關鍵要點
-
AI設計模式是為現代AI驅動的軟件中常見問題提供的可復用解決方案,幫助團隊避免重復造輪子。我們將其分為五類:提示與上下文(Prompting & Context)、負責任的AI(Responsible AI)、用戶體驗(User Experience)、AI運維(AI-Ops)和優化模式(Optimization Patterns)。
-
要生成有效的AI輸出,必須通過精心設計的提示詞和/或在提示中提供相關上下文(或外部知識)來進行有效引導。
-
構建負責任的AI系統的一部分工作包括減少幻覺(hallucinations)、防止不當或違規內容、緩解偏見,并確保AI決策過程的透明性。
-
明確的用戶體驗設計模式可以幫助開發者以用戶友好的方式處理新的交互類型,從而提升用戶參與度、滿意度并增強透明性。
-
你必須為系統做出智能的優化選擇,比如避開過于強大的模型、緩存可預測的響應、對查詢進行近實時批處理,或開發更小型的專用模型,以提高效率并降低成本。
為什么要為人工智能系統設計模式?
23 種面向對象模式塑造了整整一代開發者的軟件設計方式。2010 年代,云計算引入了發布-訂閱(“pub-sub”)、微服務、事件驅動工作流和無服務器模型等模式,這些模式如今為大多數基于云的分布式系統提供支持。
同樣,在當前人工智能熱潮興起之前,機器學習社區已經開發出了一些“機器學習設計模式”。構建和部署機器學習模型時,你會面臨一些特定的挑戰,而諸如檢查點、特征存儲和版本控制等模式已經成為了標準做法。
為什么要關注這些模式?它們可以幫助您以標準化的方式解決已知問題。您無需重新設計解決方案,而是使用共享的詞匯表。當您提到“單例”、“發布-訂閱”或“特性存儲”時,您的團隊能夠立即理解您的方法。這可以加快開發速度,減少錯誤,并使您的系統更易于維護。
現代人工智能系統帶來了新的挑戰,無論是經典軟件還是傳統的機器學習模式都無法完全解決。
例如,如何引導模型輸出并防止誤導性內容?如何構建用戶體驗,幫助用戶理解、信任并有效使用人工智能應用程序?如何管理多智能體系統中的智能體交互?如何降低計算成本,使產品可持續發展?
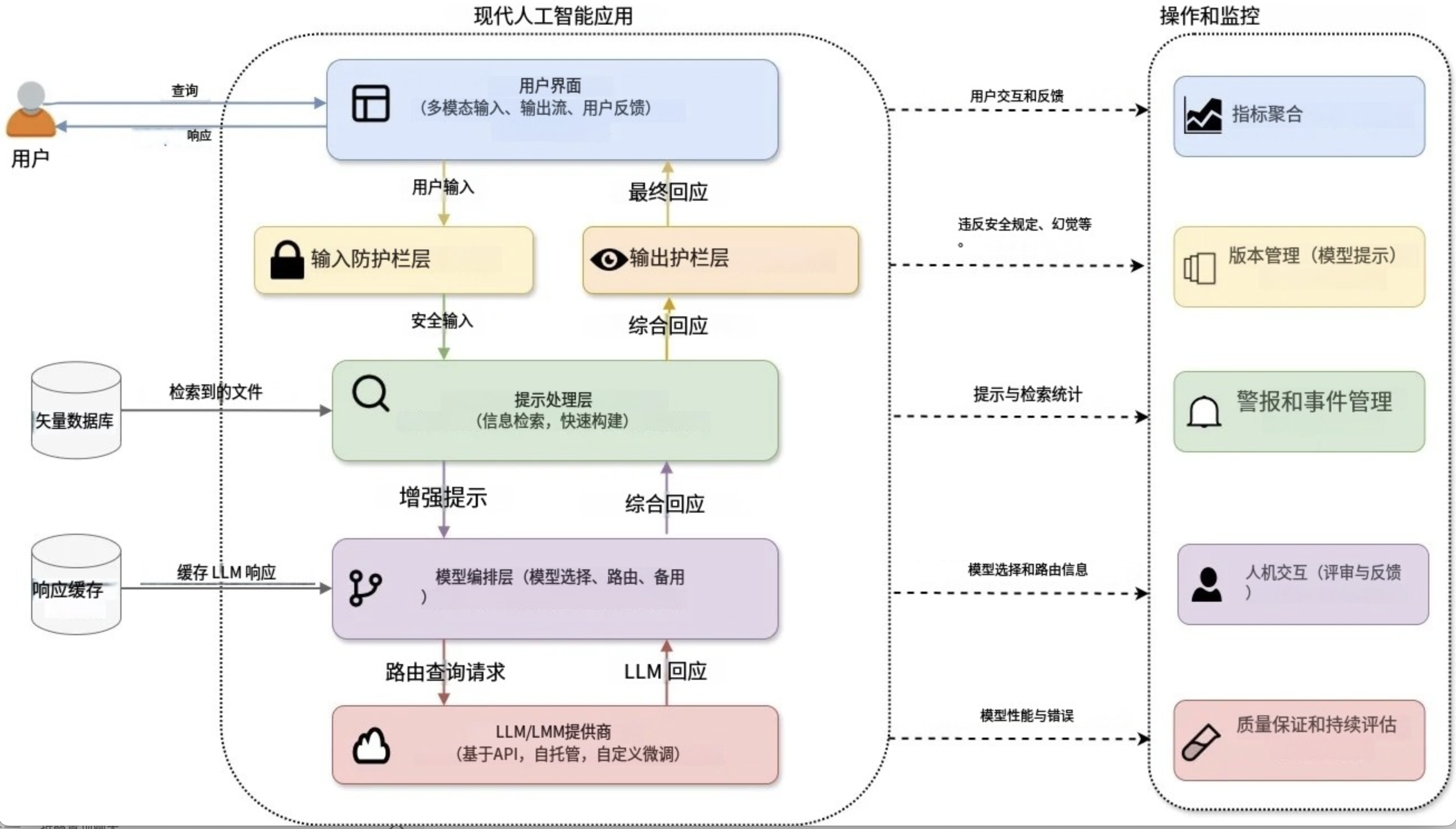
圖 1:架構良好的現代人工智能系統示意圖
為了幫助開發如圖 1 所示的架構良好的 AI 系統,業界涌現出許多 AI 模式。在本文中,我不會發明新的設計模式,而是向您展示現有模式是如何組合在一起的。我將關鍵的新興模式分為五類,它們可以在您擴展 AI 系統時相互依存。
- 提示和上下文模式:用于制定有效的指令并提供相關的上下文來指導模型的輸出
- 負責任的人工智能模式:確保道德、公平和值得信賴的輸出
- 用戶體驗模式:用于構建直觀的交互
- AI-Ops 模式:用于大規模管理 AI
- 優化模式:最大化效率并降低成本
我特別介紹了使用現有模型(主要通過 API 調用訪問)構建面向用戶的 AI 應用程序的最佳實踐。雖然我專注于基于文本的交互,但您也可以將這些模式應用于多模態應用程序。然而,我特意不討論模型訓練、定制、托管或模型優化,因為這些通常超出了使用基于 API 的 AI 模型的開發人員的工作流程。我也不涉及代理 AI 系統或多代理交互模式,因為這些主題值得專門討論。
提示和上下文模式
