mmsegmentation的使用教程
mmsegmentation微調方法總結
- 自定義自己的數據集:
mmsegmentation\configs\_base_\datasets\ZihaoDataset_pipeline.py - 注冊:
mmsegmentation\configs\_base_\datasets\__init__.py - 定義訓練和測試的pipeline:
mmsegmentation\configs\_base_\datasets\ZihaoDataset_pipeline.py,修改關鍵參數(與之前匹配) - 融合預訓練模型:
configs/fastscnn/fast_scnn_8xb4-160k_cityscapes-512x1024.py和pipeline:mmsegmentation\configs\_base_\datasets\ZihaoDataset_pipeline.py文件,注意微調分割頭!!!,注意微調分割頭!!!,注意微調分割頭!!! - 得到最后的config文件
ZihaoDataset_FastSCNN_20230818.py - 下載預訓練模型:修改
mmsegmentation\configs\segformer\segformer_mit-b5_8xb2-160k_ade20k-512x512.py的pth路徑,避免下載! - 訓練:命令
tools/train.py Zihao-Configs/ZihaoDataset_PSPNet_20230818.py,默認使用預訓練模型開始微調 - 測試:需要用到訓練時的
.pth文件 - 推理:根據融合后的config文件和
.pth文件調用inference_model()API對圖片進行推理。 - 可視化:可以使用官方提供的針對單個圖片的可視化結果
- 所有指標和日志保存在
work_dirs/xxx/.json文件下,如果需要單個class的指標結果,可以使用.log文件匹配。 - 注意:opencv加載圖片的格式是:bgr格式
自定義數據集mmsegmentation\mmseg\datasets\ZihaoDataset.py
- 繼承
BaseSegDataset:from .basesegdataset import BaseSegDataset
class ZihaoDataset(BaseSegDataset):
- 類別和RGB標簽的映射關系
METAINFO = {'classes':['background', 'red', 'green', 'white', 'seed-black', 'seed-white'],'palette':[[127,127,127], [200,0,0], [0,200,0], [144,238,144], [30,30,30], [251,189,8]]}
- 指定圖像擴展名、標注擴展名
def __init__(self,seg_map_suffix='.png', # 標注mask圖像的格式reduce_zero_label=False, # 類別ID為0的類別是否需要除去**kwargs) -> None:super().__init__(seg_map_suffix=seg_map_suffix,reduce_zero_label=reduce_zero_label,**kwargs)
from mmseg.registry import DATASETS
from .basesegdataset import BaseSegDataset@DATASETS.register_module()
class ZihaoDataset(BaseSegDataset):# 類別和對應的 RGB配色METAINFO = {'classes':['background', 'red', 'green', 'white', 'seed-black', 'seed-white'],'palette':[[127,127,127], [200,0,0], [0,200,0], [144,238,144], [30,30,30], [251,189,8]]}# 指定圖像擴展名、標注擴展名def __init__(self,seg_map_suffix='.png', # 標注mask圖像的格式reduce_zero_label=False, # 類別ID為0的類別是否需要除去**kwargs) -> None:super().__init__(seg_map_suffix=seg_map_suffix,reduce_zero_label=reduce_zero_label,**kwargs)
注冊修改mmsegmentation\mmseg\datasets\__init__.py
- 導入
ZihaoDataset
from .ZihaoDataset import ZihaoDataset
__all__后面加入'ZihaoDataset'
# yapf: enable
__all__ = ['BaseSegDataset', 'BioMedical3DRandomCrop', 'BioMedical3DRandomFlip','CityscapesDataset', 'PascalVOCDataset', 'ADE20KDataset','PascalContextDataset', 'PascalContextDataset59', 'ChaseDB1Dataset','DRIVEDataset', 'HRFDataset', 'STAREDataset', 'DarkZurichDataset','NightDrivingDataset', 'COCOStuffDataset', 'LoveDADataset','MultiImageMixDataset', 'iSAIDDataset', 'ISPRSDataset', 'PotsdamDataset','LoadAnnotations', 'RandomCrop', 'SegRescale', 'PhotoMetricDistortion','RandomRotate', 