數據庫邏輯刪除的sql語句
Structured Query Language (SQL) is famously known as the romance language of data. Even thinking of extracting the single correct answer from terabytes of relational data seems a little overwhelming. So understanding the logical flow of query is very important.
小號 tructured查詢語言(SQL)是著名的被稱為數據的浪漫語言。 甚至想從TB的關系數據中提取單個正確答案似乎也有些不知所措。 因此,了解查詢的邏輯流程非常重要。
查詢執行計劃 (Query Execution Plan)
SQL is a declarative language, this means SQL query logically describes the question to the SQL Query Optimizer which later decides on the best way to physically execute the query. This method of execution is called the query execution plan. There can be more than one execution plan, so when we say optimize a query that in turn referring to make the query execution plan more efficient.
SQL是一種聲明性語言,這意味著SQL查詢從邏輯上向SQL查詢優化器描述了問題,SQL優化器隨后決定了物理執行查詢的最佳方法。 這種執行方法稱為查詢執行計劃。 可以有多個執行計劃,因此當我們說優化查詢時,該查詢反過來又使查詢執行計劃更有效。
Let’s look into the 2 flows that a SQL query can be looked through:
讓我們看一下可以查詢SQL查詢的2個流程:
查詢的句法流程 (Syntactical Flow of Query)
The SELECT statement basically tells the database what data to be retrieved along with which columns, rows, and tables to get the data from, and how to sort the data.
SELECT語句基本上告訴數據庫要檢索哪些數據以及從中獲取數據的列,行和表,以及如何對數據進行排序。

