目錄
Transform的由來
Seq2seq 模型
Transform 的內部結構
語言模型
BERT 介紹
BERT 模型的組成
分詞器
位置編碼
Softmax
殘差結構
BERT 模型總結
Transform的由來
傳統的語?模型,?如RNN(循環神經?絡),就像?個“短視”的學?。它在讀?篇?章時,只能逐字逐句地讀,并且每次只能記住前?個詞的信息。當句?很?時,它就會“忘記” 前?讀過的內容,導致對整句話的理解不完整。
Transformer 的出現,就像給這個學?配上了“全局視野”。它最?的創新是引?了?注意?機制(Self-Attention Mechanism)。簡單來說,?注意?機制讓模型在處理?個詞時,能夠 同時關注到句?中的所有其他詞,并根據它們之間的關系來確定每個詞的重要性
RNN(或者LSTM、GRU等)的計算限制為是順序的,也就是RNN相關算法只能從左向右或從右向左依次計算:
- 時間片t的計算依賴于t-1時刻的計算結果,限制了模型的并行能力;
- 盡管LSTM等門機制的結構緩解了長期依賴的問題,但順序計算的過程中信息會丟失,
Transformer的提出解決了上面兩個問題,它使用了 Attention機制,將序列中的任意兩個位置之間的距離縮小為一個常量;其次他不是類似于RNN的順序結構,因此具有更好的并行性,符合現有的GPU框架。
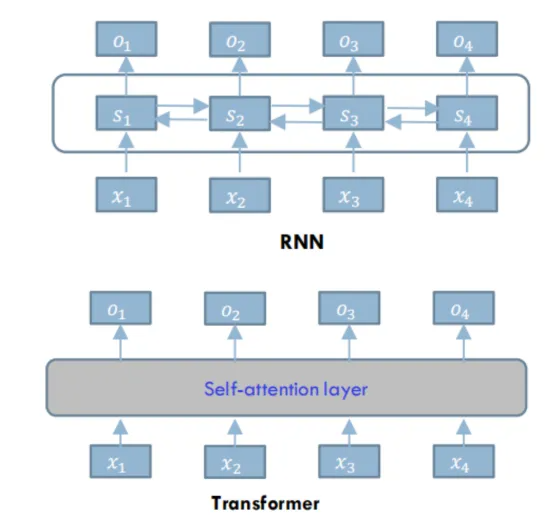
- 注意?機制(Attention Mechanism)
?類閱讀?段?字時,?腦并不是平等地處理每?個字。相反,你會根據上下?,有意識或?意識地去關注那些對理解當前信息更重要的詞語。
注意?機制的?作過程分解成三個簡單的步驟:
- 打分(Scoring): 對于句?中的每?個詞,模型都會計算它與當前正在處理的詞之間的 “相關性分數”。分數越?,代表這兩個詞越相關。
- 歸?化(Normalizing): 這些分數會被轉換成權重,通常使? Softmax 函數。這樣做的 好處是,所有權重加起來等于1,?且越重要的詞權重越?,不重要的詞權重越低,這就像 給每個詞分配了不同等級的關注度。
- 加權求和(Weighted Sum): 最后,模型會將所有詞的原始信息(也叫“值”)與它們對 應的權重相乘,然后相加。這樣得到的最終表?,就包含了所有詞的信息,但重點突出了那 些權重?的、更重要的詞。
注意?機制通過讓模型能夠“回頭看”句?中的所有詞,并給它們分配不同的權重,徹底解決了這個問題。它讓模型在處理?句?時,不再“短視”,?是擁有了“全局視野”,能更好地理解整個句?的語境和含義
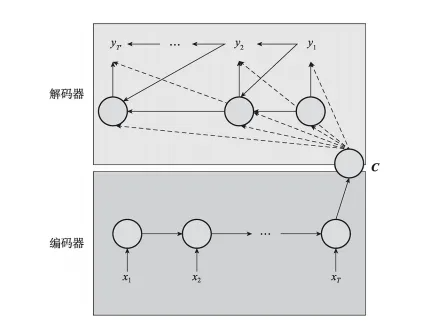
Seq2seq 模型
Seq2seq(Sequence-to-Sequence)將自然語言處理中的任務(如文本摘要、機器翻譯、對話系統等)看作從一個輸入序列到另外一個輸出序列的映射,然后通過一個端到端的神經網絡來直接學習序列的映射關系。
Seq2seq也是編碼器-解碼器結構的雛形。
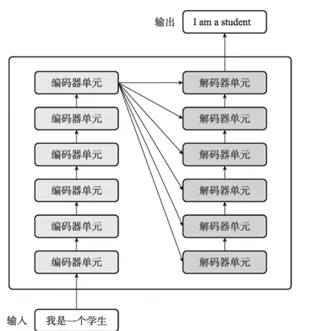
- 僅使用encoder的預訓練模型: BERT (理解文本)
- 僅使用decoder的預訓練模型: GPT (生成文本)
Transform 的內部結構
Transformer是一種基于注意力機制的編碼器-解碼器結構,具有很好的并行性能,同時利用注意力機制很好地解決了長序列的長程依賴問題
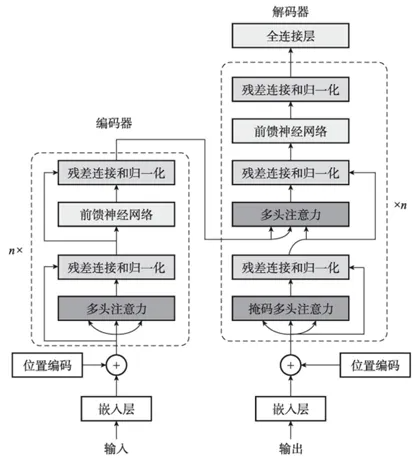
多頭注意力機制接受輸入詞嵌入與位置編碼之和,并進行多頭注意力的計算。注意力機制中的Q、K、V的來源不同。以機器翻譯為例,Q來源于目標輸出,而K和V來源于輸入信息。與之相對,自注意力機制的Q、K、V均來源于同一個X。
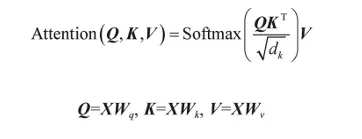
多頭注意力機制。多頭注意力機制是多個自注意力機制的組合,目的是從多個不同角度提取交互信息,其中每個角度稱為一個注意力頭,多個注意力頭可以獨立并行計算。

Transformer編碼器的輸入是詞嵌入與位置編碼之和。將輸入序列轉化成詞嵌入的方法是從一張査詢表(Lookup Table)中獲取每個詞元(Token)對應的向量表示。但如果僅使用詞嵌入作為Transformer的注意力機制的輸入,則在計算詞元之間的相關度時并未考慮它們的位置信息。原始的Tansformer采用了正余弦位置編碼。
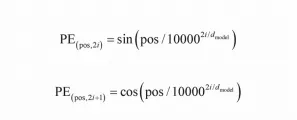
- 通過計算得出各個位置每個維度上的信息,而非通過訓練學習到
- 輸入長度不受最大長度的限制,可以計算到比訓練數據更長的位置,具有一定的外推性;
- 每個分量都是正弦或者余弦函數,并且整體的位置編碼具有遠程衰減性質,具備位置信息;
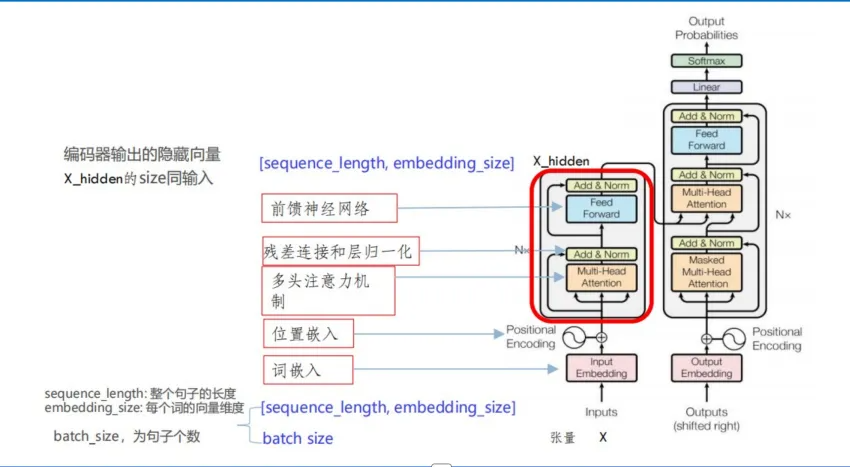
殘差連接和層歸一化
在多頭注意力機制和前饋神經網絡中都會進行相關邏輯處理
- 殘差連接的核心思想是在網絡層的輸出中直接添加該層的輸入,形成"短路"連接
- 層歸一化對每個樣本的所有特征維度進行歸一化處理,使數據的均值為0,方差為1
殘差連接其作用在于
- 緩解梯度消失 :通過直接傳遞梯度,使得深層網絡的梯度能夠更有效地回傳
- 學習恒等映射 :允許網絡層更容易學習恒等變換(identity mapping),促進模型收斂
- 增強特征表達 :保留原始輸入信息,同時引入新的特征表示
層歸一化其作用在于
- 穩定訓練 :減少內部協變量偏移(Internal Covariate Shift),使網絡訓練更穩定
- 加速收斂 :標準化的輸入分布有助于優化器更快地找到最優解
- 降低學習率敏感性 :減少對學習率選擇的依賴,提高模型魯棒性
- 支持不同長度序列 :相比批歸一化(Batch Normalization),層歸一化不依賴于批次大小,更適合處理變長序列
