論文信息
論文標題: Multi-Agent Based Character Simulation for Story Writing - In2Writing 2025
論文作者: Tian Yu, Ken Shi, Zixin Zhao, Gerald Penn
論文鏈接: https://aclanthology.org/2025.in2writing-1.9/
論文領域: 故事生成,多智能體系統,角色模擬
研究背景
近年來,大型語言模型(LLMs)在文本連貫性和流暢性方面取得了顯著進展,研究者們開始將LLMs應用于自動故事生成和人機協作寫作任務。傳統的故事生成方法通常包含兩個階段:規劃階段(sequencing events)和生成階段(elaborating events into scenes)。然而,現有的LLM生成故事仍存在諸多問題,如缺乏趣味性(由于線性敘事結構)、角色不一致、邏輯矛盾等問題,論文通過分析 Dramatron 和 Agents Room 兩篇經典論文總結問題為以下三點:
- 如何在保持敘事連貫性的同時,生成更具趣味性和非線性結構的故事?
- 如何有效模擬故事中角色的行為,使其更加真實可信?
- 如何將故事生成過程模塊化,以便更好地與人類作家協作?
創新點
論文提出的解決方案可總結為以下四點創新:
- 角色模擬策略:首次將fabula和syuzhet概念整合到一個統一的故事生成過程中
- 兩階段生成框架:將故事生成分解為角色扮演(role-play)和重寫(rewrite)兩個步驟
- 多智能體協作機制:引入導演智能體和角色智能體,實現更真實的角色模擬
- 人機協作設計:系統設計考慮了人類作家可以作為獨立智能體參與角色扮演過程
核心思想與方法論
該系統借鑒了敘事理論中的“故事時間”(syuzhet)和“事件時間”(fabula)概念 。
- 事件時間 (Fabula): 指事件發生的原始、按時間順序排列的序列,是故事世界的底層敘事 。在論文的框架中,角色扮演步驟負責構建這個“事件時間” 。
- 故事時間 (Syuzhet): 指故事最終呈現給讀者的順序,可以是非線性的,以增強戲劇效果和觀眾參與度 。重寫步驟則將角色扮演的中間結果重塑為最終的“故事時間”形式 。
該方法包含以下兩個主要步驟:
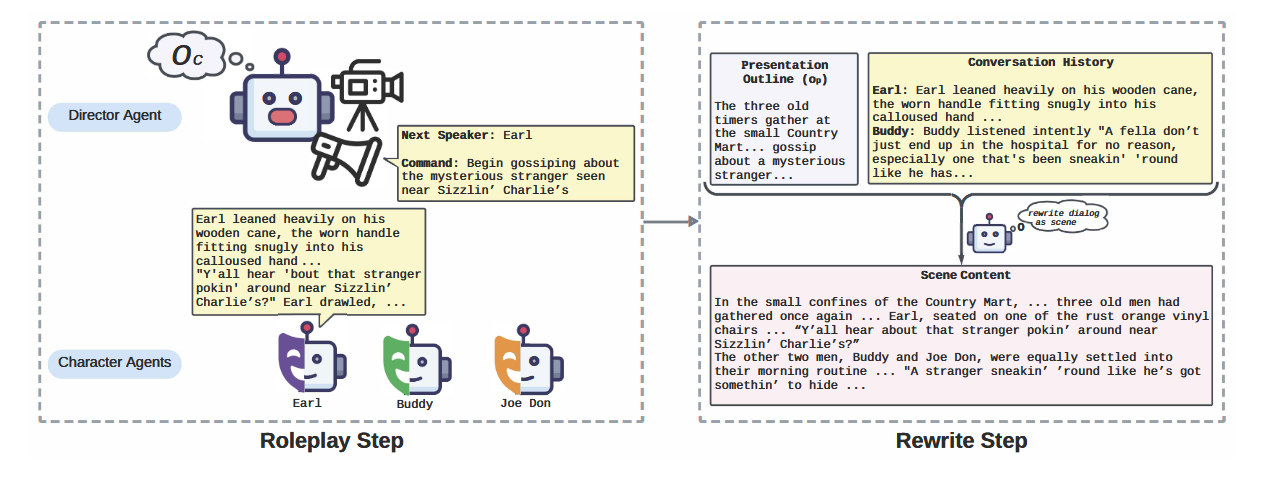
角色扮演步驟 (Role-playing Step)
-
目的: 模擬故事的“事件時間”(fabula),即事件的嚴格時間順序 。
-
工作流程:
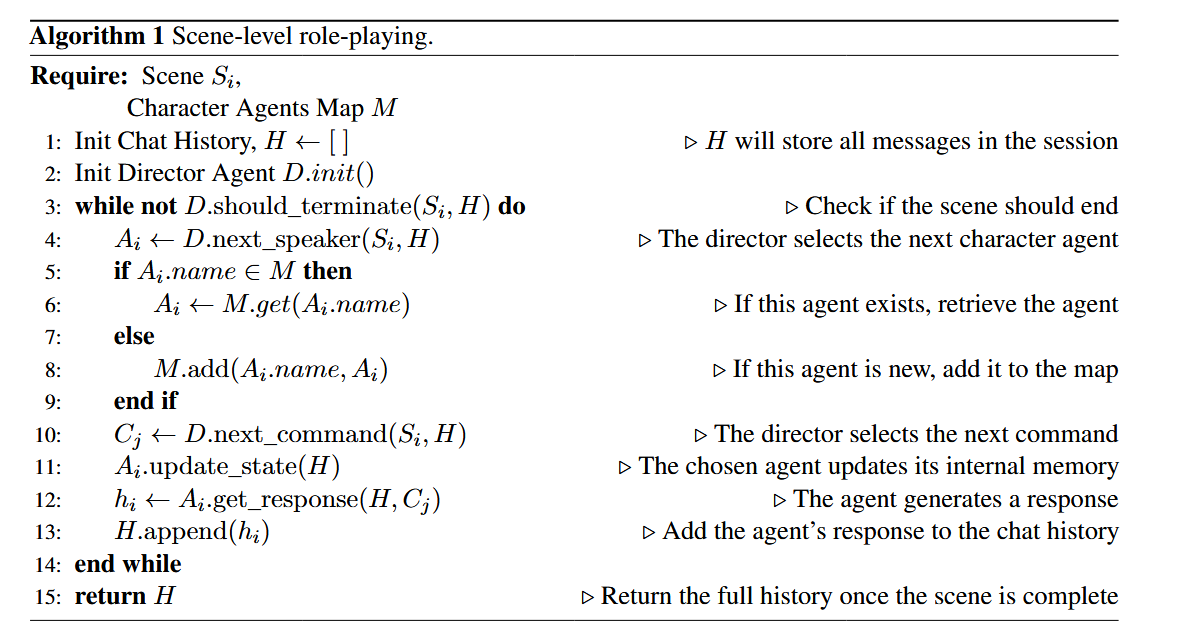
- 系統首先接收一個包含場景列表的輸入計劃 PpP_pPp?,該計劃指定了故事的呈現順序(故事時間,syuzhet)。
