總目錄 大模型相關研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
https://arxiv.org/pdf/2402.14836
https://www.doubao.com/chat/19815566713551106
文章目錄
- 速覽
- 攻擊方法速覽
- 一、攻擊核心目標與前提
- 1. 核心目標
- 2. 攻擊前提
- 二、模型無關的簡單攻擊(Victim Model-Agnostic Attack)
- 1. 基于正向詞插入的簡單攻擊(Trivial Attack with Word Insertion)
- 2. 基于GPT的文本重寫攻擊(Re-writing with GPTs)
- 三、黑盒文本攻擊(Black-Box Text Attacks)
- 1. 黑盒攻擊的核心框架
- 2. 4種具體黑盒攻擊方案
- 四、攻擊方法的關鍵特性驗證
- 五、攻擊的影響因素與局限性
- 1. 影響攻擊效果的關鍵因素
- 2. 局限性
- 論文翻譯
- 針對基于大型語言模型的推薦系統的隱蔽攻擊
- 摘要
- 1 引言
速覽
ACL 2024 | 大語言模型推薦系統的隱秘攻擊
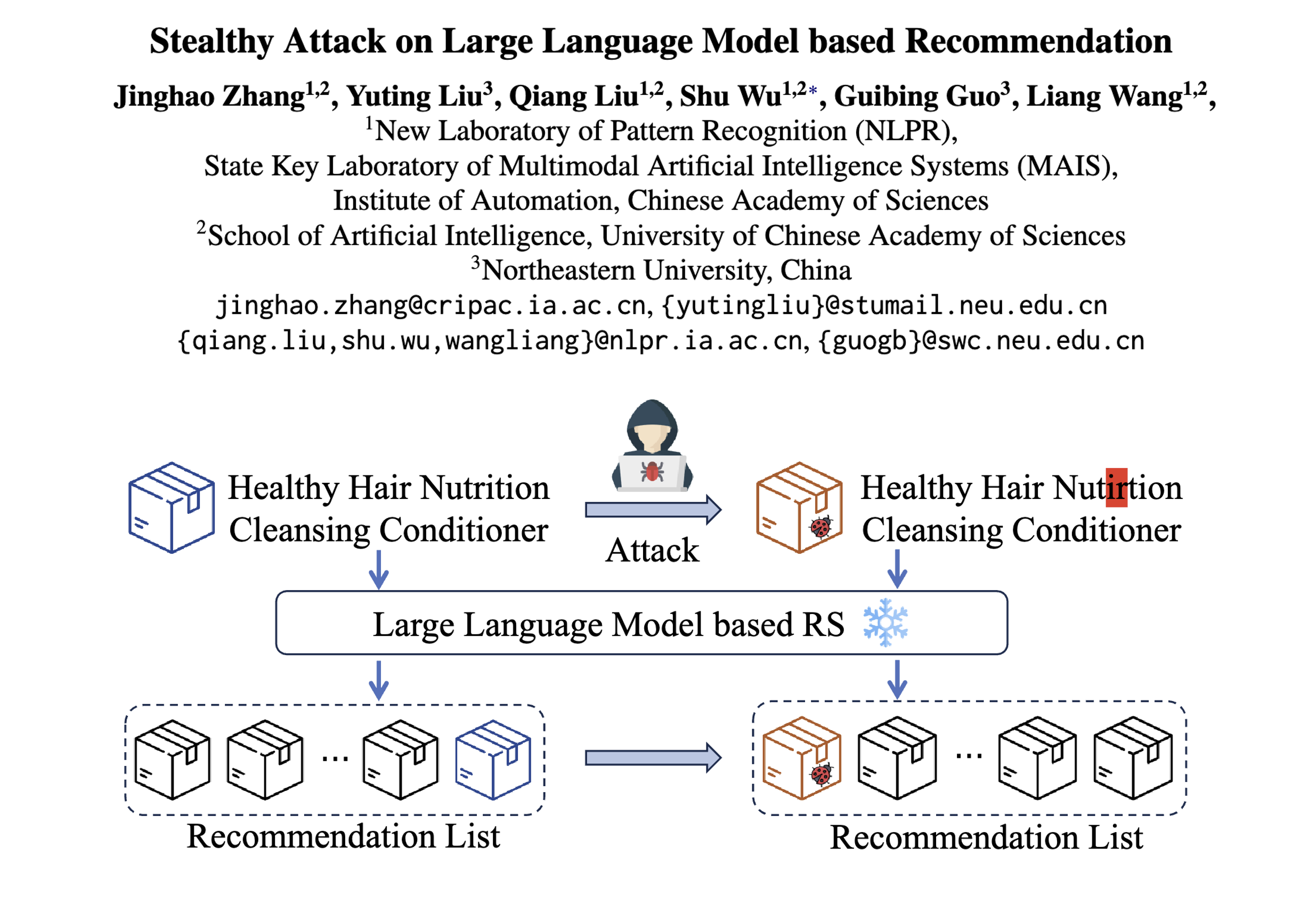
該論文發表于 ACL 2024,聚焦于大語言模型(LLM)在推薦系統中的應用及其潛在的安全漏洞。隨著 LLM 的強大能力推動推薦系統的發展,其安全性問題卻常被忽視。研究者們發現,攻擊者僅需在測試階段修改項目文本內容,無需干擾模型訓練過程,就能顯著提升項目曝光率。這種攻擊方式極其隱秘,不會影響整體推薦性能,且文本修改細微,難以被用戶和平臺察覺。
論文通過在四個主流的 LLM 基推薦模型上進行實驗,驗證了該攻擊方法的有效性和隱蔽性。研究還探討了模型微調和項目熱度對攻擊的影響,以及攻擊在不同模型和任務間的遷移性。此外,論文提出了一種簡單的重寫防御策略,雖不能完全抵御文本攻擊,但能提供一定防御效果。
該研究揭示了 LLM 基推薦系統在文本內容上的安全漏洞,為未來保護這些系統提供了研究方向。隨著 LLM 在推薦領域的廣泛應用,如何增強其安全性成為亟待解決的問題。
攻擊方法速覽
這篇論文聚焦于基于大型語言模型(LLM)的推薦系統(RS)的安全性漏洞,提出了文本篡改攻擊范式——通過微調目標物品的文本內容(如標題、描述),在不干擾模型訓練過程的前提下提升物品曝光度,同時具備高隱蔽性。論文設計的攻擊方法可分為模型無關的簡單攻擊和黑盒文本攻擊兩大類,以下是具體拆解:
一、攻擊核心目標與前提
1. 核心目標
在不影響推薦系統整體性能、不被用戶/平臺察覺的前提下,通過修改目標物品(如低質商品、虛假新聞)的文本內容,顯著提升其在推薦列表中的曝光率(Exposure)或用戶交互概率(Purchasing Propensity)。
2. 攻擊前提
基于LLM的推薦系統與傳統ID驅動型RS的核心差異——LLM-RS依賴文本的語義理解能力(如物品標題、用戶歷史行為的文本化表達),因此文本內容成為攻擊的關鍵突破口,無需像傳統“托攻擊(Shilling Attack)”那樣注入虛假用戶數據。
