?
序言
- 記錄python使用過程中碰到的一些問題及其解決方法
- 上一篇:python常見編譯問題解決方法_1
1. PermissionError: [Errno 13] Permission denied: ‘/lost+found’

- 修改前:

- 修改后(解決):

- 此外,可能文件夾已被打開,也可能是無權限打開,或者打開一個文件而不是文件夾
2. No module named ‘lark’
-
報錯:ModuleNotFoundError: No module named ‘lark’
-
解決方法:
python3 -m pip install lark-parser
3. RuntimeError: Tensors must have same number of dimensions: got 3 and 2
- 報錯:有A[2, 16]、B[2, 4]兩個tensor變量, 使用torch.cat((A, B), 1)拼接列卻報錯
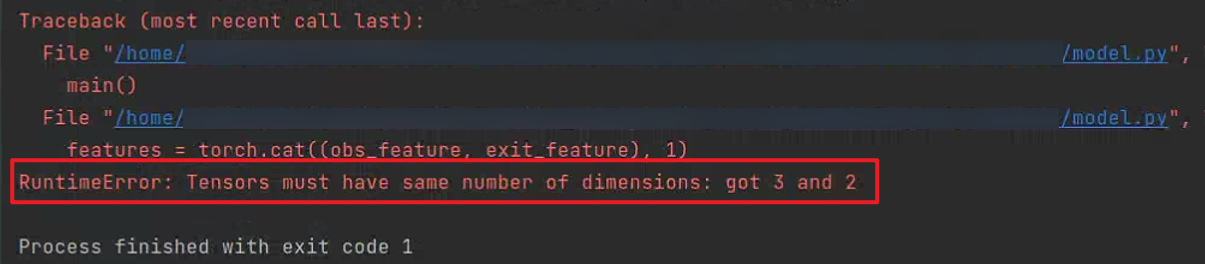
- 解決方法:注意到模型輸出帶梯度,如下截圖。如果不需要保留梯度信息,可以在變量變換之前加.detach()或.data調用,分離梯度信息

- tensor維度合并報錯,類似但不是
- tensor維度合并報錯,類似但不是
4. RuntimeError: Can’t call numpy() on Tensor that requires grad. Use tensor.detach().numpy() instead
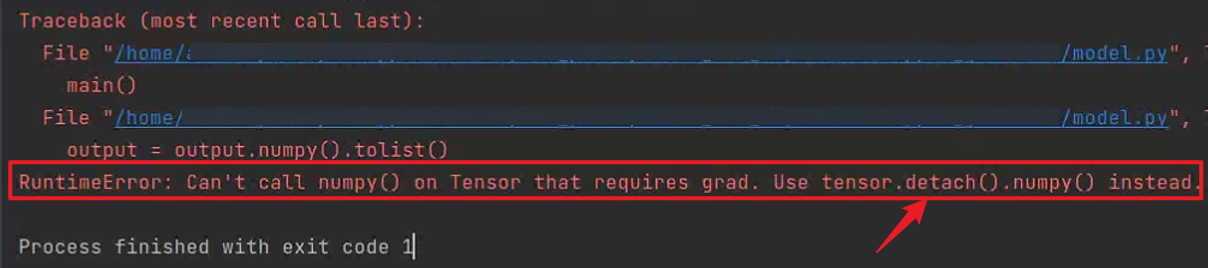
- 同上,在tensor轉換為list的過程中碰到
5. RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
- 報錯:需要梯度但是沒有梯度信息
- 報錯原因1:這里的loss默認的requires_grad是False,因此在backward()處不會計算梯度,導致出錯
- 報錯原因2:就是loss本身沒梯度,所以調用loss.backward()后向傳播時報錯,沒梯度的原因可能是loss_function的output沒有梯度,注意檢查
6. RuntimeError: Trying to backward through the graph a second time, but the saved intermediate results have already beed freed. Specify retain_grad=True when calling .backward() or autograd.grad() the first time.
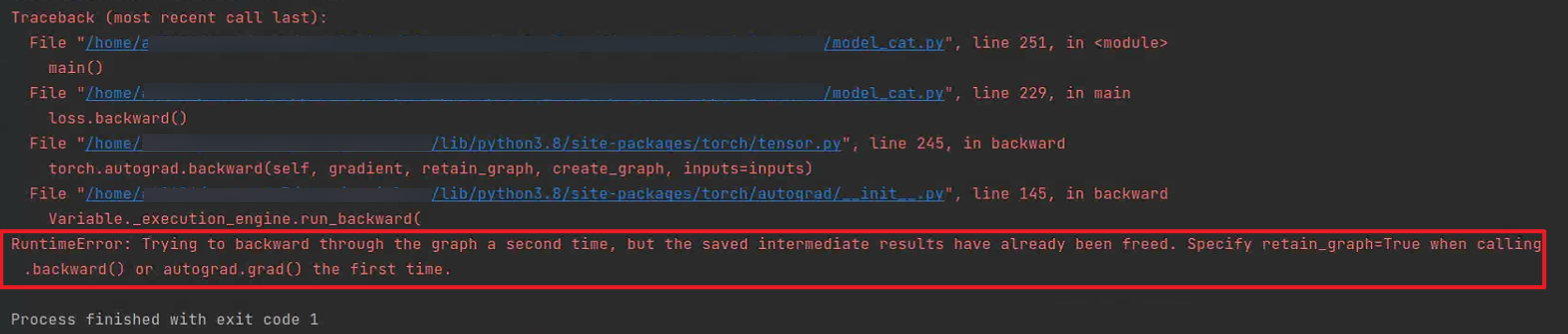
- 解決:需要更新的中間結果加.data分離梯度信息
7. RuntimeError: Input and hidden tensors are not at the same device, found input tensor at cuda:0 and hidden tensor at cpu
-
報錯:兩個tensor不在同一設備上device
-
解決:添加.to(Device解決),tensor變量需要保持在同一個設備上
-
參考:數據、網絡、損失函數放到GPU,init放到GPU或者model.to(Device),model初始化時.to(Device)
8. AttributeError: ‘torch.dtype’ object has no attribute ‘type’


