Kafka Go客戶端
在Go中里面有三個比較有名氣的Go客戶端。
- Sarama:用戶數量最多,早期這個項目是在Shopify下面,現在挪到了IBM下。
- segmentio/kafka-go:沒啥大的缺點。
- confluent-kafka-go:需要啟用cgo,跨平臺問題比較多,交叉編譯也不支持。
Sarama 使用入門:tools
IBM/sarama: Sarama is a Go library for Apache Kafka.
在 Sarama 里面提供了一些簡單的命令行工具,可以看做是 Shell腳本提供的功能一個子集。
Consumer和 producer中的用得比較多
1.設置 Go 代理(如果內網無法直連 proxy.golang.org)
export GOPROXY=https://goproxy.cn,direct
export GOSUMDB=sum.golang.google.cn
2.在虛擬機上執行安裝命令:
- ? go install github.com/IBM/sar ama/tools/kafka-console-consumer@latest
- ? go install github.com/lBM/sarama/tools/kafka-console-producer@latest
3.把可執行文件所在目錄加到 PATH(如果還沒加)
export PATH=$PATH:$(go env GOBIN)
4.確認可執行文件在哪里
# 查看 GOBIN,如果你沒顯式設置,就會是空
go env GOBIN# 查看 GOPATH,默認是 $HOME/go(對于 root 用戶就是 /root/go)
go env GOPATH#我的是/home/cxz/go/lib:/home/cxz/go/work
5.查看安裝結果
ls /home/cxz/go/lib/bin
#應該能夠看到kafka-console-consumer kafka-console-producer
6.臨時生效
export PATH=$PATH:/home/cxz/go/lib/bin# 然后驗證
which kafka-console-consumer
# 應該輸出 /home/cxz/go/lib/bin/kafka-console-consumer
7.永久生效
echo 'export PATH=$PATH:/home/cxz/go/lib/bin' >> ~/.bashrc
# 或者,如果你用的是 zsh:
# echo 'export PATH=$PATH:/home/cxz/go/lib/bin' >> ~/.zshrc# 然后重新加載配置
source ~/.bashrc
Sarama 使用入門:發送消息
虛擬機上執行
kafka-console-consumer -topic=test_topic -brokers=192.168.24.101:9094
Goland上執行
package mainimport ("github.com/IBM/sarama""github.com/stretchr/testify/assert""testing"
)var addrs = []string{"192.168.24.101:9094"}func TestSyncProducer(t *testing.T) {//創建一個 Sarama 的配置對象。cfg := sarama.NewConfig()//表示生產者要等待 Kafka 確認消息成功寫入后再返回(同步模式)。如果不設置這個,SyncProducer.SendMessage 會一直失敗。cfg.Producer.Return.Successes = true //同步的Producer一定要設置//創建一個同步的生產者實例producer, err := sarama.NewSyncProducer(addrs, cfg)assert.NoError(t, err)//構建消息并發送_, _, err = producer.SendMessage(&sarama.ProducerMessage{Topic: "test_topic",//消息數據本體Value: sarama.StringEncoder("hello world ,這是一條使用kafka的消息"),//會在生產者和消費者之間傳遞,消息頭,可傳遞自定義鍵值對,比如 trace_id 用于鏈路追蹤。Headers: []sarama.RecordHeader{{Key: []byte("trace_id"),Value: []byte("123456"),},},//只作用于發送過程。元信息,在發送過程中使用,可以用來傳遞額外信息,發送完成后會原樣返回(不會傳給消費者)。Metadata: "這是metadata",})assert.NoError(t, err)