二、模型無關的簡單攻擊(Victim Model-Agnostic Attack)
這類方法無需了解推薦模型的內部參數或結構,僅通過基礎文本修改策略提升物品“吸引力”,操作簡單且易實施,包括兩種具體方案:
1. 基于正向詞插入的簡單攻擊(Trivial Attack with Word Insertion)
- 核心邏輯:假設“正向詞匯”或“感嘆詞”能提升文本對LLM的吸引力,進而增加推薦概率。
- 具體操作:
- 構建一個預定義的正向詞庫,包含常見于商品標題的積極詞匯,如“good”“great”“best”“excellent”“!!!”等(共32個詞);
- 從詞庫中隨機選擇
k個詞,插入到原始物品標題的末尾,確保文本整體連貫性(如將“Healthy Hair Cleansing Conditioner”改為“Healthy Hair Cleansing Conditioner best quality!!!”)。
- 優缺點:優點是實現成本極低,不破壞文本核心語義;缺點是可能導致文本略顯生硬(如堆砌正向詞),部分場景下可能引發用戶懷疑。
2. 基于GPT的文本重寫攻擊(Re-writing with GPTs)
- 核心邏輯:利用GPT的常識知識和生成能力,將原始標題重寫為“更具吸引力但不改變核心含義”的版本,解決簡單插入正向詞的“生硬問題”。
- 具體操作:
- 采用GPT-3.5-turbo作為生成模型,設計3類提示詞(Prompt)引導重寫,確保文本流暢性和吸引力:
- Prompt 1(營銷視角):“作為促進商品銷售的營銷專家,將標題重寫為個詞,保留核心信息但更吸引客戶”;
- Prompt 2(創意視角):“將基礎標題轉化為獨特、抓眼球的詞標題,提升關注度”;
- Prompt 3(正向詞融合視角):“融入正向詞匯重寫標題,不改變原意且更吸引潛在用戶”;
- 限制重寫后的標題長度(),避免文本過長影響推薦模型處理。
- 采用GPT-3.5-turbo作為生成模型,設計3類提示詞(Prompt)引導重寫,確保文本流暢性和吸引力:
- 優缺點:優點是文本自然度高、隱蔽性強(用戶難以察覺修改);缺點是依賴外部大模型,且效果受提示詞設計影響較大。
三、黑盒文本攻擊(Black-Box Text Attacks)
這類方法是論文的核心創新,針對LLM-RS的文本依賴漏洞,通過“黑盒交互”(無需訪問模型參數/梯度,僅通過查詢模型輸出調整攻擊策略)生成對抗性文本,實現更高效的攻擊。論文基于經典黑盒文本攻擊框架(Morris et al., 2020),拆解為四大核心組件,并實現了4種具體攻擊方案。
1. 黑盒攻擊的核心框架
攻擊目標可通過數學公式定義為:
argmaxti′Eu∈U′fθ(Pu,i′)\underset{t_{i}'}{arg max } \mathbb{E}_{u \in \mathcal{U}'} f_{\theta}\left(\mathcal{P}_{u, i}'\right)ti′?argmax?Eu∈U′?fθ?(Pu,i′?)
