OLAP 數據庫設計的宗旨在于分析適合一次插入多次查詢的業務場景,市面上成熟的 AP 數據庫在更新和刪除操作上支持的均不是很好,當然 clickhouse 也不例外。但是不友好不代表不支持,本文主要介紹在 clickhouse 中如何實現數據的刪除,以及最新版本中 clickhouse 所做的一些技術突破
一、mutation
剛接觸 clickhouse 的小伙伴或許對 mutation 就很熟悉了,mutation 查詢可以看成 alter 語句的變種。雖然 mutation 能夠最終實現修改和刪除的需求,但不能完全用通常意義的 delete 和 update 來理解,我們需要清醒的認識到它的不同:
- mutation 是一個很重的操作,適合批量數據操作
- 不支持事務、一旦操作立刻生效無法回滾
- mutation 為異步操作
1.1 實操
創建一張表用于測試 mutation 操作
create table mutations_operate
(UserId UInt64,Score UInt64,CreateTime DateTime
) engine = MergeTree()partition by toYYYYMMDD(CreateTime)order by UserId;
接下來分別插入兩批不同分區的數據
insert into mutations_operate
select number,abs(number - 100),'2023-08-08 00:00:00'
from system.numbers
limit 1000000;insert into mutations_operate
select number,abs(number - 100),'2023-08-09 00:00:00'
from system.numbers
limit 1000000;
嘗試刪除 20230808 分區中 1000-10000 之間的所有數據,sql 如下
alter table mutations_operate delete where toYYYYMMDD(CreateTime) = 20230808 and UserId between 1000 and 10000;
可以統計一下該分區的數據條數來確認是否成功刪除,從體驗來說目前的數據規模感受不到 mutation 的“重”,感覺像是瞬間完成的。
當然我們也可以查看system.mutations表來監控 mutation 操作的進度
select table, mutation_id, `block_numbers.number` as num, is_done
from system.mutations;Query id: 0878a0f1-a5ff-474c-8f84-518ce5dc5e1d┌─table─────────────┬─mutation_id────┬─num─┬─is_done─┐
│ mutations_operate │ mutation_3.txt │ [3] │ 1 │
└───────────────────┴────────────────┴─────┴─────────┘1 row in set. Elapsed: 0.002 sec.
mutation_id 是一個日志文件,可以在表存儲目錄中查看,完整記錄了本次操作的語句和時間,例如
format version: 1
create time: 2023-08-09 18:54:06
commands: DELETE WHERE (toYYYYMMDD(CreateTime) = 20230808) AND ((UserId >= 1000) AND (UserId <= 10000))
而其中的 3 以及block_numbers.number是 mutation 號,每執行一條 delete 或 update 語句都會對應一個唯一的編號
id_done 表示本次 mutation 操作是否執行完成,1 表示已經完成
1.2 原理
為了探尋 mutation 操作的原理和執行流程重置一下表數據(刪除重建即可),在插入兩批數據后查看磁盤目錄
? du -h0B ./detached
7.7M ./20230809_2_2_0
7.7M ./20230808_1_1_015M .
可以看到兩個分區目錄均是 7.7M
嘗試執行刪除操作后,可以在日志中看到下面的查詢信息
<Debug> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): Key condition: unknown, (column 0 in [1000, +Inf)), (column 0 in (-Inf, 10000]), and, and
<Debug> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): Key condition: unknown, (column 0 in [1000, +Inf)), (column 0 in (-Inf, 10000]), and, and
<Debug> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): MinMax index condition: (toYYYYMMDD(column 0) in [20230808, 20230808]), unknown, unknown, and, and
<Debug> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): MinMax index condition: (toYYYYMMDD(column 0) in [20230808, 20230808]), unknown, unknown, and, and
<Trace> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): Running binary search on index range for part 20230808_1_1_0 (124 marks)
<Trace> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): Found (LEFT) boundary mark: 0
<Debug> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): Selected 0/1 parts by partition key, 0 parts by primary key, 0/0 marks by primary key, 0 marks to read from 0 ranges
<Trace> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): Found (RIGHT) boundary mark: 2
<Trace> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): Found continuous range in 13 steps
<Debug> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): Selected 1/1 parts by partition key, 1 parts by primary key, 2/123 marks by primary key, 2 marks to read from 1 ranges
<Trace> delete_operate.mutations_operate (7f120927-b71e-4f85-a06c-21a94b7f89e3) (SelectExecutor): Spreading mark ranges among streams (default reading)
<Trace> MergeTreeInOrderSelectProcessor: Reading 1 ranges in order from part 20230808_1_1_0, approx. 16384 rows starting from 0
<Trace> Aggregator: Aggregation method: without_key
<Trace> AggregatingTransform: Aggregated. 0 to 1 rows (from 0.00 B) in 0.000570041 sec. (0.000 rows/sec., 0.00 B/sec.)
