目錄
一、實時數倉
二、實時數倉架構介紹
2.1 Lambda架構
2.2 Kappa架構
三、攜程酒店實時數倉架構
3.1?架構選型
3.2 實時計算引擎選型
3.3 OLAP選型
四、攜程酒店實時訂單
4.1?數據源
4.2 ETL數據處理
4.3 應用效果
4.4 總結
? 原文大佬的這篇實時數倉建設案例有借鑒意義,屬于數據治理范疇,這里直接摘抄下來用作學習和知識沉淀。
一、實時數倉
? 當前,企業對于數據實時性的需求越來越迫切,因此需要實時數倉來滿足這些需求。傳統的離線數倉的數據時效性為T+1,并且調度頻率以天為單位,無法支持實時場景的數據需求,即使將調度頻率設置為小時,也僅能解決部分時效性要求低的場景,對于時效性要求較高的場景仍然無法優雅地支撐。因此,實時數據使用的問題必須得到有效解決。實時數倉主要用于解決傳統數倉數據時效性較低的問題,通常會用實時的OLAP分析,實時數據看板、業務指標實時監控等場景。
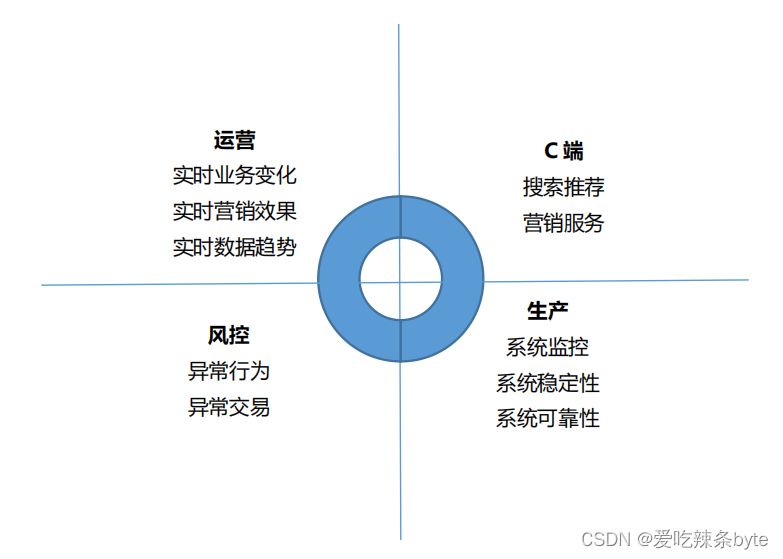
二、實時數倉架構介紹
2.1 Lambda架構
??Lambda架構將數據分為實時數據和離線數據,并分別使用流式計算引擎(例如Flink 或者 SparkStreaming)和批量計算引擎(例如 Hive、Spark)對數據進行計算,然后,將計算結果存儲在不同的存儲引擎上,并對外提供數據服務。
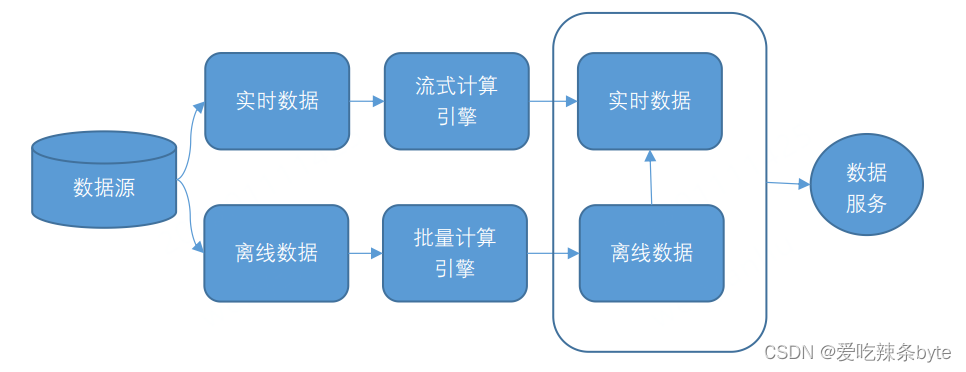
2.2 Kappa架構
? Kappa架構將所有數據源的數據轉換成流式數據,并將計算統一到流式計算引擎上,相比Lambda架構, Kappa 架構省去了離線數據流程,使得流程變得更加簡單。Kappa 架構之所以流行,主要是因為kafka不僅可以作為消息隊列使用,還可以保存更長時間的歷史數據,以替代Lambda架構中的批處理層數據倉庫。流處理引擎以更早的時間作為起點開始消費,起到了批處理的作用。

