數據挖掘流程
1-簡介 (1- Introduction)
The fact that the pace of technological change is at its peak, Silicon Valley is also introducing new challenges that need to be tackled via new and efficient ways. Continuous research is being carried out to improve the existing tools, techniques, and algorithms to maximize their efficiency. Streaming data has always remained a challenge since the last decades, nevertheless plenty of stream-based algorithms have been introduced but still, the researchers are struggling to achieve better results and performance. As you know that, when water from a fire hose starts hitting your face, chances to measure it starts decreasing gradually. This is due to the torrent nature of streams. It has introduced new challenges of analyzing and mining the streams efficiently. Stream analysis has been made easy up to some extent because of a few new tools that are introduced in the market recently. These tools are following different approaches and algorithms which are being improved continuously. However, when it comes to mining data streams, it is not possible to store and iterate over the streams like traditional mining algorithms due to their continuous, high-speed, and unbounded nature.
技術變革的步伐達到頂峰這一事實,硅谷也帶來了新的挑戰,需要通過新的有效方式來應對。 正在進行持續的研究以改進現有的工具,技術和算法,以使其效率最大化。 自從過去的幾十年以來,流數據一直是一個挑戰,盡管引入了很多基于流的算法,但是研究人員仍在努力獲得更好的結果和性能。 如您所知,當消防水帶上的水開始濺到您的臉上時,測量水的機會開始逐漸減少。 這是由于流的洪流性質。 它帶來了有效分析和挖掘流的新挑戰。 由于最近市場上引入了一些新工具,因此在某種程度上簡化了流分析。 這些工具采用了不同的方法和算法,并不斷得到改進。 但是,在挖掘數據流時,由于其連續,高速且無限制的特性,因此無法像傳統的挖掘算法一樣在數據流上進行存儲和迭代。
Due to irregularity and variation in the arriving data, memory management has become the main challenge to deal with. Applications like sensor networks cannot afford mining algorithms with high memory cost. Similarly, time management, data preprocessing techniques, and choice of the data structure are also considered as some of the main challenges in the stream mining algorithms. Therefore, summarization techniques derived from the statistical science are dealing with a challenge of memory limitation, and techniques of the computational theory are being used to improve the time and space-efficient algorithms. Another challenge is the consumption of available resources, to cope with this challenge resource-aware mining is introduced which makes sure that the algorithm always consumes the available resources with some consideration.
由于到達數據的不規則性和變化,內存管理已成為要處理的主要挑戰。 像傳感器網絡這樣的應用程序無法承受具有高存儲成本的挖掘算法。 同樣,時間管理,數據預處理技術和數據結構的選擇也被視為流挖掘算法中的一些主要挑戰。 因此,源自統計科學的摘要技術正在應對內存限制的挑戰,并且使用計算理論的技術來改進時間和空間效率高的算法。 另一個挑戰是可用資源的消耗,為了應對這一挑戰,引入了資源感知挖掘,以確保算法始終在考慮某些因素的情況下消耗可用資源。
As data stream is seen only once therefore it requires mining in a single pass, for this purpose an extremely fast algorithm is required to avoid problems like data sampling and shredding. Such algorithms should be able to run with data streams in parallel settings partitioned to many distributed processing units. Infinite data streams with high volumes are produced by many online, offline real-time applications and systems. The update rate of data streams is time-dependent. Therefore to extract knowledge from streaming data, some special mechanism is required. Due to their high volume and speed, some special mechanism is required to extract knowledge from them.
由于只能看到一次數據流,因此需要單次挖掘,因此需要一種非常快速的算法來避免數據采樣和粉碎等問題。 這樣的算法應該能夠與并行設置為多個分布式處理單元的數據流一起運行。 許多在線,離線實時應用程序和系統都會產生大量的無限數據流。 數據流的更新速率取決于時間。 因此,要從流數據中提取知識,需要一些特殊的機制。 由于它們的高容量和高速度,需要一些特殊的機制來從它們中提取知識。
Many stream mining algorithms have been developed and proposed by machine learning, statistical and theoretical computer science communities. The question is, how should we know which algorithm is best in terms of dealing with current challenges as mentioned above, and what is still needed in the market? This document intends to answer these questions. As this research topic is quite vast therefore deciding the best algorithm is not quite straightforward. We have compared the most recently published versions of stream mining algorithms in our distribution which are classification, clustering, and frequent itemset mining. Frequent itemset mining is a category of algorithms used to find the statistics about streaming data.
機器學習,統計和理論計算機科學界已經開發和提出了許多流挖掘算法。 問題是,就如何應對上述當前挑戰而言,我們如何知道哪種算法最好,而市場仍需要什么呢? 本文檔旨在回答這些問題。 由于這個研究主題非常廣泛,因此確定最佳算法并不是一件容易的事。 我們已經比較了我們發行版中最新發布的流挖掘算法版本,它們是分類,聚類和頻繁項集挖掘。 頻繁項集挖掘是用于查找有關流數據的統計信息的一種算法。
2-分類 (2- Classification)
