文章目錄
- 先言
- 一、特征工程概述
- 二、特征提取
- 1.字典特征提取(特征離散化)
- 2.文本特征提取
- 2.1英文文本提取
- 2.2中文文本提取(jieba分詞器)
- 3.TfidfVectorizer TF-IDF文本特征詞的重要程度特征提取
- 三、數據歸一化與標準化
- 1.MinMaxScaler 歸一化(Min-Max Scaling):(適合分布有界的數據)
- 2.normalize歸一化(Normalize Scaling):(適合分布有界的數據)
- 3.標準化(Z-Score Scaling):StandardScaler(適合高斯分布數據)
- 四、特征選擇與降維
- 1.方差閾值法(VarianceThreshold)剔除低方差特征
- 2.皮爾遜相關系數(Pearson correlation coefficient)
- 3.主成分分析(sklearn.decomposition.PCA)
- 結語
先言
在機器學習項目中,數據和特征決定了模型性能的上限,而優秀的特征工程能讓我們逼近這個上限。特征工程是從原始數據中提取、轉換和優化特征的過程,直接影響模型的準確性、泛化能力和訓練效率。
本文將深入探討特征工程的核心技術包括:字典特征提取(DictVectorizer)、文本特征處理(詞袋模型、TF-IDF)、數據標準化與歸一化(StandardScaler, MinMaxScaler)、特征降維(低方差過濾、PCA主成分分析)。通過理論講解與代碼實戰,幫助你掌握如何將原始數據轉化為高質量特征,為機器學習模型提供更強大的輸入!
一、特征工程概述
什么是特征工程?為什么它如此重要?
特征工程:就是對特征進行相關的處理
一般使用pandas來進行數據清洗和數據處理、使用sklearn來進行特征工程
特征工程是將任意數據(如文本或圖像)轉換為可用于機器學習的數字特征,比如:字典特征提取(特征離散化)、文本特征提取、圖像特征提取。
特征工程步驟為:
- 特征提取, 如果不是像dataframe那樣的數據,要進行特征提取,比如字典特征提取,文本特征提取
- 無量綱化(預處理)
- 歸一化
- 標準化
- 降維
- 底方差過濾特征選擇
- 主成分分析-PCA降維
二、特征提取
特征提取旨在從原始特征中提取出新的、更具表達力的特征。
1.字典特征提取(特征離散化)
sklearn.feature_extraction.DictVectorizer(sparse=True)
參數:
sparse=True返回類型為csr_matrix的稀疏矩陣
sparse=False表示返回的是數組,數組可以調用.toarray()方法將稀疏矩陣轉換為數組
-
轉換器對象:
轉換器對象調用fit_transform(data)函數,參數data為一維字典數組或一維字典列表,返回轉化后的矩陣或數組
轉換器對象get_feature_names_out()方法獲取特征名
代碼如下(示例):
from sklearn.feature_extraction import DictVectorizer
import pandas as pd
data = [{'city':'成都', 'age':30, 'temperature':200}, {'city':'重慶','age':33, 'temperature':60}, {'city':'北京', 'age':42, 'temperature':80}]
#創建字典列表特征提取對象
transfer = DictVectorizer(sparse=False)
#調用fit_transform方法,獲取轉換后的特征數組
data_new = transfer.fit_transform(data)
#打印特征數組
print(data_new)
#獲取特性名稱
print(transfer.get_feature_names_out())
[[ 30. 0. 1. 0. 200.][ 33. 0. 0. 1. 60.][ 42. 1. 0. 0. 80.]]
['age' 'city=北京' 'city=成都' 'city=重慶' 'temperature']
當sparse=True時,返回一個三元組的稀疏矩陣:
#獲取稀疏矩陣
transfer = DictVectorizer(sparse=True)
data_new = transfer.fit_transform(data)
#返回一個三元組稀疏矩陣
print(data_new)
返回數據結果如下:
<Compressed Sparse Row sparse matrix of dtype 'float64'with 9 stored elements and shape (3, 5)>Coords Values(0, 0) 30.0(0, 2) 1.0(0, 4) 200.0(1, 0) 33.0(1, 3) 1.0(1, 4) 60.0(2, 0) 42.0(2, 1) 1.0(2, 4) 80.0
三元組表 (Coordinate List, COO):三元組表就是一種稀疏矩陣類型數據,存儲非零元素的行索引、列索引和值:
(行,列) 數據
(0,0) 10
(0,1) 20
(2,0) 90
(2,20) 8
(8,0) 70
表示除了列出的有值, 其余全是0
我們可以對三元組表進行轉換為數組形式,可上面的數組一致,只不過通過三元組對數據進行獲取可以節省資源,示例代碼:
#對三元組矩陣進行轉換
data_new = data_new.toarray()
print(data_new)
print(transfer.get_feature_names_out())
返回結果如下:
[[ 30. 0. 1. 0. 200.][ 33. 0. 0. 1. 60.][ 42. 1. 0. 0. 80.]]
