熊貓數據集
Have you ever dealt with a dataset that required you to work with list values? If so, you will understand how painful this can be. If you have not, you better prepare for it.
您是否曾經處理過需要使用列表值的數據集? 如果是這樣,您將了解這會是多么痛苦。 如果沒有,則最好做好準備。
If you look closely, you will find that lists are everywhere! Here are some practical problems, where you will probably encounter list values.
如果仔細觀察,您會發現列表無處不在! 這是一些實際問題,您可能會在其中遇到列表值。
- Audio- or video tags 音頻或視頻標簽
- Open-ended questions in survey data 調查數據中的開放式問題
- Lists of all authors, artists, producers, etc. involved in a creative product 涉及創意產品的所有作者,藝術家,制作人等的列表
I have recently worked on multiple projects that required me to analyze this kind of data. After many painful hours of figuring out how to perform even the simplest operations, I realized had to share my knowledge here to save you some time.
我最近參與了多個項目,這些項目需要我分析此類數據。 經過數小時的辛苦工作,弄清楚如何執行最簡單的操作后,我意識到必須在這里分享我的知識,以節省您一些時間。
I will show you the kinds of problems you might encounter and offer practical solutions for them.
我將向您展示您可能遇到的各種問題,并為他們提供實用的解決方案。
快速準備 (Quick Preparation)
To follow this tutorial, feel free to download the fictional dataset used for all the examples. All materials including the code can be found in this repo.
要遵循本教程,請隨時下載用于所有示例的虛構數據集。 所有材料(包括代碼)都可以在此倉庫中找到。
Also, please import all the necessary libraries and load the dataframe.
另外,請導入所有必需的庫并加載數據框。
import pandas as pd
import numpy as np
import matplotlib as pltfruits = pd.read_csv("fruits.csv", delimiter = ";")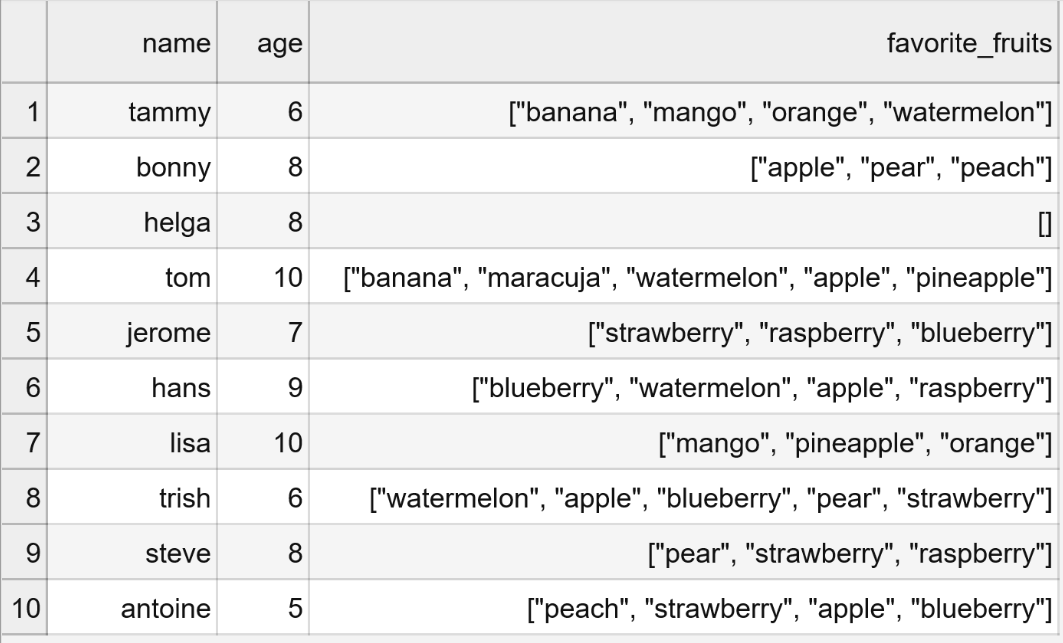
列表值到底有什么問題? (What Is Even Wrong with List Values?)
Allow me to get right to the point: List values mess up everything you know about data analysis. The simplest operations can not be performed without endless looping. Let me show you a quick example:
請允許我說清楚:列表值弄亂了您對數據分析的了解。 沒有無窮循環,就無法執行最簡單的操作。 讓我給你看一個簡單的例子:
For the “age” column in the example dataset, we can easily use the value_counts() function to count how many times which age was observed.
對于示例數據集中的“年齡”列,我們可以輕松地使用value_counts()函數來計算觀察到多少年齡。
