Redis 的數據類型(數據結構)
- string (二進制安全,可以存儲任意類型的數據)
- list(鏈表)
- 字典(就是hashmap)
- set(不重復無序的hashmap)
- zset(按照給定的 score 排序的 set)
- HyperLogLog(來做基數統計的算法,簡介)
- Geo(支持地理位置的操作,使用簡介)
- Pub/Sub
- BloomFilter
- RedisSearch
- Redis-ML
緩存雪崩(緩存擊穿)
他們出現的原理都是訪問緩存的時候,key 剛好失效,導致直接訪問 DB,壓垮后臺。
解決辦法就是讓 key 的過期時間分散開,不要集中失效
分布式鎖
使用 setnx 命令后為了防止死鎖,需要對 key 施加 expire 命令,防止死鎖,但是存在執行 expire 命令前宕機,造成死鎖的發生。
解決辦法就是使用復雜的 setnx 命令,他可以把 setnx 和 expire 一起原子執行
如何尋找有固定前綴的 key
使用 KEYS pattern 命令,如:KEYS alib*
但是因為 Redis 是單線程的,執行該命令后會導致 Redis 阻塞住。
解決辦法就是使用 scan 命令,scan 命令可以無阻塞的提取出指定模式的 key 列表,但是會有一定的重復概率,在客戶端做一次去重就可以了,但是整體所花費的時間會比直接用 keys指令長
scan 命令的特點:
Redis中的Scan命令的使用 - MSSQL123 - 博客園?www.cnblogs.com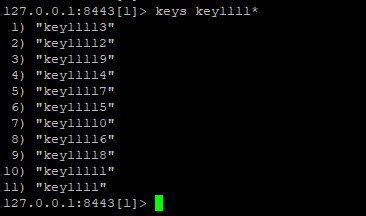
如何用 Redis 做異步隊列
使用 list 數據結構,在一遍加入,另一邊取出,若取出來的是 null,則消費線程應該 sleep,或者消費線程不使用 lpop 或 rpop 命令,改為 blpop 或者 brpop 命令,若沒有元素可取,它會阻塞列表直到等待超時或發現可彈出元素為止。
如何生產一次,消費多次
使用發布訂閱模式
但是在消費者下線的情況下,生產的消息會丟失,得使用專業的消息隊列如 rabbitmq
Redis 如何實現延時隊列
使用 zset ,用時間戳作為 score,消息會按照時間順序排序
然后使用 zrangebyscore key min max [WITHSCORES] [LIMIT offset count] 來取出比當前時間小的 key 的 value
持久化
Redis 4.0 時代以 RDB 為主,AOF 只記錄上一次 RDB 到現在的更改記錄
開啟混合持久化:aof-use-rdb-preamble yes
工作原理:其實還是一種 AOF 機制,但是新增了 RDB 的特性,先看此模式下的 AOF 的數據結構圖
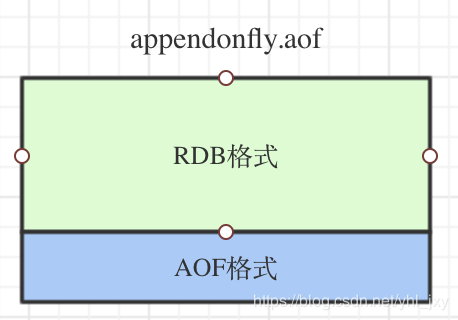
- 看圖就知道混合模式指的就是重寫 AOF 的時候,將此刻內存里面的數據做成 RDB,在此過程中增量的數據寫入到緩沖區,最終形成新的 aof 文件。接著刪除舊的 AOF。
- 重啟恢復時先恢復 RDB,再重放新增的 AOF 指令