['age' 'city=北京' 'city=成都' 'city=重慶' 'temperature']補充(稀疏矩陣):
稀疏矩陣
稀疏矩陣是指一個矩陣中大部分元素為零,只有少數元素是非零的矩陣。在數學和計算機科學中,當一個矩陣的非零元素數量遠小于總的元素數量,且非零元素分布沒有明顯的規律時,這樣的矩陣就被認為是稀疏矩陣。例如,在一個1000 x 1000的矩陣中,如果只有1000個非零元素,那么這個矩陣就是稀疏的。
由于稀疏矩陣中零元素非常多,存儲和處理稀疏矩陣時,通常會采用特殊的存儲格式,以節省內存空間并提高計算效率。
2.文本特征提取
sklearn.feature_extraction.text.CountVectorizer
?構造函數關鍵字參數stop_words,值為list,表示詞的黑名單(不提取的詞)
fit_transform函數的返回值為稀疏矩陣
2.1英文文本提取
代碼如下(示例):
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
import jieba
data=["stu is well, stu is great", "You like stu"]
#創建轉換器
transfer = CountVectorizer()
#調用fit_transform方法進行提取
data_new = transfer.fit_transform(data)
#返回的數組數字代表詞頻
print(data_new.toarray())
#獲取特征名稱
print(transfer.get_feature_names_out())
#使用pandas創建字典列表
data = pd.DataFrame(data_new.toarray(),columns=transfer.get_feature_names_out(),index=['sentence1','sentence2'])
print(data)
返回結果:
[[1 2 0 2 1 0][0 0 1 1 0 1]]
['great' 'is' 'like' 'stu' 'well' 'you']great is like stu well you
sentence1 1 2 0 2 1 0
sentence2 0 0 1 1 0 1
2.2中文文本提取(jieba分詞器)
代碼如下(示例):
#中文文本提取
data = ["小明喜歡小張","小張喜歡小王","小王喜歡小李"]
#創建中文文本分割函數
def chinese_word_cut(mytext):return " ".join(jieba.cut(mytext))
data1 = [chinese_word_cut(i) for i in data]
# print(data1)
#創建詞頻統計對象
transfer = CountVectorizer()
data_new = transfer.fit_transform(data1)
print(data_new.toarray())
print(transfer.get_feature_names_out())
返回結果:
[[1 1 1 0 0][1 1 0 0 1][1 0 0 1 1]]
['喜歡' '小張' '小明' '小李' '小王']
補充:jieba是一個工具庫可以通過pip下載,jieba用于對中文進行自動分詞對于自然語言方面一個不錯的分詞工具
3.TfidfVectorizer TF-IDF文本特征詞的重要程度特征提取
詞頻(Term Frequency, TF), 表示一個詞在當前篇文章中的重要性
逆文檔頻率(Inverse Document Frequency, IDF), 反映了詞在整個文檔集合中的稀有程度

代碼與CountVectorizer的示例基本相同,僅僅把CountVectorizer改為TfidfVectorizer即可,代碼如下(示例):
import jieba
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.preprocessing import normalize
def chinese_word_cut(mytext):return " ".join(jieba.cut(mytext))
data = ["量子糾纏是物理學中一種奇妙的現象,兩個粒子即使相隔遙遠也能瞬間影響彼此的狀態。","今天早上我吃了一個蘋果,然后去公園散步,看到很多人在跳舞。","??????是一些非常罕見的漢字,它們屬于 Unicode 擴展字符集。"
]
#通過jieba對數據進行分詞
data1 = [chinese_word_cut(i) for i in data]
#創建文字稀有度統計對象
transfer =TfidfVectorizer()
#調用對象方法轉換數據
