的 CPU 提供了對應的原子操作指令:
- x86 架構:通過?
cmpxchg(Compare and Exchange)指令實現,該指令在執行時會鎖定總線(或緩存行),確保操作原子性。若內存中的值與預期值一致,則將新值寫入;否則將內存中的實際值返回,不修改。 - ARM 架構:通過?
ldrex(Load Exclusive)和?strex(Store Exclusive)指令組合實現。ldrex?加載值并標記排他訪問,strex?僅當排他標記未被其他線程修改時才寫入新值,確保原子性。
這些 CPU 指令是原子的,不會被中斷,因此 CAS 操作在操作系統層面通過硬件保證了多線程環境下的原子性,無需依賴軟件鎖。
但 CAS 存在“ABA 問題”(變量從 A 變為 B 再變回 A,CAS 誤認為未修改),可通過版本號機制(如 AtomicStampedReference)解決;此外,長期自旋可能浪費 CPU 資源,適合短期操作。
面試關鍵點:CAS 的三要素(V、A、B)及操作邏輯;樂觀鎖思想與自旋機制;Java 中 Unsafe 類的作用;CPU 指令(如 cmpxchg)的底層支持;ABA 問題及解決方式。
記憶法:可通過“CAS 比較再交換,V、A、B 三要素;內存值等預期值,更新新值原子做;底層依賴 CPU 令,無鎖自旋效率高;ABA 問題版本解,樂觀并發場景適”來記憶,概括核心原理和實現。
CAS 操作會自旋嗎?如果自旋,就一定會成功嗎?CAS 存在什么問題?如何解決 ABA 問題?
CAS 操作本身不會自旋,自旋是基于 CAS 實現的同步邏輯中常見的重試策略。CAS 是單次原子操作(比較并交換),而自旋指的是當 CAS 操作失敗時,線程通過循環不斷重試 CAS 直到成功或放棄,典型如原子類(AtomicInteger)的?incrementAndGet?方法:
public final int incrementAndGet() {int current;do {current = get(); // 讀取當前值} while (!compareAndSet(current, current + 1)); // 自旋重試 CASreturn current + 1;
}
這里的?do-while?循環就是自旋,目的是在 CAS 失敗(值被其他線程修改)時重新嘗試,直到成功。
自旋不一定會成功。若多個線程高頻競爭同一變量,可能導致某個線程的自旋長期失敗(始終被其他線程搶先修改),極端情況下甚至一直無法成功,造成 CPU 資源浪費。因此,自旋通常會設置重試次數上限(如 JUC 中的自適應自旋),避免無限循環。
CAS 存在以下問題:
- ABA 問題:變量的值從 A 被修改為 B,再改回 A,CAS 會誤認為值未變化而成功更新,可能導致邏輯錯誤。例如,鏈表節點被刪除后重新插入,CAS 操作可能誤判節點狀態。
- 自旋開銷:高并發下,自旋重試會占用大量 CPU 資源,降低系統性能。
- 只能保證單個變量的原子性:CAS 僅能對單個變量執行原子操作,無法直接保證多個變量的復合操作(如?
i++ && j--)的原子性。
解決 ABA 問題的核心是引入版本號機制,通過記錄變量的修改次數,避免僅通過值判斷狀態。Java 中?AtomicStampedReference?類就是典型實現,它將變量值與版本號綁定,CAS 操作時同時檢查值和版本號:
// 初始化:值為100,版本號為1
AtomicStampedReference<Integer> asr = new AtomicStampedReference<>(100, 1);// 嘗試更新:預期值100,新值200;預期版本1,新版本2
boolean success = asr.compareAndSet(100, 200, 1, 2);
只有當變量當前值為 100 且版本號為 1 時,才會更新為 200 并將版本號改為 2。即使值從 100→200→100,版本號也會從 1→2→3,CAS 會因版本號不匹配而失敗,解決 ABA 問題。
面試關鍵點:CAS 與自旋的關系(自旋是基于 CAS 的重試策略);自旋的不確定性;CAS 的三大問題(ABA、自旋開銷、單變量限制);ABA 問題的版本號解決思路及?AtomicStampedReference?的使用。
記憶法:可通過“CAS 本身不自旋,自旋是重試;自旋未必成,高并發耗 CPU;ABA 問題值反復,版本號來防護;單變量原子限,復合操作需其他”來記憶,概括核心問題及解決方式。
CAS 和 Lock 的性能消耗相比,哪個更好?
