
1. 前言
隨著互聯網內容形態的多樣化發展,用戶生成內容(UGC)呈現爆發式增長。社交平臺、直播、短視頻、語聊房等應用場景中,海量的音視頻內容需要進行實時審核,以維護平臺安全與用戶體驗。
然而,企業在構建審核系統時通常面臨以下挑戰:
-
審核準確性:需要精準識別多種媒介中的違規內容,減少誤判率
-
實時性要求:在直播等場景要求盡可能快地獲取結果
-
成本壓力:審核成本高昂,自建審核平臺投入大
-
規則定制:不同場景下的審核標準各異,需要靈活配置
-
系統穩定性:需要支持高并發且保證服務可用性
基于此,我們將介紹如何利用開源項目,以及亞馬遜云科技的服務,包括 Amazon Bedrock、Amazon Rekognition、Amazon SageMaker 等,構建一個性價比高、支持多模態內容審核、響應延遲低、規則可配置的直播、存量音視頻審核解決方案。
2.直播審核簡介
2.1 直播審核整體架構圖
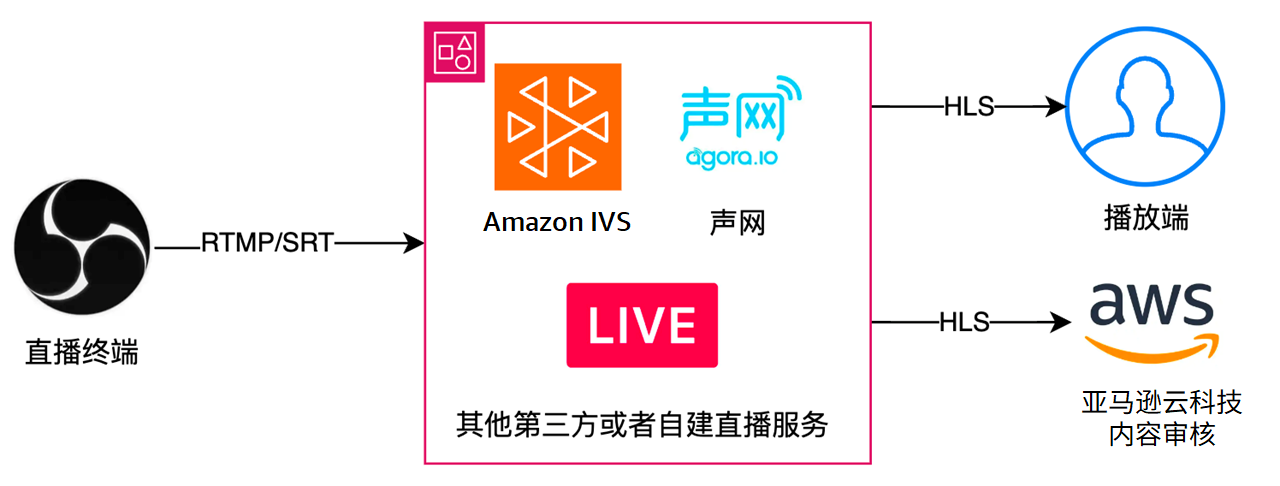
本方案支持基于實時視頻流的審核,僅需提供播放鏈接,即可進行審核。
2.2 直播審核亞馬遜云科技架構圖
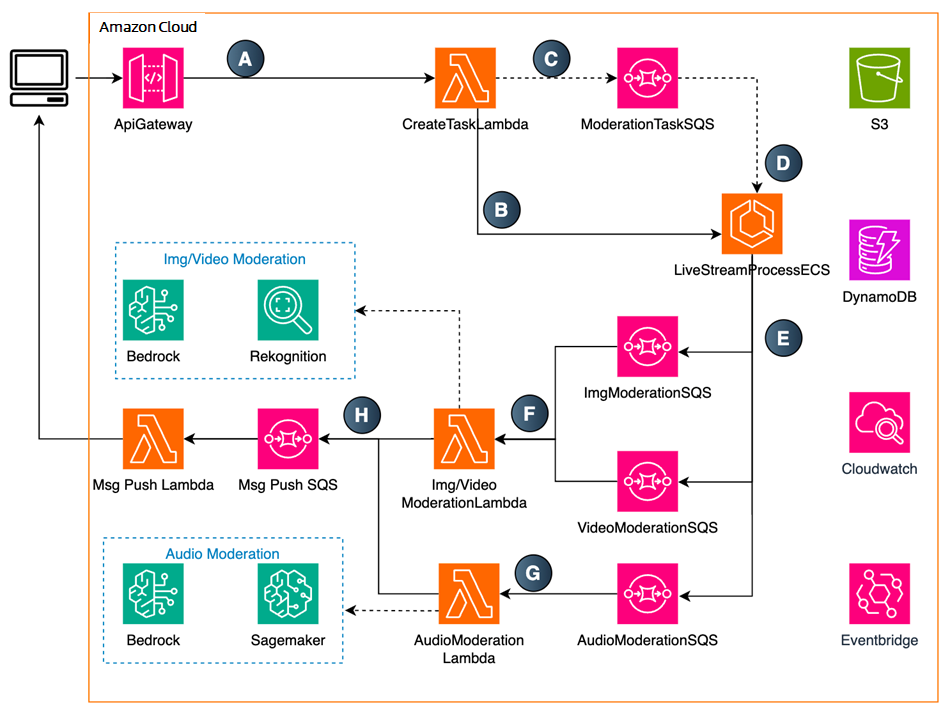
服務簡介:
-
Amazon Lambda:是一項無服務器計算服務,可執行您的代碼,可快速幫助您將想法轉化為應用程序。
-
Amazon SQS:適用于微服務、分布式系統和無服務器應用程序的完全托管的消息隊列。
-
Amazon DynamoDB:無服務器、NoSQL、完全托管的數據庫,在任何規模下均具有個位數毫秒級的性能。
-
Amazon ECS:是一項完全托管式容器編排服務,可幫助您更高效地部署、管理和擴展容器化的應用程序。
-
Amazon Fargate:是一種無服務器的計算引擎,可讓您專注于構建應用程序,而無需管理服務器。
-
Amazon Rekognition:利用機器學習技術自動執行圖像識別和視頻分析并降低成本,支持內容審核、人臉識別、面孔比較、名人識別等諸多功能。
-
Amazon Sagemaker:是一站式機器學習平臺,支持大規模構建、訓練和部署機器學習模型。我們可以在 Amazon SageMaker 中部署 ASR 模型(如 Whipser)。
-
Amazon Bedrock: 是一項完全托管的服務,通過 API 即可輕松調用 Amazon Nova、Anthropic Claude、Meta Llama、Stable Diffusion 等前沿的高性能基礎模型。我們可以通過 Amazon Bedrock 調用 Amazon Bedrock Marketplace 中的 ASR 模型(如 Whisper)。
