一、在爬蟲中,爬取的數據類型如下
1.document:返回的是一個HTML文檔
2.png:無損的圖片,jpg:壓縮后的圖片,wbep:有損壓縮,比png差,比jpg好
3.avg+xml圖像編碼字符串
4.script:腳本文件,依據一定格式編寫的可執行的文件
5.gif:圖像交換格式
6.xhr:返回的是json數據類型,在沒有刷新整個網頁的情況下,更新部分網頁,也稱Ajax請求
7.包后綴是css意味著其是css樣式
二、
1.幾個快捷進入開發者工具的指令:?
打開開發者工具方法:F12(鍵盤)/fn+f12/ctrl+shift+i
2.列表轉字符串方法:
str.join(列表)
如'\n'.join(selector.css('.noveContent p ::text').getall())
3.files = os.listdir(filename)? # 獲取文件夾下所有的小視頻
with zipfile.ZipFile(filename+title+'.mp4',mode='w') as z:
? ? ? ? z.write(content)
?4.print(response.text)后,在下方,按住ctrl+f鍵可以搜索如下圖

?點擊:
點擊.*可以用正則表達式,如果用正則表達解析數據,可以在這里嘗試,可以看見匹配的數量,然后再寫入代碼中。
5.列表中嵌套元祖,如何快速找出元祖中的元素。
如:a=[(1,'as'),(2,'ajsh'),(781,'ajhsasa')]