<Trace> Aggregator: Merging aggregated data
<Trace> MutateTask: Part 20230809_2_2_0 doesn't change up to mutation version 3
首先,clickhouse 會使用我們執行的刪除語句中附帶的 where 條件在每個分區中執行 count 查詢,為了判斷哪些分區有需要被刪除的數據,從日志可以看出Reading 1 ranges in order from part 20230808_1_1_0, approx. 16384 rows starting from 0以及Part 20230809_2_2_0 doesn't change up to mutation version 3。注意日志中所說 20230808 的范圍是 0~16384 并不是實際刪除的范圍,而是索引的范圍。我們知道 mergeTree 引擎默認的跳數索引的間隔是 8192 而我們刪除的數據范圍是 1000-10000,顯然作為一個整周期自然是 0-16384(2x8192)
當我們再次查看磁盤目錄
? du -h0B ./detached
7.7M ./20230809_2_2_0
7.7M ./20230808_1_1_00B ./20230809_2_2_0_3
7.6M ./20230808_1_1_0_323M .
總目錄從 15M 變成了 23M,而兩個分區也都各自生成了一個以 mutation version 為后綴的新分區
因此接下來的邏輯如下:
clickhouse 會創建一個 tmp_mut_ 為前綴、mutation version 為后綴的臨時分區目錄,例如這里的就是 tmp_mut_20230808_1_1_0_3
對于需要刪除的分區,會在 tmp_mut 目錄中生成全新的 .bin 和 .mrk 文件
對于無需刪除的分區,clickhouse 會創建一個 tmp_clone_ 為前綴、mutation version 為后綴的臨時分區目錄并將原分區里面的數據以硬鏈接的方式拷貝過去,并修改目錄名稱為正確的格式
下面是執行的日志情況
<Debug> delete_operate.mutations_operate (4351d317-2cd6-4328-85fe-49d5beeff5c3): Clone part /opt/homebrew/var/lib/clickhouse/store/435/4351d317-2cd6-4328-85fe-49d5beeff5c3/20230809_2_2_0/ to /opt/homebrew/var/lib/clickhouse/store/435/4351d317-2cd6-4328-85fe-49d5beeff5c3/tmp_clone_20230809_2_2_0_3
<Trace> delete_operate.mutations_operate (4351d317-2cd6-4328-85fe-49d5beeff5c3): Renaming temporary part tmp_clone_20230809_2_2_0_3 to 20230809_2_2_0_3 with tid (1, 1, 00000000-0000-0000-0000-000000000000).