data_new = transfer.fit_transform(data1)
print(data_new.toarray())
print(transfer.get_feature_names_out())
data_new = MyTfidfVectorizer(data1)
print(data_new)
提取結果:
[[0. 0. 0. 0.25819889 0.25819889 0.0. 0.25819889 0.25819889 0. 0. 0.0.25819889 0.25819889 0. 0. 0. 0.0. 0. 0.25819889 0.25819889 0.25819889 0.258198890. 0.25819889 0.25819889 0.25819889 0. 0.0. 0.25819889 0.25819889 0. ][0. 0.31622777 0. 0. 0. 0.316227770.31622777 0. 0. 0. 0. 0.0. 0. 0.31622777 0. 0.31622777 0.316227770. 0.31622777 0. 0. 0. 0.0.31622777 0. 0. 0. 0. 0.316227770.31622777 0. 0. 0. ][0.33333333 0. 0.33333333 0. 0. 0.0. 0. 0. 0.33333333 0.33333333 0.333333330. 0. 0. 0.33333333 0. 0.0.33333333 0. 0. 0. 0. 0.0. 0. 0. 0. 0.33333333 0.0. 0. 0. 0.33333333]]
['unicode' '一個' '一些' '一種' '兩個' '今天' '公園' '即使' '奇妙' '字符集' '它們' '屬于' '影響''彼此' '很多' '擴展' '散步' '早上' '漢字' '然后' '物理學' '狀態' '現象' '相隔' '看到' '瞬間' '粒子''糾纏' '罕見' '蘋果' '跳舞' '遙遠' '量子' '非常']
自己函數實現重要程度特征提取(有興趣的可以看看):
def MyTfidfVectorizer(data):#提取詞頻TFtransfer = CountVectorizer()data_new = transfer.fit_transform(data)TF = data_new.toarray()#提取IDFIDF = np.log((len(TF)+1)/(np.sum(TF!=0,axis=0)+1))+1tf_idf = TF*IDF#l2歸一化tf_idf =normalize(tf_idf,norm='l2')return tf_idf
data_new = MyTfidfVectorizer(data1)
print(data_new)
執行后連著的結果是一樣的
三、數據歸一化與標準化
通過對原始數據進行變換把數據映射到指定區間(默認為0-1)
歸一化公式:
1.MinMaxScaler 歸一化(Min-Max Scaling):(適合分布有界的數據)
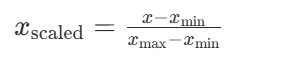
這里的 𝑥min 和 𝑥max 分別是每種特征中的最小值和最大值,而 𝑥是當前特征值,𝑥scaled 是歸一化后的特征值。
若要縮放到其他區間,可以使用公式:x=x*(max-min)+min;
比如 [-1, 1]的公式為:
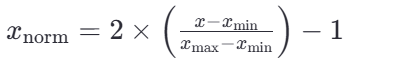
sklearn.preprocessing.MinMaxScaler(feature_range)
參數:feature_range=(0,1) 歸一化后的值域,可以自己設定
fit_transform函數歸一化的原始數據類型可以是list、DataFrame和ndarray, 不可以是稀疏矩陣
fit_transform函數的返回值為ndarray
代碼如下(示例):
#獲取數據集
iris = load_iris()
data = iris.data[:5]
print(data)
#最大最小值歸一化(MinMaxScaler)
#創建MinMaxScaler對象
transfer1 =MinMaxScaler()
#對數據進行規劃處理
data_new = transfer1.fit_transform(data)
print(data_new)
這里是以鳶尾花數據為例:
初始數據
[[5.1 3.5 1.4 0.2][4.9 3. 1.4 0.2][4.7 3.2 1.3 0.2][4.6 3.1 1.5 0.2][5. 3.6 1.4 0.2]]歸一化后數據
[[1. 0.83333333 0.5 0. ][0.6 0. 0.5 0. ][0.2 0.33333333 0. 0. ][0. 0.16666667 1. 0. ][0.8 1. 0.5 0. ]]