SELECT statement begins with a list of columns or expressions.
SELECT語句以列或表達式列表開頭。
FROM portion of the SELECT statement assembles all the data sources into a result set that is used by the rest of the SELECT statement.
SELECT語句的FROM部分將所有數據源組合成一個結果集,供其余SELECT語句使用。
WHERE clause acts upon the record set assembled by the FROM clause to filter certain rows based upon conditions.
WHERE子句作用于FROM子句組合的記錄集,以根據條件過濾某些行。
GROUP BY clause can group the larger data set into smaller data sets based on the columns specified.
GROUP BY子句可以根據指定的列將較大的數據集分組為較小的數據集。
HAVING clause can be used to restrict the result of aggregation by GROUP BY.
HAVING子句可用于限制GROUP BY的聚合結果。
ORDER BY clause determines the sort order of the result set.
ORDER BY子句確定結果集的排序順序。
Simplest possible valid SQL statement is :
最簡單的有效SQL語句是:
SELECT 1; (Oracle a requires FROM DUAL appended to accomplish this)
選擇1; (Oracle要求附加FROM FROM DUAL來完成此操作)
Hmmm... What is the problem in the flow of “Syntactical Flow”? Can you SELECT data without knowing WHERE it is coming FROM ?? ...Hmmm .. Somewhere there is LOGIC missing right !!! Soo ..
嗯...“句法流”中的問題是什么? 您可以在不知道數據來自何處的情況下選擇數據嗎? ...嗯..某個地方缺少LOGIC吧!!! o ..
查詢的邏輯流程 (Logical Flow of Query)
The best way to think the SQL statement is through the query’s logical flow. Logical may not be the same as physical flow and also it is not the same as the query syntax. Think the query in the following order:
認為SQL語句的最佳方法是通過查詢的邏輯流程。 邏輯可能與物理流程不同,也與查詢語法不同。 按以下順序考慮查詢:
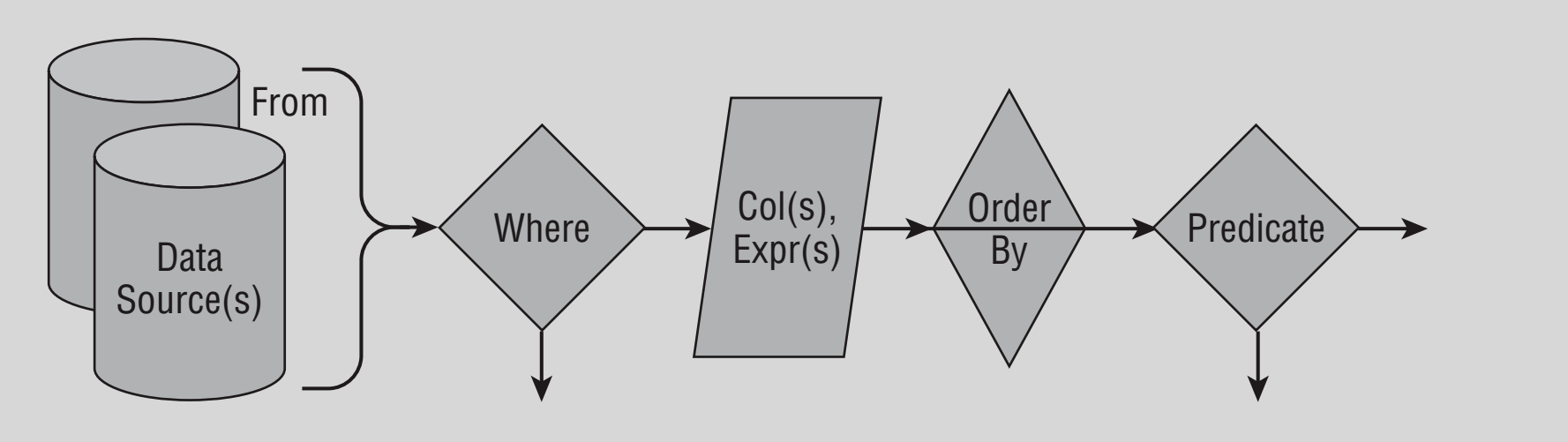
FROM: Logically query starts from the FROM clause by assembling the initial set of data.
FROM :邏輯查詢是通過組裝初始數據集從FROM子句開始的。
WHERE: Then where clause is applied to select only the rows that meet the criteria.
WHERE :然后應用where子句以僅選擇滿足條件的行。
Aggregations: Later aggregation is performed on the data such as finding the sum, grouping the data values in columns, and filtering the groups.
聚合 :稍后對數據執行聚合,例如查找總和,將數據值分組到列中以及過濾組。
Column Expressions: After the above operations the SELECT list is processed along with calculations of any expressions involved in it. (Except column expressions everything else is optional in SQL query.)
列表達式 :完成上述操作后,將處理SELECT列表以及其中涉及的任何表達式的計算。 (除了列表達式,SQL查詢中的其他所有內容都是可選的。)
ORDER BY: After getting the final resulting rows are sorted ascending or descending by ORDER BY clause.
ORDER BY :得到最終的結果行之后,按ORDER BY子句對行進行升序或降序排序。
OVER: Windowing and ranking functions can later be applied to get a separately ordered view of the result with additional functions for aggregation.
結束:以后可以使用開窗和排名功能來獲取結果的單獨排序視圖,并帶有用于聚合的其他功能。
DISTINCT: This is applied to remove any duplicate rows present in result data.
DISTINCT :用于刪除結果數據中存在的所有重復行。
TOP: After all this process of selecting data filtering it and performing all the calculations and ordering them, SQL can restrict the result to top few rows.
頂部:在完成所有這些選擇數據的過程之后,對數據進行過濾并執行所有計算并對它們進行排序,SQL可以將結果限制在前幾行。
INSERT, UPDATE, DELETE: This is the final logical step of the query to perform data modification using the resulting output.
INSERT,UPDATE,DELETE:這是查詢的最后邏輯步驟,用于使用結果輸出執行數據修改。
UNION: The output from the multiple queries can be stacked to using the UNION command.
UNION :可以使用UNION命令將多個查詢的輸出堆疊在一起。
For all the data anlysts who are working on database or datawarehouse projects. It is very important to understand the logical flow and the basic logic behind it. In any data anlysis project, data collection would be first step (FROM) and removing unessecarry data (WHERE) and then ordering the data (ORDER BY) follows.
對于從事數據庫或數據倉庫項目的所有數據分析師。 了解邏輯流程及其背后的基本邏輯非常重要。 在任何數據分析項目中,數據收集都是第一步(FROM),然后刪除未保密的數據(WHERE),然后對數據進行排序(ORDER BY)。
翻譯自: https://medium.com/@manoj.bidadiraju/logical-flow-of-sql-query-sql-through-the-eye-of-database-e7d111c87516
數據庫邏輯刪除的sql語句
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389617.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389617.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389617.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章


5940. 從數組中移除最大值和最小值

BZOJ4127Abs——樹鏈剖分+線段樹

數據挖掘流程_數據流挖掘

北門外的小吃街才是我的大學食堂

786. 第 K 個最小的素數分數
![[LeetCode]最長公共前綴(Longest Common Prefix)](http://pic.xiahunao.cn/[LeetCode]最長公共前綴(Longest Common Prefix))
[LeetCode]最長公共前綴(Longest Common Prefix)

域嵌套太深_pyspark如何修改嵌套結構域


WIN10下ADB工具包安裝的教程和總結 --201809

1816. 截斷句子

spark的流失計算模型_使用spark對sparkify的流失預測

峰識別 峰面積計算 peak detection peak area 源代碼 下載

區塊鏈開發公司談區塊鏈與大數據的關系

Jupyter Notebook的15個技巧和竅門,可簡化您的編碼體驗

給定有權無向圖的鄰接矩陣如下,求其最小生成樹的總權重,代碼。

Ubuntu-16-04-編譯-Caffe-SSD

bi數據分析師_BI工程師和數據分析師的5個格式塔原則

BSOJ 2423 -- 【PA2014】Final Zarowki
)