文章目錄
- 前言
- 一、MemoryStateBackend
- 二、FSStateBackend
- 三、RocksDBStateBackend
- 四、StateBackend配置方式
- 五、狀態持久化
- 六、狀態重分布
- OperatorState 重分布
- KeyedState 重分布
- 七、狀態過期
前言
Flink是一個流處理框架,它需要對數據流進行狀態管理以支持復雜的計算邏輯。在Flink中,狀態存儲是指如何和在哪里存儲這些狀態數據。Flink提供了多種狀態后端(State Backend)來實現這種存儲,以滿足不同的應用場景和性能需求。 StateBackend需要具備如下兩種能力:
1、在計算過程中提供訪問 State 的能力,開發者在編寫業務邏輯中能夠使用 StateBackend 的接口讀寫數據。
2、能夠將 State 持久化到外部存儲,提供容錯能力。
根據使用場景的不同, Flink 內置了 3 種 StateBackend 。其體系結構如下圖所示。
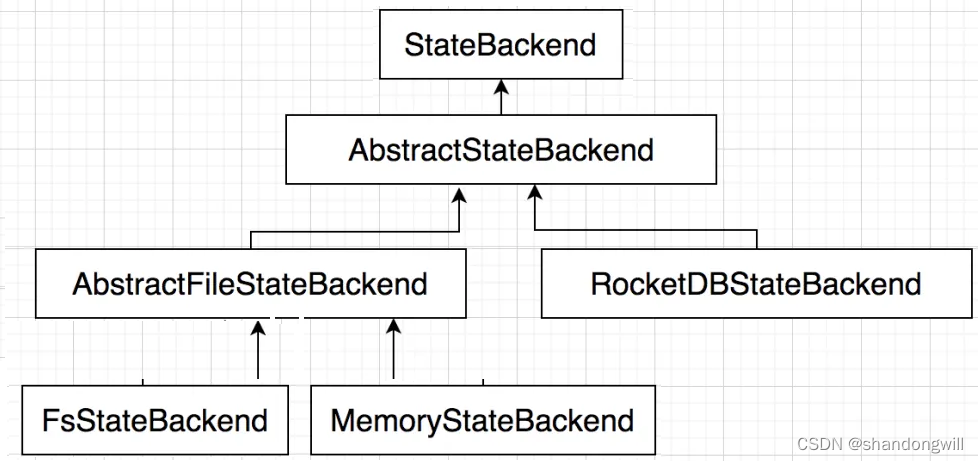
純內存:MemoryStateBackend,適用于驗證、測試,不推薦生產環境。
內存+文件:FsStateBackend,適用于長周期大規模的數據。
RocksDB:RocksDBStateBackend,適用于長周期大規模的數據。
在運行時,MemoryStateBackend 和 FsStateBackend 本地的 State 都保存在 TaskManager 的內存中,所以其底層依賴于 HeapKeyedStateBackend。HeapKeyedStateBackend 面向 Flink 引擎內部,使用者無須感知。
一、MemoryStateBackend
默認情況下,狀態信息是通過MemoryStateBackend 存儲在 TaskManager 的堆內存中的, KV 類型的State,窗口算子的 State 使用 HashTable 來保存數據、觸發器等。執行檢查點的時候,會把 State 的快照數據保存到 JobManager 進程的內存中。 MemoryStateBackend 可以使用異步的方式進行快照,(也可以同步),推薦異步,避免阻塞算子處理數據。
基于內存的 StateBackend 在生產環境下不建議使用,可以在本地開發調試測試 。
注意點如下 :
- State 存儲在 JobManager 的內存中,受限于 JobManager 的內存大小。
- 每個 State 默認 5MB,可通過 MemoryStateBackend 構造函數調整。
- 每個 State 不能超過 Akka Frame 大小。
二、FSStateBackend
文件型狀態存儲 FSStateBackend,運行時所需的 State 數據全部保存在 TaskManager 的內存中, 執行檢查點的時候,會把 State 的快照數據保存到配置的文件系統中,如使用 HDFS 的路徑為 “hdfs://namenode:40010/flink/checkpoints”,使用本地文件系統的路徑為:“file:///data/flink/checkpoints”。
FSStateBackend 適用于處理大狀態、長窗口,或大鍵值狀態的有狀態處理任務。
缺點:
狀態大小受TaskManager內存限制(默認支持5M)
優點:
狀態訪問速度很快
狀態信息不會丟失
用于: 生產,也可存儲狀態數據量大的情況
三、RocksDBStateBackend
RocksDBStateBackend 跟內存型和文件型 StateBackend 不同,其使用嵌入式的本地數據庫 RocksDB 將流計算數據狀態存儲在本地磁盤中,不會受限于 TaskManager 的內存大小,在執行檢查點的時候,再將整個 RocksDB 中保存的 State 數據全量或者增量持久化到配置的文件系統中,在 JobManager 內存中會存儲少量的檢查點元數據。RocksDB 克服了 State 受內存限制的問題,同時又能夠持久化到遠端文件系統中,比較適合在生產中使用。 但是 RocksDBStateBackend 相比基于內存的 StateBackcnd ,訪問 State 的成本高很多,可能導致數據流的吞吐量劇烈下降,甚至可能降低為原來的 1/10。