與傳統軟件明確編碼系統行為不同,現代人工智能系統的行為在很大程度上取決于你提供給大型語言模型 (?LLM?) 或大型多模態模型 (?LMM?) 的指令和上下文。為了創建有效的人工智能輸出,你必須提供有效的指導,可以通過精心設計提示和/或直接在提示中提供相關的上下文(或外部知識)來實現。
提示乍一看可能沒什么用。畢竟,你只是向模型發送了自由格式的文本,怎么可能出錯呢?然而,提示的措辭以及提供的上下文可能會極大地改變模型的行為,而且目前還沒有編譯器來捕獲錯誤,也沒有標準的技術庫。創建能夠可靠且一致地產生所需行為的提示變得越來越困難,尤其是在任務變得越來越復雜的情況下。
如果有效地運用提示和情境模式,就能提升模型的推理能力、準確性、一致性以及對指令的遵循度。同樣重要的是,您可以創建可重復使用的提示,使其能夠跨模型、任務和領域進行泛化。
讓我們研究一下四種具體的提示模式,它們將幫助你標準化和改進你的方法:
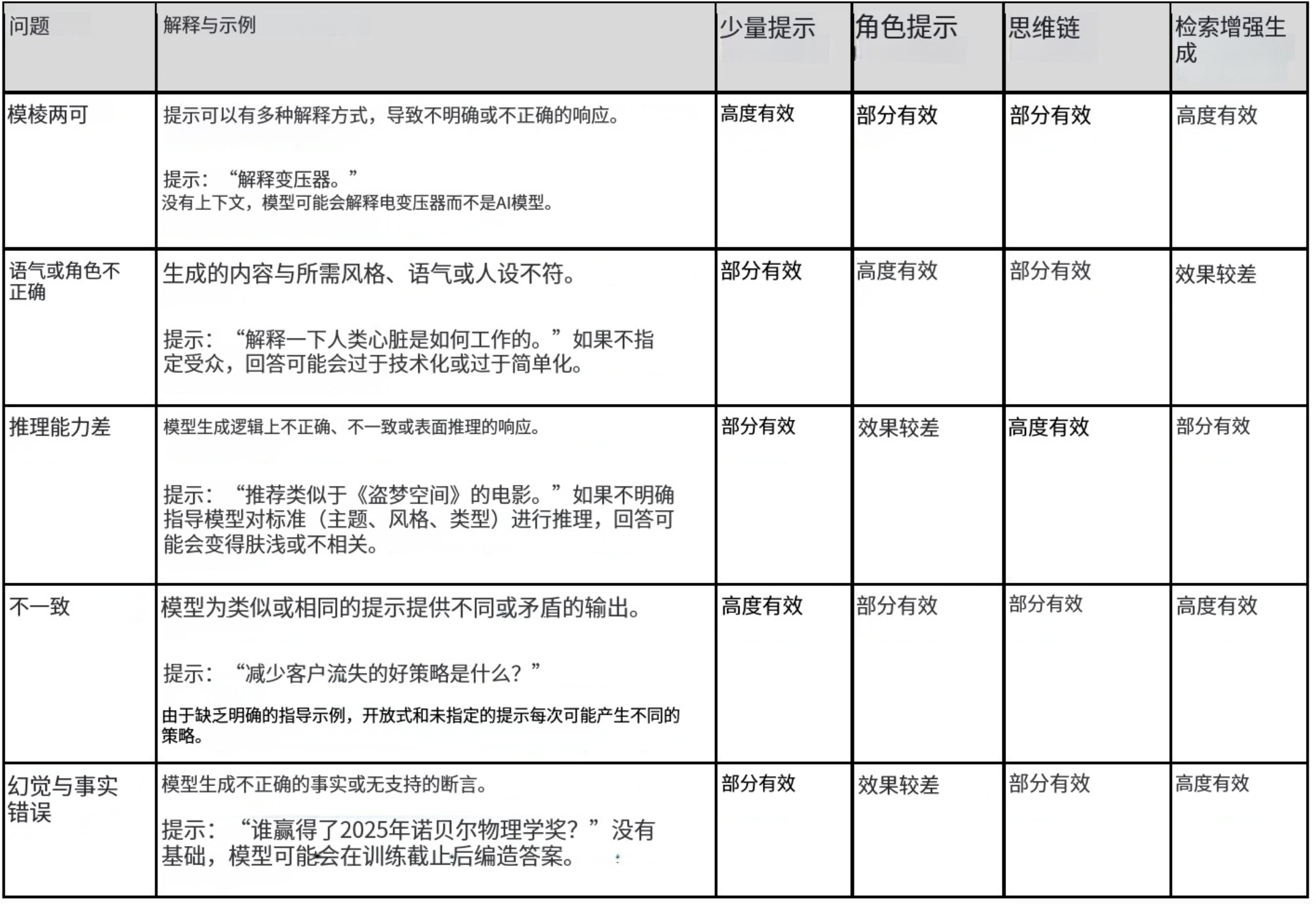
表 1:提示問題以及何時應用每個模式
少量提示模式
少量樣本提示是最直接但最有效的提示方法之一。如果沒有示例,您的模型可能會生成不一致的輸出,難以應對任務模糊性,或者無法滿足您的特定要求。您可以通過在提示中為模型提供少量示例(輸入-輸出對),然后再提供實際輸入來解決這個問題。您實際上是在動態地提供訓練數據。這使得模型無需重新訓練或微調即可進行泛化。
讓我們看一個非常簡單的例子(通過 OpenAI 的 API 使用“GPT-4o-mini”;您可以使用 OLLAMA 或 Hugging Face Transformers 在本地運行類似的提示):
<span style="background-color:#f5f2f0"><span style="color:#000000"><code class="language-markup">PROMPT:
Classify the sentiment of the following sentences as Positive, Negative, or Neutral.
Sentence: "I absolutely loved the new Batman movie!"
Sentiment: Positive
Sentence: "The food was okay, nothing special".
Sentiment: Neutral
Sentence: "I'm really disappointed by the poor customer service".
Sentiment: Negative
Sentence: "The book was thrilling and kept me engaged the whole time".
Sentiment:RESPONSE: (GPT 4o-mini)
Positive</code></span></span>當今的前沿模型是否需要這些少量樣本才能正確完成任務?不——它們已經擅長零樣本學習,不需要填鴨式的學習示例來理解基本指令。?
不過,你可以將“少樣本提示”視為一種個性化工具,引導模型滿足你的特定需求。你可以:
- 引導模型達到您預期的輸出格式、色調或復雜性。
- 無需進行微調即可使模型適應您的新場景或專門任務。
