現實世界 機器學習
In my previous posts I covered analytical subjects from a scientific point of view, rather than an applied real world problem. For this reason, this article aims at approaching an analytical idea from a managerial point of view, rather than going through the hard math. Let’s start with the “why questions”.
在我以前的文章中,我從科學的角度介紹了分析主題,而不是實際的現實問題。 出于這個原因,本文旨在從管理的觀點出發,而不是通過嚴格的數學方法來分析一種想法。 讓我們從“為什么問題”開始。
While some executives feared employees will not be as efficient as they are at the office, others were not quite convinced that processes, precisely planned and designed for on site work, could also be followed from home. Well, these concerns turned out to be wrong. As the crisis around Covid-19 has proved it, working from home is feasible even on a large scale and will likely be the new normal.
盡管一些高管擔心員工的效率不如辦公室,但另一些高管則不太相信為現場工作精心計劃和設計的流程也可以在家中進行。 好吧,這些擔心被證明是錯誤的。 正如圍繞Covid-19的危機所證明的那樣,即使大規模進行在家工作也是可行的,并且很可能成為新的常態 。
Many may have returned to their previous working environment, but still communication within the company has changed sustainably?—?do not expect this to return to the pre-Covid-time! We could observe that communicating about the virus and its impact on all of us, is essential in order to “create clarity, build resilience and catalyse positive change” among the employees. To be more concrete, sound communication is not only a task related to Corona virus, but an ongoing necessity to assure the companies’ success?—?and no, I am not only talking about the top-down company news.
許多人可能已經回到了以前的工作環境,但是公司內部的溝通仍然發生了可持續的變化-不要指望這種情況能回到Covid之前的時代! 我們可以觀察到,就員工之間的“ 創建清晰性,增強適應力和促進積極變化 ”而言,就該病毒及其對我們所有人的影響進行交流至關重要。 更具體地說,聲音交流不僅是與Corona病毒有關的任務,而且是確保公司成功的持續必要條件-不,我不僅在談論自上而下的公司新聞。
This all might sound a bit esoteric, so let me address the following agenda in more detail?—?we will even cover a breeze of unsupervised machine learning to get the most of our data 🚀?—?this is going to be real fun!
? 他的一切聽起來有點深奧,所以讓我更詳細地討論了以下議程-我們甚至將覆蓋無監督機器的微風學習,以獲得我們的大多數數據🚀 -這將是真正的樂趣!
This article will be split into two sections:
本文將分為兩部分:
Rationale: Why is analysing communication data so important?
理由:為什么分析通訊數據如此重要?
How-To: Means to analyse communcation data?
方法:分析通訊數據的方法?
The second part is covered through a quantitative approach that does some basic data exploration based on Microsoft Office 365 data.
第二部分通過定量方法進行介紹,該方法基于Microsoft Office 365數據進行一些基本數據探究。
基本原理 (Rationale)
First things first, let’s throw around a couple more buzz words. Digital Transformation and Big Data are not new and have been floating around for a couple of years now. Triggered by new ways of analysing data, the strong industry pressure to move towards a more digital business model as well as the need to gain and retain a competitive edge, these buzz words seem to remain inherent to sustainable corporate success.
首先,讓我們再說幾個時髦的詞。 數字轉型和大數據并不是什么新鮮事物,并且已經流行了兩年。 在新的數據分析方法,行業向更數字化的商業模式轉變的強大壓力以及獲得和保持競爭優勢的需求的推動下,這些時髦的話似乎仍然是可持續企業成功所固有的。
For this reason we will have a closer look at the results of previous studies and surveys carried out by several of the most industry acknowledged consulting companies.
因此,我們將更仔細地研究由一些最受業界認可的咨詢公司進行的先前研究和調查的結果。
What is communication related data?
什么是與通信相關的數據?
Communication data is data that captures interaction between individuals or groups, that can be e.g. graphs (directed and undirected), aggregations of data that may represent which application or service was used or simply the amount of time spent or number of messages sent by a user. There is of course no way to move further towards analysing text data or other private and person related details — remember privacy and GDPR folks!
通信數據是捕獲個人或組之間的交互的數據,例如可以是圖形(有向圖和無向圖),可以表示使用了哪個應用程序或服務的數據集合,或者只是用戶花費的時間量或發送的消息數。 當然,沒有辦法進一步分析文本數據或其他與私人和個人相關的詳細信息 - 記住隱私和GDPR人士 !
Digital Transformation
數字化轉型
I asked Google what is essential to a successful digital transformation and came up with a good collections of statements that seem convincing and based on experiences rather than opinions:
我問Google對成功進行數字化轉型的必要條件,并提出了一系列令人信服的陳述,這些陳述似乎是有說服力的,是基于經驗而非觀點的:
McKinsey: “Our research points to a set of factors that might improve the chances of a transformation succeeding covering five categories:
麥肯錫 :“我們的研究指出了一系列因素,這些因素可能會提高成功轉型的機會,涉及五個方面:
having the right, digital-savvy leaders in place
聘請合適的,精通數字的領導者
building capabilities for the workforce of the future
為未來的勞動力建設能力
empowering people to work in new ways
賦予人們以新方式工作的權力
giving day-to-day tools a digital upgrade
為日常工具提供數字升級
communicating frequently via traditional and digital methods”
通過傳統和數字方式進行頻繁交流”
Gartner’s opinion on the necessity of Communication Leaders in the light of digital transformation:
Gartner從數字化轉型的角度對傳播領導者的必要性的看法:
“[..] regularly discussing the company’s digital business narrative with employees can more than double their digital dexterity. Communicators can drive this effort by leveraging their storytelling ability.”
“ [..]定期與員工討論公司的數字業務敘述,可以使他們的數字靈活性提高一倍以上。 溝通者可以利用他們的 講故事能力 來推動這一努力 。 ”
“Only 17% of organizations discuss narratives consistently,” says Earl. “A successful digital business narrative
“ 只有17%的組織一直在討論敘事 ,”厄爾說。 “成功的數字業務敘事
highlights the importance of digital dexterity and
強調數字靈巧的重要性,
builds a consistent, shared understanding of what digital business transformation means and how individual employees should contribute.”
對數字業務轉型的含義以及每個員工應如何貢獻建立了一致的共識。”
Big Data
大數據
Communication data is data your company may already have — or could obtain easily! Deloitte evaluated types of data through assigning value and volume/complexity. We may determine internal communication data to be “Targeted data” for which:
通信數據是您的公司可能已經擁有的數據,或者可以輕松獲得! 德勤通過分配值和數量/復雜性來評估數據類型 。 我們可能將內部通信數據確定為“目標數據”,其目標是:
there are few sources
資料來源很少
often difficult to collect, but
通常很難收集,但是
containing insights highly relevant to the business problem
包含 與業務問題高度相關的見解

