清潔數據ploy n
As a bootcamp project, I was asked to analyze data about the sale prices of houses in King County, Washington, in 2014 and 2015. The dataset is well known to students of data science because it lends itself to linear regression modeling. You can take a look at the data over at Kaggle.com.
作為一個訓練營項目,我被要求分析有關2014年和2015年華盛頓州金縣的房屋售價數據。數據集對數據科學專業的學生來說是眾所周知的,因為它有助于進行線性回歸建模。 您可以在Kaggle.com上查看數據 。
In this post, I’ll describe my process of cleaning this dataset to prepare for modeling it using multiple linear regression, which allows me to consider the impact of multiple factors on a home’s sale price at the same time.
在這篇文章中,我將描述清理該數據集的過程,以準備使用多元線性回歸對它進行建模,這使我可以同時考慮多個因素對房屋售價的影響。
定義我的數據集 (Defining my dataset)
One of the interesting things about this dataset is that King County is home to some pretty massive wealth disparity, both internally and in comparison with state and national averages. Some of the world’s richest people live there, and yet 10% of the county’s residents live in poverty. Seattle is in King County, and the median household income of $89,675, 49% higher than the national average, can probably be attributed in part to the strong presence of the tech industry in the area. Home prices in the dataset range from a modest $78,000 to over $7 million.
關于此數據集,有趣的事情之一是,金縣在內部以及與州和全國平均水平相比都存在著相當大的財富差距。 一些世界上最富有的人居住在那里 ,但該縣10%的居民生活在貧困中 。 西雅圖位于金縣, 家庭收入中位數為89,675美元 ,比全國平均水平高49%,這可能部分歸因于該地區高科技產業的強大影響力。 數據集中的房屋價格從適中的$ 78,000到超過$ 7百萬。
# Import needed packages
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# Read in the data and view summary statistics
data = pd.read_csv('kc_house_data.csv')
data.describe()These disparities mean that it is hard to find a linear model that can describe the data while keeping error reasonably low. Common sense tells us that a twelve-bedroom house isn’t simply four times bigger than a three-bedroom house; it’s a mansion, a luxury villa, a thing of a different nature than a typical family home.