- 通過固定模型的輸出來減少幻覺。
角色提示模式
在角色提示中,你可以指示模型扮演特定的角色,這有助于將其響應情境化。例如:“你是一位生物學教授。請詳細回答這個問題。”
如果沒有指導,您的模型的風格或假設可能與您的需求不符。角色提示可以控制模型的輸出風格(例如,“充當 JSON 格式化程序”)、語氣(例如,“假裝您是憤怒的海盜”來回應)和/或內容界限(例如,“您是法律助理”)。您可以通過系統消息(在聊天模型中)或簡單地在提示中添加角色陳述來實現角色提示。就這么簡單——只需告訴您的模型它應該是誰,如下例所示。?
<span style="background-color:#f5f2f0"><span style="color:#000000"><code class="language-markup">PROMPT (without role prompting):
Explain Photosynthesis in 1-2 sentences.RESPONSE: (GPT 4o-mini)
Photosynthesis is the process by which plants, algae, and some bacteria convert light energy into chemical energy, producing glucose and oxygen. This occurs in the chloroplasts, using sunlight, water, and carbon dioxide.PROMPT (with role prompting):
You are a primary school teacher. Explain Photosynthesis to your students in 1-2 sentences. RESPONSE: (GPT 4o-mini)
Photosynthesis is how plants make their own food using sunlight, water, and air. They turn these things into sugar to grow and give off oxygen, which we breathe!</code></span></span>流行的AI助手廣泛使用角色提示:
- OpenAI 的開發者角色(以前稱為系統提示)允許您指定模型的行為和響應方式。以下是 OpenAI 提示工程指南中一個角色提示的示例:“您是一位樂于助人的助手,可以像美國東南部的南方美女一樣回答編程問題”。
- 同樣,Anthropic 的開發者指南明確建議您“使用系統提示來定義 Claude 的角色和個性。這為一致的回應奠定了堅實的基礎”。
思路鏈(CoT)模式
如果您是一位試圖解決復雜算法問題的軟件開發人員,或者是一位試圖分析復雜系統瓶頸和漏洞的軟件架構師,您可能會與同事集思廣益,探討各種想法,以了解它們的優缺點,將問題分解成更小的任務,然后迭代地解決,而不是立即跳轉到解決方案。在思維鏈(CoT) 提示中,您可以通過將問題分解成逐步的過程來鼓勵模型遵循非常相似的流程并進行自言自語。尤其是在提示復雜任務時,CoT 可以防止模型過早地跳轉到預先學習的、通常不正確的模式。?
