目錄
- 將LLM接入LangChain
- 構建檢索問答鏈
- 運行成功圖
- 遇到的問題
langchain可以便捷地調用大模型,并將其結合在以langchain為基礎框架搭建的個人應用中。
將LLM接入LangChain
from langchain_openai import ChatOpenAI- 實例化一個 ChatOpenAI 類,實例化時傳入超參數來控制回答,配置API密鑰
- llm.invoke(“prompt”)
- 提示模板(PromptTemplates):該文本提供有關當前特定任務的附加上下文。prompt=“模板”,text:用戶輸入 prompt.format(text=text)
聊天模型的接口是基于消息(message),而不是原始的文本,PromptTemplates 也可以用于產生消息列表,在這種樣例中prompt不僅包含了輸入內容信息,也包含了每條message的信息(角色、在列表中的位置等)。
一個ChatPromptTemplate是一個ChatMessageTemplate的列表。每個 ChatMessageTemplate 包含格式化該聊天消息的說明(其角色以及內容)。
- 定義設定system_template,human_template是用戶的輸入
- ChatPromptTemplate構造參數包含list下的兩個元組參數[
(“system”, template),
(“human”, human_template),
],這里可以添加更多的角色的消息
from langchain_core.prompts import ChatPromptTemplatetemplate = "你是一個翻譯助手,可以幫助我將 {input_language} 翻譯成 {output_language}."
human_template = "{text}"chat_prompt = ChatPromptTemplate([("system", template),("human", human_template),
])text = "我帶著比身體重的行李,\
游入尼羅河底,\
經過幾道閃電 看到一堆光圈,\
不確定是不是這里。\
"
messages = chat_prompt.invoke({"input_language": "中文", "output_language": "英文", "text": text})import os
# 新的導入語句os.environ['ZHIPUAI_API_KEY']="這里寫上自己的api"
api_key = os.environ["ZHIPUAI_API_KEY"] #
from zhipuai_llm import ZhipuaiLLM
from dotenv import find_dotenv, load_dotenv# 讀取本地/項目的環境變量。# find_dotenv()尋找并定位.env文件的路徑
# load_dotenv()讀取該.env文件,并將其中的環境變量加載到當前的運行環境中
# 如果你設置的是全局的環境變量,這行代碼則沒有任何作用。
_ = load_dotenv(find_dotenv())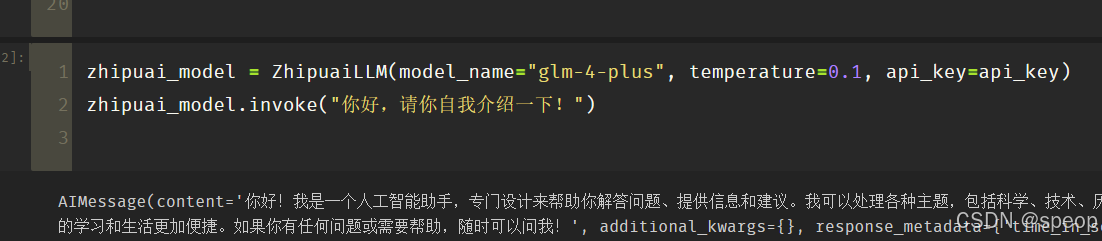
構建檢索問答鏈
我們可以使用LangChain的LCEL(LangChain Expression Language, LangChain表達式語言)來構建workflow,LCEL可以支持異步(ainvoke)、流式(stream)、批次處理(batch)等多種運行方式,同時還可以使用LangSmith無縫跟蹤。
from langchain_core.runnables import RunnableLambda
def combine_docs(docs):return "\n\n".join(doc.page_content for doc in docs)combiner = RunnableLambda(combine_docs)
retrieval_chain = retriever | combinerretrieval_chain.invoke("南瓜書是什么?")LCEL中要求所有的組成元素都是Runnable類型,前面我們見過的ChatModel、PromptTemplate等都是繼承自Runnable類。上方的retrieval_chain是由檢索器retriever及組合器combiner組成的,由|符號串連,數據從左向右傳遞,即問題先被retriever檢索得到檢索結果,再被combiner進一步處理并輸出。
llm=zhipuai_model
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnablePassthrough, RunnableParallel
from langchain_core.output_parsers import StrOutputParsertemplate = """使用以下上下文來回答最后的問題。如果你不知道答案,就說你不知道,不要試圖編造答
案。最多使用三句話。盡量使答案簡明扼要。請你在回答的最后說“謝謝你的提問!”。
{context}
問題: {input}
"""
# 將template通過 PromptTemplate 轉為可以在LCEL中使用的類型
prompt = PromptTemplate(template=template)qa_chain = (RunnableParallel({"context": retrieval_chain, "input": RunnablePassthrough()})| prompt| llm| StrOutputParser()
)
question_1 = "什么是南瓜書?"