<Trace> MergedBlockOutputStream: filled checksums 20230808_1_1_0_3 (state Temporary)
<Trace> delete_operate.mutations_operate (4351d317-2cd6-4328-85fe-49d5beeff5c3): Renaming temporary part tmp_mut_20230808_1_1_0_3 to 20230808_1_1_0_3 with tid (1, 1, 00000000-0000-0000-0000-000000000000)
從磁盤目錄也可以佐證這一點,首先上面的 20230809_2_2_0_3 占用空間為 0B,當然這是 mac 獨有的現實方式,在其它 linux 系統不一定是這么顯示,進入各個分區查看一下
wjun :: data/delete_operate/mutations_operate ?stable? ? ll 20230808_1_1_0_3
total 15632
-rw-r-----@ 1 wjun admin 17863 Aug 9 19:36 CreateTime.bin
-rw-r-----@ 1 wjun admin 369 Aug 9 19:36 CreateTime.cmrk2
-rw-r-----@ 1 wjun admin 3968891 Aug 9 19:36 Score.bin
-rw-r-----@ 1 wjun admin 409 Aug 9 19:36 Score.cmrk2
-rw-r-----@ 1 wjun admin 3969011 Aug 9 19:36 UserId.bin
-rw-r-----@ 1 wjun admin 409 Aug 9 19:36 UserId.cmrk2
-rw-r-----@ 1 wjun admin 490 Aug 9 19:36 checksums.txt
-rw-r-----@ 1 wjun admin 90 Aug 9 19:36 columns.txt
-rw-r-----@ 1 wjun admin 6 Aug 9 19:36 count.txt
-rw-r-----@ 1 wjun admin 10 Aug 9 19:36 default_compression_codec.txt
-rw-r-----@ 1 wjun admin 1 Aug 9 19:36 metadata_version.txt
-rw-r-----@ 1 wjun admin 8 Aug 9 19:36 minmax_CreateTime.idx
-rw-r-----@ 1 wjun admin 4 Aug 9 19:36 partition.dat
-rw-r-----@ 1 wjun admin 188 Aug 9 19:36 primary.cidx
wjun :: data/delete_operate/mutations_operate ?stable? ? ll 20230809_2_2_0_3
total 15768
-rw-r-----@ 2 wjun admin 18042 Aug 9 19:35 CreateTime.bin
-rw-r-----@ 2 wjun admin 375 Aug 9 19:35 CreateTime.cmrk2
-rw-r-----@ 2 wjun admin 4004938 Aug 9 19:35 Score.bin
-rw-r-----@ 2 wjun admin 415 Aug 9 19:35 Score.cmrk2
-rw-r-----@ 2 wjun admin 4004915 Aug 9 19:35 UserId.bin
-rw-r-----@ 2 wjun admin 415 Aug 9 19:35 UserId.cmrk2
-rw-r-----@ 2 wjun admin 490 Aug 9 19:35 checksums.txt
-rw-r-----@ 2 wjun admin 90 Aug 9 19:35 columns.txt
-rw-r-----@ 2 wjun admin 7 Aug 9 19:35 count.txt
-rw-r-----@ 2 wjun admin 10 Aug 9 19:35 default_compression_codec.txt
-rw-r-----@ 2 wjun admin 8 Aug 9 19:35 minmax_CreateTime.idx
-rw-r-----@ 2 wjun admin 4 Aug 9 19:35 partition.dat
-rw-r-----@ 2 wjun admin 173 Aug 9 19:35 primary.cidx
20230809_2_2_0_3 分區 inode 被連接次數為 2 表示建立了硬鏈接。
因此 mutation 的刪除邏輯如下:
- 每個分區執行附帶刪除操作的 where 條件的 count 查詢,獲取需要執行刪除操作的分區
- 對于需要執行刪除操作的分區會創建一個臨時目錄并生成全新(刪除需要刪除的行)的文件,隨后 rename 分區
- 對于無需執行刪除操作的分區會創建一個臨時目錄并以硬鏈接的方式拷貝文件,隨后 rename 分區
- 原分區在
system.parts中會被置為 inactive 狀態 - 在下一次 merge 是刪除原分區
而對于更新操作基本邏輯一致,需要注意的是需要執行更新操作的分區會有如下兩種情況:
- 分區類型為 wide:只會重新生成受影響行的 bin 和 mrk 文件,不受影響的文件以硬鏈接的方式拷貝
- 分區類型為 compact:因為所有列都是一個文件,因此會重新生成 bin 和 mrk 文件
