jdk重啟后步行
“永遠不要做出預測,尤其是關于未來的預測。” (KK Steincke) (“Never Make Predictions, Especially About the Future.” (K. K. Steincke))
- Does this picture portray a horse or a car? 這張照片描繪的是馬還是汽車?
- How likely is this customer to buy this item in the next week? 該客戶在下周購買該商品的可能性有多大?
- Will this person fail to repay her loan over the next year? 這個人明年是否不能償還貸款?
- How does this sentence translate to Spanish? 這句話如何翻譯成西班牙語?
These questions may be answered with machine learning. But — whereas questions 1 and 4 concern things that exist already (a picture, a sentence) — questions 2 and 3 regard future events, namely events that haven’t happened yet. Is this relevant? Indeed, it is.
這些問題可以通過機器學習來回答。 但是,盡管問題1和4與已經存在的事物(一張圖片,一個句子)有關,但問題2和3與未來的事件有關,即尚未發生的事件。 這相關嗎? 的確是。
In fact, we all know — first as human beings, then as data scientists — that predicting the future is hard.
實際上, 我們所有人(首先是人類,然后是數據科學家)都知道,預測未來很難 。
From a technical point of view, this is due to concept drift, which is a very intuitive notion: phenomena change over time. Since the phenomenon we want to foresee is constantly changing, using a model (which learnt on the past) to predict the future poses additional challenges.
從技術角度來看,這是由于概念漂移所致,這是一個非常直觀的概念:現象會隨著時間而變化。 由于我們要預見的現象正在不斷變化,因此使用模型(從過去學到的)來預測未來會帶來更多挑戰 。
In this post, I am going to describe three machine learning approaches that may be used for predicting the future, and how they deal with such challenges.
在本文中,我將描述三種可用于預測未來的機器學習方法,以及它們如何應對此類挑戰。
In-Time: the approach adopted most commonly. By construction, it suffers badly from concept drift.
及時 :這種方法最常用。 通過構造,它嚴重遭受概念漂移的困擾。
Walk-Forward: common in some fields such as finance, but still not so common in machine learning. It overcomes some weaknesses of In-Time, but at the cost of introducing other drawbacks.
漫游 :在金融等某些領域很普遍,但在機器學習中仍然不那么普遍。 它克服了In-Time的一些弱點,但以引入其他缺點為代價。
Walk-Backward: a novel approach that combines the pros of In-Time and Walk-Forward, while mitigating their cons. I tried it on real, big, messy data and it proved to work extremely well.
向后步行 :一種新穎的方法,結合了In-Time和Walk-Forward的優點,同時減輕了它們的弊端。 我在真實,大型,混亂的數據上進行了嘗試,事實證明它可以很好地工作。
In the first part of the article, we will go through the three approaches. In the second part, we will try them on data and see which one works best.
在本文的第一部分,我們將介紹三種方法。 在第二部分中,我們將在數據上對它們進行嘗試,然后看看哪種方法最有效。
第一種方法:“及時” (1st Approach: “In-Time”)
Suppose today is October 1, 2020, and you want to predict the probability that the customers of your company will churn in the next month (i.e. from today to October 31).
假設今天是2020年10月1日,您想預測下個月(即從今天到10月31日)公司客戶流失的可能性。
Here is how this problem is addressed in most data science projects:
以下是大多數數據科學項目中解決此問題的方法:

Note: information contained in X can go back in time indefinitely (however, in all the figures — for the sake of visual intuition — it goes back only 4 months).
注意: X中包含的信息可以無限期地返回(但是,為了直觀起見,所有圖中的信息只能返回4個月)。
This approach is called “In-Time”, because all the datasets (train, validation and test) are taken from the same timepoint (in this case, September). By train, validation and test set, we intend:
這種方法稱為“實時”,因為所有數據集(訓練,驗證和測試)均取自同一時間點 (在這種情況下為9月)。 通過培訓,驗證和測試集,我們打算:
Train set (X_train and y_train): data on which the model will learn.
訓練集 ( X_train和y_train ):模型將在其上學習的數據。
Validation set (X_validation and y_validation): data used for early stopping. During the training phase, at each iteration, the validation performance is computed. When such performance stops improving, it means the model has started to overfit, so the training is arrested.
驗證集 ( X_validation和y_validation ):用于提前停止的數據。 在訓練階段,每次迭代都會計算驗證性能。 當這種性能停止改善時,意味著模型已經開始過擬合,因此訓練被停止。
Test set (X_test and y_test): data never used during the training phase. Only used to get an estimate of how your model will actually perform in the future.
測試集 ( X_test和y_test ):在訓練階段從未使用過的數據。 僅用于估計模型將來的實際性能。
Now that you gathered the data, you fit a predictive model (let’s say an Xgboost) on the train set (September). Performance on the test set is the following: a precision of 50% with a recall of 60%. Since you are happy with this outcome, you decide to communicate this result to stakeholders and make the forecast on October.
現在,您已經收集了數據,現在可以在火車組(9月)上擬合預測模型(假設為Xgboost)。 測試儀的性能如下:精度為50%,召回率為60%。 由于您對此結果感到滿意,因此您決定將此結果傳達給利益相關者,并在10月進行預測。
One month later, you go and check how your model actually did in October. A nightmare. A precision of 20% with a recall of 25%. How is that possible? You did everything right. You validated your model. Then you tested it. Why do test performance and observed performance differ so drastically?
一個月后,您去檢查一下您的模型在十月份的實際效果。 一個噩夢。 精度為20%,召回率為25%。 那怎么可能? 你做得對。 您驗證了模型。 然后,您對其進行了測試。 為什么測試性能和觀察到的性能如此巨大的差異?
過時 (Going Out-of-Time)
The problem is that concept drift is completely disregarded by the In-Time approach. In fact, this hypothesis is implicitly made:
問題在于,In-Time方法完全忽略了概念漂移。 實際上,這個假設是隱含的:
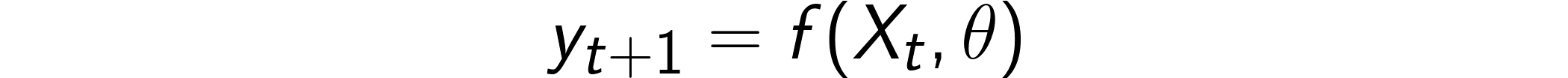
In this framework, it doesn’t really matter when the model is trained, because f(θ) is assumed to be constant over time. Unfortunately, what happens, in reality, is different. In fact, concept drift makes f(θ) change over time. In formula, this would translate to:
在此框架中, 何時訓練模型并不重要,因為假設f(θ)隨時間恒定。 不幸的是,實際上發生的情況是不同的。 實際上,概念漂移使f(θ)隨時間變化。 在公式中,這將轉換為:
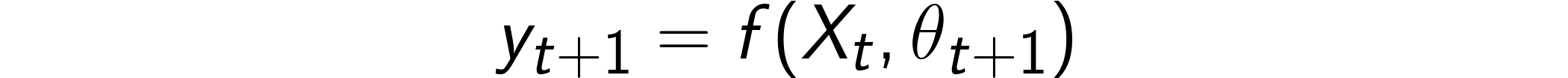
To take into account this effect, we need to move our mindset from in-time to out-of-time.
要考慮到這種影響,我們需要將思維方式從及時轉變為不及時。
第二種方法:“向前走” (2nd Approach: “Walk Forward”)
One form of out-of-time — mostly used in finance — is called Walk-Forward (read this article by Roger Stein to know more). This name comes from the fact that the model is validated and/or tested forward in time with respect to the data used for training. Visually:
超時的一種形式(通常用于財務)稱為“向前走”(請閱讀Roger Stein的這篇文章以了解更多信息)。 這個名稱來自這樣一個事實,即模型相對于用于訓練的數據及時進行了驗證和/或測試。 視覺上:

This configuration has the advantage that it simulates the real usage of the model. In fact, the model is trained on t (August), and evaluated in t+1 (September). Therefore, this is a good proxy of what can be expected by training in September and making predictions on October.
這種配置的優點是它可以模擬模型的實際用法。 實際上,該模型在t上進行了訓練(8月),并在t + 1上進行了評估(9月)。 因此,這可以很好地替代9月份的培訓和10月份的預測。
However, when I tried this approach on real data, I noticed it suffers from some major drawbacks:
但是,當我在真實數據上嘗試這種方法時,我注意到它存在一些主要缺點:
If you use the model trained on August for making predictions on October, you would use a model which is 2-month-old! Therefore, the performance in October would be even worse than by using In-Time. Practically, this happens because the latest data is “wasted” for testing.
如果您使用8月訓練的模型進行10月的預測,則將使用2個月的模型! 因此, 十月份的性能甚至比使用In-Time更差。 實際上,發生這種情況是因為“浪費”了最新數據以進行測試 。
Alternatively, if you retrain the model on September, you will fall again into In-Time. And, in the end, it will not be easy to estimate the expected performance of the model in October. So you would be back where you started.
另外, 如果您在9月對模型進行重新訓練,您將再次陷入In-Time。 最后,要估計該模型在10月份的預期性能并不容易 。 因此,您將回到開始的地方。
To sum up, I liked the idea of going out-of-time, but it seemed to me that Walk-Forward was not worth it.
綜上所述,我喜歡過時的想法,但在我看來,步行前進是不值得的。
第三種方法:“向后走” (3rd Approach: “Walk Backward”)
Then, this idea came to my mind: could it be that concept drift is in some way “constant” over time? In other words, could it be that predicting 1 month forward or 1 month backward leads on average to the same performance?
然后,這個想法浮現在我的腦海:難道是隨著時間的推移,概念漂移在某種程度上是“恒定的”? 換句話說, 預測平均向前1個月或向后1個月會導致相同的效果嗎?
If that was the case, I would have killed two birds (no, wait, three birds) with one stone. In fact, I would have kept the benefits of:
如果真是這樣,我會用一塊石頭殺死兩只鳥(不,等等,三只鳥)。 實際上,我會保留以下優勢:
using the latest data for training (as happens in In-Time, but not in Walk-Forward);
使用最新的數據進行訓練 (如在In-Time中進行,但在Walk-Forward中不進行);
making a reliable estimate of how the model would perform the next month (as happens in Walk-Forward, but not in In-Time);
對模型下個月的性能進行可靠的估算 (如在Walk-Forward中發生,但在In-Time中不發生);
training just one model (as happens in In-Time, but not in Walk-Forward).
僅訓練一種模型 (如“實時”中那樣,而在“步行”中則沒有)。
In short, I would have kept the advantages of each approach, while getting rid of their drawbacks. This is how I arrived to the following configuration:
簡而言之,我將保留每種方法的優點,同時消除它們的缺點。 這就是我到達以下配置的方式:

I’ve called it “Walk-Backward” because it does the exact opposite of Walk-Forward: training is made on the latest data, whereas validation and testing are made on previous time windows.
我將其稱為“后退步行”,是因為它與“前進”完全相反:對最新數據進行訓練,而對驗證和測試則在以前的時間窗口進行。
I know it may seem crazy to train a model in September (and validate it in July), then check how it performed in August, and even expect this is a good estimate of how it will do in October! This probably looks like as if we are going back and forth in time on a DeLorean, but I promise I’ve got a good explanation.
我知道在9月訓練模型(并在7月進行驗證),然后檢查其在8月的性能似乎瘋狂,甚至期望這可以很好地估計10月的性能! 這看起來好像我們是在DeLorean上來回走動 ,但我保證我會得到很好的解釋。
如果您喜歡哲學... (If You Like Philosophy…)
… then there is a philosophical explanation of why Walk-Backward makes sense. Let’s break it down.
…然后有一個哲學解釋,說明為什么“后退”有意義。 讓我們分解一下。
- For each set (train, validation and test), it is preferable to use a different prediction window. This is necessary to avoid that validation data or test data give a too optimistic estimate of how the model performs. 對于每組(訓練,驗證和測試),最好使用不同的預測窗口。 有必要避免驗證數據或測試數據對模型的執行情況過于樂觀。
Given point 1., training the model on September (t) is the only reasonable choice. This because the model is supposed to “learn a world” as similar as possible to the one we want to predict. And the world of September (t) is likely more similar to the world of October (t+1) than any other past month (t-1, t-2, …).
給定點1., 在9月(t)訓練模型是唯一合理的選擇。 這是因為該模型應該“學習一個世界”,與我們要預測的模型盡可能相似。 與過去一個月(t-1,t-2,...)相比,9月(t)的世界可能與10月(t + 1)的世界更相似。
At this point, we have a model trained on September, and would like to know how it will perform in October. Which month should be picked as test set? August is the optimal choice. In fact, the world of August (t-1) is “as different” from the world of September (t) as the world of October (t+1) is from the world of September (t). This happens for a very simple reason: October and August are equally distant from September.
至此,我們已經在9月對模型進行了訓練,并且想知道它在10月的表現如何。 應該選擇哪個月份作為測試集? 八月是最佳選擇。 實際上,八月的世界(t-1)與九月的世界(t)“不同”,十月的世界(t + 1)與九月的世界(t)不同 。 發生這種情況的原因很簡單:十月和八月與九月的距離相同。
Given points 1., 2. and 3., using July (t-2) as validation set is the only necessary consequence.
給定點1.,2和3.,使用July( t-2 )作為驗證集是唯一必要的結果。
如果您不喜歡哲學... (If You Don’t Like Philosophy…)
… then, maybe, you like numbers. In that case, I can reassure you: I tried this approach on a real use-case and, compared to In-Time and Walk-Forward, Walk-Backward obtained:
……然后,也許您喜歡數字。 在那種情況下,我可以向您保證:我在一個實際用例上嘗試了這種方法,并且與In-Time和Walk-Forward相比,Walk-Backward獲得了:
higher precision in predicting y_future;
預測y_future的精度更高;
lower difference between performance on y_test and on y_future (i.e. the precision observed on August is a more reliable estimate of the precision that will actually obtained on October);
y_test和y_future的性能之間的差異較小 (即8月觀察到的精度是對10月實際獲得的精度的更可靠的估計);
lower difference between performance on y_train and on y_test (i.e. less overfitting).
y_train和y_test的性能之間的差異較小 (即,過擬合程度較低)。
Basically, everything a data scientist can ask for.
基本上,數據科學家可以要求的一切。
“我還是不相信你!” (“I Still Don’t Believe You!”)
It’s ok, I’m a skeptical guy too! This is why we will try In-Time, Walk-Foward and Walk-Backward on some data, and see which one will perform best.
沒關系,我也是一個懷疑的家伙! 這就是為什么我們將對某些數據嘗試In-Time,Walk-Foward和Walk-Backward,并查看哪種數據效果最好。
To do that, we will use simulated data. Simulating data is a convenient way for reproducing concept drift “in the lab” and for making the results replicable. In this way, it will be possible to check whether the superiority of Walk-Backward is confirmed in a more general setting.
為此,我們將使用模擬數據。 模擬數據是一種方便的方法,可用于“在實驗室中”再現概念偏差并可以復制結果。 以這種方式,可以檢查在更一般的設置中是否確認了向后走的優勢。
在實驗室中重現概念漂移 (Reproducing Concept Drift in the Lab)
Let’s take 12 timepoints (monthly data from January 2020 to December 2020). Say that, each month, 50 features have been observed on 5,000 individuals. This means 12 dataframes (X_1, …, X_12), each one with 5,000 rows and 50 columns. To keep things simple, the columns are generated from a normal distribution:
讓我們采用12個時間點(從2020年1月到2020年12月的月度數據)。 假設每個月在5,000個人身上觀察到50個特征。 這意味著12個數據幀( X_1 ,…, X_12 ),每個數據幀具有5,000行和50列。 為了簡單起見,這些列是從正態分布生成的:

Once X is available, we need y (dependent, or target, variable). Out of simplicity, y will be a continuous variable (but the results could be easily extended to the case in which y is discrete).
X可用后,我們需要y (因變量或目標變量)。 出于簡單性考慮, y將是一個連續變量(但結果可以輕松地擴展到y是離散的情況)。
A linear relationship is assumed between X and y:
假設X和y之間存在線性關系:
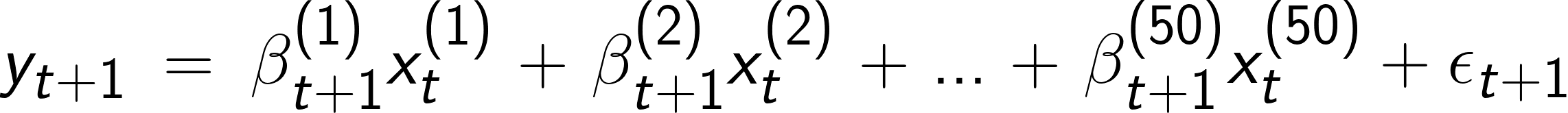
βs are indexed by t because parameters change constantly over time. This is how we account for concept drift in our simplified version of the world.
βs用t索引,因為參數會隨著時間不斷變化。 這就是我們在簡化的世界中解決概念漂移的方式 。
In particular, βs change according to an ARMA process. This means that the fluctuations of β(i) are not totally random: they depend on the past values of β(i) itself.
特別地, βs根據ARMA過程而變化 。 這意味著β(i)的波動并不是完全隨機的:它們取決于β(i)本身的過去值。
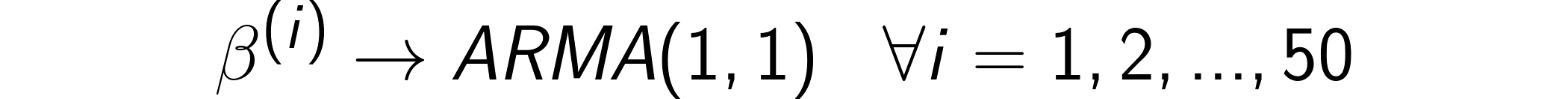
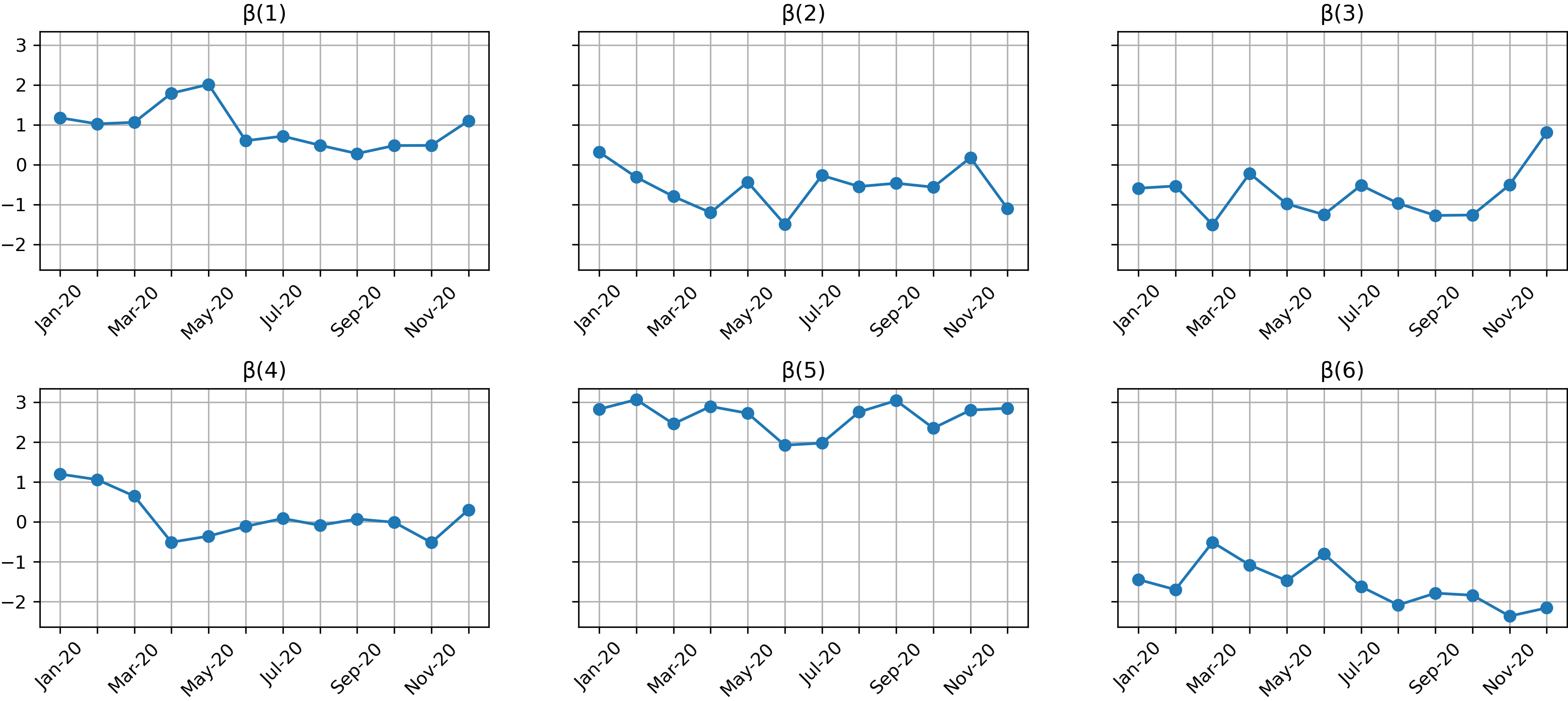
ARMA’s coefficients (and error) are chosen based on the conservative assumption that fluctuations from month to month are not so huge (note that a more aggressive hypothesis would have favored out-of-time approaches). In particular, let’s take AR coefficient to be -0.3, MA coefficient 0.3 and standard deviation of the error 0.5. These are the resulting trajectories for the first 6 (out of 50) βs.
選擇ARMA的系數(和誤差)是基于一個保守的假設,即每個月的波動幅度都不大(請注意,更具攻擊性的假設將有利于過時的方法)。 特別地,使AR系數為-0.3,MA系數為0.3,誤差的標準偏差為0.5。 這些是前6個(總共50個) βs的合成軌跡。
And this is how the target variables (y) look like:
這就是目標變量( y )的樣子:
結果 (The Outcomes)
Now that we have the data, the three approaches can be compared.
現在我們有了數據,可以比較這三種方法。
Since this is a regression problem (y is a continuous variable), mean absolute error (MAE) has been chosen as metric.