The classification task is to decide the proper label for any given record from a dataset. It is a part of Supervised learning. The way of the learning works is to have the algorithm learn patterns and important features from a set of labeled data or ground truths resulting in a model. This model will be utilized in the classification tasks. There are various metrics used to rate the performance of a model. For example, Accuracy, in which the focus of this metric is to maximize the number of correct labels. There is also, Specificity in which the focus is to minimize mislabelling negative class. There are few factors that are crucial to deciding which metrics are to be used in classification tasks, such as label distributions and the purpose of the task itself.
分類任務是為數據集中的任何給定記錄確定適當的標簽。 它是監督學習的一部分。 學習工作的方式是讓算法從一組標記數據或模型得出的基礎事實中學習模式和重要特征。 該模型將用于分類任務。 有多種指標可用于評估模型的性能。 例如,準確性,此度量標準的重點是最大化正確標簽的數量。 在“特異性”中,重點是最大程度地減少標簽錯誤的負面類別。 對于決定在分類任務中使用哪些度量至關重要的因素很少,例如標簽分布和任務本身的目的。
There are also a few types in the Classification Algorithm, such as Decision Trees, Logistic Regression, Neural Networks, and Naive Bayes. In this work, we decide to focus on Decision Tree.
分類算法中也有幾種類型,例如決策樹,邏輯回歸,神經網絡和樸素貝葉斯。 在這項工作中,我們決定專注于決策樹。
In Decision Tree, the learning algorithm will construct a tree-like model in which the node is a splitting attribute and the leaf is the predicted label. For every item, the decision tree will sort such items according to the splitting attribute down to the leaf which contained the predicted label.
在決策樹中,學習算法將構建一個樹狀模型,其中節點是拆分屬性,葉是預測標簽。 對于每個項目,決策樹將根據拆分屬性將這些項目分類到包含預測標簽的葉子。
2.1 Hoeffding樹 (2.1 Hoeffding Trees)
Currently, Decision Tree Algorithms such as ID3 and C4.5 build the trees from large amounts of data by recursively select the best attribute to be split using various metrics such as Entropy Information Gain and GINI. However, existing algorithms are not suitable when the training data cannot be fitted to the memory.
當前,諸如ID3和C4.5之類的決策樹算法通過使用諸如熵信息增益和GINI之類的各種度量來遞歸選擇要分割的最佳屬性,從而從大量數據中構建樹。 但是,當訓練數據無法擬合到存儲器中時,現有算法不適合。
There exist few incremental learning methods in which the learning system, instead of fitting the entire data-sets at once in memory, continuously learning from the stream of data. However, it is found that those model lack of correctness guarantee compared to batch learning for the same amount of the data.
很少有增量學習方法,其中學習系統不是從內存中一次擬合整個數據集,而是從數據流中不斷學習。 但是,發現對于相同數量的數據,與批處理學習相比,這些模型缺乏正確性保證。
Domingos and Hulten [1] formulated a decision tree algorithm called the Hoeffding Tree. With Hoeffding Tree, the record or training instance itself is not saved in the memory, only the tree nodes and statistics are stored. Furthermore, the most interesting property of this tree is that the correctness of this tree converges to trees built using a batch learning algorithm given sufficient massive data.
Domingos和Hulten [1]制定了一種決策樹算法,稱為Hoeffding樹。 使用霍夫丁樹,記錄或訓練實例本身不會保存在內存中,僅存儲樹節點和統計信息。 此外,該樹的最有趣的屬性是,在給定足夠的大量數據的情況下,該樹的正確性收斂到使用批處理學習算法構建的樹。
The training method for this tree is simple. For each sample, sort it to the subsequent leaf and update its statistic.
這棵樹的訓練方法很簡單。 對于每個樣本,將其排序到隨后的葉子并更新其統計信息。
There are two conditions that must be fulfilled in order for a leaf to be split
為了分裂葉子,必須滿足兩個條件
1. There exists impurity in the leaf node. That is, not every record that is stored on the leaf has the same class.
1.葉節點中存在雜質。 即,并非每個存儲在葉子上的記錄都具有相同的類。
2. The difference of the result of the evaluation function between the best attribute and second-best attribute denoted ?G is greater than E, where E is
2.最佳屬性和次佳屬性之間的評估函數結果之差表示為? G大于E ,其中E為
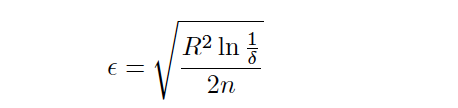
Where R is the range of the attribute, δ (provided by the user) is the desired probability of the sample not within E and n is the number of collected samples in that node.
其中R是屬性的范圍, δ (由用戶提供)是樣本不在E中的期望概率, n是在該節點中收集的樣本數。
In the paper, it is rigorously proven that the error of this tree is bounded by Hoeffding Inequality. Another excellent property of this tree is that even though we reduce the error rate exponentially, we only need to increase the sample size linearly.
在本文中,嚴格證明了該樹的錯誤受Hoeffding不等式的限制。 該樹的另一個出色特性是,即使我們以指數方式減少錯誤率,我們也只需要線性增加樣本大小。
2.2 VFDT算法 (2.2 VFDT Algorithm)
Domingos and Hutten further introduced a refinement of Hoeffding Tree called VFDT (Very Fast Decision Tree). The main idea is the same as Hoeffding Tree.
Domingos和Hutten進一步介紹了Hoeffding樹的改進,稱為VFDT(超快速決策樹)。 主要思想與霍夫丁樹相同。
The refinements are
細化是
?Ties VFDT introduced an extra parameter τ. It is used when the delta between the best and the second-best attribute is too similar
? 領帶 VFDT引入了額外的參數τ 。 當最佳屬性和次佳屬性之間的差值太相似時使用
?G computation Another parameter introduced is nmin, which denotes the minimum number of samples before G is recomputed. That means the computation of the G can be deferred instead of every time a new sample arrives, which reduces global times resulted from frequents calculation of G