'AdjustGamma', 'CLAHE', 'Rerange', 'RGB2Gray','RandomCutOut', 'RandomMosaic', 'PackSegInputs', 'ResizeToMultiple','LoadImageFromNDArray', 'LoadBiomedicalImageFromFile','LoadBiomedicalAnnotation', 'LoadBiomedicalData', 'GenerateEdge','DecathlonDataset', 'LIPDataset', 'ResizeShortestEdge','BioMedicalGaussianNoise', 'BioMedicalGaussianBlur','BioMedicalRandomGamma', 'BioMedical3DPad', 'RandomRotFlip','SynapseDataset', 'REFUGEDataset', 'MapillaryDataset_v1','MapillaryDataset_v2', 'Albu', 'LEVIRCDDataset','LoadMultipleRSImageFromFile', 'LoadSingleRSImageFromFile','ConcatCDInput', 'BaseCDDataset', 'DSDLSegDataset', 'BDD100KDataset','ZihaoDataset'
]
`mmsegmentation\mmseg相當于源碼部分
在configs中自定義訓練和測試pipeline mmsegmentation\configs\_base_\datasets\ZihaoDataset_pipeline.py
必須修改的地方有:
- 類名和數據集根地址,注意接下來的
img_path和seg_map_path參數會和data_root拼接在一起 - 還包括一些數據增強和訓練相關的參數。
dataset_type = 'ZihaoDataset' # 數據集類名
data_root = 'Watermelon87_Semantic_Seg_Mask/' # 數據集路徑(相對于mmsegmentation主目錄)
img_path和seg_map_path參數
train_dataloader = dict(batch_size=2,num_workers=2,persistent_workers=True,sampler=dict(type='InfiniteSampler', shuffle=True),dataset=dict(type=dataset_type,data_root=data_root,data_prefix=dict(img_path='img_dir/train', seg_map_path='ann_dir/train'),pipeline=train_pipeline))# 驗證 Dataloader
val_dataloader = dict(batch_size=1,num_workers=4,persistent_workers=True,sampler=dict(type='DefaultSampler', shuffle=False),dataset=dict(type=dataset_type,data_root=data_root,data_prefix=dict(img_path='img_dir/val', seg_map_path='ann_dir/val'),pipeline=test_pipeline))
# 數據處理 pipeline
# 數據集路徑
dataset_type = 'ZihaoDataset' # 數據集類名
data_root = 'Watermelon87_Semantic_Seg_Mask/' # 數據集路徑(相對于mmsegmentation主目錄)# 輸入模型的圖像裁剪尺寸,一般是 128 的倍數,越小顯存開銷越少
crop_size = (512, 512)# 訓練預處理
train_pipeline = [dict(type='LoadImageFromFile'),dict(type='LoadAnnotations'),dict(type='RandomResize',scale=(2048, 1024),ratio_range=(0.5, 2.0),keep_ratio=True),dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),dict(type='RandomFlip', prob=0.5),dict(type='PhotoMetricDistortion'),dict(type='PackSegInputs')
]# 測試預處理
test_pipeline = [dict(type='LoadImageFromFile'),dict(type='Resize', scale=(2048, 1024), keep_ratio=True),dict(type='LoadAnnotations'),dict(type='PackSegInputs')
]# TTA后處理(增強性能的技巧)
img_ratios = [0.5, 0.75, 1.0, 1.25, 1.5, 1.75] # 先縮放后全部加權得到結果
tta_pipeline = [dict(type='LoadImageFromFile', file_client_args=dict(backend='disk')),dict(type='TestTimeAug',transforms=[[dict(type='Resize', scale_factor=r, keep_ratio=True)for r in img_ratios],[dict(type='RandomFlip', prob=0., direction='horizontal'),dict(type='RandomFlip', prob=1., direction='horizontal')], [dict(type='LoadAnnotations')], [dict(type='PackSegInputs')]])