持久化的意義在于故障恢復
- AOF:記錄每一次的寫操作到日志上,重啟時重放日志以重建數據
- 每隔一段時間調用系統的 fsync 函數強制將 os cache 里面的數據刷新到磁盤上
- RDB:每隔一段時間保存一次當前時間點上的數據快照
- 快照就是一次又一次地從頭開始創造一切,全量的
持久化如何工作的
關鍵詞:寫時復制和 fork 子進程
- 每當 Redis 需要轉儲數據集到磁盤時,會發生:
- Redis 調用 fork()。于是我們有了父子兩個進程。
- 子進程開始將數據集寫入一個臨時 RDB / AOF 文件。
- 當子進程完成了新 RDB 文件,替換掉舊文件。
- AOF 的 fork(),與 RDB 不同的是父進程會在一個內存緩沖區中積累新的變更,同時將新的變更寫入新的 AOF 文件,所以即使重寫失敗我們也安全。當子進程完成重寫文件,父進程收到一個信號,追加內存緩沖區到子進程創建的文件末尾,接著自動重命名文件為新的,然后開始追加新數據到新文件
- 這個方法可以讓 Redis 獲益于寫時復制(copy-on-write)機制。
AOF 為什么要重寫
AOF 記錄的是 Redis 的每一次變更,這個變更包含了大量的冗余操作,導致 AOF 體積變大,恢復緩慢。
通過重寫這個體積大的 AOF 文件,可以實現新的 AOF 文件不會包含任何浪費空間的冗余命令,通常體積會較舊 AOF 文件小很多。
Pipeline
將多個指令一起發送,減少 IO,提高吞吐量
Redis 的同步機制
Redis 可以使用主從同步,從從同步。
第一次同步時,主節點做一次 bgsave,并同時將后續修改操作記錄到內存 buffer,待完成后將 RDB 文件全量同步到復制節點,復制節點接受完成后將 RDB 鏡像加載到內存。
加載完成后,再通知主節點將期間修改的操作記錄同步到復制節點進行重放就完成了同步過程。后續的增量數據通過 AOF 日志同步即可,有點類似數據庫的 binlog
Redis 集群
Redis Sentinal 著眼于高可用,在 master 宕機時會自動將 slave 提升為 master,繼續提供服務。
Redis Cluster 著眼于擴展性,在單個 redis 內存不足時,使用 Cluster 進行分片存儲。
Redis 的通訊協議是什么
答案是文本協議
雖然文本協議耗費流量,但是解析性能很好
Redis 的事務
首先 Redis 支持事務,但是它的事務與MySQL這類傳統的數據庫的事務不同,不同點為:
- 通過 MULTI 開啟事務(類似于MySQL的 STARTtransaction; 命令)
- 通過 EXEC 命令觸發事務(類似于MySQL的 COMMIT; 命令)
- 執行事務的時候放入事務隊列里面的命令都會被執行,不管是否有命令執行時出錯
- Redis 的事務可以理解為打包的批量執行腳本,所以不支持原子性,失敗了可以繼續執行完,也不會回滾
- 但是單個的Redis命令是原子的
具備隔離性:Redis 因為是單線程操作,所以在隔離性上有天生的隔離機制,當 Redis 執行事務時,Redis 的服務端保證在執行事務期間不會對事務進行中斷,所以,Redis 事務總是以串行的方式運行,事務也具備隔離性。