更新和刪除操作流程不一致的原因是:刪除影響全部列而更新只影響部分列
mergeTree 表的分區類型分為 wide 和 compact 兩種受
min_bytes_for_wide_part和min_rows_for_wide_part參數影響。wide 類型的分區一個列一個文件,compact 類型的分區所有列公用一個文件,當分區數據的行數和字節較小時為 compact 類型,不管是查詢所有字段或某個字段相對較快;當數據量很大時就會以列式存儲來追求 AP 查詢性能
1.3 不足
當我們走一遍 mutation 時發現在刪除任務完成后表 merge 前的這一段時間磁盤空間不減反增,這個就讓用戶很難接受了。因此就可能會出現因為磁盤空間不足想要刪除數據,結果刪除操作導致空間進一步不足的窘境。同時 mutation 會重寫受影響的分區,這也是 mutation 操作重的原因所在。
二、mergeTree
對于 clickhouse 這類高性能分析型數據庫而言,修改源文件是一件非常奢侈且代價昂貴的操作,相對于直接修改源文件,我們將修改和新增操作都轉換為新增操作,即以增代刪將是一個非常不錯的選擇。是不是和 Hbase 的思路十分接近。在 mergeTree 家族中有一個特殊的表引擎叫 CollapsingMergeTree,翻譯過來叫折疊合并樹引擎就是提供了這樣的功能。它通過定義一個 sign 標記字段來記錄數據行的狀態。如果 sign 為 1 表示這是一行有效的數據,如果 sign 為 -1 表示這行數據被刪除。當 CollapsingMergeTree 分區合并時同一分區的 +1、-1 將會被抵消,猶如一張紙折疊一般。
2.1 實操
創建 CollapsingMergeTree 表
create table collapsing_table
(Id String,Code Int32,CreateTime DateTime,Sign Int8
) engine = CollapsingMergeTree(Sign)partition by toYYYYMMDD(CreateTime)order by Id;
注:和其它 mergeTree 引擎一樣 CollapsingMergeTree 依然是以 order by 字段作為后續數據唯一性的依據
插入一批原始數據
insert into collapsing_table values ('A000', 100, '2023-08-09 00:00:00', 1);
insert into collapsing_table values ('A001', 100, '2023-08-09 00:00:00', 1);
insert into collapsing_table values ('A002', 100, '2023-08-09 00:00:00', 1);
修改 A000 的 Code 為 200 并刪除 A002 的數據
# 修改 A000 的 Code 為 200
insert into collapsing_table values ('A000', 100, '2023-08-09 00:00:00', -1);
insert into collapsing_table values ('A000', 200, '2023-08-09 00:00:00', 1);
# 刪除 A002 的數據
insert into collapsing_table values ('A002', 100, '2023-08-09 00:00:00', -1);
# 手動執行一下分區合并操作
optimize table collapsing_table final;
可以觀察到數據已經被刪除和修改。
CollapsingMergeTree 在分區合并折疊數據的時候,遵循下面規則
- 如果 sign = 1 比 sign = -1 多一行,最后保留 sign = 1 的數據
- 如果 sign = 1 比 sign = -1 少一行,最后保留 sign = -1 的數據
- 如果 sign = 1 和 sign = -1 一樣多,且最后一行時 sign = 1,則保留第一行的 sign = -1 和最后一行 sign = 1
- 如果 sign = 1 和 sign = -1 一樣多,且最后一行時 sign = -1,則什么也不保留
- 其余情況 clickhouse 會打印告警日志,但不會報錯且查詢情況不可預知
2.2 不足
當前表的數據如下
select *
from collapsing_table;Query id: 4b1da757-d02a-4b88-92e5-1fe659ca462c┌─Id───┬─Code─┬──────────CreateTime─┬─Sign─┐
│ A002 │ 300 │ 2023-08-09 00:00:00 │ -1 │
└──────┴──────┴─────────────────────┴──────┘
┌─Id───┬─Code─┬──────────CreateTime─┬─Sign─┐
│ A002 │ 300 │ 2023-08-09 00:00:00 │ 1 │
└──────┴──────┴─────────────────────┴──────┘
┌─Id───┬─Code─┬──────────CreateTime─┬─Sign─┐
│ A000 │ 200 │ 2023-08-09 00:00:00 │ 1 │
│ A001 │ 100 │ 2023-08-09 00:00:00 │ 1 │
└──────┴──────┴─────────────────────┴──────┘4 rows in set. Elapsed: 0.003 sec.