- 利用一個基于 LLM 的排序算法,將 PpP_pPp? 中的場景重新排列成嚴格按時間順序排列的角色扮演計劃 PcP_cPc?。類似地,場景內部的事件大綱 opo_pop? 也會被重新排序成時間大綱 oco_coc?
- 系統定義了兩種智能體:
- 導演智能體 (Director Agent):負責控制場景的發展,選擇下一個發言的角色智能體,并向其發出行動指令 (command) 。
- 角色智能體 (Character Agent):根據其目標、身體狀態和記憶,對導演的指令做出回應,并以第三人稱視角描述對話和行動
- 角色扮演過程類似于一個“群聊”管理,導演智能體根據時間大綱 oco_coc? 引導角色智能體進行模擬,直到場景結束。
- 角色智能體擁有一個基于文本的記憶和身體狀態系統,可以根據新的聊天歷史進行更新,以保持一致性 。
重寫步驟 (Rewrite Step)
- 目的: 將角色扮演的輸出(事件時間)精煉成符合原始計劃呈現順序(故事時間)的最終故事文本 。
- 工作流程:
- 重寫算法依次處理原始輸入計劃 PpP_pPp? 中指定的每個場景,并按照其呈現順序生成內容 。
- 系統提示 LLM,根據原始的呈現大綱 opo_pop? 撰寫場景內容,并參考角色扮演步驟中生成的對話和行動模擬結果 。
- 這種模塊化的方法允許作者在生成下一個場景之前對當前場景的內容進行修改 。
實驗與評估
數據集與設置
- 數據集: 使用了名為“Tell Me A Story”的數據集,該數據集包含復雜的寫作提示和人工撰寫的故事 。作者通過 UMAP 和 k-means 聚類方法對數據集進行了分析,并選擇了 28 個代表性提示進行實驗 。
- 對比方法:
- 單一智能體方法:Dramatron 。
- 多智能體方法:Agents’ Room 。
- 實驗流程:
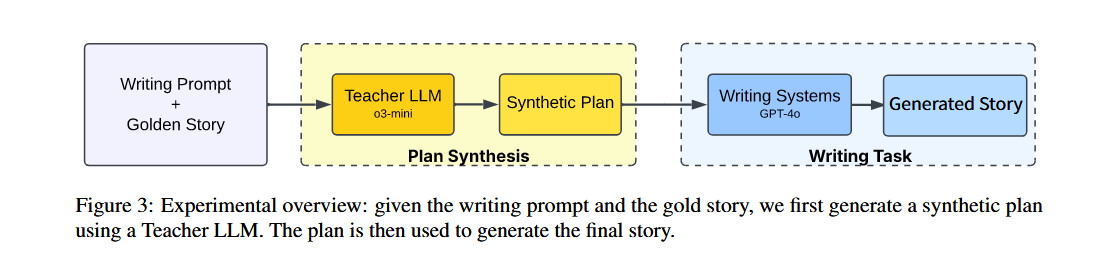
- 通過一個“教師 LLM”(03-mini)從“黃金故事”中合成一個“合成計劃”,然后將該計劃作為輸入,讓三種寫作系統(Dramatron、Agents’ Room 和本論文提出的系統)生成故事 。
- 所有系統均使用 GPT-4o 模型,并采用零樣本(zero-shot)提示策略,以確保公平比較 。
評估方法
- 自動評估: 采用基于 LLM 的評估器,靈感來自 Agents’ Room 的評估方法 。采用兩篇文章選擇其中一篇的方式,實現通過設定 prompt 讓 LLM 進行選擇,如下圖所示。
- 評估標準: 評估器根據四個標準對故事進行兩兩比較:情節(Plot)、創意(Creativity)、發展(Development)和語言使用(Language Use)。同時還包括一個單獨的“總體”(Overall)標準 。
- 評估模型: 使用 Gemini 1.5 Pro 作為評估模型 。
- 結果分析: 使用 Bradley-Terry 模型將兩兩比較結果線性化,得到各系統的潛在能力參數(strength)。