如果您正在使用當今最先進的或先進的推理模型(例如Claude-3.7和OpenAI o1),您可能會觀察到其內部的逐步推理過程,而無需明確的提示。然而,明確指示這些模型“逐步思考”仍然是一種有效的方法,尤其是在使用較舊或規模較小的模型時。OpenAI和 Anthropic在其快速工程指南中推薦使用 CoT。?
通過推動模型產生中間推理步驟,您可以:
- 提高模型的邏輯推理和決策能力。
- 使模型的輸出更易于解釋并增強其預測的信心。?
- 診斷模型輸出中的錯誤或偏差。
- 顯著減少幻覺。?
我們來看下面的例子:
<span style="background-color:#f5f2f0"><span style="color:#000000"><code class="language-markup">PROMPT (with CoT):
A user recently watched and enjoyed the movies 'Inception,' 'The Social Network,' and 'Blade Runner 2049.' Think step-by-step about what these movies have in common, such as themes, genres, style, or storytelling, and then recommend a few more movies or tv shows the user might like. RESPONSE: (o4-mini)
Here’s my quick breakdown and some picks you might enjoy:Step-by-step commonalities1. High-concept premises – each film poses a big "what if?" (dream control, social media origin, AI-driven future).
2. Smart, twisty narratives – nonlinear or slowly-unfolding storytelling that rewards close attention.
3. Tech-oriented/social commentary – they explore how technology shapes identity, society, or reality.
4. Striking visuals & mood – strong production design, immersive cinematography, atmospheric score.Recommendations● Memento (2000) – Nolan’s early mind-bender of memory loss told in reverse.
● Ex Machina (2014) – A tense, intimate study of AI consciousness and human manipulation.
● Arrival (2016) – Thought-provoking first-contact drama where language and time intertwine.
● Black Mirror (TV series, 2011– ) – Standalone episodes examining near-future tech’s dark side.Each shares that blend of brains-and-cinema you seem to love. Enjoy!</code></span></span>檢索增強生成 (RAG) 模式
從初創公司到科技巨頭,RAG已成為整個 AI 行業的最佳實踐標準。先進的模型能夠從海量真實數據中學習。向它們詢問歷史、科學或熱門話題,它們通常都能正確回答。然而,這些模型也存在局限性。它們的訓練會在特定日期結束,它們的知識是通用的而非專業的,而且它們無法獲取最新的、專有的或動態變化的信息。?
這正是 RAG 的優勢所在。RAG 將模型的推理能力與對外部知識(例如數據庫、向量存儲或文檔)的實時訪問相結合。因此,您可以兼得兩者之長。?