CAS 和 Lock 的性能消耗無法絕對比較,需結合并發場景(競爭程度、操作耗時)判斷,兩者各有優勢場景:
低并發、短操作場景下,CAS 性能更優。CAS 是無鎖機制,基于 CPU 原子指令實現,無需線程阻塞/喚醒(用戶態操作),開銷主要來自自旋重試。當并發程度低、線程沖突少(如偶爾有線程修改共享變量),CAS 的自旋次數少,甚至一次成功,避免了 Lock 的鎖競爭、線程切換(內核態操作)開銷。例如,單線程或少量線程更新計數器時,AtomicInteger(基于 CAS)的性能遠高于?ReentrantLock?保護的普通變量。
高并發、長操作場景下,Lock 性能更優。當并發激烈(大量線程競爭同一資源)或操作耗時較長(如復雜計算、IO 操作),CAS 的自旋會成為負擔:線程不斷重試 CAS 卻頻繁失敗,導致 CPU 空轉(自旋本質是“忙等”),浪費資源。而 Lock(如?ReentrantLock)在競爭失敗時會將線程阻塞(通過?LockSupport.park()),釋放 CPU 資源給其他線程,減少無效消耗。例如,大量線程并發寫入數據庫時,使用 Lock 控制并發比 CAS 自旋更高效。
具體差異可從底層開銷分析:
- CAS 開銷:主要是 CPU 自旋(循環執行 CAS 指令),無內核態切換,但高并發下自旋次數激增,CPU 利用率飆升。
- Lock 開銷:包含鎖競爭(CAS 嘗試獲取鎖)、線程阻塞/喚醒(內核態操作,開銷較大),但競爭激烈時可避免 CPU 空轉,資源利用率更合理。
此外,操作耗時影響選擇:短操作(如變量自增)適合 CAS,自旋成本低;長操作(如批量數據處理)適合 Lock,避免長時間自旋浪費 CPU。
示例場景對比:
- 計數器更新(短操作,低并發):CAS 性能 > Lock,因自旋少,無阻塞開銷。
- 訂單創建(長操作,高并發):Lock 性能 > CAS,因避免大量線程自旋,減少 CPU 浪費。
面試關鍵點:CAS 與 Lock 性能的場景依賴性;低并發短操作 CAS 更優的原因(無阻塞);高并發長操作 Lock 更優的原因(減少自旋);底層開銷差異(用戶態自旋 vs 內核態切換)。
記憶法:可通過“低并發短操作,CAS 無鎖更輕快;高并發長操作,Lock 阻塞省資源;場景決定優劣勢,競爭耗時是關鍵”來記憶,概括性能對比的核心邏輯。
JUC 的底層實現原理是什么?(可從 Unsafe 類、LockSupport、原子類、AQS 逐步說明)
JUC(java.util.concurrent)是 Java 并發編程的核心工具包,其底層依賴多個核心組件協同工作,從基礎到上層依次為 Unsafe 類、LockSupport、原子類和 AQS,構成了并發工具的實現基礎:
Unsafe 類:JUC 的“底層引擎”,提供直接操作內存和線程的 native 方法,是實現 CAS、線程掛起/喚醒等功能的基礎。它通過內存偏移量直接訪問對象字段(繞過 JVM 安全檢查),主要功能包括:
- CAS 操作:如?
compareAndSwapInt,為原子類和 AQS 提供原子更新能力。 - 線程操作:
park()?和?unpark()?方法,用于線程的掛起和喚醒(被 LockSupport 封裝)。 - 內存操作:直接分配/釋放內存(如?
allocateMemory)、獲取對象字段偏移量(如?objectFieldOffset),為定位變量內存地址提供支持。
Unsafe 類是 JUC 實現無鎖同步和高效線程控制的核心依賴。
- CAS 操作:如?
