大數據技術 學習之旅
Machine Learning seems to be fascinating to a lot of beginners but they often get lost into the pool of information available across different resources. This is true that we have a lot of different algorithms and steps to learn but starting with a strong base not only gives confidence but also the motivation to learn and explore further. In this story, we will go through the steps on how to set up your environment and start learning with the help of a known dataset i.e. IRIS dataset which is a multi-class classification problem in Machine Learning. We will also go through some helpful python libraries which can speed up the learning process which can help you even if you are a data scientist. If you have done the setup already, you can skip the setup steps. Let’s begin with the first step of your journey.
機器學習似乎使許多初學者著迷,但是他們常常迷失在跨不同資源的可用信息庫中。 的確,我們有很多不同的算法和步驟需要學習,但是從一個強大的基礎開始不僅會給人信心,而且還會激發學習和進一步探索的動力。 在這個故事中,我們將逐步了解如何設置環境并借助已知數據集(即IRIS數據集)開始學習,該數據集是機器學習中的多類分類問題。 我們還將介紹一些有用的python庫 ,這些庫可以加快學習過程,即使您是數據科學家 ,也可以為您提供幫助。 如果已經完成設置,則可以跳過設置步驟。 讓我們從旅程的第一步開始。
搭建環境 (Setting up the Environment)
We will use the Anaconda distribution to setup the data science environment. Download the latest version of Anaconda from here and open the anaconda prompt and run the following command-
我們將使用Anaconda發行版來設置數據科學環境。 從此處下載最新版本的Anaconda,然后打開anaconda提示符并運行以下命令:
jupyter notebookThe above command will start the Jupyter server and load the notebook directory in your browser.
上面的命令將啟動Jupyter服務器,并在瀏覽器中加載筆記本目錄。
創建一個虛擬環境 (Create a virtual environment)
I hope you are aware of virtual environments, if not you can read about them here. Although Anaconda comes with a base environment which is having most of the libraries already installed, it is recommended to use virtual environments as they help us to manage different environments that can have different packages and if something goes wrong with one environment it will not affect others. Here are the commands you can use to create, activate, and install packages in the virtual environment.
我希望您了解虛擬環境,如果沒有,您可以在這里閱讀有關它們的信息 。 盡管Anaconda帶有一個已安裝了大多數庫的基本環境 ,但建議使用虛擬環境,因為它們可以幫助我們管理可以具有不同程序包的不同環境,如果一個環境出了問題,則不會影響其他環境。 。 這是可用于在虛擬環境中創建,激活和安裝軟件包的命令。
將虛擬環境與筆記本鏈接 (Link virtual environment with the Notebook)
By default, the new environment would not show up in the Jupyter notebook. You need to run following commands to link your environment with Jupyter client
默認情況下,新環境不會顯示在Jupyter筆記本中。 您需要運行以下命令來將環境與Jupyter客戶端鏈接
啟動筆記本和有用的命令 (Starting notebook and useful commands)
Once you have a virtual environment, go to the browser and open a new notebook as shown below. Select the environment you just created.