架構簡介:
A. 通過 ApiGateway 發送審核請求到 CreateTask Lambda。
B. CreateTask Lambda 創建 ECS Fargate 任務用于處理直播流(為降低延遲 ECS 中可預置部分 Fargate)。
C. CreateTask Lambda 將審核任務信息(播放鏈接、用戶信息等)存入 ModerationTaskSQS 以及 DynamoDB。
D. ECS 中的 Fargate 服務從 ModerationTaskSQS 獲取消息,并處理直播流。
E. ECS 從直播流中截取圖片/視頻(直播視頻的視覺審核,可通過截取直播視頻中的圖片或者短視頻進行審核)、音頻文件存入 S3,并將音頻/圖片/視頻審核信息存入 SQS。
F. 圖片/視頻審核的 SQS 觸發 Image/Video ModerationLambda,調用 Bedrock 中的模型/Rekogniton 進行審核。
G. 音頻審核的 SQS 觸發 Audio ModerationLambda,首先調用 SageMaker 中的 Whisper 進行語音識別,然后調用 Bedrock 中的模型進行審核。
H. 音頻/圖片/視頻審核審核完成后,會將信息存入 Dynamodb,將違規素材存入 S3,同時將信息存入 MessagePush SQS。SQS 會調用 MessagePush Lambda 給用戶的回調服務器推送消息。
方案費用:
本方案采用無服務器架構,只需為用量付費,并可享受部分免費套餐。其中部分費用如下:
-
Amazon Nova Micro:進行文本審核,每 1000token 僅需 $0.000035。
-
Amazon Nova Lite:進行圖片/視頻審核,每 1000token 僅需 $0.00006。
-
Amazon DynamoDB:免費提供 25GB 的存儲量以及每月最多 2 億次讀/寫請求(永久)。
-
Amazon SQS:每月免費提供 100 萬的請求(永久)。
-
Amazon Api Gateway:每月接收 100 萬次 API 調用(12 個月內)。
-
Amazon Lambda:每月免費提供 100 萬個請求(永久)。
-
Amazon Rekognition:每月可以免費使用 Rekognition 分析 1000 張圖像(12 個月內)。
直播審核涉及的技術點主要有直播流處理、音頻審核、文本審核、圖像審核。
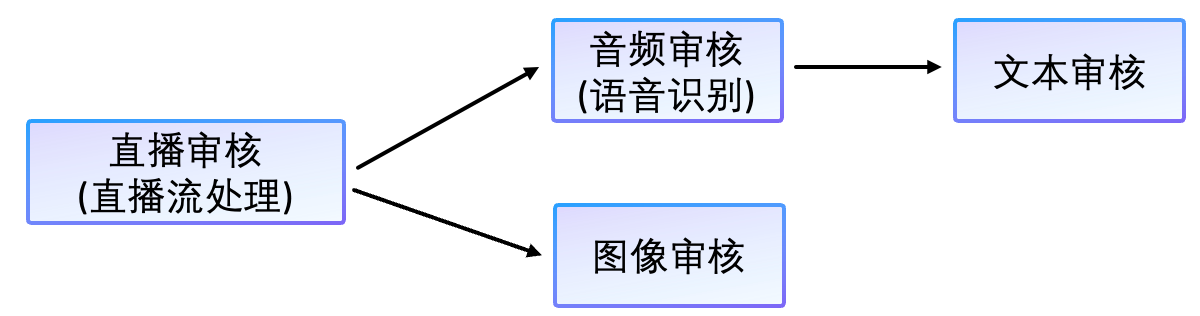
2.3 直播流處理
