missforest
Missing data often plagues real-world datasets, and hence there is tremendous value in imputing, or filling in, the missing values. Unfortunately, standard ‘lazy’ imputation methods like simply using the column median or average don’t work well.
丟失的數據通常困擾著現實世界的數據集,因此,估算或填寫丟失的值具有巨大的價值。 不幸的是,標準的“惰性”插補方法(例如僅使用列中位數或平均值)效果不佳。
On the other hand, KNN is a machine-learning based imputation algorithm that has seen success but requires tuning of the parameter k and additionally, is vulnerable to many of KNN’s weaknesses, like being sensitive to being outliers and noise. Additionally, depending on circumstances, it can be computationally expensive, requiring the entire dataset to be stored and computing distances between every pair of points.
另一方面,KNN是一種基于機器學習的插補算法,它已經取得了成功,但需要調整參數k,而且容易受到KNN的許多弱點的影響,例如對異常值和噪聲敏感。 另外,根據情況,計算可能會很昂貴,需要存儲整個數據集并計算每對點之間的距離。
MissForest is another machine learning-based data imputation algorithm that operates on the Random Forest algorithm. Stekhoven and Buhlmann, creators of the algorithm, conducted a study in 2011 in which imputation methods were compared on datasets with randomly introduced missing values. MissForest outperformed all other algorithms in all metrics, including KNN-Impute, in some cases by over 50%.
MissForest是基于隨機森林算法的另一種基于機器學習的數據插補算法。 該算法的創建者Stekhoven和Buhlmann于2011年進行了一項研究,該研究在具有隨機引入的缺失值的數據集上比較了插補方法。 在所有指標上,MissForest的性能均優于其他所有算法,包括KNN-Impute,在某些情況下超過50%。
First, the missing values are filled in using median/mode imputation. Then, we mark the missing values as ‘Predict’ and the others as training rows, which are fed into a Random Forest model trained to predict, in this case, Age based on Score. The generated prediction for that row is then filled in to produce a transformed dataset.
首先,使用中位數/眾數插補來填充缺失值。 然后,我們將缺失的值標記為'Predict',將其他值標記為訓練行,將其輸入經過訓練的Random Forest模型中,該模型用于預測基于Score Age 。 然后填寫針對該行生成的預測,以生成轉換后的數據集。
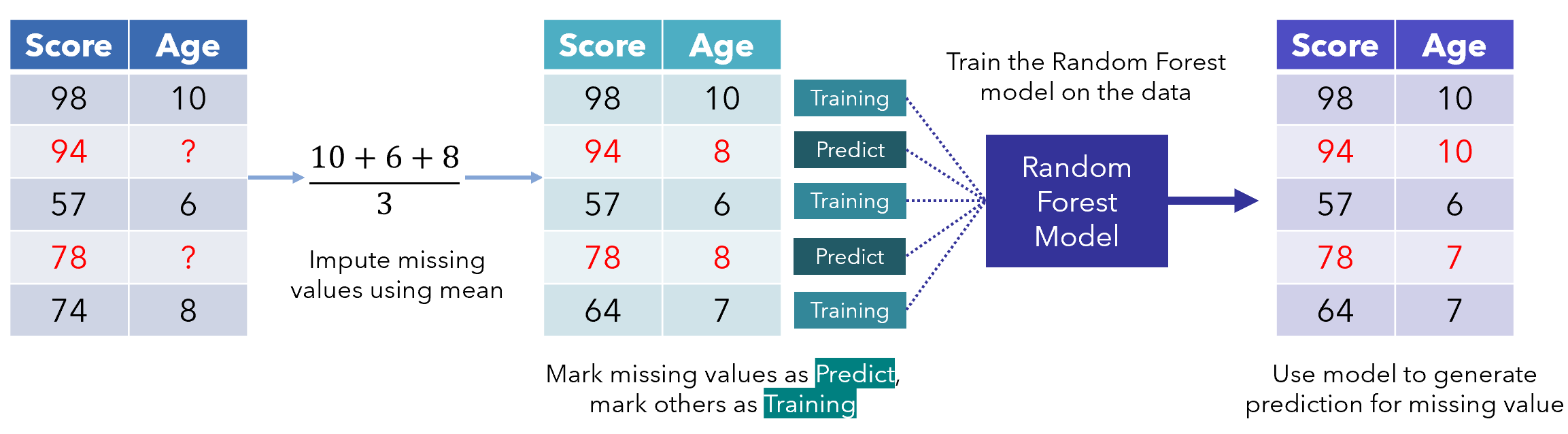
This process of looping through missing data points repeats several times, each iteration improving on better and better data. It’s like standing on a pile of rocks while continually adding more to raise yourself: the model uses its current position to elevate itself further.