這些差異意味著很難找到一個可以描述數據并同時保持較低誤差的線性模型。 常識告訴我們,一間十二居室的房屋不僅僅是三居室的房屋的四倍。 這是一座豪宅,一棟豪華別墅,其性質與典型的家庭住宅不同。
While exploring this dataset, I decided that not only was I unlikely to find a model that could describe modest homes and mansions alike, I also didn’t want to. Billionaires, if you’re reading this: I’m sure there is someone else who can help you figure out how to maximize the sale price of your Medina mansion. I would rather use my skills to help middle-income families understand how they can use homeownership to build wealth.
在瀏覽此數據集時,我決定不僅不大可能找到一個可以描述謙虛的房屋和豪宅的模型,而且我也不想這么做。 億萬富翁,如果您正在閱讀此書:我敢肯定還有其他人可以幫助您找出如何最大化麥地那豪宅的銷售價格。 我寧愿使用自己的技能來幫助中等收入家庭了解如何利用房屋所有權來積累財富。
This thinking brought me to my first big decision about cleaning the data: I decided to cut it down to help me focus on midrange family homes. I removed the top 10% most expensive homes and then limited the remaining data to just those homes with 2 to 5 bedrooms.
這種想法使我做出了清理數據的第一個重大決定:我決定縮減數據范圍,以幫助我專注于中端家庭住宅。 我刪除了最昂貴的前10%房屋,然后將剩余數據限制為只有2到5個臥室的房屋。
# Filter the dataset
midrange_homes = data[(data['price'] < np.quantile(data['price'], 0.9))
& (data['bedrooms'].isin(range(2, 6)))]
# View summary statistics
midrange_homes.describe()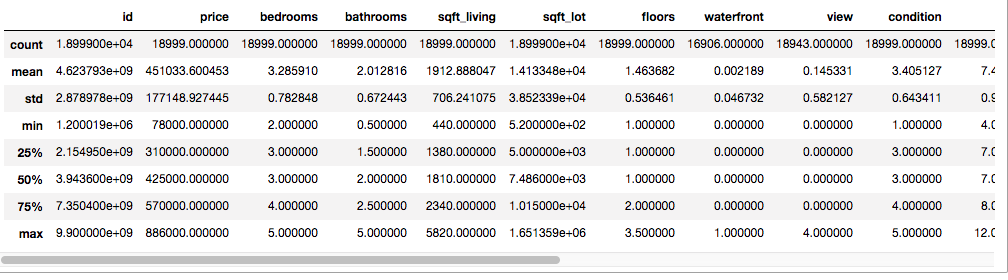
All told, this left me with 18,999 homes with a median sale price of $425,000. A little fiddling with a mortgage calculator persuaded me that this could be an affordable price for a family making the median income of $89,675, assuming they had excellent credit, could make a 14% downpayment, and got a reasonable interest rate.
總而言之,這給我留下了18,999套房屋,中位售價為425,000美元。 有點按揭計算器的說服我說這對于一個家庭中位數收入為89,675美元的家庭來說是一個負擔得起的價格,前提是他們擁有良好的信用,可以首付14%并獲得合理的利率。
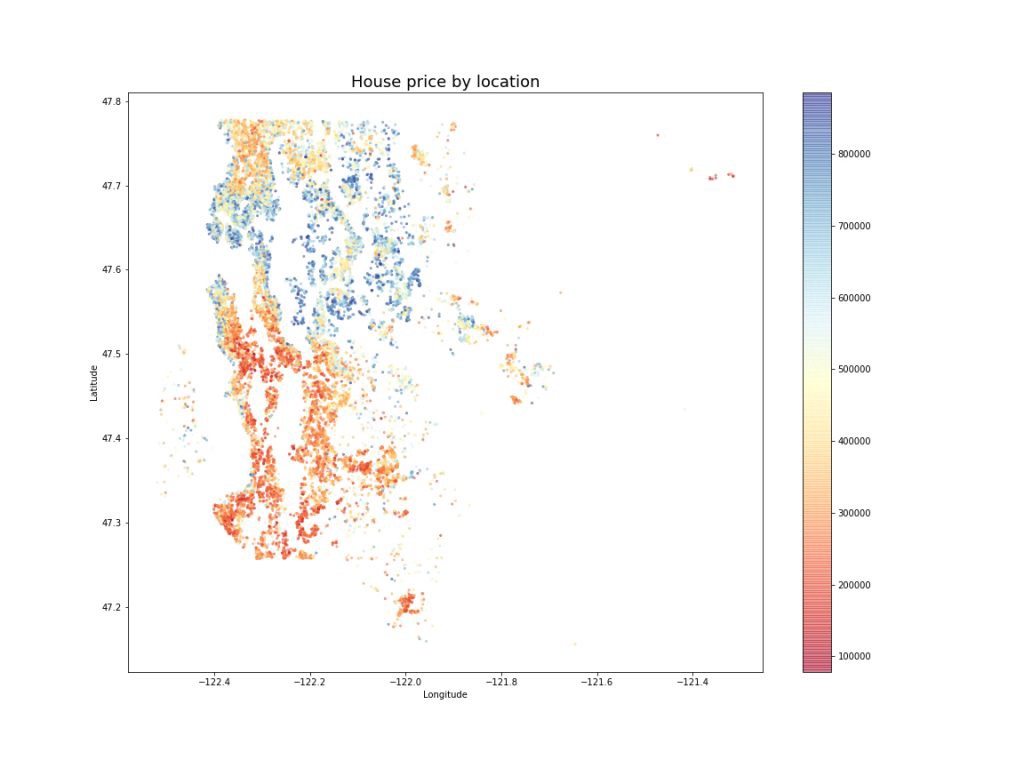
Limiting the price and number of bedrooms had a nice collateral effect of making most of the extreme values in the dataset disappear. At this point, I was ready to move on my first real cleaning steps: resolving missing values.
限制臥室的價格和數量具有很好的附帶效果,可以使數據集中的大多數極值消失。 此時,我已經準備好進行我的第一個實際清潔步驟:解決缺失的值。
不再缺少 (Missing no more)
