mongdb 群集
This is a part 2 of the series analyzing healthcare chart notes using Natural Language Processing (NLP)
這是使用自然語言處理(NLP)分析醫療保健圖表筆記的系列文章的第2部分。
In the first part, we talked about cleaning the text and extracting sections of the chart notes which might be useful for further annotation by analysts. Hence, reducing their time in manually going through the entire chart note if they are only looking for “allergies” or “social history”.
在第一部分中 ,我們討論了清理文本和提取圖表注釋的各個部分,這可能有助于分析師進一步注釋。 因此,如果他們只是在尋找“過敏”或“社會病史”,則可以減少他們手動查看整個圖表筆記的時間。
NLP任務: (NLP Tasks:)
Pre-processing and Cleaning
預處理和清潔
Text Summarization — We are here
文字摘要-我們在這里
Topic Modeling using Latent Dirichlet allocation (LDA)
使用潛在Dirichlet分配(LDA)進行主題建模
Clustering
聚類
If you want to try the entire code yourself or follow along, go to my published jupyter notebook on GitHub: https://github.com/gaurikatyagi/Natural-Language-Processing/blob/master/Introdution%20to%20NLP-Clustering%20Text.ipynb
如果您想親自嘗試或遵循整個代碼,請轉至我在GitHub上發布的jupyter筆記本: https : //github.com/gaurikatyagi/Natural-Language-Processing/blob/master/Introdution%20to%20NLP-Clustering% 20Text.ipynb
數據: (DATA:)
Source: https://mimic.physionet.org/about/mimic/
資料來源: https : //mimic.physionet.org/about/mimic/
Doctors take notes on their computer and 80% of what they capture is not structured. That makes the processing of information even more difficult. Let’s not forget, interpretation of healthcare jargon is not an easy task either. It requires a lot of context for interpretation. Let’s see what we have:
醫生會在計算機上做筆記,而所捕獲的內容中有80%都是沒有結構的。 這使得信息處理更加困難。 別忘了,對醫療術語的解釋也不是一件容易的事。 它需要很多上下文來進行解釋。 讓我們看看我們有什么:
文字摘要 (Text Summarization)
Spacy isn’t great at identifying the “Named Entity Recognition” of healthcare documents. See below:
Spacy不能很好地識別醫療文檔的“命名實體識別”。 見下文:
doc = nlp(notes_data["TEXT"][178])
text_label_df = pd.DataFrame({"label":[ent.label_ for ent in doc.ents],
"text": [ent.text for ent in doc.ents]
})
display(HTML(text_label_df.head(10).to_html()))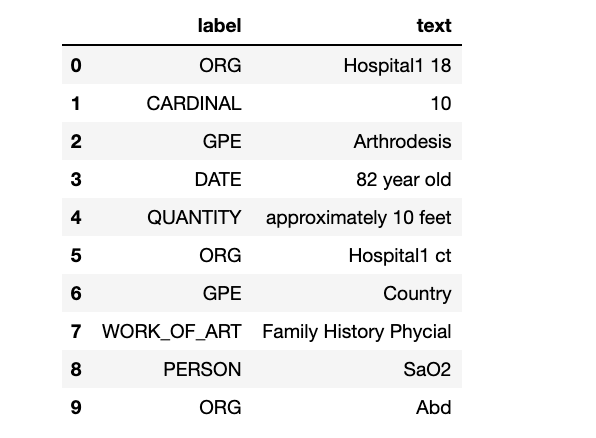
But, that does not mean it can not be used to summarize our text. It is still great at identifying the dependency in the texts using “Parts of Speech tagging”. Let’s see:
但是,這并不意味著它不能用來總結我們的文字。 在使用“詞性標簽”來識別文本中的依存關系方面仍然很棒。 讓我們來看看:
# Process the text
doc = nlp(notes_data["TEXT"][174][:100])
print(notes_data["TEXT"][174][:100], "\n")
# Iterate over the tokens in the doc
for token in doc:
if not (token.pos_ == 'DET' or token.pos_ == 'PUNCT' or token.pos_ == 'SPACE' or 'CONJ' in token.pos_):
print(token.text, token.pos_)
print("lemma:", token.lemma_)
print("dependency:", token.dep_, "- ", token.head.orth_)
print("prefix:", token.prefix_)
print("suffix:", token.suffix_)
So, we can summarize the text; based on the dependency tracking. YAYYYYY!!!
因此,我們可以總結文本; 基于依賴項跟蹤。 耶!
Here are the results for the summary! (btw, I tried zooming out my jupyter notebook to show you the text difference, but still failed to capture the chart notes in its entirety. I’ll paste these separately as well or you can check my output on the Github page(mentioned at the top).
這是摘要的結果! (順便說一句,我嘗試將jupyter筆記本放大以顯示文本差異,但仍然無法完整捕獲圖表注釋。我也將它們分別粘貼,或者您可以在Github頁面上檢查我的輸出(頂端)。

Isn’t it great how we could get the gist of the entire document into concise and crisp phrases? These summaries will be used in topic modeling (in section 3) and the clustering of documents in section 4.
我們怎樣才能使整個文檔的要旨簡明扼要,這不是很好嗎? 這些摘要將用于主題建模(第3節)和第4節中的文檔聚類。
翻譯自: https://towardsdatascience.com/text-summarization-for-clustering-documents-2e074da6437a
mongdb 群集
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389499.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389499.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389499.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

keras框架實現手寫數字識別

gdal進行遙感影像讀寫_如何使用遙感影像進行礦物勘探

從零開始神經網絡:keras框架實現數字圖像識別詳解!


推薦算法的先驗算法的連接_數據挖掘專注于先驗算法

Android 頁面多狀態布局管理

Tensorflow入門神經網絡代碼框架

手把手教你把代碼丟入github 中

時間序列模式識別_空氣質量傳感器數據的時間序列模式識別

oracle 性能優化 07_診斷事件

Tensorflow框架:卷積神經網絡實戰--Cifar訓練集

計算機科學速成課36:自然語言處理

linux內存初始化初期內存分配器——memblock

數據科學學習心得_學習數據科學

Keras框架:Alexnet網絡代碼實現


微軟Azure CDN現已普遍可用

數據科學生命周期_數據科學項目生命周期第1部分