在transformer 中,代碼中的實現采用了"預歸一化"(Pre-Normalization)設計,即層歸一化應用在每個子層的輸出之后,而不是輸入之前。這種設計有以下優勢:
- 使殘差連接更有效,因為歸一化后的梯度更穩定
- 簡化了訓練過程,不需要精心調整學習率和初始化
- 允許構建更深的網絡架構
self.layer_norm = nn.LayerNorm(d_embedding) # 一行代碼實現殘差連接+歸一化# 將輸出與殘差連接相加,并進行層歸一化
# 殘差連接的作用是將原始輸入與計算結果相加 ---> 繞過注意力機制相關的線條
# output 的維度: [batch_size, len_q, d_embedding]
output = self.layer_norm(output + residual)
transformer 結構代碼示例
import numpy as np # 導入 numpy 庫,用于科學計算
import torch # 導入 torch 庫,用于構建神經網絡
import torch.nn as nn # 導入 torch.nn 庫,包含了各種神經網絡層# --- 全局參數 ---
d_k = 64 # Q 和 K 向量的維度
d_v = 64 # V 向量的維度
d_embedding = 128 # 詞嵌入的維度
n_heads = 8 # 多頭注意力機制中頭的數量
n_layers = 6 # 編碼器和解碼器的層數
batch_size = 3 # 訓練批次大小
epochs = 10 # 訓練輪次# --- 注意力機制模塊 ---class ScaledDotProductAttention(nn.Module):"""縮放點積注意力模塊根據 Q、K、V 計算注意力分數和上下文向量包含掩碼機制,通過 scores.masked_fill_(attn_mask.bool(), -1e9) 屏蔽填充位置或未來信息輸入:Q: 查詢向量,維度 [batch_size, n_heads, len_q, dim_q]K: 鍵向量,維度 [batch_size, n_heads, len_k, dim_k]V: 值向量,維度 [batch_size, n_heads, len_v, dim_v]attn_mask: 注意力掩碼,維度 [batch_size, n_heads, len_q, len_k]輸出:context: 上下文向量,維度 [batch_size, n_heads, len_q, dim_v]attn_weights: 注意力權重,維度 [batch_size, n_heads, len_q, len_k]輸出:點積注意力的縮放操作解決了高維空間中點積值過大導致softmax梯度消失的問題,提高了訓練穩定性縮放操作通過除以 sqrt(d_k) 來縮放點積,防止點積值過大導致 softmax 函數輸出接近于 0 或 1,從而避免梯度消失問題"""def __init__(self):super(ScaledDotProductAttention, self).__init__()def forward(self, Q, K, V, attn_mask):# Q, K, V 的維度: [batch_size, n_heads, len_q/k/v, dim_q=k/v]# attn_mask 的維度: [batch_size, n_heads, len_q, len_k]# 1. 計算注意力分數# 將 Q 與 K 的轉置相乘,并除以 sqrt(d_k) 進行縮放# scores 的維度: [batch_size, n_heads, len_q, len_k]scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)# 2. 應用注意力掩碼# 將 attn_mask 中為 True 的位置的 scores 替換為一個極小值 (-1e9)# 這樣在 softmax 之后,這些位置的權重將接近于0scores.masked_fill_(attn_mask, -1e9)# 3. 對分數進行 softmax 歸一化# 沿著最后一個維度 (len_k) 進行 softmax# weights 的維度: [batch_size, n_heads, len_q, len_k]weights = nn.Softmax(dim=-1)(scores)# 4. 計算上下文向量# 將歸一化后的權重與 V 相乘# context 的維度: [batch_size, n_heads, len_q, dim_v]context = torch.matmul(weights, V)# 返回上下文向量和注意力權重return context, weightsclass MultiHeadAttention(nn.Module):"""多頭注意力機制模塊將輸入投影到多個子空間,并并行計算注意力,最后將結果拼接"""def __init__(self):super(MultiHeadAttention, self).__init__()# 線性投影層,用于生成 Q, K, Vself.W_Q = nn.Linear(d_embedding, d_k * n_heads)self.W_K = nn.Linear(d_embedding, d_k * n_heads)self.W_V = nn.Linear(d_embedding, d_v * n_heads)# 最后的線性層,將拼接后的多頭輸出投影回原始維度self.linear = nn.Linear(n_heads * d_v, d_embedding)# 層歸一化(Layer Normalization),樣本的特征進行歸一下,使其均值為0 ,方差為1self.layer_norm = nn.LayerNorm(d_embedding)def forward(self, Q, K, V, attn_mask):# Q, K, V 的維度: [batch_size, len_q/k/v, d_embedding]residual, batch_size = Q, Q.size(0)# 1. 