推薦算法的先驗算法的連接
So here we are diving into the world of data mining this time, let’s begin with a small but informative definition;
因此,這一次我們將進入數據挖掘的世界,讓我們從一個小的但內容豐富的定義開始;
什么是數據挖掘? (What is data mining ?!)
It’s technically a profound dive into datasets searching for some correlations, rules, anomaly detection and the list goes on. It’s a way to do some simple but effective machine learning instead of doing it the hard way like using regular neural networks or the ultimate complex version that is convolutions and recurrent neural networks (we will definitely go through that thoroughly in future articles).
從技術上講,這是對數據集的深入研究,以尋找一些相關性,規則,異常檢測,并且列表還在繼續。 這是一種進行簡單但有效的機器學習的方法,而不是像使用常規神經網絡或卷積和遞歸神經網絡這樣的終極復雜版本那樣艱苦的方法來完成它(我們肯定會在以后的文章中全面介紹)。
Data mining algorithms vary from one to another, each one has it’s own privileges and disadvantages, i will not go through that in this article but the first one you should focus on must be the classical Apriori Algorithm as it is the opening gate to the data mining world.
數據挖掘算法因人而異,每種算法都有其自身的特權和劣勢,在本文中我不會進行介紹,但是您應該關注的第一個算法必須是經典的Apriori算法,因為它是數據的門戶采礦世界。
But before going any further, there’s some special data mining vocabulary that we need to get familiar with :
但是在進一步介紹之前,我們需要熟悉一些特殊的數據挖掘詞匯:
k-Itemsets : an itemset is just a set of items, the k refers to it’s order/length which means the number of items contained in the itemset.
k-Itemsets:一個項目集只是一組項目, k表示它的順序/長度,這意味著該項目集中包含的項目數。
Transaction : it is a captured data, can refer to purchased items in a store. Note that Apriori algorithm operates on datasets containing thousands or even millions of transactions.
交易:它是捕獲的數據,可以參考商店中購買的物品。 請注意,Apriori算法對包含數千甚至數百萬個事務的數據集進行操作。
Association rule : an antecedent → consequent relationship between two itemsets :
關聯規則:兩個項目集之間的前→后關系:
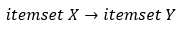
Implies the presence of the itemset Y (consequent) in the considered transaction given the itemset X (antecedent).
在給定項目集X(先行者)的情況下,表示在考慮的事務中存在項目集Y(因此)。
Support : represents the popularity/frequency of an itemset, calculated this way :
支持:表示項目集的受歡迎程度/頻率,通過以下方式計算:
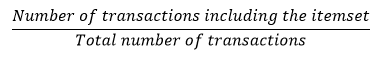
Confidence ( X → Y ) : shows how much a rule is confident/true, in other words the likelihood of having the consequent itemset in a transaction, calculated this way :
置信度(X→Y):顯示一條規則置信度/真實度的多少,換句話說,在交易中擁有后續項集的可能性,計算方式為:
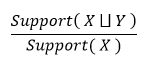
A rule is called a strong rule if its confidence is equal to 1.
如果規則的置信度等于1,則稱為強規則 。
Lift ( X → Y ) : A measure of performance, indicates the quality of an association rule :
提升(X→Y):一種性能度量,表示關聯規則的質量:

MinSup : a user-specified variable which stands for the minimum support threshold for itemsets.
MinSup:用戶指定的變量 代表項目集的最低支持閾值。
MinConf : a user-specified variable which stands for the minimum confidence threshold for rules.
MinConf:用戶指定的變量,代表規則的最小置信度閾值。
Frequent itemset : whose support is equal or higher than the chosen minsup.
頻繁項目集:支持等于或大于選擇的minsup 。
Infrequent itemset : whose support is less than the chosen minsup.
不 頻繁項目 集:其支持小于所選的minsup 。
那么... Apriori如何工作? (So…how does Apriori work ?)
Starting with a historical glimpse, the algorithm was first proposed by the computer scientists Agrawal and Srikant in 1994, it proceeds this way :
從歷史的一瞥開始,該算法由計算機科學家Agrawal和Srikant于1994年首次提出,它以這種方式進行:
Generates possible combinations of k-itemsets (starts with k=1)
生成k個項目集的可能組合(以k = 1開頭)
- Calculates support according to each itemset 根據每個項目集計算支持
- Eliminates infrequent itemsets 消除不頻繁的項目集
- Increments k and repeats the process 遞增k并重復該過程
Now, how to generate those itemsets ?!!
現在,如何生成這些項目集?
For itemsets of length k=2, it is required to consider every possible combination of two items (no permutation is needed). For k > 2, two conditions must be satisfied first :
對于長度為k = 2的項目集,需要考慮兩個項目的每種可能的組合(不需要排列)。 對于k> 2 ,必須首先滿足兩個條件:
The combined itemset must be formed of two frequent ones of length k-1, let’s call’em subsets.
組合的項目集必須由兩個長度為k-1的 頻繁項組成,我們稱它們為em 子集 。
Both subsets must have the same prefix of length k-2
兩個子集必須具有相同的長度k-2前綴
If you think about it, these steps will just extend the previously found frequent itemsets, this is called the ‘bottom up’ approach. It also proves that Apriori algorithm respects the monotone property :
如果您考慮一下,這些步驟將僅擴展先前發現的頻繁項目集,這稱為“自下而上”方法。 這也證明Apriori算法尊重單調性 :
All subsets of a frequent itemset must also be frequent.
頻繁項目集的所有子集也必須是頻繁的。
As well as the anti-monotone property :
以及抗單調特性 :
All super-sets of an infrequent itemset must also be infrequent.
罕見項目集的所有超集也必須是不頻繁的。
Okay, but wait a minute, this seems infinite !!
好的,但是等等,這似乎是無限的!
No, luckily it is not infinite, the algorithm stops at a certain order k if :
不,幸運的是它不是無限的,如果滿足以下條件,該算法將以某個順序k停止:
All the generated itemsets of length k are infrequent
生成的所有長度為k的項目集很少
No found prefix of length k-2 in common which makes it impossible to generate new itemsets of length k
找不到長度為k-2的前綴,這使得無法生成長度為k的新項目集
Sure…it’s not rocket science ! but how about an example to make this clearer ?
當然……這不是火箭科學! 但是如何使這個例子更清楚呢?
Here’s a small transaction table in binary format, the value of an item is 1 if it’s present in the considered transaction, otherwise it’s 0.
這是一個二進制格式的小交易表,如果項目存在于所考慮的交易中,則該項目的值為1 ,否則為0 。
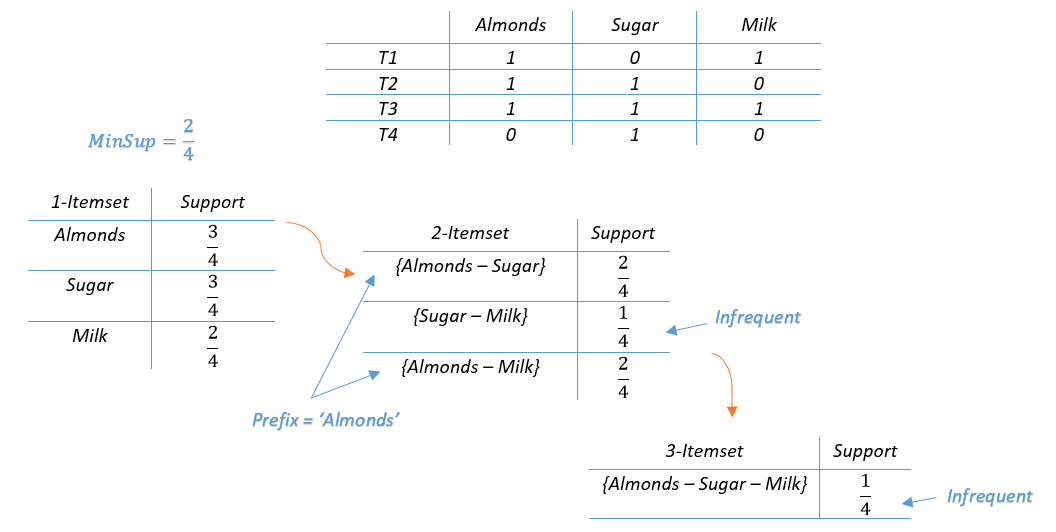
太好了……是時候進行一些關聯規則挖掘了! (Great…It’s time for some association rule mining !)