想象一下,為您的律師事務所構建一個聊天機器人。借助 RAG,當客戶詢問特定的法律問題時,您的聊天機器人可以立即從內部知識庫中檢索相關法規和最新案例摘要,從而創建準確且有理有據的回復。
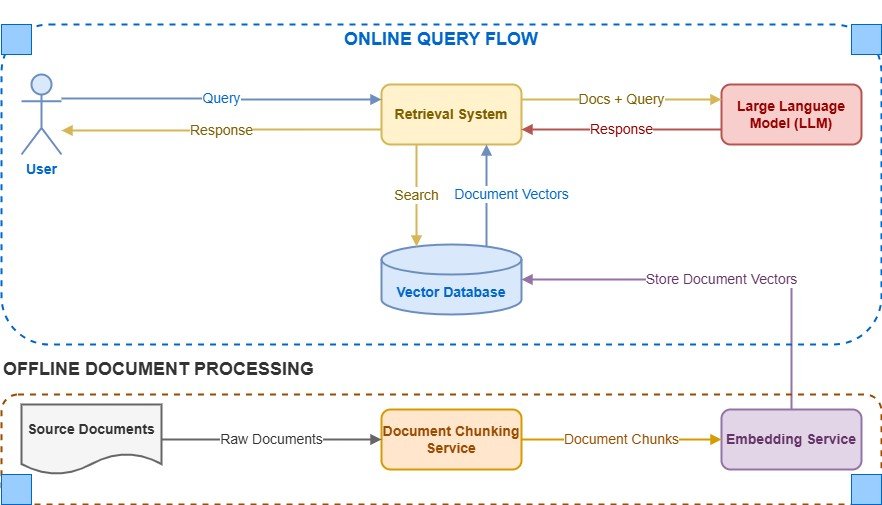
圖 2:檢索增強生成
在構建 AI 系統時,應考慮在以下情況下使用 RAG:
- 您的模型需要超出模型訓練截止日期的最新信息。
- 您的系統依賴于特定領域、專有或經常更新的數據。
- 準確性和透明度至關重要,您必須減少幻覺或錯誤的輸出。
- 您想在回復中引用或直接參考外部內容或知識庫。
負責任的 AI 模式
我們之前討論的提示和語境模式可以通過更完善的指導和更貼切的語境來幫助減少歧義、不一致和錯覺。然而,您可能很快就會注意到,需要采取額外的保障措施來處理道德、公平和安全問題。即使是準確的回應也可能存在偏見、有害或不恰當之處。這正是負責任的 AI 模式發揮作用的地方。
作為構建負責任的人工智能系統的一部分,您必須減少幻覺,防止不當或不允許的內容,減輕偏見,并確保人工智能決策的透明度。否則,您的人工智能輸出可能會誤導用戶,傳播錯誤信息,甚至引發責任問題。
像前面討論過的 RAG 這樣的技術,已經通過將輸出與外部環境聯系起來,幫助減少了幻覺。讓我們再看看一些其他模式,它們不僅關注準確性,更注重安全性、公平性和道德合規性。
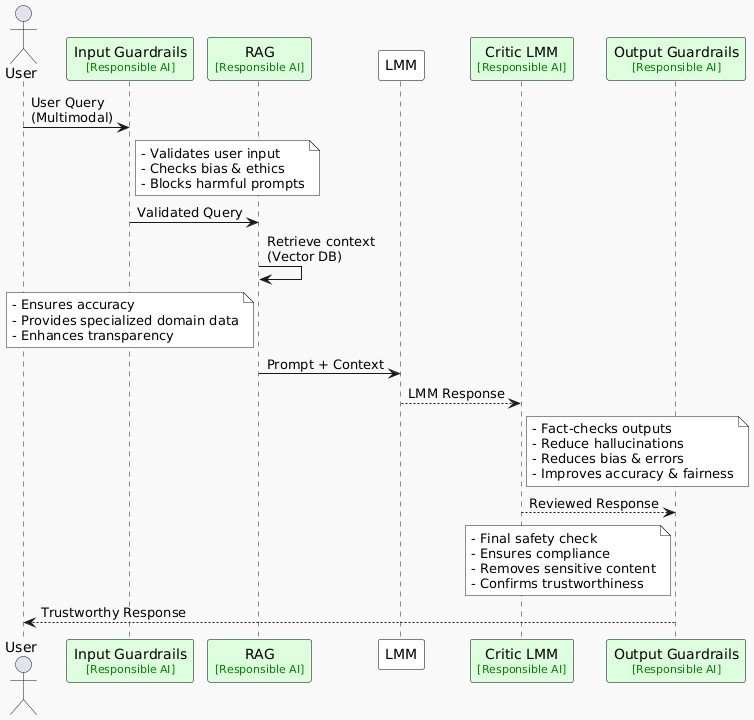
圖 3:說明現代基于 AI 的系統中負責任模式的序列圖
[點擊此處將上面的圖片放大到全尺寸]
輸出護欄模式
即使你所有操作都正確,模型仍可能生成不正確、有偏見或有害的內容。你需要護欄!這些是在模型生成輸出后應用的規則、檢查或干預措施。它們充當你的最終防線,在內容到達用戶之前對其進行修改或屏蔽。護欄對于法律或醫療應用等敏感領域尤為重要。?
根據您的領域和用例,您可以通過多種方式實施防護機制。例如,您可以:
- 使用既定的業務規則或領域指南驗證輸出是否符合道德規范、公平性和準確性。
- 通過輕量級分類器或公平指標檢測偏見。?
- 使用 ML 模型檢測和過濾有害的多模式 AI 內容。
- 使用諸如接地分數之類的指標來衡量響應在輸入或檢索到的參考中的“接地”程度。
- 指示模型重新生成內容并給出明確的警告以避免之前的錯誤。
許多模型提供商還將公平性和道德檢查集成到其自身的護欄流程中。例如,Anthropic 的 Claude 模型遵循憲法方法,根據預先定義的道德原則修改輸出。然而,擁有自己的護欄層將為您的用戶提供一致的體驗,無論您使用哪種模型或提供商。
模型評論家模式
除了基本的防護措施外,您還可以使用專門的事實核查或“批評家”模型來驗證主模型的輸出。第二個模型可以與主模型不同,也可以是同一個模型,充當“批評家”或“評判家”的角色。這類似于作者或編輯審閱和修改草稿。即使第一次驗證包含錯覺,這個驗證循環也會使模型核實其事實,從而減少最終輸出中的虛假信息和偏見。
在不增加系統復雜性、延遲或成本的情況下,添加輔助評判者或批評者并不總是可行的。但是,在自動化 QA 測試中,您絕對應該考慮這種方法。設想一下,您的生產系統為了提高效率,使用了較小的“迷你”或“納米”LLM 版本。您可以在離線測試中使用較大的模型作為評判者,以驗證準確性并確保生成可靠的輸出。例如,??Github Copilot使用第二個 LLM 來評估其主要模型。
用戶體驗(UX)模式
在使用適當的提示和防護機制穩定輸出后,下一個需要重點關注的點是用戶體驗 (UX)。人工智能系統的行為方式與傳統軟件系統不同,它們通常會生成不可預測的開放式內容,這些內容有時可能會出錯、運行緩慢或令人困惑。同樣,用戶對這些工具的期望也各不相同。例如,他們可能希望提出后續問題、優化人工智能的響應,或者在人工智能不確定時看到免責聲明。
這就是為什么定義明確的用戶體驗模式至關重要。它們可以幫助開發者以用戶友好的方式處理這些新型交互,從而保持用戶的參與度和滿意度,并提高透明度。您可以使用許多技巧來簡化這些復雜性,例如:
- 提供清晰的入職示例
- 透明地發出不確定性信號
- 允許快速編輯生成的內容
- 實現迭代探索
- 通過建議的后續行動協助用戶
- 明確確認關鍵用戶意圖
讓我們詳細了解一些說明性的 UX 模式。?