? G計算引入的另一個參數是nmin ,它表示重新計算G之前的最小樣本數。 這意味著可以推遲G的計算,而不是每次到達新樣本時都進行延遲,這減少了由于頻繁計算G而導致的全局時間
?Memory VFDT introduces a mechanism of pruning the least promising leaf from the Tree whenever the maximum available memory already utilized. The criterion used to determine whether a leaf is to be prune is the product of the probability of a random example that will go to it denoted as pl and its observed error rate el. The leaf with the lowest that criteria value will be considered as the least promising and will be deactivated.
? 內存 VFDT引入了一種機制,只要已利用了最大的可用內存,就會從Tree中修剪掉前景最差的葉子。 用于確定是否要修剪葉子的標準是將要出現在葉子上的隨機示例的概率乘以p1并觀察到的錯誤率el的乘積。 具有最低標準值的葉子將被認為是最沒有希望的葉子,并將被停用。
?Dropping Poor Attributes Another approach to have a performance boost is to drop attributes that are considered not promising early. If the difference of its evaluation function value between an attribute with the best attribute is bigger than E, then that attribute can be dropped. However, the paper doesn’t explain what is the exact parameter or situation for an attribute to be dropped.
? 刪除較差的屬性提高性能的另一種方法是刪除被認為不盡早實現的屬性。 如果具有最佳屬性的屬性之間的評估函數值之差大于E ,則可以刪除該屬性。 但是,本文沒有說明要刪除的屬性的確切參數或情況是什么。
?Initialization The VFDT can be bootstrapped and combined by an existing memory-based decision tree to allow the VFDT to accomplish the same accuracy with a smaller number of examples. No detailed algorithm is provided, however.
? 初始化 VFDT可以通過現有的基于內存的決策樹進行引導和合并,以使VFDT能夠以更少的示例數實現相同的精度。 但是,沒有提供詳細的算法。
2.3 Hoeffding自適應樹 (2.3 Hoeffding Adaptive Trees)
One of the fallacies in Data Mining is the assumption that the distribution of data remains stationary. This is not the case, consider data from a kind of supermarket retails, the data can change rapidly in each different season. Such a phenomenon is called concept drift.
數據挖掘的謬論之一是假設數據分布保持平穩。 情況并非如此,考慮到一種超市零售的數據,該數據在每個不同的季節都會快速變化。 這種現象稱為概念漂移 。
As a solution, Bifet et al [2] proposed a sliding window and adaptively based enhancements to Hoeffding Tree. Furthermore, the algorithm to build such a tree is based on the authors’ previous work, ADWIN (Adaptive Windowing) Algorithm which is a parameter-free algorithm to detect and estimates changes in Data Stream.
作為解決方案,Bifet等人[2]提出了一個滑動窗口和對Hoeffding樹的自適應增強。 此外,構建此類樹的算法基于作者先前的工作,即ADWIN(自適應窗口)算法,該算法是一種無參數算法,可檢測和估計數據流中的變化。
In building adaptive learning algorithm, needs to be able to decides these three things
在建立自適應學習算法時,需要能夠決定這三件事
? What are things that need to be remembered?
?需要記住哪些事情?
? When is the correct time to upgrade the model?
? 什么時候升級模型?
? How to upgrade the model?
? 如何升級模型?
Therefore there is a need for a procedure that is able to predict and detect changes in Data Distribution. In this case, is served by ADWIN algorithm mentioned before.
因此,需要一種能夠預測和檢測數據分布變化的過程。 在這種情況下,由前面提到的ADWIN算法提供服務。
The main idea of Hoeffding Adaptive Tree is that aside from the main tree, alternative trees are created as well. Those alternative trees are created when distribution changes are detected in the data stream immediately. Furthermore, the alternate tree will replace the main tree when it is evidence that the alternate tree is far more accurate than the main tree. Ultimately, the changing and adaptation of trees are happening automatically judged from the time and nature of data instead of prior knowledge by the user. Note that, having said that it still retains in principle the algorithm to build and split the tree according to Hoeffding bound, similar to VFDT.
Hoeffding自適應樹的主要思想是,除了主樹之外,還創建替代樹。 當立即在數據流中檢測到分布更改時,將創建這些備用樹。 此外,當有證據表明備用樹比主樹準確得多時,備用樹將替換主樹。 最終,樹木的改變和適應是根據數據的時間和性質自動進行判斷的,而不是用戶的先驗知識。 注意,盡管如此,它仍然保留了類似于Hoofding邊界的樹的構建和分割算法,類似于VFDT。
In experiments, the authors mainly compared the Hoeffding Adaptive Tree with CVFDT (Concept Adapting Very Fast Decision Tree). CVFDT itself is formulated by the same authors of VFDT, it is basically VFDT with an attempt to include concept drift. In terms of performance measured with an error rate, using a synthetically generated dataset with a massive concept change, the algorithm managed to achieve a lower error rate quickly compared to CVFDT i.e. faster adaption to other trees. In addition, it managed to lower memory consumption by half. However, the drawback is that this algorithm consumes the longest time, 4 times larger than CVFDT.
在實驗中,作者主要將Hoeffding自適應樹與CVFDT(概念自適應非常快決策樹)進行了比較。 CVFDT本身由VFDT的相同作者制定,基本上是VFDT,試圖包括概念漂移。 就以錯誤率衡量的性能而言,使用具有重大概念變化的綜合生成的數據集,該算法設法比CVFDT更快地實現了更低的錯誤率,即更快地適應了其他樹。 另外,它設法將內存消耗降低了一半。 但是,缺點是該算法耗時最長,是CVFDT的4倍。