我們可以通過 FFmpeg 處理直播流。針對直播中的聲音,可以通過 FFmpeg 截取音頻。針對直播中的圖像,可以通過 FFmpeg 截取圖片或視頻(無聲)。
FFmpeg 是一個強大的多媒體處理工具,常用于音視頻轉碼、剪輯、格式轉換等。在 AWS 上,除傳統虛擬機外,還支持通過 Lambda 或 Fargate 等 Serverless 服務來部署 FFmpeg。通過 Lambda 和 Fargate 部署 FFmpeg 的區別如下:
-
Amazon Lambda 部署 FFmpeg:適用于短時、低頻的處理任務,按使用量計費,無需管理服務器,支持高并發。但受 15 分鐘執行時間限制,適用于短音視頻處理。
-
Amazon Fargate 部署 FFmpeg:適用于長時間、高性能處理任務,自動擴展計算資源。無需管理容器。相比 Lambda,適合復雜和大規模需求的處理。
通過 FFmpeg 從直播流中截取音頻的代碼如下:
#音頻截幀時長
audio_segment_duration=10
audio_dir ="audio"
media_url="lee.mp4"
stream = ffmpeg.input(media_url,)
audio_output_pattern = os.path.join(audio_dir, '%06d.wav')audio_output = ffmpeg.output(stream['a:0'], audio_output_pattern,acodec='pcm_s16le',ar=16000,ac=1,f='segment',segment_time=audio_segment_duration,reset_timestamps=1)通過 FFmpeg 從直播流中截取圖片的代碼如下:
#圖片截幀頻率
snapshot_interval=1
img_dir = "image"
stream = ffmpeg.input(media_url,)
image_output_pattern = os.path.join(img_dir, '%06d.jpg')image_output = ffmpeg.output(stream['v'], image_output_pattern,vf=f'fps=1/{snapshot_interval}',start_number=0
)
通過 FFmpeg 從直播流中截取無聲視頻的示例代碼如下:
#### 小標題
video_output = ffmpeg.output(stream.video, output_pattern,c='copy',f='segment',segment_time=segment_duration,reset_timestamps=1)下一步我們需要分別對音頻及圖像(圖片或無聲視頻)進行審核。