線性投影并重塑# 將輸入 Q, K, V 投影到多頭子空間,并調整維度以便并行計算# .view() 和 .transpose() 操作將維度變為: [batch_size, n_heads, len_q/k/v, d_q=k/v]q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1, 2)k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1, 2)v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1, 2)# 2. 復制注意力掩碼# 將 attn_mask 復制 n_heads 次,以適應多頭注意力# attn_mask 的維度: [batch_size, n_heads, len_q, len_k]# unsqueeze(1) :在第1維(索引從0開始)插入一個新的維度,將掩碼形狀變為 [batch_size, 1, len_q, len_k]# repeat(1, n_heads, 1, 1) :在新增的維度上復制 n_heads 次(其他維度保持不變),最終掩碼形狀變為 [batch_size, n_heads, len_q, len_k]attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)# 3. 計算縮放點積注意力context, weights = ScaledDotProductAttention()(q_s, k_s, v_s,attn_mask)# context 的維度: [batch_size, n_heads, len_q, dim_v]# weights 的維度: [batch_size, n_heads, len_q, len_k]# 4. 拼接多頭結果# 調整維度并使用 .contiguous() 確保內存連續,然后用 .view() 將多頭結果拼接# context 的維度: [batch_size, len_q, n_heads * dim_v]context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v)# 5. 最終線性投影和層歸一化# 將拼接后的結果通過線性層投影回 d_embedding 維度output = self.linear(context)# 將輸出與殘差連接相加,并進行層歸一化# output 的維度: [batch_size, len_q, d_embedding]output = self.layer_norm(output + residual)# 返回最終輸出和注意力權重return output, weights# --- 前饋網絡模塊 ---class PoswiseFeedForwardNet(nn.Module):"""逐位置前饋網絡模塊對序列中的每個位置獨立地應用一個全連接前饋網絡"""def __init__(self, d_ff=2048):super(PoswiseFeedForwardNet, self).__init__()# 兩個一維卷積層,相當于兩個全連接層self.conv1 = nn.Conv1d(in_channels=d_embedding, out_channels=d_ff, kernel_size=1)self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_embedding, kernel_size=1)# 層歸一化self.layer_norm = nn.LayerNorm(d_embedding)def forward(self, inputs):# inputs 的維度: [batch_size, len_q, d_embedding]residual = inputs# 1. 維度轉換并應用第一個卷積層# inputs.transpose(1, 2) 將維度變為 [batch_size, d_embedding, len_q]# 卷積操作后,output 的維度: [batch_size, d_ff, len_q]output = nn.ReLU()(self.conv1(inputs.transpose(1, 2)))# 2. 應用第二個卷積層并轉換維度# 卷積操作后,output 的維度: [batch_size, d_embedding, len_q]# .transpose(1, 2) 將維度恢復為 [batch_size, len_q, d_embedding]output = self.conv2(output).transpose(1, 2)# 3. 殘差連接和層歸一化output = self.layer_norm(output + residual)return output# --- 位置編碼和掩碼函數 ---def get_sin_enc_table(n_position, embedding_dim):"""生成正弦位置編碼表用于在序列中引入詞語的絕對位置信息"""# 初始化正弦編碼表sinusoid_table = np.zeros((n_position, embedding_dim))# 計算不同位置和維度的角度for pos_i in range(n_position):for hid_j in range(embedding_dim):angle = pos_i / np.power(10000, 2 * (hid_j // 2) / embedding_dim)sinusoid_table[pos_i, hid_j] = angle# 將偶數維應用 sin 函數,奇數維應用 cos 