擁有虛擬環境后,請轉到瀏覽器并打開一個新筆記本,如下所示。 選擇您剛剛創建的環境。
Jupyter notebook provides many handy shortcuts. Below 2 are my favorite-
Jupyter筆記本電腦提供了許多方便的快捷方式。 以下2是我的最愛-
- Tab- this acts as a autocomplete. Tab-這是自動完成。
- Shift + Tab- this will give you the command details and you do not need to go to the library documentation every time. Shift + Tab鍵-這將為您提供命令詳細信息,您無需每次都轉到庫文檔。
See, how these commands can be helpful
看,這些命令有什么幫助
探索Python庫并應用機器學習 (Exploring Python libraries and applying Machine Learning)
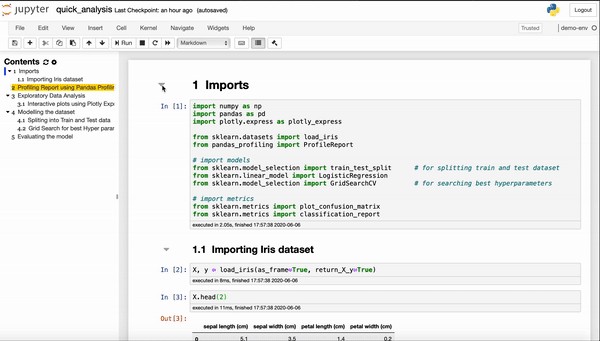
We need to have different libraries for loading the data sets, visualizations, and modeling. We will go through each and install them in the environment. You can have a look at my notebook, feel free to download and import it in your environment and play around with it-
我們需要有不同的庫來加載數據集,可視化和建模。 我們將逐一檢查并將它們安裝在環境中。 您可以看一下我的筆記本,可以在您的環境中隨意下載和導入它,并可以隨意使用-
Jupyter Contrib Nbextensions (Jupyter Contrib Nbextensions)
We often need to share our notebook with different stakeholders or might need to present them, this library provides us a lot of different extensions. I will not go through the extensions here, but I recommend using this. My favorite ones are-
我們經常需要與不同的利益相關者共享我們的筆記本,或者可能需要展示他們,這個庫為我們提供了許多不同的擴展。 我不會在這里進行擴展,但是我建議使用它。 我最喜歡的是-
- Collapsible headings. 可折疊的標題。
- Table of Contents. 目錄。
- Execution Time. 執行時間處理時間。
You can install it using
您可以使用安裝
conda install -c conda-forge jupyter_contrib_nbextensionsHere is a short demo on how it can help-
這是一個簡短的演示,介紹了如何幫助您-
熊貓-Python數據分析庫 (Pandas- Python Data Analysis Library)
This is the heart of data science with python and provides many different capabilities like
這是python數據科學的核心,并提供許多不同的功能,例如
- Data structures to work with the data. 使用數據的數據結構。
- Operations you can perform on the data. 您可以對數據執行的操作。
- Load and save data in different formats. 加載和保存不同格式的數據。
and many more. Many other libraries we use for machine learning with python have pandas as a dependency. Install it using-
還有很多。 我們用于python機器學習的許多其他庫都將pandas作為依賴項。 使用-安裝它
conda install -c conda-forge pandasThe above command will install other libraries like NumPy which pandas uses under the hood.
上面的命令將安裝其他庫,例如Pandas在后臺使用的NumPy。
斯克萊恩(Scikit-Learn) (Sklearn (Scikit-Learn))
We will use this library to download test datasets and apply different machine learning algorithms. Install using the following command.
我們將使用該庫下載測試數據集并應用不同的機器學習算法。 使用以下命令進行安裝。