]# 訓練 Dataloader
train_dataloader = dict(batch_size=2,num_workers=2,persistent_workers=True,sampler=dict(type='InfiniteSampler', shuffle=True),dataset=dict(type=dataset_type,data_root=data_root,data_prefix=dict(img_path='img_dir/train', seg_map_path='ann_dir/train'),pipeline=train_pipeline))# 驗證 Dataloader
val_dataloader = dict(batch_size=1,num_workers=4,persistent_workers=True,sampler=dict(type='DefaultSampler', shuffle=False),dataset=dict(type=dataset_type,data_root=data_root,data_prefix=dict(img_path='img_dir/val', seg_map_path='ann_dir/val'),pipeline=test_pipeline))# 測試 Dataloader
test_dataloader = val_dataloader# 驗證 Evaluator
val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU', 'mDice', 'mFscore'])# 測試 Evaluator
test_evaluator = val_evaluator
微調(遷移學習)方法
- 導入兩個py文件,一個是預訓練模型的文件
configs/fastscnn/fast_scnn_8xb4-160k_cityscapes-512x1024.py - 一個是我們定義好的訓練和測試pipeline文件
./configs/_base_/datasets/ZihaoDataset_pipeline.py - 兩個要結合起來
from mmengine import Config
cfg = Config.fromfile('configs/fastscnn/fast_scnn_8xb4-160k_cityscapes-512x1024.py')
dataset_cfg = Config.fromfile('./configs/_base_/datasets/ZihaoDataset_pipeline.py')
cfg.merge_from_dict(dataset_cfg)
微調方法
- 修改分割頭
NUM_CLASS = 6
cfg.norm_cfg = dict(type='BN', requires_grad=True) # 只使用GPU時,BN取代SyncBN
cfg.model.backbone.norm_cfg = cfg.norm_cfg
cfg.model.decode_head.norm_cfg = cfg.norm_cfgcfg.dump('Zihao-Configs/ZihaoDataset_FastSCNN_20230818.py')
cfg.model.auxiliary_head[0].norm_cfg = cfg.norm_cfg
cfg.model.auxiliary_head[1].norm_cfg = cfg.norm_cfg# 模型 decode/auxiliary 輸出頭,指定為類別個數
cfg.model.decode_head.num_classes = NUM_CLASS
cfg.model.auxiliary_head[0]['num_classes'] = NUM_CLASS
cfg.model.auxiliary_head[1]['num_classes'] = NUM_CLASScfg.train_dataloader.batch_size = 4cfg.test_dataloader = cfg.val_dataloader# 結果保存目錄
cfg.work_dir = './work_dirs/ZihaoDataset-FastSCNN'cfg.train_cfg.max_iters = 30000 # 訓練迭代次數
cfg.train_cfg.val_interval = 500 # 評估模型間隔
cfg.default_hooks.logger.interval = 100 # 日志記錄間隔
cfg.default_hooks.checkpoint.interval = 2500 # 模型權重保存間隔
cfg.default_hooks.checkpoint.max_keep_ckpts = 2 # 最多保留幾個模型權重
cfg.default_hooks.checkpoint.save_best = 'mIoU' # 保留指標最高的模型權重# 隨機數種子
cfg['randomness'] = dict(seed=0)
保存為最終的Config配置文件
cfg.dump('Zihao-Configs/ZihaoDataset_FastSCNN_20230818.py')
修改預訓練模型
mmsegmentation\configs\segformer\segformer_mit-b5_8xb2-160k_ade20k-512x512.py:默認會下載預訓練模型(見下面的url鏈接),可以手動修改為預先下載的文件。
_base_ = ['./segformer_mit-b0_8xb2-160k_ade20k-512x512.py']# checkpoint = 'https://download.openmmlab.com/mmsegmentation/v0.5/pretrain/segformer/mit_b5_20220624-658746d9.pth' # noqa