函數sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2])sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2])# 轉換為 PyTorch 張量return torch.FloatTensor(sinusoid_table)def get_attn_pad_mask(seq_q, seq_k):"""生成填充注意力掩碼用于在注意力計算中忽略填充 <pad> 詞語"""# seq_q 的維度: [batch_size, len_q]# seq_k 的維度: [batch_size, len_k]batch_size, len_q = seq_q.size()batch_size, len_k = seq_k.size()# 找到 seq_k 中所有值為 0 (<pad>) 的位置# pad_attn_mask 的維度: [batch_size, 1, len_k]pad_attn_mask = seq_k.data.eq(0).unsqueeze(1)# 將掩碼擴展到與注意力分數相同的形狀# pad_attn_mask 的維度: [batch_size, len_q, len_k]pad_attn_mask = pad_attn_mask.expand(batch_size, len_q, len_k)return pad_attn_maskdef get_attn_subsequent_mask(seq):"""生成后續注意力掩碼 (僅用于解碼器)用于在注意力計算中忽略當前位置之后的信息,防止信息泄露"""# seq 的維度: [batch_size, seq_len]attn_shape = [seq.size(0), seq.size(1), seq.size(1)]# 創建一個上三角矩陣,k=1 表示主對角線上方的元素為 1# subsequent_mask 的維度: [batch_size, seq_len, seq_len]subsequent_mask = np.triu(np.ones(attn_shape), k=1)# 轉換為 PyTorch 字節張量 (布爾類型)subsequent_mask = torch.from_numpy(subsequent_mask).byte()return subsequent_mask# --- 編碼器和解碼器模塊 ---class EncoderLayer(nn.Module):"""編碼器的一層包含一個多頭自注意力層和一個位置前饋網絡"""def __init__(self):super(EncoderLayer, self).__init__()self.enc_self_attn = MultiHeadAttention()self.pos_ffn = PoswiseFeedForwardNet()def forward(self, enc_inputs, enc_self_attn_mask):# enc_inputs 的維度: [batch_size, seq_len, d_embedding]# enc_self_attn_mask 的維度: [batch_size, seq_len, seq_len]# 將相同的 Q, K, V 輸入多頭自注意力層enc_outputs, attn_weights = self.enc_self_attn(enc_inputs, enc_inputs,enc_inputs, enc_self_attn_mask)# 將自注意力輸出輸入位置前饋網絡enc_outputs = self.pos_ffn(enc_outputs)# 返回最終輸出和注意力權重return enc_outputs, attn_weightsclass Encoder(nn.Module):"""Transformer 編碼器由詞嵌入層、位置嵌入層和多個編碼器層組成"""def __init__(self, corpus):super(Encoder, self).__init__()self.src_emb = nn.Embedding(len(corpus.src_vocab), d_embedding)# 從預計算的位置編碼表初始化位置嵌入層,并凍結參數self.pos_emb = nn.Embedding.from_pretrained(get_sin_enc_table(corpus.src_len + 1, d_embedding), freeze=True)# 堆疊 n_layers 個編碼器層self.layers = nn.ModuleList(EncoderLayer() for _ in range(n_layers))def forward(self, enc_inputs):# enc_inputs 的維度: [batch_size, source_len]# 生成位置索引序列# orch.arange(1, enc_inputs.size(1) + 1) 創建一個從1開始到輸入序列長度的整數序列 # unsqueeze(0) 在第0維(索引從0開始)插入一個新的維度,將序列長度轉換為 [1, source_len]# to(enc_inputs) 將位置索引移動到與輸入相同的設備上(如 GPU)pos_indices = torch.arange(1, enc_inputs.size(1) + 1).unsqueeze(0).to(enc_inputs)# 詞嵌入和位置嵌入相加enc_outputs = self.src_emb(enc_inputs) + self.pos_emb(pos_indices)# 生成填充注意力掩碼# get_attn_pad_mask 函數用于生成填充注意力掩碼,忽略輸入序列中的 <pad> 詞語# enc_self_attn_mask 的維度: [batch_size, source_len, source_len]# True 