conda install -c conda-forge scikit-learnIn machine learning classification problems, the problem can be understood as for X features (input variables) predict y (target value). Sklearn provides few test datasets which we can use to play with, we will take the IRIS dataset for this exercise but if you would like to play with others then you can refer to this.
在機器學習分類問題中,該問題可以理解為X特征(輸入變量)預測y(目標值)。 Sklearn提供了一些可用于測試的測試數據集,我們將使用IRIS數據集進行此練習,但是如果您想與其他人一起玩,則可以參考此內容 。
Scikit-learn 0.23.1 added a feature by which we can return the test dataset directly into the X and y dataframe. Make sure you are running version 0.23.1.
Scikit-learn 0.23.1添加了一項功能,通過該功能,我們可以將測試數據集直接返回到X和y數據框中。 確保您正在運行0.23.1版。
from sklearn.datasets import load_iris
We will now go through the other libraries and we will use Sklearn for modeling later
現在,我們將介紹其他庫,稍后將使用Sklearn進行建模
熊貓分析 (Pandas Profiling)
I am sure many of you would be aware of this library but if you are not please do give it a try. It provides a rich profiling report for the data which gives a lot of information from missing values to correlations. You need to install it using pip as conda-package downloads old version of it.
我敢肯定,你們中的許多人都會知道這個庫,但是如果您不知道,請嘗試一下。 它為數據提供了豐富的概要分析報告,該報告提供了從缺失值到相關性的大量信息。 您需要使用pip來安裝它,因為conda-package會下載舊版本。
pip install --user pandas-profiling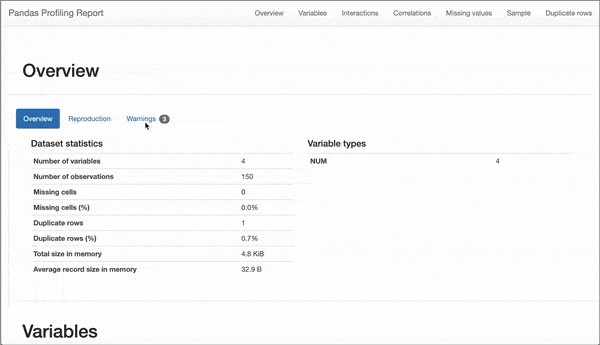
This report provides many details, out of which few are-
該報告提供了許多詳細信息,其中很少是-
- Overview of different variables in the dataset. 數據集中不同變量的概述。
- Correlation between variables. 變量之間的相關性。
- Interactions between variables. 變量之間的相互作用。
- Details about each variable. 有關每個變量的詳細信息。
The following commands can be used to generate and save the profile report-
以下命令可用于生成和保存配置文件報告-
情節快遞 (Plotly Express)
Although pandas-profiling provides a lot of useful information, we still need to visualize different information like for example we need to find how the target variable is distributed among multiple input variables. There exist many libraries for visualization, Matlplotlib and Seaborn are the famous ones you would have heard about. The main thing where Plotly stands out is the interactive plots i.e. you can interact with the generated plots. Install it using the following command
盡管pandas分析提供了許多有用的信息,但是我們仍然需要可視化不同的信息,例如我們需要找到目標變量如何在多個輸入變量之間分配。 有許多可視化庫,Matlplotlib和Seaborn是您會聽說的著名庫。 Plotly脫穎而出的主要功能是交互式繪圖,即您可以與生成的繪圖進行交互。 使用以下命令安裝
conda install -c conda-forge plotlyBelow we plotted a scatter plot between sepal length with petal length and used ‘color’ to show how the target variable is related.
下面我們在萼片長度和花瓣長度之間繪制了散點圖,并使用“顏色”顯示了目標變量之間的關系。
You can see below how we can filter out different targets.
您可以在下面看到我們如何過濾出不同的目標。
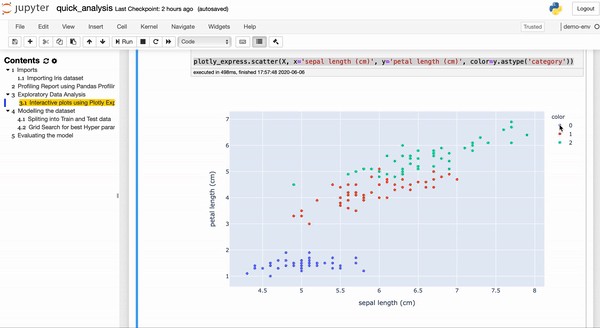
