引言
Redis是一款基于鍵值對的數據結構存儲系統,它的特點是基于內存操作、單線程處理命令、IO多路復用模型處理網絡請求、鍵值對存儲與簡單豐富的數據結構等等
這篇文章主要圍繞Redis中的對象與數據結構來詳細說明鍵值對存儲與簡單豐富的數據結構這兩大特點
Redis中的數據以Key,Value鍵值對的形式存儲在字典中,字典的實現是哈希表
鍵Key只能使用字符串對象來表示,值Value能夠使用其他所有對象
對象與數據結構
Redis中存在豐富的對象,常用的對象(數據類型)有字符串對象string、列表對象list、散列對象hash、集合對象set、有序集合對象zset等
還有其他的數據類型如Bitmap、Hyperloglog、Geospatial、布隆過濾器等,但這篇文章只涉及常用的對象,其他數據類型再以后的文章中再展開說明
redis中的對象RedisObject由類型、編碼、引用次數、lru、指向編碼使用的數據結構對象構成
類型標識這個對象是什么類型對象
- 比如字符串、列表、哈希、集合、有序集合等
編碼表示構成對應類型對象時使用哪種數據結構
引用次數表示這個對象被引用了多少次
- redis內存回收使用引用計數法,回收引用次數為0的對象 redis只依賴字符串對象,而不存在循環依賴所以不存在循環引用,因此可以使用引用計數法
lru記錄這個對象最近被調用的時間,當空間回收算法使用lru時會優先回收很久未用的對象(后續刪除回收的文章會介紹)
數據結構
sds簡單動態字符串
sds使用字節數組維護,len記錄字符串長度(表示結尾的'\0'不算),free表示字節數組中空閑的長度
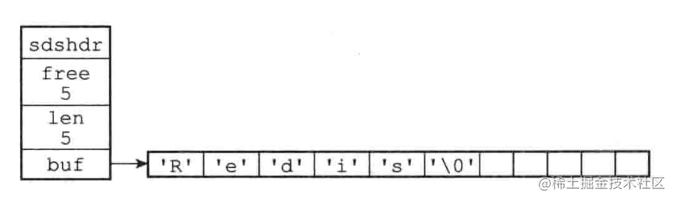
在添加元素前會判斷數組長度是否足夠,不夠則會進行擴容;擴容有空間預分配策略,會留有一部分空閑空間
如果下次修改字符串未超出數組長度就能夠直接修改,節省了擴容的開銷
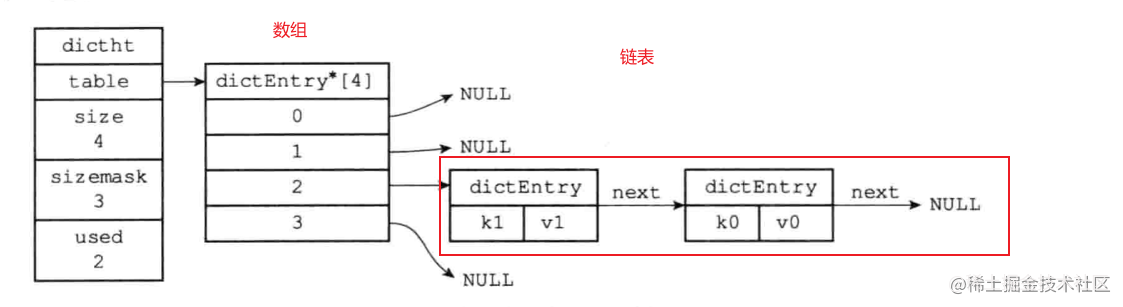
hashtable字典
字典使用哈希表實現,哈希表的原理本篇文章不會詳細概述
哈希沖突使用鏈地址法解決,查找時先通過 hash%數組長度-1 來獲取索引,得到索引后再遍歷鏈表節點,如果是新增則直接使用頭插法,插入鏈表頭部
為了防止大字典擴容時發生阻塞,字典中哈希表的擴容是循序漸進的,在發生擴容時會有倆個哈希表
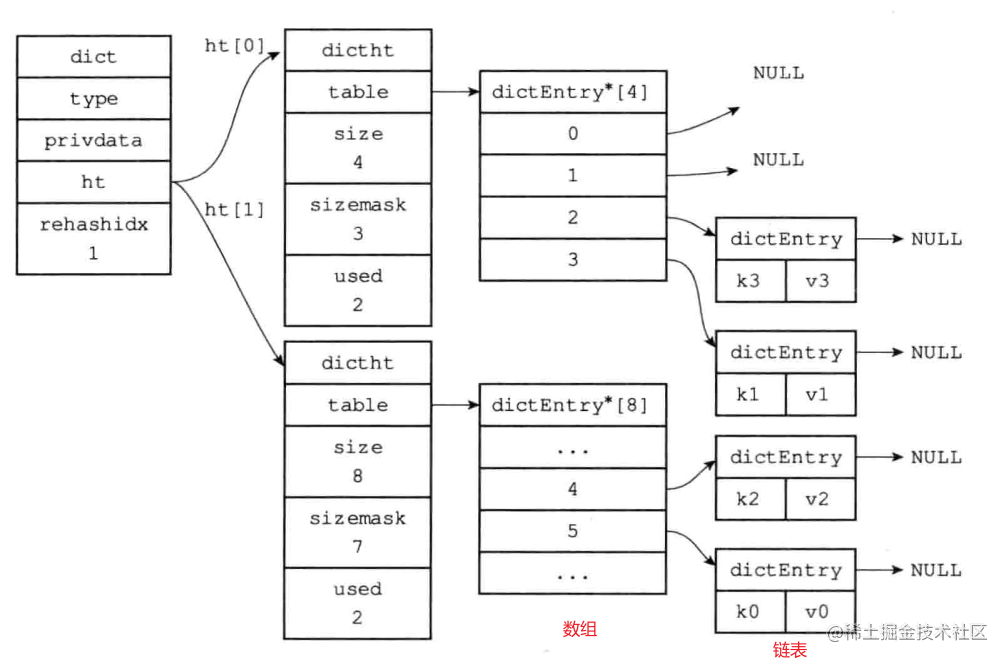
舊哈希表和新哈希表中都可能存儲數據,再收到hget等請求時先在舊哈希表中查找,找到了就順便把它遷移到新哈希表中;在舊哈希表中沒找到就去新哈希表中找
在完成遷移時,新哈希表將舊哈希表替換
skiplist跳表
跳表維護多層級的有序鏈表,利用高層能夠快速達到后續節點,實現簡單,維護方便,增刪改查時間復雜度平均log n
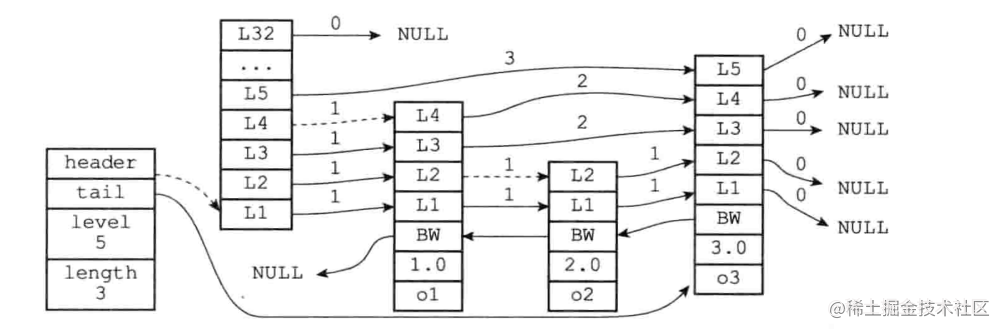
比如查找值為2.0的節點,查找順序為圖中虛線