Many datasets come with missing values, where someone forgot or chose not to collect or record a value for a particular variable in a particular observation. Missing values are a problem because they can interfere with several forms of analysis. They may be a different data type than the other values (e.g., text instead of a number). If lots of values are missing for a particular variable or observation, that column or row may be effectively useless, which is a waste of all the good values that were there. It is important to resolve missing values before doing any quantitative analysis so that we can better understand what our calculations actually represent.
許多數據集帶有缺失值,其中有人忘記或選擇不收集或記錄特定觀測值中特定變量的值。 缺少值是一個問題,因為它們會干擾幾種形式的分析。 它們可能是與其他值不同的數據類型(例如,文本而不是數字)。 如果大量的值都缺少特定變量或觀測,該列或行可能是有效沒用,這是所有在那里的良好價值觀的浪費。 在進行任何定量分析之前,解決缺失值很重要,這樣我們才能更好地理解我們的計算實際代表什么。
# Check for missing values by column
midrange_homes.isna().sum()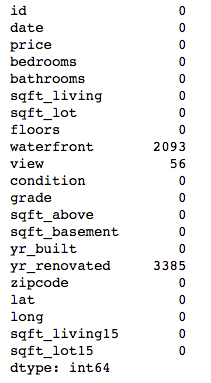
There are a couple of typical ways to resolve missing values. First, you can just remove the columns or rows with missing values from the dataset altogether. This definitely protects you from the perils of missing data, but at the expense of any perfectly good data that happened to be in one of those columns or rows.
有兩種解決缺失值的典型方法。 首先,您可以從數據集中完全刪除缺少值的列或行。 這無疑可以保護您免受丟??失數據的危害,但要以犧牲恰好在這些列或行之一中的任何完美數據為代價。
An alternative is to change the missing values to another value that you think is reasonable in context. This could be the mean, median, or mode of the existing values. It could also be some other value that conveys “missingness” while still being accessible to analysis, like 0, ‘not recorded,’ etc.
一種替代方法是將缺失值更改為您認為在上下文中合理的另一個值。 這可以是現有值的平均值,中位數或眾數。 它也可以是其他值,在傳達“缺失”的同時仍然可以進行分析,例如0,“未記錄”等。
My dataset had missing values in three columns: waterfront, view, and yr_renovated.
我的數據集缺少三列的值: waterfront , view和yr_renovated 。
Waterfront records whether a house is on a waterfront lot, with 1 apparently meaning “yes” and 0 “no.”
濱水區記錄房屋是否在濱水地帶,其中1個明顯表示“是”,0個表示“否”。