適用場景:
最適合用于處理大狀態、長窗口,或大鍵值狀態的有狀態處理任務。
RocksDBStateBackend 非常適合用于高可用方案。
RocksDBStateBackend 是目前唯一支持增量檢查點的后端,增量檢查點非常適用于超大狀態的場景。
注意點
- 總 State 大小僅限于磁盤大小,不受內存限制。
- RocksDBStateBackend 也需要配置外部文件系統,集中保存 State。
- RocksDB的 JNI API 基于byte數組,單 key 和單 Value 的大小不能超過 231 字節。
- 對于使用具有合并操作狀態的應用程序,如 ListState ,隨著時間可能會累積到超過 231 字節大小,這將會導致在接下來的查詢中失敗。
四、StateBackend配置方式
- 單任務調整
修改當前任務代碼
public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setStateBackend(newFsStateBackend("hdfs://namenode:9000/flink/checkpoints"));或者new MemoryStateBackend()或者new RocksDBStateBackend(filebackend, true);【需要添加第三方依賴】
}
- 全局調整(不建議)
修改flink-conf.yaml
state.backend: filesystem
state.checkpoints.dir: hdfs://namenode:9000/flink/checkpoints
注意:state.backend的值可以是下面幾種:jobmanager(MemoryStateBackend),
filesystem(FsStateBackend), rocksdb(RocksDBStateBackend)
五、狀態持久化
StateBackend 中的數據最終需要持久化到第三方存儲中,確保集群故障或者作業故障能夠恢復。 HeapSnapshotStrategy 策略對應于 HeapKeyedStateBackend,RocksDBStateBackend 的持久化策略有兩種:全量持久化策略(RocksFullSnapshotStrategy)和 增量持久化策略 (RocksIncementalSnapshotStrategy)。
1、全量持久化策略
全盤持久化,也就是說每次把全量的 Slate 寫人到狀態存儲中 (如 HDFS)。內存型、文件型、 RocksDB 類型的 StatcBackend 支持全量持久化策略。 在執行持久化策略的時候,使用異步機制,每個算子啟動 1 個獨立的線程,將自身的狀態寫入分布式存儲中。在做持久化的過程中,狀態可能會被持續修改,基于內存的狀態后端使用 CopyOnWriteStateTable 來保證線程安全,RocksDBStateBackend 則使用 RocksDB 的快照機制,使用快照來保證線程安全。
2、增量持久化策略
增量持久化就是每次持久化增量的 State,只有 RocksDBStateBackend 支持增量持久化。Flink 增量式的檢查點以 RocksDB 為基礎, RocksDB 是一個基于 LSM-Tree 的 KV 存儲。新的數據保存在內存中, 稱為 memtable。如果 Key 相同,后到的數據將覆蓋之前的數據,一旦 memtable 寫滿了,RocksDB 就會將數據壓縮并寫入磁盤。memtable 的數據持久化到磁盤后,就變成了不可變的 sstable。
因為 sstable 是不可變的,Flink 對比前一個檢查點創建和刪除的 RocksDB sstable 文件就可以計算出狀態有哪些發生改變。
為了確保 sstable 是不可變的,Flink 會在 RocksDB 觸發刷新操作,強制將 memtable 刷新到磁盤上 。在 Flink 執行檢查點時,會將新的 sstable 持久化到 HDFS 中,同時保留引用。這個過程中 Flink 并不會持久化本地所有的 sstable,因為本地的一部分歷史 sstable 在之前的檢查點中已經持久化到存儲中了,只需增加對 sstable 文件的引用次數就可以。 RocksDB 會在后臺合并 sstable 并刪除其中重復的數據。然后在 RocksDB 刪除原來的 sstable,替換成新合成的 sstable.。新的 sstable 包含了被刪除的 sstable中的信息,通過合并歷史的 sstable 會合并成一個新的 sstable,并刪除這些歷史sstable。可以減少檢查點的歷史文件,避免大量小文件的產生。