3聚類 (3 Clustering)
Clustering is to partition a given set of objects into groups called clusters in a way that each group have similar kind of objects and is strictly different from other groups. Classifying objects into groups of similar objects with a goal of simplifying data so that a cluster can be replaced by one or few representatives is considered as a core of the clustering process. Clustering algorithms are considered as tools to cluster high volumes datasets. We have selected three latest clustering algorithms and compared them with others based on a performance metric i.e. efficient creation of clusters, the capability to handle a large number of clusters, and the chosen data structure.
聚類是將一組給定的對象劃分為稱為聚類的組,其方式是每個組具有相似的對象類型,并且與其他組完全不同。 為了簡化數據,將對象分為相似對象的組,以便可以用一個或幾個代表替換群集,這被認為是群集過程的核心。 聚類算法被認為是聚類大量數據集的工具。 我們選擇了三種最新的聚類算法,并根據性能指標將它們與其他算法進行了比較,即有效創建集群,處理大量集群的能力以及所選的數據結構。
3.1 流KM ++聚類算法 (3.1 Stream KM++ Clustering Algorithm)
Stream KM++ clustering algorithm is based on the idea of k -MEANS++ and Lloyd’s algorithm (also called k -MEANS algorithm) [3]. Lloyd’s algorithm is one of the famous clustering algorithms. Best clustering in Lloyd’s algorithm is achieved by assigning each point to the nearest center in a given sent of centers (fixed) and MEAN of these points is considered as the best center for the cluster. Also, k -MEANS++ serves as a seeding method for Lloyd’s algorithm. It gives a good practical result and guarantees a quality solution. Both algorithms are not suitable for the data streams as they require random access to the input data.
流 KM ++聚類算法基于k -MEANS ++和勞埃德算法(也稱為k -MEANS算法) [3]。 勞埃德算法是著名的聚類算法之一。 勞埃德算法中的最佳聚類是通過將每個點分配給給定發送的中心(固定)中的最近中心來實現的,這些點的MEAN被認為是聚類的最佳中心。 同樣, k -MEANS ++用作勞埃德算法的播種方法。 它提供了良好的實踐結果,并保證了質量解決方案。 這兩種算法都不適合數據流,因為它們需要隨機訪問輸入數據。
Def: Stream KM++ computes a representative small weighted sample of the data points (known as a coreset) via a non-uniform sampling approach in one pass, then it runs k -MEANS++ on the computed sample and in a second pass, points are assigned to the center of nearest cluster greedily. Non-uniform sampling is a time-consuming task. The use of coreset trees has decreased this time significantly. A coreset tree is a binary tree that is associated with hierarchical divisive clustering for a given set of points. One starts with a single cluster that contains the whole set of points and successively partitions existing clusters into two sub-clusters, such that points in one sub-cluster are far from the points in another sub-cluster. It is based on merge and reduces technique i.e. whenever two samples with the same number of input points are detected, it takes the union of these points in the merge phase and produces a new sample in the reduced phase which uses coreset trees.[4]
Def: Stream KM ++通過非均勻采樣方法在一次通過中計算數據點的代表性小加權樣本(稱為核心集),然后在計算的樣本上運行k -MEANS ++,在第二次通過中,分配點貪婪地到達最近的星團的中心。 非均勻采樣是一項耗時的任務。 這次, 核心集樹的使用已顯著減少。 核心集樹是與給定點集的分層除法聚類關聯的二叉樹。 一個群集從包含整個點集的單個群集開始,然后將現有群集依次劃分為兩個子群集,以使一個子群集中的點與另一個子群集中的點相距甚遠。 它基于合并和歸約技術,即,每當檢測到兩個具有相同輸入點數量的樣本時,它將在合并階段合并這些點,并在歸約階段使用核心集樹生成一個新樣本。[4]
In comparison with BIRCH (A top-down hierarchical clustering algorithm), Stream KM++ is slower but in terms of the sum of squared errors, it computes a better solution up to a factor of 2. Also, it does not require trial-and-error adjustment of parameters. Quality of StreamLS algorithm is comparable to Stream KM++ but running time of Stream KM++ scales much better with the number of cluster centers than StreamLS. Stream KM++ is faster on large datasets and computes solutions that are on a par with k -MEANS++.
與BIRCH(自上而下的層次聚類算法)相比, Stream KM ++較慢,但就平方誤差的總和而言,它計算出的最佳解法高達2倍。而且,它不需要反復試驗。參數的誤差調整。 流 LS算法的質量可媲美流 KM ++但比流 LS集群中心的數量要好得多流 KM ++秤的運行時間。 在大型數據集上, Stream KM ++更快,并且可以計算與k -MEANS ++相當的解決方案。
3.2動態物聯網數據流的自適應集群 (3.2 Adaptive Clustering for Dynamic IoT Data Streams)
A dynamic environment such as IoT where the distribution of data streams changes overtime requires a type of clustering algorithm that can adapt according to the flowing data. Many stream clustering algorithms are dependent on different parameterization to find the number of clusters in data streams. Determining the number of clusters in the unknown flowing data is one of the key tasks in clustering. To deal with this problem, an adaptive clustering method is introduced by P. B. Daniel Puschmann and R. Tafazoll in this research paper [5]. It is specifically designed for IoT stream data. This method updates the cluster centroids upon detecting a change in the data stream by analyzing its distribution. It allows us to create dynamic clusters and assign data to these clusters by investigating data distribution settings at a given time instance. It is specialized in adapting to data drifts of the data streams. Data drift describes real concept drift (explained in 2.3) that is caused by changes in the streaming data. It makes use of data distribution and measurement of the cluster quality to detect the number of categories which can be found inherently in the data stream. This works independently of having prior knowledge about data and thus discover inherent categories.