由于這是一個回歸問題( y是連續變量),因此已選擇平均絕對誤差(MAE)作為度量。
To make the results more reliable, each approach has been carried out on all the timepoints (in a “sliding window” fashion). Then, the outcomes have been averaged over all the timepoints.
為了使結果更可靠,已在所有時間點(以“滑動窗口”方式)執行了每種方法。 然后,在所有時間點上對結果進行平均。
This is the outcome:
結果如下:
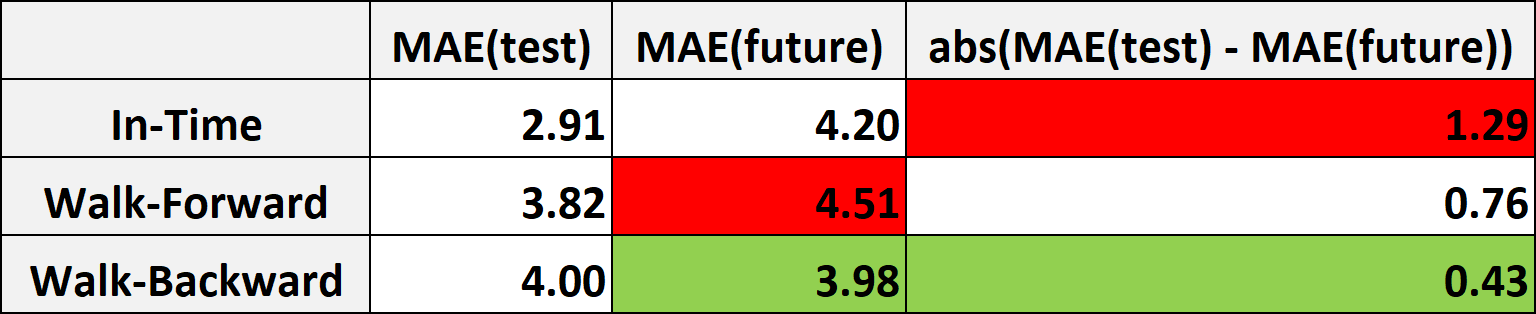
Typically, the most important indicator of a predictive model’s goodness is the performance observed on y_future. From this point of view, Walk-Backward is the best approach, since it delivers the best MAE (3.98).
通常, 預測模型優劣的最重要指標是y_future上觀察到的性能。 從這個角度來看,Walk-Backward是最好的方法,因為它提供了最佳的MAE(3.98) 。
But there’s more than that. Take a look at In-Time: MAE(test) is on average 2.91, while MAE(future) is 4.20. Thus, in a real-world use case, you would communicate to stakeholders that you expect your model to deliver a MAE of 2.91. But the actual performance that you will observe one month later is on average 4.19. It’s a huge difference (and a huge disappointment)!
不僅如此。 看一下In-Time:MAE( test )平均為2.91,而MAE( future )為4.20。 因此,在實際的用例中,您將與利益相關者進行交流,您希望模型能夠提供2.91的MAE。 但是一個月后您將觀察到的實際性能平均為4.19。 這是一個巨大的差異(和巨大的失望)!
Indeed, the absolute difference between test performance and future performance is on average three times higher for In-Time than for Walk-Backward (1.28 versus 0.43). So, Walk-Backward turns out to be by far the best approach (also) from this perspective.
確實, In-Time的測試性能和未來性能之間的絕對差異平均比Walk-Backward高出三倍(1.28對0.43)。 因此,從這個角度來看,向后走行也是迄今為止最好的方法。
