編者按:
人工智能正以前所未有的滲透力重塑生產與生活圖景。作為國內領先的數據智能科技企業,和鯨科技自 2015 年成立以來,深耕人工智能與數據科學,歷經十年發展,已在氣象、教育、醫療、航空航天、金融、通信、能源、零售等領域,與眾多高校、科研機構、企業等單位展開了深度合作。
大模型技術正掀起新一輪產業變革浪潮。在此背景下,和鯨科技資深架構工程師鄭宇宸基于工作中的豐富經驗,帶來基于 Kubernetes 的 LLM 分布式推理框架架構分享。
隨著大語言模型(LLM)在生產環境中的廣泛應用,高效的推理部署已成為業界面臨的核心挑戰。為了應對這一挑戰,工業界和學術界正在積極探索多種優化方案,包括:
多維度并行技術:數據并行(Data Parallelism)、張量并行(Tensor Parallelism)、流水線并行(Pipeline Parallelism)、專家并行(Expert Parallelism)等
批處理優化:連續批處理(Continuous Batching)
這些技術都對 LLM 的推理性能有著顯著的優化。然而,隨著模型規模的持續增長和應用場景的復雜化,傳統的單機部署方式已經無法適用,特別是像 DeepSeek V3/R1 與 Kimi K2 等大規模 MoE(Mixture of Experts)模型的出現,其對計算資源的需求已經超出了單機的承載能力,對 LLM 的推理提出新的挑戰。
本文將會圍繞基于 Kubernetes 的大語言模型分布式推理框架架構進行介紹,包括目前 Kubernetes 社區主流的分布式推理解決方案以及其集成的學術界的相關工作,旨在分享目前基于 Kubernetes 的主流解決方案所解決的問題以及未來可能的發展方向。需要注意的是,本文主要關注集群編排層面的架構設計,不涉及 vLLM 與 SGLang 等推理引擎內部的具體優化實現。
背 景
在介紹基于 Kubernetes 的 LLM 分布式推理框架之前,我們需要對 LLM 的推理過程有初步的了解。
LLM 的推理
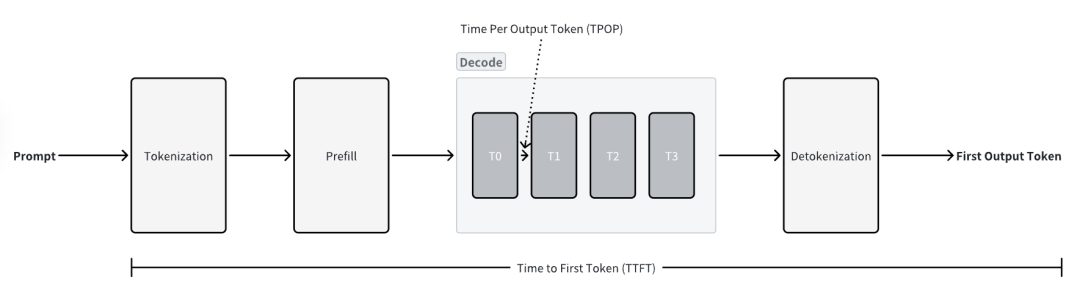
基于 Transformer 的 LLM 的推理主要分為兩個階段,Prefill 與 Decode。
Prefill:Prefill 階段是推理過程的第一步,其核心任務是處理用戶輸入的 Prompt。在這個階段,模型會并行處理輸入提示中的所有 Token,一次性計算出整個輸入序列的 Attention 狀態 。這個過程會生成一組關鍵的中間結果,即 Key 與 Value,并將它們存儲在 KV Cache 中 。由于 Prefill 階段涉及對整個輸入序列進行大量的矩陣乘法運算,它是一個計算密集型(Compute-bound)的過程 。
Decode:當 Prefill 階段完成并生成初始的 KV Cache 后,模型便進入 Decode 階段,開始逐個生成輸出 Token 。這是一個自回歸(Auto-regressive)的過程,即每生成一個新的 Token,都需要將其作為輸入,與之前的所有上下文(包括原始 Prompt 和已生成的 Token)一同來預測下一個 Token。與 Prefill 不同,Decode 階段是串行的,無法并行處理 。在生成每個 Token 時,主要的性能瓶頸在于從 HBM 中加載和讀取龐大的模型權重參數,因此這是一個訪存密集型(Memory-bound)的過程 。
LLM 推理的關鍵指標
本節介紹了一些在討論 LLM 的推理的時候會提及的關鍵指標,這些關鍵指標是優化 LLM 推理性能的基準,通過它們才能夠衡量在不同場景之下 LLM 推理優化的目標。