不具備一致性:雖然開啟持久化之后可以在數據出現問題是恢復到之前的狀態,但是因為Redis的事務不是原子性的,不會回滾數據,Redis設計時也沒有考慮ACID特性,所以認為Redis不具備一致性
持久性:開啟持久化就支持,不開啟就不支持
Redis 的樂觀鎖 Watch 是怎么實現的
Watch 會在事務開始之前盯住 1 個或多個關鍵變量,如下圖:
當事務執行時,也就是服務器收到了 exec 指令要順序執行緩存的事務隊列時, Redis 會檢查關鍵變量自 Watch 之后,是否被修改了。
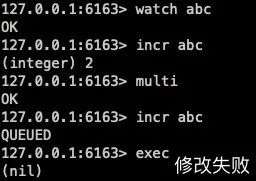
上圖顯示,watch abc 之后執行事務之前,執行了一次 incr 操作,所以在 exec 的時候失敗,watch 的實現原理不是 CAS 中的 Cmpxchg 指令,而是借助 Redis 的單線程執行機制,采用了 watched_keys 的數據結構和串行流程實現了樂觀鎖,具體解釋就是:
每一個被 watch 的 key 都會被構造成一個 watched_keys 數據類型,多個被 watch 的 key 構造成鏈表存儲著假設客戶端 A 和 B 都 watch abc
但是并發時 Redis Server 中只會有一個線程在執行,
當 A 修改了 watch 命令監視的 key 后,會改變 abc 的 watched_keys 的狀態為 dirty,
客戶端 B 會檢查這個被 watch 的 abc,發現他的狀態是 dirty 的時候就會終止事務Redis 如何節省內存
關鍵詞:ziplist、quicklist、對象共享
Ziplist 是一個緊湊的數據結構,每一個元素之間都是連續的內存,如果在 Redis 中,Redis 啟用的數據結構數據量很小時,Redis 就會切換到使用緊湊存儲的形式來進行壓縮存儲。
Quicklist 是 ziplist 的雙向鏈表版本,可以在兩端執行 push 和 pop 操作
對象共享:指的就是多個key的value是一樣的話,就把多個key指向同一個value即可,如下圖:
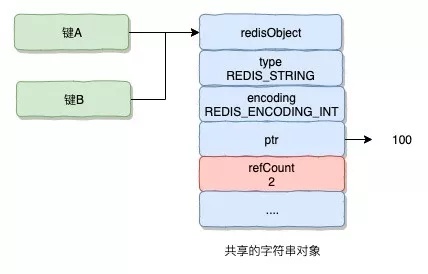
A和B都指向值100,則A、B 共用同一個100對象
Redis 的過期策略
- 定時刪除:創建一個定時器,讓定時器在鍵過期時來執行刪除
- 對CPU不友好
- 影響性能
- 定期刪除:每隔一段時間,程序都要對數據庫進行一次檢查,刪除里面的過期鍵,至于要刪除多少過期鍵,由算法而定。
- 要么對 CPU 不友好
- 要么對內存不友好
- 惰性刪除:get Key 的時候才檢查是否過期,過期了就刪除返回 null
- 對內存不友好
- 可能導致內存溢出
Redis 同步策略
最簡單的架構模式就是:一臺 master 和多個 slave
僅 master 開啟持久化策略,負責寫入操作,slave 只負責讀取操作
同步的目的就是為了【讀寫分離】和【容災備份】
同步的過程:
- slave 發送 SYNC 給 master