2.4 音頻審核
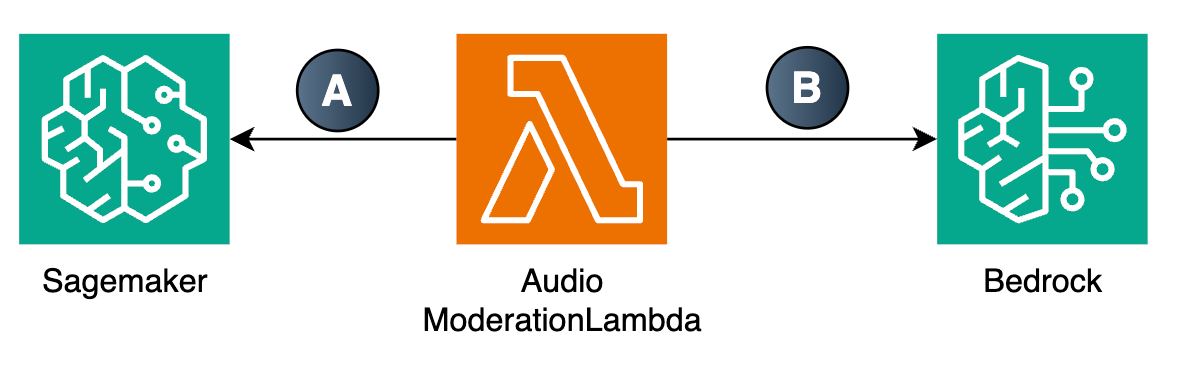
音頻審核通常需要先將語音轉換為文本,再利用文本審核技術識別違規內容。
在本方案中我們在 Audio Moderation Lambda 中調用 SageMaker 中的 Whipser 進行語音識別獲取文本。然后調用 Bedrock 中的 Nova/Claude 對文本進行審核。
在亞馬遜云科技有多種方式均可實現語音識別,我們以 SageMaker 部署自定義 ASR 模型(如 Whisper)為例。首先在 SageMaker 中創建筆記本實例。

然后在 SageMaker Notebook 中運行以下代碼即可部署 Whipser 推理端點。
import sagemaker
import boto3
from sagemaker.huggingface import HuggingFaceModeltry:role = sagemaker.get_execution_role()
except ValueError:iam = boto3.client('iam')role = iam.get_role(RoleName='sagemaker_execution_role')['Role']['Arn']hub = {'HF_MODEL_ID':'openai/whisper-large-v3-turbo','HF_TASK':'automatic-speech-recognition'
}huggingface_model = HuggingFaceModel(transformers_version='4.37.0',pytorch_version='2.1.0',py_version='py310',env=hub,role=role
)my_endpoint_name="content-moderation-endpoint-whisper"predictor = huggingface_model.deploy(initial_instance_count=1, instance_type='ml.g4dn.xlarge' ,endpoint_name=my_endpoint_name
)
在審核項目中使用以下代碼即可以調用 SageMaker Endpoint 中的 Whisper 將音頻轉為文本。