fruits["age"].value_counts()## OUTPUT ##
8 3
10 2
6 2
9 1
7 1
5 1What if we want to find out which fruits were named the most? In principle, we have all the data we need for this in the “favorite_fruits” column. However, if we apply the same function, the results are less than unhelpful.
如果我們想找出哪種水果被命名最多,該怎么辦? 原則上,我們在“ favorite_fruits”列中擁有為此所需的所有數據。 但是,如果我們應用相同的功能,結果將無濟于事。
fruits["favorite_fruits"].value_counts()## OUTPUT ##
["strawberry", "raspberry", "blueberry"] 1
["mango", "pineapple", "orange"] 1
["blueberry", "watermelon", "apple", "raspberry"] 1
["apple", "pear", "peach"] 1
["pear", "strawberry", "raspberry"] 1
["banana", "maracuja", "watermelon", "apple", "pineapple"] 1
["peach", "strawberry", "apple", "blueberry"] 1
[] 1
["banana", "mango", "orange", "watermelon"] 1
["watermelon", "apple", "blueberry", "pear", "strawberry"] 1The reason this does not work is that Pandas does not have direct access to every individual element of the lists. Thus, Pandas is unable to apply functions like value_counts() properly. So, what do we do instead? I will show you in the following!
這樣做不起作用的原因是,熊貓無法直接訪問列表中的每個單獨元素。 因此,Pandas無法正確應用諸如value_counts()之類的功能。 那么,我們該怎么做呢? 我將在下面向您展示!
問題1:我的列表存儲為字符串 (Problem 1: My Lists are Stored as Strings)
One problem you will always encounter is that Pandas will read your lists as strings, not as lists.
您將永遠遇到的一個問題是,熊貓將以字符串而不是列表的形式讀取列表。
for i, l in enumerate(fruits["favorite_fruits"]):
print("list",i,"is",type(l))## OUTPUT ##
list 0 is <class 'str'>
list 1 is <class 'str'>
list 2 is <class 'str'>
list 3 is <class 'str'>
list 4 is <class 'str'>
list 5 is <class 'str'>
list 6 is <class 'str'>
list 7 is <class 'str'>
list 8 is <class 'str'>
list 9 is <class 'str'>This means that you can not even loop through the lists to count unique values or frequencies. Depending on how your lists are formatted in the dataframe, there is an easy or a more complex solution. In any case, you will simply be able to use the code I provide.
這意味著您甚至無法遍歷列表來計算唯一值或頻率。 根據數據框中列表的格式,有一個簡單或更復雜的解決方案。 無論如何,您都可以使用我提供的代碼。