其中,ti′t_i'ti′?是修改后的目標物品文本,Pu,i′\mathcal{P}_{u,i}'Pu,i′?是包含ti′t_i'ti′?的推薦模型輸入提示(如用戶歷史文本+修改后物品文本),fθf_\thetafθ?是LLM推薦模型,目標是最大化用戶U′\mathcal{U}'U′對ti′t_i'ti′?的推薦評分期望。
框架的四大組件分工如下:
| 組件 | 核心作用 | 論文實現細節 |
|---|---|---|
| 目標函數 | 評估修改后文本的攻擊效果,指導搜索最優對抗文本 | 以“目標物品曝光率提升幅度”或“用戶交互概率提升幅度”為核心指標,設置閾值(如0.05)判斷攻擊是否成功 |
| 約束條件 | 確保修改后的文本“有效且隱蔽”,避免被檢測 | 1. 語義一致性:原始文本與修改后文本的余弦相似度≥0.8;2. 詞性一致性:不改變核心詞的詞性;3. 長度約束:修改前后文本長度差異較小 |
| 文本變換 | 生成可能的文本修改方案(即“擾動”) | 包括字符級變換(如替換字符、插入標點)和詞級變換(如同義詞替換、掩碼詞預測) |
| 搜索方法 | 迭代查詢模型,篩選最優擾動方案 | 采用“基于詞重要性的貪心搜索(GreedyWordSwapWIR)”,優先修改對推薦結果影響大的詞 |
2. 4種具體黑盒攻擊方案
論文實現了字符級和詞級兩類攻擊,覆蓋不同修改粒度,具體差異如下表:
| 攻擊方法 | 攻擊粒度 | 核心變換策略 | 特點 |
|---|---|---|---|
| DeepwordBug | 字符級 | 通過字符級擾動生成拼寫錯誤:1. 隨機刪除字符;2. 隨機插入字符;3. 相鄰字符交換;4. 隨機替換字符(如將“People”改為“ePople”) | 修改痕跡極細微(僅單個字符),隱蔽性強;無需外部詞庫支持 |
| PuncAttack | 字符級 | 在文本中插入特定標點符號(如“-”“'”),如將“Little People”改為“Little P-eople”或“Little Peo’ple” | 不破壞語義和詞形,用戶難以察覺;計算成本低 |
| TextFooler | 詞級 | 基于詞嵌入相似度替換同義詞:1. 計算原始詞的詞嵌入(如GloVe);2. 篩選相似度≥0.6的同義詞;3. 替換核心詞(如將“People”改為“Inhabitants”) | 攻擊效果強(曝光率提升幅度大);但依賴高質量詞嵌入,部分替換可能生硬 |
| BertAttack | 詞級 | 基于掩碼語言模型(BERT)預測替換詞:1. 將原始詞掩碼(如“Little [MASK]”);2. 選擇BERT預測概率Top48的詞作為替換候選;3. 篩選語義一致的詞替換 | 替換詞更符合上下文邏輯,文本自然度高;但需查詢BERT模型,成本較高 |
四、攻擊方法的關鍵特性驗證
論文通過實驗驗證了攻擊方法的有效性和隱蔽性,核心結論如下:
- 有效性:黑盒攻擊的曝光率提升幅度遠超傳統托攻擊(Shilling Attack)——如TextFooler在Beauty數據集上使目標物品曝光率提升520.4%,而傳統Bandwagon攻擊僅提升約1%;
- 隱蔽性:
- 對推薦系統整體性能無影響:攻擊后模型的NDCG@10、Recall@10等指標與“無攻擊”狀態幾乎一致(差異≤0.5%);