從操作來看 A002 是要被刪除的
但是如果查詢sql如下
select Id, sum(Code), count(Code), avg(Code)
from collapsing_table
group by Id;Query id: 610f6503-1344-4ba0-9564-6327277ffe95┌─Id───┬─sum(Code)─┬─count(Code)─┬─avg(Code)─┐
│ A001 │ 100 │ 1 │ 100 │
│ A000 │ 200 │ 1 │ 200 │
│ A002 │ 600 │ 2 │ 300 │
└──────┴───────────┴─────────────┴───────────┘3 rows in set. Elapsed: 0.005 sec.
此時的結果是不對的,因此需要改寫 sql
select Id, sum(Code * Sign), count(Code * Sign), avg(Code * Sign)
from collapsing_table
group by Id
having sum(Sign) > 0;Query id: a3fe84d0-33a5-4287-bd02-49ab03df1852┌─Id───┬─sum(multiply(Code, Sign))─┬─count(multiply(Code, Sign))─┬─avg(multiply(Code, Sign))─┐
│ A001 │ 100 │ 1 │ 100 │
│ A000 │ 200 │ 1 │ 200 │
└──────┴───────────────────────────┴─────────────────────────────┴───────────────────────────┘2 rows in set. Elapsed: 0.005 sec.
當然還有一種方式就是在查詢數據前執行分區合并操作optimize table collapsing_table final;,但這種方式效率極低在生產中慎用
同時 CollapsingMergeTree 還存在一些問題,例如在分區合并前用戶是可以看到所有數據的。當然上面所說的問題都不是最致命的,CollapsingMergeTree 最致命點在于對于 sign 的寫入順序有嚴格的要求,對于一個刪除操作正常的順序應該是先寫入 1 再寫入 -1
insert into collapsing_table values ('A002', 300, '2023-08-09 00:00:00', 1);
insert into collapsing_table values ('A002', 300, '2023-08-09 00:00:00', -1);
但如果顛倒順序
insert into collapsing_table values ('A002', 300, '2023-08-09 00:00:00', -1);
insert into collapsing_table values ('A002', 300, '2023-08-09 00:00:00', 1);
