通過計算機視覺對掃描文件分類
一種解決掃描文檔分類問題的深度學習方法
在數字經濟時代, 銀行、保險、治理、醫療、法律等部門仍在處理各種手寫票據和掃描文件。在業務生命周期的后期, 手動維護和分類這些文檔變得非常繁瑣。
對這些非機密文檔進行簡單而有意義的自動化處理,將使維護和利用信息變得容易的多,并顯著減少手工工作。

本案例研究的目的是開發一個基于深度學習的解決方案,可以自動分類的文件
Data:
在這個案例研究中,我們將使用RVL-CDIP (Ryerson Vision Lab Complex Document Information Processing)數據集,該數據集包含16個類中的400,000張灰度圖像,每個類包含25,000張圖像。有32萬張訓練圖像、4萬張驗證圖像和4萬張測試圖像。圖像的大小,使他們的最大尺寸不超過1000像素。這個數據集的大小超過200 GB。
Business-ML問題映射:
我們可以將業務問題映射為一個多類分類問題。當前的數據集中有16個類,我們需要根據被掃描文檔的像素值來預測文檔的類,這使得問題更加困難。但是等等,**為什么我們不能使用OCR來提取文本并應用NLP技術呢?**是的,我們對這個想法也很興奮,但是低質量的掃描導致了文本提取的低質量。在實際的業務場景中,我們也無法控制掃描的質量,因此依賴OCR的模型可能會在適當的預處理后泛化能力較差。
KPI和業務約束:
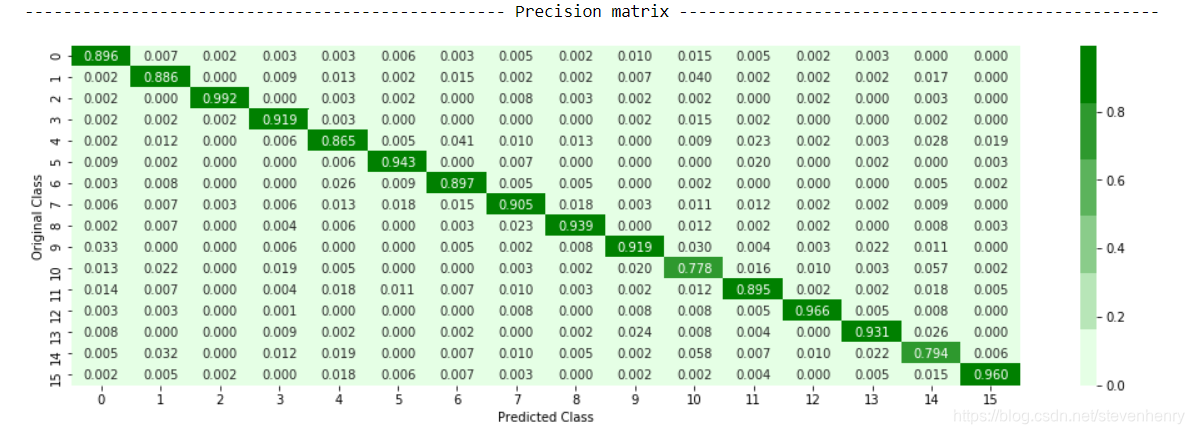
數據集相當平衡。因此,我們選擇準確性作為主要指標,微平均F1分數作為次要指標來懲罰分類錯誤的數據點。我們還使用了混淆度量來驗證模型的性能。有一個中等的延遲需求,沒有特定的可解釋性需求。
我們能從文檔的像素強度和大小中得到任何信息嗎?