}
10.執行結果
Partition: 0
Offset: 0
Key:
Value: hello world ,這是一條使用kafka的消息
使用控制臺工具連接Kafka
Sarama 使用入門:指定分區
可以注意到,前面所有的消息都被發送到了 Partition 0 上面。
正常來說,在 Sarama 里面,可以通過指定 config 中的Partitioner來指定最終的目標分區。
常見的方法:
- ? Random:隨機挑一個。
- ? RoundRobin:輪詢。
- ? Hash(默認):根據 key 的哈希值來篩選一個。
- ? Manual: 根據 Message 中的 partition 字段來選擇。
- ? ConsistentCRC:一致性哈希,用的是 CRC32 算法。
- ? Custom:實際上不 Custom,而是自定義一部分Hash 的參數,本質上是一個 Hash 的實現。
//默認HashPartitioner 適合: 按用戶 ID、訂單 ID 等字段分區場景
cfg.Producer.Partitioner = sarama.NewHashPartitioner
//使用 CRC32 算法 計算 Key 的哈希。 適合: 需要高一致性分布的業務,例如日志收集系統
cfg.Producer.Partitioner = sarama.NewConsistentCRCHashPartitioner
//忽略 Key,每條消息隨機分配 partition。 適合: 普通消息隊列、廣播類場景。
cfg.Producer.Partitioner = sarama.NewRandomPartitioner
//需要手動指定 partition(ProducerMessage.Partition 字段)。適合: 明確知道要寫哪個 partition,例如做數據分流
cfg.Producer.Partitioner = sarama.NewManualPartitioner
//用于實現你自己的 Partitioner 一般不推薦使用這個空參函數(它會 panic),應實現完整接口。
cfg.Producer.Partitioner = sarama.NewCustomPartitioner()
//允許你使用自定義哈希函數來做 key 分區。 適合: 有特定哈希策略需求時,例如分布要盡可能均勻。
cfg.Producer.Partitioner = sarama.NewCustomHashPartitioner(func() hash.Hash32 {})Topic: "test_topic",
//分區依據
Key: sarama.StringEncoder("user_123"), // 🔑 這里是分區依據
//消息數據本體
Value: sarama.StringEncoder("hello world ,這是一條使用kafka的消息"),
最典型的場景,就是利用Partitioner來保證同一個業務的消息一定發送到同一個分區上,從而保證業 有序。
Sarama 使用入門:異步發送
Sarama有一個異步發送的producer,它的用法稍微復雜一點。
- ? 把Return.Success和 Errors都設置為true,這是為了后面能夠拿到發送結果。
- ? 初始化異步producer。
- ? 從producer里面拿到Input的channel,并且發送 一條消息。
- ? 利用select case,同時**監聽Success和Error兩個channel,**來獲得發送成功與否的信息。