三、攜程酒店實時數倉架構
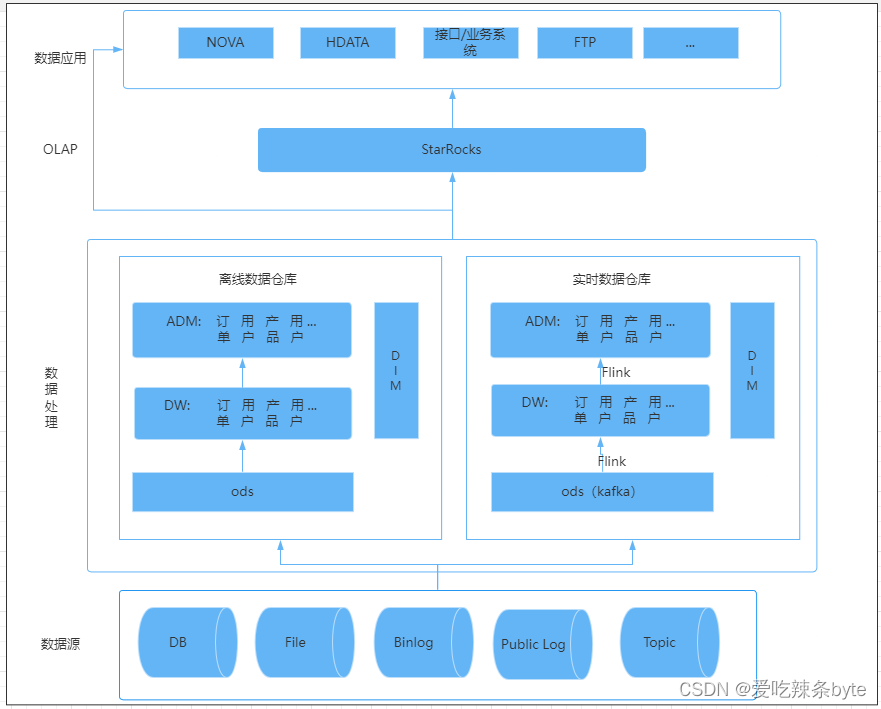
3.1?架構選型
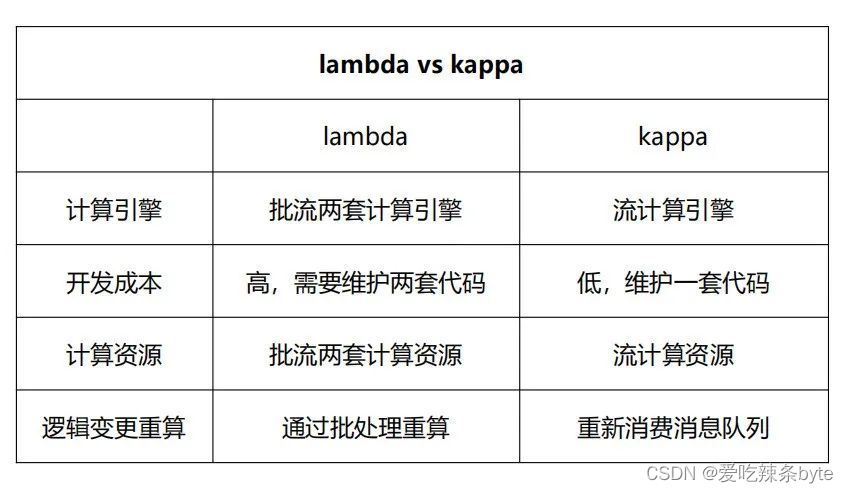
? 采用的是Lambda+OLAP 變體架構。Lambda架構具有靈活性高、容錯性高、成熟度高和遷移成本低的優點,但是實時數據和離線數據需要分別使用兩套代碼。
? ?OLAP變體架構:將實時計算中的聚合計算由OLAP引擎承擔,從而減輕實時計算部分的聚合處理壓力。這樣做的優點是既可以滿足數據分析師的實時自助分析需求,并且可以減輕計算引擎的處理壓力,同時也減少了相應的開發和維護成本。缺點是對OLAP 引擎的數據寫入性能和計算性能有更高的要求。
? 3.2 實時計算引擎選型
? ? ?Flink具備Exactly-once的語義,輕量級checkpoint容錯機制、低延遲、高吞吐和易用性高的特點。SparkStreaming 更適合微批處理。我們選擇了使用 Flink。
3.3 OLAP選型
??我們選擇 StarRocks 作為 OLAP 計算引擎。主要原因有3個:
- StarRocks 是一種使用MPP分布式執行框架的數據庫,集群查詢性能強大;
- StarRocks在高并發查詢和多表關聯等復雜多維分析場景中表現出色,并發能力強于clickhouse,而攜程酒店的業務場景需要OLAP數據庫支持每小時幾萬次的查詢量;
-
StarRocks 提供了4種數據模型,可以更好的應對攜程酒店的各種業務場景
四、攜程酒店實時訂單
4.1?數據源
? ? Mysql Binlog,通過攜程自研平臺 Muise接入生成 Kafka。
4.2 ETL數據處理
?問題一:如何保證消息處理的有序性?