六、狀態重分布
在實際的生產環繞中,作業預先設置的并行度很多時候并不合理,太多則浪費資源,太少則資源不足,可能導致數據積壓延遲變大或者處理時間太長,所以在運維過程中,需要根據作業的運行監控數據調整其并行度。調整并行度的關鍵是處理 State。回想一下前文中的內容,State 位于算子內,改變了并行度,則意味著算子個數改變了,需要將 State 重新分配給算子。下面從 OperatorState 和 KeyedState 兩種 State 角度,介紹如何將 State 重新分配給算子。
OperatorState 重分布
1、ListState
并行度在改變的時候,會將并發上的每個 List 都取出,然后把這些 List 合并到一個新的 List,根據元素的個數均勻分配給新的 Task。
2、UnionListState
比 ListState 更加靈活, 把劃分的方式交給用戶去做,當改變并發的時候,會將原來的 List 拼接起來,然后不做劃分,直接交給用戶。
3、BroadcastState
操作 BroadcastState 的 UDF 需要保證不可變性,所以各個算子的同一個 BroadcastState 完全一樣。在改變并發的時候,把這些數據分發到新的 Task 即可。
KeyedState 重分布
基于 Key-Group ,每個 Key 隸屬于唯一的 Key-Group。Key Group 分配給 Task 實例,每個 Task 至少有 一個 Key-Group 。 Key-Group 數量取決于最大并行度 (MaxParallism) 。 KeyedStream 并發的上限是 Key-Group 的數量,等于最大并行度。
七、狀態過期
1、DataStream 中狀態過期
可以對 每一個 State 設置 清理策略 StateTtlConfig,可以設置的內容如下:
過期時間:超過多長時間未訪問,視為 State 過期,類似于緩存。
過期時間更新策略:創建和寫時更新、讀取和寫時更新。
State 可見性:未清理可用,超時則不可用。
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.seconds(1)).setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite).setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired).build();ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("text state", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);
2、Flink SQL 中狀態過期
Flink SQL 在流 Join、聚合類的場景中,使用了 State,如果 State 不定時清理。 則可能會導致 State 過多,內存溢出。 為了穩妥起見,最好為每個 FLink SQL 作業提供 State 清理的策略。如果定時清理 State,則存在可能因為 State 被清理而導致計算結果不完全準確的風險。FLink 的 Table API 和 SQL 接口中提供了參數設置選項,能夠讓使用者在精確和資源消耗做折中。
StreamQueryConfig qConfig = ...
//設置過期時間為 min = 12 小時 ,max = 24 小時
qConfig.withIdleStateRetentionTime(Time.hours(12),Time.hours(24));



)







![[物聯網] OneNet 多協議TCP透傳](http://pic.xiahunao.cn/[物聯網] OneNet 多協議TCP透傳)