func TestAsyncProducer(t *testing.T) {cfg := sarama.NewConfig()//怎么知道發送是否成功cfg.Producer.Return.Errors = truecfg.Producer.Return.Successes = trueproducer, err := sarama.NewAsyncProducer(addrs, cfg)require.NoError(t, err)messages := producer.Input()go func() {for {messages <- &sarama.ProducerMessage{Topic: "test_topic",//分區依據Key: sarama.StringEncoder("user_123"), // 🔑 這里是分區依據//消息數據本體Value: sarama.StringEncoder("hello world ,這是一條使用kafka的消息"),//會在生產者和消費者之間傳遞Headers: []sarama.RecordHeader{{Key: []byte("trace_id"),Value: []byte("123456"),},},//只作用于發送過程Metadata: "這是metadata",}}}()errCh := producer.Errors()succCh := producer.Successes()for {//兩個都不滿足就會阻塞select {case err := <-errCh:t.Log("發送出了問題", err.Err)case <-succCh:t.Log("發送成功")}}
}Sarama 使用入門:acks
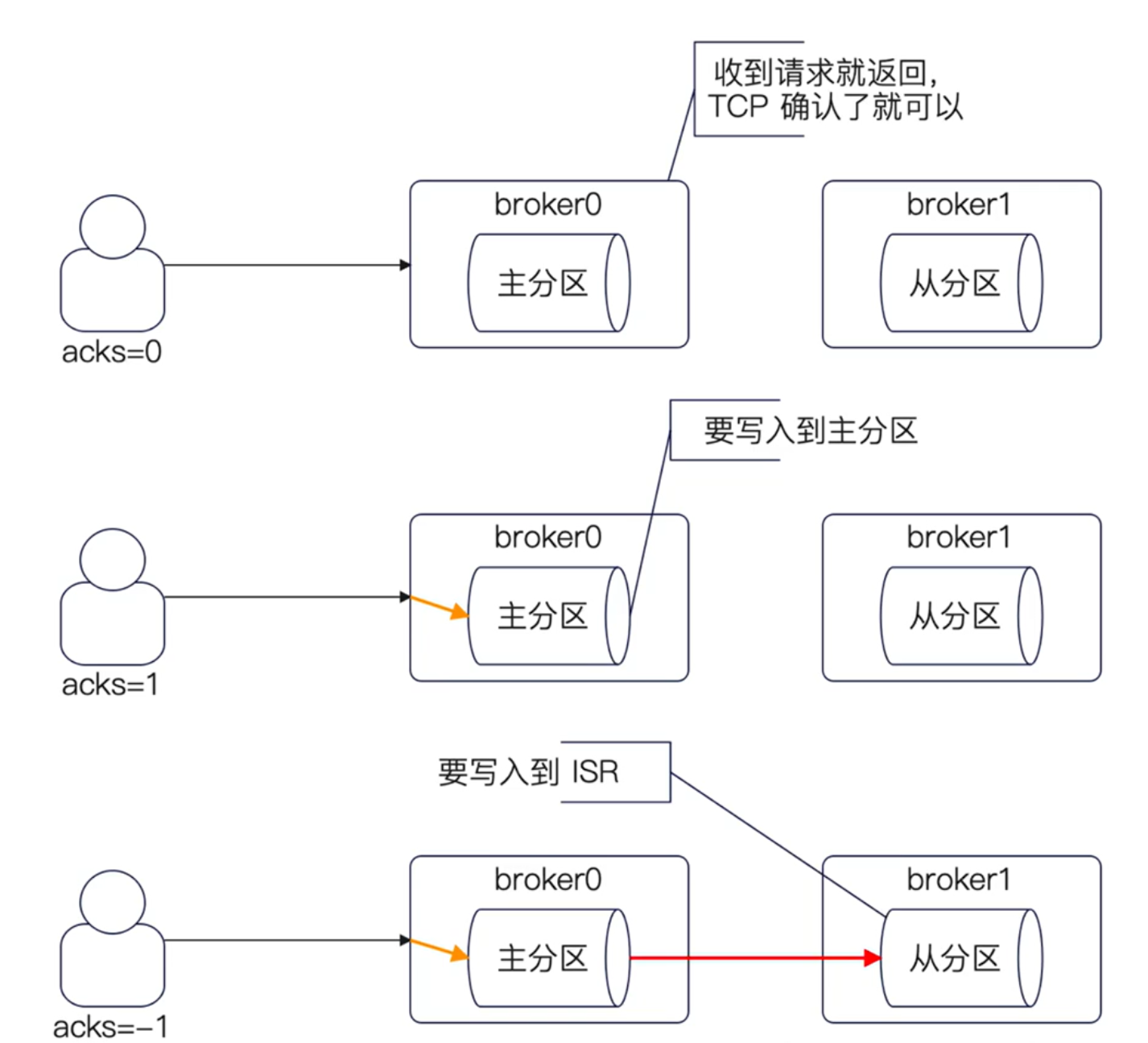
在Kafka里面,生產者在發送數據的時候,有一個很關鍵的參數,就是 acks。
有三個取值:
- ? 0:客戶端發一次,不需要服務端的確認。
- ? 1:客戶端發送,并且需要服務端寫入到主分區。
- ? -1:客戶端發送,并且需要服務端同步到所有的ISR 上。
從上到下,性能變差,但是數據可靠性上升。需要性能,選 0,需要消息不丟失,選-1。
理解acks你就要抓住核心點,誰ack才算數?
- 0:TCP協議返回了ack就可以。
- 1:主分區確認寫入了就可以。
- -1:所有的ISR都確認了就可以。
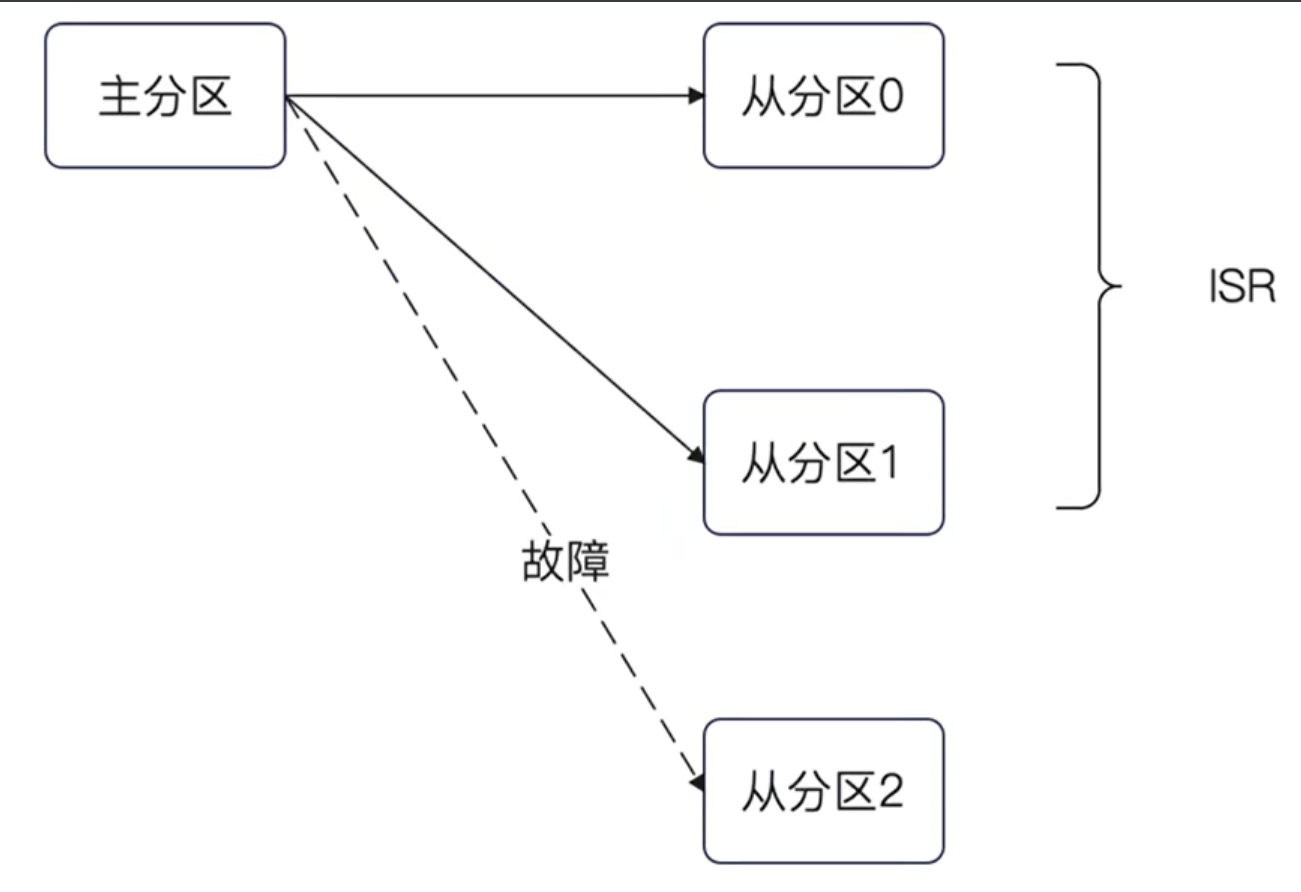
ISR (In Sync Replicas),用通俗易懂的話來說,就是跟上了節奏的從分區。
什么叫做跟上了節奏?就是它和主分區保持了數據同步。
所以,當消息被同步到從分區之后,如果主分區崩潰了那么依舊可以保證在從分區上還有數據。
sarama 使用入門:啟動消費者
Sarama的消費者設計不是很直觀,稍微有點復雜。
- ? 首先要初始化一個ConsumerGroup。
- ? 調用ConsumerGroup上的Consume方法。
- ? 為 Consume 方法傳入一個 ConsumerGroupHandler的輔助方法。
package mainimport ("context""github.com/IBM/sarama""github.com/stretchr/testify/assert""log""testing"
)func TestConsumer(t *testing.T) {cfg := sarama.NewConfig()//正常來說,一個消費者都是歸屬一個消費者組的//消費者就是你的業務consumerGroup, err := sarama.NewConsumerGroup(addrs, "test_group", cfg)assert.NoError(t, err)err = consumerGroup.Consume(context.Background(), []string{"test_topic"}, testConsumerGroupHandler{})//你消費結束,就會到這里t.Log(err)
}type testConsumerGroupHandler struct {
}func (t testConsumerGroupHandler) Setup(session sarama.ConsumerGroupSession) error {log.Println("Setup session:", session)return nil
}func (t testConsumerGroupHandler) Cleanup(session sarama.ConsumerGroupSession) error {log.Println("Cleanup session:", session)return nil