2.normalize歸一化(Normalize Scaling):(適合分布有界的數據)
sklearn.preprocessing.normalize(data, norm='l2', axis=1)
- norm表述normalize標準化的三種方式
<1> L1歸一化(norm=l1):絕對值相加作為分母,特征值作為分子
<2> L2歸一化(norm=l2):平方相加作為分母,特征值作為分子
<3> max歸一化(norm=max):max作為分母,特征值作為分子
代碼如下(示例):
#不用創建對象直接調用方法
#l1絕對值相加做分母
data_new= normalize(data,norm="l1",axis=1)
print(data_new)
#l2平方和做分母
data_new = normalize(data,norm="l2",axis=1)
print(data_new)
#max最大值做分母
data_new = normalize(data,norm="max",axis=1)
print(data_new)
歸一化效果:
l1歸一化
[[0.5 0.34313725 0.1372549 0.01960784][0.51578947 0.31578947 0.14736842 0.02105263][0.5 0.34042553 0.13829787 0.0212766 ][0.4893617 0.32978723 0.15957447 0.0212766 ][0.49019608 0.35294118 0.1372549 0.01960784]]
l2歸一化
[[0.80377277 0.55160877 0.22064351 0.0315205 ][0.82813287 0.50702013 0.23660939 0.03380134][0.80533308 0.54831188 0.2227517 0.03426949][0.80003025 0.53915082 0.26087943 0.03478392][0.790965 0.5694948 0.2214702 0.0316386 ]]
max歸一化
[[1. 0.68627451 0.2745098 0.03921569][1. 0.6122449 0.28571429 0.04081633][1. 0.68085106 0.27659574 0.04255319][1. 0.67391304 0.32608696 0.04347826][1. 0.72 0.28 0.04 ]]
3.標準化(Z-Score Scaling):StandardScaler(適合高斯分布數據)
在機器學習中,標準化是一種數據預處理技術,也稱為數據歸一化或特征縮放。它的目的是將不同特征的數值范圍縮放到統一的標準范圍,以便更好地適應一些機器學習算法,特別是那些對輸入數據的尺度敏感的算法。
- <1>標準化公式
最常見的標準化方法是Z-score標準化,也稱為零均值標準化。它通過對每個特征的值減去其均值,再除以其標準差,將數據轉換為均值為0,標準差為1的分布。這可以通過以下公式計算:
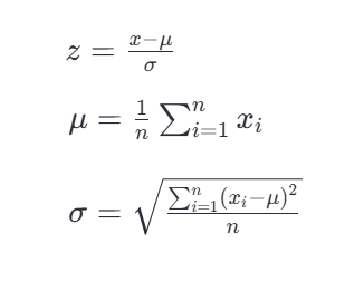
其中,z是轉換后的數值,x是原始數據的值,μ是該特征的均值,σ是該特征的 標準差
- <2> 標準化 API
sklearn.preprocessing.StandardScale
與MinMaxScaler一樣,原始數據類型可以是list、DataFrame和ndarray
fit_transform函數的返回值為ndarray, 歸一化后得到的數據類型都是ndarray
代碼示例:
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
#獲取數據集
iris = load_iris()
data = iris.data[:5]
#StandardScaler標準化
#創建標準化轉換對象
transfer = StandardScaler()
#調用fit_transform
data_new = transfer.fit_transform(data)
print(data_new)
標準化效果:
[[ 1.29399328 0.95025527 0. 0. ][ 0.21566555 -1.2094158 0. 0. ][-0.86266219 -0.34554737 -1.58113883 0. ][-1.40182605 -0.77748158 1.58113883 0. ][ 0.75482941 1.38218948 0. 0. ]]
四、特征選擇與降維
實際數據中,有時候特征很多,會增加計算量,降維就是去掉一些特征,或者轉化多個特征為少量個特征
特征降維其目的:是減少數據集的維度,同時盡可能保留數據的重要信息。
特征降維的好處:
減少計算成本:在高維空間中處理數據可能非常耗時且計算密集。降維可以簡化模型,降低訓練時間和資源需求。
去除噪聲:高維數據可能包含許多無關或冗余特征,這些特征可能引入噪聲并導致過擬合。降維可以幫助去除這些不必要的特征。
特征降維的方式:
- 特征選擇
- 從原始特征集中挑選出最相關的特征
- 主成份分析(PCA)
- 主成分分析就是把之前的特征通過一系列數學計算,形成新的特征,新的特征數量會小于之前特征數量
1.方差閾值法(VarianceThreshold)剔除低方差特征
-
Filter(過濾式): 主要探究特征本身特點, 特征與特征、特征與目標 值之間關聯-
方差選擇法: 低方差特征過濾
如果一個特征的方差很小,說明這個特征的值在樣本中幾乎相同或變化不大,包含的信息量很少,模型很難通過該特征區分不同的對象,比如區分甜瓜子和咸瓜子還是蒜香瓜子,如果有一個特征是長度,這個特征相差不大可以去掉。
- 計算方差:對于每個特征,計算其在訓練集中的方差(每個樣本值與均值之差的平方,在求平均)。
- 設定閾值:選擇一個方差閾值,任何低于這個閾值的特征都將被視為低方差特征。
- 過濾特征:移除所有方差低于設定閾值的特征
-
代碼示例:
from sklearn.datasets import load_iris
from sklearn.feature_selection import VarianceThreshold
import numpy as np
iris = load_iris()
X = iris.data[:10]
y = [1,1,1,0,0,0,1,0,1,1]
print(X)#低反差過濾特征選擇
#創建轉換器對象
transfer1 = VarianceThreshold(threshold=0.01)
data_new = transfer1.fit_transform(X)
print(data_new)
特征過濾前
[[5.1 3.5 1.4 0.2][4.9 3. 1.4 0.2][4.7 3.2 1.3 0.2][4.6 3.1 1.5 0.2][5. 3.6 1.4 0.2][5.4 3.9 1.7 0.4][4.6 3.4 1.4 0.3][5. 3.4 1.5 0.2][4.4 2.9 1.4 0.2][4.9 3.1 1.5 0.1]]經過低方差過濾后
[[5.1 3.5 1.4][4.9 3. 1.4][4.7 3.2 1.3][4.6 3.1 1.5][5. 3.6 1.4][5.4 3.9 1.7][4.6 3.4 1.4][5. 3.4 1.5][4.4 2.9 1.4][4.9 3.1 1.5]]
2.皮爾遜相關系數(Pearson correlation coefficient)
皮爾遜相關系數(Pearson correlation coefficient)是一種度量兩個變量之間線性相關性的統計量。它提供了兩個變量間關系的方向(正相關或負相關)和強度的信息。皮爾遜相關系數的取值范圍是 [?1,1],其中:
- ρ=1\rho=1ρ=1 表示完全正相關,即隨著一個變量的增加,另一個變量也線性增加。
- ρ=?1\rho=-1ρ=?1 表示完全負相關,即隨著一個變量的增加,另一個變量線性減少。
- ρ=0\rho=0ρ=0 表示兩個變量之間不存在線性關系。
相關系數
ρ\rho ρ
的絕對值為0-1之間,絕對值越大,表示越相關,當兩特征完全相關時,兩特征的值表示的向量是
在同一條直線上,當兩特征的相關系數絕對值很小時,兩特征值表示的向量接近在同一條直線上。當相關系值為負數時,表示負相關,皮爾遜相關系數:pearsonr相關系數計算公式, 該公式出自于概率論
對于兩組數據 𝑋={𝑥1,𝑥2,…,𝑥𝑛} 和 𝑌={𝑦1,𝑦2,…,𝑦𝑛},皮爾遜相關系數可以用以下公式計算:
ρ=Cos?(x,y)Dx?Dy=E[(x?Ex)(y?Ey)]Dx?Dy=∑i=1n(x?x~)(y?yˉ)/(n?1)∑i=1n(x?xˉ)2/(n?1)?∑i=1n(y?yˉ)2/(n?1)\rho=\frac{\operatorname{Cos}(x, y)}{\sqrt{D x} \cdot \sqrt{D y}}=\frac{E[(x_-E x)(y-E y)]}{\sqrt{D x} \cdot \sqrt{D y}}=\frac{\sum_{i=1}^{n}(x-\tilde{x})(y-\bar{y}) /(n-1)}{\sqrt{\sum_{i=1}^{n}(x-\bar{x})^{2} /(n-1)} \cdot \sqrt{\sum_{i=1}^{n}(y-\bar{y})^{2} /(n-1)}} ρ=Dx??Dy?Cos(x,y)?=Dx??Dy?E[(x??Ex)(y?Ey)]?=∑i=1n?(x?xˉ)2/(n?1)??∑i=1n?(y?yˉ?)2/(n?1)?∑i=1n?(x?x~)(y?yˉ?)/(n?1)?