情境引導模式
這似乎顯而易見,但許多新的 AI 工具在發布時缺乏適當的用戶指導。用戶通常不了解如何與這些工具交互,也不了解它們的功能和局限性。不要想當然地認為用戶會立即學會如何使用你的工具。通過提供快速示例、上下文提示和快速功能概覽來降低他們的學習難度。在用戶旅程中需要的時候,適時地展示這些幫助。例如,在Notion中,在空白頁上按下空格鍵會觸發寫作建議(因為用戶可能想要草擬內容),而選擇文本則會彈出編輯選項,例如“改進寫作”或“更改語氣”,這些選項會與原文一起顯示,以便于比較。
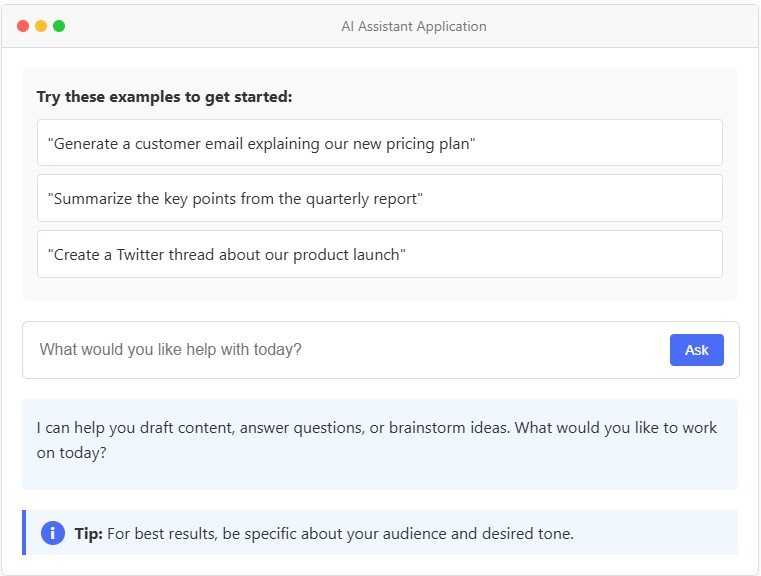
圖 4:情境指導圖解
可編輯輸出模式
對于 GenAI 模型,在許多情況下,沒有單一的正確答案。最佳輸出取決于上下文、應用程序和用戶偏好。認識到這一點,您應該考慮允許用戶修改或重寫生成的內容。這將增強人機協作的感知。您的工具將不再是黑匣子,而是讓用戶可以控制最終輸出。有時,這是一個顯而易見的功能(例如GitHub Copilot允許用戶直接在 IDE 中編輯建議的代碼)。在其他情況下,這是一個經過深思熟慮的設計選擇(例如ChatGPT 的畫布)。
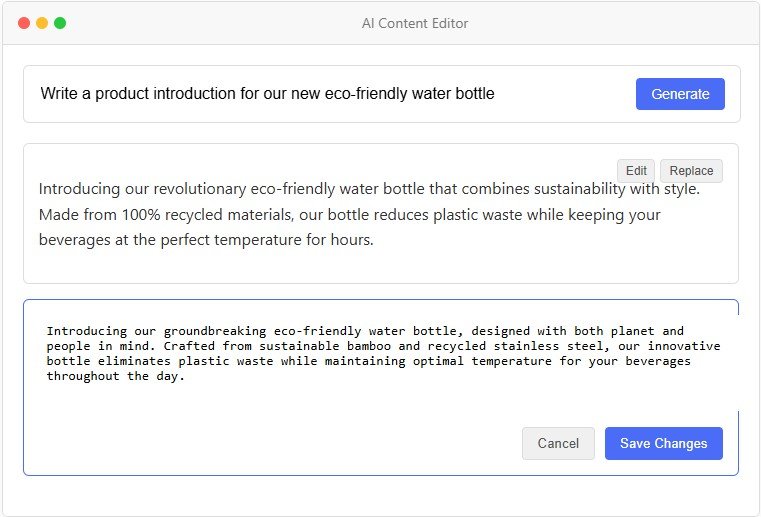
圖 5:可編輯輸出模式的圖示
迭代探索模式
永遠不要想當然地認為第一個輸出就能讓用戶滿意。添加“重新生成”或“重試”按鈕,以便用戶快速迭代。對于圖像生成,可以一次顯示多個選項。在聊天機器人中,允許用戶優化或跟進回復。這種反饋循環可以幫助用戶找到最佳輸出,而不會感到卡殼。微軟的研究表明,當用戶嘗試多個提示時,新的嘗試有時效果不如之前的——因此,允許他們恢復到之前的輸出(或組合不同代次的部分內容)可以顯著提升他們的體驗。
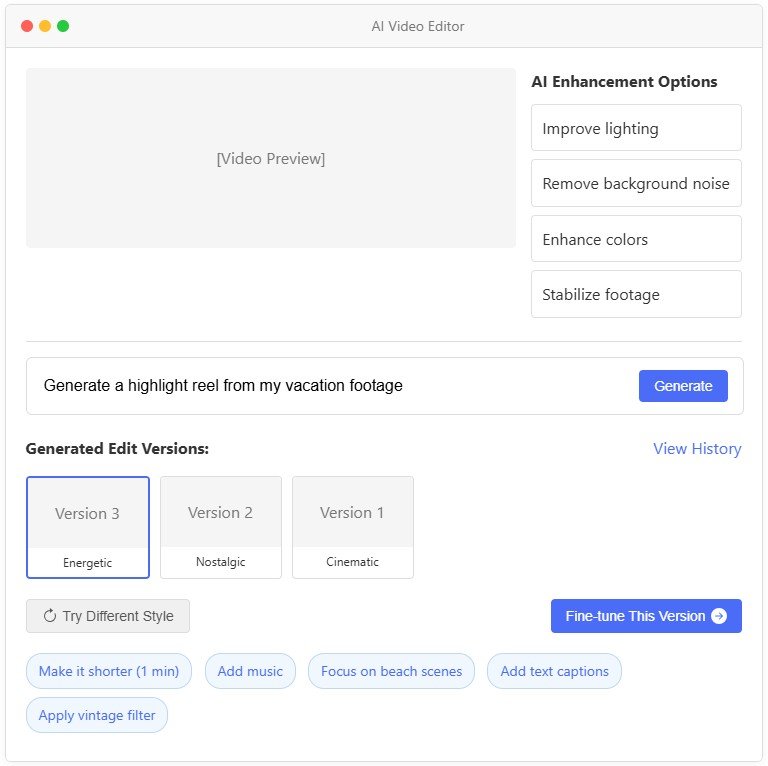
圖 6:允許迭代探索的 AI 視頻編輯器工具的圖示
[點擊此處將上面的圖片放大到全尺寸]
AI-Ops模式
當您開始將 AI 軟件投入生產時,您將面臨傳統軟件所不具備的全新運營挑戰。您仍然需要版本控制、監控和回滾,但現在您的核心“邏輯”存在于提示、模型配置和生成流程中。此外,GenAI 的輸出結果可能難以預測,需要新的測試和評估方法。?