- 文本質量高:修改后文本與原始文本的余弦語義相似度≥0.6,GPT-Neo評估的流暢度(Perplexity)接近原始文本;
- 修改量少:平均僅修改2-4個詞(或字符),用戶難以察覺。
五、攻擊的影響因素與局限性
1. 影響攻擊效果的關鍵因素
- 模型微調狀態:零-shot的LLM-RS(未在目標數據集上微調)比微調后的模型更易受攻擊——微調模型需更多查詢次數(平均增加30%),且曝光率提升幅度降低20%-40%;
- 物品流行度:高流行度物品更易被攻擊——高流行度物品的曝光率提升幅度比低流行度物品高30%-50%,且所需查詢次數更少(平均減少15%);
- 跨模型/跨任務遷移性:
- 跨任務遷移:攻擊“直接推薦任務”生成的對抗文本,可遷移到“評分預測任務”(如P5模型),曝光率提升幅度保持80%以上;
- 跨模型遷移:僅在相同 backbone 的模型間可遷移(如基于LLaMA的TALLRec和CoLLM),不同backbone(如Longformer的RecFormer)間無遷移性。
2. 局限性
- 黑盒查詢依賴:黑盒攻擊需多次查詢推薦模型(如BertAttack平均需140次查詢),在大規模工業級推薦系統中可能觸發頻率限制;
- 僅針對文本模態:當前攻擊僅修改文本內容,未涉及圖像、視頻等其他模態(如商品圖片),實際場景中多模態推薦系統可能降低攻擊效果;
- 部分防御可緩解:基于GPT的文本重寫防御(如修正拼寫錯誤、刪除多余標點)可有效抵御字符級攻擊(如DeepwordBug、PuncAttack),但對詞級攻擊(如TextFooler)防御效果有限。
綜上,論文提出的文本篡改攻擊范式,通過“微調文本+黑盒交互”精準利用LLM-RS的文本依賴漏洞,兼具高效性和隱蔽性,為LLM推薦系統的安全防護提供了關鍵研究方向。
論文翻譯
針對基于大型語言模型的推薦系統的隱蔽攻擊
摘要
近年來,功能強大的大型語言模型(LLM)在推動推薦系統(RS)發展方面發揮了重要作用。然而,盡管這些系統蓬勃發展,其在安全威脅面前的脆弱性卻在很大程度上被忽視。在本研究中,我們發現,將大型語言模型引入推薦模型會帶來新的安全漏洞,這一問題源于模型對物品文本內容的重視。我們證明,攻擊者只需在測試階段修改目標物品的文本內容,無需直接干擾模型的訓練過程,就能顯著提高該物品的曝光率。此外,這種攻擊具有顯著的隱蔽性——它不會影響推薦系統的整體性能,且對文本的修改十分細微,使用戶和平臺難以察覺。我們在四種主流的基于大型語言模型的推薦模型上開展了全面實驗,結果表明我們提出的攻擊方法具有出色的有效性和隱蔽性。本研究揭示了基于大型語言模型的推薦系統中一個重要的安全缺口,為未來保護這類系統的相關研究奠定了基礎。
1 引言
在過去幾十年里,推薦系統(RS)在各個領域都獲得了重要地位。近年來,功能強大的大型語言模型(LLM)在推動推薦系統發展方面發揮了關鍵作用,針對推薦任務定制大型語言模型的研究關注度顯著上升。
