RNN循環神經網絡
整體思想:
將整個序列劃分成多個時間步,將每一個時間步的信息依次輸入模型,同時將模型輸出的結果傳給下一個時間步,也就是說后面的結果受前面輸入的影響。

RNN的實現公式:
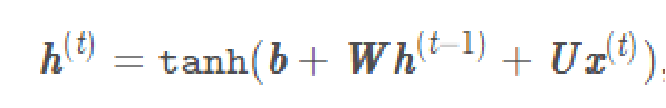

個人思路:
首先設置一個初始權重h(一般情況下設置為全0矩陣),將h(0)與權重W相乘在加上輸入X(0)與權重U相乘再加上偏差值b(本文設為0)的和通過tanh這個激活函數后的結果為第二層的h(1),依次類推。各層h(除了h(0)和最后一個輸出的h(n)以外)組成的向量既為輸出結果,h(n)為預測隱含層結果。
Pytorch模型下RNN代碼實現:
import torch
import torch.nn as nn
import numpy as np"""
實現簡單的神經網絡
使用pytorch實現RNN
不考慮偏差值
"""
class TorchRNN(nn.Module):def __init__(self, input_size, hidden_size):super(TorchRNN, self).__init__()self.layer = nn.RNN(input_size, hidden_size, bias=False, batch_first=True)def forward(self, x):return self.layer(x)x = np.array([[1, 2, 3], [3, 4, 5], [5, 6, 7]]) #網絡輸入#torch實驗
hidden_size = 4 #隱單元是4維 1×4矩陣
torch_model = TorchRNN(3, hidden_size) #輸入是3維,因此輸出應為3×4矩陣
#print(len(torch_model.state_dict()))
w_ih = torch_model.state_dict()["layer.weight_ih_l0"] #獲得隨機初始化的權重U
w_hh = torch_model.state_dict()["layer.weight_hh_l0"] #獲得隨機初始化的權重Wtorch_x = torch.FloatTensor([x])
output, h = torch_model.forward(torch_x)
print(output.detach().numpy(), "torch模型預測結果")
#這里的輸出第一行是第一個輸入值之后得到的h,以此類推
#print(h.detach().numpy(), "torch模型預測隱含層結果")
#預測隱含層結果就是最后一個輸入值得到的h
在自定義模型中的RNN的代碼實現:
"""
手動實現簡單的神經網絡
手動實現RNN
需要將該代碼放入pytorch模型中才能運行
對比理解過程
"""
#自定義RNN模型
class DiyModel:def __init__(self, w_ih, w_hh, hidden_size):self.w_ih = w_ihself.w_hh = w_hhself.hidden_size = hidden_sizedef forward(self, x):ht = np.zeros((self.hidden_size)) #初始化h為全0矩陣output = []for xt in x:ux = np.dot(self.w_ih, xt) #函數實現wh = np.dot(self.w_hh, ht) #函數實現ht_next = np.tanh(ux + wh) #函數實現output.append(ht_next) #放入output列表中ht = ht_next #h向下更新return np.array(output), htdiy_model = DiyModel(w_ih, w_hh, hidden_size)
output, h = diy_model.forward(x)
print(output, "diy模型預測結果")
# print(h, "diy模型預測隱含層結果")
因為自定義模型中需要得到跟pytorch模型中的輸入和隨機初始化的W和,如果需要運行需將自定義模型代碼放在pytorch模型的下面運行。同樣不考慮偏差值。
結果如下:

可以看到兩者運行結果相同,說明運算邏輯沒有問題。














方法源碼解析(二))
)

python在anaconda安裝opencv庫及skimage庫(scikit_image庫)諸多問題解決辦法)