with open(local_file, 'rb') as audio_file:audio_data = audio_file.read()sagemaker_runtime = boto3.client('sagemaker-runtime', REGION_NAME)response = sagemaker_runtime.invoke_endpoint(EndpointName=WHISPER_ENDPOINT_NAME,ContentType='audio/x-audio',Body=audio_data)print(json.loads(response['Body'].read().decode()))為了提高 Whisper 轉錄的效率以及提高 Whisper 的準確率,可以在調用 Whisper 之前將音頻使用 VAD 進行預處理,從音頻中提取人聲,然后再將音頻文件交給 Whisper 進行識別。
除在 SageMaker 中部署 ASR 模型的方式外,亞馬遜云科技還提供多種語音識別(ASR)相關的服務,助力高效音頻審核:
-
Amazon Transcribe:完全托管的語音識別服務,基于強大語音模型,為流式或錄制音頻提供高精度轉錄,適用于大規模、高實時性場景。
-
Amazon Bedrock:支持通過 API 訪問領先的模型,無需管理基礎設施,即可調用模型(如 Whisper)。
2.5 文本審核
通過語音識別獲取到音頻文本后,可以通過 Amazon Bedrock 調用 Nova/Claude 等大語言模型對文本審核。
通過大語言模型進行文本審核的示例提示詞如下:
你是一個論壇的審核員,需要維護網絡環境,請對下面用戶提供的內容進行文本審核,判斷是否涉及色情、仇恨、賭博、辱罵等違規內容。我們會根據你反饋的內容,選擇是否封禁這段內容。用戶提供的內容為:
xxxxxxxxxxxxxxx通過 Amazon Bedrock 進行文本審核的優勢在于高效性、準確性和可擴展性。
-
它能快速處理海量文本,識別敏感信息、違規內容及潛在風險。
-
LLM 具備上下文理解能力,能更精準地判斷語境,減少誤判率。
-
LLM 支持多語言,適應性強
-
LLM 能根據規則通過修改提示詞的方式自定義優化審核標準。
此外,使用 Amazon Bedrock 進行審核,極具性價比。使用 Nova Micro 進行文本審核,每 1000token 僅需 $0.000035。
*許多基礎模型在 API 調用中會重復使用提示詞的某些部分。通過提示緩存,可允許在請求中緩存這些重復的提示前綴。該緩存允許模型跳過重新計算匹配前綴的步驟。對于支持的模型,Amazon Bedrock 中的提示緩存可將成本降低多達 90%,并將延遲減少高達 85%。
2.6 圖像審核