您的字符串看起來像這樣:“ ['草莓','蘋果','橙色']”嗎? (Do your strings look like this: “[‘strawberry’, ‘apple’, ‘orange’]”?)
In that case, there is a quick method using the apply() and eval() functions.
在這種情況下,有一種使用apply()和eval()函數的快速方法。
fruits["favorite_fruits"] = fruits["favorite_fruits"].apply(eval)您的字符串看起來像這樣:“ [草莓,蘋果,橙子]”嗎? (Do your strings look like this: “[strawberry, apple, orange]”?)
This one is tougher, because the eval() function will not work, as the list is lacking the inner quotation marks in order for it to be recognized as a list object. The quick and dirty solution is to simply add the quotation marks to the string and apply eval() afterwards. Use this function:
這一點比較困難,因為eval()函數將不起作用,因為列表缺少內部引號以便將其識別為列表對象。 快速而骯臟的解決方案是簡單地在字符串中添加引號,然后再應用eval() 。 使用此功能:
def clean_alt_list(list_):
list_ = list_.replace(', ', '","')
list_ = list_.replace('[', '["')
list_ = list_.replace(']', '"]')
return list_To apply this to your dataframe, use this pseudo code:
要將其應用于您的數據框,請使用以下偽代碼:
df[col] = df[col].apply(clean_alt_list)Note that in both cases, Pandas will still assign the series an “O” datatype, which is typically used for strings. But do not let this confuse you. You can check the actual datatype using:
請注意,在兩種情況下,Pandas仍將為系列分配“ O”數據類型,該數據類型通常用于字符串。 但是,不要讓這讓您感到困惑。 您可以使用以下方法檢查實際的數據類型:
for i, l in enumerate(fruits[“favorite_fruits”]):
print(“list”,i,”is”,type(l))## OUTPUT ##
list 0 is <class 'list'>
list 1 is <class 'list'>
list 2 is <class 'list'>
list 3 is <class 'list'>
list 4 is <class 'list'>
list 5 is <class 'list'>
list 6 is <class 'list'>
list 7 is <class 'list'>
list 8 is <class 'list'>
list 9 is <class 'list'>問題2:獲取唯一值或值計數 (Problem 2: Getting Unique Values or Value Counts)
After this first step, our lists are finally recognized as such by Pandas. Still, we can not use the standard functions, because they are not made for list applications.
邁出第一步之后,熊貓終于承認了我們的名單。 但是,我們仍然不能使用標準功能,因為它們不是為列表應用程序而設計的。