}func (t testConsumerGroupHandler) ConsumeClaim(//代表的是你和Kafka的會話(從建立連接到連接徹底斷掉的那一段時間)session sarama.ConsumerGroupSession,claim sarama.ConsumerGroupClaim) error {msgs := claim.Messages()for msg := range msgs {//var bizMsg MyBizMsg//err := json.Unmarshal(msg.Value, &bizMsg)//if err != nil {// //這就是消費消息出錯// //大多數時候就是重試// //記錄日志// continue//}log.Println(string(msg.Value))session.MarkMessage(msg, "")}//什么情況下會到這里//msg被人關了,也就是要退出消費邏輯return nil
}type MyBizMsg struct {Name string
}sarama 使用入門:ConsumerGroupHandler
下面的代碼就是對ConsumerGroupHandler的實現,關鍵就是在消費了msg之后,如果消費成功了,要記得提交。
也就是調用MarkMessage方法。
至于 Setup 和 Cleanup 方法反而用得不多。
type testConsumerGroupHandler struct {
}func (t testConsumerGroupHandler) Setup(session sarama.ConsumerGroupSession) error {log.Println("Setup session:", session)return nil
}func (t testConsumerGroupHandler) Cleanup(session sarama.ConsumerGroupSession) error {log.Println("Cleanup session:", session)return nil
}func (t testConsumerGroupHandler) ConsumeClaim(//代表的是你和Kafka的會話(從建立連接到連接徹底斷掉的那一段時間)session sarama.ConsumerGroupSession,claim sarama.ConsumerGroupClaim) error {msgs := claim.Messages()for msg := range msgs {//var bizMsg MyBizMsg//err := json.Unmarshal(msg.Value, &bizMsg)//if err != nil {// //這就是消費消息出錯// //大多數時候就是重試// //記錄日志// continue//}log.Println(string(msg.Value))session.MarkMessage(msg, "")}//什么情況下會到這里//msg被人關了,也就是要退出消費邏輯return nil
}
sarama 使用入門:利用context來控制消費者退出
可以利用初始化ConsumerGroup 時候傳入的ctx來控制消費者組退出消息。
下圖中,我傳入了一個超時的context,那么:
start := time.Now()//這里是測試,我們就控制消費10sctx, cancel := context.WithTimeout(context.Background(), 10*time.Second)defer cancel()//開始消費,會在這里阻塞住err = consumerGroup.Consume(ctx, []string{"test_topic"}, testConsumerGroupHandler{})//你消費結束,就會到這里t.Log(err, time.Since(start).String())
下圖中,我主動調用了cancel,那么:
start := time.Now()//這里是測試,我們就控制消費5sctx, cancel := context.WithCancel(context.Background())time.AfterFunc(time.Second*5, func() {cancel()})//開始消費,會在這里阻塞住err = consumerGroup.Consume(ctx, []string{"test_topic"}, testConsumerGroupHandler{})//你消費結束,就會到這里t.Log(err, time.Since(start).String())