在亞馬遜云科技上我們有兩種技術路線可以用來進行圖像審核:Amazon Bedrock 中的多模態 LLM 或 Amazon Rekognition 服務,他們的大致特點如下:
Amazon Rekognition:
-
利用機器學習技術自動執行圖像識別和視頻分析并降低成本,支持內容審核、人臉識別、面孔比較、名人識別等諸多功能。
-
Rekognition 默認支持 31 個類別的圖片審核,并支持用戶自定義標簽。
-
Rekognition 根據用量每張圖審核的價格為 001-0.00025。
Amazon Bedrock:
-
Bedrock 中的 Nova/Claude 模型支持對圖片進行批量審核。
message_list = [{"role": "user","content": [{"text": "下方圖片為image 1"},{"image": {"format": "png","source": {"bytes": "base64_string"}}},{"text": "下方圖片為image 2"},{"image": {"format": "png","source": {"bytes": "base64_string"}}},{"text": "請對圖片進行審核."}]}
]-
Bedrock 中的 Nova Lite/Pro 模型支持視頻(無聲)進行審核。
#方式1:直接上傳視頻進行審核
message_list = [{"role": "user","content": [{"video": {"format": "mp4","source": {"bytes": base64_string},}},{"text": "請對該視頻進行審核."},],}
]
#方式2:支持直接審核S3中的視頻
{"video": {"format": "mp4","source": {"s3Location": {"uri": "s3://my_bucket/my_video.mp4"}}}
}LLM 審核支持自定義提示詞,對審核的規則進行調整。
-
Amazon Nova Lite 每 1000 token $0.00006。
-
Amazon Nova Pro 每 1000 token $0.0008。
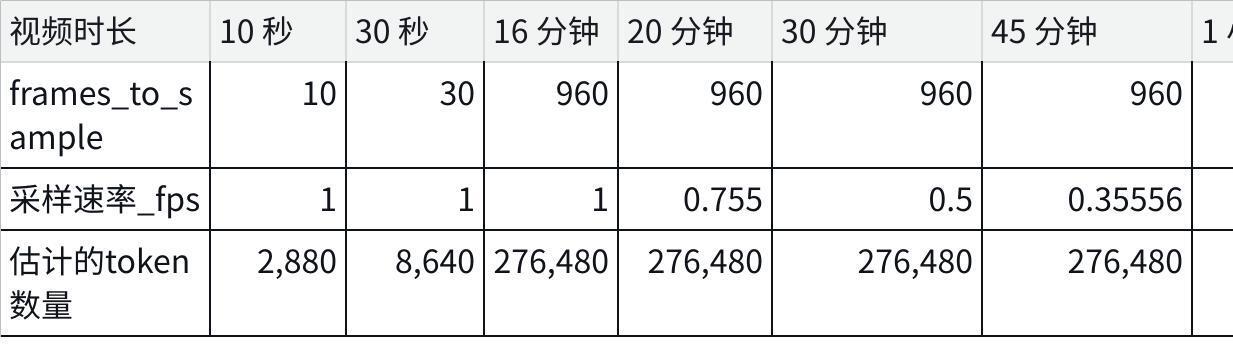
*通過 Nova 進行視頻審核,極具性價比。下表列出了每個視頻長度的幀采樣和令牌使用率的一些近似值:
3. 存量音視頻審核簡介
本方案除直播審核外,同樣支持存量音視頻的審核。
3.1 長視頻/音頻審核
如果音視頻時長大于 15 分鐘,建議使用 ECS 進行對音視頻進行截取。