讓我們嘗試使用箱形圖來可視化文檔的平均像素強度和大小
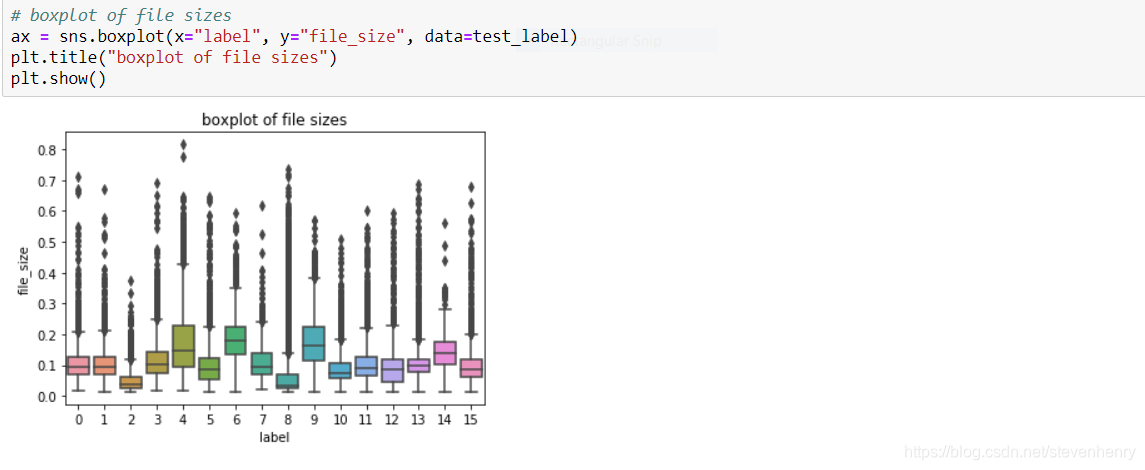
從box plot中我們可以觀察到,某些類型的掃描文檔的大小與其他類型的非常不同,但是也存在重疊。例如,類13和類9的文件大小差別很大,但是類9的大小與類4和類6、類7重疊。
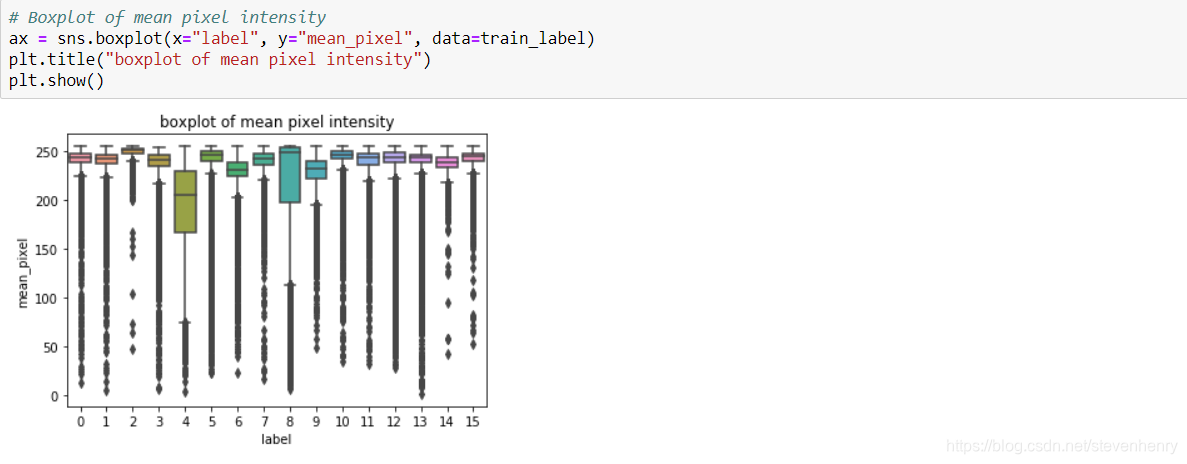