At least we could use loops for everything now. This method works with small datasets, but can get awfully slow with large ones. For example, I had to analyze taglists of up to 999 tags for around 500k music tracks. This means, that the inner loop would have had hundreds of millions of iterations, which would have taken many hours and probably crashed my computer. I will show you a cleaner and quicker way to do this in a minute. However, if you really want to use loops, here is the code:
至少我們現在可以對所有內容使用循環。 此方法適用于小型數據集,但適用于大型數據集會變得非常慢。 例如,我不得不分析多達500個音樂曲目的多達999個標簽的標簽列表。 這意味著,內部循環將進行數億次迭代,這將花費許多小時,并且可能使我的計算機崩潰。 我將在一分鐘內為您展示一種更清潔,更快捷的方法。 但是,如果您真的想使用循環,請使用以下代碼:
fruit_dict = {}
for i in fruits["favorite_fruits"]:
for j in j:
if j not in fruit_dict:
fruit_dict[j] = 1
else:
fruit_dict[j] += 1Here is the clean way that took me a while to figure out. If we conceptualize the favorite_fruits column as a 2D array, reducing its dimensions from 2 to 1 would allow us to apply the typical pandas functions again. For that, you can use this function:
這是我花了一段時間才弄清楚的干凈方法。 如果將favourite_fruits列概念化為2D數組,則將其尺寸從2減小到1將允許我們再次應用典型的pandas函數。 為此,您可以使用以下功能:
def to_1D(series):
return pd.Series([x for _list in series for x in _list])If we use value_counts() now, we get the results we want.
如果現在使用value_counts() ,我們將獲得所需的結果。
to_1D(fruits[“favorite_fruits”]).value_counts()## OUTPUT ##
apple 5
blueberry 4
watermelon 4
strawberry 4
raspberry 3
pear 3
banana 2
pineapple 2
mango 2
peach 2
orange 2
maracuja 1To get unique values, just extract them from the results above chaining .index() onto it.
要獲取唯一值,只需將.index()鏈接到上面的結果中即可將它們提取出來。
At this point, we can produce our first meaningful visualization.
在這一點上,我們可以產生第一個有意義的可視化。
fig, ax = plt.subplots(figsize = (14,4))
ax.bar(to_1D(fruits["favorite_fruits"]).value_counts().index,
to_1D(fruits["favorite_fruits"]).value_counts().values)
ax.set_ylabel("Frequency", size = 12)
ax.set_title("Children's Favorite Fruits", size = 14)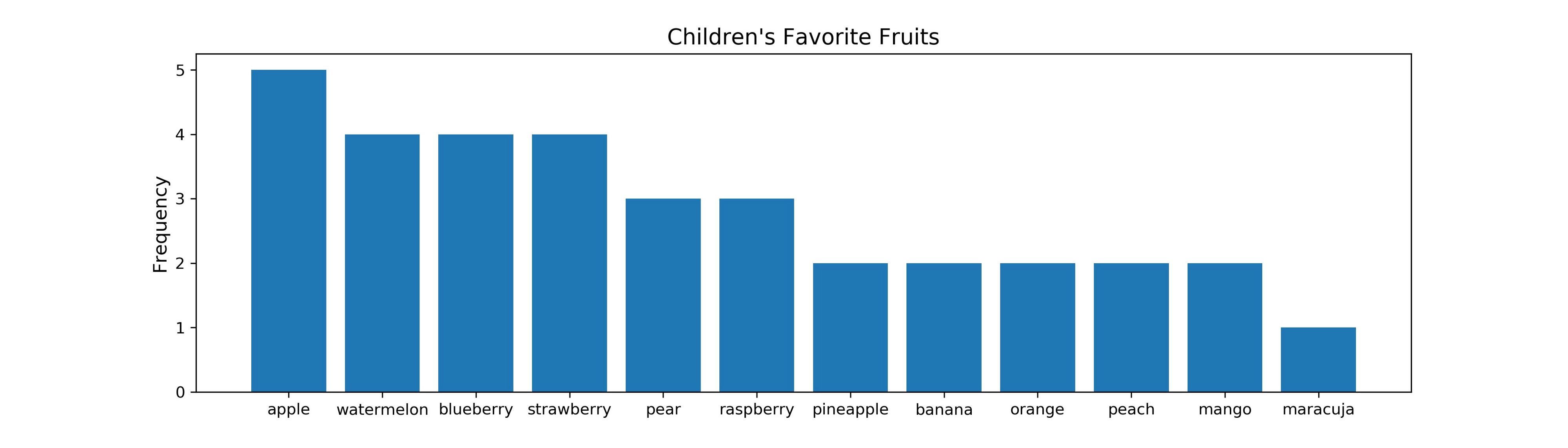
問題3:所有唯一值的單獨列 (Problem 3: Individual Columns for All Unique Values)