可以將 AI-Ops 視為專門針對現代 AI 系統的 DevOps。您不僅僅是部署代碼,還要交付嵌入在提示-模型-配置組合中的 AI“知識”,這些組合可能每周都會發生變化。您必須管理性能和成本、跟蹤用戶交互、識別回歸問題,并維護可靠、可用的系統。
您可以采用許多傳統軟件中常見的運維策略,以及一套全新的、前所未有的 AI 專屬方法。讓我們詳細了解幾個 AI 專屬模式(盡管這只是完整劇本的一小部分),以了解 AI-Ops 的細微差別。
指標驅動的 AI-Ops 模式
當您的變更投入生產時,請跟蹤所有方面:延遲、令牌使用情況、用戶接受率以及每次調用成本。定義對您的業務最重要的成功指標。它可以是來自用戶反饋的每日接受度分數,也可以是由LLM 評審流程測量的“幻覺率”。如果這些指標下降,請設置警報。這種數據驅動的方法可以讓您快速檢測到新模型或快速版本何時會影響質量。然后,您可以回滾或運行 A/B 測試進行確認。將指標視為您在不可預測的環境中的安全網。
提示-模型-配置版本控制模式
如果出現不受控制的提示更改、配置調整或臨時模型交換,您的 AI 系統可能會失敗。如果您將每個(提示、模型、配置)組合視為一個“版本”,則可以像管理任何其他軟件版本一樣管理它。為確保不出現回歸,您必須使用版本標簽、QA 測試和黃金數據集對其進行標記。自動化流水線可以在您更新提示、修改配置設置或從一個模型切換到另一個模型時運行這些測試查詢。如果輸出結果根據您的指標下降,您可以進行回滾。這種規范可以防止破壞用戶體驗的“隱形更改”。
除了特定于 AI 的實踐之外,您還應該延續傳統軟件開發中的標準操作最佳實踐,例如:
- 嚴格的 QA 檢查:確保在部署變更之前進行徹底的測試。
- 回歸測試:定期運行測試以驗證新的更改沒有引入問題。
- 金絲雀部署:在廣泛發布之前,逐步向較小的用戶群部署新功能。
- 回滾策略:建立清晰、簡單的流程,以便在指標下降時快速恢復更改。
- 備份和后備系統:在主模型不可用的情況下,提供備份模型或版本。
典型的 AI-Ops 工作流程如下:
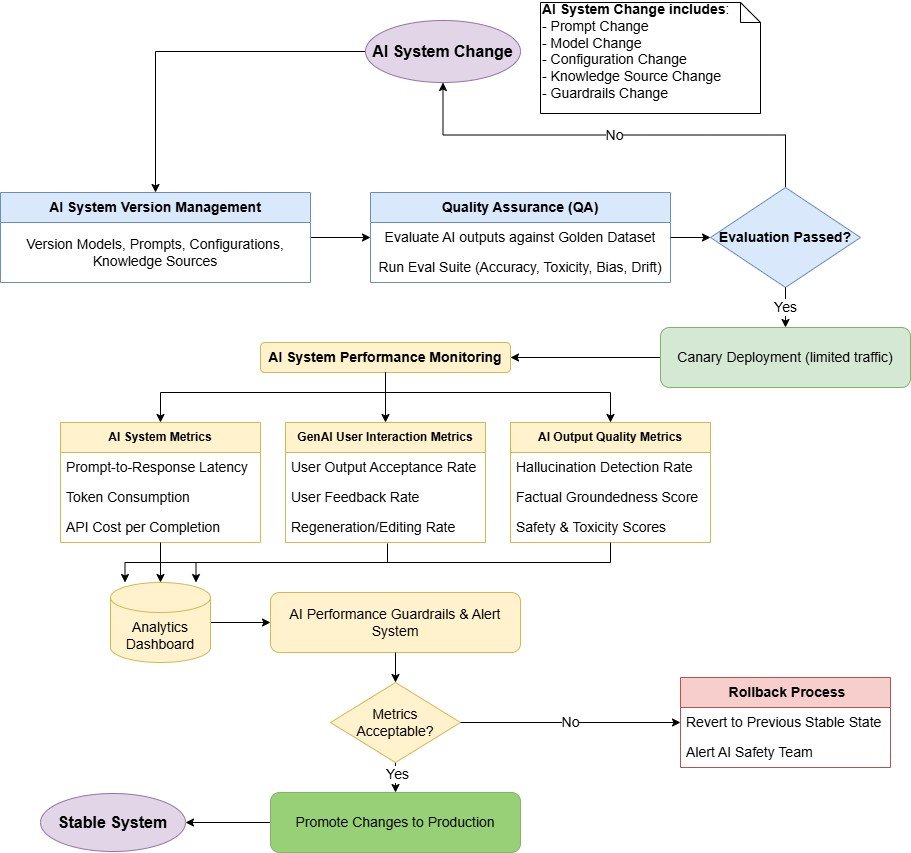
圖 7:用于管理、測試和部署 AI 系統變更的 AI-Ops 工作流程圖
優化模式
隨著 AI 應用的增長,您將面臨運營瓶頸。API 速率限制、延遲增加以及推理成本的快速上升,很快就會成為重大挑戰。您領導層所鐘愛的優秀原型,突然間變得難以在生產環境中持續運行。?