則不會被刪除。而在生產環境一旦 CollapsingMergeTree 在多線程中處理就無法保證寫入順序了。
當然幸運的是 clickhouse 也注意到 CollapsingMergeTree 的缺點并推出了新的表引擎 VersionedCollapsingMergeTree,在 CollapsingMergeTree 的基礎上將按照寫入順序折疊修改為按照版本號順序進行折疊,而版本號交由用戶來管理。VersionedCollapsingMergeTree 引擎的操作就交給讀者來體驗,畢竟下面還有一種更貼合 TP 數據庫操作的刪除操作
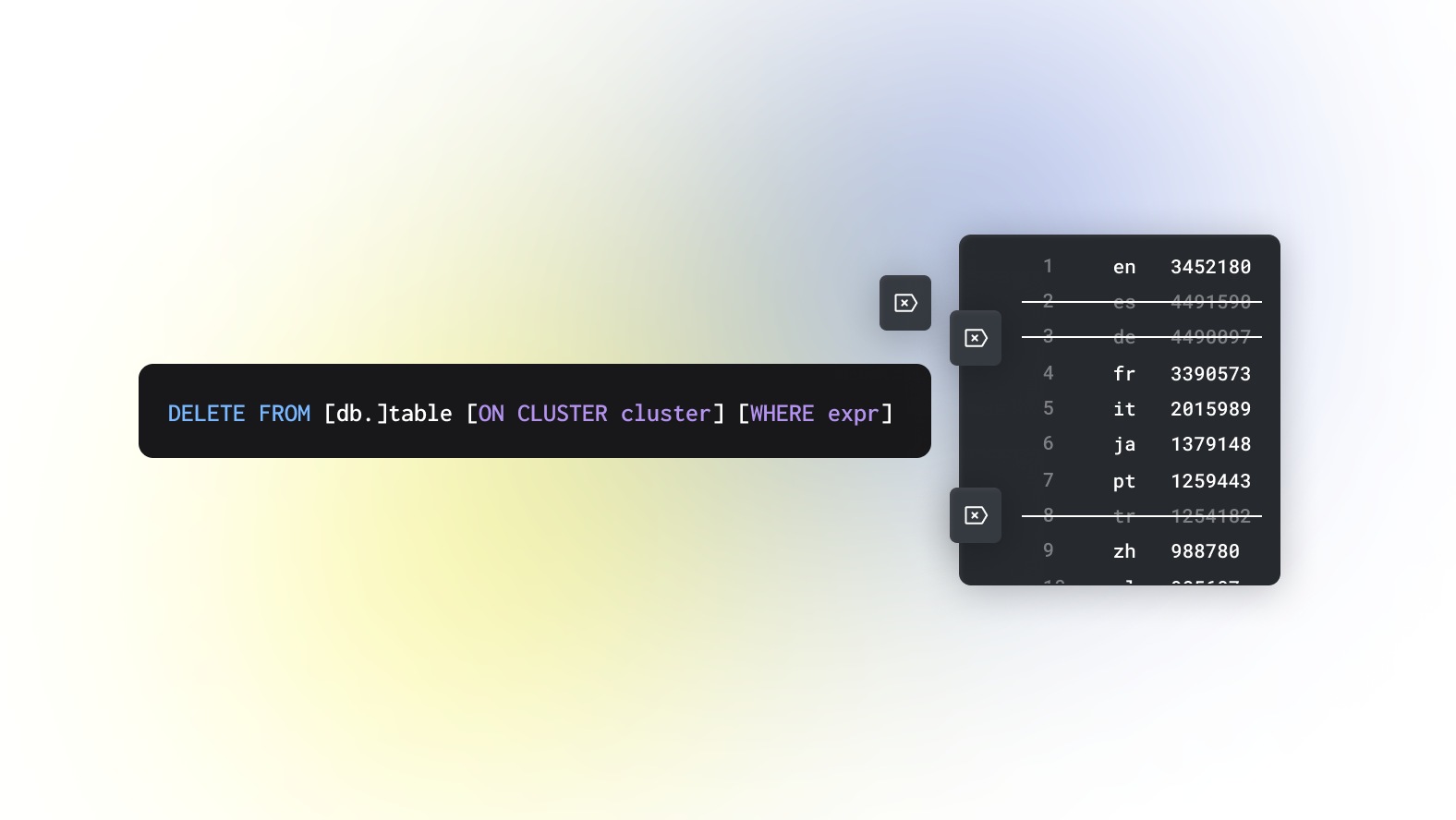
三、lightweight
上面介紹了通過 mutation 和 mergeTree 來實現刪除操作,但是 mutation 操作太重,mergeTree 則需要修改 sql 且刪除操作受分區合并時機影響。從 clickhouse v22.8 開始提供了一個輕量級刪除功能且語法為標準 sql 🎉🎉🎉
3.1 實操
準備表和數據
create table lightweight_operate
(UserId UInt64,Score UInt64,CreateTime DateTime
) engine = MergeTree()partition by toYYYYMMDD(CreateTime)order by UserId;insert into lightweight_operate
select number,abs(number - 100),'2023-08-08 00:00:00'
from system.numbers
limit 1000000;insert into lightweight_operate
select number,abs(number - 100),'2023-08-09 00:00:00'
from system.numbers
limit 1000000;
同樣刪除 20230808 分區中 1000-10000 之間的所有數據,sql 如下
delete from lightweight_operate where toYYYYMMDD(CreateTime) = 20230808 and UserId between 1000 and 10000;
驗證一下
select count() from lightweight_operate where toYYYYMMDD(CreateTime) = 20230808;Query id: 0344da3b-5ea5-436d-ba29-cfb1a8e3420e┌─count()─┐
│ 990999 │
└─────────┘1 row in set. Elapsed: 0.008 sec. Processed 1.00 million rows, 5.00 MB (128.59 million rows/s., 642.93 MB/s.)