? ? Muisev平臺保證了Binlog消息的有序性,這里需要討論的是ETL過程中如何保證消息的有序性。例如:一個酒店訂單先在同一張表觸發了兩次更新操作,共計有了兩條 Binlog 消息,消息1和消息2會先后進入流處理系統,如果這兩個消息是在不同的Flink Task上進行處理,那么就有可能由于兩個并發處理的速度不一致,先發生的消息后處理,導致最終輸出的結果不對(出現亂序)
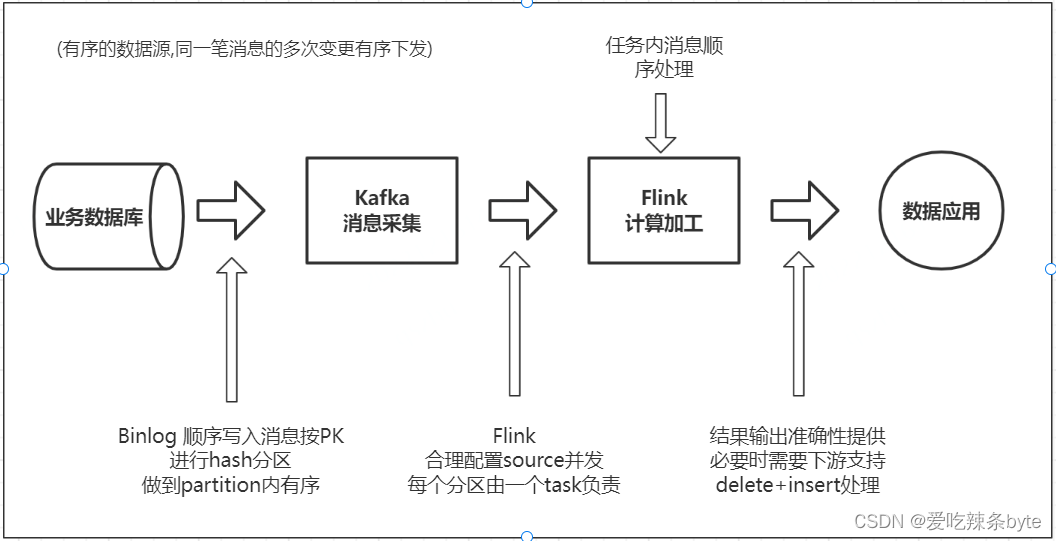
?上圖是一個簡化的過程,業務庫流入到Kafka,Binlog 日志是順序寫入的,根據主鍵進行Hash分區 ,保證同一個主鍵的數據寫入到kafka同一個分區。當Flink消費kafka時,需要設置合理的并發,保證同一個分區的數據由一個Task負責,另外盡量采取邏輯主鍵作為?Shuffle Key,從而保證了Flink內部的有序性。最后在寫入StarRocks時,按照主鍵進行更新或刪除操作,這樣才能保證端到端的一致性。
?問題二:如何生產實時訂單寬表?
? ?為了方便分析師和數據應用使用,我們需要生成明細訂單寬表并存儲在 StarRocks 上。酒店訂單涉及的業務過程相對復雜,數據源來自多個數據流中,且由于酒店訂單變化生命周期較長,客人可能會提前幾個月甚至更久預訂下單。這些都給生產實時訂單寬表帶來一定的困難。
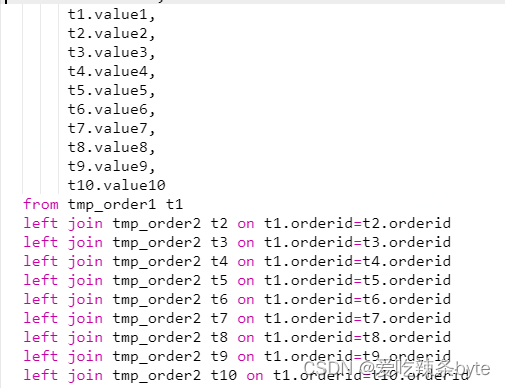
? ?上圖中生成訂單寬表的sql邏輯在離線批處理場景下沒有問題,但是實時場景下,這個sql會按照雙流join的方式依次處理,每次只能處理一個join,所以上面代碼有9個 Join 節點,Join節點會將左流的數據和右流的數據全部保存下來,最終會導致join過程中state狀態存儲膨脹了9倍。
? ?因此,我們采用了union all + group by的方式替代join;先用union all把數據錯位拼接到一起,然后再最外層進行group by。這種方式相當于將 Join 關聯轉換成group by,不會放大 Flink的狀態存儲。