Time to First Token (TTFT)
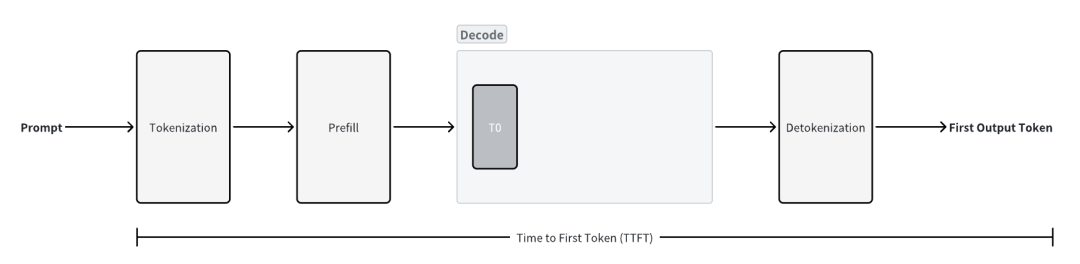
請求到達之后生成第一個 Token 所需要的時間,是衡量 Prefill 階段的性能的指標。
Time Per Output Token (TPOT)
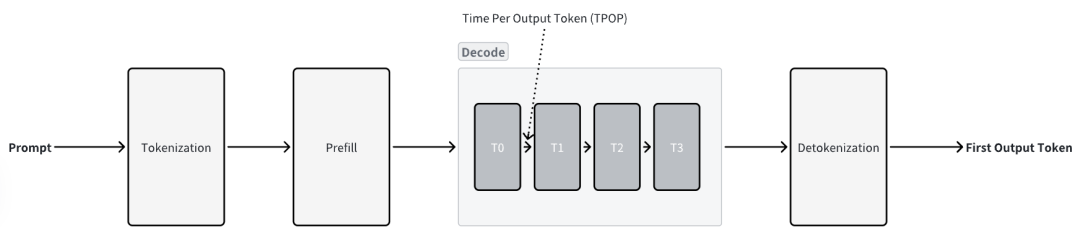
平均生成一個輸出 Token 所需要的時間,是衡量 Decode 階段的性能的指標。
Latency (E2E Latency)
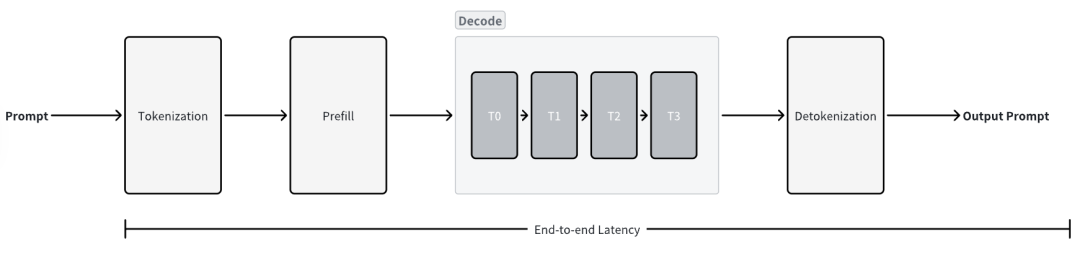
端到端的延遲。
latency = TTFT + TPOT x number of tokens
Throughput (Tokens Per Second)
單位時間內生成的 Token 的數量,即端到端的吞吐量。
Requests per second (RPS)
單位時間內成功的請求個數。
除了前述的幾個常見的指標以外,還有一些額外的指標,如:
Normalized Time Per Output Token (NTPOT):歸一化的 TPOT,其計算方式為 NTPOP = latency / number of tokens。
Inter-Token Latency(ITL):兩個 Token 生成之間的延遲,與 TPOP 的不同之處在于其測量的是生成 Token 之間的時間的離散值。
回顧:在 Kubernetes 上單機部署 LLM
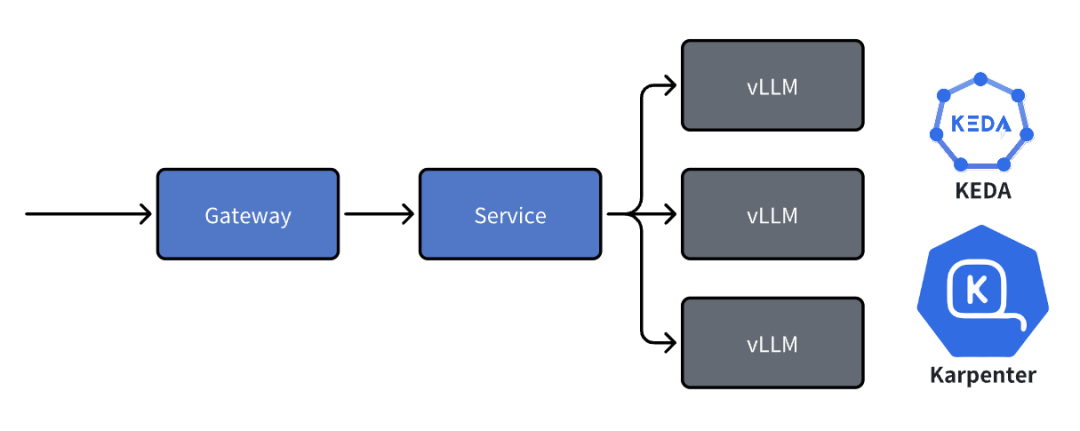
上圖是在 Kubernetes 集群中部署基于 vLLM 單機推理服務的常見解決方案,采用的是基于?KEDA(Pod 自動擴縮容)與?Karpenter(節點自動擴縮容)的自動擴縮容,由 Gateway 在網關層面進行路由與負載均衡,是當時部署 LLM 的主流解決方案。當時的模型只需要單機多卡就能滿足推理的需要,而基于 vLLM 與 Ray 的多機多卡部署由于網絡基礎設施的異同與限制會對 Decode 階段張量并行的性能造成顯著的下降(如在 10Gbps 的以太網的基礎上網絡帶寬會成為性能瓶頸),因此采用前述的方案其實是相對合理的選擇,可以利用多個維度的自動擴縮容機制根據流量對部署的規模進行控制,以得到更好的推理性能。
然而,隨著 DeepSeek V3/R1 與 Kimi K2 ?等 MoE 架構的模型的橫空出世,前述的這種部署架構就面臨了挑戰,而更大參數量與上下文的模型以及更復雜的使用場景使得單機的 GPU 部署方式無法再適用,因為節點內卡間的通信以及跨節點的通信(根據網絡拓撲的不同)在不同的并行方式下都會引入難以忽略的延遲,對多個關鍵指標都會造成顯著的降級,從而影響推理服務的質量。
因此,工程師們才會著眼于分布式推理,基于 Kubernetes 的分布式推理解決方案在 2024 年末至今得到了高速的發展,各大公司都在社區開源了自己所提出的解決方案,如何利用集群編排的能力使得下層的推理框架得到更好的性能,如服務質量的提升,以及成本的降低等,都是分布式推理框架所需要達成的目標。下文將會對基于 Kubernetes 的 LLM 分布式推理框架進行整體的介紹,以及這些框架如何將工業界的經驗與學術界的成果互相有機結合,實現更加高效的 LLM 推理。
基于 Kubernetes 的 LLM 分布式推理框架