諸如IoT之類的動態環境,其中數據流的分布會隨著時間的變化而變化,這需要一種可以根據流動數據進行適應的聚類算法。 許多流聚類算法依賴于不同的參數化來查找數據流中的聚類數量。 確定未知流動數據中的聚類數量是聚類的關鍵任務之一。 為了解決這個問題,PB Daniel Puschmann和R.Tafazoll在本文中介紹了一種自適應聚類方法[5]。 它是專門為物聯網流數據設計的。 此方法通過分析數據流的分布來檢測數據流中的變化,從而更新群集質心。 它允許我們通過研究給定時間實例的數據分發設置來創建動態集群并將數據分配給這些集群。 它專門用于適應數據流的數據漂移。 數據漂移描述了由流數據的更改引起的實際概念漂移(在2.3中進行了說明) 。 它利用數據分布和群集質量的度量來檢測可以在數據流中固有地找到的類別數量。 這獨立于具有有關數據的先驗知識而工作,因此可以發現固有類別。
A set of experiments has been performed on synthesized and intelligent live traffic data scenarios in this research paper [5]. These experiments are performed using both adaptive and non-adaptive clustering algorithms and results are compared based on cluster’ quality metric (i.e. silhouette coefficient). The result has shown that the adaptive clustering method produces clusters with 12.2 percent better in quality than non-adaptive.
在這篇研究論文中,已經對合成的和智能的實時交通數據場景進行了一組實驗[5]。 這些實驗使用自適應和非自適應聚類算法進行,并基于聚類的質量度量(即輪廓系數)比較結果。 結果表明,自適應聚類方法產生的聚類質量比非自適應聚類好12.2%。
In comparison to Stream KM++ algorithm explained in 3.1, it can be induced that Stream
與3.1中解釋的Stream KM ++算法相比,可以推斷出Stream
KM++ is not designed for evolving data streams.
KM ++不適用于不斷發展的數據流。
3.3 PERCH-一種用于極端聚類的在線分層算法 (3.3 PERCH-An Online Hierarchical Algorithm for Extreme Clustering)
The number of applications requiring clustering algorithms is increasing. Therefore, their requirements are also changing due to the rapidly growing data they contain. Such modern clustering applications need algorithms that can scale efficiently with data size and complexity.
需要集群算法的應用程序數量正在增加。 因此,由于其中包含的數據快速增長,它們的要求也在發生變化。 這樣的現代集群應用程序需要能夠隨著數據大小和復雜性而有效擴展的算法。
As many of the currently available clustering algorithms can handle the large datasets with high dimensionality, very few can handle the datasets with many clusters. This is also true for Stream Mining clustering algorithms. As the streaming data can have many clusters, this problem of having a large number of data points with many clusters is known as an extreme clustering problem. PERCH (Purity Enhancing Rotations for Cluster Hierarchies) algorithm scales mildly with high N (data points) and K (clusters), and thus addresses the extreme clustering problem. Researchers of the University of Massachusetts Amherst published it in April 2017.
由于許多當前可用的聚類算法可以處理具有高維數的大型數據集,因此很少能處理具有許多聚類的數據集。 對于Stream Mining聚類算法也是如此。 由于流數據可以具有許多群集,因此具有許多群集的大量數據點的問題被稱為極端群集問題。 PERCH(用于群集層次結構的純度增強旋轉)算法在N(數據點)和K(群集)較高的情況下進行適度縮放,從而解決了極端的群集問題。 麻省大學阿默斯特分校的研究人員于2017年4月發表了該論文。
This algorithm maintains a large tree data structure in a well efficient manner. Tree construction and its growth are maintained in an increment fashion over the incoming data points by directing them to leaves while maintaining the quality via rotation operations. The choice of a rich tree data structure provides an efficient (logarithmic) search that can scale to large datasets along with multiple clustering that can be extracted at various resolutions. Such greedy incremental clustering procedures give rise to some errors which can be recovered using rotation operations.
該算法以高效的方式維護大型樹數據結構。 通過將傳入的數據點定向到葉子,并通過旋轉操作保持質量,以增量方式保持樹的構造及其生長。 豐富樹數據結構的選擇提供了一種有效的(對數)搜索,該搜索可以縮放到大型數據集,并且可以以各種分辨率提取多個聚類。 這種貪婪的增量聚類過程會引起一些錯誤,這些錯誤可以使用旋轉操作來恢復。
It is being claimed in [6] that this algorithm constructs a tree with the perfect dendrogram purity regardless of the number of data points and without the knowledge of the number of clusters. This is done by recursive rotation procedures. To achieve scalability, another type of rotation operation is also introduced in this research paper which encourages balance and an approximation that enables faster point insertions. This algorithm also possesses a leaf collapsing mode to cope with limited memory challenge i.e. when the dataset does not fit in the main memory (like data streams). In this mode, the algorithm expects another parameter which is an upper bound on the number of leaves in the cluster tree. Once the balance rotations are performed, the COLLAPSE procedure is invoked which merges leaves as necessary to meet the upper bound.