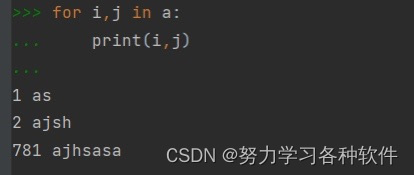
用第二張圖的方法,可以直接取出元素
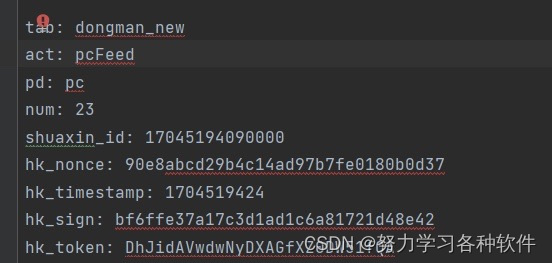
6.遇到參數很多,加冒號很麻煩怎么辦,如下圖:
?
?首先選中代碼,按ctrl+r出現下圖:
點擊·*進入正則,寫入下圖: ?
?
代碼是:?(.*?): (.*)
'$1': '$2',
點擊replaceall
結果展現: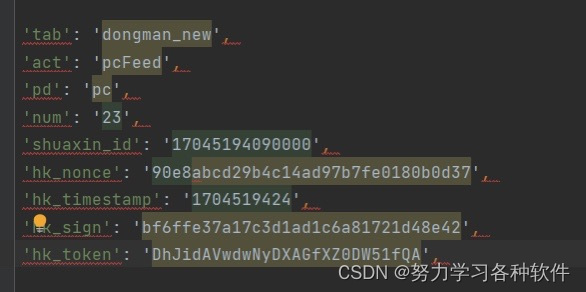
服務器端通常在接收?POST?請求時,根據請求頭中的?Content-Type?字段來判斷請求體的格式。如果?Content-Type?設置為?application/json,則服務器端會期望接收?JSON?格式的請求體數據。這在前后端分離的?Web?應用中比較常見,因為前端通常使用?JavaScript?或其他語言發送?JSON?格式的數據給后端。
以下是一些常見的情況,服務器端可能會要求?JSON?格式的請求體:
RESTful?API:?許多基于?REST?架構的?Web?服務要求客戶端發送?JSON?格式的數據給服務器端,以便執行?CRUD(創建、讀取、更新、刪除)操作。
前后端分離應用:?在前后端分離的應用中,前端通常發送?JSON?格式的數據給后端,后端再根據接收到的?JSON?數據進行處理。
某些框架或庫要求:?某些后端框架或庫可能要求客戶端發送?JSON?格式的數據給服務器端,以便與服務器端進行交互。
Webhooks:?一些?Webhooks?可能要求發送?JSON?格式的數據給指定的?URL,以便觸發某些操作。
在這些情況下,客戶端通常需要將數據序列化為?JSON?格式,并將?Content-Type?設置為?application/json,以便服務器端能夠正確解析請求體中的數據?
服務器端通常在接收?POST?請求時,根據請求頭中的?Content-Type?字段來判斷請求體的格式。如果?Content-Type?設置為?application/x-www-form-urlencoded?或?multipart/form-data,則服務器端會期望接收表單格式的請求體數據。
以下是一些常見的情況,服務器端可能會要求表單格式的請求體:
傳統?Web?表單提交:?在傳統的?Web?應用中,用戶通過?HTML?表單提交數據給服務器端時,通常使用表單格式的請求體數據。
文件上傳:?當表單中包含文件上傳字段時,通常使用?multipart/form-data?格式提交請求體數據。
某些框架或庫要求:?某些后端框架或庫可能要求客戶端以表單格式提交數據給服務器端,以便與服務器端進行交互。
部分?API?接口:?一些?API?接口可能要求客戶端以表單格式提交數據,而不是?JSON?格式,這取決于接口的設計和需求。
在這些情況下,客戶端通常需要將數據編碼為表單格式,并將?Content-Type?設置為?application/x-www-form-urlencoded?或?multipart/form-data,以便服務器端能夠正確解析請求體中的數據。
二、視頻類爬蟲總結
爬取短視頻類型的數據一般步驟:
1.點擊media,刷新,播放一個視頻,會刷新一個包,點擊發現是播放視頻的包,
2.復制這個包url中的關鍵字,在搜索框中進行搜索,看有哪些包有關鍵字。
3.搜索后找到有play_url的包
4.看這個包的url,觀察有什么規律
5.以糖豆視頻為例,發現這個包的url有參數vid
6.查找參數在哪個位置
7.在xhr 動態加載中找到包,發現其中json數據中有vid的數據。
8.訪問xhr 中的包獲取vid數據,利用獲取到的vid數據拼湊含有play_url的包的鏈接,訪問這個鏈接,獲取play_url
9.多頁爬取,觀察xhr 包的鏈接有什么規律,發現參數為頁數,即可多頁爬取
注意:訪問視頻play_url時,爬取短視頻類型,headers中把user-agent,cookie,refer全部加上
爬取長視頻的一般步驟:長視頻通常以m3u8的格式存在,找包的過程與上述一致,找的是ts格式的文件,但一般存在于xhr下面。小技巧,若通過參數找不到就直接搜索m3u8,說不定可以找到終極目標是找到一個包能返回下面的界面
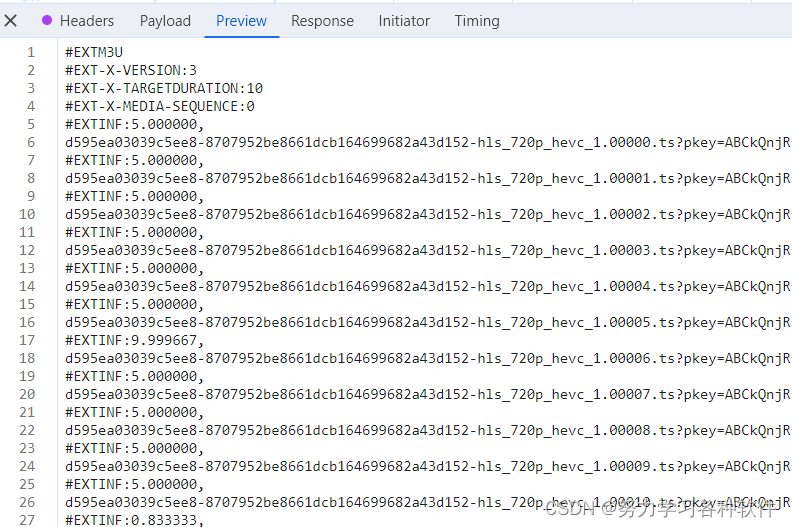
不同的網站,這個包找的地方不同,A站中搜索就可以找到,騰訊視頻則先要找到一個含m3u8的包,從里面提取出一個鏈接,再訪問這個鏈接,得到上面的界面。?
下載時,要下載為ts的視頻格式,多的一步是將文件合成。
可以將多個ts包合成一個下載代碼:
with open('斗羅大陸.mp4',mode='ab') as f:f.write(ts_content)三、打包exe與制表庫的使用
?1.制表模塊使用prettytable
from prettytable import PrettyTable
tb = PrettyTable() # 實例化一個對象
tb.field_names = ['序號','歌手','歌名'] # 設置字段名
tb.add_row([num,singer,song_name]) # 寫入表格行2. 將python文件打包成exe文件
首先,在項目中下載pyinstaller包pip install pyinstaller
然后在需要打包的python文件目錄路徑下輸入cmd

混淆矩陣)



)




)



 方法)





)