xˉ\bar{x}xˉ和 yˉ\bar{y}yˉ? 分別是𝑋和𝑌的平均值
|ρ|<0.4為低度相關; 0.4<=|ρ|<0.7為顯著相關; 0.7<=|ρ|<1為高度相關
scipy.stats.personr(x, y) 計算兩特征之間的相關性
返回對象有兩個屬性:
- statistic皮爾遜相關系數[-1,1]
- pvalue零假設(了解),統計上評估兩個變量之間的相關性,越小越相關
代碼示例:
from sklearn.datasets import load_iris
from scipy.stats import pearsonr
import numpy as np
iris = load_iris()
X = iris.data[:10]
y = [1,1,1,0,0,0,1,0,1,1]
#相關系數過濾特征選擇
#將數據轉為numpy數組提取每一列
del1 = np.array(X)[:,0]
print(del1)
print(y)
#pearsonr可以直接計算相關系數
r1 = pearsonr(del1,y)
#輸出相關系數statistic 相關性:負數值表示負相關,正數表示正相關,0表示不相關
print(r1.statistic)
#輸出相關系數pvalue 程度相關性:pvalue的值越小,則越相關
print(r1.pvalue)
[5.1 4.9 4.7 4.6 5. 5.4 4.6 5. 4.4 4.9]
[1, 1, 1, 0, 0, 0, 1, 0, 1, 1]
-0.4135573338871735
0.2348356617037816
3.主成分分析(sklearn.decomposition.PCA)
-
用矩陣P對原始數據進行線性變換,得到新的數據矩陣Z,每一列就是一個主成分, 如下圖就是把10維降成了2維,得到了兩個主成分
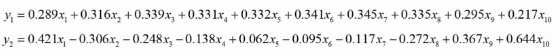
-
根據主成分的方差等,確定最終保留的主成分個數, 方差大的要留下。一個特征的多個樣本的值如果都相同,則方差為0, 則說明該特征值不能區別樣本,所以該特征沒有用。
PCA(n_components=None)
- 主成分分析
- n_components:
- 實參為小數時:表示降維后保留百分之多少的信息
- 實參為整數時:表示減少到多少特征
代碼示例:
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
x,y = load_iris(return_X_y=True)
data = x[0:5]
print(data)
#創建轉化器對象n_components為小數時表示保留原始數據80%的信息
transfer = PCA(n_components=0.8)
#調用轉換器方法fit_transform()
data_new = transfer.fit_transform(data)
print(data_new)#n_components為整數時表示保留的維度
transfer = PCA(n_components=2)
data_new = transfer.fit_transform(data)
print(data_new)
執行效果:
[[5.1 3.5 1.4 0.2][4.9 3. 1.4 0.2][4.7 3.2 1.3 0.2][4.6 3.1 1.5 0.2][5. 3.6 1.4 0.2]]
[[ 0.31871016][-0.20314124][-0.15458491][-0.30200277][ 0.34101876]]
[[ 0.31871016 0.06464364][-0.20314124 0.19680403][-0.15458491 -0.07751201][-0.30200277 -0.10904729][ 0.34101876 -0.07488837]]
結語
特征工程是機器學習中的“藝術”,需要領域知識、統計思維和編程技巧的結合。本文從 字典特征 到 PCA降維,系統介紹了特征工程的核心方法,并提供了可直接復用的代碼示例。
🔧 動手挑戰:嘗試對一份真實數據集(如Kaggle的Titanic數據)進行完整的特征工程處理,觀察模型效果的變化!
📚 下期預告:我們將進入 模型訓練與調優 階段,探討如何選擇算法并優化超參數。




![[免費]【NLP輿情分析】基于python微博輿情分析可視化系統(flask+pandas+echarts)【論文+源碼+SQL腳本】](http://pic.xiahunao.cn/[免費]【NLP輿情分析】基于python微博輿情分析可視化系統(flask+pandas+echarts)【論文+源碼+SQL腳本】)


)
)




)



)
 視頻教程 - 微博評論數據可視化分析-點贊區間折線圖實現)