目前,開源社區當中基于 Kubernetes 的 LLM 分布式推理框架或解決方案主要有以下幾個:
AIBrix?(ByteDance)
Dynamo?(NVIDIA)
llm-d?(Red Hat / Google / IBM)
OME?(SGLang / Oracle)
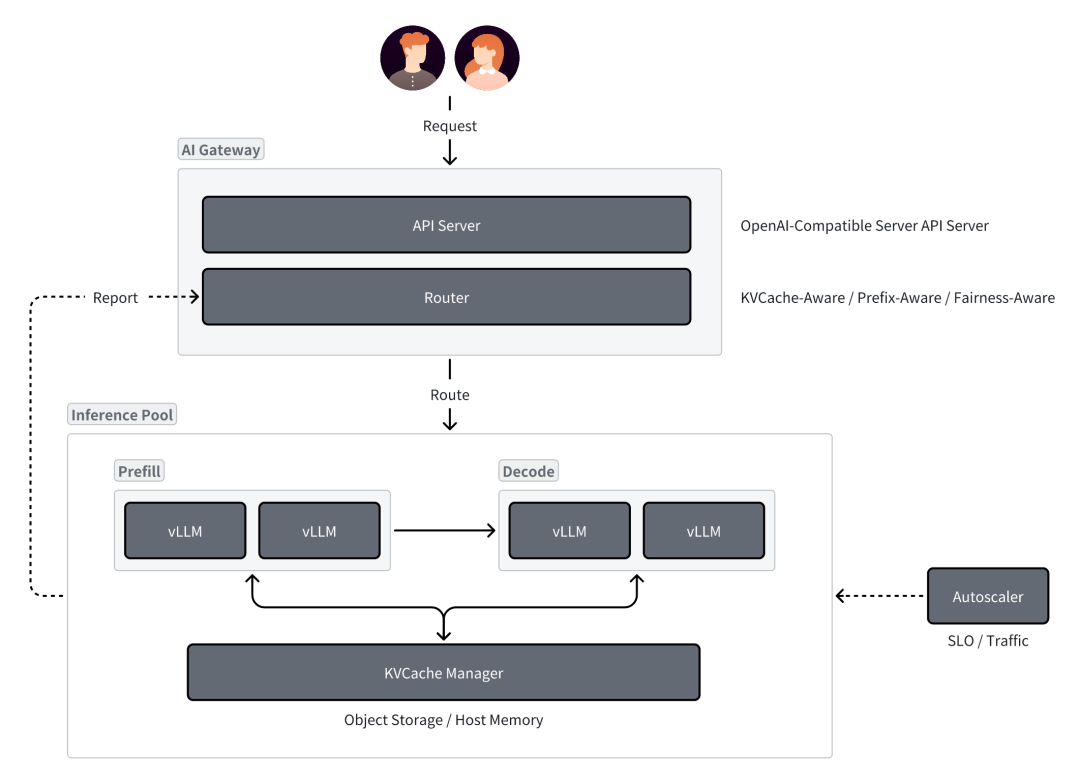
雖然前述項目都是由不同公司主導,但是它們的關注點是相似的,上圖展示了較為通用的基于 LLM 的分布式推理框架的概覽,主要由以下幾個組件構成:
AI Gateway:提供兼容 OpenAI API 的接口的 API Server,以及負責調度請求的 Router
Inference Pool:負責工作負載的部署
Autoscaler:負責工作負載節點的自動擴縮容。
目前基于 Kubernetes 的分布式推理框架主要關注在以下幾個主題,下文將會分別進行介紹:
PD 分離
負載均衡
KV Cache 管理
自動擴縮容
PD 分離
如同前文所提及的,LLM 的推理分為兩個階段,其中 Prefill 是計算密集型,Decode 是訪存密集型,兩者對資源的需求是完全不同的。一般而言,LLM 推理引擎都會采用 Continuous Batching 的方式聚合多個請求再進行處理,這就會造成嚴重的資源沖突與效率瓶頸,即執行計算密集的 Prefill 任務時,系統無法同時滿足 Decode 任務對內存帶寬的高頻需求,另一方面,執行訪存密集的 Decode 任務時,大量計算資源處于閑置狀態。此外,這種混合執行的模式還會導致阻塞,即一個計算量大的 Prefill 請求會阻塞后面許多本可以快速完成的 Decode 步驟,從而增加了其他用戶的等待延遲,使得 Continuous Batching 的優勢無法充分發揮。
PD 分離(Prefill-Decode Disaggregation)正是為解決上述問題而提出的架構優化方案,該技術最初由學術界的 Splitwise 和 DistServe 等研究工作提出,核心思想是將 Prefill 和 Decode 階段物理分離,在不同的工作節點上分別運行,根據彼此的資源使用特性分別調整兩類服務的資源配置,從而實現不同關鍵指標的優化,同時還能避免兩個階段的作業的相互干擾。此外,在特定的工作場景下,甚至可以采用異構的硬件資源分別運行 Prefill 與 Decode 作業,更好地利用不同計算資源的能力。
然而,?PD 分離并不是萬能的策略,在 PD 分離的架構下,Prefill 階段的 KV Cache 需要被傳輸到 Decode 階段,這就引入了額外的數據傳輸開銷,考慮到 KV Cache 的大小,頻繁地在不同服務之間傳輸數據可能會帶來顯著的延遲,甚至可能抵消掉 PD 分離帶來的性能提升。此外,PD 分離還需要額外的編排與調度邏輯來管理 Prefill 和 Decode 服務之間的協作,以及服務間的 KV Cache 的管理,這會顯著增加系統的復雜性。因此,PD 分離會更加適合于大規模部署的推理場景,尤其是在請求足夠異構(即請求的模式以及資源需求差異化較大)的情況下,會帶來更佳的收益,而在如具身智能等邊緣場景可能引入的收益有限,甚至可能產生負面的影響。目前,AIBrix、Dynamo 與 llm-d 等項目都基于不同實現提供了基于推理引擎的 PD 分離的支持。
路由與負載均衡