question_2 = "Prompt Engineering for Developer是誰寫的?"
result = qa_chain.invoke(question_1)
print("大模型+知識庫后回答 question_1 的結果:")
print(result)
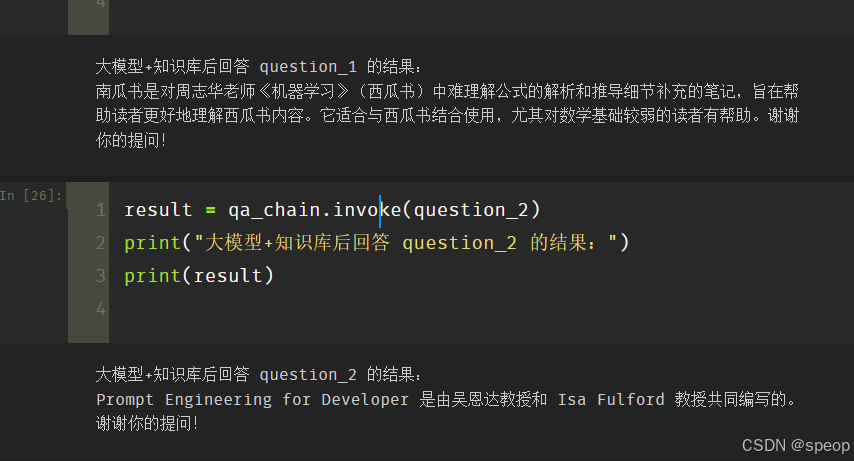
result = qa_chain.invoke(question_2)
print("大模型+知識庫后回答 question_2 的結果:")
print(result)
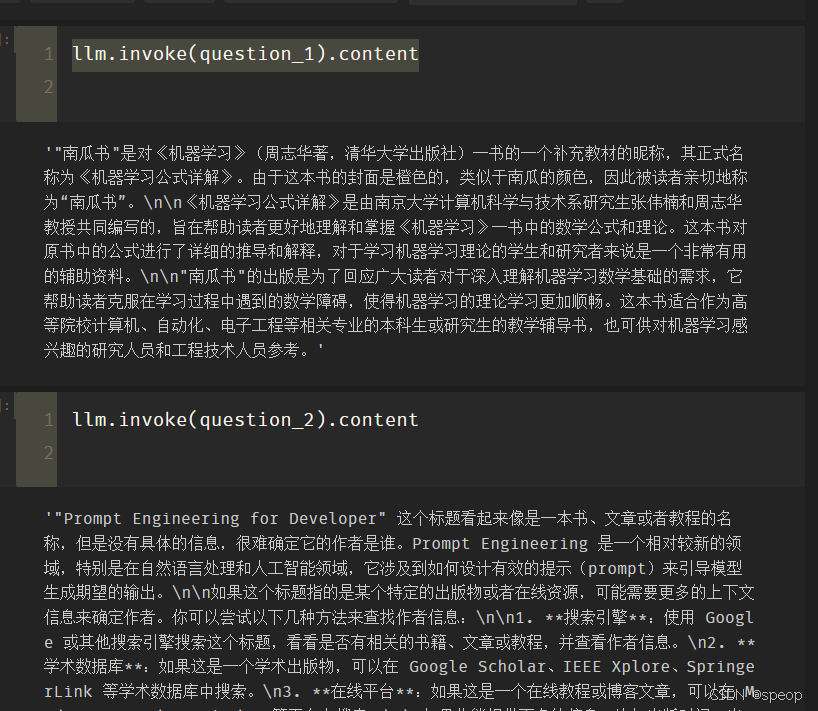
llm.invoke(question_1).content
# 無歷史記錄
messages = qa_prompt.invoke({"input": "南瓜書是什么?","chat_history": [],"context": ""}
)
for message in messages.messages:print(message.content)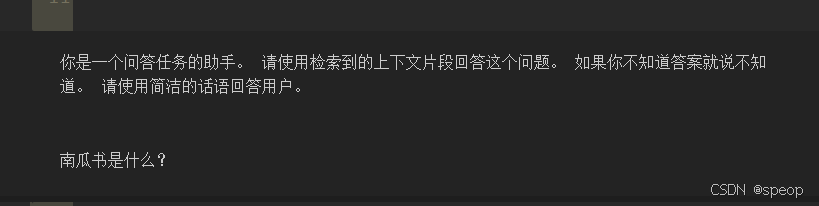
# 有歷史記錄
messages = qa_prompt.invoke({"input": "你可以介紹一下他嗎?","chat_history": [("human", "西瓜書是什么?"),("ai", "西瓜書是指周志華老師的《機器學習》一書,是機器學習領域的經典入門教材之一。"),],"context": ""}
)
for message in messages.messages:print(message.content)
import os
import sys
from zhipuai_llm import ZhipuaiLLM
os.environ['ZHIPUAI_API_KEY']=""
api_key = os.environ["ZHIPUAI_API_KEY"] #填寫控制臺中獲取的 APIKey 信息sys.path.append(os.getcwd())# 將父目錄放入系統路徑中import streamlit as st
# from langchain_openai import ChatOpenAIfrom langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableBranch, RunnablePassthrough
from zhipuai_embedding import ZhipuAIEmbeddings