Once you reach this part, all there’s left to do is to take one frequent k-itemset at a time and generate all its possible rules using binary partitioning.
一旦達到這一部分,剩下要做的就是一次獲取一個頻繁的k項集,并使用二進制分區生成所有可能的規則。
If the 3-itemset {Almonds-Sugar-Milk} from the previous example were a frequent itemset, then the generated rules would look like :
如果前面示例中的3個項目集{Almonds-Sugar-Milk}是一個頻繁項集,則生成的規則將如下所示:

我的Apriori模擬概述! 使用Python (An overview of my Apriori simulation !! Using Python)
數據集 (Dataset)
Of format csv (Comma separated values), containing 7501 transactions of purchased items in a supermarket. Restructuring the dataset with the transaction encoder class from mlxtend library made the use and manipulation much easier. The resulting structure is occupying an area of ??871.8 KB with 119 columns indexed respectively by food name from “Almonds” to “Zucchini”.
格式為csv (逗號分隔值),包含在超市中的7501個已購買商品的交易。 使用mlxtend庫中的事務編碼器類重構數據集 使使用和操作更加容易。 最終的結構占據了871.8 KB的區域,其中119列分別由食品名稱從``杏仁''到``西葫蘆''索引。
Here’s an overview of the transaction table before and after :
這是之前和之后的事務表的概述:
實現算法 (Implementing the algorithm)
I will not be posting any code fragments as it was a straight forward approach, the procedure is recursive, calls the responsible functions for the itemsets generation, support calculation, elimination and association rule mining in the mentioned order.
我不會發布任何代碼片段,因為這是一種直接的方法,該過程是遞歸的,并按上述順序調用負責項集生成,支持計算,消除和關聯規則挖掘的負責功能。
The execution took 177 seconds which seemed optimised and efficient thanks to Pandas and NumPy’s ability to perform quick element-wise operations. All found association rules were saved in an html file for later use.
由于Pandas和NumPy能夠執行快速的按元素操作,因此執行過程耗時177秒,這似乎是優化和高效的。 找到的所有關聯規則都保存在html文件中,以備后用。
現在,去超市逛逛怎么樣? 通過Plotly使用Dash (Now, how about a tour in the supermarket ? Using Dash by Plotly)
Finally, i got to use the previously saved rules to suggest food items based on what my basket contains. Here’s a quick preview :
最后,我必須使用之前保存的規則根據購物籃中的食物來建議食物。 快速預覽:
Feel free to check my source code here.
請在此處隨意檢查我的源代碼。
翻譯自: https://medium.com/the-coded-theory/data-mining-a-focus-on-apriori-algorithm-b201d756c7ff
推薦算法的先驗算法的連接
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389494.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389494.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389494.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

Android 頁面多狀態布局管理

Tensorflow入門神經網絡代碼框架

手把手教你把代碼丟入github 中

時間序列模式識別_空氣質量傳感器數據的時間序列模式識別

oracle 性能優化 07_診斷事件

Tensorflow框架:卷積神經網絡實戰--Cifar訓練集

計算機科學速成課36:自然語言處理

linux內存初始化初期內存分配器——memblock

數據科學學習心得_學習數據科學

Keras框架:Alexnet網絡代碼實現


微軟Azure CDN現已普遍可用

數據科學生命周期_數據科學項目生命周期第1部分

Keras框架:VGG網絡代碼實現

![BZOJ 2003 [Hnoi2010]Matrix 矩陣](http://pic.xiahunao.cn/BZOJ 2003 [Hnoi2010]Matrix 矩陣)
BZOJ 2003 [Hnoi2010]Matrix 矩陣

Keras框架:resent50代碼實現
)
MySQL數據庫的回滾失敗(JAVA)

條件概率分布_條件概率
之樂觀鎖插件)