在分布式推理場景下,Gateway 需要將用戶請求轉發到特定的實例上,這些實例是運行在不同 GPU 或服務器節點上的模型副本。然而,LLM 的負載均衡要比傳統的無狀態服務更加復雜,其核心挑戰源于推理過程本身的狀態性和異構性。LLM 推理的核心是 KV Cache,其存儲了模型在 Prefill 階段計算出的 Key 和 Value。由于不同請求的 Prompt 可能存在重疊的前綴,這些共享的前綴信息可以被多個請求復用,從而顯著提升推理效率。因此,在負載均衡時需要考慮如何高效地利用這些緩存,而不是簡單地將請求隨機分配到不同的實例上。Dynamo 與 AIBrix 等項目都通過插件化的方式擴展了負載均衡的功能,支持在網關層面進行多種負載均衡算法的靈活配置。
Prefix-Aware
Prefix Caching 是一種能夠緩存并復用請求前綴部分 KV Cache 的技術。當多個請求共享相同的前綴時,系統可以避免重復計算,直接復用已緩存的 Key 和 Value,從而顯著降低 TTFT 并提升整體吞吐量。vLLM 和 SGLang 等推理引擎都實現了 Prefix Caching 功能。在分布式推理環境中,Prefix-Aware 負載均衡策略會優先將具有相似前綴的請求路由到同一個實例,以最大化緩存的命中率。這種策略需要負載均衡器維護每個實例的緩存狀態信息,并根據請求的前綴特征進行路由。
Fairness
LLM 實例的公平調度也是負載均衡的一個重要方面,尤其是在多租戶環境中,公平性確保了所有用戶都能獲得相對一致的服務質量,而不會因為某些實例過載而導致其他用戶的請求延遲。
AIBrix 基于 Sheng et al. 實現了 Virtual Token Counter (VTC) 的 Fair Queuing 調度策略。VTC 為每個客戶端維護一個虛擬 Token 計數器,通過跟蹤每個客戶端已接受的服務量來實現公平調度,優先服務計數器值最小的客戶端。
Example: Ray Serve LLM
Source: https://github.com/ray-project/ray/blob/master/python/ray/llm/_internal/serve/request_router/prefix_aware/prefix_aware_router.py
The Power of Two Choices 是負載均衡領域很經典的算法,其主要思想相當簡單,即在所有的可選項中隨機選擇兩個,再根據某種標準選擇更好的那個(在負載均衡場景下即為負載更小的那個),從數學期望的角度理解的話,這個算法可將最壞的情況由
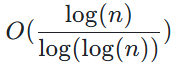
降低到
![]()
。
Ray Serve LLM 目前的實現將 Power of Two Choices 與 Prefix-Aware 進行結合:
當負載均衡(即 Queue 之間的差異小于一定閾值)時,它會選擇與輸入的前綴匹配度最高的實例;
當負載均衡當時匹配度低于 10% 時,它會選擇負載最小的實例;
當負載不均衡時,它會使用 Power of Two Choices 進行選擇。
這種混合的負載均衡策略可以在保證 KV Cache 的有效利用的同時,盡可能地平衡不同實例之間的負載,從而提高整體的推理性能。
KV Cache 管理
如同前文所述,KV Cache 是被設計來在自回歸的過程中緩存前序 Token 計算出來的 Key 與 Value 的值,它們會被保存在顯存中供后續的步驟使用。通過 KV Cache,在推理的過程中就不需要重復計算前序的 Token 的 KV 值,從而能夠顯著加快推理的過程。然而,隨著上下文長度的增加,KV Cache 的大小也會隨之線性增長,尤其是在大規模推理的場景之下,GPU 的顯存很快就會被消耗殆盡從而導致推理服務無法利用 KV Cache 能力,成為推理過程當中的瓶頸。