LockSupport:線程阻塞/喚醒的工具類,封裝了 Unsafe 的?
park()?和?unpark()?方法,提供更安全的線程控制。與?Thread.suspend()/resume()?相比,它避免了線程懸掛(suspend 可能導致鎖資源泄露),支持中斷響應和超時控制。JUC 中的鎖(如 ReentrantLock)和同步器在競爭失敗時,通過 LockSupport.park() 掛起線程,獲取資源后通過 LockSupport.unpark(thread) 喚醒,是線程等待/通知機制的底層實現。原子類:如 AtomicInteger、AtomicReference 等,基于 Unsafe 的 CAS 操作實現線程安全的原子更新。它們通過自旋 CAS 機制(循環重試 CAS 直到成功)保證變量的原子修改,無需加鎖,適用于簡單同步場景。例如,AtomicInteger 的?
incrementAndGet()?方法通過 CAS 實現原子自增,底層調用 Unsafe 的?compareAndSwapInt。AQS(AbstractQueuedSynchronizer):JUC 同步工具的“框架基石”,定義了基于狀態變量(state)和雙向隊列(CLH 隊列)的同步模板。其核心思想是:
- 用 volatile 變量?
state?表示同步狀態(如鎖的持有計數)。 - 用雙向隊列存儲競爭失敗的線程,實現線程排隊等待。
- 提供模板方法(如?
acquire()、release()),子類通過實現?tryAcquire()、tryRelease()?等方法定制同步邏輯。
JUC 中的 ReentrantLock、CountDownLatch、Semaphore 等均基于 AQS 實現: - ReentrantLock:
state?表示鎖的重入次數,tryAcquire()?實現鎖的獲取邏輯。 - CountDownLatch:
state?表示計數器值,tryReleaseShared()?實現計數器遞減。
- 用 volatile 變量?
這些組件的協作關系:AQS 依賴 Unsafe 操作?state?和隊列節點,通過 LockSupport 掛起/喚醒隊列中的線程;原子類直接使用 Unsafe 的 CAS 操作;LockSupport 封裝 Unsafe 的線程操作。這種分層設計使 JUC 工具兼具高效性和靈活性。
面試關鍵點:Unsafe 的核心功能(CAS、線程操作);LockSupport 的線程控制作用;原子類的 CAS 實現;AQS 的狀態變量和隊列機制;各組件的協作關系。
記憶法:可通過“JUC 底層四件套,Unsafe 引擎最關鍵;LockSupport 管掛醒,原子類靠 CAS 轉;AQS 框架定模板,狀態隊列承上邊”來記憶,概括核心組件及作用。
AQS(AbstractQueuedSynchronizer)的底層實現原理是什么?AQS 是否可以實現非公平鎖?
AQS(AbstractQueuedSynchronizer)是 JUC 中同步工具的基礎框架,底層通過“狀態變量 + 雙向同步隊列”實現線程同步,核心是對共享資源的競爭與等待機制。
底層實現原理:
核心狀態變量(state):AQS 用 volatile 修飾的?
state?變量表示共享資源的同步狀態(如鎖的持有次數、計數器值),確保多線程間的可見性。線程通過 CAS 操作修改?state?競爭資源,如獲取鎖時?state?從 0→1(非重入)或遞增(重入),釋放鎖時遞減或重置。雙向同步隊列(CLH 隊列):當線程競爭資源失敗(CAS 修改?
state?失敗),會被包裝為 Node 節點加入隊列尾部,進入等待狀態。隊列采用雙向鏈表結構,每個 Node 包含:- 線程引用(thread):等待資源的線程。
- 等待狀態(waitStatus):如 CANCELLED(已取消)、SIGNAL(需喚醒后繼節點)。
- 前驅節點(prev)和后繼節點(next):維護隊列結構。
隊列頭部(head)是已獲取資源的線程節點,其他節點等待被喚醒。
模板方法設計:AQS 定義了獲取/釋放資源的模板方法(如?
acquire()、release()),封裝了隊列管理邏輯,子類只需實現?tryAcquire(int arg)(獨占式獲取)、tryRelease(int arg)(獨占式釋放)等抽象方法,定制資源競爭規則。線程等待/喚醒:競爭失敗的線程通過?