這些問題很常見,但只要您始終遵循一些最佳實踐,就可以解決。例如,不要自動選擇最大、最強大的模型。問問自己,您的任務是否可以更快、更便宜地處理,或者使用可重復使用的輸出。同樣,您必須為您的系統做出明智的優化選擇,無論是將流量從不必要的強大模型中重定向,緩存可預測的響應,近乎實時地批量處理查詢,還是開發更小的專用模型。
讓我們深入了解三種可以在 AI 工作流程中直接實現的強大優化模式:
提示緩存模式
最快、最便宜的 LLM 咨詢電話就是你不打的電話。如果你的系統經常使用相同或類似的提示,可以考慮緩存并重復使用回復。這對于文檔助理、客服機器人或用戶問題經常重復的內部聊天工具來說非常有效。
前綴緩存更為有效,您可以緩存提示符中開銷較大的部分(例如,系統指令或少量樣本)。Amazon?Bedrock(以及許多其他平臺)原生支持此功能,并報告稱大型提示符的延遲減少了高達 85%。?
連續動態批處理模式
如果您管理著一個高容量的 AI 系統,最大化 GPU 利用率和系統吞吐量對于降低成本和高效擴展至關重要。如果您按順序處理每個查詢,您的計算資源將無法充分利用,需要支付更多費用,并且可能更快地達到 API 限制。
不要在每個請求到達后立即處理,而是考慮短暫等待(可能為幾十到幾百毫秒,具體取決于應用程序的延遲容忍度),以便動態地批量處理傳入的請求。然后,您可以通過推理服務器和 LLM 處理這些批次。這種方法可以幫助提高系統的吞吐量,并確保 GPU 以接近最佳的利用率運行。
雖然您可以在定制系統中實現自定義排隊和批處理邏輯,但vLLM、NVIDIA Triton Inference Server和AWS Bedrock等可用于生產的工具提供了適合大多數用例的強大、開箱即用的解決方案。?
智能模型路由模式
與其不加區分地將所有請求發送到規模最大、成本最高的模型,不如實現智能模型路由。這個想法簡單卻強大。在入口點引入一個輕量級的初始模型,類似于傳統微服務中的反向代理或 API 網關。與反向代理類似,該模型可以幫助在模型之間實現負載平衡、緩存頻繁響應,并優雅地處理回退。它還可以充當 API 網關,根據每個請求的復雜性或上下文,將查詢智能地路由到合適的下游模型。?
對于常見或重復的查詢,路由模型可以直接從緩存或預取中提取數據,從而完全避免模型推理。對于需要中等推理能力或領域特定知識的查詢,則路由到專門且經濟高效的模型。您應該只將最復雜或最模糊的查詢路由到規模最大的通用模型。
如果您正在構建處理各種查詢的通用系統,智能模型路由模式將特別有用。此模式可以平衡成本效率和模型準確性,確保每個查詢精確地使用其所需的計算資源。?
高級模式
本文探討了可以幫助您將最佳實踐融入 AI 軟件開發不同階段的基礎模式。然而,我們有意忽略了一些高級領域。不過,我想簡要提一下三個關鍵主題,它們包含許多新興模式和最佳實踐,因為它們在現代 AI 系統中正變得至關重要。
- 微調和定制模型:有時,現成的模型不足以滿足您的特定用例,或者價格過高,或者需要在本地網絡或設備上運行。這時,對大型基礎模型進行微調、定制和優化將對您的用例大有裨益。常見的方法包括領域特定微調、知識提煉、低秩自適應 (?LoRA?)、混合專家 (?MoE?) 和量化。Hugging Face、VertexAI 和 AWS Bedrock 等平臺使您能夠輕松地定制和微調模型。
- 多智能體編排:當任務過于復雜,單個模型無法勝任時,可以考慮使用多個專門的AI智能體協同工作。你會遇到的一些常見模式包括:法學碩士(LLM-as-a-Judge)、基于角色的多智能體協作、 ?反射循環和使用工具的智能體。
- 代理人工智能與自主系統:可以說,構建自主人工智能代理是當今最熱門的領域之一。代理系統涉及能夠獨立動態規劃、推理和執行復雜任務的模型,通常使用外部工具和 API。代理人工智能是一個引人入勝且快速發展的領域,擁有其自身新興的最佳實踐。它值得我們在此范圍之外進行專門的探索。
這些高級概念超出了我們目前的范疇。認識到它們的重要性是跟上現代人工智能系統不斷發展的趨勢的關鍵。關注不斷增長的創新人工智能模式,并不斷將它們添加到你的技能庫中。它們可以幫助你解鎖更強大、更專業的應用程序!











學習筆記(CLASS 1):組件)

)

JVM 內存模型更新與 G1 垃圾收集器優化)