This library provides a lot of additional functionality, maybe we can cover that in a different story.
該庫提供了許多其他功能,也許我們可以在另一個故事中進行介紹。
培訓和測試數據集 (Training and Test dataset)
The idea of generating models is to predict values that are not known. If we learn the model on the entire dataset then we will not be able to evaluate how it performs on the unseen data. To achieve this, we split the dataset into training and test dataset. A training dataset is used to train the model and the test set is used to evaluate the model. Sklearn provides a function ‘train_test_split’ which split the dataset into train and test datasets. The following code can be used to split the datasets.
生成模型的想法是預測未知的值。 如果我們在整個數據集上學習該模型,那么我們將無法評估該模型在看不見的數據上的表現。 為此,我們將數據集分為訓練和測試數據集。 訓練數據集用于訓練模型,而測試集用于評估模型。 Sklearn提供了一個函數“ train_test_split”,可將數據集分為訓練和測試數據集。 以下代碼可用于拆分數據集。
from sklearn.model_selection import train_test_split
調整超參數 (Tuning Hyperparameters)
One of the important tasks in machine learning is to tune hyperparameters, these parameters are the different attributes of the algorithm which control the learning process. Different values are suitable for different learning problems and it is important to find out the best parameters. Sklearn provides mainly two ways ‘GridSearchCV’ and ‘RandomizedSearchCV’ to find the best parameters. For large training sets, we might need to use RandomizedSearchCV as it will take a lot of time to learn all parameters. In the IRIS dataset, we have only 150 rows and hence we used ‘GridSearchCV’.
機器學習的重要任務之一是調整超參數,這些參數是控制學習過程的算法的不同屬性。 不同的值適用于不同的學習問題,因此找出最佳參數很重要。 Sklearn主要提供“ GridSearchCV”和“ RandomizedSearchCV”兩種查找最佳參數的方法。 對于大型訓練集,我們可能需要使用RandomizedSearchCV,因為它將花費大量時間來學習所有參數。 在IRIS數據集中,我們只有150行,因此我們使用了“ GridSearchCV”。
For this story, we will train the LogisticsRegression model which is well-suited for classification problems and have different hyperparameters like ‘solver’, ‘C’, ‘penalty’, and ‘l1-ratio’. Not every solver supports all parameters and hence we create different dictionaries for all different solvers.
對于這個故事,我們將訓練物流回歸模型,該模型非常適合分類問題,并且具有不同的超參數,例如“求解器”,“ C”,“罰分”和“ l1-比率”。 并非每個求解器都支持所有參數,因此我們為所有不同的求解器創建不同的字典。
The above code would search for different combinations of parameters and find the best one which best generalizes the problem.
上面的代碼將搜索參數的不同組合,并找到最能概括該問題的最佳組合。
評估模型 (Evaluating the model)
As we mentioned, we need to evaluate the model on the test dataset, many different metrics are available. The common one is accuracy for classification problems. Here we will show the accuracy, classification_report, and confusion matrix which Sklearn provides.
