摘要
最近,視覺語言導航(VLN)——要求機器人代理遵循導航指令——已經取得了巨大的進步。然而,現有文獻最強調將指令解釋為行動,只提供“愚蠢”的尋路代理。在本文中,我們設計了 LANA,一種支持語言的導航代理,它不僅能夠執行人類編寫的導航命令,還能夠向人類提供路線描述。這是通過僅使用一個模型同時學習指令跟隨和生成來實現的。更具體地說,分別用于路由和語言編碼的兩個編碼器由兩個分別用于動作預測和指令生成的解碼器構建和共享,以便利用跨任務知識并捕獲特定于任務的特征。在整個預訓練和微調過程中,指令跟蹤和生成都被設置為優化目標。我們憑經驗驗證,與最新的先進任務特定解決方案相比,LANA 在指令跟蹤和路由描述方面都獲得了更好的性能,并且復雜度接近一半。此外,LANA具有語言生成能力,可以向人類解釋其行為并協助人類尋路。這項工作預計將促進未來構建更值得信賴和社交智能導航機器人的努力。
引言
開發能夠以自然語言與人類交互,同時在環境中感知并采取行動的智能體,是人工智能的基本目標之一。作為朝著這一目標邁出的一小步,視覺語言導航(VLN)[4]——賦予智能體執行自然語言導航命令——最近受到了極大的關注。在 VLN 領域,人們在語言基礎方面做了很多工作——教導智能體如何將人類指令與感知相關的動作聯系起來。然而,在相反的方面——語言生成——教智能體如何用語言生動地描述導航路線,卻很少有工作[27,71,1,78,23]。更重要的是,現有的 VLN 文獻分別訓練專門針對每個任務的代理。結果,交付的代理要么是強大的尋路演員但從不說話,要么是健談的路線指導員但從不走路。
本文強調了 VLN 中的一個基本挑戰:我們能否學習一個既能夠遵循導航指令又能夠創建路線描述的代理?
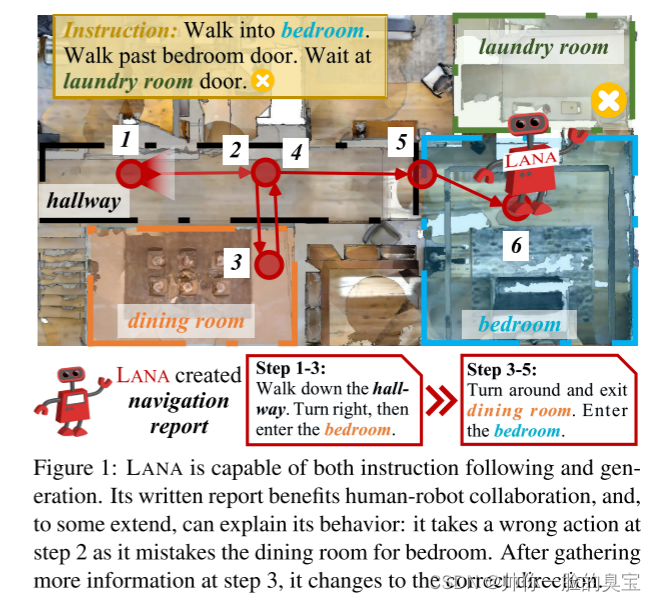
我們提出 LANA,一種具有語言能力的導航代理,它充分意識到這種挑戰(圖 1)。通過同時學習指令基礎和生成,LANA 將人與機器人和機器人與人的通信形式化,并在統一的框架中使用面向導航的自然語言進行傳達。這非常重要,因為:i)它完成了人類和智能體之間必要的通信周期,并促進了 VLN 智能體在現實世界中的效用[59]。例如,當代理需要很長時間來執行導航命令時,在此期間持續的人類注意力是不可行且不可取的,代理應該報告其進度[73]。此外,智能體還需要在智能體探索的區域中引導人類 [82],這與災區的搜索和救援機器人 [72, 19]、公共場所的引導機器人 [78] 以及視障人士的導航設備相關[36]。 ii) 雙向通信是緊密的人機協調不可或缺的一部分(即“我將繼續這樣……”)[7],并增強人類對機器人的信任[6, 24],從而提高導航機器人的接受度。 iii)發展語言生成技能可以制造出更易于解釋的機器人,它們可以以人類可讀的路線描述的形式解釋其導航行為。
從技術上講,LANA 是一個基于 Transformer 的多任務學習框架。該網絡由兩個單模態編碼器組成,分別用于語言和路由編碼,以及基于這兩個編碼器的兩個多模態解碼器,分別用于路由到指令和指令到路由翻譯。在預訓練和微調階段,整個網絡都是通過指令基礎和生成任務進行端到端學習的。綜上所述,LANA 提供了一個統一、強大的框架,探索模型設計和網絡訓練核心的特定任務和跨任務知識。因此,即使在沒有明確監督的情況下,LANA 也可以更好地理解語言線索(例如單詞、短語和句子)、視覺感知、長期行動及其關系,并最終使這兩項任務受益。
我們在三個著名的 VLN 數據集(即 R2R [4]、R4R [38]、REVERIE [63])上進行了廣泛的實驗,用于指令跟蹤和生成,給出了一些有趣的點:首先,LANA 使用以下方法成功解決了這兩個任務:只需一臺代理,無需在不同型號之間切換。其次,憑借優雅的集成架構,LANA 的性能可與最近領先的特定任務替代方案相媲美,甚至更好。第三,與單獨學習每個任務相比,在兩個任務上聯合訓練 LANA 可以獲得更好的性能,同時降低復雜性和模型大小,證實了 LANA 在跨任務相關性建模和參數效率方面的優勢。第四,LANA 可以通過口頭描述其導航路線來向人類解釋其行為。 LANA 本質上可以被視為一個可解釋的 VLN 機器人,配備了自適應訓練的語言解釋器。第五,主觀分析表明我們的語言輸出質量高于基線,但仍然落后于人類生成的話語。雖然仍有改進的空間,但我們的結果揭示了未來 VLN 研究的一個有希望的方向,在可解釋的導航代理和機器人應用方面具有巨大的潛力。
相關工作
navigation instruction following