The meaning of the view column is not entirely clear. If you do some searching through other people’s uses of this dataset, you’ll see it interpreted in various ways. The best interpretation I found was that it reflects how much a house was viewed before it sold, and the numeric values (0 to 4) probably represent tiers of a scale rather than literal numbers of views.
視圖列的含義并不十分清楚。 如果您通過其他人對該數據集的使用進行搜索,您會發現它以各種方式被解釋。 我發現最好的解釋是,它反映了房屋出售前的景觀,數值(0到4)可能代表比例尺的等級,而不是視圖的字面數量。
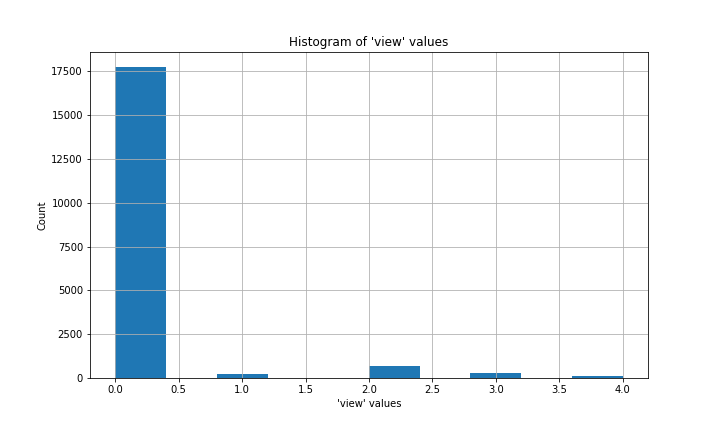
Yr_renovated is also a bit tricky. The vast majority of values are 0, with other values concentrated in the last few decades before 2014/2015.
Yr_renovated也有些棘手。 絕大多數值是0,其他值集中在2014/2015之前的最后幾十年。
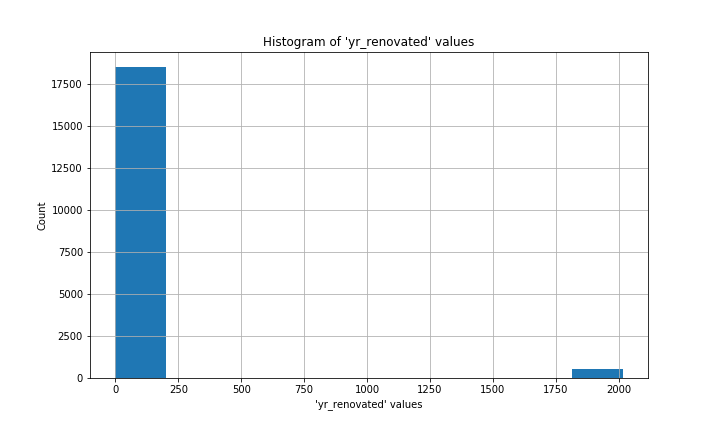
In each case, 0 was the most common value (the mode) by a long shot. I’ll never know whether the folks who recorded this data meant to put 0 for each missing value, or if those values were truly unknown. Under the circumstances, filling the missing values with 0 wouldn’t make a substantial difference to the overall distribution of values, so that is what I chose to do.
在每種情況下,從長遠來看,0是最常見的值(模式)。 我永遠不會知道記錄此數據的人是否打算為每個缺失值放入0,或者這些值是否真正未知。 在這種情況下,用0填充缺少的值不會對值的總體分布產生實質性的影響,所以我選擇這樣做。
# Fill missing values with 0, the mode of each column
midrange_homes['waterfront'] = midrange_homes['waterfront'].fillna(0.0)
midrange_homes['waterfront'] = midrange_homes['waterfront'].astype('int64')
midrange_homes['view'] = midrange_homes['view'].fillna(0.0).astype('int64')
midrange_homes['yr_renovated'] = midrange_homes['yr_renovated'].fillna(0)
midrange_homes['yr_renovated'] = midrange_homes['yr_renovated'].astype('int64')Looking at the info on this dataset, we can see that two columns — date and sqft_basement — are “objects” (i.e., text) while the rest are numbers (integers or decimal values, a.k.a. floats). But dates and basement square footage are values that I will want to treat like numbers, so I need to changes these columns to new datatypes.
查看此數據集上的信息,我們可以看到兩列( 日期和sqft_basement )是“對象”(即文本),其余兩列是數字(整數或十進制值,又稱浮點數)。 但是日期和地下室平方英尺是我想要像數字一樣對待的值,因此我需要將這些列更改為新的數據類型。
# Review column datatypes
midrange_homes.info()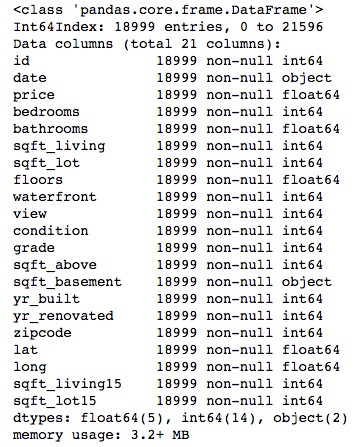
Date is a little tricky because it contains three pieces of information (day, month, and year) in one string. Converting it to a “datetime” object won’t do me much good; I know from experimentation that my regression model doesn’t like datetimes as inputs. Because all the observations in this dataset come from a short period in 2014–2015, there’s not much I can learn about changes over time in home prices. The month of each sale is the only part that really interests me, because it could help me detect a seasonal pattern in sale prices.
日期有點棘手,因為它在一個字符串中包含三個信息(日,月和年)。 將其轉換為“ datetime”對象對我沒有多大幫助; 從實驗中我知道,我的回歸模型不喜歡日期時間作為輸入。 由于此數據集中的所有觀察值均來自2014-2015年的短期時間,因此我對房價隨時間的變化了解不多。 每個銷售月份都是我真正感興趣的唯一部分,因為它可以幫助我發現銷售價格的季節性模式。