如前所述,我們需要在測試數據集上評估模型,可以使用許多不同的指標。 常見的一種是分類問題的準確性。 在這里,我們將顯示Sklearn提供的準確性,classification_report和混淆矩陣。
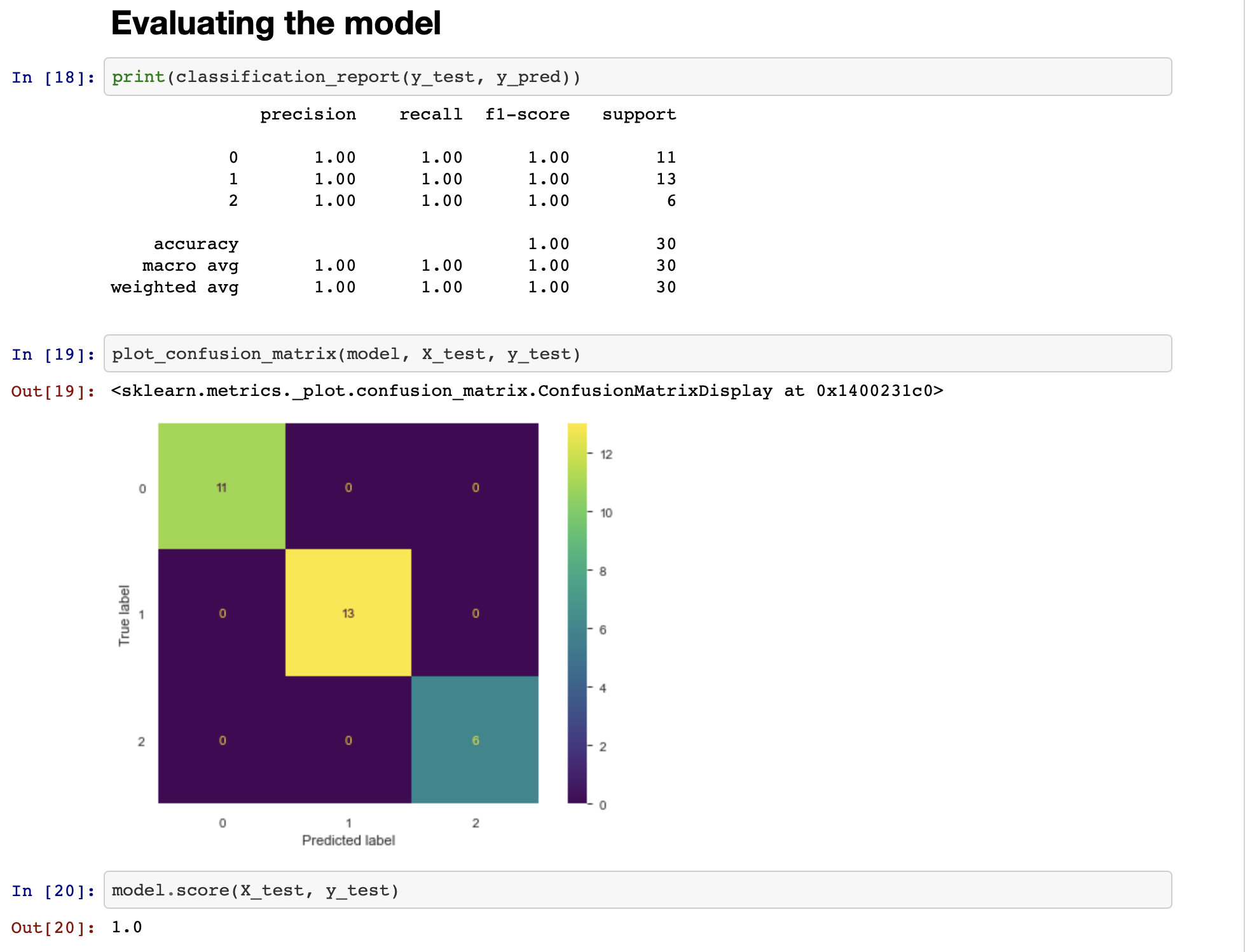
The IRIS dataset is classified as an easy dataset which means data is already suitable for machine learning purposes and hence we were able to get a perfect score i.e. accuracy score of 1.0 with our model. This means our model predicted all the samples in the test dataset correctly. It will vary with the different problems you are trying to solve.
IRIS數據集被歸類為簡單數據集,這意味著數據已經適合于機器學習目的,因此我們能夠獲得理想的評分,即模型的準確性評分為1.0。 這意味著我們的模型可以正確預測測試數據集中的所有樣本。 您要解決的不同問題會有所不同。
結論 (Conclusion)
The idea of this story was to give you a head start on machine learning and a glimpse of different libraries that you can utilize to speed up the process. I provided a simple overview of many things to keep this story short and precise. There is still a lot to explore such as different types of machine learning problems, different models, different metrics, and where to use them. You can try different things, in the same way, I did here so that you can see how it works. I will try to add more stories to give you deep dive into specific areas to help accelerate your learning.
這個故事的目的是讓您搶先學習機器學習,并瞥見可以用來加速過程的各種庫。 為了使這個故事簡短而準確,我提供了許多內容的簡單概述。 還有很多需要探索的東西,例如不同類型的機器學習問題,不同的模型,不同的度量標準以及在何處使用它們。 您可以用相同的方法嘗試不同的事情,我在這里做了,所以您可以了解它的工作原理。 我將嘗試添加更多故事,以使您深入了解特定領域,以幫助您加速學習。
Update 16th June 2020: Recently I found a way to combine Sklearn Pipeline with GridSearchCV to search for best preprocessing steps. If interested, check out this- Are you using Pipeline in Scikit-Learn?
2020年6月16日更新 :最近,我找到了一種將Sklearn Pipeline與GridSearchCV結合以搜索最佳預處理步驟的方法。 如果有興趣,請查看此- 您是否在Scikit-Learn中使用管道?
翻譯自: https://medium.com/swlh/start-your-data-science-journey-today-37366ee463f
大數據技術 學習之旅
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389276.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389276.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389276.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

純API函數實現串口讀寫。

數據可視化工具_數據可視化

Android Studio調試時遇見Install Repository and sync project的問題
: Ignite Java Thin Client)
Apache Ignite 學習筆記(二): Ignite Java Thin Client
論文及代碼解讀)
VGAE(Variational graph auto-encoders)論文及代碼解讀


tableau大屏bi_Excel,Tableau,Power BI ...您應該使用什么?

python 可視化工具_最佳的python可視化工具

網絡編程 socket介紹

猿課python 第三天

在C#中使用代理的方式觸發事件

BP神經網絡反向傳播手動推導

使用python和pandas進行同類群組分析
模式—精讀《JavaScript 設計模式》Addy Osmani著)
3.Contructor(構造器)模式—精讀《JavaScript 設計模式》Addy Osmani著
)
BZOJ 3653: 談笑風生(離線, 長鏈剖分, 后綴和)

搜索引擎優化學習原理_如何使用數據科學原理來改善您的搜索引擎優化工作
詳解)
Siamese網絡(孿生神經網絡)詳解

Dubbo 源碼分析 - 服務引用

期權價格的上限和下限