先找到虛擬頭節點,從當前維護的最高層(L5)開始尋找,往后找到o3對象值為3.0,說明已經找過頭了,于是要去下一層進行尋找;來到L4先后遍歷,o1對象值為1.0,比目標值2.0小,說明沒有目標值在o1對象后面,于是來到o1對象L4層;繼續在o1對象L4向后遍歷,發現o3值為3.0大于目標值,于是降層來到o1對象L3層;L3層后面也是o3于是繼續降層,來到L2層,L2層向后遍歷為o2對象,值為2.0并比較o2對象相同說明找到了
從維護的最高層開始查詢,查詢為空或者查詢值大于目標值則降層,當前在最后一層還需要降層說明找不到
當排序值相同時,按照對象大小排序,這里的對象都是字符串對象
增加節點時的層數是隨機生成的,越高層幾率越小;其他修改操作,也是通過查詢再進行,同時還要維護一些如最高層級等其他屬性
intset整數集合
intset 維護了一個有序,無重復的數組
在實現上使用數組、長度(記錄元素數量)和編碼(編碼能夠標識元素類型,如16、32、64位的整型)
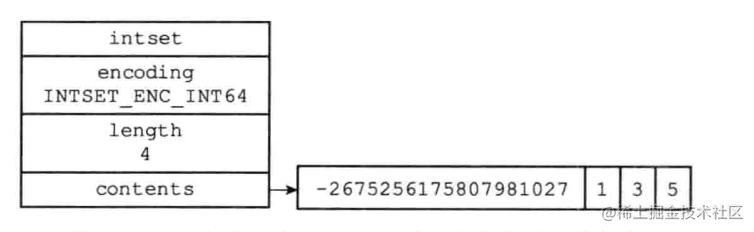
當加入的元素為當前數組內不存在的高位整型時(比如數組中都是32位整型,此時加入一個64位整型)發生升級:先申請內存重分配,再將舊元素移動到對應位置上,然后加入新元素同時修改編碼,當刪除高位整型時不會發生降級
intset的升級有效的節約內存,當set對象都為整型且數據量較小時使用intset實現以此來節約內存
ziplist壓縮列表
ziplist用連續空間的節點構成,節點由記錄前驅節點偏移量(逆序遍歷)、編碼(字節數組或整型的編碼)、內容(內容可以是字節數組或整型)組成

因為ziplist的內容不是固定的,比如記錄前驅節點偏移量是可變長的,這會影響節點的長度,又因為ziplist是空間連續的,這會導致后續的節點空間都要變動,被稱為連鎖更新(發生的概率小)
為了節省空間,用于數量量小場景下列表、哈希、有序集合的實現
quicklist快速列表
快速列表可以當作雙向鏈表,只不過節點使用ziplist,常用來實現數據量大場景下的列表對象
對象
說明:
下文中數據量代表著占用字節情況和數據元素數量
本篇文章不介紹各個對象的命令使用規則,需要學習命令的同學可以去官網查看
字符串對象
字符串對象string由sds簡單動態字符串來實現
sds有不同的編碼:int、embstr、row
- int 用來存儲整型字符串,計算時可能發生整型與字符串的轉換
- embstr 用來存儲短的字符串,只分配一次內存,分配內存時同時分配redisobject和sds
- row 用來存儲長字符串,分配內存時需要分配兩次:redisobject、sds
字符串對象是Redis中最常用的對象,也是唯一會被其他對象依賴使用的對象
字符串對象常見的使用場景:整存整取的緩存、計數器、分布式鎖
列表對象
列表對象list是一個隊列,可以操作隊頭隊尾,由ziplist或quicklist來實現
數據量小時使用ziplist,數據量大時使用quicklist( linkedlist+ziplist )
列表的使用場景是FIFO隊列保證元素訪問順序
哈希對象