I use the string .split() method in a list comprehension to grab just the month from each date and put it into a new column. The original date column can now be eliminated in the next step.
我在列表推導中使用字符串.split()方法從每個日期中僅獲取月份并將其放入新列中。 現在可以在下一步中刪除原始日期列。
# Create 'month' column
midrange_homes['month'] = [x.split('/')[0] for x in midrange_homes['date']]
midrange_homes['month'] = pd.to_numeric(midrange_homes['month'],
errors='coerce')停止,拖放和.info() (Stop, drop, and .info())
Now I’m ready to drop some columns that I don’t want to consider when I build my multiple linear regression model.
現在,我準備刪除一些在構建多元線性回歸模型時不想考慮的列。
I don’t want id around because it is supposed to be a unique identifier for each sale record — a serial number, basically — and I don’t expect it to have any predictive power.
我不想要id ,因為它應該是每個銷售記錄的唯一標識符(基本上是序列號),而且我不希望它具有任何預測能力。
Date isn’t needed anymore because I now have the month of each sale stored in the month column.
不再需要日期 ,因為我現在將每個銷售的月份存儲在month列中。
Remember sqft_basement, a numeric column trapped in a text datatype? I didn’t bother coercing it to integers or floats above because I noticed that sqft_living appears to be the sum of sqft_basement and sqft_above. My focus is on things that a family can do to maximize the sale price of their home, and I doubt many people are going to shift the balance of above- versus below-ground space in their homes without also increasing overall square footage. I’ll drop the two more specific columns in favor of using sqft_living to convey similar information.
還記得sqft_basement ,它是捕獲在文本數據類型中的數字列嗎? 我沒有麻煩將其強制為整數或浮于上面,因為我注意到sqft_living似乎是sqft_basement和sqft_above的總和。 我的重點是家庭可以做的事情,以使房屋的銷售價格最大化,而且我懷疑許多人會在不增加整體建筑面積的情況下轉移房屋中地面和地下空間之間的平衡。 我將刪除兩列更具體的列,以利于使用sqft_living傳達相似的信息。
# Drop unneeded columns
midrange_homes.drop(['id', 'date', 'sqft_above', 'sqft_basement'],
axis=1, inplace=True)# Review the remaining columns
midrange_homes.info()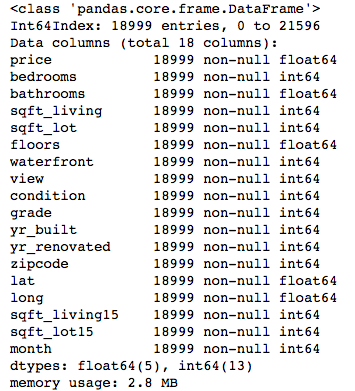
What remains is a DataFrame with 18,999 rows and 18 columns, all numeric datatypes, perfect for regression modeling.
剩下的是一個具有18,999行和18列的DataFrame,所有數字數據類型,非常適合回歸建模。
這是絕對的,假的 (It’s categorical, dummy)
So I fit models to a few minor variations of my dataset, but the results weren’t what I wanted. I was getting adjusted R-squared values around 0.67, which meant that my model was only describing 67% of the variability in home price in this dataset. Given the limits of the data itself — no info on school districts, walkability of the neighborhood, flood risk, etc. — my model is never going to explain 100% of the variability in price. Still, 67% is lower than I would like.
因此,我將模型擬合到數據集的一些細微變化,但結果并非我想要的。 我得到的調整后R平方值約為0.67,這意味著我的模型僅描述了該數據集中房屋價格波動的67%。 考慮到數據本身的局限性-沒有關于學區,鄰里的可步行性,洪水風險等的信息-我的模型永遠無法解釋100%的價格變化。 仍然比我想要的低67%。
As I mentioned above, King County is home to some extremes of wealth, and even though I excluded the most expensive houses from my dataset, I didn’t exclude their more modest neighbors. The locations of the houses, expressed through zipcode, could be having an effect on price. On my instructor’s advice, I tried one-hot encoding on the zipcode column.