KV Cache Offloading
KV Cache Offloading 指的是將 GPU 顯存中的 KV Cache 卸載到 CPU 內存或是外部存儲的過程,其提出就是為了解決前述的 KV Cache 占用 GPU 顯存的問題,當 LLM 需要訪問被卸載的 KV Cache 時,它會按需將這些 Block 重新加載回 GPU 顯存中。AIBrix 提供了多層 KV Cache 的緩存框架,默認情況下會使用 DRAM 中的 L1 Cache,在需要共享 KV Cache 的場景下則可以使用 L2 Cache,即分布式的外部存儲。Dynamo 與 llm-d 等框架同樣也支持使用 LMCache 等框架將不常用的 KV Cache 卸載到 CPU 內存與外部存儲中。
KV Cache Sharing
隨著 KV Cache Offloading 的引入,如何在不同的 LLM 推理實例共享 KV Cache 也是個被廣泛研究的問題。
Centralized:即通過一個中心化的 KV Cache 的池來管理不同實例的 KV Cache,其優點在于能夠最大化地共享 KV Cache,可以更好地利用 Prefix Caching 的能力,但是在高并發的場景之下其可能會成為單點的性能瓶頸。
Peer-to-Peer:即直接通過 P2P 通信機制在不同實例間傳輸 KV Cache,避免了中心化的存儲,且具有更好的容錯與動態擴縮容的能力的支持。
自動擴縮容
目前 Kubernetes 的生態系統中被廣泛使用的自動擴縮容工具主要有以下三個:
HPA(Horizontal Pod Autoscaler):Kubernetes 的水平擴縮器
KPA(Knative Pod Autoscaler):Knative 的水平擴縮器
KEDA(Kubernetes Event-driven Autoscaling):事件驅動的服務擴縮器,支持服務的從零到一部署
而針對 LLM 推理服務的自動擴縮容,其關鍵在于如何決定觸發自動擴縮容的指標。AIBrix 的演講者在 vLLM Meetup Beijing 分享了與傳統的微服務的自動擴縮容不同,LLM 推理請求的 QPS 可能與產生的延遲并不是正相關的,且 SM Active 等 GPU 指標也不一定能及時反映出指標的變化。因此,如何基于 LLM 推理的特性來進行可靠的自動擴縮容仍然是需要探索的問題。長期來看,筆者認為 LLM 推理服務的自動擴縮容也有可能會由 Reactive 逐漸發展到 Proactive 甚至是 Predictive 的形態(如時間序列分析與基于強化學習的預測)。
討 論
推理引擎
筆者在 2023 年末的時候就開始使用 vLLM 部署 LLM,在當時主流的幾個推理框架當中,基于?PagedAttenton?的 vLLM 無論從性能上還是易用性的角度來看都是屬于前列的,當時同期的一些推理引擎如 Microsoft 的 DeepSpeed-MII 與 NVIDIA 的 TensorRT-LLM 都不是其競爭對手。直到隨后同樣來自 UCB 的 Sky Computing Lab 所開源的基于?RadixAttention?的 SGLang 的出現才讓 vLLM 的壟斷地位受到了挑戰,當前 vLLM 與 SGLang 兩者社區的發展都相當迅速。