哈希對象hash是維護KV鍵值對的無序數據結構,由ziplist或hashtable來實現
數據量少使用ziplist、數據量大使用hashtable
哈希的使用場景是緩存的部分存取(比如一個大禮包下有A商品B商品等)
集合對象
集合對象set的特點是無序、無重,由intset或hashtable來實現
數據量少且數據為整型使用intset、數據量大或數據不為整型使用hashtable且值永遠為null
集合的使用場景是唯一性元素或交集并集(共同關注、可能認識)等(無序、無重復)
有序集合對象
有序集合對象zset是有序、無重的數據結構,由ziplist或skiplist + hashtable實現
數據量少時使用ziplist、數據量大時使用skiplist + hashtable(為了滿足根據對象查詢分指常量級功能,共享對象,不造成內存開銷)
有序集合的使用場景是排行榜、關注程度榜單等(有序、無重復)
總結
本篇文章圍繞Redis以鍵值對存儲、豐富多元的數據結構為特點詳細介紹了Redis中的對象與數據結構
對象由類型、編碼、數據結構指針等構成
為了節省空間,每種類型的對象都有多種編碼類型的數據結構能夠實現
字符串對象常用來做緩存、分布式鎖、計數器等,被其他對象依賴使用
- 由sds實現主要有int、embstr、row三種編碼來處理不同類型的字符串,embstr處理短字符串優化內存分配
- sds是動態字符串,利用空間預分配策略在修改不超過數組長度情況下可以不需要進行擴容,節省開銷
列表對象常用來維護隊列元素有序性
- 當數據量小時使用壓縮列表ziplist實現,數據量大時使用快速列表quicklist實現
- 壓縮列表使用連續空間,節點中存儲可以時字符串也可以是整型
- 快速列表則可以當作鏈表,節點為壓縮列表
哈希對象常用來維護部分存取的緩存
- 當數據量小時使用壓縮列表zpilist實現,數據量大時使用哈希表hashtable實現
- 哈希表為了防止阻塞,在擴容時使用新舊兩個哈希表存儲元素,在處理命令的同時完成遷移
集合對象有無序、無重的特點,常用來做唯一、交集(共同好友)、并集(可能認識)
- 當數據量小且元素都為整型時使用整型集合intset實現,當數據量大使用哈希表實現
- 整型集合有不同的編碼形式,充分節省了空間;使用哈希表時Value為空
有序集合對象有有序、無重的特點,常用來做排行榜
- 當數據量小時使用壓縮列表實現;當數據量大時使用跳表skiplist+哈希表實現,哈希表保存K對象V比較值
- 跳表是多層級有序的鏈表,平均時間復雜度在log n,簡單易維護
最后(一鍵三連求求拉~)
本篇文章筆記以及案例被收入 gitee-StudyJava、 github-StudyJava 感興趣的同學可以stat下持續關注喔~
有什么問題可以在評論區交流,如果覺得菜菜寫的不錯,可以點贊、關注、收藏支持一下~
關注菜菜,分享更多干貨,公眾號:菜菜的后端私房菜
本文由博客一文多發平臺 OpenWrite 發布!


)



)









——在Stateflow編輯窗口Debug)
)