-
報錯:使用np.mean(xx)去計算張量xx的均值
-
解決:np.mean可以操作list和array,但是此處的loss.data類型是torch.tensor, 需要使用torch.mean進行運算,torch.mean得到的結果也是tensor
-
補充:獲取張量的值 tensor.item()
9. ImportError: cannot import name ‘TypeAlias’ from ‘typing_extensions’

- 或報錯:TypeError: Plain typing_extensions.Self is not valid as type argument
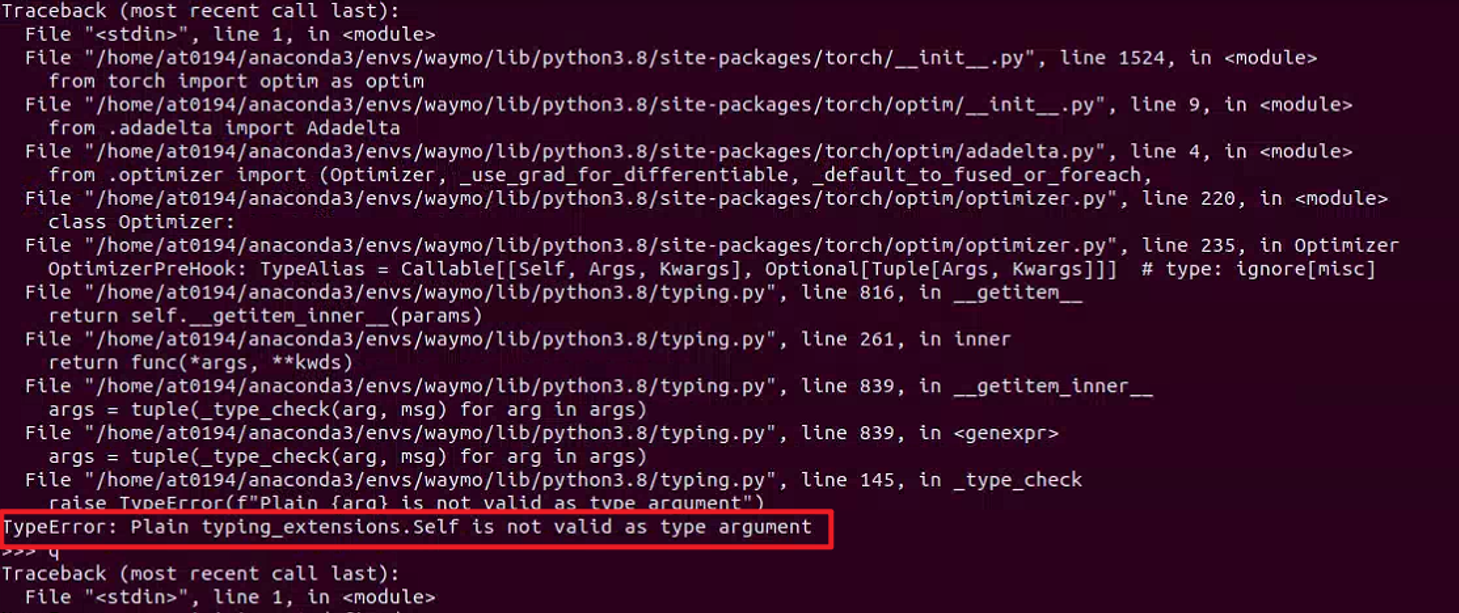
-
原因:以上兩個報錯都是typing_extensions版本過舊,使用了3.7.4
-
解決方法:直接升級typing_extensions版本
conda install typing_extensions=4.10.0 # 或其他版本
10. Torch.cuda.is_available()顯示GPU Driver過老
- 報錯:The NVIDIA driver on your system is too old, torch.cuda.is_available()=False

-
分析:GPU Driver版本11.1,并不老,我之前是通過如下命令在conda環境安裝torch:
pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html -
在網上查了這種情況需要重新裝一下cuda配套的pytorch版本
-
原因:不是GPU驅動版本老,而是pytorch版本和cuda版本不匹配
-
解決方法:重新安裝pytorch,如下
-
在該網站 https://pytorch.org/get-started/previous-versions/ 搜索cuda 11.1
-
按照該命令重裝后torch.cuda.is_available()查詢正常
# CUDA 11.1 pip install torch==1.10.1+cu111 torchvision==0.11.2+cu111 torchaudio==0.10.1 -f https://download.pytorch.org/whl/cu111/torch_stable.html
-
?
【參考文章】
[1]. Permission denied解決方案1
[2]. Permission denied解決方案2
[3]. 不保留梯度信息
[4]. 中間變量添加.data分離梯度信息
[5]. .data和.detach()的區別
[6]. pytorch和cuda版本不匹配
created by shuaixio, 2024.03.03


)




)



 方法)





)