和 False 分別表示填充位置和非填充位置,填充位置的注意力權重為 0,非填充位置的注意力權重為 1# True 表示該位置是填充標記,需要被忽略 # False 表示該位置不是填充標記,需要被考慮enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs)# 存儲所有層的注意力權重enc_self_attn_weights = []# 逐層通過編碼器層for layer in self.layers:enc_outputs, enc_self_attn_weight = layer(enc_outputs, enc_self_attn_mask)enc_self_attn_weights.append(enc_self_attn_weight)# 返回最終輸出和所有層的注意力權重return enc_outputs, enc_self_attn_weightsclass DecoderLayer(nn.Module):"""解碼器的一層包含一個多頭自注意力層、一個編碼器-解碼器注意力層和一個位置前饋網絡"""def __init__(self):super(DecoderLayer, self).__init__()self.dec_self_attn = MultiHeadAttention()self.dec_enc_attn = MultiHeadAttention()self.pos_ffn = PoswiseFeedForwardNet()def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):# dec_inputs 的維度: [batch_size, target_len, d_embedding]# enc_outputs 的維度: [batch_size, source_len, d_embedding]# 1. 第一個注意力子層: 多頭自注意力# Q, K, V 都來自解碼器輸入dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs,dec_inputs, dec_self_attn_mask)# 2. 第二個注意力子層: 編碼器-解碼器注意力# Q 來自解碼器輸出,K, V 來自編碼器輸出dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs,enc_outputs, dec_enc_attn_mask)# 3. 位置前饋網絡dec_outputs = self.pos_ffn(dec_outputs)# 返回最終輸出和兩個注意力層的權重return dec_outputs, dec_self_attn, dec_enc_attnclass Decoder(nn.Module):"""Transformer 解碼器由詞嵌入層、位置嵌入層和多個解碼器層組成"""def __init__(self, corpus):super(Decoder, self).__init__()self.tgt_emb = nn.Embedding(len(corpus.tgt_vocab), d_embedding)# 從預計算的位置編碼表初始化位置嵌入層,并凍結參數# from_pretrained 方法用于從預計算的位置編碼表中初始化位置嵌入層# get_sin_enc_table 函數用于生成正弦位置編碼表# freeze=True 表示凍結位置嵌入層的參數,不進行訓練self.pos_emb = nn.Embedding.from_pretrained(get_sin_enc_table(corpus.tgt_len + 1, d_embedding), freeze=True)# 堆疊 n_layers 個解碼器層self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])def forward(self, dec_inputs, enc_inputs, enc_outputs):# dec_inputs 的維度: [batch_size, target_len]# enc_inputs 的維度: [batch_size, source_len]# enc_outputs 的維度: [batch_size, source_len, d_embedding]# 生成位置索引序列pos_indices = torch.arange(1, dec_inputs.size(1) + 1).unsqueeze(0).to(dec_inputs)# 詞嵌入和位置嵌入相加dec_outputs = self.tgt_emb(dec_inputs) + self.pos_emb(pos_indices)# 1. 生成解碼器自注意力掩碼dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs)dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs)# 將填充掩碼和后續掩碼相加,結果大于 0 的位置為 Truedec_self_attn_mask = torch.gt((dec_self_attn_pad_mask+ dec_self_attn_subsequent_mask), 0)# 2. 