實驗結果
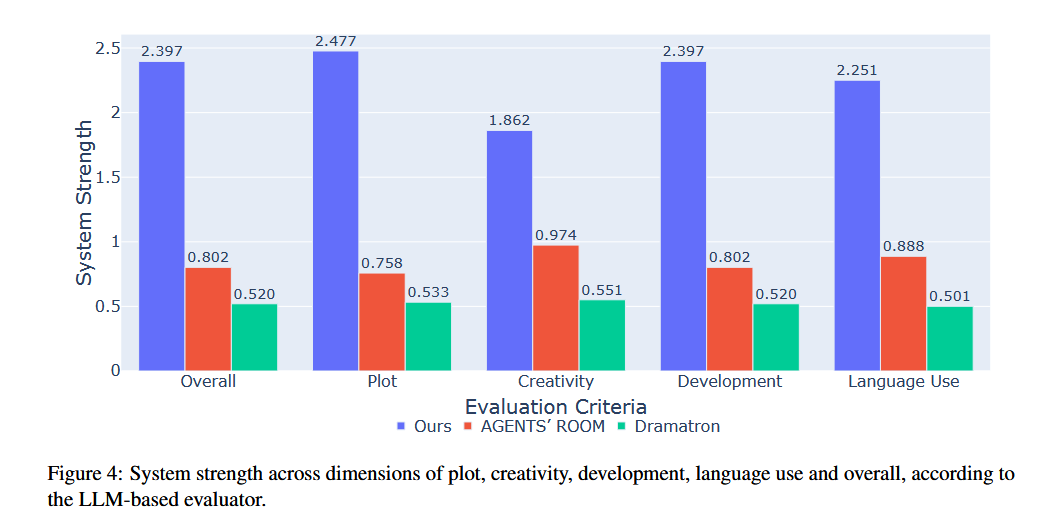
- LLM 評估結果: 在所有評估標準(總體、情節、創意、發展和語言使用)上,作者提出的系統都顯著優于 Agents’ Room 和 Dramatron 。
- 定性分析:
- 作者的系統在角色一致性和敘事連貫性方面表現更好 。
- 通過一個具體的例子(train 026),論文解釋了其優勢:由于采用了時間順序的角色扮演,角色智能體(Aerie)在扮演第一個場景(與 Kissen 會面)之前已經有了第二個場景(回顧早期旅程)的記憶,從而避免了其他系統可能出現的幻覺或過早劇透問題 。
- 其他方法存在問題,例如 Agents’ Room 可能會出現重復或無關的詞語,這可能是因為其生成過程約束較弱 。
結論
- 結論: 該論文首次將“事件時間”和“故事時間”的概念整合到一個統一的故事生成流程中 。通過角色扮演步驟生成“事件時間”,再通過重寫步驟將其修改為“故事時間”,實現了作者意圖和角色驅動對話之間的自然平衡 。這種方法利用角色模擬結果,大大降低了實際故事內容創作的難度 。
- 未來工作:
- 改進排序算法,以更好地處理包含閃回等復雜時間結構的場景 。
- 在角色扮演過程中實施明確的隱私控制,以防止智能體訪問其不應獲取的信息 。
- 探索將人類參與者更有效地整合到創作流程中的方法 。


)




)





上部署Oracle 11g、19C RAC詳細圖文教程)


)
![6-7 TIM編碼器接口 [江科協STM32]](http://pic.xiahunao.cn/6-7 TIM編碼器接口 [江科協STM32])