LockSupport.park()?掛起,進入阻塞狀態;持有資源的線程釋放資源時,通過?LockSupport.unpark()?喚醒隊列中的后繼線程,使其重新競爭資源。
AQS 可以實現非公平鎖,且多數基于 AQS 的同步工具(如 ReentrantLock 默認模式)都實現了非公平鎖。非公平鎖的核心是“搶鎖”機制:線程獲取資源時,不遵守隊列順序,直接嘗試 CAS 修改?state,成功則獲取資源;失敗才加入隊列等待。
以 ReentrantLock 的非公平鎖實現為例:
tryAcquire()?方法首先嘗試 CAS 修改?state(不檢查隊列),若當前線程是鎖的持有者則重入(state?遞增)。- 只有 CAS 失敗且當前線程不是持有者時,才會加入隊列。
這種設計允許新線程“插隊”獲取資源,可能導致隊列中的線程饑餓,但減少了線程切換開銷,性能通常高于公平鎖。
公平鎖則在?tryAcquire()?中檢查隊列是否有前驅節點,若有則放棄競爭,直接入隊,嚴格按順序獲取資源,保證公平性但犧牲部分性能。
面試關鍵點:AQS 的核心組成(state 變量、CLH 隊列);模板方法與子類實現的分工;非公平鎖的“搶鎖”邏輯;ReentrantLock 中非公平鎖的實現方式。
記憶法:可通過“AQS 狀態加隊列,線程競爭靠 CAS;獲取釋放模板定,子類實現 try 方法;非公平鎖可實現,搶鎖優先于隊列;公平則按順序來,性能公平難兩全”來記憶,概括底層原理和非公平鎖實現。
什么是線程池?創建一個線程池需要哪些參數?各參數的作用是什么?
線程池是管理線程生命周期的容器,通過重用已創建的線程減少頻繁創建/銷毀線程的開銷(線程創建需分配棧內存、內核資源,銷毀需回收資源),提高系統響應速度和資源利用率,是 Java 并發編程中控制并發量的核心工具。
創建線程池的核心類是?ThreadPoolExecutor,其構造函數定義了 7 個核心參數,各參數決定了線程池的行為特性:
corePoolSize(核心線程數):線程池長期維持的最小線程數,即使線程空閑也不會被銷毀(除非設置?
allowCoreThreadTimeOut?為 true)。當新任務提交時,若當前線程數小于 corePoolSize,線程池會創建新線程執行任務;若達到 corePoolSize,則將任務放入隊列。maximumPoolSize(最大線程數):線程池允許創建的最大線程數,用于應對任務高峰期。當任務隊列滿且當前線程數小于 maximumPoolSize 時,線程池會創建新線程(非核心線程)執行任務;若達到 maximumPoolSize,觸發拒絕策略。
keepAliveTime(空閑線程存活時間):非核心線程的空閑超時時間。當非核心線程空閑時間超過該值,會被銷毀以釋放資源;若?
allowCoreThreadTimeOut?為 true,核心線程也會遵守該超時時間。unit(時間單位):keepAliveTime 的時間單位,如?
TimeUnit.SECONDS(秒)、TimeUnit.MILLISECONDS(毫秒)等。workQueue(任務隊列):用于存放待執行任務的阻塞隊列,當核心線程都在工作時,新任務會進入隊列等待。常用隊列類型:
ArrayBlockingQueue:有界數組隊列,需指定容量,防止任務無限堆積。LinkedBlockingQueue:無界鏈表隊列(默認容量 Integer.MAX_VALUE),可能導致內存溢出。SynchronousQueue:直接傳遞隊列,不存儲任務,需立即有線程接收,適合任務處理快的場景。
threadFactory(線程工廠):用于創建線程的工廠,可定制線程名稱、優先級、是否為守護線程等。默認使用?
Executors.defaultThreadFactory(),創建的線程屬于同一線程組,優先級為正常。handler(拒絕策略):當任務隊列滿且線程數達到 maximumPoolSize 時,對新提交任務的處理策略。JDK 提供 4 種默認策略:
AbortPolicy:直接拋出?RejectedExecutionException(默認策略)。CallerRunsPolicy:讓提交任務的線程自己執行任務,減緩提交速度。DiscardPolicy:默默丟棄新任務,不拋出異常。DiscardOldestPolicy:丟棄隊列中最舊的任務,嘗試提交新任務。
示例(創建自定義線程池):
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, // corePoolSize:5個核心線程10, // maximumPoolSize:最多10個線程60, // keepAliveTime:空閑線程存活60秒TimeUnit.SECONDS, // 時間單位:秒new ArrayBlockingQueue<>(20), // 任務隊列:容量20的有界隊列Executors.defaultThreadFactory(), // 線程工廠:默認new ThreadPoolExecutor.CallerRunsPolicy() // 拒絕策略:調用者執行
);
這些參數共同決定了線程池的負載能力和資源控制策略,合理配置可避免線程耗盡或內存溢出,是面試中的高頻考點。
面試關鍵點:線程池的作用(重用線程、控制并發);7個核心參數的含義及相互關系;任務隊列和拒絕策略的類型及適用場景;參數配置對線程池行為的影響。
記憶法:可通過“核心線程常駐留,最大線程限峰值;空閑超時非核心,隊列存任務;工廠造線程,拒絕策略滿時用;七參定池性,合理配置是關鍵”來記憶,概括參數作用和線程池特性。
當有任務提交時,線程池的運行原理是什么?為什么線程池會先將任務加入隊列,再創建最大線程數的線程?