Note that, in a real-world use case, this aspect is maybe even more important than performance itself. In fact, being able to anticipate the actual performance of a model — without having to wait the end of the following period — is crucial for allocating resources and for planning actions.
請注意, 在實際的用例中,這方面可能比性能本身更為重要 。 實際上,無需等待下一個階段的結束就能夠預期模型的實際性能,這對于分配資源和計劃操作至關重要。
Results are fully reproducible. Python code is available in this notebook.
結果是完全可重復的。 此筆記本中提供了Python代碼。
All images created by author, through matplotlib (for plots) or codecogs (for Latex formulas).
作者通過matplotlib (用于繪圖)或codecogs (用于Latex公式)創建的所有圖像。
Thank you for reading! I hope you found this post useful.
感謝您的閱讀! 我希望您發現這篇文章有用。
I appreciate feedback and constructive criticism. If you want to talk about this article or other related topics, you can text me at my Linkedin contact.
我感謝反饋和建設性的批評。 如果您想談論本文或其他相關主題,可以通過Linkedin聯系人發短信給我 。
翻譯自: https://towardsdatascience.com/introducing-walk-backward-a-novel-approach-to-predicting-the-future-c7cf9e15e9e2
jdk重啟后步行
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389426.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389426.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389426.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

PyTorch官方教程中文版:入門強化教程代碼學習

css3-2 CSS3選擇器和文本字體樣式

mongodb仲裁者_真理的仲裁者

優化 回歸_使用回歸優化產品價格

Node.js——異步上傳文件

用 JavaScript 的方式理解遞歸

PyTorch官方教程中文版:Pytorch之圖像篇

大數據數據科學家常用面試題_進行數據科學工作面試

scrapy模擬模擬點擊_模擬大流行

公司想申請網易企業電子郵箱,怎么樣?

莫煩Matplotlib可視化第二章基本使用代碼學習

vue.js python_使用Python和Vue.js自動化報告過程

plsql中導入csvs_在命令行中使用sql分析csvs

第十八篇 Linux環境下常用軟件安裝和使用指南

莫煩Matplotlib可視化第三章畫圖種類代碼學習

計算機科學必讀書籍_5篇關于數據科學家的產品分類必讀文章

es6解決回調地獄問題

交替最小二乘矩陣分解_使用交替最小二乘矩陣分解與pyspark建立推薦系統

莫煩Matplotlib可視化第四章多圖合并顯示代碼學習