這種遍歷缺失數據點的循環過程會重復幾次,每次迭代都會改善越來越好的數據。 這就像站在一堆巖石上,而不斷增加更多東西以提高自己:模型使用其當前位置進一步提升自己。
The model may decide in the following iterations to adjust predictions or to keep them the same.
模型可以在接下來的迭代中決定調整預測或使其保持不變。
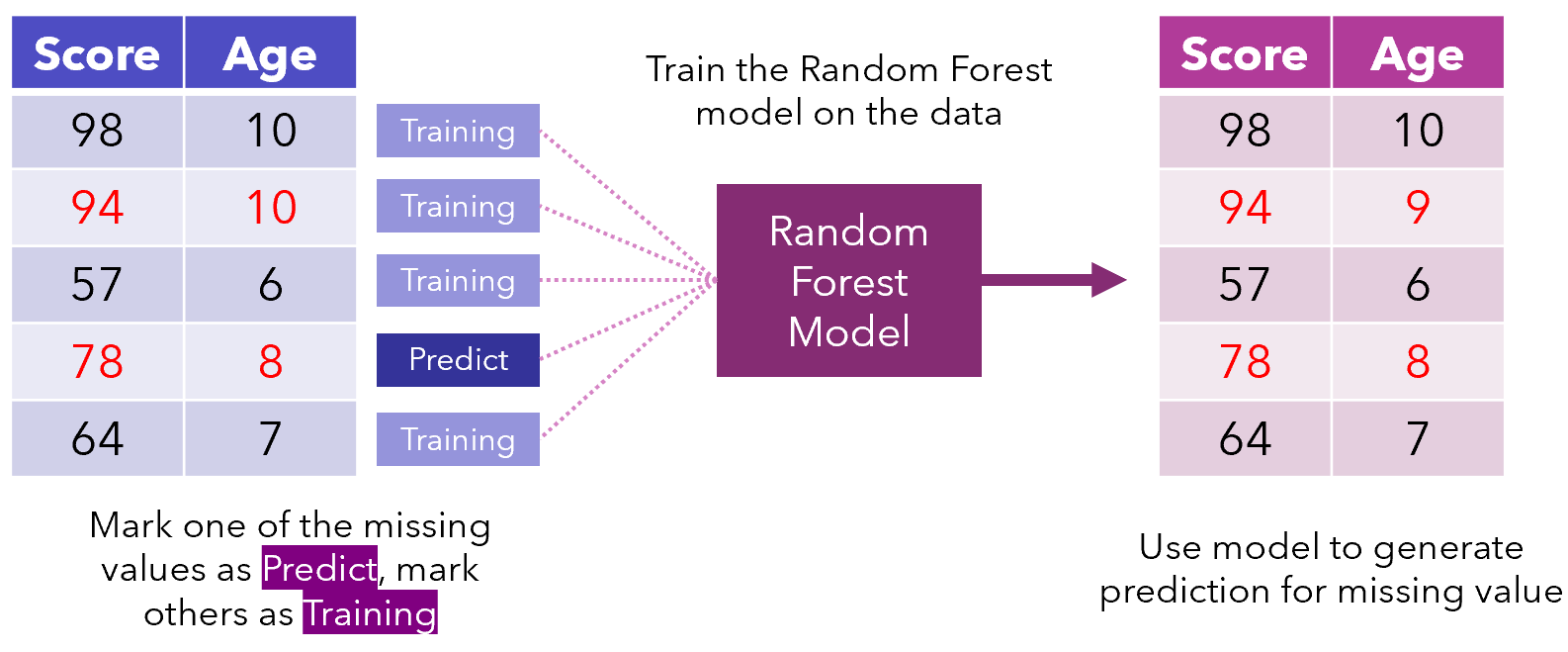
Iterations continue until some stopping criteria is met or after a certain number of iterations has elapsed. As a general rule, datasets become well imputed after four to five iterations, but it depends on the size and amount of missing data.
迭代一直持續到滿足某些停止條件或經過一定數量的迭代之后。 通常,經過四到五次迭代后,數據集的插補效果會很好,但這取決于丟失數據的大小和數量。
There are many benefits of using MissForest. For one, it can be applied to mixed data types, numerical and categorical. Using KNN-Impute on categorical data requires it to be first converted into some numerical measure. This scale (usually 0/1 with dummy variables) is almost always incompatible with the scales of other dimensions, so the data must be standardized.
使用MissForest有很多好處。 一方面,它可以應用于數值和分類的混合數據類型。 對分類數據使用KNN-Impute要求首先將其轉換為某種數字量度。 此比例(通常為0/1,帶有虛擬變量 )幾乎總是與其他尺寸的比例不兼容,因此必須對數據進行標準化。
In a similar vein, no pre-processing is required. Since KNN uses na?ve Euclidean distances, all sorts of actions like categorical encoding, standardization, normalization, scaling, data splitting, etc. need to be taken to ensure its success. On the other hand, Random Forest can handle these aspects of data because it doesn’t make assumptions of feature relationships like K-Nearest Neighbors does.
同樣,不需要預處理。 由于KNN使用樸素的歐幾里得距離,因此需要采取各種措施,例如分類編碼,標準化,歸一化,縮放,數據拆分等,以確保其成功。 另一方面,Random Forest可以處理數據的這些方面,因為它沒有像K-Nearest Neighbors那樣假設特征關系。
MissForest is also robust to noisy data and multicollinearity, since random-forests have built-in feature selection (evaluating entropy and information gain). KNN-Impute yields poor predictions when datasets have weak predictors or heavy correlation between features.
MissForest還對嘈雜的數據和多重共線性具有魯棒性,因為隨機森林具有內置的特征選擇(評估熵和信息增益 )。 當數據集的預測變量較弱或特征之間的相關性很強時,KNN-Impute的預測結果很差。
The results of KNN are also heavily determined by a value of k, which must be discovered on what is essentially a try-it-all approach. On the other hand, Random Forest is non-parametric, so there is no tuning required. It can also work with high-dimensional data, and is not prone to the Curse of Dimensionality to the heavy extent KNN-Impute is.