from langchain_community.vectorstores import Chromadef get_retriever():# 定義 Embeddingsembedding = ZhipuAIEmbeddings()# 向量數據庫持久化路徑persist_directory = 'D:\\code\\llm_universe\\chroma'# 加載數據庫vectordb = Chroma(persist_directory=persist_directory,embedding_function=embedding)return vectordb.as_retriever()
def combine_docs(docs):return "\n\n".join(doc.page_content for doc in docs["context"])def get_qa_history_chain():retriever = get_retriever()zhipuai_model = ZhipuaiLLM(model_name="glm-4-plus", temperature=0.1, api_key=api_key)llm = zhipuai_modelcondense_question_system_template = ("請根據聊天記錄總結用戶最近的問題,""如果沒有多余的聊天記錄則返回用戶的問題。")condense_question_prompt = ChatPromptTemplate([("system", condense_question_system_template),("placeholder", "{chat_history}"),("human", "{input}"),])retrieve_docs = RunnableBranch((lambda x: not x.get("chat_history", False), (lambda x: x["input"]) | retriever, ),condense_question_prompt | llm | StrOutputParser() | retriever,)system_prompt = ("你是一個問答任務的助手。 ""請使用檢索到的上下文片段回答這個問題。 ""如果你不知道答案就說不知道。 ""請使用簡潔的話語回答用戶。""\n\n""{context}")qa_prompt = ChatPromptTemplate.from_messages([("system", system_prompt),("placeholder", "{chat_history}"),("human", "{input}"),])qa_chain = (RunnablePassthrough().assign(context=combine_docs)| qa_prompt| llm| StrOutputParser())qa_history_chain = RunnablePassthrough().assign(context = retrieve_docs, ).assign(answer=qa_chain)return qa_history_chaindef gen_response(chain, input, chat_history):response = chain.stream({"input": input,"chat_history": chat_history})for res in response:if "answer" in res.keys():yield res["answer"]
def main():st.markdown('### 🦜🔗 動手學大模型應用開發')# st.session_state可以存儲用戶與應用交互期間的狀態與數據# 存儲對話歷史if "messages" not in st.session_state:st.session_state.messages = []# 存儲檢索問答鏈if "qa_history_chain" not in st.session_state:st.session_state.qa_history_chain = get_qa_history_chain()# 建立容器 高度為500 pxmessages = st.container(height=550)# 顯示整個對話歷史for message in st.session_state.messages: # 遍歷對話歷史with messages.chat_message(message[0]): # messages指在容器下顯示,chat_message顯示用戶及ai頭像st.write(message[1]) # 打印內容if prompt := st.chat_input("Say something"):# 將用戶輸入添加到對話歷史中st.session_state.messages.append(("human", prompt))# 顯示當前用戶輸入with messages.chat_message("human"):st.write(prompt)# 生成回復answer = gen_response(chain=st.session_state.qa_history_chain,input=prompt,chat_history=st.session_state.messages)# 流式輸出with messages.chat_message("ai"):output = st.write_stream(answer)# 將輸出存入st.session_state.messagesst.session_state.messages.append(("ai", output))if __name__ == "__main__":main()運行成功圖