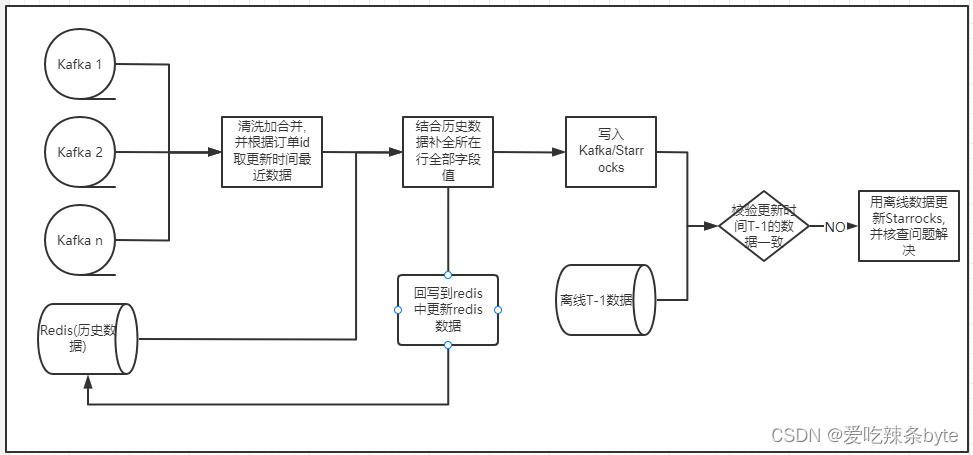
? 還有一個問題,上面說過酒店訂單的生命周期很長,用 union all 的方式,狀態周期只保存了30分鐘,一些訂單的狀態可能已經過期,當出現訂單狀態時,我們需要獲取訂單的歷史狀態,這樣就需要一個中間層保存歷史狀態數據來做補充。歷史數據我們選擇存放在 Redis 中,第一次選擇從離線數據導入,實時更新數據的同時,還更新 Redis和StarRocks。
?問題三:如何做數據校驗?
? ?實時數據存在數據丟失或邏輯變更不及時的風險,為了保證數據的準確性,每日凌晨將實時數據和離線T-1數據做比對,如果數據校驗不一致,會用離線數據更新StarRocks中對應的數據,并排查原因。
? 整體流程見下圖:
4.3 應用效果
? 酒店實時訂單表的數據量為十億級,維表數據量有幾百萬,現已經在幾十個數據看板和監控報表中使用,數據報表通常有二三十個維度和十幾個數據指標,查詢耗時99%約為3秒。
4.4 總結
? ?酒店實時數據具有量級大,生命周期長,業務流程多等復雜數據特征,攜程酒店實時數倉選用 Lambda+OLAP 變體架構,借助 Starrocks 強大的計算性能,不僅降低了實時數倉開發成本,同時達到了支持實時的多維度數據統計、數據監控的效果,在實時庫存監控以及應對緊急突發事件等項目獲得了良好效果。
參考文章:
干貨 | 攜程酒店實時數倉架構和案例

?它在 C++ 中是如何實現的?)

)




:對象與數據結構)


)



)