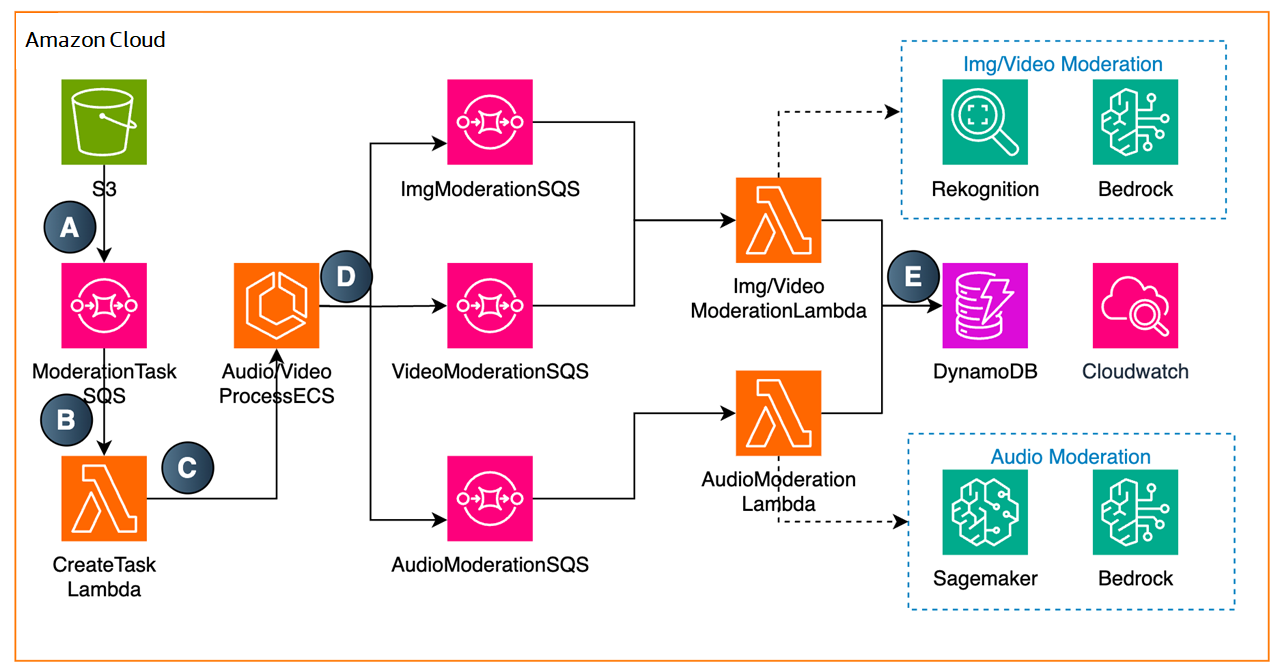
A. 將文件存入 S3,S3 通過事件觸發 ModerationTaskSQS。
B. ModerationTaskSQS 觸發 CreateTask Lambda。
C. CreateTask Lambda 創建 ECS 任務用于處理音視頻文件。
D. AudioVideo ProcessECS 將截取后的音視頻文件存入 S3,并將審核信息存入 DynamoDB,同時將審核任務信息存入圖像/視頻/音頻審核的 SQS。
E. 音頻/圖片/視頻審核審核完成后,會將信息存入 DynamoDB。
3.2 短視頻/短音頻審核
如果音視頻時長小于等于 15 分鐘,建議使用 Lambda 進行對音視頻進行審核。
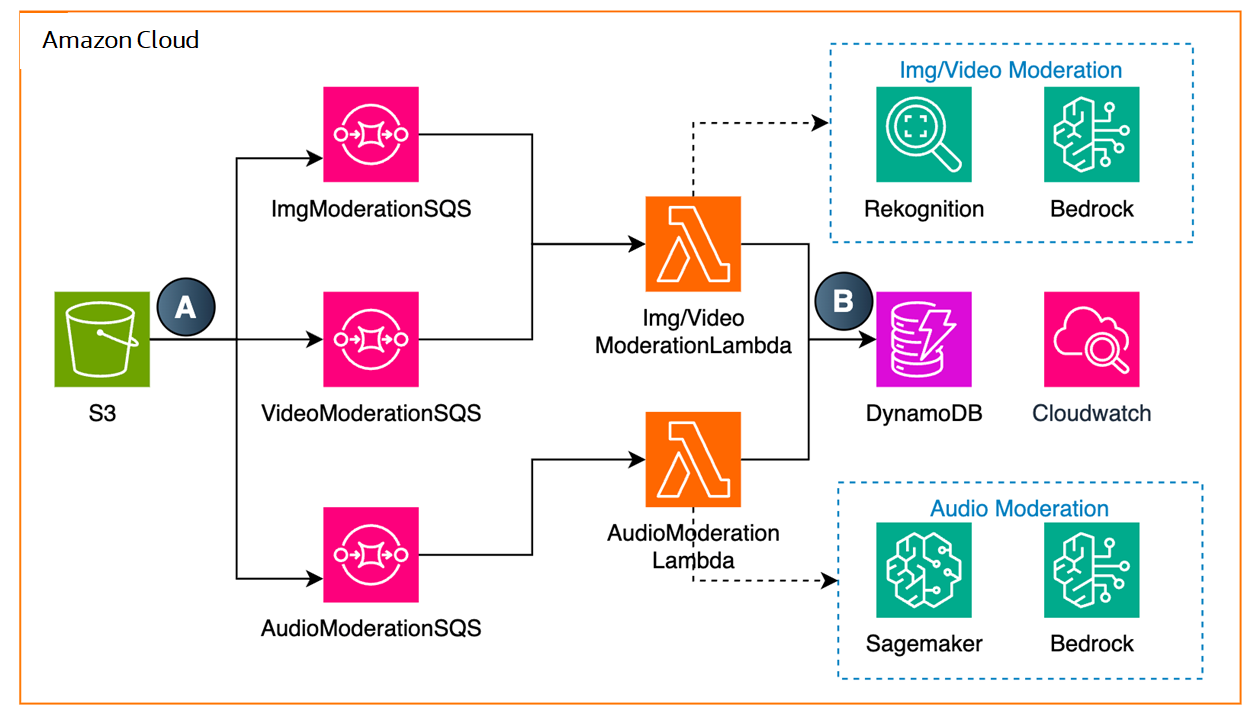
A. 將文件存入 S3,S3 通過事件觸發圖像/視頻/音頻審核的 SQS,然后調用 Lambda 進行審核。
B. 音頻/圖片/視頻審核審核完成后,會將信息存入 DynamoDB。
4. 部署與測試
本方案支持通過 CDK 進行部署。
4.1 直播審核測試
4.1.1 準備直播流
1、在 IVS 控制臺創建直播通道
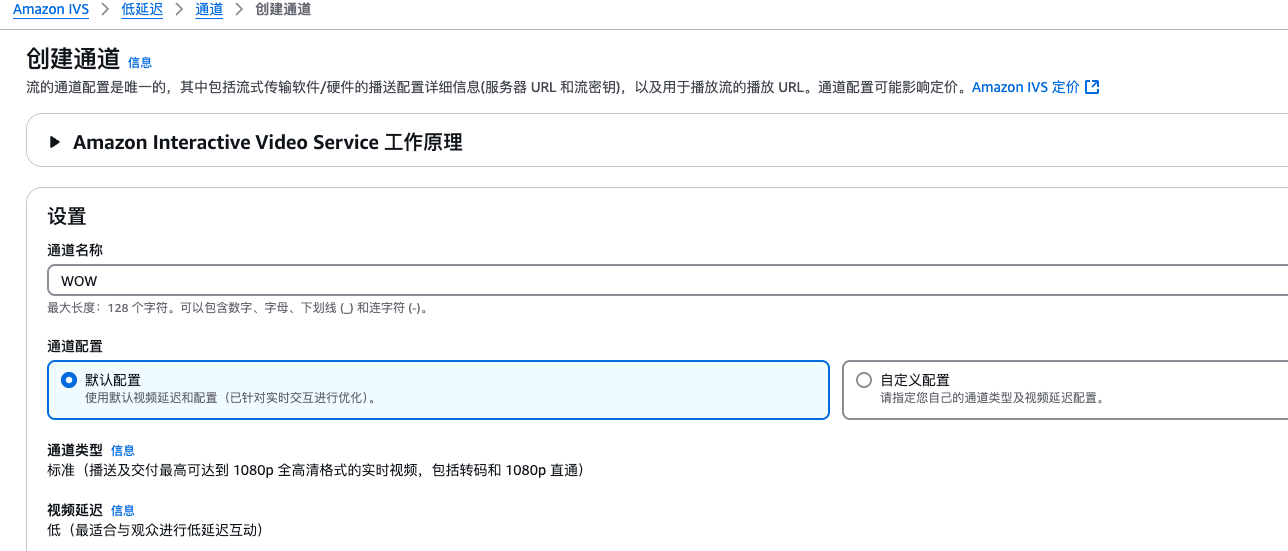
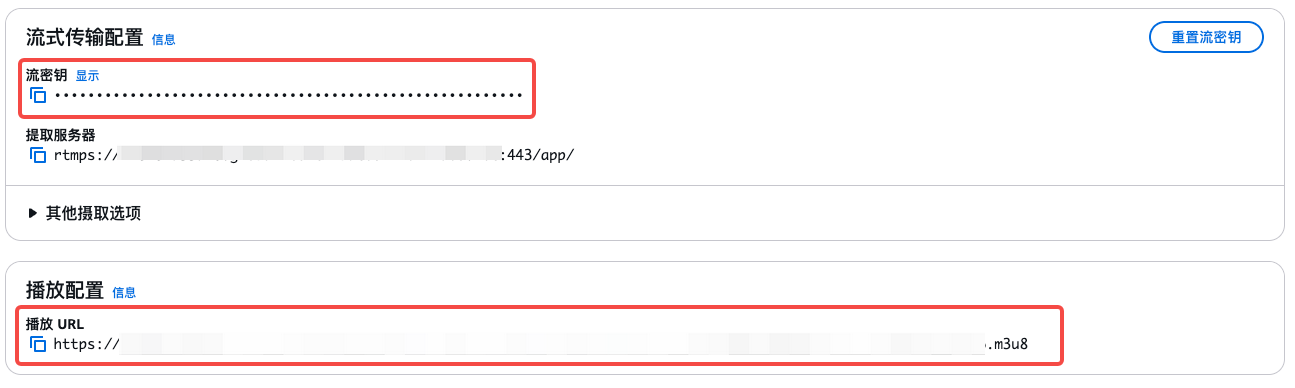
2、在直播通道詳情頁面,獲取推流地址、流密鑰與播放地址
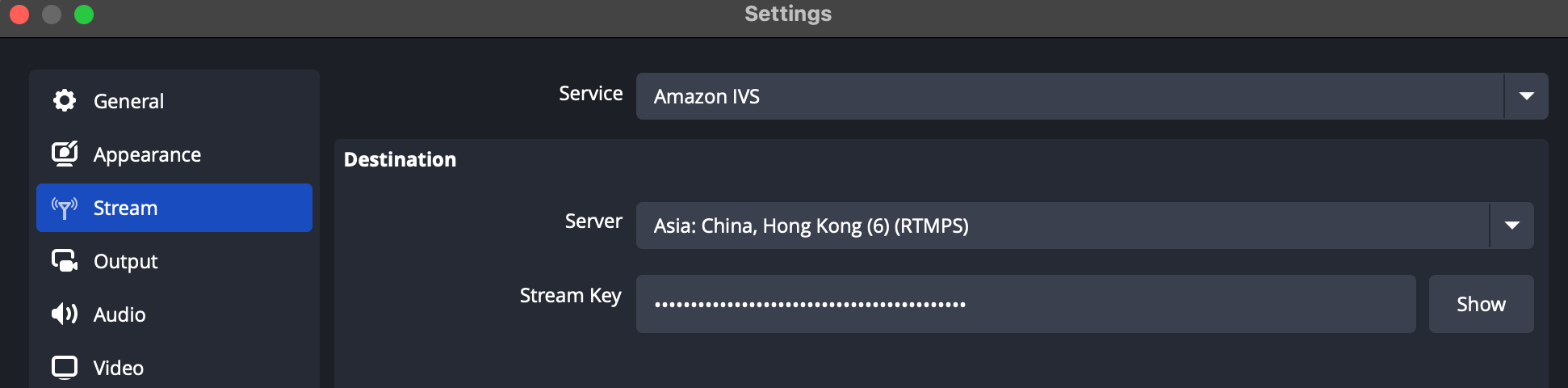
3、在 OBS 等推流軟件,配置推流密鑰/推流地址
*Amazon IVS :互動視頻服務,采用與全球知名直播流媒體平臺 Twitch 相同的技術,只需幾分鐘即可構建流媒體互動直播。
4.1.2 直播審核
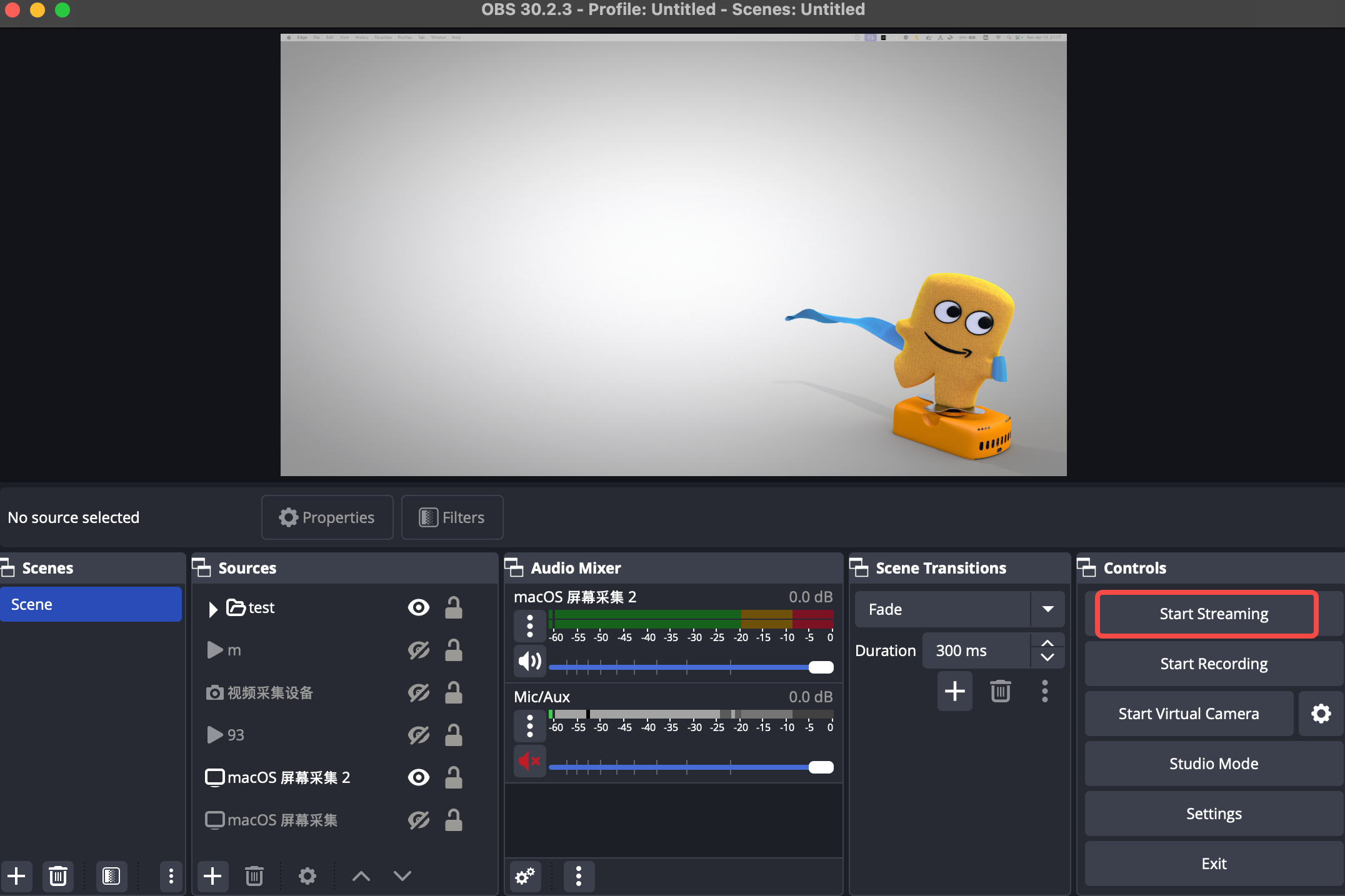
1、在 OBS 軟件點擊開啟直播
2、調用直播審核接口即可進行直播審核
curl --location 'https://xxxxxx/api/submit_moderation' \
--header 'user_id: [YOUR_USER_ID]' \
--header 'token: [YOUR_TOKEN]' \
--header 'Content-Type: application/json' \
--data '{"url":"https://xxxxxx/xxx/xxx.m3u8"
}'4.2 存量音視頻審核測試
在 S3 存儲桶中創建 s3_audio_moderation、s3_video_moderation 文件夾。將音視頻文件放入對應的目錄即可實現審核。