AIBrix 與 llm-d 等項目都將 vLLM 作為首個接入的推理,Dynamo 在前兩者之上又兼容了 NVIDIA 自身的 TersorRT-LLM,而 OME 作為 SGLang 社區開源的框架對 SGLang 提供了第一方的支持。在編排側的一些框架會選擇兼容更多種類的底層推理引擎,如使用?LWS?來作為有狀態服務的抽象(如 llm-d 與 OME)。LWS 是 Kubernetes SIGs 所提出的用于封裝主從 StatefulSet 的抽象,它為在 Kubernetes 上運行像 LLM 推理這樣的復雜有狀態應用提供了標準化的范式。
基于 Kubernetes 的分布式推理
由目前 AIBrix 與 llm-d 等框架的設計上來看,將負載均衡與 KV Cache 管理等功能由推理引擎的層面上升到集群編排的層面去解決是目前的主流趨勢,編排側能夠更好地與現有的集群資源管理系統(如 Kubernetes)的生態系統集成,避免一些重復性的工作,推理引擎也可以關注在內部的推理過程優化,只需要暴露一些特定的抽象與接口供編排側對接。
另一方面,隨著 LLM 的興起,很多早年專注于傳統 MLOps 生態的 Kubernetes 生態的項目都在嘗試向 LLM 生態靠攏,比如 Kubeflow 的子項目 Trainer(Training Operator)與 KServe 目前新的版本都在引入第一方的 LLM 支持,嘗試往 LLMOps 靠攏,這對平臺側用戶而言可以以更小的成本由 MLOps 向 LLMOps 轉型,能更加便利地與 LLM 的生態系統集成。近期,SGLang 社區也開源了與 Oracle 合作的 OME,除了推理服務的集成,OME 也關注在模型管理的能力。此外,除了 Kubernetes 生態系統以外,Ray 近期也基于 Ray Data 與 Ray Serve 與提供對 LLM 相關功能的第一方支持。
從分布式推理到分離式推理
除了前文所提及的 PD 分離以及 KV Cache 管理之外,目前基于基礎設施層的分離式推理(Disaggregated Inference)也是被廣泛討論的話題,即模塊化地拆分推理的各個模塊形成分離式的部署,彼此之間通過協議傳輸數據。目前學術界與工業界的相關工作如下所示,展示了未來大規模推理的基礎設施可能的發展方向:
Prefill / Decode Disaggregation
Splitwise: Efficient generative LLM inference using phase splitting, https://arxiv.org/abs/2311.18677
DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving, https://arxiv.org/abs/2401.09670
Mooncake: A KVCache-centric Disaggregated Architecture for LLM Serving, https://arxiv.org/abs/2407.00079
MoE Attention / FFN Disaggregation
MegaScale-Infer: Serving Mixture-of-Experts at Scale with Disaggregated Expert Parallelism, https://arxiv.org/abs/2504.02263
Step-3 is Large yet Affordable: Model-system Co-design for Cost-effective Decoding, https://arxiv.org/abs/2507.19427