PwC is very clear on the complexity of communication information — whether it is internal or external:
普華永道非常清楚通信信息的復雜性,無論是內部的還是外部的:
“As with the growth of email, the proliferation of other digital communications and service channels mean that whether your audience is business or consumer facing — they are undoubtedly hit with a barrage of information, much of which is ignored simply due to the sheer volume.”
“隨著電子郵件的增長,其他數字通信和服務渠道的泛濫意味著您的受眾是面向企業還是面向消費者–毫無疑問,他們受到大量信息的沖擊,其中的許多信息由于數量龐大而被忽略 。 ”
如何? (How-To?)
Let’s proceed with the analytical part, this is where things become tangible, finally.
讓我們繼續分析部分 ,最后這是東西變得有形的地方。
As outlined under Deloitte’s opinion on big data, there are very few sources that allow obtaining communication data. With regard to my data source, I have used data originated from an application called OfficeExpert which allows its users to collect meta-data-like communication data within the Microsoft Office environment. More specifically, I focused on communication data gathered from Microsoft Teams (Messages to individuals and in groups) and Exchange in order to identify “Communication Leaders”.
正如德勤對大數據的看法所概述的那樣,很少有資源可以獲取通信數據。 關于我的數據源,我使用了來自名為OfficeExpert的應用程序的數據,該應用程序允許其用戶在Microsoft Office環境中收集類似元數據的通信數據。 進一步來說, 我專注于從Microsoft團隊(發給個人和小組的消息)和Exchange收集的通信數據,以便確定“通信負責人”。
First, I checked on what data was actually collected per user in order to get a bit of a feeling what further analysis I could do. Anonymous user data is visualised in different ways e.g.:
首先,我檢查了每個用戶實際上收集了哪些數據,以便對我可以做進一步的分析有所了解。 匿名用戶數據以不同方式可視化,例如:


After having clicked through the tabs I felt that I would even be more interested in the raw data collected by the tool. In order to stay consistent with my first impression, I went through the underlying data which is the basis for the above visualisations and is can be accessed through a SQL client. With a bit of SQL understanding this works without any issues.
單擊選項卡后,我感到我對該工具收集的原始數據會更加感興趣。 為了與第一印象保持一致,我仔細研究了基礎數據,這些數據是上述可視化的基礎,可以通過SQL客戶端進行訪問。 對SQL有一點了解,這可以正常工作。
My first impression is, that there are quite a few users that are considerably more involved in communications than others. Through another functionality in the tool, I could draw a graph of users that are related to each other in terms of how intensively they communicate. A company undirected graph can be observed in the tool and looks like this (users are nodes, any type of connection is an edge):
我的第一印象是,有相當多的用戶比其他用戶參與通信。 通過該工具中的另一個功能, 我可以繪制一張用戶圖表,這些圖表根據他們的交流強度而彼此相關 。 可以在工具中觀察到公司無向圖,它看起來像這樣(用戶是節點,任何類型的連接都是邊):

Clearly there are very well connected users at the bottom of the visualisation, these do have a variety of connections to other users and many tiny rectangles as well. The rectangles describe channels. Microsoft Teams allows to create channels and Teams in order to orchestrate and facilitate communication to several users.
顯然,在可視化的底部有連接良好的用戶,這些用戶與其他用戶的連接確實多種多樣,并且還有許多小矩形。 矩形描述通道。 Microsoft團隊允許創建渠道和團隊,以編排并促進與多個用戶的通信。
As a data scientist you will now probably have a hard time resisting to think of this even further. Is there a way to cluster users? Naturally I would expect a group of highly active users, medium and less involved users. Addressing the Communication leaders in the company is essential — I am referring to Gartner (Digital Transformation) once again.
作為數據科學家,您現在可能會很難拒絕進一步考慮。 有沒有一種群集用戶的方法? 當然,我希望一群活躍的用戶,中度和較少參與的用戶。 與公司的溝通負責人打交道是至關重要的–我再一次指的是Gartner (數字化轉型)。
For this purpose I will use a method of unsupervised learning — Kmeans clustering. The purpose of kmeans clustering is to divide our data in k segments that can be differentiated from each other.
為此,我將使用一種無??監督學習的方法-Kmeans聚類。 kmeans聚類的目的是將我們的數據分為可彼此區分的k個段。
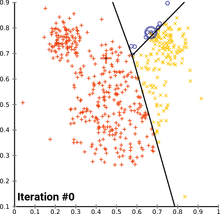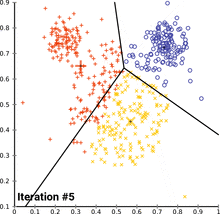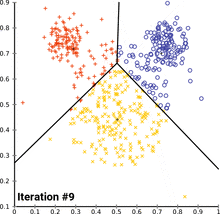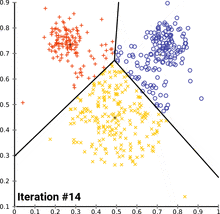
This heuristic algorithm is very straightforward, as soon as the number k cluster centers is determined, the algorithm iterates over the dataset and re-calculates the cluster centers for every iteration, hence the crucial part is to determine the number clusters the data is separated into. According to the next chart, more than two to three clusters will not provide a sufficiently large cluster size.
此啟發式算法非常簡單,一旦確定了k個聚類中心,該算法就會對數據集進行迭代,并針對每次迭代重新計算聚類中心,因此關鍵部分是確定將數據分為多少個聚類。 根據下一張圖表,超過兩到三個群集將無法提供足夠大的群集大小。