At this point, things are getting advanced. If you are happy with the results we got before, you can stop here. However, a deeper level of analysis might be required for your research goal. Maybe you want to correlate all list elements with each other to compute similarity scores. E.g. do kids who eat bananas typically also like mangos? Or maybe you want to find out which fruit has been ranked as the top favorite fruit by the most kids. These questions can only be answered at a deeper level of analysis.
在這一點上,事情正在發展。 如果您對我們之前獲得的結果感到滿意,可以在這里停止。 但是,您的研究目標可能需要更深層次的分析。 也許您想將所有列表元素相互關聯以計算相似性得分。 例如,吃香蕉的孩子通常也喜歡芒果嗎? 或者,也許您想找出哪種水果被大多數孩子評為最喜歡的水果。 這些問題只能在更深層次的分析中得到回答。
For this, I will introduce two useful methods. They differ in complexity, but also in what you can do with their results.
為此,我將介紹兩種有用的方法。 它們的復雜性不同,但是您可以如何處理它們的結果。
方法1 (Method 1)
This is a shockingly easy and fast method I stumbled upon. And it is so useful! All you need is one line of code.
這是我偶然發現的一種非常簡單快捷的方法。 它是如此有用! 您只需要一行代碼。
fruits_expanded_v1 = fruits["favorite_fruits"].apply(pd.Series)
As you can see, this one-liner produced a dataframe where every list is split into its single elements. The columns indicate the order, in which the fruit was placed in the list. With this method, you will always get a dataframe with a shape of (n, len(longest_list)). In this case, two of the 10 children named five favorite fruits, which results a 10x5 dataframe.
如您所見,這種單行代碼產生了一個數據框,其中每個列表都被拆分為單個元素。 列指示將水果放置在列表中的順序。 使用此方法,您將始終獲得形狀為(n,len(longest_list))的數據框。 在這種情況下,10個孩子中的2個命名了5個最喜歡的水果,其結果為10x5數據幀。
Using this, we can find out which fruit was named most often as the number one favorite fruit.
使用此工具,我們可以找出哪種水果最常被稱為最喜歡的水果之一。
fruits_expanded_v1.iloc[:,0].value_counts(normalize = True)## OUTPUT ##
banana 0.222222 pear 0.111111 watermelon 0.111111 blueberry 0.111111 strawberry 0.111111 apple 0.111111 peach 0.111111 mango 0.111111We can see that bananas are most often kids’ absolute favorite fruit.
我們可以看到香蕉是孩子們最喜歡的水果。
Alternatively, we could target single fruits and find out how many times they were named at each position of the lists. This is the function I wrote for that:
或者,我們可以定位單個水果,并找出它們在列表的每個位置被命名了多少次。 這是我為此編寫的功能:
def get_rankings(item, df):
# Empty dict for results
item_count_dict = {}
# For every tag in df
for i in range(df.shape[1]):
# Calculate % of cases that tagged the item
val_counts = df.iloc[:,i].value_counts(normalize = True)
if item in val_counts.index:
item_counts = val_counts[item]
else:
item_counts = 0
# Add score to dict
item_count_dict["tag_{}".format(i)] = item_counts
return item_count_dictIf we apply it, we get:
如果我們應用它,我們將得到:
get_rankings(item = "apple", df = fruits_expanded_v1)## OUTPUT ##
{'tag_0': 0.1111111111111111, 'tag_1': 0.1111111111111111, 'tag_2': 0.2222222222222222, 'tag_3': 0.2, 'tag_4': 0}As you can see, we can perform rank-based analyses very well with this approach. However, this method is near useless for other approaches. Because the columns do not represent a single tag, but a rank, most tag-based operations can not be done properly. For example, calculating the correlation between bananas and peaches is not possible with the dataframe we got from method 1. If that is your research goal, use the next method.
如您所見,我們可以使用這種方法很好地執行基于排名的分析。 但是,該方法對于其他方法幾乎沒有用。 由于這些列不代表單個標簽,而是一個等級,因此大多數基于標簽的操作無法正確完成。 例如,使用我們從方法1獲得的數據框,不可能計算香蕉和桃子之間的相關性。如果這是您的研究目標,請使用下一種方法。
方法2 (Method 2)
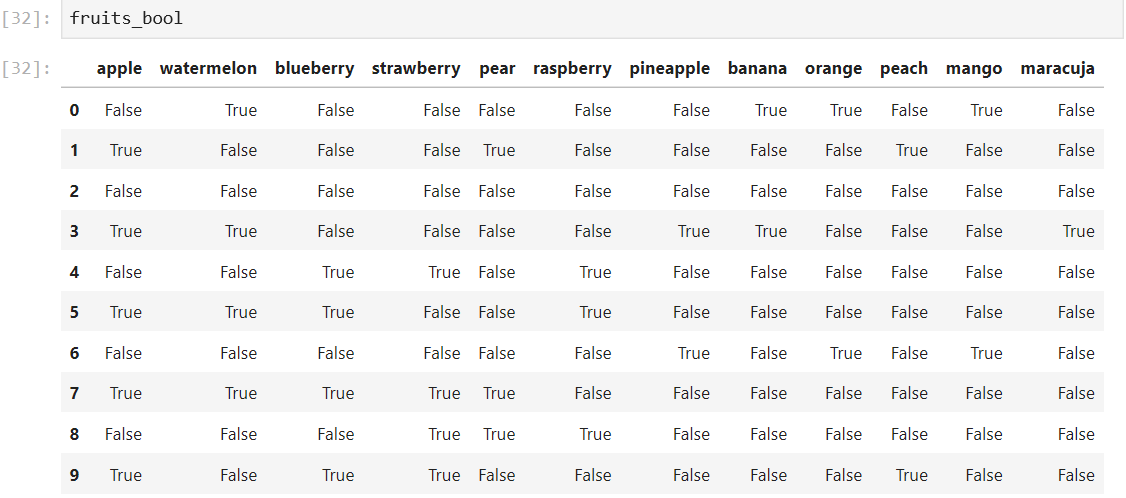
This method is more complex and requires more resources. The idea is that we create a dataframe where rows stay the same as before, but where every fruit is assigned its own column. If only kid #2 named bananas, the banana column would have a “True” value at row 2 and “False” values everywhere else (see Figure 6). I wrote a function that will perform this operation. It relies on looping, which means that it will take lots of time with large datasets. However, out of all the methods I tried, this was the most efficient way to do it.
此方法更復雜,并且需要更多資源。 我們的想法是,我們創建一個數據框,其中的行與以前相同,但是每個水果都被分配了自己的列。 如果只有#2孩子命名為香蕉,那么香蕉列的第2行將具有“ True”值,而其他所有地方將具有“ False”值(參見圖6)。 我寫了一個函數來執行此操作。 它依賴于循環,這意味著大型數據集將花費大量時間。 但是,在我嘗試過的所有方法中,這是最有效的方法。