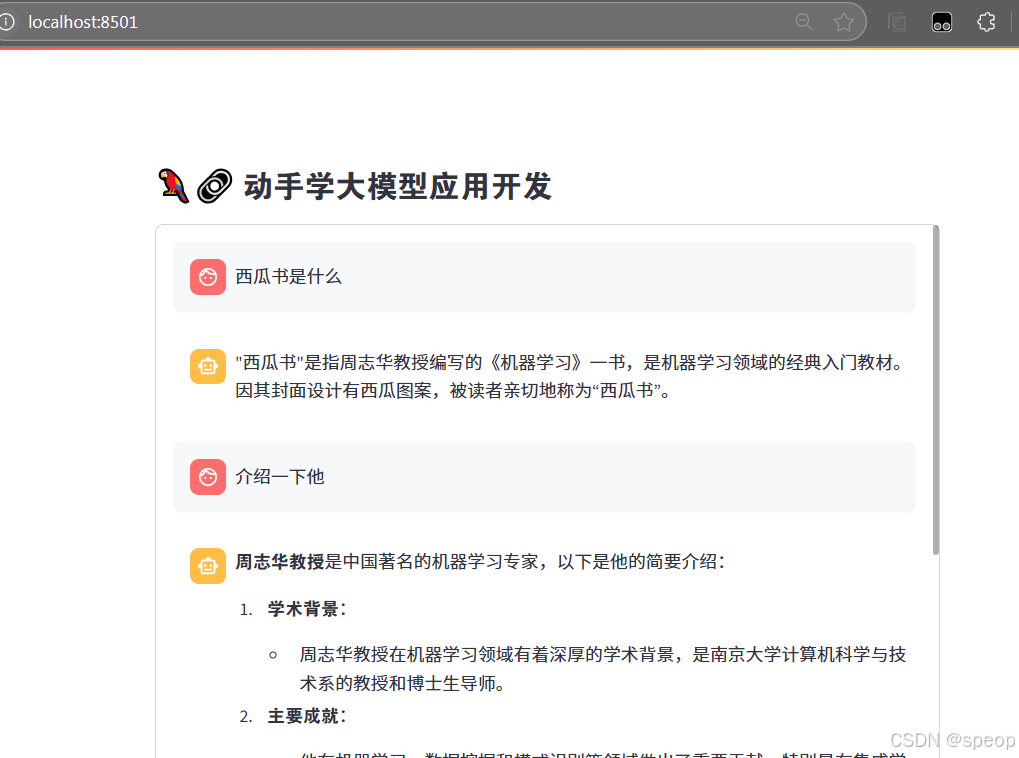
遇到的問題
解決了一個很久以來都覺得奇怪的問題,pip的下載的包是依據與conda虛擬環境的,jupyter內核也有運行的conda虛擬環境,這些都是相互依賴的,我出現的問題是jupyternotebook運行在環境2的,而直接pip下載的包是在環境1里面的,所以需要conda activate 環境2之后再進行包的下載。jupyter notebook的python核版本可以自己進行設置,但是如果在環境中運行了!python --version可能顯示的是環境1的version。使用import sys print(sys.executable)可以查看當前jupyternotebook運行的python的環境。

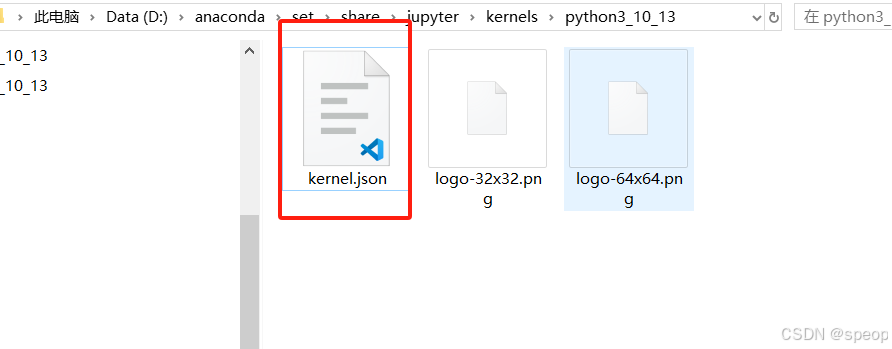
“D:\anaconda\set\share\jupyter\kernels\python3_10_13”這里可以修改運行的python核的路徑,直接進行復制
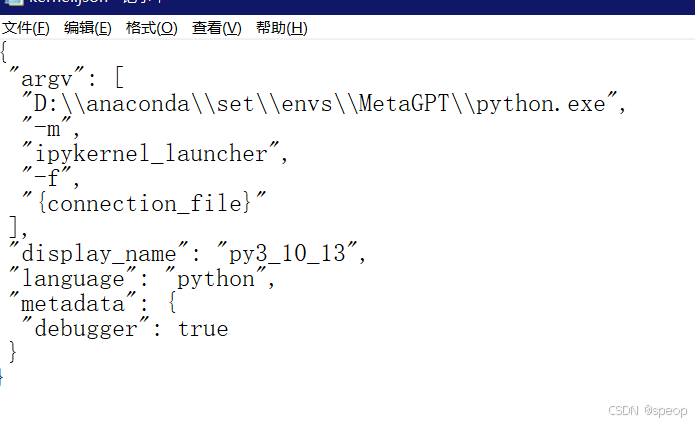
再修改argv的路徑就行。display_name和文件夾的名字需要相同
元組tuple()
列表list[]
字典dictionary{“key”:“value”,“key”:“value”}
集合set{a,b,c}
數組array
import array
arr = array.array("i",[1,2,3])隊列:queue
from collections import deque#雙端
q = deque([1,2,3])
q.append(4)
q.popleft()#隊頭刪除,返回1
堆:heap
import heapq
heap = [3,1,2]
heapq.heapify(heap)#轉換為最小堆
heapq.heappush(heap,0)# 插入 元素0
heapq.heappop(heap)#彈出最小元素





![【題解-洛谷】P6180 [USACO15DEC] Breed Counting S](http://pic.xiahunao.cn/【題解-洛谷】P6180 [USACO15DEC] Breed Counting S)

 - /安全與維護組件/industrial-firewall-dcs-protection)



)