MM Encode Disaggregation
Efficiently Serving Large Multimodal Models Using EPD Disaggregation, https://arxiv.org/abs/2501.05460
結 語
基于 Kubernetes 的分布式推理框架目前仍處于百家爭鳴的階段,各個公司也都分別提出了各自的解決方案,如字節跳動的 AIBrix,Red Hat、Google 與 IBM 的 llm-d,以及 NVIDIA 的 Dynamo 等。這些公司也都積極與包括 vLLM 與 SGLang 在內的推理引擎的社區緊密合作,期望推理引擎提供必要的接口與抽象供上層的編排框架使用,以期能夠更加方便地與推理引擎集成,從而能以更低的成本得到更好的推理性能并提高部署的性價比。
分布式推理框架也在不斷吸收學術界所提出的解決方案,集成了如 PD 分離、LLM 特有的負載均衡策略以及更加動態的 KV Cache 管理等功能,學術界與工業界的緊密合作筆者認為是在未來一段時間內在該領域的常態,也因此負責推理的工程師更加需要關注前沿的學術成果與開源社區的動態,才能根據自身的使用場景與使用需求提出更好的解決方案。
參 考
NVIDIA. A Comprehensive Guide to NIM LLM Latency-Throughput Benchmarking
Austin et al. All About Transformer Inference | How To Scale Your Model, Google DeepMind. (2025)
Bo Jiang and Sherlock Xu. The Shift to Distributed LLM Inference: 3 Key Technologies Breaking Single-Node Bottlenecks (2025)
Fog Dong and Sherlock Xu. 25x Faster Cold Starts for LLMs on Kubernetes (2025)
Yu et al. Orca: A Distributed Serving System for Transformer-Based Generative Models, OSDI 2022. https://www.usenix.org/conference/osdi22/presentation/yu
Patel et al. Splitwise: Efficient Generative LLM Inference Using Phase Splitting. arXiv:2311.18677 (2024)
Zhong et. al. DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving, OSDI 2024. https://www.usenix.org/conference/osdi24/presentation/zhong-yinmin
QIn et al. Mooncake: Trading More Storage for Less Computation — A KV Cache-centric Architecture for Serving LLM Chatbot, FAST 2025, https://www.usenix.org/conference/fast25/presentation/qin