正如我上面提到的,金縣擁有一些極端的財富,即使我從數據集中排除了最昂貴的房屋,也沒有排除他們較謙虛的鄰居。 用郵政編碼表示的房屋位置可能會對價格產生影響。 根據老師的建議,我在zipcode列上嘗試了一次熱編碼。
# Generate dummy variables
zip_dummies = pd.get_dummies(midrange_homes['zipcode'], prefix='zip')# Drop the original 'zipcode' column
mh_no_zips = midrange_homes.drop('zipcode', axis=1)# Concatenate the dummies to the copy of 'midrange_homes'
mh_zips_encoded = pd.concat([mh_no_zips, zip_dummies], axis=1)# Drop one of the dummy variables
mh_zips_encoded.drop('zip_98168', axis=1, inplace=True)One-hot encoding, also known as creating dummy variables, takes a variable and splits each unique value off into its own column filled with zeroes and ones. In this case, I ended up with a column for each zipcode in the dataset, filled with a 1 if a house was in that zip code and 0 if not. I then dropped one zipcode column arbitrarily to represent a default location. The coefficients my model generated for the other zipcodes would represent what a homeowner stood to gain or lose by having their home in those zipcodes as opposed to the dropped one.
一鍵編碼,也稱為創建偽變量,它采用一個變量并將每個唯一值拆分為由零和一填充的自己的列。 在這種情況下,我最后為數據集中的每個郵政編碼添加一列,如果該郵政編碼中有房屋,則填充為1,否則填充0。 然后,我任意刪除一個郵政編碼列以表示默認位置。 我的模型為其他郵政編碼生成的系數將代表房主通過將自己的房屋置入這些郵政編碼而不是丟棄的郵政編碼中而獲得或失去的東西。
Treating zipcodes as a categorical variable instead of a continuous, quantitative one paid off immediately: the adjusted R-squared value jumped to 0.82. My model could now explain 82% of the variability in price across this dataset. With that happy outcome, I was ready to move on to validating the model, or testing its ability to predict the prices of houses it hadn’t encountered yet.
將郵政編碼視為一種分類變量,而不是一個連續的,定量的變量立即得到了回報:調整后的R平方值躍升至0.82。 我的模型現在可以解釋此數據集內82%的價格波動。 有了這個令人欣喜的結果,我準備繼續驗證模型,或測試其預測尚未遇到的房屋價格的能力。
That’s a summary of how I explored and cleaned the data for my project on house prices in King County, Washington. You can read my code or look at the slides of a non-technical presentation of my results over on my GitHub repository.
這是我如何瀏覽和清理華盛頓金縣房價項目數據的摘要。 您可以在GitHub存儲庫上閱讀我的代碼或查看結果的非技術性演示的幻燈片。
Cross-posted from jrkreiger.net.
從 jrkreiger.net 交叉發布 。
翻譯自: https://medium.com/swlh/cleaning-house-data-4fcc09017b6c
清潔數據ploy n
本文來自互聯網用戶投稿,該文觀點僅代表作者本人,不代表本站立場。本站僅提供信息存儲空間服務,不擁有所有權,不承擔相關法律責任。 如若轉載,請注明出處:http://www.pswp.cn/news/389037.shtml 繁體地址,請注明出處:http://hk.pswp.cn/news/389037.shtml 英文地址,請注明出處:http://en.pswp.cn/news/389037.shtml
如若內容造成侵權/違法違規/事實不符,請聯系多彩編程網進行投訴反饋email:809451989@qq.com,一經查實,立即刪除!相關文章

redis安裝redis集群

聯想拯救者y7000p加內存條_內存、硬盤不夠用?手把手教你升級聯想拯救者Y7000P...

機器學習實踐一 logistic regression regularize

ajax+webservice

深度學習數據擴張_適用于少量數據的深度學習結構


基于邊緣計算的實時績效_基于績效的營銷中的三大錯誤


Maven Web項目解決跨域問題

為什么Facebook的API以一個循環作為開頭?

城市軌道交通運營票務管理論文_城市軌道交通運營管理專業就業前景怎么樣?中職優選告訴你...

計算機視覺對掃描文件分類 OCR

從錢龍數據中讀取股票權息信息導入到數據庫

笑話生成器_爸爸笑話發生器

AWS Amplify Console:賦予應用程序快速部署的能力

機器學習實踐二 -多分類和神經網絡

Hadoop 倒排索引

koa2異常處理_讀 koa2 源碼后的一些思考與實踐

Bind9的dns解析服務