- 如果超時了
- 如果我主動調用了cancel
以上兩種情況,任何一種情況出現了,都會讓消費者退出消息。
sarama 使用入門:指定偏移量消費
在部分場景下,我們會希望消費歷史消息,或者從某個消息開始消費,那么可以考慮在Setup里面設置偏移量。
關鍵調用是 ResetOffset。
不過一般建議走離線渠道,操作Kafka集群去重置對應的偏移量。
核心在于,你并不是每次重新部署,重新啟動都是要重置這個偏移量的。
只要你的消費者組在這個分區上有過“已提交的 offset”,Kafka 就會優先使用這個提交的 offset,而忽略你在 Setup() 中設置的 offset。
// 在每次 rebalance 或初次連接 Kafka 后調用,用于初始化。
func (t testConsumerGroupHandler) Setup(session sarama.ConsumerGroupSession) error {//執行一些初始化的事情log.Println("Setup")//假設要重置到0var offset int64 = 0//遍歷所有的分區partitions := session.Claims()["test_topic"]for _, p := range partitions {session.ResetOffset("test_topic", p, offset, "")//session.ResetOffset("test_topic", p, sarama.OffsetNewest, "")//session.ResetOffset("test_topic", p, sarama.OffsetOldest, "")}return nil
}
sarama使用入門:異步消費,批量提交
正常來說,為了在異步消費失敗之后還能繼續重試,可以考慮異步消費一批,提交一批。
下圖中,ctx.Done分支用來控制湊夠一批的超時機制,防止生產者的速率很低,一直湊不夠一批。
func (t testConsumerGroupHandler) ConsumeClaim(//代表的是你和Kafka的會話(從建立連接到連接徹底斷掉的那一段時間)//可以通過 session 控制 offset 提交,獲取消費者信息,并感知退出時機。session sarama.ConsumerGroupSession,//claim 是你獲取消息的入口claim sarama.ConsumerGroupClaim) error {msgs := claim.Messages()//設置批量處理的條數const batchSize = 10for {ctx, cancel := context.WithTimeout(context.Background(), time.Second*1)var eg errgroup.Groupvar last *sarama.ConsumerMessagefor i := 0; i < batchSize; i++ {done := falseselect {case <-ctx.Done()://這邊表示超時了done = truecase msg, ok := <-msgs:if !ok {cancel()return nil}last = msgmsg1 := msgeg.Go(func() error {//我就在這里消費time.Sleep(time.Second)//你在這里重試log.Println(string(msg1.Value))return nil})}if done {break}}cancel()err := eg.Wait()if err != nil {//這邊能怎么辦?//記錄日志continue}//就這樣session.MarkMessage(last, "")}return nil
}
另外一個分支就是讀取消息,并且提交到errgroup里面執行。
Sleep是模擬長時間業務執行。
)













學習筆記(CLASS 1):組件)

)

JVM 內存模型更新與 G1 垃圾收集器優化)