Qin et al. Mooncake: A KV Cache-centric Disaggregated Architecture for LLM Serving. arXiv:2407.00079 (2024)
Sheng et al. Fairness in Serving Large Language Models, OSDI 2024. https://www.usenix.org/conference/osdi24/presentation/sheng
Liu et al. CacheGen: KV Cache Compression and Streaming for Fast Large Language Model Serving. SIGCOMM 2024. 10.1145/3651890.3672274
Yao et al. CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion. EuroSys 2025. 10.1145/3689031.3696098
Srivatsa et al. Preble: Efficient Distributed Prompt Scheduling for LLM Serving. ICLR 2025. arXiv:2407.00023
Lou et al. Towards Swift Serverless LLM Cold Starts with ParaServe. arXiv:2502.15524v1 (2025)
Zhu et al. MegaScale-Infer: Serving Mixture-of-Experts at Scale with Disaggregated Expert Parallelism. arxiv:2504.02263 (2025)
Wang et al. Step-3 is Large yet Affordable: Model-system Co-design for Cost-effective Decoding. arxiv:2507.19427 (2025)
Singl et al. Efficiently Serving Large Multimodal Models Using EPD Disaggregation. arxiv:2501.05460 (2024)
Zhu et al. PolyServe: Efficient Multi-SLO Serving at Scale. arxiv:2507.17769 (2025)
Prefix Caching 詳解:實現 KV Cache 的跨請求高效復用 | Se7en的架構筆記 (2025)
Ce Gao. 在 Kubernetes 中 Autoscale LLM 的實踐 (2024)
AIBrix 團隊. AIBrix v0.3.0 發布:KVCache 多級卸載、前綴緩存、公平路由與基準測試工具 (2025)
BentoML. LLM Inference Handbook (2025)
[PUBLIC] llm-d Autoscaling Northstar - Google 文檔
[PUBLIC] llm-d Disaggregated Serving Northstar - Google 文檔





)



:使用 Arduino IDE 對 ESP8266 進行編程并刷新其內存)








)