def boolean_df(item_lists, unique_items):# Create empty dict
bool_dict = {}
# Loop through all the tags
for i, item in enumerate(unique_items):
# Apply boolean mask
bool_dict[item] = item_lists.apply(lambda x: item in x)
# Return the results as a dataframe
return pd.DataFrame(bool_dict)If we now apply the function
如果我們現在應用該功能
fruits_bool = boolean_df(fruits[“favorite_fruits”], unique_items.keys())we get this dataframe:
我們得到以下數據框:
From here, we can easily calculate correlations. Note that “correlation” is not really the correct term, because we are not using metric or ordinal, but binary data. If you want to be correct, use “association”. I will not.
從這里,我們可以輕松地計算相關性。 請注意,“相關性”并不是真正正確的術語,因為我們不是在使用度量或序數,而是二進制數據。 如果您想正確,請使用“關聯”。 我不會。
Again, there are multiple ways to correlate the fruits. One straight forward way is the Pearson correlation coefficient, which can also be used for binary data. Pandas has a built-int function for this.
同樣,有多種關聯水果的方法。 一種直接的方法是皮爾遜相關系數,該系數也可用于二進制數據。 熊貓為此提供了內置功能。
fruits_corr = fruits_bool.corr(method = "pearson")
Another way is to simply count how many times a fruit was named alongside all other fruits. This can be solved using matrix multiplication. For this, we will need to convert the boolean dataframe to an integer based on first.
另一種方法是簡單地計算一個水果與所有其他水果一起命名的次數。 這可以使用矩陣乘法來解決。 為此,我們將需要基于first將布爾數據幀轉換為整數。
fruits_int = fruits_bool.astype(int)Then, we can calculate the frequencies.
然后,我們可以計算頻率。
fruits_freq_mat = np.dot(fruits_int.T, fruits_int)## OUTPUT ##array([[5, 3, 3, 2, 2, 1, 1, 1, 0, 2, 0, 1],
[3, 4, 2, 1, 1, 1, 1, 2, 1, 0, 1, 1],
[3, 2, 4, 3, 1, 2, 0, 0, 0, 1, 0, 0],
[2, 1, 3, 4, 2, 2, 0, 0, 0, 1, 0, 0],
[2, 1, 1, 2, 3, 1, 0, 0, 0, 1, 0, 0],
[1, 1, 2, 2, 1, 3, 0, 0, 0, 0, 0, 0],
[1, 1, 0, 0, 0, 0, 2, 1, 1, 0, 1, 1],
[1, 2, 0, 0, 0, 0, 1, 2, 1, 0, 1, 1],
[0, 1, 0, 0, 0, 0, 1, 1, 2, 0, 2, 0],
[2, 0, 1, 1, 1, 0, 0, 0, 0, 2, 0, 0],
[0, 1, 0, 0, 0, 0, 1, 1, 2, 0, 2, 0],
[1, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1]])All we need to do now is add labels and transform it back to a dataframe.