checkpoint = 'C:\\Users\\ASUS\\PycharmProjects\\pythonProject\\research\\MMSegmentation_Tutorials-main\\MMSegmentation_Tutorials-main\\20230816\\mmsegmentation\\pretrained\\mit_b5_20220624-658746d9.pth' # noqa
# model settings
model = dict(backbone=dict(init_cfg=dict(type='Pretrained', checkpoint=checkpoint),embed_dims=64,num_heads=[1, 2, 5, 8],num_layers=[3, 6, 40, 3]),decode_head=dict(in_channels=[64, 128, 320, 512]))訓練細節
08/02 12:35:34 - mmengine - INFO - Iter(val) [11/11] aAcc: 87.5900 mIoU: 56.0600 mAcc: 71.7300 mDice: 65.9000 mFscore: 79.0800 mPrecision: 75.2700 mRecall: 71.7300 data_time: 0.0069 time: 0.0345
08/02 12:35:47 - mmengine - INFO - Iter(train) [ 9600/10000] lr: 1.1351e-01 eta: 0:00:50 time: 0.1238 data_time: 0.0031 memory: 864 loss: 0.0688 decode.loss_ce: 0.0305 decode.acc_seg: 92.9966 aux_0.loss_ce: 0.0163 aux_0.acc_seg: 87.6057 aux_1.loss_ce: 0.0220 aux_1.acc_seg: 87.0640
08/02 12:35:59 - mmengine - INFO - Iter(train) [ 9700/10000] lr: 1.1344e-01 eta: 0:00:37 time: 0.1298 data_time: 0.0033 memory: 864 loss: 0.1297 decode.loss_ce: 0.0651 decode.acc_seg: 71.6496 aux_0.loss_ce: 0.0297 aux_0.acc_seg: 69.3979 aux_1.loss_ce: 0.0349 aux_1.acc_seg: 58.9588
08/02 12:36:12 - mmengine - INFO - Iter(train) [ 9800/10000] lr: 1.1337e-01 eta: 0:00:25 time: 0.1242 data_time: 0.0031 memory: 864 loss: 0.1223 decode.loss_ce: 0.0587 decode.acc_seg: 51.1257 aux_0.loss_ce: 0.0292 aux_0.acc_seg: 53.5561 aux_1.loss_ce: 0.0345 aux_1.acc_seg: 46.3654
08/02 12:36:25 - mmengine - INFO - Iter(train) [ 9900/10000] lr: 1.1330e-01 eta: 0:00:12 time: 0.1261 data_time: 0.0032 memory: 864 loss: 0.0845 decode.loss_ce: 0.0380 decode.acc_seg: 86.1641 aux_0.loss_ce: 0.0210 aux_0.acc_seg: 77.3401 aux_1.loss_ce: 0.0255 aux_1.acc_seg: 62.3304
08/02 12:36:37 - mmengine - INFO - Exp name: ZihaoDataset_FastSCNN_20230818_20250802_121506
08/02 12:36:37 - mmengine - INFO - Iter(train) [10000/10000] lr: 1.1323e-01 eta: 0:00:00 time: 0.1213 data_time: 0.0031 memory: 864 loss: 0.0956 decode.loss_ce: 0.0432 decode.acc_seg: 93.6745 aux_0.loss_ce: 0.0243 aux_0.acc_seg: 90.1726 aux_1.loss_ce: 0.0281 aux_1.acc_seg: 90.2538
08/02 12:36:37 - mmengine - INFO - Saving checkpoint at 10000 iterations
08/02 12:36:38 - mmengine - INFO - per class results:
08/02 12:36:38 - mmengine - INFO -
+------------+-------+-------+-------+--------+-----------+--------+
| Class | IoU | Acc | Dice | Fscore | Precision | Recall |
+------------+-------+-------+-------+--------+-----------+--------+
| background | 85.65 | 89.88 | 92.27 | 92.27 | 94.79 | 89.88 |
| red | 81.3 | 98.28 | 89.69 | 89.69 | 82.47 | 98.28 |
| green | 59.15 | 67.73 | 74.33 | 74.33 | 82.37 | 67.73 |