The possible ways to analyse this data are numerous. According to the above described basic algorithm, we may already be able to identify three key users that share certain similarities in a way that allows us gather them together in a cluster. Further, there are 24 users that are quite active as well, not specified as “Communication Leader”, but still very relevant to the overall flow of information within and outside of the company.
分析此數據的可能方法很多。 根據上述基本算法,我們可能已經能夠識別三個具有某些相似性的關鍵用戶,從而使我們可以將他們聚集在一起。 此外,還有24個用戶也非常活躍,沒有指定為“通信主管”,但仍然與公司內部和外部的總體信息流相關。

# Clustering counts| label| user ||-----:|-----:|| 0 | 107 | # Low involvement with other users and groups| 1 | 24 | # Medium involvement with other users and groups| 2 | 3 | # Communication leaders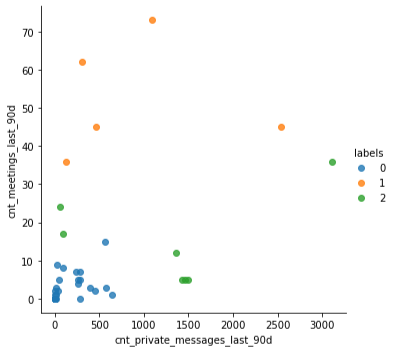
When using a variety of predictors we come to the result that there 3 clusters is a proper number to separate the data points. If we compared our final result to just a lower number of predicting dimensions, cluster sizes would be considerably larger (image to the left).
當使用各種預測變量時,我們得出的結果是,有3個聚類是適當的數目來分隔數據點。 如果我們將最終結果與較少的預測維數進行比較,則聚類大小將大得多 (左圖)。
Back at the model that explained 3 extraordinary users, that showed different using patterns than the majority of other users, I could learn the following from this tiny group of users:
回到解釋3個非常規用戶的模型,該模型顯示出與大多數其他用戶不同的使用模式,我可以從這一小部分用戶中學到以下知識:
- they have the highest involvement in internal channels/groups 他們對內部渠道/群體的參與度最高
- they are among the top users being responsible for channels/groups 他們是負責渠道/組的主要用戶之一
- they contribute a lot of time to external communication (that could mean partners or customers) 他們為外部交流貢獻了很多時間(這可能意味著合作伙伴或客戶)
- The tend to have fewer direct messages, they are rather involved in the groups where they post and interact 趨向于減少直接消息,他們寧愿參與發布和交互的小組
Of course this is just the tip of the iceberg?—?but nonetheless, this should have given a basic idea of what could be possible and how the treasure of company owned data could be used.
當然,這只是冰山一角,但盡管如此,這應該已經給出了一個基本的思路,即可能發生的事情以及如何利用公司擁有的數據的寶藏。
Other ideas towards I could imagine heading to:
我能想到的其他想法可能會導致:
- Label users according to their position in the company. Through tweaking and fitting a classification model, it may be possible to identify users that show a behaviour that is more related to another label than actually specified (e.g. a data analyst may be even more similar to a team leader than compared to other analysts) 根據用戶在公司中的職位為用戶貼標簽。 通過調整和擬合分類模型,有可能識別出顯示出與實際指定的標簽相比與另一個標簽更相關的行為的用戶(例如,與其他分析員相比,數據分析員與團隊領導者的相似性更高)
- Can we answer the question, whether a project is likely to be more successful than another based on the team members behave? With regard to this communication topic, does communication contribute to the project’s success? 我們能否回答這個問題,根據團隊成員的表現,一個項目是否可能比另一個項目更成功? 關于此交流主題,交流是否有助于項目的成功?