當有任務提交到線程池時,其運行原理遵循一套優先級明確的處理流程,核心是通過“核心線程→任務隊列→非核心線程→拒絕策略”的順序高效分配資源,具體如下:
檢查核心線程:當任務提交時,線程池首先判斷當前運行的線程數是否小于 corePoolSize(核心線程數)。若小于,直接創建新的核心線程執行任務(核心線程創建后長期駐留,除非設置 allowCoreThreadTimeOut 為 true);若已達到 corePoolSize,則進入下一步。
嘗試加入任務隊列:線程池檢查任務隊列(workQueue)是否未滿。若未滿,將任務放入隊列等待執行(由已有的核心線程或后續空閑線程處理);若隊列已滿,則進入下一步。
檢查最大線程數:判斷當前線程數是否小于 maximumPoolSize(最大線程數)。若小于,創建非核心線程執行任務(非核心線程空閑時會被回收);若已達到 maximumPoolSize,則觸發拒絕策略(由 handler 處理)。
這種流程設計的核心原因是“優先利用現有資源,減少線程創建開銷”。線程的創建和銷毀需要消耗系統資源(如分配棧內存、內核態與用戶態切換),頻繁創建線程會顯著降低性能。任務隊列的作用是緩沖任務,讓核心線程充分利用(核心線程常駐,無需頻繁銷毀),只有當隊列滿了(說明核心線程已飽和),才會創建非核心線程應對峰值,避免不必要的線程資源浪費。
例如,核心線程數為4、隊列容量為20、最大線程數為8的線程池:當提交第5個任務時,核心線程已滿,任務進入隊列;提交第25個任務時,隊列已滿,此時創建第5個線程(非核心);直到線程數達到8,第29個任務會觸發拒絕策略。
若反過來“先創建最大線程數再入隊”,會導致輕微任務增長就創建大量線程,不僅浪費資源,還可能因線程過多導致上下文切換頻繁,降低系統吞吐量。因此,“先入隊再擴容”是平衡資源利用率和性能的最優設計。
面試關鍵點:線程池處理任務的四步流程(核心線程→隊列→非核心線程→拒絕策略);隊列的緩沖作用;優先入隊的原因(減少線程創建開銷,提高資源利用率)。
記憶法:可通過“任務提交先看核心線,不滿直接來處理;核心滿了入隊列,隊列滿了擴線程;擴到最大還滿了,拒絕策略來兜底;先入隊再擴線程,減少開銷效率高”來記憶,概括運行原理和設計邏輯。
若線程池參數設置為 corePoolSize=4、maxPoolSize=8,什么情況下會從 4 個線程擴容到 8 個線程?