| white | 58.04 | 69.85 | 73.45 | 73.45 | 77.44 | 69.85 |
| seed-black | 61.43 | 78.07 | 76.11 | 76.11 | 74.24 | 78.07 |
| seed-white | 0.0 | 0.0 | 0.0 | nan | nan | 0.0 |
+------------+-------+-------+-------+--------+-----------+--------+
08/02 12:36:38 - mmengine - INFO - Iter(val) [11/11] aAcc: 88.9900 mIoU: 57.5900 mAcc: 67.3000 mDice: 67.6400 mFscore: 81.1700 mPrecision: 82.2600 mRecall: 67.3000 data_time: 0.0075 time: 0.0340
可視化數據mmsegmentation\work_dirs\ZihaoDataset-FastSCNN\20250802_121506\vis_data
在vis_data目錄下的log_path = './work_dirs/ZihaoDataset-FastSCNN/20250802_121506/vis_data/scalars.json'的文件,用于記錄整體各種指標的記錄情況。
with open(log_path, "r") as f:json_list = f.readlines()eval(json_list[4])
輸出結果如下:
{'lr': 0.11973086417099389,'data_time': 0.004000043869018555,'loss': 0.1377907693386078,'decode.loss_ce': 0.07181963995099068,'decode.acc_seg': 88.35430145263672,'aux_0.loss_ce': 0.032481906749308107,'aux_0.acc_seg': 85.88199615478516,'aux_1.loss_ce': 0.03348922152072191,'aux_1.acc_seg': 81.13632202148438,'time': 0.12697319984436034,'iter': 400,'memory': 863,'step': 400}
針對每一個類別的各種指標可視化
存儲在log文件中:work_dirs/ZihaoDataset-FastSCNN/20250802_121506/20250802_121506.log
我們要讀取的就是這種格式的指標:
+------------+-------+-------+-------+--------+-----------+--------+
| Class | IoU | Acc | Dice | Fscore | Precision | Recall |
+------------+-------+-------+-------+--------+-----------+--------+
| background | 85.65 | 89.88 | 92.27 | 92.27 | 94.79 | 89.88 |
| red | 81.3 | 98.28 | 89.69 | 89.69 | 82.47 | 98.28 |
| green | 59.15 | 67.73 | 74.33 | 74.33 | 82.37 | 67.73 |
| white | 58.04 | 69.85 | 73.45 | 73.45 | 77.44 | 69.85 |
| seed-black | 61.43 | 78.07 | 76.11 | 76.11 | 74.24 | 78.07 |
| seed-white | 0.0 | 0.0 | 0.0 | nan | nan | 0.0 |
+------------+-------+-------+-------+--------+-----------+--------+
pth權重保存路徑mmsegmentation\work_dirs\ZihaoDataset-FastSCNN
我將這個pth文件移動到mmsegmentation\pretrained\ZihaoDataset_FastSCNN_20230818.pth這個路徑下
測試方法
最終config配置文件+模型的權重文件
python tools/test.py Zihao-Configs/ZihaoDataset_FastSCNN_20230818.py pretrained/ZihaoDataset_FastSCNN_20230818.pth
默認保存路徑mmsegmentation\work_dirs\ZihaoDataset-FastSCNN\20250802_134015,與訓練的保存目錄一致。
推理
使用合并后的config配置文件和權重
載入模型
# 模型 config 配置文件
config_file = 'Zihao-Configs/ZihaoDataset_FastSCNN_20230818.py'
# 模型 checkpoint 權重文件
checkpoint_file = 'pretrained/ZihaoDataset_FastSCNN_20230818.pth'
# device = 'cpu'
device = 'cuda:0'
model = init_model(config_file, checkpoint_file, device=device)
推理過程
result = inference_model(model, img_bgr),好像要用BGR格式的圖片進行推理?返回一個result,SegDataSample類型,分為兩個東西,一個是預測的類別,一個是概率,其余就是tensor的使用方法。
result = inference_model(model, img_bgr)