現在我們要做的就是添加標簽并將其轉換回數據框。
fruits_freq = pd.DataFrame(fruits_freq_mat, columns = unique_items.keys(), index = unique_items.keys())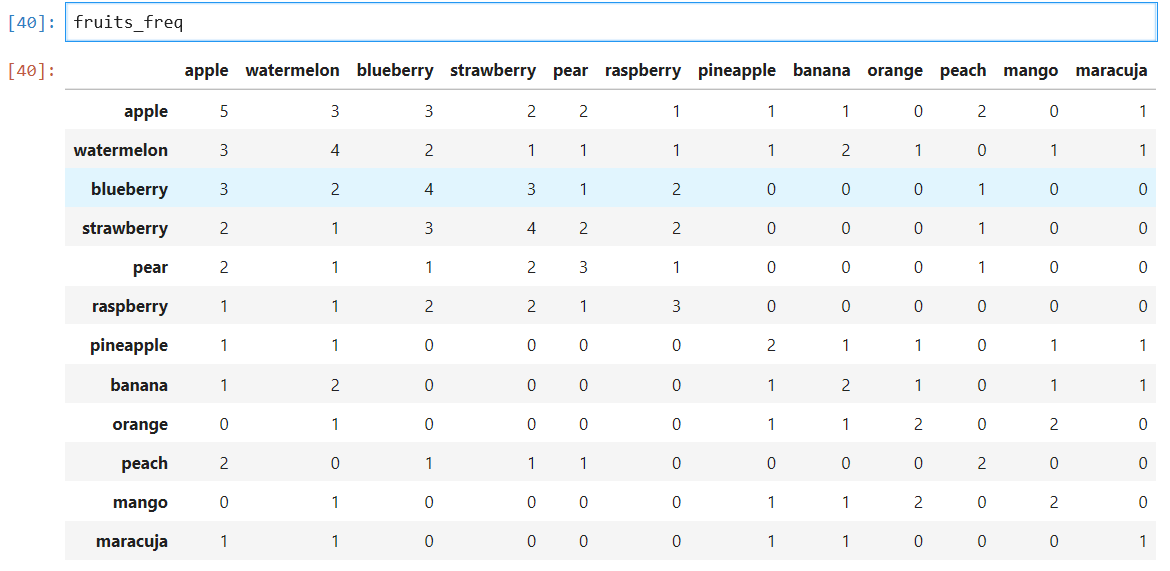
If you are looking for a nice visualization, you can create a heatmap with the seaborn library.
如果您正在尋找不錯的可視化效果,則可以使用seaborn庫創建一個熱圖。
import seaborn as snfig, ax = plt.subplots(figsize = (9,5))
sn.heatmap(fruits_freq, cmap = "Blues")
plt.xticks(rotation=50)
plt.savefig("heatmap.png", dpi = 300)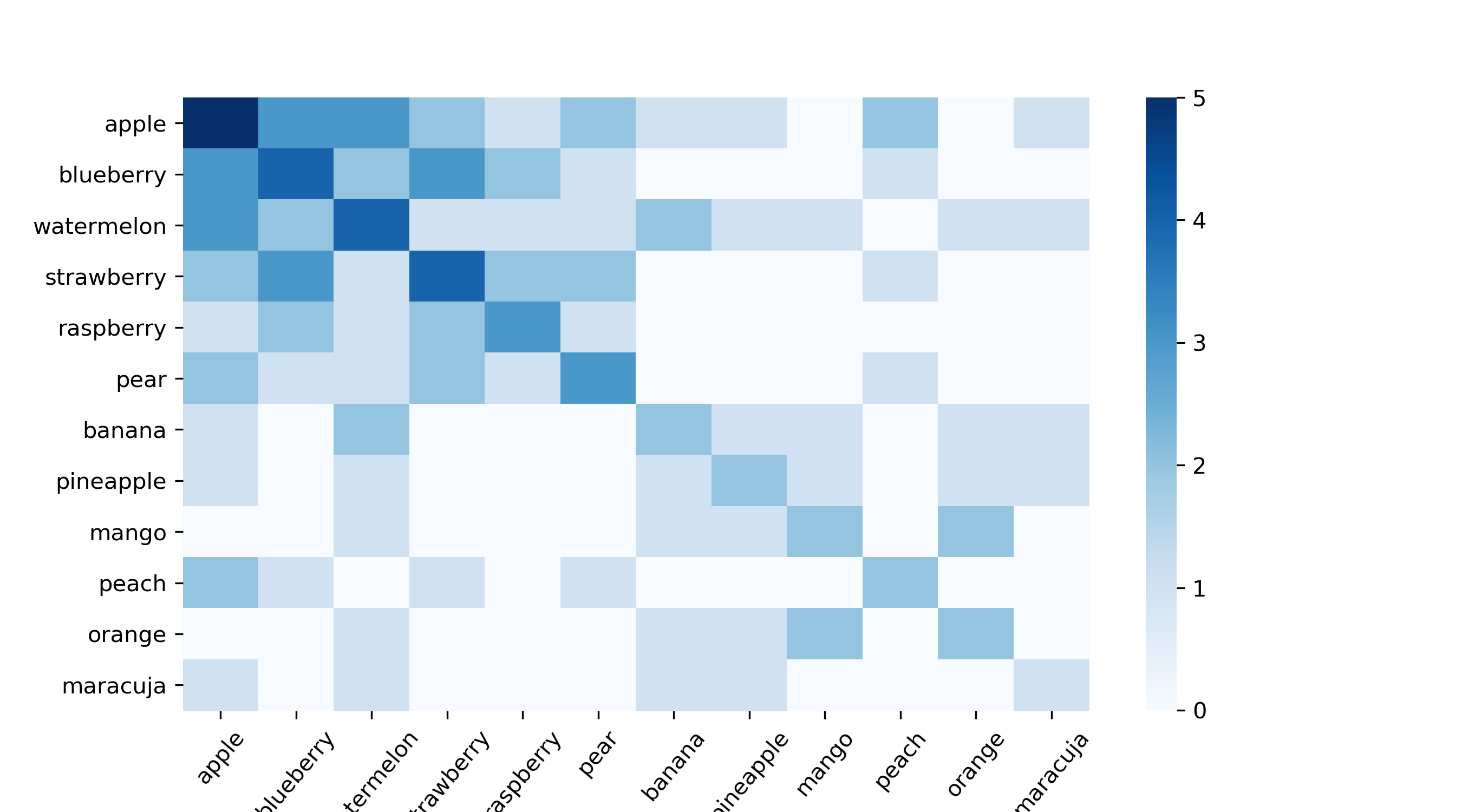
With the Pearson matrix, we can easily build a fruit recommender system. For example, if you input that you like bananas, it will recommend you a maracuja, because those two have the highest correlation (0.67). You will be surprised by how powerful this simple approach is. I have used it successfully multiple times. If you want to do something like this with the frequency dataframe, you need to normalize the data first. However, that is a topic for another post.
借助Pearson矩陣,我們可以輕松構建水果推薦系統。 例如,如果您輸入您喜歡香蕉,它將推薦您使用“ maracuja”,因為這兩者具有最高的相關性(0.67)。 您會驚訝于這種簡單方法的強大功能。 我已經成功使用了多次。 如果要對頻率數據幀執行類似的操作,則需要首先對數據進行規范化。 但是,這是另一篇文章的主題。
I hope this guide was useful to you and saved you some time or inspired you. Thank you all for reading!
希望本指南對您有所幫助,并節省您一些時間或啟發您。 謝謝大家的閱讀!
翻譯自: https://towardsdatascience.com/dealing-with-list-values-in-pandas-dataframes-a177e534f173
熊貓數據集
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389593.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389593.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389593.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

聊聊jdk http的HeaderFilter
旋轉矩陣)
旋轉變換(一)旋轉矩陣

數據預處理 泰坦尼克號_了解泰坦尼克號數據集的數據預處理

Pytorch中DNN入門思想及實現

IDEA去除mapper.xml文件中的sql語句的背景色

vc6.0 繪制散點圖_vc有關散點圖的一切

sudo配置臨時取得root權限

Pytorch中RNN入門思想及實現

小扎不哭!FB又陷數據泄露風波,9000萬用戶受影響

在衡量歐洲的政治意識形態時,調查規模的微小變化可能會很重要

Pytorch中CNN入門思想及實現

java常用設計模式一:單例模式

SDUT-2121_數據結構實驗之鏈表六:有序鏈表的建立

事件映射 消息映射_映射幻影收費站


Pytorch中BN層入門思想及實現

JDK源碼學習筆記——TreeMap及紅黑樹

匿名內部類和匿名類_匿名schanonymous

Pytorch框架中SGD&Adam優化器以及BP反向傳播入門思想及實現