當線程池參數為 corePoolSize=4、maxPoolSize=8 時,線程數從4擴容到8的觸發條件是“核心線程全忙碌 + 任務隊列已滿 + 新任務持續提交”,具體過程如下:
初始狀態:線程池啟動后,若有任務提交,會先創建核心線程,直到達到 corePoolSize=4。此時4個核心線程處理任務,新提交的任務會進入線程池的任務隊列等待(假設隊列有界,如容量為N)。
核心線程飽和:當4個核心線程都在處理任務(無空閑),且新提交的任務不斷進入隊列,直到隊列被填滿(達到容量N)。此時隊列無法再接收新任務,線程池進入“擴容準備”狀態。
觸發擴容:當隊列已滿后,若有新任務繼續提交,線程池會判斷當前線程數(4)是否小于 maxPoolSize(8)。由于4 < 8,線程池會創建新的非核心線程處理新任務,每次提交新任務可能觸發一次擴容,直到線程數達到8。
擴容上限:當線程數達到8(maxPoolSize),若仍有新任務提交,隊列已滿且無法再創建線程,線程池會執行拒絕策略(如拋出異常、丟棄任務等)。
舉例說明:假設任務隊列容量為10,核心線程4個均忙碌。當第5-14個任務提交時,會進入隊列(共10個任務);第15個任務提交時,隊列已滿,線程池創建第5個線程;第16個任務創建第6個線程……直到第18個任務提交時,線程數達到8,之后的任務觸發拒絕策略。
需注意,若任務隊列是無界隊列(如 LinkedBlockingQueue 默認容量為 Integer.MAX_VALUE),則隊列永遠不會滿,線程數不會超過 corePoolSize=4,不會觸發擴容(這也是不建議使用無界隊列的原因之一,可能導致內存溢出)。只有使用有界隊列且隊列滿時,才可能觸發從核心線程數到最大線程數的擴容。
面試關鍵點:擴容的三大條件(核心線程滿、隊列滿、新任務提交);有界隊列的重要性(無界隊列無法觸發擴容);擴容的上限是 maxPoolSize。
記憶法:可通過“核心滿,隊列滿,新任務來要擴容;core4到max8,條件缺一都不行;無界隊列不擴容,有界滿了才加線”來記憶,概括擴容的觸發條件和限制。
線程池中是如何根據 keepAliveTime 來回收線程的?
線程池通過 keepAliveTime 回收線程的機制,主要針對非核心線程(默認),核心線程需特殊配置才會被回收,其底層通過監控線程空閑時間并主動中斷實現,具體過程如下:
回收對象:默認情況下,keepAliveTime 僅作用于非核心線程(即線程數超過 corePoolSize 的部分)。核心線程會長期駐留,即使空閑也不會被回收,以快速響應新任務。若需回收核心線程,需調用?
allowCoreThreadTimeOut(true)?方法,此時核心線程也會遵守 keepAliveTime 規則。空閑時間監控:線程池中的工作線程在執行完任務后,會進入循環獲取隊列中任務的狀態。若隊列中沒有任務,線程會進入空閑狀態,此時開始計時。當空閑時間達到 keepAliveTime 時,線程會判斷是否需要被回收:
- 若當前線程數 > corePoolSize(非核心線程):直接退出線程,被系統回收。
- 若當前線程數 ≤ corePoolSize 且未設置 allowCoreThreadTimeOut:繼續等待任務,不回收。
- 若當前線程數 ≤ corePoolSize 且設置了 allowCoreThreadTimeOut:退出線程,被回收。
回收實現:線程池通過?
ThreadPoolExecutor.Worker?類管理工作線程,Worker 是一個內部類,實現了 Runnable 接口。Worker 線程的 run 方法會循環調用?getTask()?方法從隊列獲取任務:getTask()?方法在隊列無任務時,會調用?LockSupport.parkNanos(keepAliveTime)?使線程阻塞指定時間。- 若阻塞時間內仍無任務,
getTask()?返回 null,Worker 線程退出循環,run 方法結束,線程被回收。
示例邏輯(簡化的 getTask() 核心代碼):
private Runnable getTask() {boolean timedOut = false;while (true) {int c = ctl.get();// 檢查是否需要回收線程if (runStateAtLeast(c, SHUTDOWN) && (runStateAtLeast(c, STOP) || workQueue.isEmpty())) {decrementWorkerCount();return null;}int wc = workerCountOf(c);// 判斷是否需要超時等待(非核心線程或允許核心線程超時)boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;// 若超時且符合回收條件,返回null觸發線程回收if ((wc > maximumPoolSize || (timed && timedOut)) && (wc > 1 || workQueue.isEmpty())) {if (compareAndDecrementWorkerCount(c))return null;continue;}try {// 阻塞等待任務,超時返回nullRunnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take();if (r != null)return r;timedOut = true; // 標記超時} catch (InterruptedException retry) {timedOut = false;}}
}
這種機制確保線程池在任務量減少時自動釋放多余資源,避免空閑線程占用內存和CPU,平衡了資源利用率和響應速度。
面試關鍵點:keepAliveTime 對非核心線程的默認作用;核心線程回收的條件(allowCoreThreadTimeOut=true);getTask()?方法的超時等待與線程退出邏輯;回收的底層實現(Worker 線程循環與阻塞)。
記憶法:可通過“keepAlive 管空閑,默認只收非核心;核心要收需配置,allowCoreTimeout 真;線程空閑超時后,getTask 返回 null,Worker 退出被回收”來記憶,概括回收機制和條件。
線程池的拒絕策略有哪些?哪種拒絕策略不會導致任務丟失?(例如 callerRunsPolicy)
線程池的拒絕策略是當任務隊列滿且線程數達到 maximumPoolSize 時,對新提交任務的處理機制。JDK 內置了4種拒絕策略,每種策略的行為和適用場景不同,具體如下:
AbortPolicy(默認策略):直接拋出?