我們可以觀察到75%的案例中,class 4的平均像素強度在160-230像素之間。但是對于大約50%的情況,它也與類6的平均像素值重疊。對于其他類,平均像素值重疊。
分析方法
為了解決這個問題,我們對擴充數據進行卷積神經網絡(CNN)訓練。我們嘗試在有和沒有數據擴充的情況下訓練模型,兩種結果進行比較。
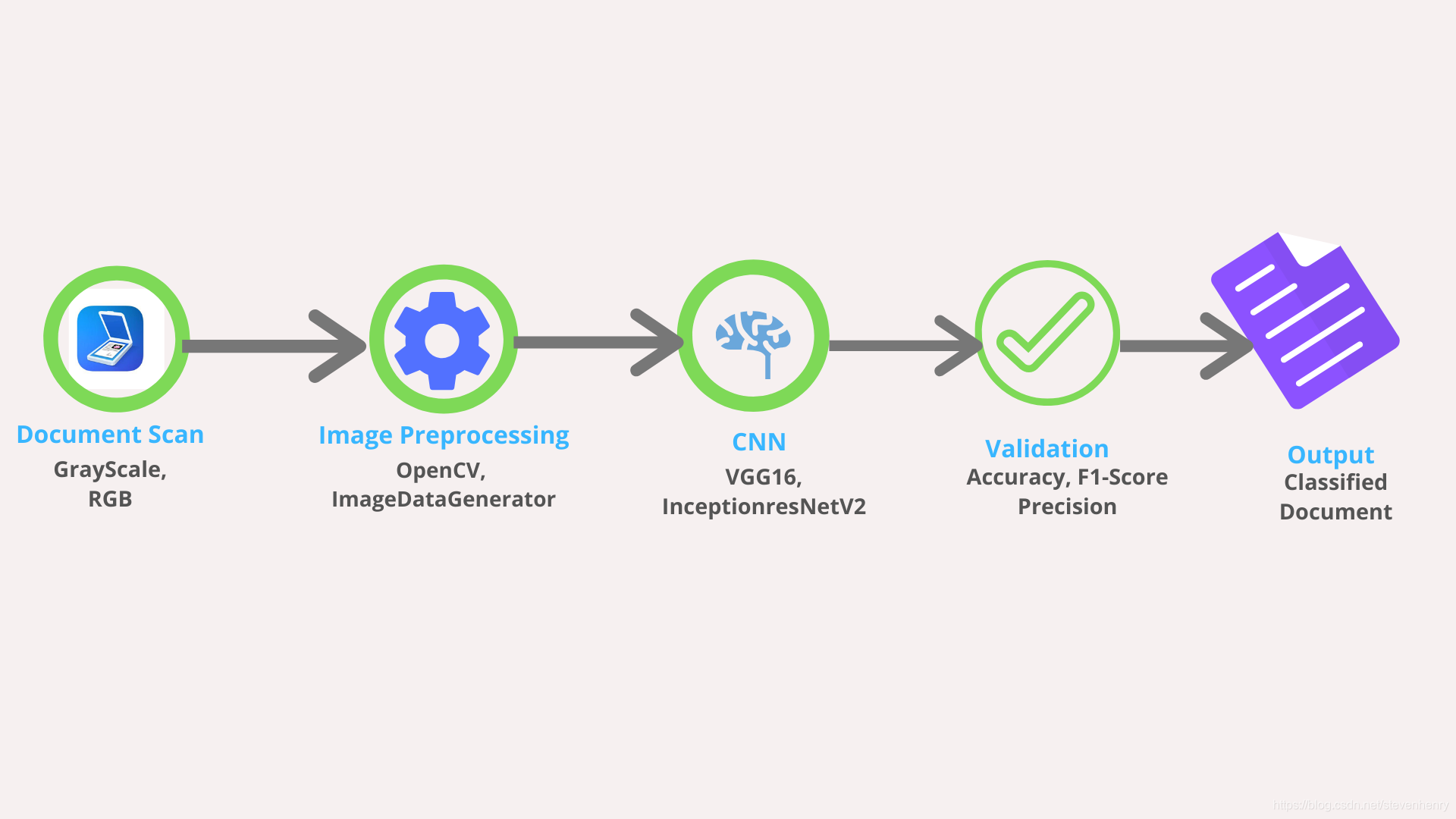
太棒了!但是如何確定網絡架構呢?你是如何訓練網絡的,因為數據不能一次放入內存?