成功刪除
3.2 原理
查看磁盤目錄
? ll
total 16
drwxr-x---@ 16 wjun admin 512 Aug 9 21:09 20230808_1_1_0
drwxr-x---@ 18 wjun admin 576 Aug 9 21:10 20230808_1_1_0_3
drwxr-x---@ 16 wjun admin 512 Aug 9 21:09 20230809_2_2_0
drwxr-x---@ 15 wjun admin 480 Aug 9 21:10 20230809_2_2_0_3
drwxr-x---@ 2 wjun admin 64 Aug 9 21:09 detached
-rw-r-----@ 1 wjun admin 1 Aug 9 21:09 format_version.txt
-rw-r-----@ 1 wjun admin 171 Aug 9 21:10 mutation_3.txt? du -h0B ./detached
7.7M ./20230809_2_2_0
7.7M ./20230808_1_1_00B ./20230809_2_2_0_328K ./20230808_1_1_0_315M .
可以看出輕量刪除依然是一個 mutation 操作,從system.mutations表也可以驗證,但輕量刪除生成的新的分區 20230808_1_1_0_3 僅 28K,那么輕量刪除和 mutation 刪除的區別在哪
查看 20230808_1_1_0_3 磁盤目錄
wjun :: data/delete_operate/lightweight_operate ?stable? ? ll 20230808_1_1_0_3
total 15800
-rw-r-----@ 2 wjun admin 18042 Aug 9 21:09 CreateTime.bin
-rw-r-----@ 2 wjun admin 375 Aug 9 21:09 CreateTime.cmrk2
-rw-r-----@ 2 wjun admin 4004938 Aug 9 21:09 Score.bin
-rw-r-----@ 2 wjun admin 415 Aug 9 21:09 Score.cmrk2
-rw-r-----@ 2 wjun admin 4004915 Aug 9 21:09 UserId.bin
-rw-r-----@ 2 wjun admin 415 Aug 9 21:09 UserId.cmrk2
-rw-r-----@ 1 wjun admin 4493 Aug 9 21:10 _row_exists.bin