RejectedExecutionException?異常,中斷任務提交流程。這種策略的優點是快速反饋錯誤,讓開發者及時感知系統過載;缺點是會導致當前任務丟失,適用于不允許任務丟失且需立即處理錯誤的場景(如金融交易)。CallerRunsPolicy:讓提交任務的線程(調用者線程)親自執行該任務。例如,主線程提交任務被拒絕時,主線程會暫停當前工作,執行被拒絕的任務,執行完成后再繼續。這種策略的優點是不會丟失任務,且通過減慢調用者的提交速度(調用者忙于執行任務),間接降低任務提交頻率,給線程池緩沖時間;缺點是可能阻塞調用者線程,影響其他任務提交,適用于任務量不大、需保證任務不丟失的場景(如日志記錄)。
DiscardPolicy:默默丟棄被拒絕的任務,不拋出任何異常,也不執行該任務。優點是不會中斷系統運行;缺點是任務丟失且無任何提示,適用于任務可丟失、對系統穩定性要求高的場景(如非核心統計數據)。
DiscardOldestPolicy:丟棄任務隊列中最舊的任務(即將被執行的任務),然后嘗試提交當前被拒絕的任務。這種策略會丟失舊任務,但可能讓新任務有機會執行,適用于舊任務時效性差、新任務更重要的場景(如實時數據處理)。
在這四種策略中,CallerRunsPolicy 是唯一不會導致任務丟失的策略,因為被拒絕的任務會由提交者線程執行,確保任務被處理。其他策略均會導致任務丟失(AbortPolicy 丟失當前任務,DiscardPolicy 丟失當前任務,DiscardOldestPolicy 丟失舊任務)。
實際開發中,也可通過實現?RejectedExecutionHandler?接口自定義拒絕策略,例如將任務持久化到數據庫或消息隊列,待線程池空閑后重試,進一步保證任務不丟失。
面試關鍵點:4種內置拒絕策略的行為差異;CallerRunsPolicy 不丟失任務的原因;各策略的適用場景;自定義拒絕策略的可能性。
記憶法:可通過“Abort 拋異常,Caller 自己跑,Discard 悄悄丟,Oldest 丟最老;唯有 Caller 不丟任務,其他策略皆丟失”來記憶,概括各策略特點和任務丟失情況。
線程池拒絕策略的代碼是由哪個線程執行的?
線程池拒絕策略的代碼由提交任務的線程執行。當線程池無法處理新提交的任務(隊列滿且線程數達到 maximumPoolSize),會觸發拒絕策略,此時執行拒絕策略中?rejectedExecution(Runnable r, ThreadPoolExecutor executor)?方法的線程,正是調用?execute()?或?submit()?方法提交任務的線程。
這一機制的底層邏輯是:任務提交過程是同步的,提交線程會主動檢查線程池狀態和資源,若符合拒絕條件,則直接在當前線程中執行拒絕策略代碼。具體流程如下:
- 提交線程調用?
executor.execute(task)?提交任務。 - 線程池內部檢查:核心線程是否滿→隊列是否滿→是否可擴容至最大線程數。
- 若所有條件均不滿足(觸發拒絕),線程池調用拒絕策略的?