構建基于語言的自主導航代理是自然語言處理和機器人社區的長期目標。 Anderson 等人并未將之前的研究局限于受控環境背景 [55,72,10,5,57]。 [4] 將此類任務提升到逼真的環境 - VLN,激發了人們對計算機視覺領域日益增長的興趣。早期的努力是建立在循環神經網絡的基礎上的。他們探索不同的訓練策略 [84, 83],從合成樣本 [27, 71, 28] 或輔助任務 [83, 35, 53, 93, 78] 中挖掘額外的監督信號,并探索智能路徑規劃 [39, 54, 81]。對于結構化和遠程上下文建模,最近的解決方案是通過環境地圖[92,13,21,80],transformer架構[33,61,48,64,11]和多模態預訓練[56,31,30,12]開發的。
與專門用于follower導航指令的現有 VLN 解決方案不同,我們雄心勃勃地構建一個強大的代理,它不僅能夠執行導航指令,還能夠描述其導航路線。我們在整個算法中都堅持這個目標——從網絡設計到模型預訓練,再到微調。通過共同學習指令執行和生成,我們的智能體可以更好地將指令轉化為感知和行動,并在一定程度上解釋其行為并培養人類信任。我們的目標導航和視覺對話導航[73]是不同的(但互補),因為后者只關注代理使用語言請求人類幫助的情況。
navigation instruction generation
對instruction creation的研究[17]可以追溯到20世紀60年代[52]。早期工作[88,2,51]發現人類路線方向與認知地圖[42]相關,并受到許多因素的影響,例如文化背景[74]和性別[37]。他們還達成了共識,即涉及路線導航和顯著地標可以使人類更容易遵循指令[50,77,67]。基于這些努力,一些計算系統是使用預先構建的模板 [50, 29] 或手工制定的規則 [18] 開發的。雖然在目標場景中提供高質量的輸出,但它們需要語言知識的專業知識和構建模板/規則的大量努力。一些數據驅動的解決方案[16,59,19,26]后來出現,但僅限于簡化的網格狀或感知較差的環境。
生成自然語言指令長期以來一直被視為社交智能機器人的核心功能,并且引起了許多學科的極大興趣,例如機器人學 [29]、語言學 [69]、認知 [42, 25]、心理學 [74] 和地球科學 [ 20]。令人驚訝的是,在具身視覺領域所做的工作卻很少。對于罕見的例外[27,71,68,1,78,23],[27,71,68]只是為了增強尋路的訓練數據,并且所有這些都學習專門用于指令生成的單個代理。我們的想法是根本不同的。我們要構建一個具有語言能力的導航代理,它能夠掌握指令遵循和創建。因此,這項工作代表了對社交智能、具體化導航機器人的早期但扎實的嘗試。
Auxiliary Learning in VLN
有幾種 VLN 解決方案 [53,93,79] 利用來自輔助任務的額外監督信號來幫助導航策略學習。對于輔助任務,代表性的包括下一步方向回歸[93]、導航進度估計[53]、路徑反向翻譯[93, 78]、軌跡指令兼容性預測[93]以及最終目標定位[92] ]。
這些 VLN 解決方案將重點放在指令遵循上;輔助任務是手段,而不是目的。相比之下,我們的目標是構建一個能夠很好地掌握指令跟隨和創建的單一智能體。盡管[78]在雙任務學習方案下同樣關注指令跟隨和生成,但它仍然學習兩個獨立的單任務智能體。此外,上述輔助任務原則上可以被我們的代理利用。
Vision-Language Pretraining for VLN
大規模圖像-文本對的視覺-語言預訓練[65,70,14]最近取得了快速進展。事實證明,可轉移的跨模式表示可以通過這種預訓練來交付,并促進下游任務[85,47,91,65,44,46]。這種訓練方式在 VLN 中越來越受歡迎。特別是,一些早期的努力 [45, 33] 直接采用通用視覺語言預訓練來進行 VLN,而沒有考慮任務特定的性質。隨后,[30,31,12]使用不同的 VLN 特定代理任務對豐富的網絡圖像標題 [30] 或合成軌跡指令對 [31, 12] 進行預訓練。 [11, 64] 引入歷史感知代理任務以進行更多 VLN 對齊的預訓練。
從代理任務的角度來看,現有的 VLN 預訓練遵循屏蔽語言建模機制 [40]。不同的是,我們的預訓練基于語言生成,這有助于智能體捕獲語言結構,從而達到對語言命令的全面理解并促進指令執行。一般視覺語言預訓練的最新進展[87,90,22,86]也證實了生成語言建模的價值。此外,對于 LANA 來說,指令生成不僅僅是預訓練后經常被丟棄的代理任務,而且也是預訓練期間的主要訓練目標。微調,是部署時基于語言的路由導向能力的根本基礎。

)





混淆矩陣)



)




)