生成編碼器-解碼器注意力掩碼 (僅考慮填充)dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs)dec_self_attns, dec_enc_attns = [], []# 逐層通過解碼器層for layer in self.layers:dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs,dec_self_attn_mask, dec_enc_attn_mask)dec_self_attns.append(dec_self_attn)dec_enc_attns.append(dec_enc_attn)# 返回最終輸出和所有層的注意力權重return dec_outputs, dec_self_attns, dec_enc_attns# --- Transformer 模型 ---class Transformer(nn.Module):"""Transformer 模型的總框架由編碼器、解碼器和最后的線性投影層組成"""def __init__(self, corpus):super(Transformer, self).__init__()self.encoder = Encoder(corpus)self.decoder = Decoder(corpus)# 最后的線性層,將解碼器輸出映射到目標詞匯表大小self.projection = nn.Linear(d_embedding, len(corpus.tgt_vocab), bias=False)def forward(self, enc_inputs, dec_inputs):# enc_inputs 的維度: [batch_size, source_seq_len]# dec_inputs 的維度: [batch_size, target_seq_len]# 1. 編碼器前向傳播enc_outputs, enc_self_attns = self.encoder(enc_inputs)# enc_outputs 的維度: [batch_size, source_len, d_embedding]# 2. 解碼器前向傳播dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)# dec_outputs 的維度: [batch_size, target_len, d_embedding]# 3. 線性投影dec_logits = self.projection(dec_outputs)# dec_logits 的維度: [batch_size, target_len, tgt_vocab_size]# 返回邏輯值和所有注意力權重return dec_logits, enc_self_attns, dec_self_attns, dec_enc_attns# --- 數據處理 ---from collections import Counterclass TranslationCorpus:"""數據處理類,用于管理語料庫、詞匯表和批次生成"""def __init__(self, sentences):self.sentences = sentencesself.src_len = max(len(sentence[0].split()) for sentence in sentences) + 1self.tgt_len = max(len(sentence[1].split()) for sentence in sentences) + 2self.src_vocab, self.tgt_vocab = self.create_vocabularies()self.src_idx2word = {v: k for k, v in self.src_vocab.items()}self.tgt_idx2word = {v: k for k, v in self.tgt_vocab.items()}def create_vocabularies(self):src_counter = Counter(word for sentence in self.sentences for word in sentence[0].split())tgt_counter = Counter(word for sentence in self.sentences for word in sentence[1].split())src_vocab = {'<pad>': 0, **{word: i + 1 for i, word in enumerate(src_counter)}}tgt_vocab = {'<pad>': 0, '<sos>': 1, '<eos>': 2,**{word: i + 3 for i, word in enumerate(tgt_counter)}}return src_vocab, tgt_vocabdef make_batch(self, batch_size, test_batch=False):input_batch, output_batch, target_batch = [], [], []# 隨機選擇句子索引# torch.randperm(len(self.sentences)) 生成一個長度為句子總數的隨機排列整數序列# [:batch_size] 選擇前 batch_size 個索引sentence_indices = torch.randperm(len(self.sentences))[:batch_size]for index in sentence_indices:src_sentence, tgt_sentence = self.sentences[index]# 將句子轉換為索引序列src_seq = [self.src_vocab[word] for word in src_sentence.split()]tgt_seq = ([self.tgt_vocab['<sos>']] +[self.tgt_vocab[word] for word in tgt_sentence.split()] +[self.tgt_vocab['<eos>']])# 對序列進行填充src_seq += [self.src_vocab['<pad>']] * (self.src_len - len(src_seq))tgt_seq += [self.tgt_vocab['<pad>']] * (self.tgt_len - len(tgt_seq))input_batch.append(src_seq)# 在測試模式下,解碼器輸入只包含 <sos> 符號output_batch.append([self.tgt_vocab['<sos>']] +([self.tgt_vocab['<pad>']] * (self.tgt_len - 2)) if test_batch else tgt_seq[:-1])target_batch.append(tgt_seq[1:])return torch.LongTensor(input_batch), torch.LongTensor(output_batch), torch.LongTensor(target_batch)# --- 訓練和推理 ---# 定義語料庫
sentences = [['毛老師 喜歡 人工智能', 'TeacherMao likes AI'],['我 愛 學習 人工智能', 'I love studying AI'],['深度學習 改變 世界', ' DL changed the world'],['自然語言處理 很 強大', 'NLP is powerful'],['神經網絡 非常 復雜', 'Neural-networks are complex']
]# 創建語料庫實例
corpus = TranslationCorpus(sentences)# 實例化模型、損失函數和優化器
model = Transformer(corpus)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.0001)# 模型訓練
print("--- 開始訓練 ---")
for epoch in range(epochs):optimizer.zero_grad()enc_inputs, dec_inputs, target_batch = corpus.make_batch(batch_size)outputs, _, _, _ = model(enc_inputs, dec_inputs)# 調整輸出和目標張量維度以適應損失函數# - outputs.view(-1, len(corpus.tgt_vocab)) 將輸出調整為 [batch_size * target_len, tgt_vocab_size]# - target_batch.view(-1) 將目標調整為 [batch_size * target_len]loss = criterion(outputs.view(-1, len(corpus.tgt_vocab)), target_batch.view(-1))if (epoch + 1) % 1 == 0:print(f"Epoch: {epoch + 1:04d} cost = {loss:.6f}")loss.backward()optimizer.step()# 模型推理 (翻譯)
print("\n--- 開始翻譯 ---")
# 創建一個大小為 1 的測試批次
enc_inputs, dec_inputs, target_batch = corpus.make_batch(batch_size=1, test_batch=True)# 打印輸入數據
print("編碼器輸入 :", enc_inputs)
print("解碼器輸入 :", dec_inputs)
print("目標數據 :", target_batch)# 進行翻譯預測
predict, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)# 后處理預測結果
predict = predict.view(-1, len(corpus.tgt_vocab))
predict = torch.argmax(predict, dim=1, keepdim=True) # Greedy Encoding 貪婪解碼,選取每個位置概率最大的詞的索引# 將索引轉換為單詞
translated_sentence = [corpus.tgt_idx2word[idx.item()] for idx in predict.squeeze()]
input_sentence = ' '.join([corpus.src_idx2word[idx.item()] for idx in enc_inputs[0]])# 打印翻譯結果
print(f"輸入句子: '{input_sentence}'")
print(f"翻譯結果: '{' '.join(translated_sentence)}'")語言模型
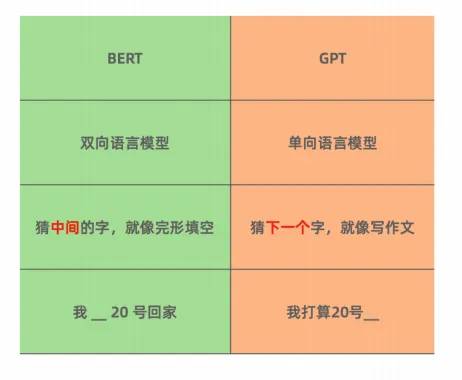
現階段所有的NLP模型都不能理解這個世界,只是依賴已有的數據集進行概率計算。而在目前的“猜概率”游戲環境下,基于大型語言模型(LLM, Large Language Model)演進出了最主流的兩個方向:BERT 和GPT
BERT 是之前最流行的方向,統治了所有NLP領域的判別任務,并在自然語言理解類任務中發揮出色。而最初GPT則較為薄弱,在GPT3.0發布前,GPT方向一直是弱于BERT的。
BERT 介紹
掩碼預訓練語言模型BERT
2018年Devlin等人提出了掩碼預訓練語言型BERT(Bidirectional Encoder Representation from Transformers)。BERT利用掩碼機制構造了基于上下文預測中間詞的預訓練任務,相較于傳統的語言模型建模方法,BERT能進一步挖掘上下文所帶來的豐富語義。
Bidirectional Encoder Representations fromTransformers,直譯過來就是“來自Transformer的雙向編碼表示”。
- 雙向(Bidirectional):這是 BERT最大的特點。