從零開始訓練神經網絡需要大量的時間和集中計算資源,為了避免這種情況,我們采用了轉移學習。我們從在ImageNet數據集上訓練的預訓練網絡的權值開始,然后在我們的數據集上重新訓練。針對這類問題的當前SOTA模型使用域內和域內轉移學習,其中圖像被分成四個部分:頁眉、頁腳、左身體和右身體。首先利用預先訓練好的VGG16模型對整個圖像(域內)進行訓練,然后利用該模型對部分圖像(域內)進行訓練。
在這個實驗中,我們采用了一種稍微不同的方法。我們沒有使用VGG16進行域內轉移學習,而是訓練了兩個并行模型VGG16和InceptionResNetV2,并使用它們的堆棧作為我們的最終模型。我們的假設是,由于這兩種模型的架構不同,它們會學習圖像的不同方面,將它們疊加起來會得到很好的泛化效果。但是我們如何選擇這些模型呢?這基本上來自交叉驗證的結果。我們嘗試了各種網絡架構,如VGG16、VGG19、DenseNet、ResNet、InceptionNet,并選出了最好的兩個。
我們使用keras的ImageDataGenerator類對訓練數據進行預處理和加載,而不是在內存中加載整個數據。

好的, 但是如何處理超參數呢?
對于任何CNN,超參數是:學習率,池大小,網絡大小,批量大小,優化器的選擇,正則化,輸入大小等。
學習率對神經網絡的收斂性有重要影響。在深度學習問題中使用的損失函數是非凸的,這意味著在存在多個局部極小值和鞍點的情況下,尋找全局極小值不是一件容易的事情。如果學習率太低,它會慢慢收斂;如果學習率太高,它會開始振蕩。在這個案例研究中,我們使用了一種叫做“循環學習速率”的技術,其目的是訓練神經網絡,使每個訓練批次的學習速率以循環方式變化。
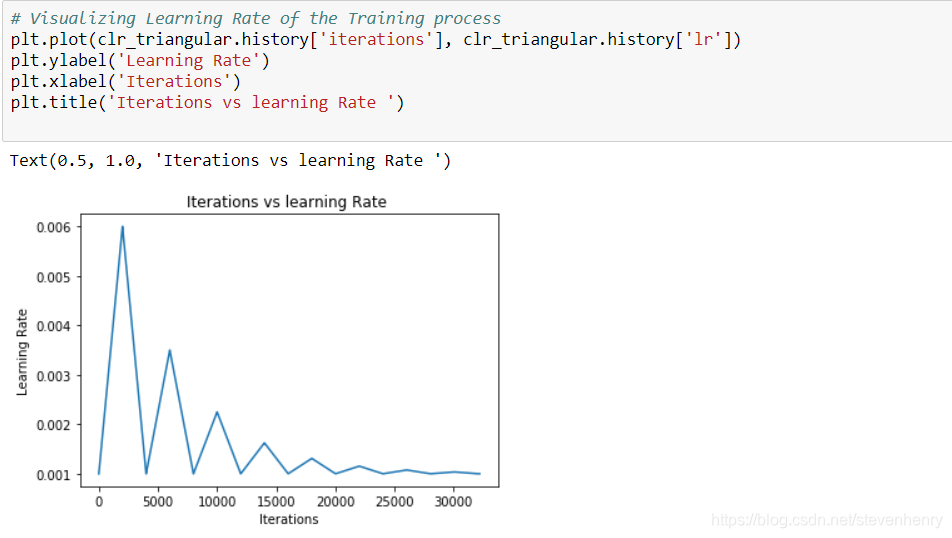
但為什么會這樣呢? 在CLR中,我們在一個閾值內改變學習率。周期性的高學習率有助于克服它的鞍點或局部極小值。
對于其他超參數,我們開發了自定義實用程序函數來檢查哪種配置工作得更好。假設10個epoch之后,準確率是47%我們將使用此模型作為測試基線,并使用實用工具函數檢查哪個配置集(即batch_size/optimizer/learning_rate)將在以后的epochs帶來更高的準確性
結果
我們使用VGG16模型獲得了90.7%的準確率,使用InceptionResNetV2獲得了88%的準確率。上述兩種模型的比例疊加模型訓練正確率為97%,測試正確率為91.45%。

you can find the full implementation here.
Citation:
- A. W. Harley, A. Ufkes, K. G. Derpanis, “Evaluation of Deep Convolutional Nets for Document Image Classification and Retrieval,” in ICDAR, 2015.
- https://arxiv.org/abs/1506.01186
- https://www.researchgate.net/publication/332948719_Segmentation_of_Scanned_Documents_Using_Deep-Learning_Approach









)




)