在[6]中要求保護的是,該算法構建的樹具有完美的樹狀圖純度,而與數據點的數量無關,并且不知道簇的數量。 這是通過遞歸循環過程完成的。 為了實現可伸縮性,本研究論文中還引入了另一種旋轉操作類型,該操作鼓勵平衡和近似實現更快的點插入。 該算法還具有葉子折疊模式以應對有限的存儲挑戰,即當數據集不適合主存儲時(如數據流)。 在這種模式下,算法需要另一個參數,該參數是群集樹中葉數的上限。 完成天平旋轉后,將調用COLLAPSE過程,該過程會根據需要合并葉子以達到上限。
In comparison with other online and multipass tree-building algorithms, perch has achieved the highest dendrogram purity in addition to being efficient. It is also competitive with all other scalable clustering algorithms. In comparison with both type of algorithms which uses the tree as a compact data structure or not, perch scales best with the number of clusters K. In comparison with BIRCH, which is based on top-down hierarchical clustering methods in which leaves of each internal node are represented by MEAN and VARIANCE statistics, and these node statistics are used to insert points greedily and there are no rotation operations performed, it has been proved that BIRCH constructs worst clustering as compared to its competitors. In comparison with Stream KM++, it shows that coreset construction is an expensive operation and it does not scale to the extreme clustering problem where K is very large.
與其他在線和多遍樹構建算法相比,鱸魚除效率高外,還獲得了最高的樹狀圖純度。 它與所有其他可伸縮群集算法相比也具有競爭力。 與使用樹作為緊湊數據結構或不使用樹作為緊湊數據結構的兩種算法相比,鱸魚的最佳擴展群集數為K。與BIRCH相比,BIRCH是基于自上而下的層次聚類方法,其中每個內部葉子節點由MEAN和VARIANCE統計信息表示,這些節點統計信息用于貪婪地插入點,并且不執行任何旋轉操作,已證明BIRCH與其競爭者相比構成最差的聚類。 與Stream KM ++相比,它表明核心集構建是一項昂貴的操作,并且無法擴展到K非常大的極端聚類問題。
PERCH algorithm has been applied on a variety of real-world datasets by writers of this research paper and it has proven as correct and efficient. [6]
本研究的作者將PERCH算法應用于各種現實數據集,并被證明是正確有效的。 [6]
4頻繁項集挖掘 (4 Frequent Itemset mining)
Frequent Itemset Mining refers to mine a pattern or item that appears frequently from a dataset. Formally, assume there exist a set I comprising of n distinct items {i1, i2, . . . , in}. A subset of it X, X?I is called a pattern. The source of data to be mined is transactions. If a pattern is a subset of a transaction denoted t, X?t, then it is said X occurs in t. A metric for Frequent Item Mining is called support. Support of a pattern is the number of how many transactions in which that pattern occurs. For a natural number min sup, given as a parameter, any pattern in which support is greater or equal to it is called a frequent pattern.
頻繁項集挖掘是指挖掘從數據集中頻繁出現的模式或項目。 形式上,假設存在一個集合I ,該集合I由n個不同的項{i 1 ,i 2 ,...組成。 。 。 ,in}中 。 X的子集X?I稱為模式。 要挖掘的數據源是交易。 如果模式是表示為t的事務的子集X?t ,則稱X出現在t中 。 頻繁項目挖掘的度量標準稱為支持 。 模式的支持是發生該模式的事務數量。 對于作為參數給出的自然數min sup ,任何支持大于或等于它的模式都稱為頻繁模式。
One of the most famous data structures for Frequent Itemset Mining is FP-Tree [7]. However, FP-Tree requires multiple scanning of item databases, something that is very costly for fast-moving data streams. An ideal algorithm should have a one-pass like property to function optimally.
頻繁項集挖掘最著名的數據結構之一是FP-Tree [7]。 但是,FP-Tree需要對項目數據庫進行多次掃描,這對于快速移動的數據流而言非常昂貴。 理想的算法應具有類似單次通過的屬性才能發揮最佳功能。
Common recurrent property in Data Stream Mining is the utilization of window models. According to Jin et al, there are three types of window model [8]
數據流挖掘中的常見重復屬性是窗口模型的利用。 根據Jin等人的說法,窗口模型有三種類型[8]
1. Landmark window In this window model, the focus is to find frequent itemsets from a starting time a to time point b. Consequently, if a is set to 1, then the Mining Algorithm will mine the entire data stream
1. 地標窗口在此窗口模型中,重點是查找從開始時間a到時間點b的頻繁項目集。 因此,如果將a設置為1,則挖掘算法將挖掘整個數據流
2. Sliding window From a time point b and given the length of the window a, the algorithm will mine item from time b ? a + 1 and b. In other words, it only considers item that enters our window stream at a time
2. 滑動窗口從時間點b開始并給定窗口a的長度,該算法將從時間b ? a + 1和b挖掘項目。 換句話說,它只是認為,在同一時間進入我們的窗口流項目
3. Damped window model In this model, we give more weight to newly arrived items. This can be done simply by assigning a decaying rate to the itemsets. 1, t]
3. 阻尼窗口模型在此模型中,我們將更多權重分配給新到達的物品。 只需將衰減率分配給項目集即可完成。 1,t]
4.1基于FP-Tree挖掘數據流中最大頻繁項集 (4.1 Mining Maximal Frequent Itemsets in Data Streams Based on FP- Tree)
This work [9] introduces a new algorithm FpMFI-DS, which is an improvement of FpMFI (frequent pattern tree for maximal frequent itemsets) [10] algorithm for the data stream. FpMFI itself is an algorithm to compress the FP-Tree and to check the superset pattern optimally.
這項工作[9]引入了一種新的算法FpMFI-DS,它是針對數據流的FpMFI(用于最大頻繁項集的頻繁模式樹) [10]算法的改進。 FpMFI本身是一種算法,用于壓縮FP-Tree并以最佳方式檢查超集模式。