-rw-r-----@ 1 wjun admin 236 Aug 9 21:10 _row_exists.cmrk2
-rw-r-----@ 1 wjun admin 589 Aug 9 21:10 checksums.txt
-rw-r-----@ 1 wjun admin 110 Aug 9 21:10 columns.txt
-rw-r-----@ 2 wjun admin 7 Aug 9 21:09 count.txt
-rw-r-----@ 1 wjun admin 10 Aug 9 21:10 default_compression_codec.txt
-rw-r-----@ 1 wjun admin 1 Aug 9 21:10 metadata_version.txt
-rw-r-----@ 2 wjun admin 8 Aug 9 21:09 minmax_CreateTime.idx
-rw-r-----@ 2 wjun admin 4 Aug 9 21:09 partition.dat
-rw-r-----@ 2 wjun admin 173 Aug 9 21:09 primary.cidx
發現多了一組 _row_exists 文件而其余文件的 inode 連接數均為 2,也就是說輕量刪除是真正的給字段添加了一個標記。
在查詢的時候過濾
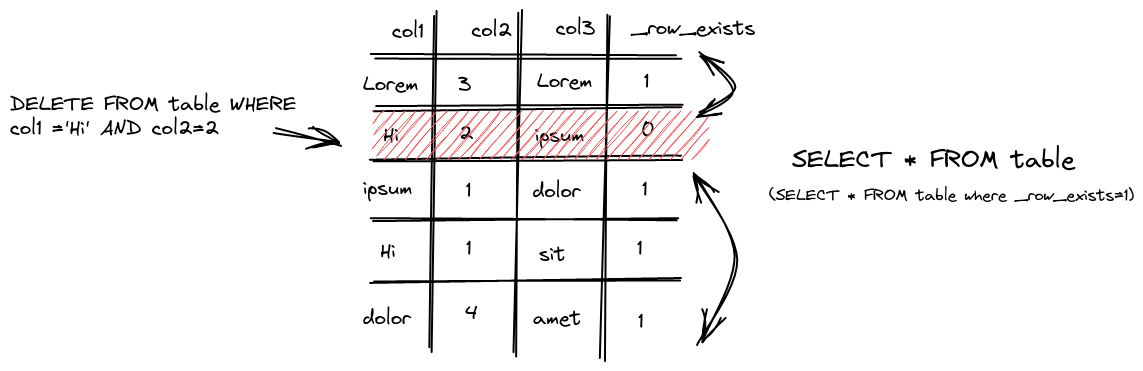
在分區合并的時候刪除
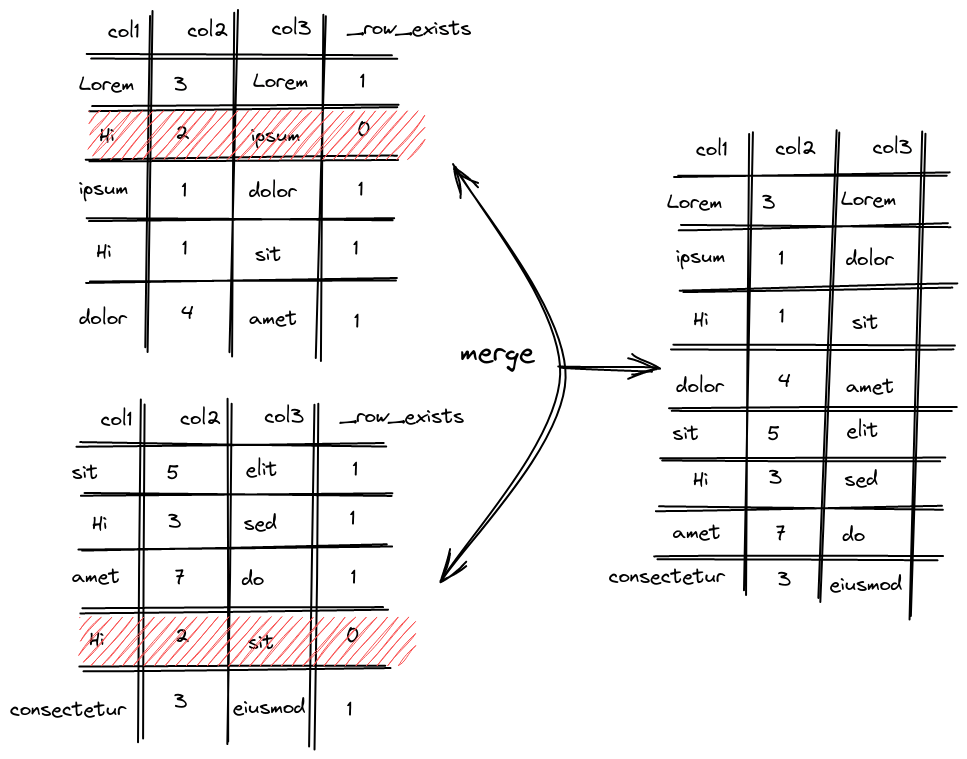
比 mutation 輕的點在于輕量刪除不會重構整個分區目錄而是重寫 _row_exists 文件這樣涉及到的修改會少很多,至于分區的拷貝和不涉及刪除操作的分區操作邏輯則和上面介紹的 mutation 流程一致
3.3 不足
輕量刪除的設計思路相比之前的會好上很多,但 clickhouse 畢竟不是 TP 數據庫,目前輕量刪除依然存在一些問題和限制,如:
- 輕量刪除是異步的,只有在分區合并的時候才會被真正刪除(輕量刪除執行完是邏輯上刪除)
- 對 wide 類型分區友好,對于 compact 類型分區會產生較大的磁盤 IO
- 會修改分區在磁盤中的名稱,可能會影響備份
對于 mutation 是否為異步操作可以通過參數進行配置,只需將mutations_sync置為 true 即可
set mutations_sync = true;
至于其它的不足需要用戶結合實際場景進行取舍
)
》)




二叉樹part07)
)


)


)