- master 接收到命令后一邊緩存繼續寫入的命令,一邊 fork 子進程生成 RDB 文件
- 子進程寫完 RDB 之后,父進程把 RDB 發送給 slave,slave 接收 RDB 并重現數據
- 父進程增量地將緩存的寫命令發送給 slave
Redis 為什么是單進程單線程的
注意:這里的單線程指的是處理 I/O 事件是單線程的,并發的請求進入 Redis 后會排隊,只有上一個處理完了,才會繼續處理下一個。
注意:Redis 可不完全是單進程的,開啟持久化的時候,會 fork 子進程完成 RDB/AOF 的創建
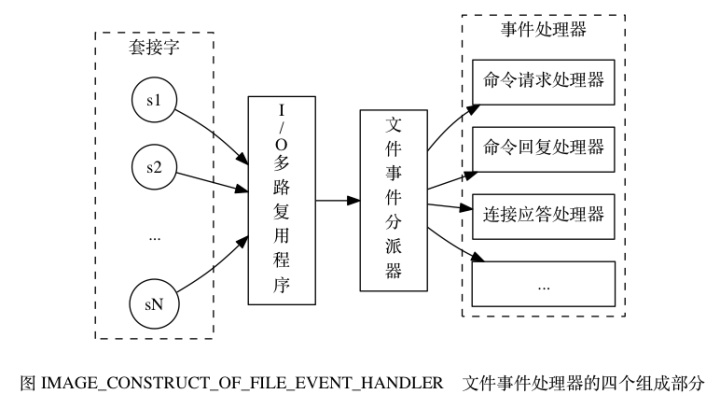
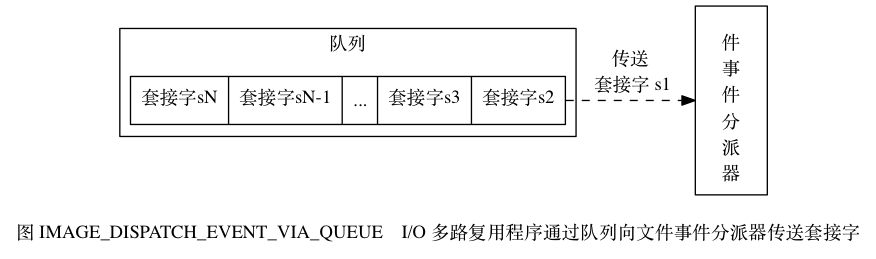
我們所謂的多線程操作是為了加快計算,所以開啟多個線程同步操作,而這會耗費大量的 CPU 資源。
Redis 設計之初就是純內存運行,計算速度夠快了,若再使用多線程操作的話會因為線程管理問題以及上下文切換耗時,反而會降低性能。Redis 官方測試中一臺普通的筆記本電腦沒鳥的QPS可達十幾萬,所以目前來看沒有必要使用多線程。
客戶端獲取 value 阻塞時,卻不會影響后面的命令的執行
Redis 為什么這么快
- 純內存運行
- 單線程(這個單線程指的是處理命令的時候只有一個線程執行,其他的命令加入隊列阻塞)
- 數據結構簡單,使用專門的數據結構存儲數據
- 例如:ZSet 使用跳表存儲
- 字符串使用 SDS(Simple Dynamic String)的結構體保存(該結構體可以存儲字符串的長度,還能防止字符串溢出,實現二進制存儲安全等特性)
- 哈希表用的是字典,且通過兩個 ht 實現漸進式 rehash(有利于加快Redis響應效率)
- 還有通過 ZipList、QuickList 來壓縮內存
- 非阻塞的 I/O 多路復用模型:用一個線程管理多個網絡連接
- epoll
- React 線程模型
談一下 Redis 的哈希槽
Redis 集群使用數據分片(sharding)而非一致性哈希(consistency hashing)來實現分區(因為一致性哈希開銷很大)
數據分片就是用到了16384個槽,槽里面可存多個key
集群使用公式 CRC16(key) % 16384 來計算鍵 key 屬于哪個槽
也就是說整個集群里面不管有幾臺機器,只有 16384 個槽,集群把槽分配給全部的實例,每個實例管理一部分的槽,如圖:
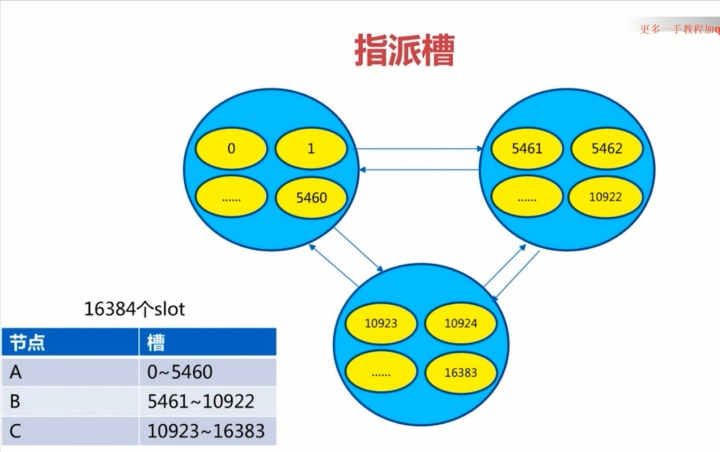
擴容、縮容都要涉及槽的遷移;擴容后要給新機器分配槽、縮容后要分配被釋放的槽給其他節點。
傳統的一致性哈希
后知后覺:面試必備:什么是一致性Hash算法??zhuanlan.zhihu.com



)


的詳細操作)
)






1. Simulink仿真實現)
![arima模型_[不說人話系列]-ARIMA模型](http://pic.xiahunao.cn/arima模型_[不說人話系列]-ARIMA模型)



模擬卷客觀題...)