FmpMFI-DS is designed to store the transactions in Landmark Window or Sliding Windows. The consequence of adapting Windows for mining is that the FP-Tree needs to be updated when the transaction is out of the window. This is done by tidlist a list of transactions’ ID and a pointer to the ultimate node of the transaction in the tree. Other important details of FpMFI-DS are due to the requirement of having a one-pass algorithm, instead of ordering items in FP-Tree with its frequency, it is done lexicographically.
FmpMFI-DS旨在將事務存儲在“地標窗口”或“滑動窗口”中。 使Windows適用于挖掘的結果是,當事務不在窗口中時,需要更新FP-Tree。 這是通過tidlist做交易ID列表和一個指向樹中的交易的最終節點。 FpMFI-DS的其他重要細節是由于需要使用一次遍歷算法,而不是按頻率順序對FP-Tree中的項目進行排序,而是按字典順序進行。
A further improvement of FpMFI-DS is the introduction of a new technique called ESEquivPS. In ESEquivPS. From an experiment by the authors, the size of the search space can be reduced by about 30%.
FpMFI-DS的進一步改進是引入了一種稱為ESEquivPS的新技術。 在ESEquivPS中。 根據作者的實驗,搜索空間的大小可以減少約30%。
4.2在事務數據庫和動態數據流中挖掘最大頻繁模式:一種基于火花的方法 (4.2 Mining maximal frequent patterns in transactional databases and dynamic data streams: A spark-based approach)
In this work [11], Karim et al describes how to build a tree-like structure to mine Maximal Frequent Pattern effectively. Maximal Frequent Patterns refers to patterns with a maximal number of items, that is: it should not have any superset patterns.
在這項工作中[11], Karim等人描述了如何構建樹狀結構來有效挖掘最大頻繁模式。 最大頻繁模式是指項目數量最多的模式,即:它不應具有任何超集模式。
For example, assume that in our transaction database, there are three patterns AB, BC, and ABD with the occurrences of 7, 5, and 3. If we decide that the minimum support is 2, all of them are frequent patterns. However, AB is not a maximal frequent pattern, since it is a subset of ABD which is a frequent pattern.
例如,假設在我們的交易數據庫中,存在三種模式AB,BC和ABD,它們的出現次數分別為7、5和3。如果我們確定最小支持為2,則它們都是頻繁模式。 但是,AB不是最大的頻繁模式,因為它是作為頻繁模式的ABD的子集。
The author utilized prime numbers for having faster computation and lower memory computation. The idea is that each distinct item from the database is represented as a distinct prime number. A transaction is represented as the multiplication of the prime number representing each item in that transaction which is called Transaction Value. From these formulations, there are few interesting properties.
作者利用質數來實現更快的計算和更低的內存計算。 這個想法是將數據庫中每個不同的項目都表示為一個不同的素數。 交易表示為代表該交易中每個項目的質數的乘積,稱為交易值。 根據這些公式,幾乎沒有有趣的特性。
1. A huge number of possible distinct items For a 32-bit integer, the biggest prime number is 105097565 thus theoretically we can represent around 100 million different items. However, the computation of Transaction Value may result in Integer Overflow, thus class like BigInteger is used.
1. 大量可能的不同項目對于32位整數,最大質數為105097565,因此從理論上講,我們可以表示大約1億個不同項目。 但是,交易值的計算可能會導致整數溢出,因此使用了BigInteger之類的類。
2. No two different transactions have the same Transaction Value. Since the Transaction Value is the product of prime numbers, it is trivial to show that every Transaction Value should be unique and bijective.
2. 沒有兩個不同的交易具有相同的交易價值 。 由于交易價值是素數的乘積,因此證明每個交易價值都應該是唯一的且是雙射的很簡單。
3. Greatest Common Divisor to denote common item If δ is the GCD of the Transaction Value of a transaction α and the Transaction Value of a transaction β, we can get the common items from those two transactions by factoring δ
3. 表示公共項目的最大公因數如果δ是交易的交易價值α的GCD和交易的交易價值β的GCD,我們可以通過分解δ來從這兩個交易中獲得公共項目。
With the Transaction Value of the transaction, a tree-like structure called ASP-tree is constructed. Inside this structure, the Transaction Value and its count is preserved. Furthermore, the tree contains the following invariants
利用交易的交易價值,構造了一個稱為ASP-tree的樹狀結構。 在此結構內部,保留了交易值及其計數。 此外,樹包含以下不變量
1. Every node α is a descendant direct or indirect of all nodes in which TV value is a multiple of TV of α.
1.每個節點α是TV值是α的TV的倍數的所有節點的直接或間接后代。
2. The count of each node is the total support of the transaction represented by its TV
2.每個節點的數量是其電視代表的交易的總支持
The authors also introduce the MFPAS algorithm to generate the Maximal Frequent Itemsets from the ASP-tree. The algorithm simply scans the tree bottom-up and do necessary pruning to get the relevant Transaction Value to be decoded to a real list of items. Interestingly, all information to get the frequent itemset are available on the tree without a need to scan the database.
作者還介紹了MFPAS算法,以從ASP樹生成最大頻繁項集。 該算法僅對樹進行自下而上的掃描,并進行必要的修剪,以獲取相關的交易值,以將其解碼為真實的項目列表。 有趣的是,獲取頻繁項集的所有信息都可以在樹上找到,而無需掃描數據庫。
The procedure is suitable for either Batch or Data Stream environment. The authors include a Spark Implementation for this procedure. It is also shown that the differences between Batch or Data Stream lie only on using correct Spark API i.e. use Spark Stream API when doing works on stream data, while the proposed algorithm remains intact.
該過程適用于批處理或數據流環境。 作者包括此過程的Spark實施。 還顯示了批處理或數據流之間的區別僅在于使用正確的Spark API,即在對流數據進行處理時使用Spark Stream API,而所提出的算法保持完整。
5匯總表 (5 Summary Table)