rejectedExecution?方法。 - 由于整個提交過程未涉及線程切換,
rejectedExecution?方法由提交任務的線程直接執行。
示例驗證:
public class RejectedThreadDemo {public static void main(String[] args) {// 創建核心線程1、最大線程1、隊列容量1的線程池ThreadPoolExecutor executor = new ThreadPoolExecutor(1, 1, 0, TimeUnit.SECONDS,new ArrayBlockingQueue<>(1),new ThreadPoolExecutor.AbortPolicy());// 提交3個任務(必然觸發拒絕)executor.execute(() -> { try { Thread.sleep(1000); } catch (InterruptedException e) {} });executor.execute(() -> { try { Thread.sleep(1000); } catch (InterruptedException e) {} });// 第三個任務會被拒絕,打印執行拒絕策略的線程try {executor.execute(() -> System.out.println("任務3"));} catch (RejectedExecutionException e) {System.out.println("拒絕策略執行線程:" + Thread.currentThread().getName()); // 輸出:拒絕策略執行線程:main(即提交任務的主線程)}executor.shutdown();}
}
上述代碼中,主線程提交第三個任務時觸發拒絕策略,RejectedExecutionException?由主線程拋出,證明拒絕策略代碼在主線程中執行。
這一設計的原因是:拒絕策略需要即時反饋任務提交結果,由提交線程執行可避免額外的線程調度開銷,且符合“誰提交誰處理”的直觀邏輯。若由線程池內部線程執行,可能導致延遲或線程池狀態不一致。
面試關鍵點:拒絕策略由提交任務的線程執行;同步提交過程導致的線程關聯;示例驗證的核心邏輯。
記憶法:可通過“誰提交任務,誰執行拒絕;同步調用無切換,提交線程擔職責”來記憶,概括執行拒絕策略的線程來源。
若將線程池的任務隊列設置為無界隊列,會對服務產生什么影響?
將線程池的任務隊列設置為無界隊列(如?LinkedBlockingQueue?未指定容量,默認容量為?Integer.MAX_VALUE),會對服務產生多方面影響,主要體現在資源占用、線程池行為和系統穩定性上:
線程數永遠不會超過核心線程數:無界隊列可無限接收任務,因此當核心線程(corePoolSize)都在忙碌時,新任務會持續進入隊列,不會觸發“隊列滿后創建非核心線程”的邏輯。這意味著線程池中的線程數始終維持在 corePoolSize,maximumPoolSize 參數失去意義,無法通過擴容應對任務峰值。例如,corePoolSize=5、maxPoolSize=20的線程池,若使用無界隊列,即使提交1000個任務,線程數也只會保持5個,無法利用更多線程加速處理。
任務堆積可能導致內存溢出(OOM):無界隊列會無限制存儲任務,若任務提交速度遠快于處理速度,隊列中的任務會持續增長,占用大量堆內存。當內存耗盡時,會拋出?
OutOfMemoryError,導致服務崩潰。例如,每個任務占用1KB內存,1000萬個任務就會占用約10GB內存,遠超普通應用的內存上限。系統響應延遲加劇:隊列中堆積的任務需要等待核心線程處理,任務越多,等待時間越長,系統響應速度變慢。極端情況下,新提交的任務可能需要等待數小時甚至更久才能被執行,違背實時性要求。
拒絕策略失效:由于隊列永遠不會滿,線程池的拒絕策略(如?
AbortPolicy)永遠不會觸發,無法通過拒絕機制保護系統。即使任務已經積壓到危險程度,線程池仍會接收新任務,加速系統資源耗盡。排查問題難度增加:任務堆積時,線程池沒有明顯的錯誤提示(如拒絕異常),問題可能被掩蓋,直到內存溢出才暴露,增加了故障排查的復雜度。
無界隊列僅適用于“任務提交速度遠低于處理速度,且任務總量可控”的場景(如低頻率后臺任務),但絕大多數生產環境(尤其是高并發服務)應避免使用,建議采用有界隊列(如?ArrayBlockingQueue)并合理設置容量,結合拒絕策略和監控機制,確保系統穩定性。
面試關鍵點:無界隊列對線程數的限制(不超過核心線程);內存溢出風險;響應延遲和拒絕策略失效的后果;適用場景的局限性。
記憶法:可通過“無界隊列無限裝,線程不超核心量;任務堆積耗內存,OOM風險高;響應延遲拒策略廢,生產環境慎用它”來記憶,概括核心影響。
)
打開工程文件的幾種方法)
:2.點燈與ubuntu安裝)


》)













