大數據架構-Lambda
- Lambda架構由Storm的作者Nathan Marz提出。旨在設計出一個能滿足實時大數據系統關鍵特性的架構,具有高容錯、低延時和可擴展等特性。
- Lambda架構整合離線計算和實時計算,融合不可變性(Immutability),讀寫分離和復雜性隔離等一系列架構原則,可集成Hadoop,Kafka,Storm,Spark,HBase等各類大數據組件
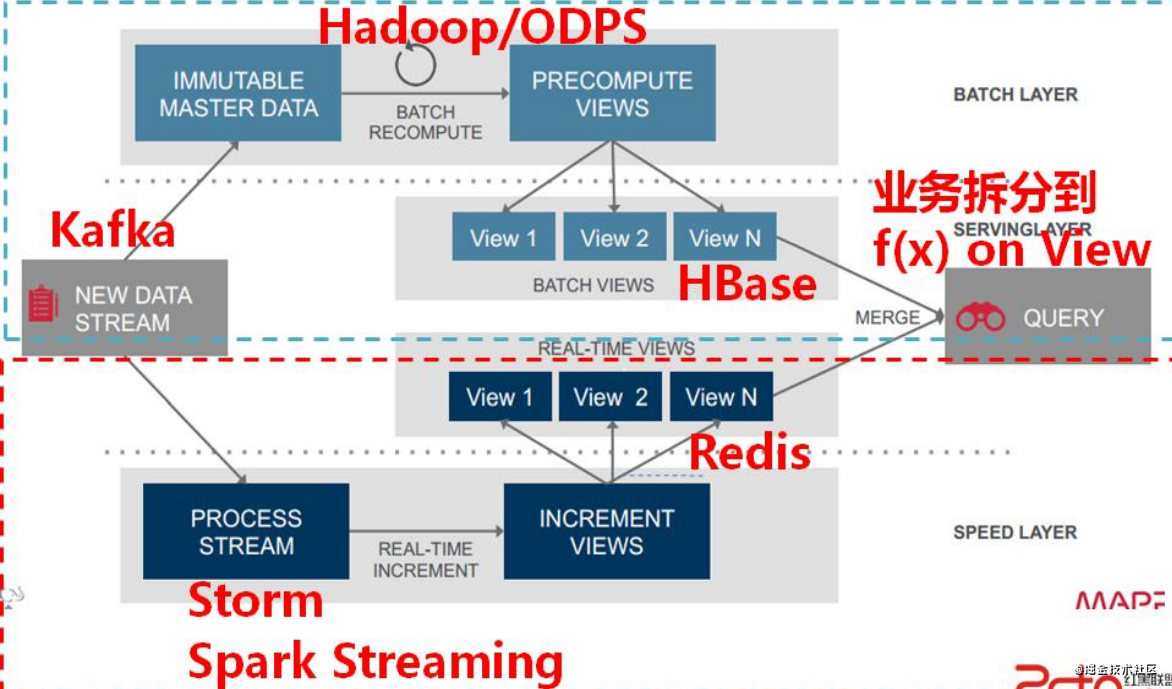
三層架構:批處理層、實時處理層、服務層
數據采集之Flume和Kafka
Flume
Flume是Cloudera提供的高可用的、高可靠的、分布式的海量日志采集、聚合和傳輸的系統,Flume支持在日志系統中定制各類數據發送方,用于收集數據;
Flume提供對數據進行簡單處理,并寫到各種數據接受方(可定制)的能力。 Flume提供了從console(控制臺)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系統,支持TCP和UDP等2種模式),exec(命令執行)等數據源上收集數據的能力
Kafka
Apache Kafka是分布式發布-訂閱消息系統。它最初由LinkedIn公司開發,之后成為Apache項目的一部分。Kafka是一種快速、可擴展的、設計內在就是分布式的,分區的和可復制的提交日志服務.
Apache Kafka與傳統消息系統相比,有以下不同:
- 它被設計為一個分布式系統,易于向外擴展;
- 它同時為發布和訂閱提供高吞吐量;
- 它支持多訂閱者,當失敗時能自動平衡消費者;
- 它將消息持久化到磁盤,因此可用于批量消費,例如ETL,以及實時應用程序
工作流-OOzie
在Hadoop中執行的任務有時候需要把多個Map/Reduce作業連接到一起,這樣才能夠達到目的。
數據分析工具:Pig
Pig是一個基于Hadoop的大規模數據分析平臺,它提供的SQL-LIKE語言叫Pig Latin,該語言的編譯器會把類SQL的數據分析請求轉換為一系列經過優化處理的MapReduce運算。Pig為復雜的海量數據并行計算提供了一個簡單的操作和編程接口。
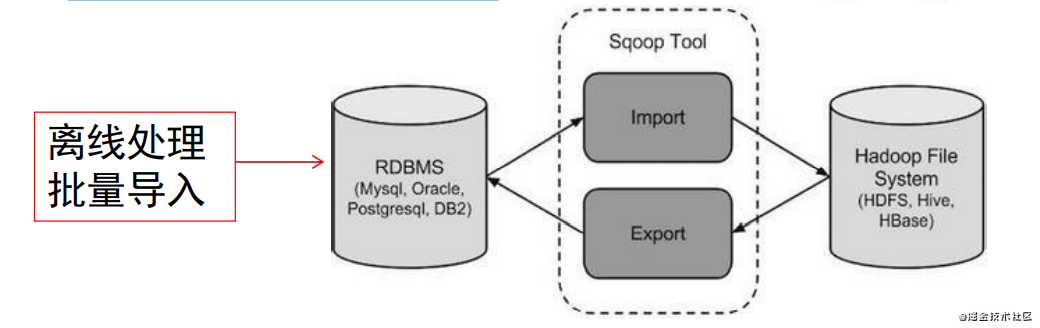
RDBMS 與 Hadoop 數據遷移工具:Sqoop
Sqoop=SQL+hadoop
數據挖掘分析工具:Mahout
Mahout 是一個很強大的數據挖掘工具,是一個分布式機器學習算法的集合,包括:被稱為Taste的分布式協同過濾的實現、分類、聚類等。Mahout最大的優點就是基于hadoop實現,把很多以前運行于單機上的算法,轉化為了MapReduce模式,這樣大大提升了算法可處理的數據量和處理性能。
Spark:基于內存的大型的、低延遲的數據分析應用程序;












)