KNN的結果在很大程度上還取決于k的值,該值必須在本質上是一種“萬能嘗試”方法中進行發現。 另一方面,“隨機森林”是非參數的,因此不需要調整。 它也可以處理高維數據,并且在很大程度上不會出現KNN-Impute的維數詛咒。
On the other hand, it does have some downsides. For one, even though it takes up less space, if the dataset is sufficiently small it may be more expensive to run MissForest. Additionally, it’s an algorithm, not a model object; this means it must be run every time data is imputed, which may not work in some production environments.
另一方面,它確實有一些缺點。 一方面,即使占用的空間較小,但如果數據集足夠小,則運行MissForest可能會更昂貴。 另外,它是一種算法,而不是模型對象。 這意味著每次插補數據時都必須運行它,這在某些生產環境中可能無法運行。
Using MissForest is simple. In Python, it can be done through the missingpy library, which has a sklearn-like interface and has many of the same parameters as the RandomForestClassifier/RandomForestRegressor. The complete documentation can be found on GitHub here.
使用MissForest很簡單。 在Python中,這可以通過missingpy庫完成,該庫具有sklearn的界面,并且具有與RandomForestClassifier / RandomForestRegressor相同的許多參數。 完整的文檔可以在GitHub上找到 。
The model is only as good as the data, so taking proper care of the dataset is a must. Consider using MissForest next time you need to impute missing data!
該模型僅與數據一樣好,因此必須適當注意數據集。 下次需要填寫缺少的數據時,請考慮使用MissForest!
Thanks for reading!
謝謝閱讀!
翻譯自: https://towardsdatascience.com/missforest-the-best-missing-data-imputation-algorithm-4d01182aed3
missforest
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389282.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389282.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389282.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

華碩猛禽1080ti_F-22猛禽動力回路的視頻分析

 的認知)
溫故而知新:柯里化 與 bind() 的認知


Memory-Associated Differential Learning論文及代碼解讀

大數據技術 學習之旅_如何開始您的數據科學之旅?

純API函數實現串口讀寫。

數據可視化工具_數據可視化

Android Studio調試時遇見Install Repository and sync project的問題
: Ignite Java Thin Client)
Apache Ignite 學習筆記(二): Ignite Java Thin Client
論文及代碼解讀)
VGAE(Variational graph auto-encoders)論文及代碼解讀


tableau大屏bi_Excel,Tableau,Power BI ...您應該使用什么?

python 可視化工具_最佳的python可視化工具

網絡編程 socket介紹

猿課python 第三天

在C#中使用代理的方式觸發事件

BP神經網絡反向傳播手動推導

使用python和pandas進行同類群組分析
模式—精讀《JavaScript 設計模式》Addy Osmani著)