- 編碼器(Encoder):表明它擅長理解文本。
- 來自Transformer (from Transformers):說明它的底層架構是Transformer。
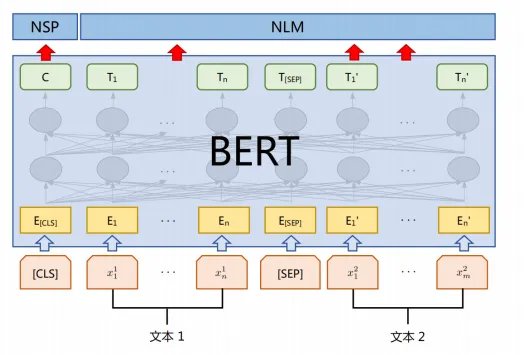
BERT 模型的組成
ERT由多層Transformer編碼器組成,這意味著在編碼過程中每個位置都能獲得所有位置的信息,而不僅僅是歷史位置的信息。BERT同樣由輸入層,編碼層和輸出層三部分組成。編碼層由多層Transformer編碼器組成。
在預訓練時,模型的最后有兩個輸出層MLM和NSP,分別對應了兩個不同的預訓練任務:掩碼語言模型(Masked LanguageModeling,MLM)和下一句預測(Next Sentence Prediction,NSP)
掩碼語言模型的訓練對于輸入形式沒有要求,可以是一句話也可以一段文本,甚至可以是整個篇章,但是下一句預測則需要輸入為兩個句子,因此BERT在預訓練階段的輸入形式統一為兩段文字的拼接,這與其他預訓練模型相比有較大區別。
BERT的創新之處在于,它采用了雙向的訓練方式。它在訓練時,會隨機遮蓋(mask)掉句子中一部分詞,然后讓模型根據被遮蓋詞的前后所有詞來預測它。除了“完形填空”(MaskedLanguage Model)這個主要任務外,BERT還有另一個輔助任務:下一句預測(NextSentence Prediction)。
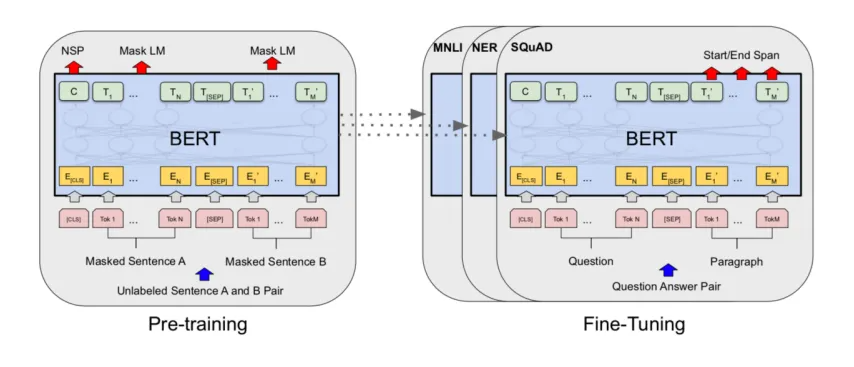
BERT首先在海量的文本數據上進行“預訓練”,學習通用的語言知識。之后,我們可以用少量的特定任務數據對它進行“微調”,讓它勝任具體的任務,如情感分析、問答系統、命名實體識別等。
分詞器
tokenizer將原始文本轉換為模型能夠處理的數字序列。像 BERT和 GPT 這樣的 Transformer模型,都只能處理數字,模型根本不認識這些漢字。分詞器的作用,就是把這個句子拆解并轉 換成一串數字,比如[101,23,45,67,102]。然后,這些數字才能被輸入到模型中進行 計算。
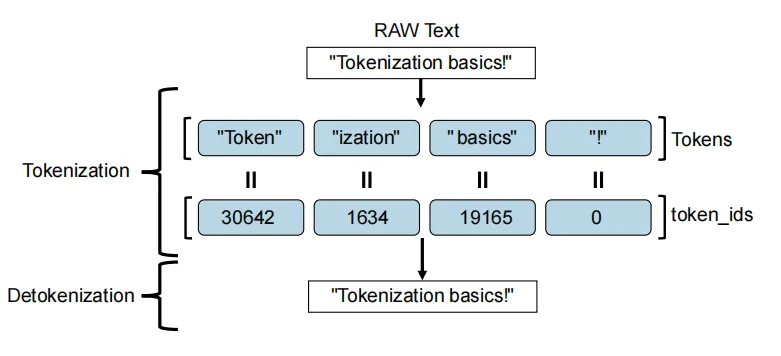
1. 分詞(Tokenization)分詞器會把一句話分解成一個個獨立的“詞元”(Token)。
- 按詞分詞:比如,句子“love cats”會被分成['I','love','cats']
- 按字分詞:對于中文,句子“我愛中國”會被分成['我','愛’,'中','國']
2. 特殊標記(Special Tokens)為了讓模型更好地理解句子的結構,分詞器會添加一些特殊的標22.記:
- ?[CLS]?:通常放在句子的開頭,它代表了整個句子的信息,常用于文0本分類任務。
- ?[SEP]?:通常放在句子的結尾,用于分隔不同的句子。如果想讓模型同時處理兩個句子(比如問答任務),會在它們之間放一個[SEP]。
- ?[PAD]?:當批次中的句子長度不一時,分詞器會用 [PAD]來填充短句子,讓所有句子的長度都相同,方便模型并行處理。
3. 映射到 ID(Token to lD)分詞器內部有一個巨大的“詞匯表”(Vocabulary),它將每個詞元映射到一個唯一的整數 ID。
4. 生成注意力掩碼(Attention Mask)在上面的步驟2中,我們用 [PAD]填充了句子。 但模型需要知道哪些是真正的詞,哪些是填充物。
位置編碼
Transformer 的位置編碼不是簡單的數字。它是一種與詞嵌入(word embedding)相加的編碼方式。在將詞語輸入模型之前,會將它的詞嵌入向量和位置編碼向量相加。位置編碼有多種實現方式,但Transformer論文中介紹的是一種基于正弦(sine)和余弦(cosine)函數的編碼方法。
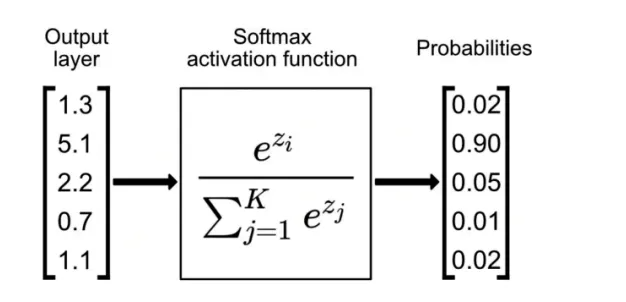
Softmax
Softmax 主要作用是吧一串普通的數字,轉換成一串所有數字加起來等于1的概率
殘差結構
在深度神經網絡中,信息需要一層一層地向前傳遞。當網絡層數很深時,就像信息要走一條非常長的路。在這個過程中,可能會出現梯度消失的問題,導致信息越來越弱,甚至丟失。這會讓模型很難訓練,效果也會變差。殘差結構的核心思想就是為信息傳遞提供一條捷徑(shortcut)
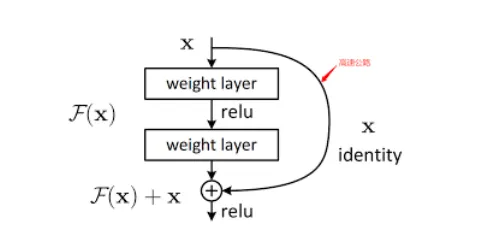
- 解決梯度消失問題:當梯度在反向傳播時,可以通過這條捷徑直接傳遞到前面的層,避免了信息在多層計算中逐漸衰減。這讓訓練更深的網絡變得可能。
- 保留原始信息:它確保了每一層的輸出都包含了原始輸入的信息。這就像在學習新知識時,不僅要吸收新的內容,還要不斷回顧舊的知識,這樣才能學得更扎實。
BERT 模型總結
預訓練階段: BERT采用了無監督的預訓練策略,通過在大規模語料庫上進行預訓練,學習通用的語言表示。模型在兩個任務上進行預訓練:
- Masked Language Model(MLM): 隨機遮蔽輸入文本中的一些詞,然后預測這些被遮蔽的詞。
- Next Sentence Prediction(NSP): 預測兩個相鄰句子是否是原文中相鄰的句子。
微調階段: 在具體任務上進行有監督的微調,例如文本分類、命名實體識別等。
- 優點:模型精度高,且泛化性較好
- 缺點:模型復雜度較高?
GPT 介紹
生成式預訓練語言模型GPT
OpenAI公司在2018年提出的GPT(Generative Pre-Training)模型是典型的生成式預訓練語言模型之一。GPT-2由多層Transformer組成的單向語言模型,主要可以分為輸入層,編碼層和輸出層三部分。
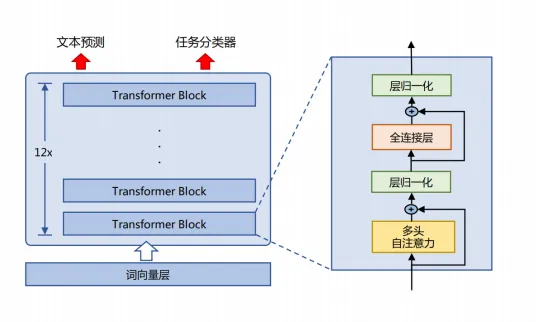
GPT 也預留了文本預測、文本分類的相關架構
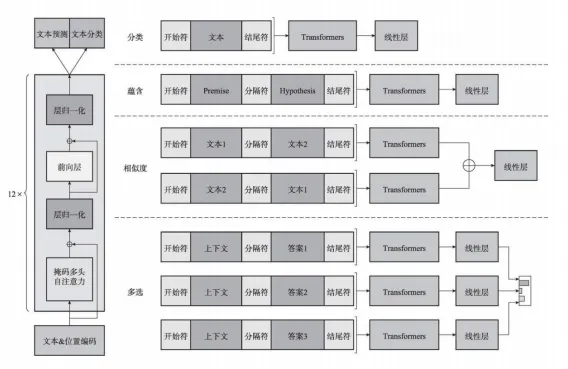
)






)




總結(89))
-圖像修復與編輯)


)