六,結論 (6 Conclusion)
In this report, we have conducted a survey of recent streaming data algorithms. Each algorithm is explained briefly along with key points and comparisons with other algorithms of the same class. In the end, we have presented a summary table with a crux of all the algorithms explained. We found out that recently introduced algorithms have solved the data problems (e.g. concept drift, data shredding, and sampling) and few of the main challenges (e.g. Memory limitation and data structure) which were considered as drawbacks of algorithms a few years back. As the wheel of advancement has no destination, we expect further evolution in data streams mining algorithms, opening research lines for further developments.
在此報告中,我們對最近的流數據算法進行了調查。 簡要說明了每種算法,以及要點和與同類的其他算法的比較。 最后,我們給出了一個匯總表,其中包含了所有已解釋算法的關鍵。 我們發現,最近推出的算法解決了數據問題(例如概念漂移,數據分解和采樣)以及少數主要挑戰(例如內存限制和數據結構),這些挑戰被視為幾年前算法的缺點。 由于前進的輪子沒有終點,我們希望數據流挖掘算法會進一步發展,為進一步的發展打開研究路線。
翻譯自: https://medium.com/swlh/data-streams-mining-c5012ff1b4c1
數據挖掘流程
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389613.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389613.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389613.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

北門外的小吃街才是我的大學食堂

786. 第 K 個最小的素數分數
![[LeetCode]最長公共前綴(Longest Common Prefix)](http://pic.xiahunao.cn/[LeetCode]最長公共前綴(Longest Common Prefix))
[LeetCode]最長公共前綴(Longest Common Prefix)

域嵌套太深_pyspark如何修改嵌套結構域


WIN10下ADB工具包安裝的教程和總結 --201809

1816. 截斷句子

spark的流失計算模型_使用spark對sparkify的流失預測

峰識別 峰面積計算 peak detection peak area 源代碼 下載

區塊鏈開發公司談區塊鏈與大數據的關系

Jupyter Notebook的15個技巧和竅門,可簡化您的編碼體驗

給定有權無向圖的鄰接矩陣如下,求其最小生成樹的總權重,代碼。

Ubuntu-16-04-編譯-Caffe-SSD

bi數據分析師_BI工程師和數據分析師的5個格式塔原則

BSOJ 2423 -- 【PA2014】Final Zarowki
)
WPF綁定資源文件錯誤(error in binding resource string with a view in wpf)


如何優化網站加載時間

VMWARE VCSA 6.5安裝過程