result.keys() ['pred_sem_seg', 'seg_logits']
pred_mask = result.pred_sem_seg.data[0].cpu().numpy()
pred_mask.shape (1280, 1280)
result.seg_logits.data.shape torch.Size([6, 1280, 1280])
批量推理
其實就是將每個圖像都預測一下,然后與掩碼矩陣疊加一下,保存到輸出文件夾下
def process_single_img(img_path, save=False):img_bgr = cv2.imread(img_path)# 語義分割預測result = inference_model(model, img_bgr)pred_mask = result.pred_sem_seg.data[0].cpu().numpy()# 將預測的整數ID,映射為對應類別的顏色pred_mask_bgr = np.zeros((pred_mask.shape[0], pred_mask.shape[1], 3))for idx in palette_dict.keys():pred_mask_bgr[np.where(pred_mask==idx)] = palette_dict[idx]pred_mask_bgr = pred_mask_bgr.astype('uint8')# 將語義分割預測圖和原圖疊加顯示pred_viz = cv2.addWeighted(img_bgr, opacity, pred_mask_bgr, 1-opacity, 0)# 保存圖像至 outputs/testset-pred 目錄if save:save_path = os.path.join('../','../','../','outputs', 'testset-pred', 'pred-'+img_path.split('/')[-1])cv2.imwrite(save_path, pred_viz)
攝像頭推理(實時分割)
但是我沒有攝像頭😒
python demo/video_demo.py 0 Zihao-Configs/ZihaoDataset_FastSCNN_20230818.py pretrained/ZihaoDataset_FastSCNN_20230818.pth --device cuda:0 --opacity 0.5 --show
可視化
官方提供的可視化分割圖片的代碼
根據在Dataset中定義METAINFO來繪制掩碼矩陣的,最后返回處理好的圖片。
METAINFO = {'classes':['background', 'red', 'green', 'white', 'seed-black', 'seed-white'],'palette':[[127,127,127], [200,0,0], [0,200,0], [144,238,144], [30,30,30], [251,189,8]]}
from mmseg.apis import show_result_pyplot
img_viz = show_result_pyplot(model, img_path, result, opacity=0.8, title='MMSeg', out_file='outputs/K1-4.jpg')
plt.figure(figsize=(14, 8))
plt.imshow(img_viz)
plt.show()
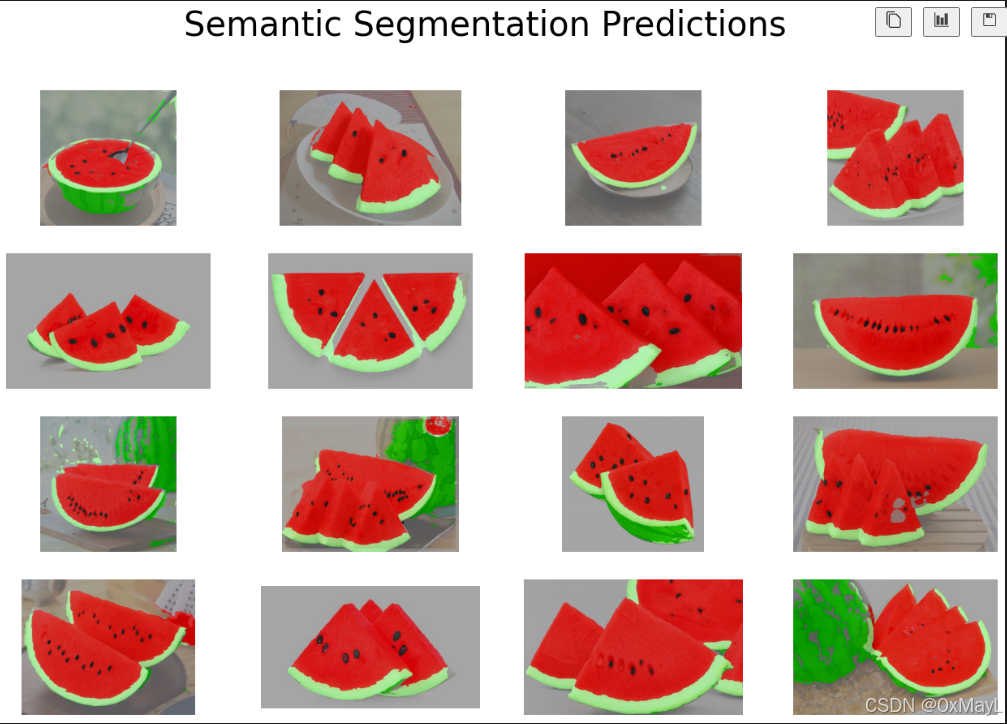
批量可視化代碼:用于獲得n行n列的圖像
不用記憶
# n 行 n 列可視化
n = 4fig, axes = plt.subplots(nrows=n, ncols=n, figsize=(16, 10))for i, file_name in enumerate(os.listdir()[:n**2]):img_bgr = cv2.imread(file_name)# 可視化axes[i//n, i%n].imshow(img_bgr[:,:,::-1])axes[i//n, i%n].axis('off') # 關閉坐標軸顯示
fig.suptitle('Semantic Segmentation Predictions', fontsize=30)
# plt.tight_layout()
plt.savefig('../K3.jpg')
plt.show()
數據集的存儲要求(待續)
整數掩碼/掩膜
- 存儲格式必須是
png,目的是為了無損

像素太小,什么都看不出來。

雖然掩碼是一個整數矩陣,但是保存為png格式時,必須存儲3通道
img.shape
mask.shape
(300, 440, 3)
(300, 440, 3)
整數掩碼轉換為RGB通道可視化
取圖像的任一一個通道,關鍵是使用np.where()
mask = mask[:,:,0]# 將整數ID,映射為對應類別的顏色
viz_mask_bgr = np.zeros((mask.shape[0], mask.shape[1], 3))
for idx in palette_dict.keys():viz_mask_bgr[np.where(mask==idx)] = palette_dict[idx]
viz_mask_bgr = viz_mask_bgr.astype('uint8')# 將語義分割標注圖和原圖疊加顯示
opacity = 0.1 # 透明度越大,可視化效果越接近原圖
label_viz = cv2.addWeighted(img, opacity, viz_mask_bgr, 1-opacity, 0)

opencv的注意事項
注意opencv載入圖片是bgr格式,要進行一個轉換img_bgr[:,:,::-1]
img_bgr = cv2.imread(img_path)


參考文獻
同濟子豪兄
)





簡介與簡單示例)

)
Day14——性能監控與調優(一))