5. 總結
本文介紹了一種基于亞馬遜云服務、ffmpeg 的音視頻審核方案。該方案為音視頻審核提供了完整的端到端解決方案和參考實現。基于 AWS Serverless 服務,在確保高可用的同時,用戶只需為實際用量進行付費。基于 Amazon Bedrock 等服務,可以實現高效的審核,有效幫助用戶實現降本增效。
希望本文能夠為大家進行音視頻審核時提供靈感。如果你對該項目感興趣,歡迎關注、試用并提出寶貴建議,共同推動審核技術的發展!
*前述特定亞馬遜云科技生成式人工智能相關的服務僅在亞馬遜云科技海外區域可用,亞馬遜云科技中國僅為幫助您了解行業前沿技術和發展海外業務選擇推介該服務。
參考鏈接
內容審核項目地址:https://github.com/aws-samples/sample-for-content-moderation
Amazon Bedrock:使用基礎模型構建生成式人工智能應用程序 – Amazon Bedrock – AWS
Amazon Nova:https://aws.amazon.com/cn/ai/generative-ai/Nova
Amazon Rekogniton:Amazon Rekognition 圖像識別_圖片識別服務-AWS云服務
Amazon Sagemaker:Amazon SageMaker 機器學習_機器學習模型構建訓練部署-AWS云服務
Amazon IVS:交互式直播流 — Amazon Interactive Video Service — Amazon Web Services
Prompt Caching:緩存請求之間的提示 – Amazon Bedrock 提示緩存 – AWS
本篇作者

本期最新實驗《多模一站通 —— Amazon Bedrock 上的基礎模型初體驗》
? 精心設計,旨在引導您深入探索Amazon Bedrock的模型選擇與調用、模型自動化評估以及安全圍欄(Guardrail)等重要功能。無需管理基礎設施,利用亞馬遜技術與生態,快速集成與部署生成式AI模型能力。
??[點擊進入實驗] 即刻開啟 AI 開發之旅
構建無限, 探索啟程!
)

JVM 內存模型更新與 G1 垃圾收集器優化)






![【題解-洛谷】P6180 [USACO15DEC] Breed Counting S](http://pic.xiahunao.cn/【題解-洛谷】P6180 [USACO15DEC] Breed Counting S)

 - /安全與維護組件/industrial-firewall-dcs-protection)



)