傳統推薦模型嚴重依賴抽象且可解釋性較低的基于ID的信息,與之不同的是,基于大型語言模型的推薦模型充分利用了大型語言模型的語義理解能力和強大的遷移能力。這種方法更加注重物品的文本內容,例如物品標題和描述(Lin等人,2023a;Chen等人,2023)。例如,許多研究者(Hou等人,2022,2023a;Yuan等人,2023;Li等人,2023a;Yang等人,2023;Geng等人,2022;Cui等人,2022;Bao等人,2023a;Zhang等人,2023b;Li等人,2023b;Zhang等人,2023c)已嘗試從語言角度對用戶偏好和物品特征進行建模。這種方法能夠對新物品和新數據集實現泛化,有望為傳統推薦范式帶來革命性變革。
盡管取得了這些進展,推薦系統的安全性仍是一個在很大程度上未得到解決的問題。對這類系統的惡意攻擊可能導致不良后果,例如在電子商務平臺中不當推廣低質量產品,或在新聞傳播場景中擴散虛假信息。針對推薦系統的傳統托攻擊(shilling attack)策略(Wang等人,2023a,2024c)通常會生成虛假用戶,這些虛假用戶被設定為對特定目標物品給出高分評價。通過注入此類欺詐數據,攻擊者旨在影響推薦模型的訓練,進而提高目標物品的曝光率。
然而,將大型語言模型引入推薦模型會帶來新的安全漏洞。在本文中,據我們所知,我們首次證明,由于對物品文本內容的重視,基于大型語言模型的推薦系統具有更高的脆弱性。我們發現,攻擊者只需在測試階段采用簡單的啟發式重寫或黑盒文本攻擊策略(Morris等人,2020)修改物品的文本內容,就能顯著提高該物品的曝光率。與傳統托攻擊相比,這種攻擊范式具有顯著的隱蔽性——它無需影響模型訓練,且推薦系統的整體性能幾乎不受影響。此外,對物品標題的修改十分細微,使用戶和平臺難以察覺。
為了驗證文本攻擊范式相較于傳統托攻擊(Burke等人,2005b;Kaur和Goel,2016;Lin等人,2020)所具備的出色有效性和隱蔽性,我們以四種主流的基于大型語言模型的推薦模型(Geng等人,2022;Bao等人,2023a;Li等人,2023a;Zhang等人,2023c)作為攻擊目標模型,開展了全面實驗。我們進一步深入研究了模型微調程度和物品流行度對攻擊效果的影響,同時還探究了該攻擊在不同目標模型和推薦任務間的遷移能力,以證明其在實際場景中的適用性和實用性。最后,我們評估了一種簡單的重寫防御策略,該策略在一定程度上能夠緩解上述安全問題。
綜上所述,本研究的貢獻如下:
- 我們指出,基于大型語言模型的推薦模型由于對文本內容信息的重視,可能會引發此前被忽視的安全問題。
- 據我們所知,我們是首個針對基于大型語言模型的推薦模型發起攻擊的研究團隊,并提出通過文本攻擊來提高目標物品的曝光率。
- 我們開展了大量實驗,以證明文本攻擊范式的有效性和隱蔽性。進一步的實驗還揭示了物品流行度和模型微調程度對攻擊效果的影響,并探究了攻擊的遷移能力。
- 最后,我們提出了一種簡單的重寫防御策略。該策略雖無法完全抵御基于文本的攻擊,但能提供一定程度的防護,為未來相關研究提供參考。
)









![[react] react-router-dom是啥?](http://pic.xiahunao.cn/[react] react-router-dom是啥?)



深入無鎖并發演進,AtomicInteger核心API詳解與典型場景舉例)
)