These are just some very generic ideas, however, no matter what we would like to investigate next, further analytics require spending more time on additional data exploration. Visualisations are a good starting point and often allow (visually) identifying essential attributes (features) with regard to the models.
這些只是一些非常通用的想法,但是,無論我們接下來要調查什么,進一步的分析都需要花費更多的時間進行額外的數據探索。 可視化是一個很好的起點,并且通常允許(視覺上)識別模型的基本屬性(特征)。
As an example, a simple pair plot might help us to identify useful relationships. Although quite hard to interpret at this stage, but the large variety of different scatter plots could enable better clustering algorithms. But again, these are just starting points.
例如,簡單的對圖可能有助于我們識別有用的關系。 盡管在這個階段很難解釋,但是各種各樣的散點圖可以實現更好的聚類算法。 但是,這些僅僅是起點 。
外賣 (Take aways)
There are many things we need to learn from this crisis. Especially in the corporate environment, the new normal of more frequent “working from home” days, more remote employees and the need of technical capabilities to successfully drive communication will remain and require the companies to adapt.
我們需要從這場危機中學到很多東西。 尤其是在公司環境中,新的常態將變得更加頻繁,即“在家工作”的日子越來越多,遠程員工越來越多,對成功推動溝通的技術能力的需求將仍然存在,并且需要公司適應 。
These changes resulting in new sources of data bear the potential to be a real gold mine for data scientists. Corporations must not oversee this opportunity and should aim at obtaining precious insights into their own structures in a way they have never considered before. Analytical tools are numerous, so it is up to the creativity of the data scientists to dive into world of corporate data.
這些變化產生了新的數據源,這有可能成為數據科學家真正的金礦。 公司絕不能忽視這個機會,而應該以從未有過的方式獲取對自己的結構的寶貴見解。 分析工具多種多樣,因此取決于數據科學家的創造力,以深入研究公司數據世界。
{see you next time}
{下次見}
Thanks to Volodymyr Hryshchenko for the title image and to panagenda for providing tools, visualizations and insights through OfficeExpert which allowed collecting and obtaining my dataset out of the Microsoft 365 environment.
感謝弗拉基米爾Hryshchenko為標題圖像和panagenda通過OfficeExpert這使得收集和獲取我的數據集了微軟365環境提供工具,可視化和見解。
Charts are created through OfficeExpert and Seaborn library
通過OfficeExpert和Seaborn庫創建圖表
翻譯自: https://towardsdatascience.com/an-introduction-to-corporate-communication-analysis-a-real-world-machine-learning-approach-bb82e5755bbc
現實世界 機器學習
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389946.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389946.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389946.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

拷貝構造函數和賦值函數
![[bzoj3036]綠豆蛙的歸宿](http://pic.xiahunao.cn/[bzoj3036]綠豆蛙的歸宿)
[bzoj3036]綠豆蛙的歸宿

5902. 檢查句子中的數字是否遞增


Chrome keyboard shortcuts

數據中心細節_當細節很重要時數據不平衡

辛普森悖論_所謂的辛普森悖論

查看NVIDIA使用率工具目錄

2043. 簡易銀行系統

余弦相似度和歐氏距離_歐氏距離和余弦相似度

bzoj2152 聰聰可可
)
七、 面向對象(二)

機器學習 客戶流失_通過機器學習預測流失

2044. 統計按位或能得到最大值的子集數目

redis系列:分布式鎖


預測股票價格 模型_建立有馬模型來預測股票價格

Python 模塊 timedatetime

